

はじめに
私たちが使用するデータ量は日々増加します。すべての人がデータの収集と保存を24時間365日行っています。
IT世界では、これらのデバイスがモノのインターネット(IOT)を構成します。マイクロソフトによると、2020年までに1人あたりに作成される情報の量が5TBをわずかに上回ると言われています。
それは誰もが参加をしているが、日々の仕事でそれに対処しなければならないのはごく少数です。データ管理は、システム管理者のアジェンダの重要な部分です。私たちは情報の流れをよりよく管理し、予算を浪費することなくデータを効率的に保管できるようにするテクノロジーとサービスを実装することを常に模索しています。これを達成する方法はたくさんありますが、今日はMicrosoft Windows Serverチームによって開発されたデータ重複排除テクノロジの1つの特殊な例について紹介します。
Veeamのバックアップリポジトリのスペースを節約するために活用すると非常に効果的です。
この記事は重複排除テクノロジを検討している人にとって、また特定のVeeamシナリオでそのメリットと実用的な節約を知りたい場合に役に立ちます。
Windows Server 2016でのデータ重複排除とは
ディスクボリュームに格納され、数日間放置されたファイルは、特別なプロセスによってチェックされ、このデータを小さなブロック(32KB~128KB)に分割してチェックすることができます。次にチャンクでチャンクを分析します。システムはユニークなブロックのみを保持し、ブロックをチャンクストアに移動し、複数回使用されるブロックを残します。これにより、上記のデータが似ている場合にストレージを節約できます。最も重要な使用例には、Hyper-V VDI環境、バックアップストレージ、ファイルサーバーなどがあります。重複排除プロセスは、以下の4つの異なるタスクタイプのうちの1つを実行します:最適化(チャンクへのデータ分割とチャンクスストアへの移動)、ガベージコレクション(不要なチャンクを除去したスペースの再利用)、完全なスクラビング(チャンクストアの破損の検出)、または最適化の無効化、(このボリュームでの最適化の無効化と重複排除の無効化)。
データ重複排除の基本の詳細については、マイクロソフトのナレッジベースを参照してください。
データ重複排除の実行方法
重複排除を有効にするのは、サーバーマネージャーを使用して新しいサーバー機能を追加するのと同じくらい簡単です(図1)。
または、単純なPowerShellコマンドレットを実行してWindows Server Deduplicationをインストールすることもできます:
Install-WindowsFeature -Name FS-Data-Deduplication
これで、Server Managerのディスクボリュームリストに移動し、システムボリュームではないNTFSボリュームで重複排除を有効にするか(図1)、Powershellを再度使用できます:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Default/HyperV/Backup>
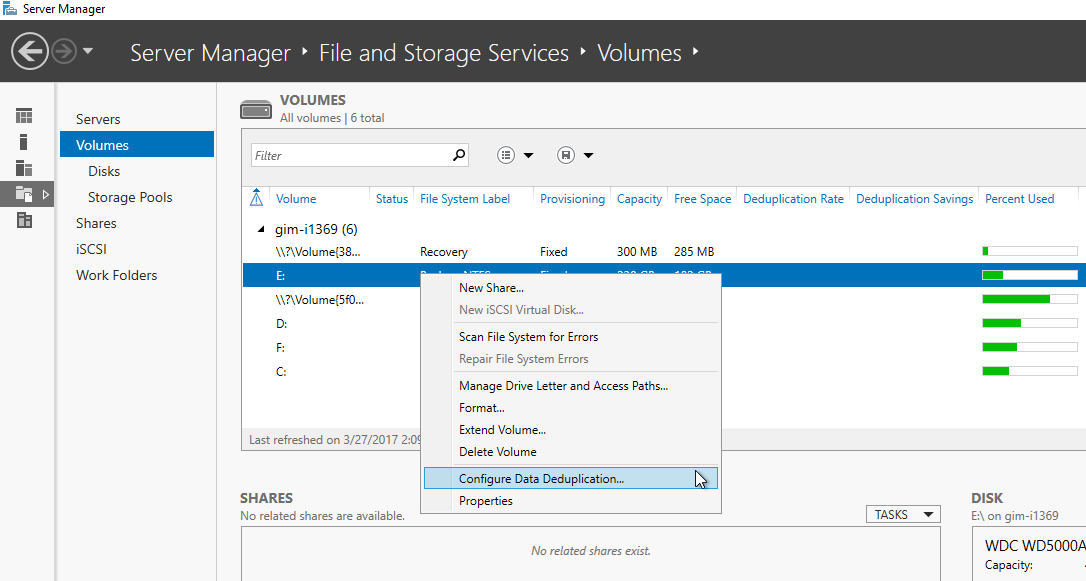
図1 ディスクボリュームのDedupを有効にする