
データベースの主流はその時代時代で移り変わってきました。1990年代はリレーショナル データベースが一躍脚光を浴びた時代です。リレーショナル データベース(RDB)は今でも変わらずがんばっていると、RDBファンに叱られてしまうかもしれませんが、いちおう2000年代にはベテランの域に達し、いぶし銀の活躍を見せながらも、華々しく脚光を浴びるポジションはXMLやNoSQLデータベースなどの若手に譲りました。2010年代になるとJSON型のデータベースが注目を集め、ビッグデータへの対応が求められる時代になってきました。そして、2020年代はグラフ データベースの時代が来るかもしれません。
とはいえ、グラフ データベースは2000年代前半から徐々に使われ出してはいたようです。データの構成を論理的に分析しやすい特性もあって、主に学術分野で利用されてきましたが、商業利用が進みませんでした。それが、2014年から頭角を現し、ハードウェアの高速化やクラウドをはじめとするインフラの発達にともない、活用範囲が急速に広がり始めました。
グラフ データベースと言っても、日本語でイメージする「グラフ」とは異なるので、どちらかと言うと「ネットワーク データベース」と呼んだほうがわかりやすいかもしれません。リレーショナル データベースは、テーブル間の関係を外部キーなどで定義し、多数のテーブルを複雑に関連付けながら構成されますが、グラフ データベースでは個々のデータ間の関係をネットワークで構成していきます。
よく使われる例は、SNSの人と人とのつながりです。たとえば、AさんがBさんをフォローし、BさんはCさんを、CさんはAさんとDさんをフォローする、というようなネットワーク構成です。
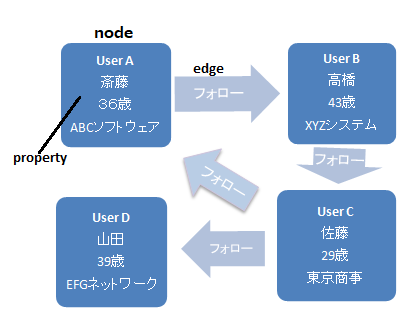
グラフ データベースでは、Aさん、Bさんなどの各ユーザーをnode、フォローする、されるといった関係はedge、Aさんの名前や年齢、所属などの属性を propertyと呼びます。
この データベースの最大の特長は、データの構成が目で見てわかりやすいという分析上の便利さもさることながら、特定データを見つけるスピードにあります。
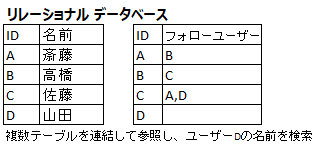
たとえば、上の例で、Aさんと直接つながりのないDさんの情報をAさんに自動的に紹介する機能をシステムに加えたいとします。グラフ データベースなら、nodeのedgeをたどって簡単に情報を見つけ出すことができますが、同じことをリレーショナル データベースでやろうとすると、テーブルを外部キーで参照して、連結したビューを用意してから必要なデータを照会するなど、2重3重の手間がかかります。ここで挙げた単純な例ではテーブル数も限られ、グラフ データベースとの差はほとんどないのでしょうが、実用環境では膨大なデータが複雑に構成され、グラフ データベースのパフォーマンスが際立ってくるはずです。
以上、グラフ データベースの特長をほんのさわりだけ紹介しましたが、これを見ただけでも、マルチクラウドのデータセンターにビッグデータが溢れる時代の主役は、グラフ データベースをおいてほかにはいないような気がしてきませんか?
関連したトピックス
- NoSQLクラウドデータベース: メリットと特徴
- ドキュメント・データベースは何か?
- GlueSyncでNoSQL活用を加速:データモデリング編
- GlueSyncがAWS S3(互換も含む)に対応:分析、データレイク、コールドストレージ向けに、AWS S3 へのリアルタイムデータレプリケーションがシンプルに
- Oracle RAC One Node環境を構成してみました ステップ1 Oracle Linux環境の導入
- データベース・バックアップのタイプ、ヒント、利用例
- Gluesyncのレプリケーションソース(CDC付)およびレプリケーションターゲットとしてのDynamoDBのサポート
- Oracle RAC One Node環境を構成してみました 補足 Syniti Replicateを使用して異種DBへ連携
- スケールアップ とスケールアウト [データベース]
- GlueSyncでNoSQL活用を加速:導入編

 RSSフィードを取得する
RSSフィードを取得する

