
データウェアハウス(DW)は、複数のシステムから統合されたデータの一元的な保管場所です。このデータは、多くの場合、ロードされる前にクレンジングされ、標準化されます。データウェアハウスは、分析ワークロードをサポートするように設計されており、組織が現在のデータと過去のデータの両方をより効果的に活用し、ビジネスプロセスと結果の分析を通じて意思決定を改善するのに役立ちます。
DWに加えて、エンタープライズデータウェアハウス(EDW)やデータマートといった用語も、これらのデータリポジトリを表すために使用されている場合があります。組織にはEDWのほかに、複数のデータマートが存在する場合もあります。EDWは企業全体の統合データを提供し、データマートはEDWのデータのうちチームやプロセスに特化したサブセットを格納するソースとして機能します。また、EDWと複数の分析モデルまたはOLAPキューブを構築し、データウェアハウスのテーブルのサブセットを格納して、クエリの高速化や複雑なデータ計算のための追加機能を提供するという方法もあります。
複数のシステムからデータを統合して、プロセスを全体的に把握することに苦労したことはありませんか?このガイドでは、なぜデータウェアハウスがこのような状況の改善に役立つのかについて説明します。
データウェアハウスの主な利点
例えば、あなたがウィジェットやギズモを製造する会社に勤めていて、マーケティング部門がウィジェットのプロモーションを計画したとします。プロモーション情報は、POSシステムに入力されます。在庫計画システムは、売上増を見込んで更新されます。プロモーションの結果は、販売システムに反映されます。マーケティング、POS、在庫、販売業務システムの異なるソースからデータを手動で引っ張ってくるには、かなりの労力が必要です。代わりに、4つのシステムからデータウェアハウスへのロードを自動的にスケジュールすることができます。データロードプロセスにより、データのクレンジングと統合が行われ、データウェアハウス内で読み取り最適化された形式に整理されます。
データウェアハウスは、多くのソースからのデータを統合するだけでなく、分析の作業負荷をトランザクション(OLTP)データストアから移動させ、トランザクションシステムのパフォーマンス向上に役立てることも可能です。
データウェアハウスでは、データが高速に読み込めるようにモデル化されているため、分析クエリも高速に実行できます。 また、ソースデータがアーカイブされ、ソースシステムが交換されても、データウェアハウスはデータの可用性を維持することが可能です。また、データウェアハウスは、用語や命名規則の一貫性を高め、異なるソースからのデータ値を標準化することで、データの品質を保証することができます。
データウェアハウスアーキテクチャの一般的なタイプ
データウェアハウスは、約30年前から組織の統合報告の定番となっていますが、使用されるテクノロジーは時代とともに変化しています。新しいビッグデータ技術がその常識を変えつつありますが、データウェアハウスのアーキテクチャは基本的に変わっていません。一般に、生データはソースシステムから取得され、変換のためにステージングされ、データウェアハウスにロードされ、構造化クエリー言語(SQL)でクエリーが行われます。
データウェアハウスにデータを格納する方法には、一般的に3つのアプローチがあります。
1. ラルフ・キンボール(Ralph Kimball)のディメンション・アプローチ
2. ビル・インモン(Bill Inmon)の正規化アプローチ
3. Dan Linstedtのデータボールトアプローチ
以下では、これらのデータベースアーキテクチャモデルの主な違いについて説明します。
ディメンショナル・モデル
ディメンジョンアプローチでは、スタースキーマを使用し、利用可能なデータの最下層をファクトとディメンジョンに整理します。ファクトは、ビジネスプロセスに関する測定可能な定量データを保持するテーブルで、ディメンジョンには、ファクトデータのグループ化やスライスに使用する記述属性が含まれます。ファクトは、ディメンジョン・テーブルの主キーに関連する外部キーによって、ディメンジョンに関連付けられます。ディメンジョン・テーブルの主キーは、多くの場合、ソース・システムから取得した自然キーではなく、連続的に割り当てられた 整数である代理キーになります。これらの代替キーによって、”不明” または “該当なし” のディメンジョンに値を追加して、データ・ソースを置き換えることができます。
ファクト・テーブルは通常、第3正規形式で設計されますが、ディメンジョンは第2正規形式で設計されます。これは、一般的に完全に第三正規形である運用データベースとは異なります。この違いにより、書き込み作業用に最適化された運用データベースと比較して、データウェアハウスは分析作業用に最適化されます。ディメンションモデルに対するクエリはより単純であり(結合の数が少ない)、多くのメトリクスはファクトテーブルのカラムの単純集計(合計、平均、最大)です。
Kimballのアプローチでは、レポートとエンドユーザがこのデータウェアハウスに直接クエリを実行します。異種データの変換とクレンジング中に行われた決定により、データがディメンションモデルにロードされる際に、データ値が変更されたり、ソースデータが除外されたりすることがあります。私は15年以上にわたってデータウェアハウスを構築してきましたが、そのほとんどはディメンジョンモデルを使用しています。ディメンジョンモデルはデータモデルの複雑さを軽減し、レポート、ダッシュボード、セルフサービスのビジネスインテリジェンスユーザーにとっての使い勝手を最適化することができるからです。
正規化モデル(Dimensional Model)
正規化アプローチでは、テーブルは主に第三正規形式で格納されます。テーブルはエンティティを表し、エンティティはサブジェクト領域にグループ化されます。正規化されたデータウェアハウスの上には、通常は部門や機能に沿った要約されたデータを含む次元データマートがあります。 要約された次元データマートにないデータが必要な場合、アナリストは正規化データウェアハウスに照会して必要なデータを取得することが可能です。このアプローチでは、データウェアハウスへのデータの書き込みが非常に簡単になります。しかし、正規化されたデータウェアハウスへのクエリは、より複雑なクエリを必要とする場合があります。
Data Vault
Data Vault(データ保管庫)のモデリングでは、ハブ、リンク、サテライトを含む構造を使用して、真実の単一バージョンを提供します。データは、保存される前にクレンジングされたり、ビジネス要件に適合させられたりすることはありません。ハブにはビジネスキー、サロゲートキー、ソースシステムのインジケータが含まれる。
Data Vaultのリンクテーブルには、2つ以上のハブテーブルのサロゲートキーが含まれ、ビジネスキー間の関連付けを表現している。サテライトテーブルには、親ハブまたはリンクにリンクするメタデータ、関連と属性に関するメタデータ、属性の開始日と終了日が含まれます。 このデータ保管庫のストレージ層は分析用に最適化されていないため、データ保管庫の上にディメンションモデルを作成することが、分析のニーズを満たすために非常によく使われる方法となっています。
データ統合の仕組み
データウェアハウスは通常、バッチまたはマイクロバッチでロードされます。複数のレコードを収集してから、1回の操作でまとめて処理します。データ統合プロセスは、しばしばETL(抽出、変換、ロード)またはELT(抽出、ロード、変換)のいずれかに分類されます。その違いは、処理が行われる場所である。ELTでは、データはデータウェアハウスにロードされ、その後変換されます。ETLでは、データは通常インメモリで変換され、その後データウェアハウスにロードされます。
現在筆者構築しているデータウェアハウスのほとんどは、Azure(SQL ServerまたはSynapse)で、データウェアハウスへのデータ投入にAzure Data Factory(ADF)を使用しています。小規模なデータウェアハウスでは、ADFを使用してソースからDWにデータをコピーし、ストアドプロシージャを呼び出してディメンジョンモデルにデータを投入するのは簡単です。これはELTの一例です。データロードはELTやETLである必要はありません。
最新のデータウェアハウスについて知っておくべきこと
データウェアハウスは伝統的にリレーショナルデータベースで作成され、バッチロードによってデータを受け取りますが、現代のデータウェアハウスはそのような慣習を越えて拡張されています。最新のデータウェアハウスは、リレーショナルデータベースを使用することが多いですが、超並列処理(MPP)エンジンを搭載して、大量のデータセット(構造化データと非構造化データの両方を含む)のクエリをサポートしている場合もあります。また、多くのデータウェアハウスは、リアルタイムデータやストリーミングデータを受信できるように最適化されています。
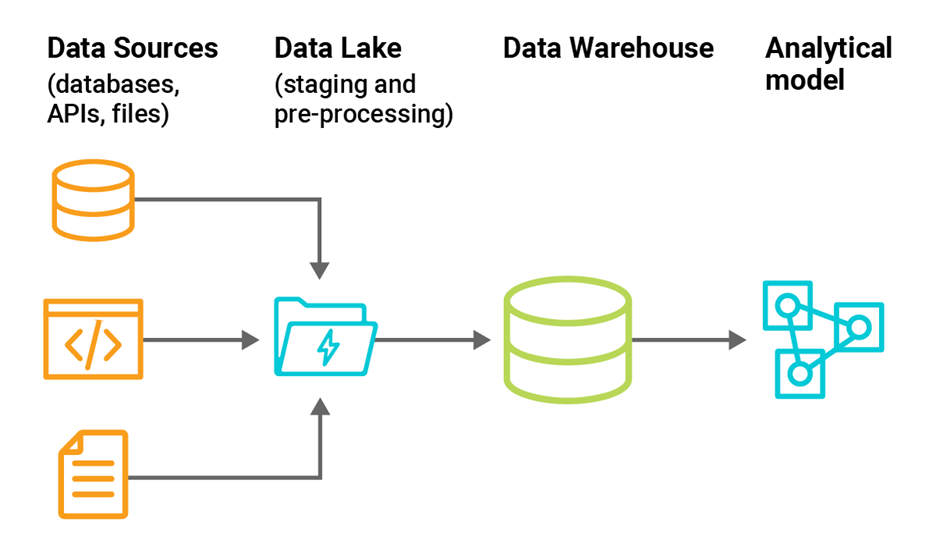
以下に示すように、データウェアハウスはデータレイクに取り込まれた生データと組み合わせて提供されることもあります。
●データの処理とデータウェアハウスへのロードに伴うステージングをより速く、より安価に行うことができます。
●より安価なアーカイブ保存データ
●データウェアハウスから半構造化データをクエリするためのデータ仮想化機能
クラウドデータウェアハウスはどうでしょうか?
マイクロソフトやAWSなどの多くのクラウドベンダーは、Platform-as-a-Service(PaaS)型のデータウェアハウスを提供しています。このため、仮想マシンを作成して管理したり、オンプレミスでアプライアンスを維持したりする必要はありません。PaaSソリューションでは、クラウドベンダーがサーバー、ストレージ、ネットワーク、オペレーティングシステム、ミドルウェア、データベース管理システム(アップグレードやパッチ適用も含む)を担当します。これにより、従来のデータウェアハウスに関連するメンテナンスのオーバーヘッドが削減されるだけでなく、他の多くの利点が得られます。
●新しいデータロードやデータ分析に対応するために、リソースを迅速かつ容易に拡張することができます。
●データベースの信頼性の高いバックアップとリストア
●内蔵の高可用性
●新しい環境の迅速なデプロイメントが可能
関連したトピックス
- データベースのバックアップはどのように業務を遂行しているかに依存する
- Azure Synapse Analytics(旧 SQL DW)へのレプリケーションを検証してみました[Syniti DR]
- Azure Database for PostgreSQLを使い始めるにあたって
- Entrust KeyControl Vault for Oracle
- DBaaSとは何か
- Azureのデプロイメントオプションで適切なSQL Serverを選択する方法
- ACID原理とCAP定理 ~ NewSQLへの道 ~
- DBA:データベース管理の働きに付いて
- Parquetで連携し、より効率的なデータ分析を簡単に実現【Gluesync】
- データウェアハウスとは何なのか?

 RSSフィードを取得する
RSSフィードを取得する


