Gluesync用のAzure Cosmos DB コネクタがリリースされ、(CDC)変更データキャプチャとターゲット機能の両方が提供されています。 この多機能なアップデートにより、企業はAzure Cosmos DBとデータを同期し、そこからの変更をキャプチャできるようになり、データ統合とリアルタイム分析のための包括的なソリューションが提供されます。
Azure Cosmos DB:クラウドネイティブアプリケーション用のマルチモデルデータベース
Azure Cosmos DB は、Microsoft Azure が提供する完全マネージド型の NoSQL データベースサービスです。 ドキュメント、キーバリュー、ワイドカラム、グラフデータベースをサポートするマルチモデルデータベース機能を提供します。 Azure Cosmos DB コネクタを使用すると、Azure Cosmos DB へのデータの送信と Azure Cosmos DB からのデータの受信の両方が可能になり、情報を一元化して詳細な分析に利用できるようになります。
● Microsoft SQL Server: Microsoft SQL Serverの大きな利点は、複数のエディションが用意されていることです。これは、組織がデータベース戦略を慎重に調整するのに役立ちます。Oracle同様、Microsoft SQL Serverもまた、エンタープライズ・アプリケーションに十分な機能とパフォーマンス、オンプレミスおよびクラウドベースのインスタンスのサポート、包括的なセキュリティ、Linuxのサポートを提供しています。多くの場合、オラクルと価格競争力がある(エディションによるが)一方で、マイクロソフトのライセンス慣行は複雑な場合があります。そのため、最近のデータでは、MySQLとPostgreSQLが主流を占めるオープンソースデータベースへのトレンドが確認されています:
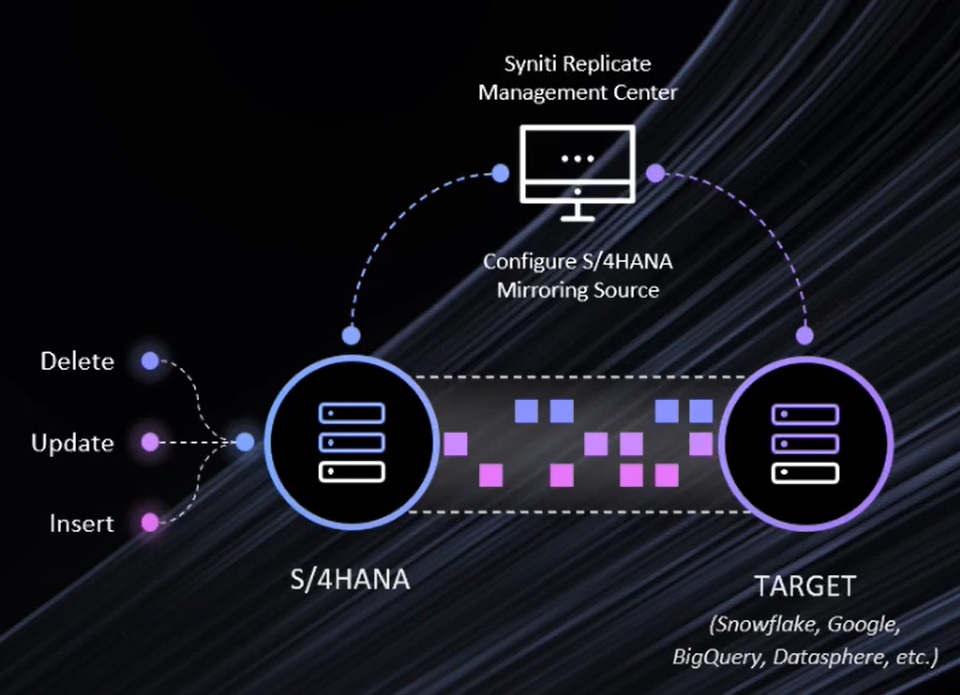
このSyniti Replicate(SDR) の新機能はデータウェアハウスへ最新でタイムリーなデータ移動をデータ分析者に提供します。Synitiは、リアルタイムの変更データキャプチャを使用して、SAPから任意のデータウェアハウスプラットフォームに最新の重要なビジネスデータをレプリケーション、アップデート、統合します。それはSAPのアプリケーション層と直接の相互作用を可能とします。これによりCDC(Change Data Capture)ベースのレプリケーションが可能とし、SAPのランタイム・ライセンス違反も回避できます。
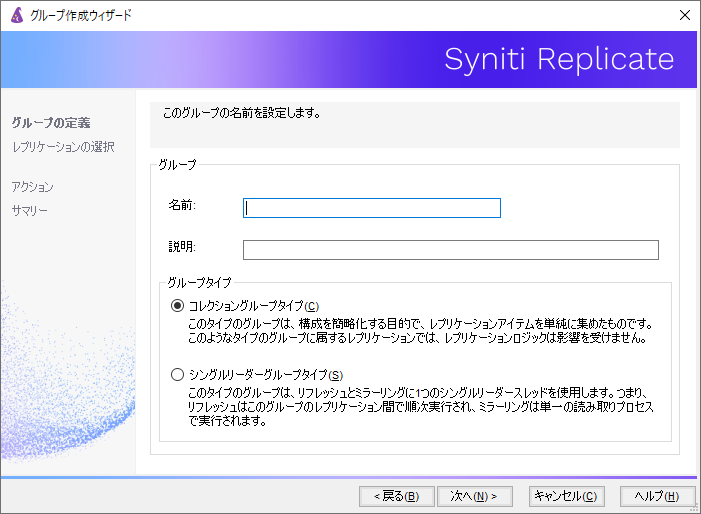
Syniti 新機能のデモ
SAP S/4HANAのデータをSnowflakeにリアルタイムにレプリケーション
(注)Remote Function Call (RFC) は、SAP システム間の通信のための SAP 標準インタフェースです。RFC は、リモートシステムで実行される関数を呼び出します。
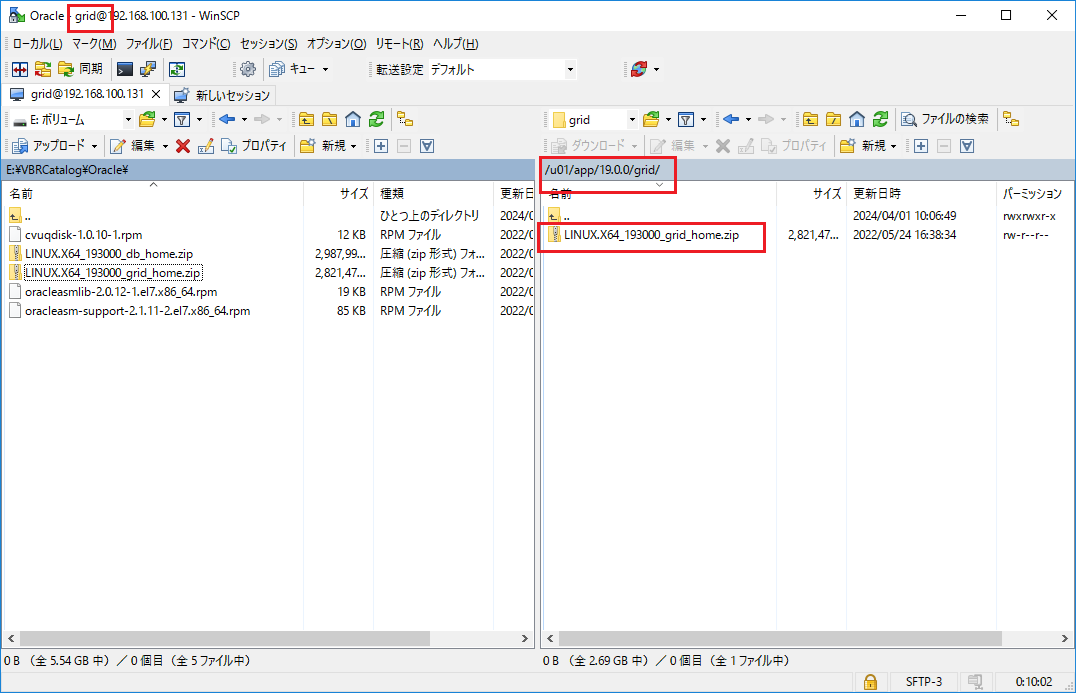
cd /u01/app/19.0.0/grid
unzip -q LINUX.X64_193000_grid_home.zip
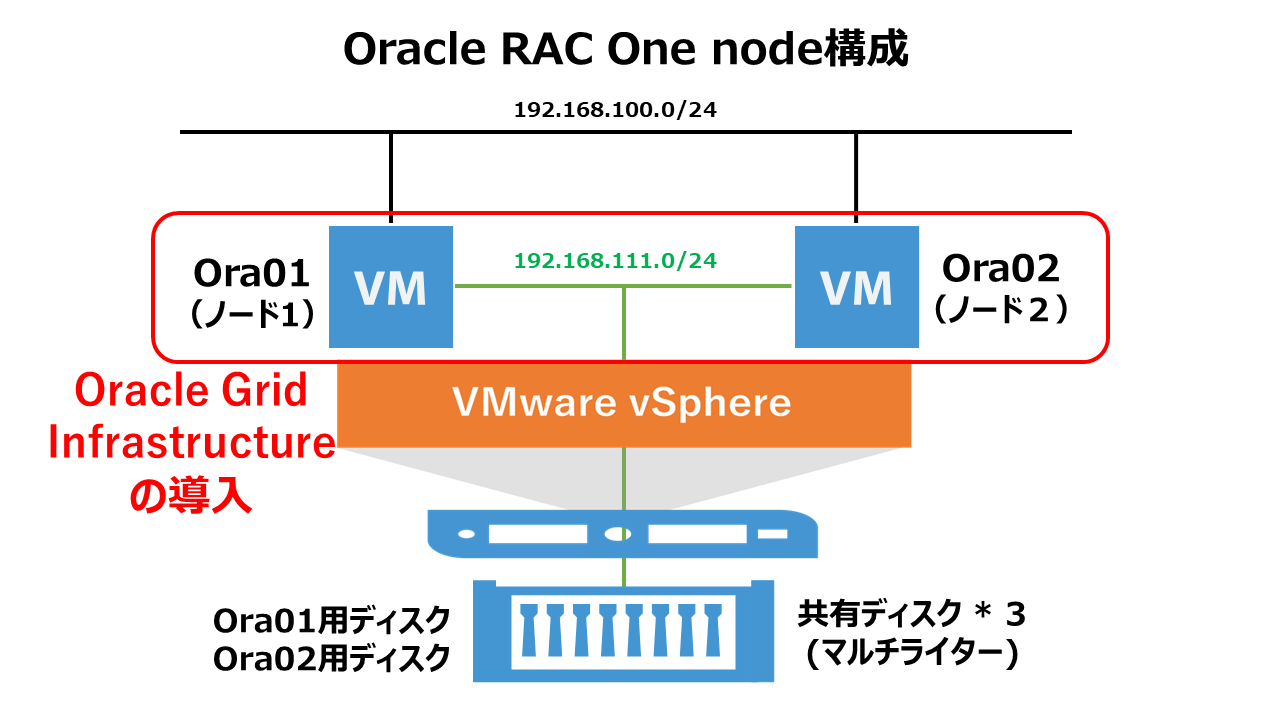
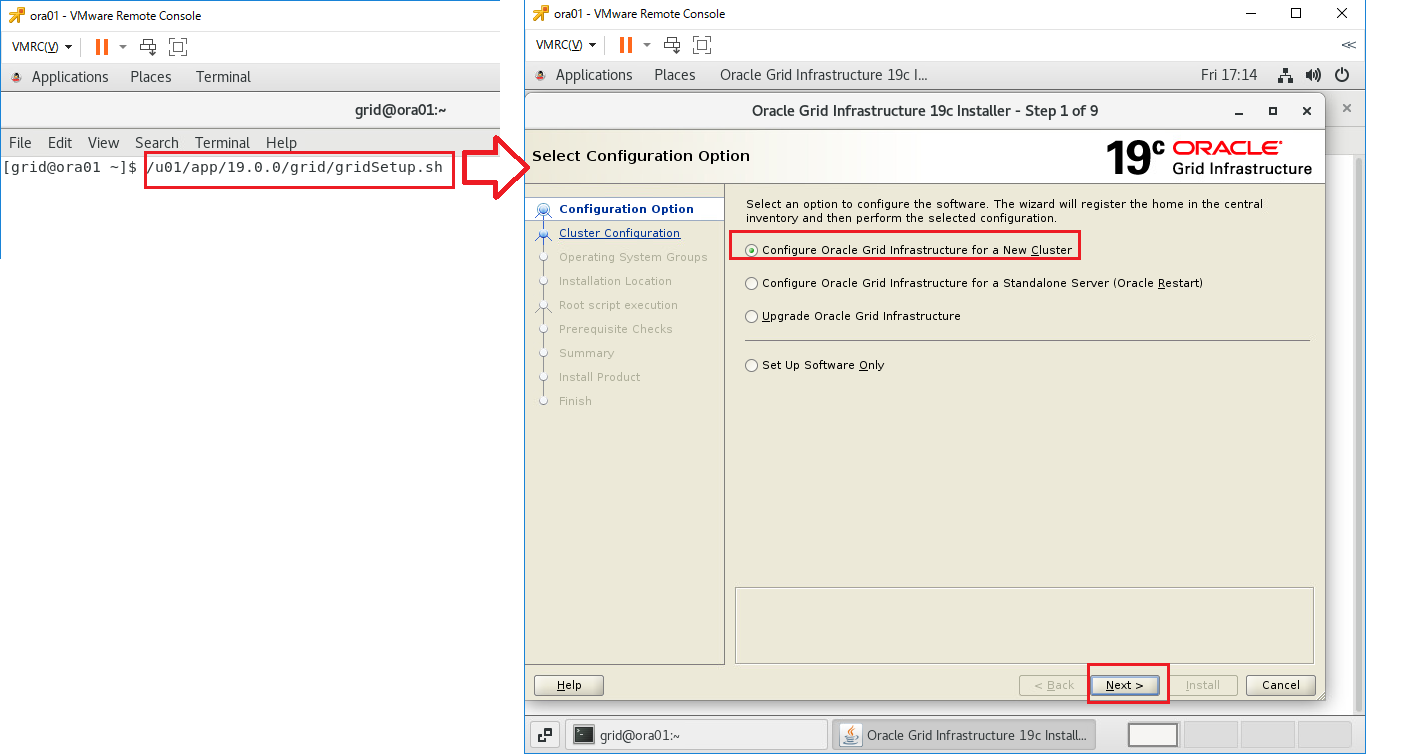
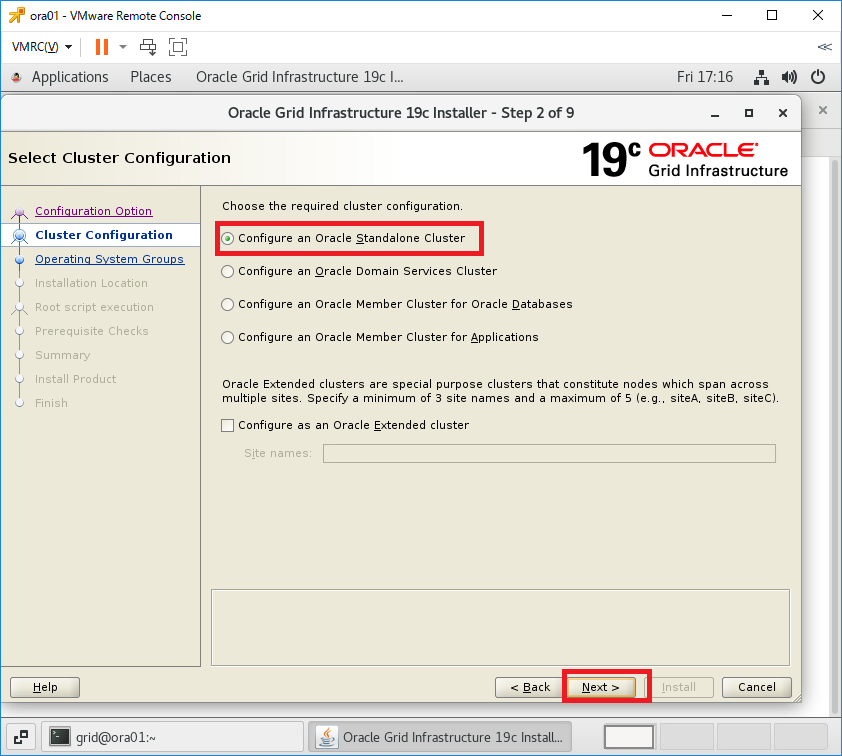
Oracle Grid Infrastructureインストールの実行
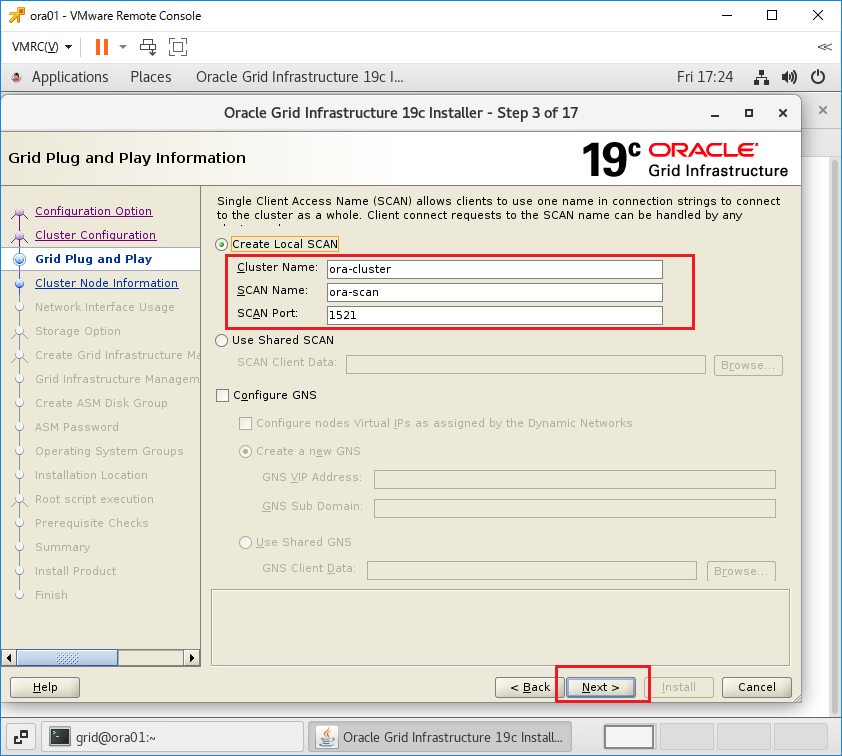
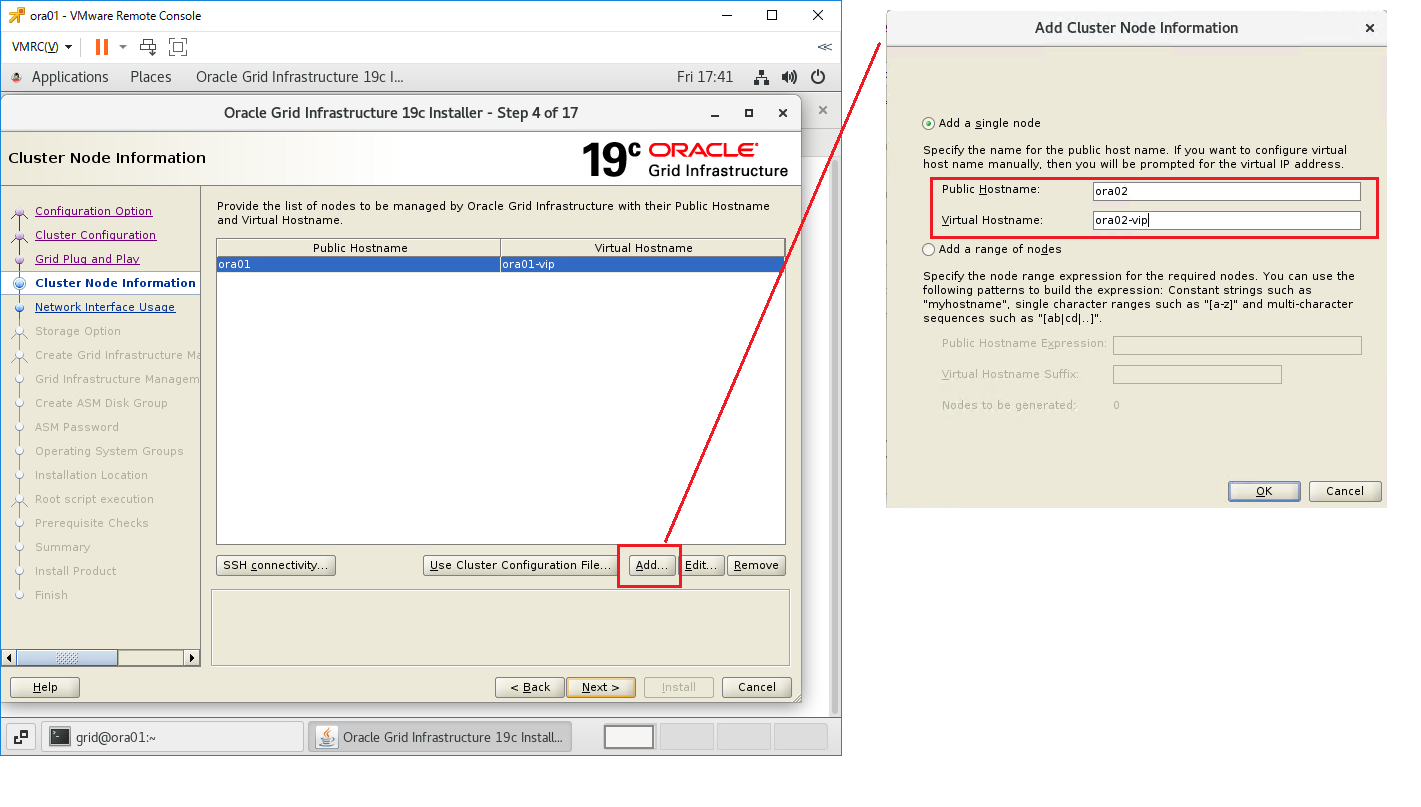
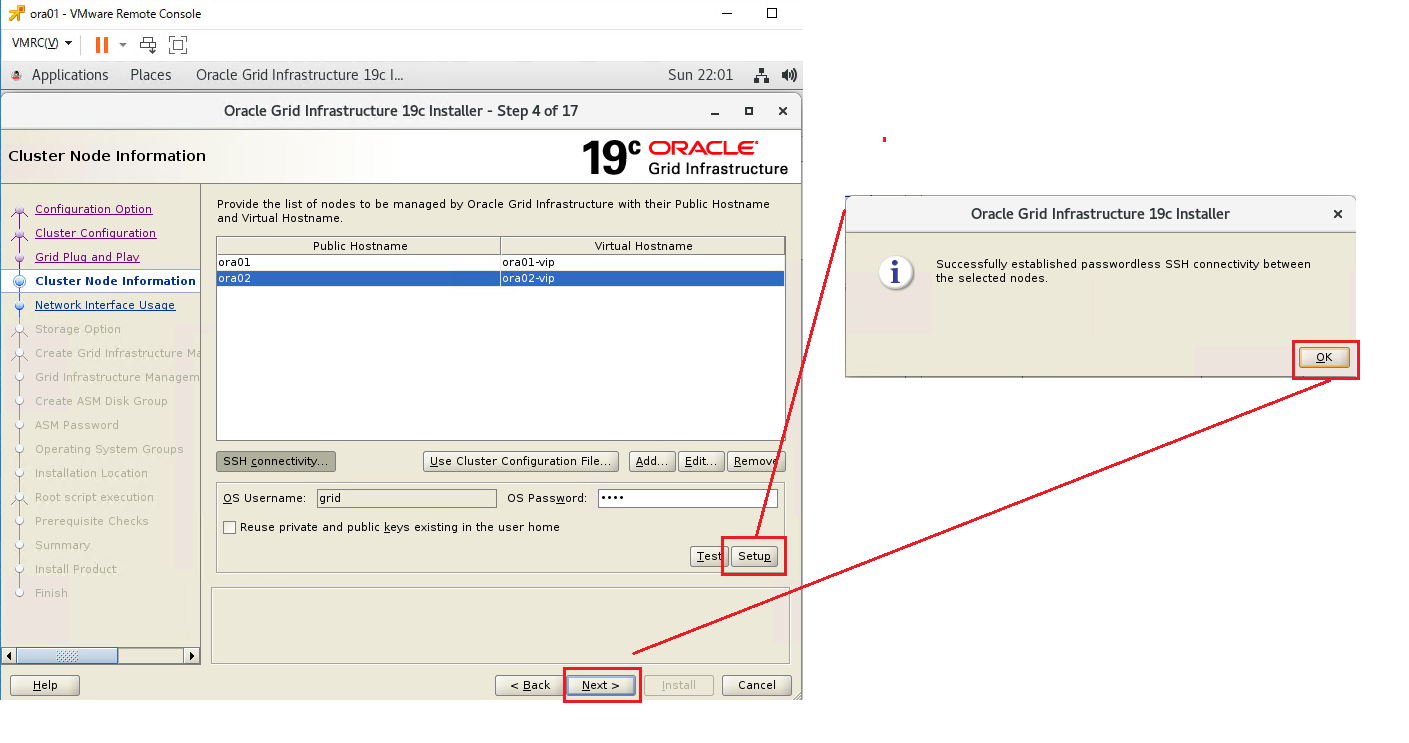
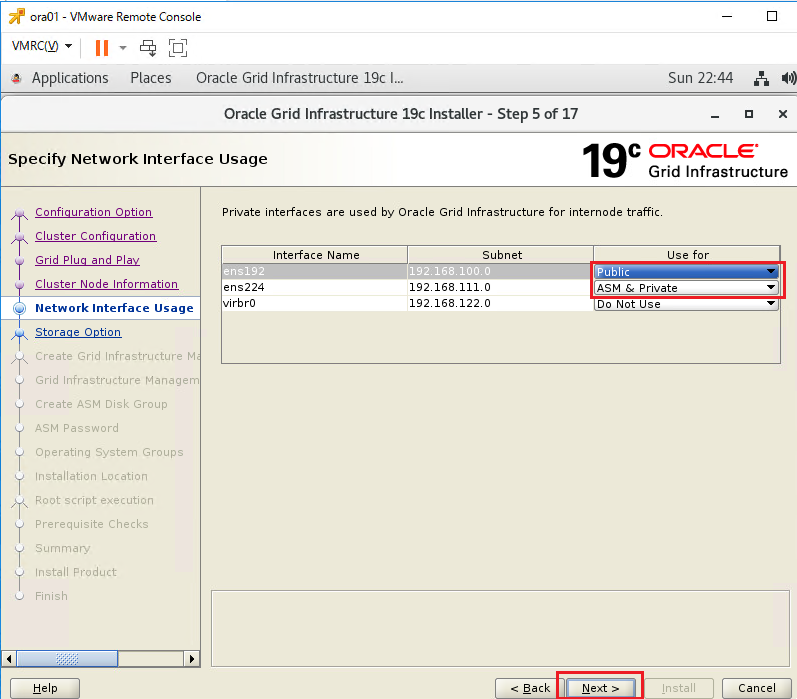
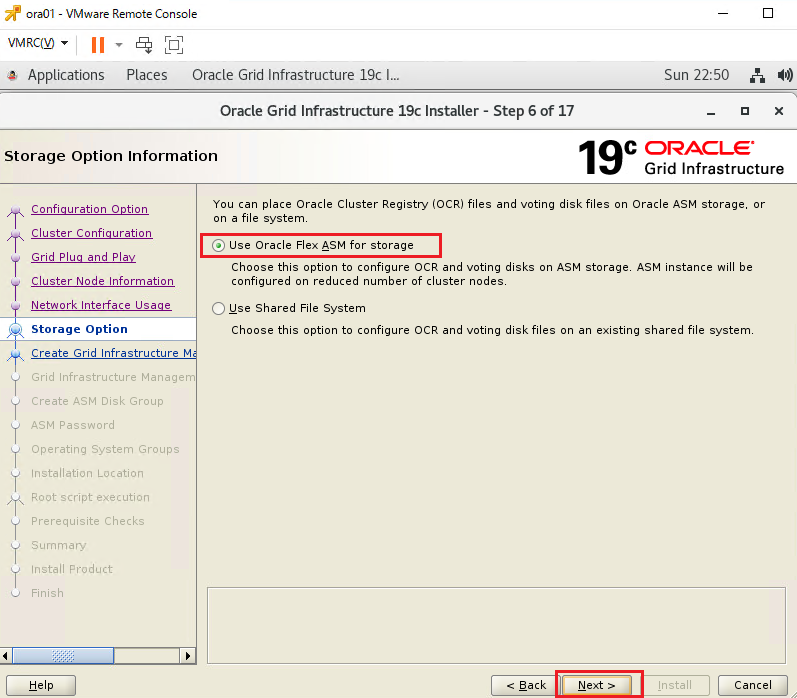
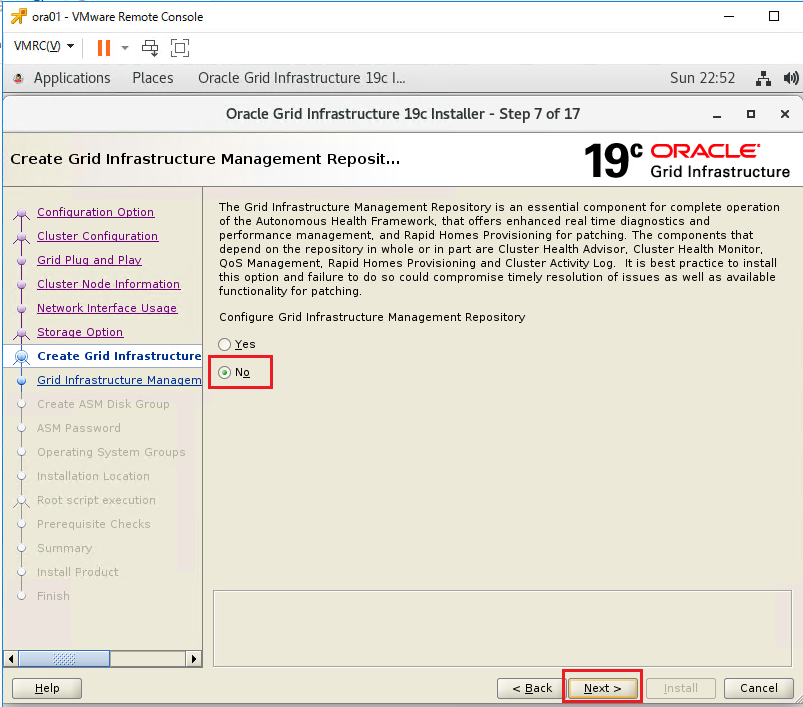
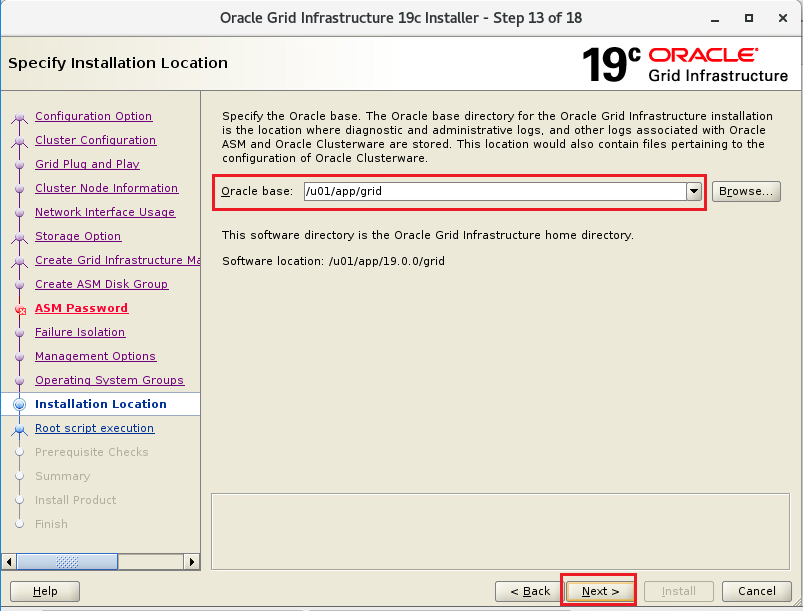
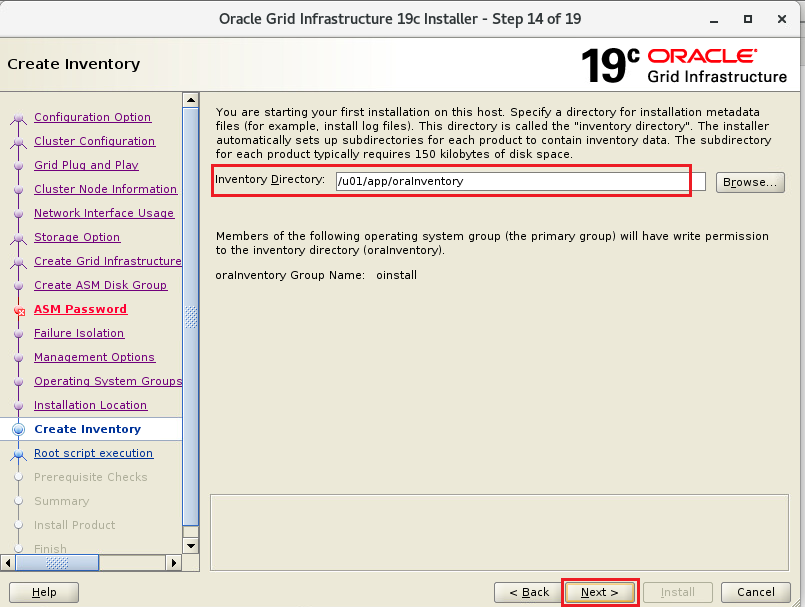
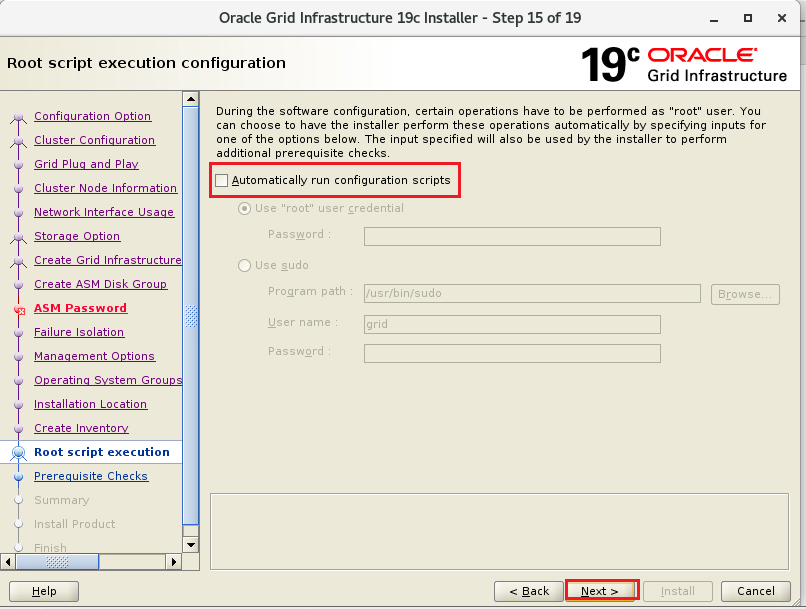
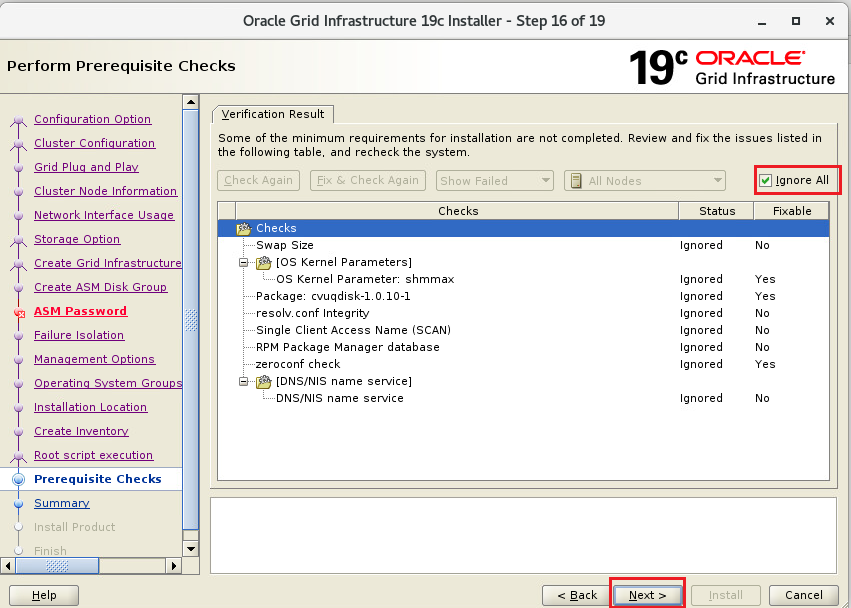
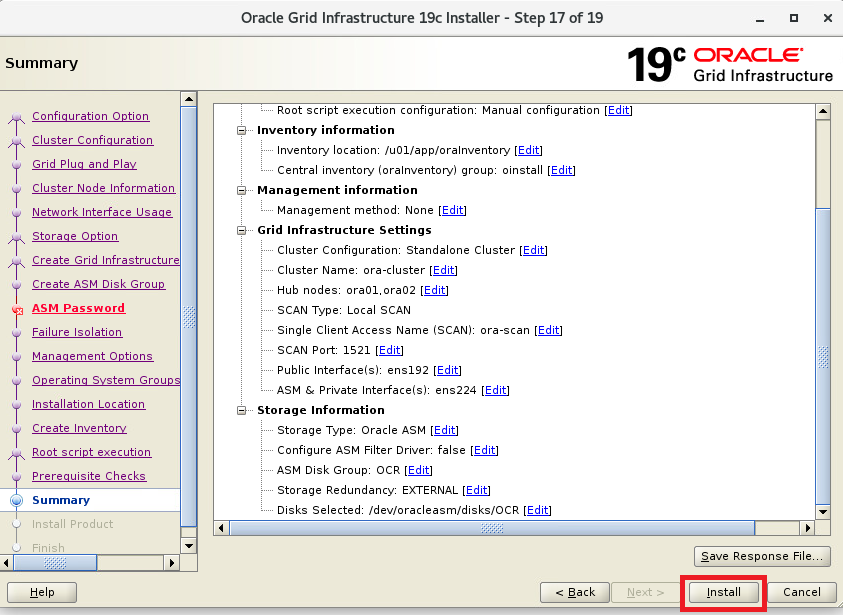
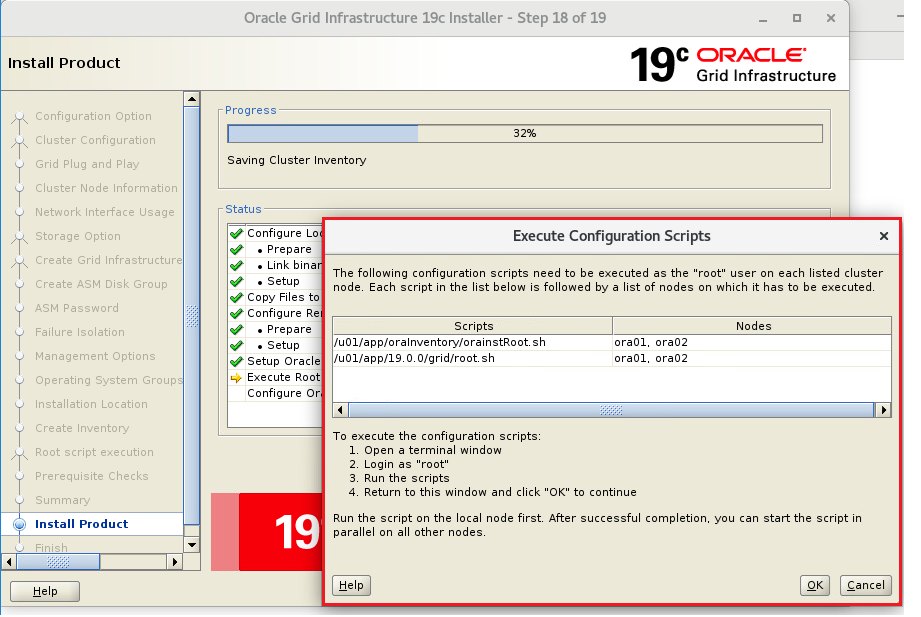
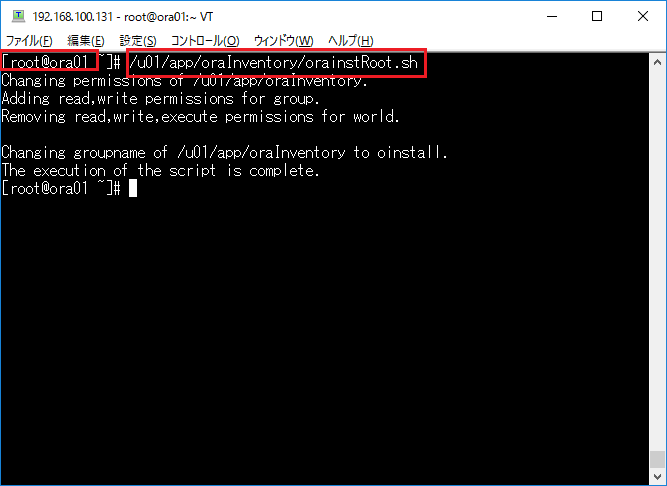
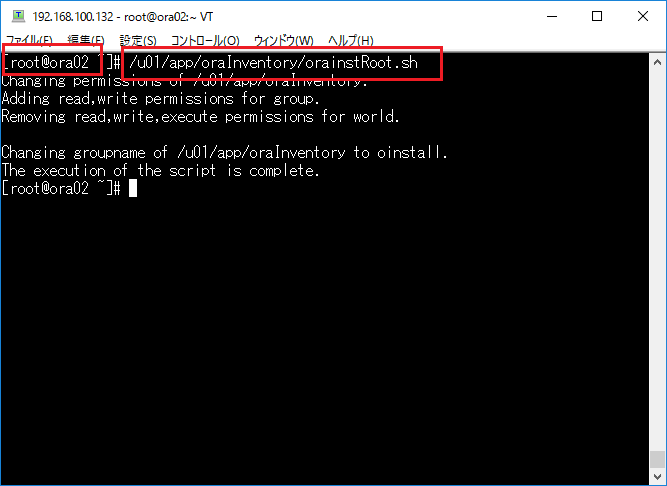
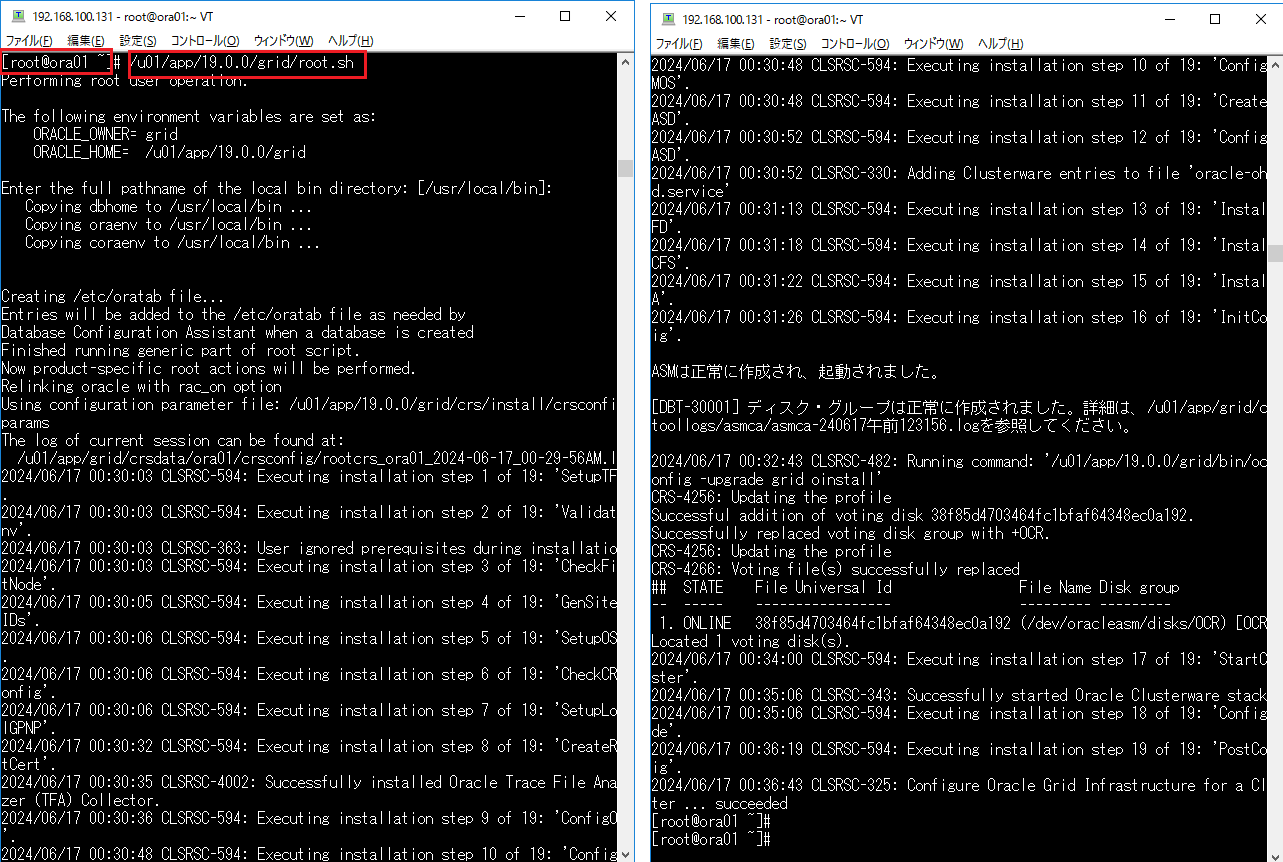
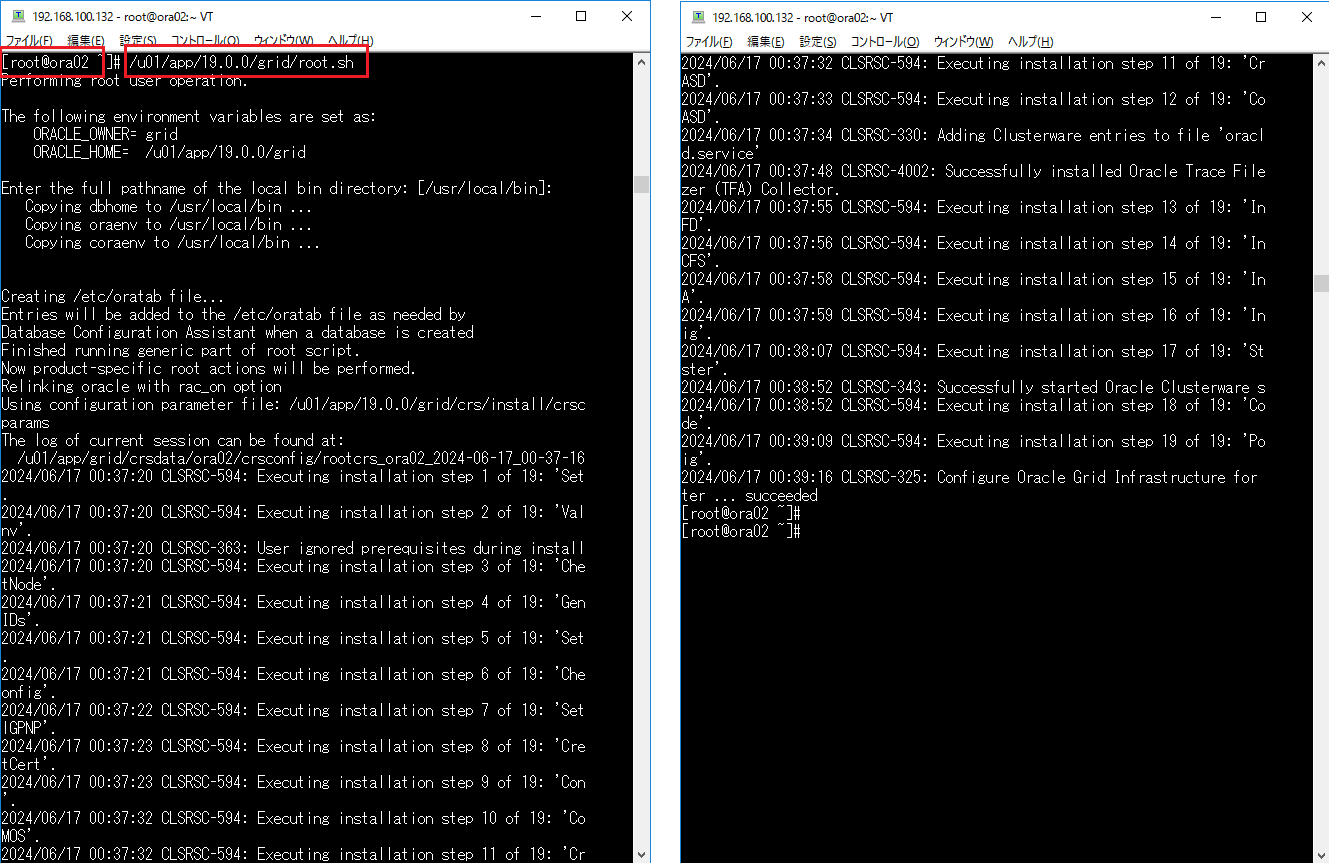
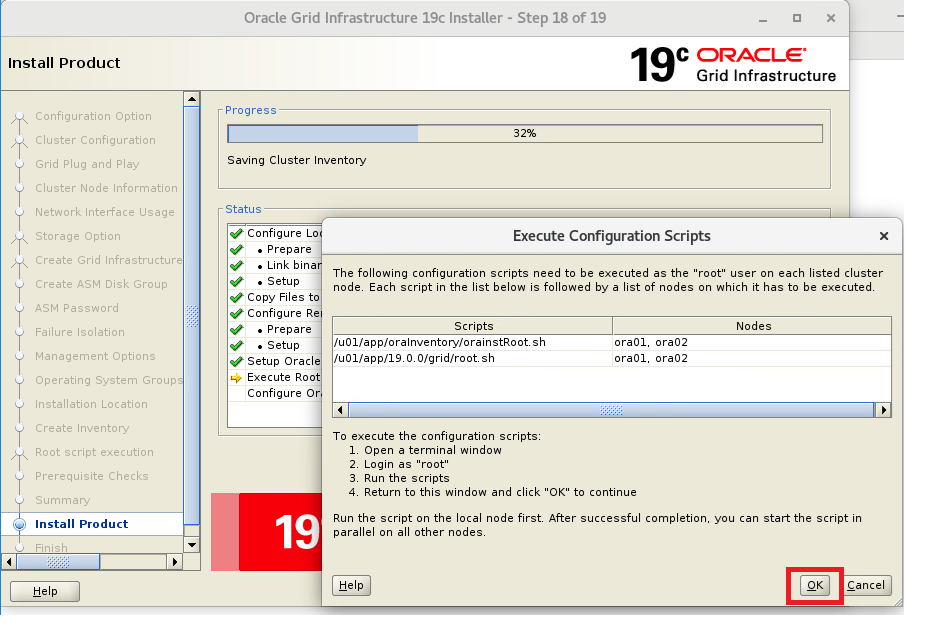
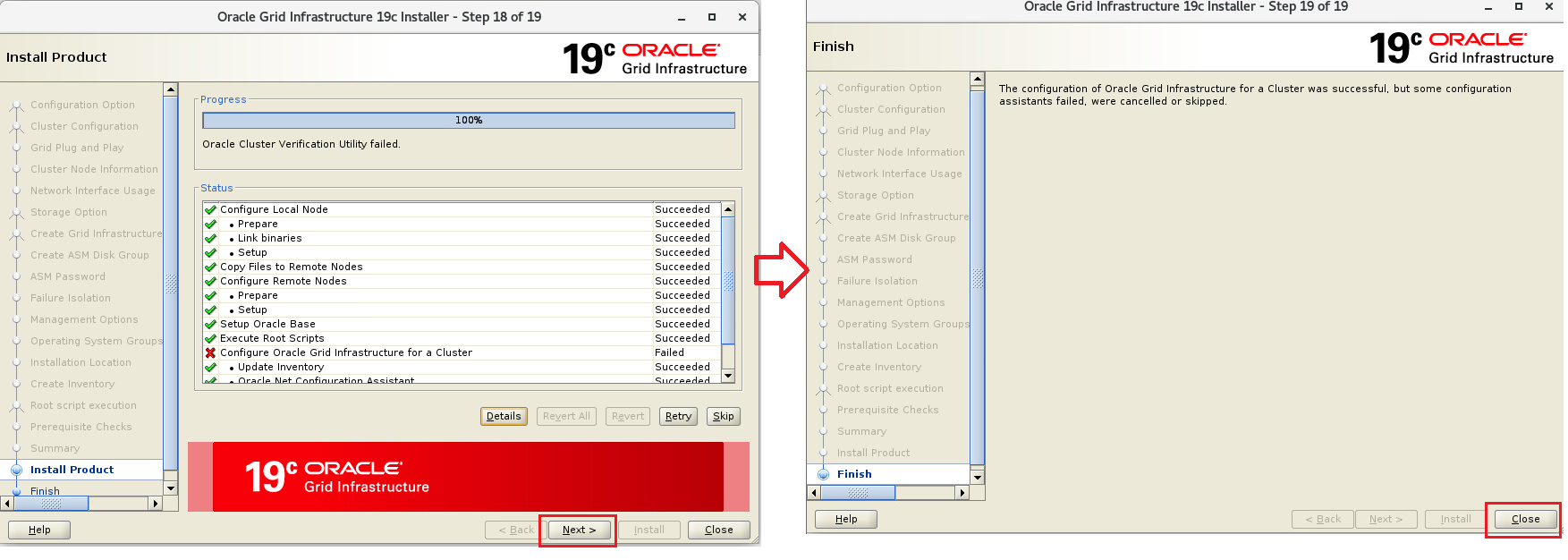
インストーラを配置したOra01マシンに対してvSpher ClientなどからgridユーザでGUIログインし、「/u01/app/19.0.0/grid/gridSetup.sh」コマンドを実行してOracle Grid Infrastructureインストールウィザードを起動します。最初の画面では「Configure Oracle Grid Infrastructure a New Cluster」を選択し、[Next」をクリックします。
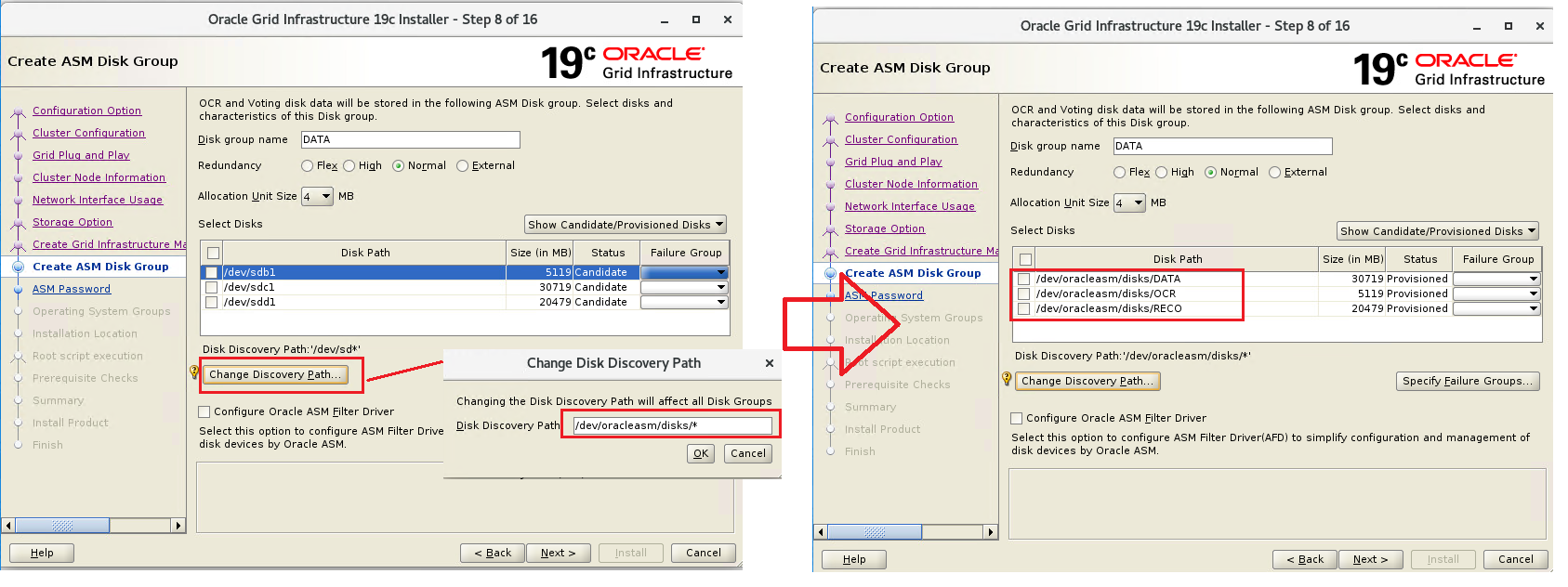
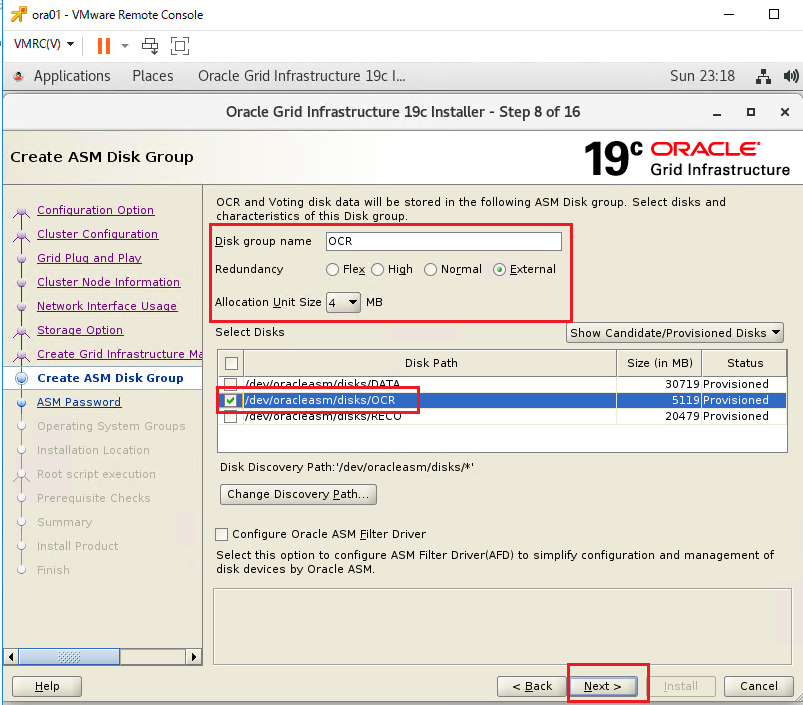
その後、OCR領域用のASMディスクの各種パラメータを指定します。今回はそれぞれ下記のように指定しました。 Disk Group Name:OCR Redundancy:External Allocation Unit Size:4MB Select Disks:/dev/oracleasm/disks/OCR
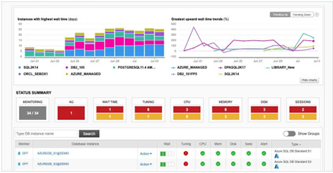
DPAはデータベースのワークロードを把握し、Wait Time Analysis(待機時間分析)を理解し、適切なツールを持っているとします。その場合、まだPostgreSQLを学習中であっても、移行したデータベースのチューニングを加速させることができます。Oracleから移行したPostgreSQLデータベースのWait分析について説明します。

























 RSSフィードを取得する
RSSフィードを取得する


