
![]()
Amazon Web Serviceが提供するサービスRedshiftは、PostgreSQLをベースとして開発された、分析用途のデータ処理に特化したデータベースです。
AWSではこのサービスを、DWaaS(Data Warehouse as a Service)と位置付けています。
Redshiftはペタバイト単位の拡張性・超並列演算、「カラムナ型」と呼ばれる特別なデータ格納方式による高速処理、そして低額の従量課金制という特徴を持ち、ビッグデータ分析に当たっての、その大量のレコードデータの処理に使われます。
こういった分析用途の大規模なデータ処理機構としてはHadoopがよく利用されてきました。
HadoopはAWSからもAmazon Elastic MapReduce(EMR)というサービス名で提供されていますが、これとRedshiftの違いはどこにあるのでしょうか?
Hadoopは、データフォーマットの自由度の高さから、機械学習のような用途にも使われるなど、幅広い用途に適用できます。
しかし、Redshiftはリレーショナル構造データからの分析に特化している点から来る強みをもっています。
RedshiftはこれまでのRDBMSと同じくリレーショナル構造のデータを扱いますが、前述のとおり実際のデータ構造としては、列データの縦覧に最適化された「カラムナ型」を採用しています。
分析用途では行ではなく列を重視した計算を行うため、従来の行を重視したデータ構造ではなく、列を重視したデータ構造を採用することにより、より優れたパフォーマンスを発揮できるようになっています。
また、Hadoopのデータフォーマットの自由度の高さは、逆にRDBの代用品ではないという点で扱いづらいということがありました。
さらにHadoopの構築や運用は時間や手間がかかることが多く、ちょっとした用途に使うにはとっつきづらいという難点があります。
この点、Redshiftは企業にある既存の構造化データからの分析にフォーカスし、より手軽に、より安く、より効率的なパフォーマンスを提供しています。
また、Redshiftへの接続は、Amazon製のJDBCおよびODBC、またPostgreSQLの.Netドライバであるnpgsqlでも可能であるため、各種ドライバの利用によりソフトウェアとの連携・統合も容易です。
このようにエンタープライズユーザが使うに際して導入のハードルを下げることにも注力しています。
続いてRedshiftのシステムですが、内部的には複数台の(EC2インスタンスと同等の)ノードで構成された1つのクラスタで、それを外部には単一のデータベースのように見せています。
各ノードには役割があり、1台のリーダーノードが接続を引き受け、受け取ったクエリを計算役のコンピュートノードに渡します。
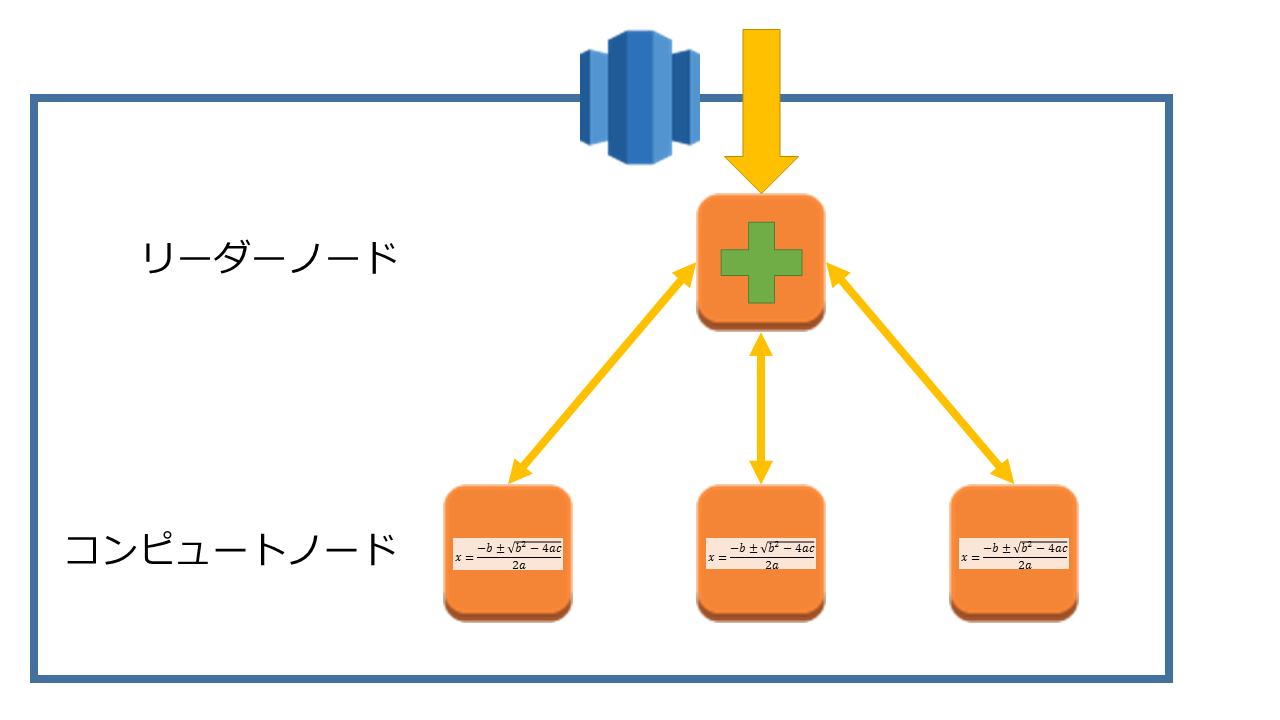
コンピュートノードはS3やDynamoDBなどに蓄積されたデータを参照し、クエリを実行した結果を返却します。
クエリの内容によってはコンピュートノードは複数台作成され、それぞれのノードで行われた計算結果をリーダーノードがまとめてクエリの結果として返却します。
このようにRedshiftには、処理性能を向上させるために役割分担を行うクラスタシステムを導入しつつ、簡単に利用できるように表にはその複雑さを出さない改良を加えられています。
Redshiftは既存のデータベースと同じようにSQLクエリでデータの収集が可能ですが、その反面既存のリレーショナルデータベースと同じ問題を抱えています。
その一番の典型例は、クエリに対しデータ内容や形式が最適化されていない場合、応答に時間がかかること、があります。
これはハードウェア面の工夫ではどうしてもカバーできない問題です。
通常のリレーショナルデータベースでは主キーやインデックスの付与により、データ取得の効率化を図りますが、PostgreSQLから改造された列指向のRedshiftには主キー・インデックスの概念はありません。(正確には、形式的に存在してはいます。)
その代わりに、SORTKEYとDISTKEYという2つのキーが用意されており、これを利用することにより性能向上を図れます。
SORTKEYは、データのディスク上の格納順序を司る項目です。
Redshiftのデータはある程度のサイズでデータブロックとしてまとめて保存されます。
SORTKEYを指定すればそれを基準にデータブロックを格納するため、クエリ対象のSORTKEYがまったくないデータブロックにはそもそもI/O処理が発生しないようにでき、その分処理が高速化できます。
SORTKEYとして指定するべきカラムとしては、クエリの範囲・等式検索でよく指定されるカラムやJOINするクエリのときにJOINの基準となるカラムです。
DISTKEYは、コンピュートノードへのデータ割り振りを決定する項目です。
割り振りの方法は以下の3種類あります。
- DISTKEYに基づいてデータが分散する KEY
- すべてのノードにデータをコピーする ALL
- ラウンドロビンでデータが分散する EVEN
使い方としては、以下の通りとなります。
- ごく小規模なテーブルでは、分散させるよりは ALL にしてすべてのノードに配布したほうがパフォーマンスが上がります。
- 値が全体を通して偏りが少なく一様であるカラムに対してDISTKEYを指定する。KEYでは指定されたDISTKEYに従ってデータが分散配置されます。
特にそのキーが複数のテーブル間でジョインを頻繁に行う場合に使用するカラムであればパフォーマンスが上がります。 - フィールドのデータ内容がよくわからない状態、またはデータ内容が非正規の状態で、ALLまたはDISTKEYどちらが適切か判断できない場合は EVEN を使用する。
もしジョインを使ったクエリの結果返却が遅い場合、EXPLAINを使ってクエリの実行計画を確認することが可能です。
このEXPLAIN句の使用方法および結果はPostgreSQLとほぼ同じです。
この結果では様々な情報が返ってきますが、「XN Hash Join」に続いて「DS_BCAST_INNER」「DS_DIST_BOTH」という記載があると、要求されたクエリに対し、データ配分に問題があり、不要な全件走査など、処理において余計に時間がかかっていることを指しています。
(下記画像は通常のPostgreSQLでのクエリ計画の一例)
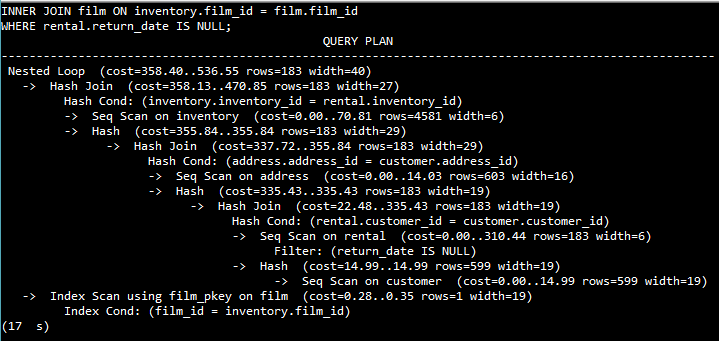
このような場合、その次の行にHash Cond: ("outer".venueid = "inner".venueid)といった形でジョインで使用されたカラム名が出ていますので、それに従ってALTER TABLEなどを使いジョインに使用するカラムをDISTKEYにする、SORTKEYを適切なフィールドに設定することで対処可能です。
設定後再度EXPLAINを実行してDS_DIST_NONE/DS_DIST_ALL_NONE/DS_DIST_INNER/DS_DIST_ALL_INNERになればパフォーマンスが改善されています。
このように、Redshiftでは構築が簡単なだけでなく、クエリの改善点も見つけやすいなど、運用面での配慮もなされている優れたデータウェアハウスといえます。
APNテクノロジーパートナーである弊社取り扱いの異種RDB間データレプリケーションツールDBMotoでは、Redshiftへのデータレプリケーションに対応しています。
DBMotoを使えば、リアルタイムでかつオンラインでのデータレプリケーション、異種データベース間でのスムーズなデータ連携が実現できます。
このほかRDSやSAP HANA、EC2上のデータベースへのレプリケーションにも対応しています。
詳細は弊社AWS対応ソリューション紹介ページをご覧ください。
関連したトピックス
- Amazon Redshiftに対してOracle、AS/400、SQL Server、MySQLなどからデータをリアルタイムにレプリケーション[DBMoto]
- PostgreSQLに対してバルクインサートが可能に【DBMoto Ver8.5新機能①】
- DBMotoからPostgreSQLへ接続するには・・・Npgsqlと外部接続の設定
- Gluesyncのレプリケーションソース(CDC付)およびレプリケーションターゲットとしてのDynamoDBのサポート
- GlueSyncでNoSQL活用を加速:データモデリング編
- Amazon Web Service(EC2/RDS)へオンプレミス(自社)データべースをリアルタイムにレプリケーション[DBMoto]
- データベースのバックアップはどのように業務を遂行しているかに依存する
- MySQLを最適化するための10の秘訣
- DBMotoレプリケーションに必要なOracleユーザ権限
- 進化するクエリと PostgreSQLの台頭:そのデータベー スパフォーマンス重要性

 RSSフィードを取得する
RSSフィードを取得する


Amazon Redshiftに接続しビッグデータを活用、そして自社Webへチャート/レポート/ダッシュボードで可視化:EspressReport ES Cloud =>
https://www.climb.co.jp/blog_espress/archives/1169