

「グローバル2000」にリストされるような有力企業のシステムをサポートするうえでしばしば気づかされるのは、Red Hat OpenShiftが実に多くの企業の業務環境に浸透していることです。OpenShiftは、Kubernetesを基盤とし、「クラウドやオンプレミスのインフラストラクチャ全体を通じて一貫したコンテナ ベースのアプリケーションを安全に構築、実装、管理」できるように設計されています。今日、OpenShiftはプライベート データセンターのみならず、パブリック クラウドにも多数採用されています。
Red HatはOpenShiftの最新リリースOpenShift 4で、Kubernetesスタックのアーキテクチャを全般的に設計しなおしています。そのため、OpenShift 4には興味深い特性や見どころが満載なのですが、それについての解説は他の専門記事に譲ります。ここで注目したいのは、OpenShift 4が企業システムにおけるKubernetesの存在感を強め、Kubernetes普及の起爆剤となる可能性です。
さらに重要なことは、OpenShift 4にOpenShift Container Storage(OCS)が付随する点です。OCSはGlusterFS(OpenShiftの旧バージョン向けRed Hatコンテナ ネイティブ ストレージで使用)から離れ、コンテナ ストレージ インターフェース(CSI)にもとづくCephとRookへの移行を遂げました。CephはOpenShift 3.x でもすでにより一般的な選択となっていたので、この移行は合理的な正しい選択と言えます。
Red HatがOCSを奨励していることや、ステートフル(stateful)なクラウド ネイティブ アプリケーションの普及が急速に進んでいることを踏まえ、Kastenは同社の企業データ管理プラットフォームK10を、OpenShift 3同様、OpenShift 4でも完璧に機能するように精密な更新を加えました。K10は、KubernetesとOpenShiftの組み合わせに適合するように設計されており、Kubernetesで稼働するアプリケーションのバックアップとリカバリ、災害復旧やモビリティのための安全確実で利便性と拡張性に優れたシステムとして、企業の運用チームから好評を得ています。K10と他の同種のシステムとの大きな違いは、アプリケーションを使用するユーザー目線を重視したアプリケーション中心型の設計と、さらにリレーショナル データベースはもちろん、NoSQLデータベースとも完全統合する点です。あらゆるKubernetesサービスやクラウド サービスと完全統合でき、現行の運用プロセスに何ら変更を強いることなく、インフラストラクチャの組み合わせを自由に選択することができます。
このブログでは、特にK10とOpenShift 4のコンビネーションのパワーを示すために、K10、OpenShift、Rook、Ceph、そして任意のアプリケーションを組み合わせて稼働させるための手順を紹介します。OpenShiftをAWS上にインストールするのは、Red Hatのおかげで非常に簡単です。try.openshift.comを通じて設定するだけですが、他のインストール方法やクラウドを通じた方法もあり、どれを利用しても問題ありません。OpenShift以外では、Helmパッケージ
マネージャーとgit(Rookコードを確認するため)を設定すれば、下準備はすべて完了です。
以下、本稿では次の4項目を順に紹介していきます。
- OpenShiftのスナップショット リストアを有効にする
- OpenShiftにRook+Cephをインストール
- エンタープライズ データ管理プラットフォームとしてK10をインストール
- テスト アプリケーションでバックアップ/リストアのワークフローを確認
I. OpenShiftのスナップショット リストアを有効にする
コンテナ ストレージ インターフェース(CSI)ベースのCephボリューム
スナップショットのリストアを可能にするには、VolumeSnapshotDataSourceのフィーチャーゲート(–feature-gate)を有効にする必要があります。OpenShiftではこのステップが非常に簡単で、ocツールのコマンドラインを実行するか、OpenShiftコンソールから行うことができます(OpenShift Procedure文書を参照)。
- OpenShiftコンソール
Administrationに切り替え → Custom Resource Definitionsページ → FeatureGateをクリック → Instancesをクリック → clusterをクリック → YAMLをクリックして編集
- コマンドライン
$ oc edit featuregate cluster
どちらの方法をとるにせよ、空のspecセクション({}で表示されます)を以下のように置き換えます。YAMLは最終的にこのようになります。
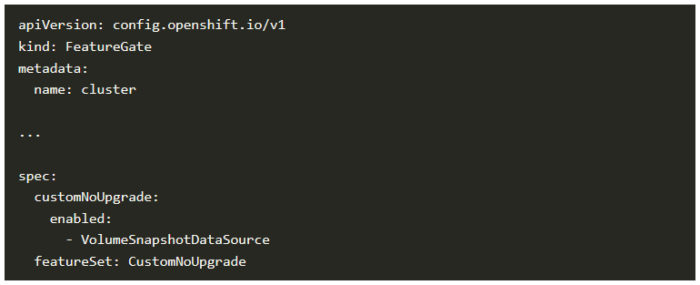
変更を加えてから、それがクラスタに実際に適用されるまでに数分かかります。変更が正しく適用されたかどうかを見極めるには、OpenShiftのポッド(pod)がすべてエラーなしで稼働しているかどうかを確認します(例:oc get pods –all-namespaces –watch)。特に、openshift-kube-apiserverネームスペースにあるすべてのポッドがRunningの状態にあることを確かめる必要があります。
正しいフィーチャーゲートが有効化されているかどうかを確認するには、以下のコマンドの実行結果から"feature-gates":["VolumeSnapshotDataSource=true"]を確認するだけです。
$ oc –namespace=openshift-kube-apiserver rsh <pod-name> cat /etc/kubernetes/static-pod-resources/configmaps/config/config.yaml
注:上記のフィーチャーゲートの有効化はOpenShiftではまだ正式にはサポートされていません。
II. OpenShiftにCSIベースのストレージRook+Cephをインストール

ここでは、OpenShiftにおけるCephベースのブロック ストレージのプロビジョニングにRookを使用します。インストール手順についての詳細は他の公式文書に譲るとして、以下に標準的なステップを紹介します。
Ceph RADOS Block Device(RDB)クラスタの設定
まず、Cephを設定するためのRookソースコードを取得します。
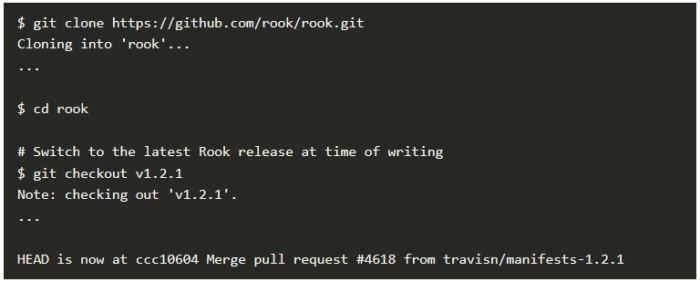
さらに、rook-cephネームスペースにRookを、次いでCephをインストールします。
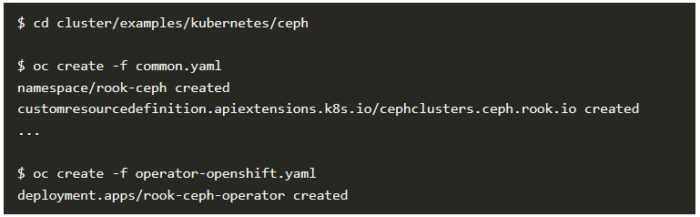
この段階で、Rook Cephオペレータの状態がRunningであることを確認します。以下のようなコマンドラインで確認できます。
$ oc –namespace=rook-ceph –watch=true get pods
オペレータの稼働状態を確認したら、テストCephクラスタをインストールします。

Cephの稼働状態を確認するには、以下のコマンドを実行して、クラスタ ヘルスがHEALTH_OKになっているかどうかを確かめます。
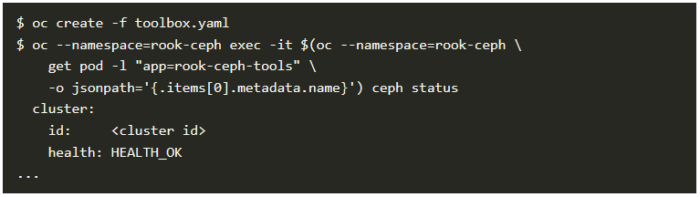
ストレージとスナップショットのプロビジョニング設定
上記のステップがすべてエラーなく完了し、rook-cephネームスペースにすべてのポッド(pod)が問題なく稼働していることを確認したら、ダイナミック ストレージ プロビジョニングを有効にし、ボリューム スナップショット定義を設定します。
まず、以下のコマンドでStorageClassをインストールします。
$ oc create -f csi/rbd/storageclass.yaml
さらに、StorageClassと同じように、CephのVolumeSnapshotClassをインストールしてCephのスナップショット機能を有効にします。
$ oc create -f csi/rbd/snapshotclass.yaml
最後に、クラスタのデフォルト ストレージ
クラスを新しいCephストレージ クラスに変更する必要があります。デフォルトがgp2だと仮定して(AWSの場合)、以下のコマンドを実行すればストレージ クラスが変更できます。

III. エンタープライズ データ管理プラットフォームとしてK10をインストール
CSI準拠のストレージ システムをOpenShiftで使用開始するための手順はこれまで述べてきたとおりですが、これはほんの入り口に過ぎません。使用するアプリケーションのデータをしっかりと管理し、有効活用するには、これまで設定した構成にデータ管理システムを追加するのがベストです。ここでは特に、データ管理プラットフォームK10のフル機能完備の無償版を使用します。K10はOpenShiftとの密接な統合が可能です。たとえば、OpenShiftのSecurity Contextポリシーに応じて完全な透明性をもって機能し、DeploymentConfigsなど、OpenShiftのエクステンションを取得することができます。
K10は、OpenShiftアプリケーション全体のバックアップとリストア、そしてモビリティを実現する安全性と利便性に優れたシステムです。たとえば、以下のようなユースケースに対応することができます。
- アプリケーション スタック全体のバックアップとリストアのプロセスを単純化し、システムを適正な状態にリセットします。
- 開発クラスタ内のネームスペースにおけるクローニングによって、デバッグを容易にします。
- 業務環境からテスト環境にデータを移して、より実効性あるテストの実施を可能にします。
K10をインストールして、CSIベースのRook/Cephと統合する
K10のインスールはいたってシンプルで、5分以内で実際に使用できるようになります。以下の手順で簡単に始めることができるのですが、詳しい情報が必要な場合はKastenのドキュメンテーションを参照してください。
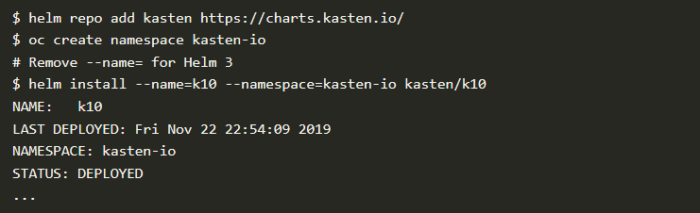
次に、Rook+Cephのインストール手順の一環として作成したVolumeSnapshotClassに、K10で使用可能にするためのアノテーションを追加します。デフォルトのStorageClassと同様に、アノテーションのVolumeSnapshotClassは1件だけに限られます。また、スナップショットのリテンションも、ここで削除ポリシーを設定することにより定義します。

IV. テスト アプリケーションでバックアップ/リストア
Redisをテスト アプリケーションとしてインストール
次に、テスト クラスタにRedisをインストールして、万能型ストレージ/データ管理システムとしてのK10の機能性を具体的に見ていきましょう。

Redisがインストールできたら、新しいCephストレージのプロビジョニングを検証します。そのためには、oc get pvを実行し、Redis永続ボリューム(PV)のStorageClassを確認します。
バックアップとリカバリのワークフロー
K10のダッシュボードには、以下のコマンドを実行すればアクセスできます。また、APIとコマンドライン インターフェース(CLI)の利用も可能です。
$ oc –namespace kasten-io port-forward service/gateway 8080:8000
上記のコマンド実行後にブラウザからhttp://127.0.0.1:8080/k10/#/にアクセスすれば、ダッシュボードが表示されます。
ダッシュボードには、下記の画像のように、自動検知されたすべてのアプリケーションがカード表示されます。それをクリックすると、そのアプリケーションの具体的な情報が表示されます。ここで、バックアップの詳細設定を定義するポリシーを作成したり、あるいは実験的に手動でフルバックアップを実行することができます。ダッシュボードのメイン画面には進行中のアクティビティ、その後は完了アクティビティが、その進行状況に応じて表示されます。さらに、アプリケーションのページで変更を加えた後にそのアプリケーションをリストア(または新しいネームスペースにクローン)することもできます。
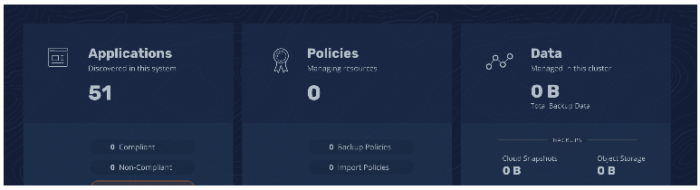
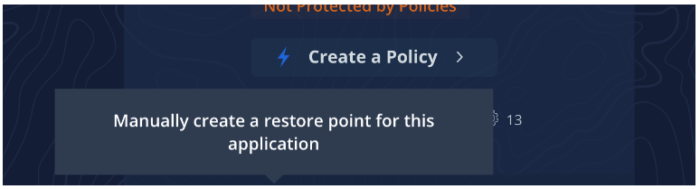

スナップショットをバックアップに変換する
上記のスナップショット作成ワークフローは、リカバリのすばやい実行に大変便利ですが、Cephに保存されるスナップショット作成を起動するだけです。つまり、障害分離が達成されているわけではなく、データ紛失に備えたデータ保護手段としては完ぺきとは言えません。その観点からは、スナップショットを単独のオブジェクト ストアにエクスポートして、バックアップを作成することが強く推奨されます。
これを簡単に行うには、定期的なバックアップとスナップショットのポリシーに加え、オブジェクト ストレージを使用して重複バックアップを保存するモビリティ プロファイルの関連ポリシーを作成するのが得策です。K10は幅広いオブジェクト ストレージ システムをサポートします。すべてのパブリック クラウドをサポートし、Minio、Red Hat Nooba、S3準拠のCeph Object Gatewayなどもに対応可能です。
さまざまなワークフローをサポートするためには、スナップショットとバックアップのリテンション スケジュールを個々に独立して作成することが推奨されます。ポリシー設定画面は、下記のスクリーンショットを参照してください。このようにすれば、数件のスナップショットを削除なしですばやく作成でき、オブジェクト ストレージにはより大量のバックアップを保存しならがら、高い費用効率とパフォーマンス、スケーラビリティを達成できます。



より高度なユースケース:マルチクラウドのモビリティ
以上、単一のクラスタにおけるスナップショット、バックアップ、リカバリの例を紹介しました。これは、K10の持つ機能性の表層部分を垣間見たにすぎません。実際の用途はずっと幅広く、たとえば、アプリケーション スタック全体とそのデータを業務環境のクラスタからまるごとエクスポートして、地理的に隔離されたDR(災害復旧)クラスタに稼働させることも可能です。また、その代わりに、データをマスキングしてオブジェクト ストレージ システムに移管し、そこからローカルの開発クラスタに読み込むこともできます。これら多種多様なユースケースは、Kastenのドキュメンテーションから参照できます。また、以下のデモンストレーション ビデオには、バックアップ、リストア、マイグレーションの一連のプロセスが簡潔に紹介されています(英語)。
まとめ
本稿では、Kasten K10がOpenShiftバージョン4.xとRookベースのCephストレージといかに簡単に統合できるかを紹介しました。これは、あくまで一例で、K10はOpenShiftと連携するあらゆるストレージ システムと統合可能です。AWS、Azure、Google、IBMなどの大手パブリック クラウド プロバイダやNetApp(Tridentプロバイダ)など、そのラインナップは枚挙に暇がありません。また、K10はアプリケーション レベルで一連のリレーショナル データベース(MySQL、PostgreSQLなど)やNoSQLシステム(MongoDB、Elasticなど)ともシームレスに統合します。詳しくは、Kastenのデータシートを参照してください。
関連トピックス
- Red Hat + Kasten: OpenShift Container StorageとのKubernetes バックアップ
- VMwareとKasten:Kubernetesと先端アプリケーションのためのデータ管理
- Entrust KeyControl Ecosystem
- Kasten K10 Version 2.5 リリース
- Kasten K10 Version 2.0 のリリースについて
- VMwareの代替製品・競合企業について
- AWSとZerto、組み合わせてできること[Zerto]
- ホワイトペーパー: Kubernetesバックアップの5大ベストプラクティス (コンテナ ネイティブ環境のデータ管理ニーズに応える)
- SQL Serverのデータをバックアップ~データをクラウドへ、データを他DBへ、仮想マシンごとNASやSANへ~
- Kasten K10 Ver3.0でのマルチクラスタとマルチテナントのバックアップとDRを実現 (K10 Ver3.0をリリース)







 RSSフィードを取得する
RSSフィードを取得する
