
GlueSyncはデータレプリケーションツールですが、既存のソフトウェアと大きく異なり、以下の点に特化しています。
- クラウドネイティブでステートレスなコンテナとして動作
- NoSQLやビッグデータへのデータ連携
コンテナで動作し、DockerやKubernetes環境で簡単に実行できるという点で実装を容易にしつつ、RDBMS上のテーブルに格納されているデータをどのようにNoSQL上のJSON形式に落とし込んでいくかといった点に柔軟に対応したツールです。
今回は実際にこのGlueSyncをDocker環境で実行してみたいと思います。
まず、Dockerのインストールに関してですが、特別な構成は不要です。公式のドキュメントにある手順でインストールいただければ問題なくご利用いただけます。
https://docs.docker.com/engine/install/
その後、イメージを作成していきます。これに関しても以下のように開発元のレジストリからダウンロードしてくるだけですので、難しいことは特にありません。
評価や製品ご購入いただいた際にはレジストリアクセスのための認証情報が開発元から提供されますので、それで、ログインいただけます。
$ docker login -u molo17com
Password:
WARNING! Your password will be stored unencrypted in /home/climb/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded使用するイメージはデータベース/NoSQLの組み合わせや変更追跡方法でことなっていますので、環境にあわせて選択する必要があります。
今回はMicrosoft SQL ServerからCouchbaseへのレプリレーションを構成していきますので、それにあわせたイメージを指定してdocker-compose.ymlを作成します。
# docker-compose.yml
version: '3.7'
services:
gluesync-s2n:
image: molo17com/gluesync-sql-to-nosql:mssql-to-couchbase-1.5.29
restart: 'no'
environment:
- CONFIG_FILE=/opt/app/config/config.json
- LICENCE_KEY=/opt/app/config/gs-licence.dat
volumes:
- "$PWD/config:/opt/app/config"イメージを作成します。
climb@gs-forblog:~$ docker compose create
[+] Running 6/6
✔ gluesync-s2n 5 layers [⣿⣿⣿⣿⣿] 0B/0B Pulled 21.8s
✔ 3dd181f9be59 Pull complete 2.2s
✔ daaba932f0b8 Pull complete 13.3s
✔ a7d194dba5db Pull complete 1.0s
✔ 97ae4decef80 Pull complete 11.5s
✔ 4f4fb700ef54 Pull complete 2.8s
[+] Creating 1/1
✔ Container climb-gluesync-s2n-1 Created 次に、docker-compose.ymlで指定しているライセンスファイルgs-licence.datを配置します。こちらも評価、製品ご購入時に開発元から提供されます。
climb@gs-forblog:~$ ls config/
gs-licence.datそして設定をconfig.jsonで行います。
{
"sourceHost": "192.168.33.15",
"sourcePort": "1433",
"sourceName": "demo",
"sourceUsername": "gs-user",
"sourcePassword": "P@ssword123",
"mssql": {
"temporaryTableNamePrefix": "gs",
"statePreservationTableNamePrefix": "gs"
},
"targetHost": "192.168.33.15",
"targetPort": "8091",
"targetName": "demo",
"targetUsername": "gs-user",
"targetPassword": "password",
"couchbase": {
"useCollections": true
},
"sourceEntities": {
"tableSync": {
"schema": "dbo",
"table": "DRIVERS",
"type": "drivers",
"scope": "data"
}
},
"sourceChangeRetention": 5,
"copySourceEntitiesAtStartup": true,
"maxItemsCountPerTransaction": 100,
"maxMigrationItemsCountPerIteration": 20000
}ソース接続に関する設定
- sourceHost – 接続先となるSQL ServerのIPアドレスまたはDNS名
- sourcePort – 接続先となるSQL Serverのポート
- sourceName – 接続先となるデータベース名
- sourceUsername – 特権ユーザのユーザ名
- sourcePassword – 特権ユーザのパスワード
- mssql – SQL Serverに関する固有の設定
- temporaryTableNamePrefix – (オプション) パフォーマンスを向上させるために、Gluesync によって作成される一時テーブルのカスタム プレフィックスを指定できます。
一般的な使用例は、複数のGluesyncで同じソースを使用する際に競合を回避するために使用します。 - statePreservationTableNamePrefix – (オプション) 処理された変更のチェックポイントを保持するために、Gluesync によって作成される状態保存テーブルのカスタム プレフィックスを指定できます。
一般的な使用例は、複数 のGluesyncで同じソースを使用する際に競合を回避するために使用します。
- temporaryTableNamePrefix – (オプション) パフォーマンスを向上させるために、Gluesync によって作成される一時テーブルのカスタム プレフィックスを指定できます。
ターゲット接続に関する設定
- targetHost – 接続先となるcouchbaseのIPアドレスまたはDNS名
- targetPort – 接続先となるcouchbaseのポート
- targetName – 接続先となるバケット名
- targetUsername – 特権ユーザのユーザ名
- targetPassword – 特権ユーザのパスワード
- couchbase – couchbaseに関する固有の設定
- certificatesPath – (オプション) HTTPSでの通信時に、Couchbase Serverインスタンスに接続するときに使用する必要がある証明書へのパス。省略した場合、証明書は使用されません。
- timeoutSeconds – (オプション) Couchbase サーバとの通信タイムアウトとして設定(秒)
- indexReplicaCount – (オプション) Gluesync によって生成されるインデックス レプリカの数を設定します。その数値はインデックスノード数―1として計算して設定することをお勧めします。たとえば、3 ノード インデックスの場合、2をレプリカとして設定することが推奨されます。詳細については、Couchbase のドキュメントを参照してください。
- useCollections – (オプション) デフォルトは で
falseです。trueの場合、指定されたスコープ、コレクションに対して同期されます。falseの場合、デフォルトのスコープ、コレクション(バケット名._default._default)に対して同期されます。これは、Couchbase バージョン 7.0 以降にのみ適用されます。
レプリレーション設定
- sourceEntities – どのように同期するかといった対応付けや設定を記載
その他の構成パラメータ
- sourceChangeRetention – (オプション) デフォルトは 5日です。変更追跡のためにソースDB上で保持されるデータの保持日数を設定できます。
SQL Serverの場合は変更を追跡するための方法として、トランザクションログを使用した変更追跡とCDC機能を使用する方法の2種類を提供しています。 - copySourceEntitiesAtStartup – 初回起動時に Gluesync がテーブル全体をコピーするかどうかを示すブール値です。
- maxTransactionCountPerIteration – 同時に処理されるトランザクションの最大数を設定できます。
- maxItemsCountPerTransaction – 1 つのトランザクション内で処理する必要がある行の最大数を設定できます。これは、トランザクションの影響を受ける行のページド・リードを伴います。
- maxMigrationItemsCountPerIteration – デフォルトは 1000 です。これは、初期スナップショットプロセスによってスレッドごとにロードされるデータの各チャンクのサイズです。特定のユースケースのニーズに応じてその値を変更します。
今回はテスト用の環境であるため、同サーバ(192.168.33.15)上でコンテナとしてSQL ServerとCouchBaseが実行されており、SQL Serverをソースとして設定、CouchBaseをターゲットとして設定しています。
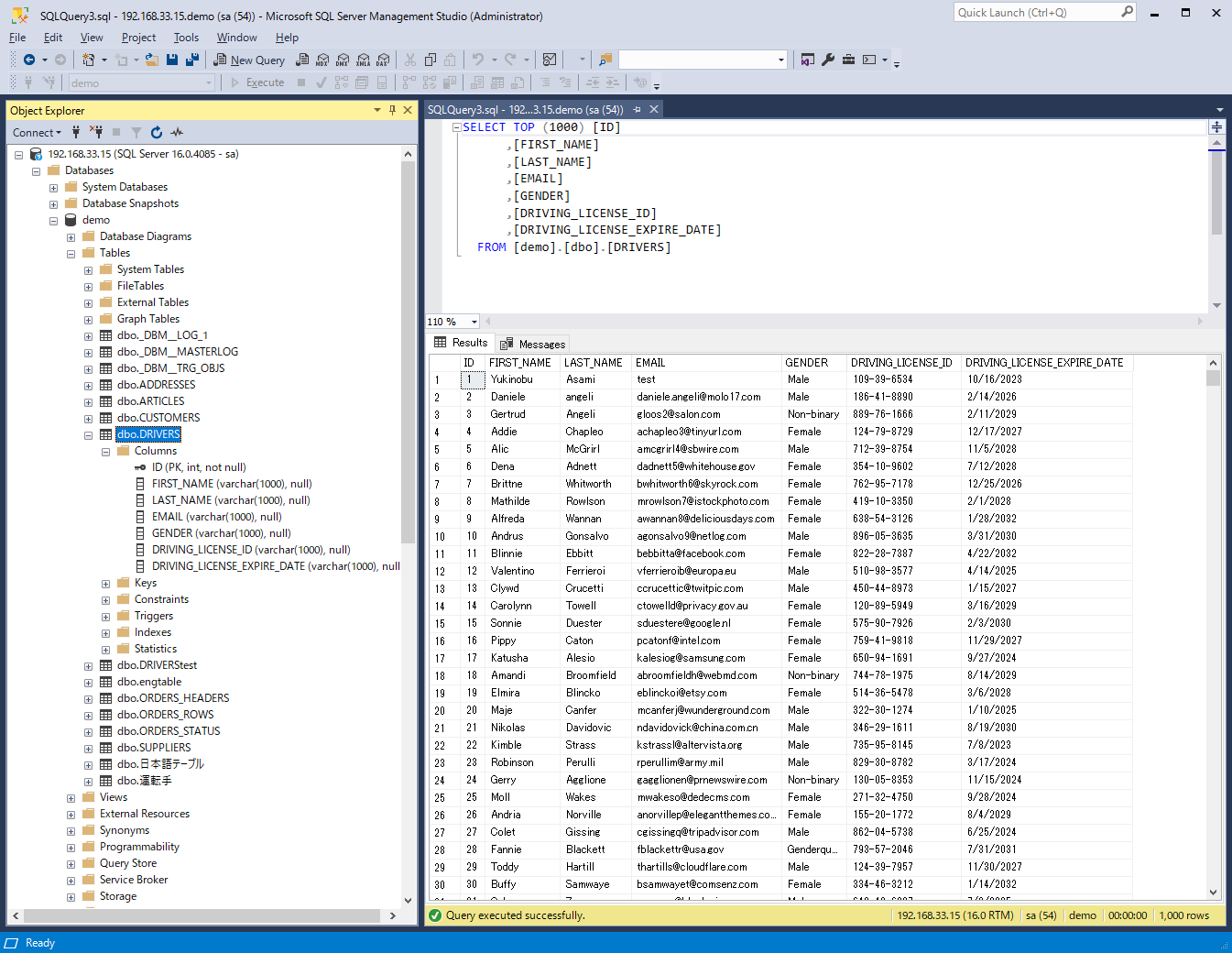
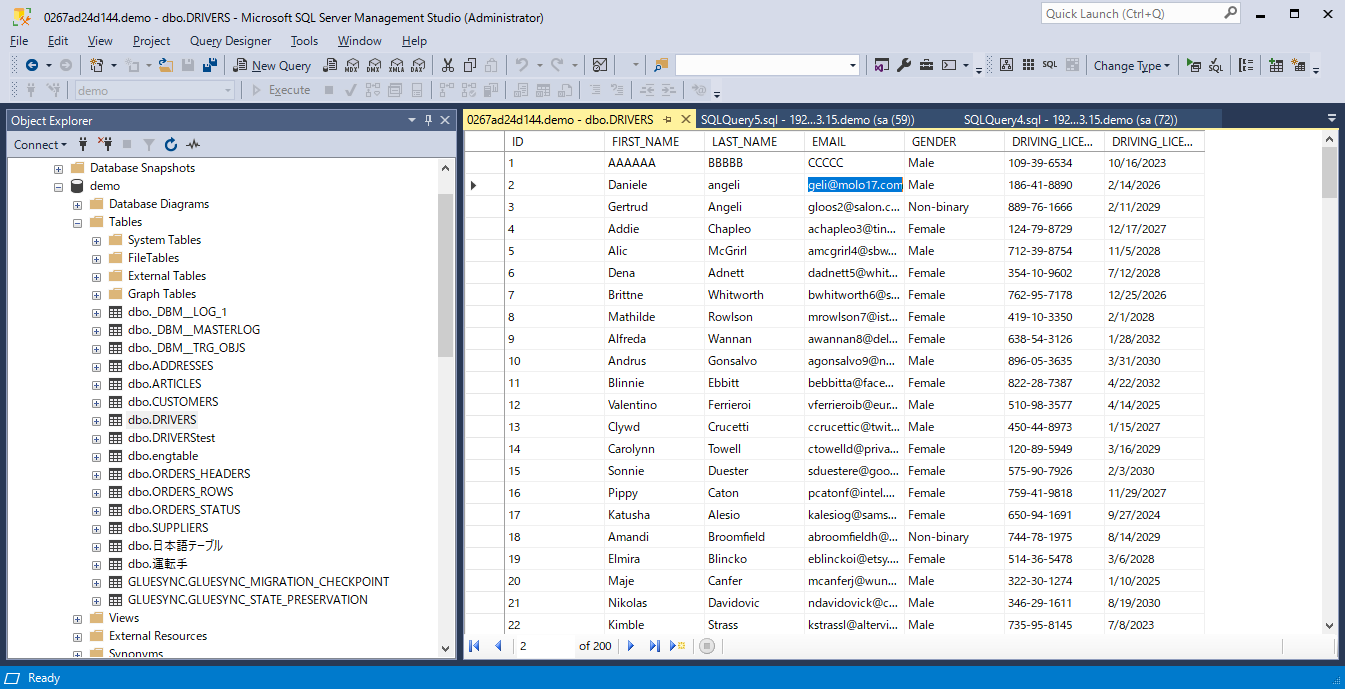
ソースとなるSQL Server上のDRIVERSテーブル
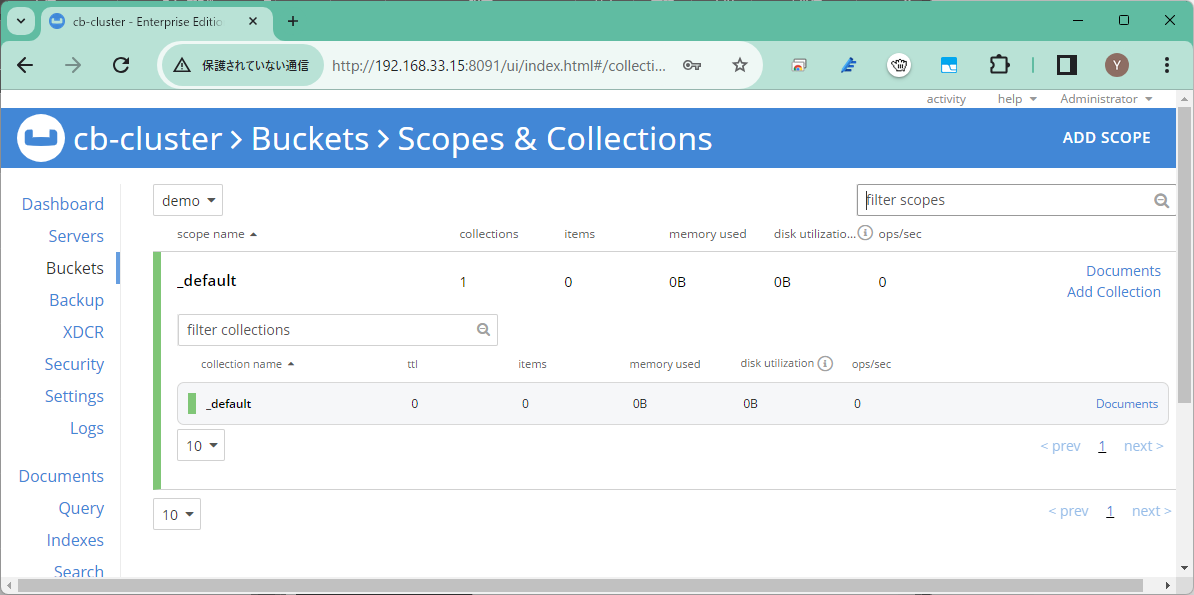
ターゲットとなるCouchBase上の空のdemoバケット
レプリレーション設定としては下記のように、ソースとなるSQL Server上のDRIVERSテーブルの各レコードを、CouchBase上のdataスコープに各オブジェクトとして配置する単純な設定です。
"sourceEntities": {
"tableSync": {
"schema": "dbo",
"table": "DRIVERS",
"type": "drivers",
"scope": "data"
}
}より複雑なデータモデルにも対応していますが、それは次回以降にご紹介予定です。
構成はこれで完了ですので、実際にGlueSyncを実行します。
climb@gs-forblog:~$ docker compose start
[+] Running 1/1
✔ Container climb-gluesync-s2n-1 Started 0.3s
climb@gs-forblog:~$
各レコードが以下のようにオブジェクトとして同期されました。
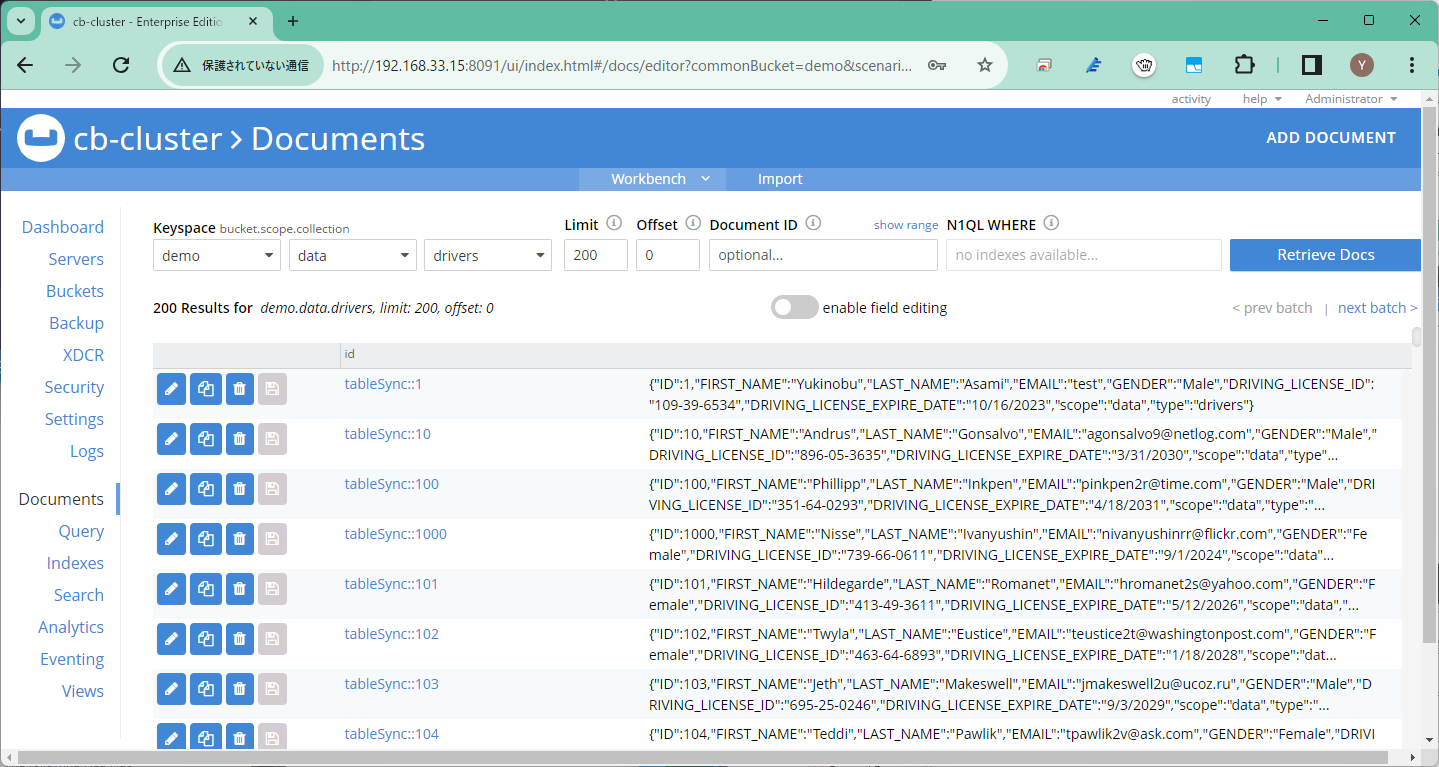
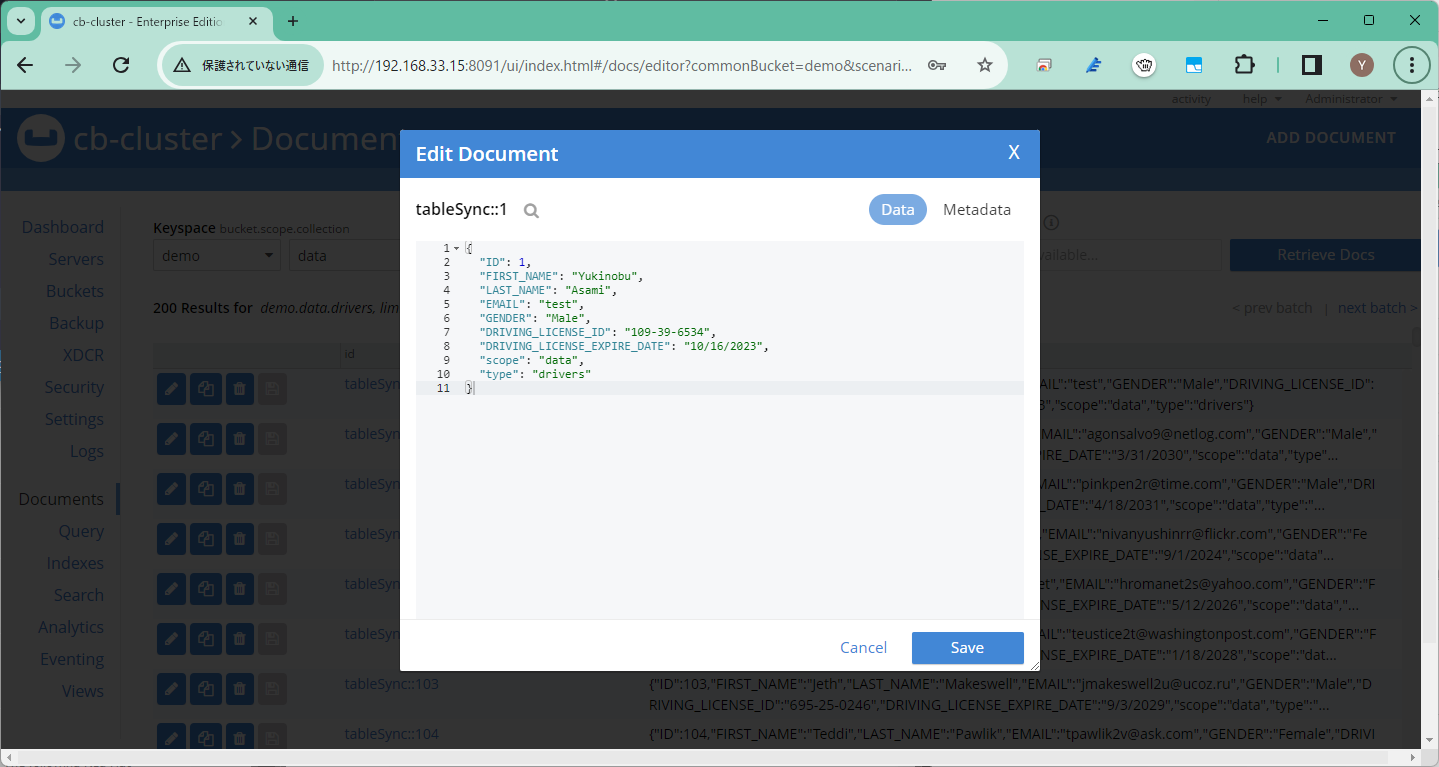
初期同期後は変更されたレコードのみをレプリレーションしますので、一つのレコードのみを更新してみるとターゲットにもそれが同期されます。
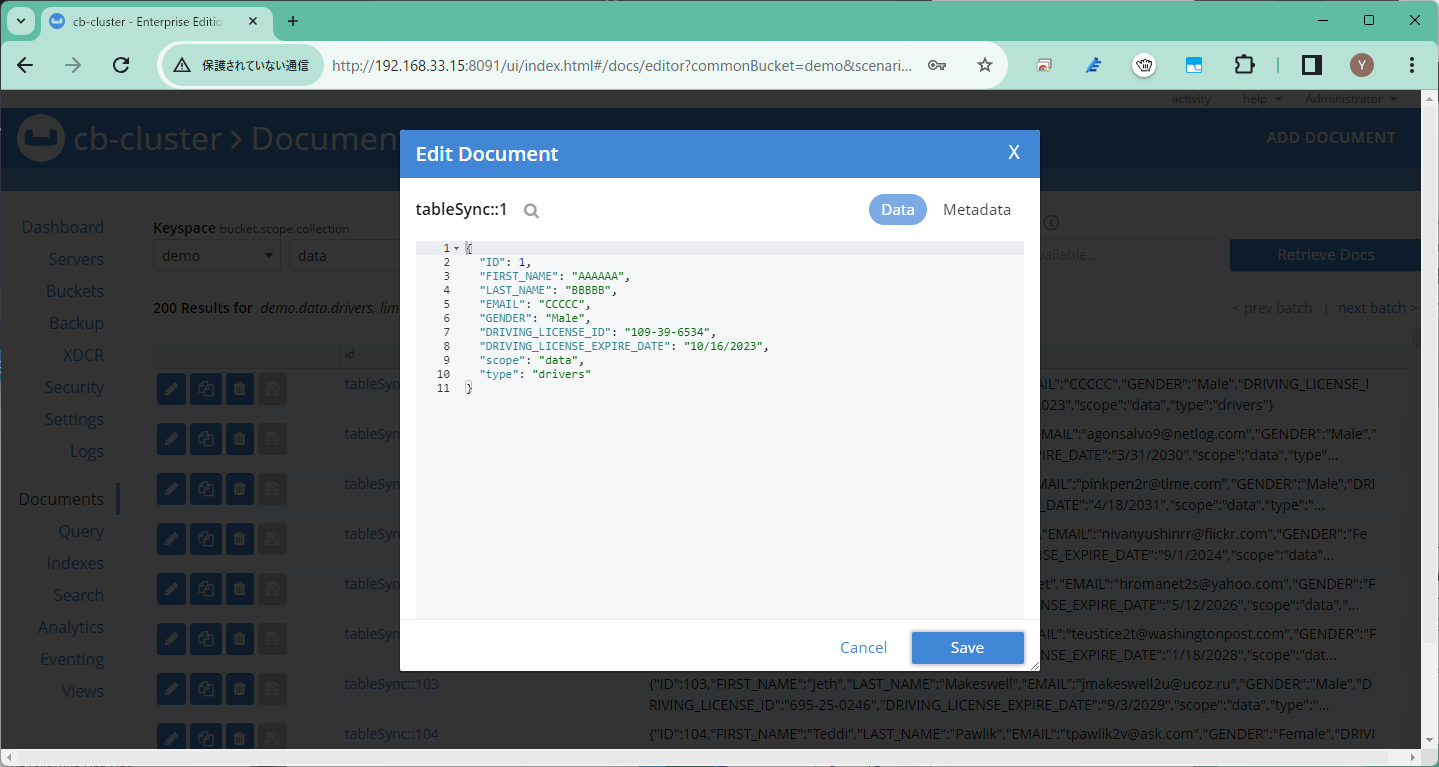
このように簡単にレプリレーションできるGlueSyncですが、そのコンテナ自体はステートレスであり、必要な管理情報(どこまでレプリレーションしたかなど)はソースやターゲットに記録されます。
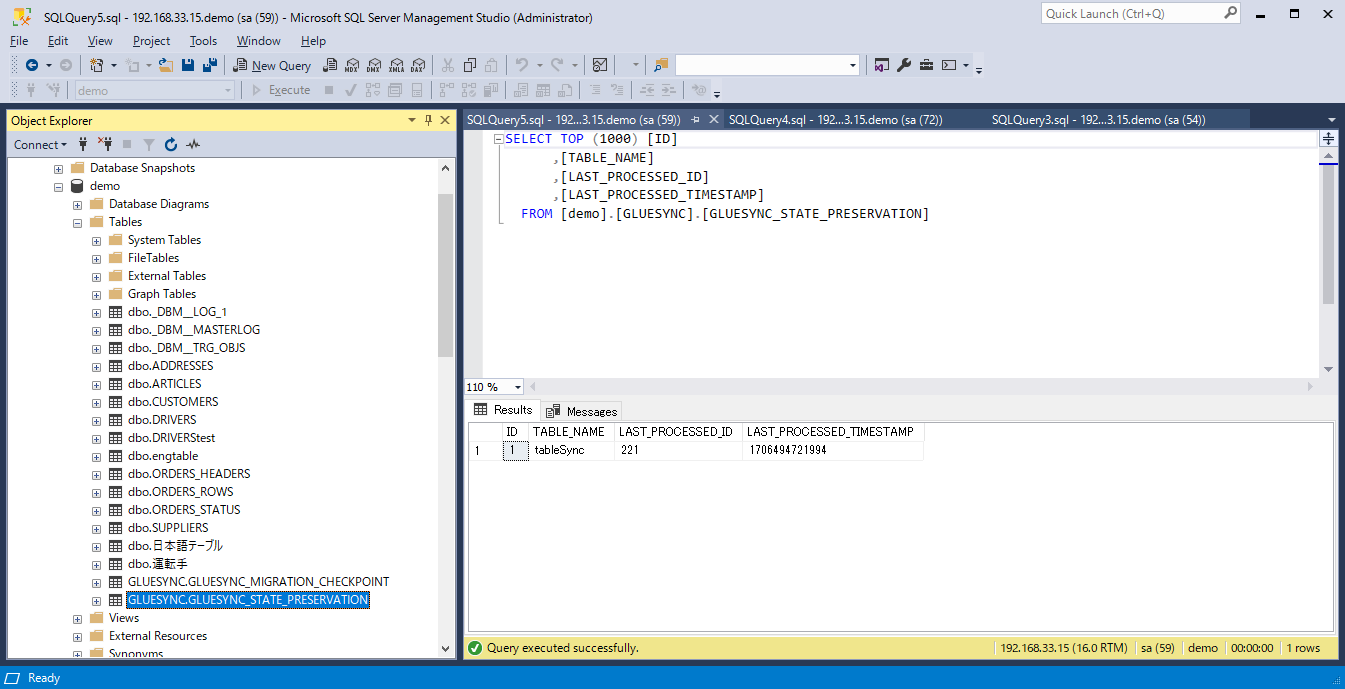
ソースで管理情報を保持するテーブル
ターゲットで管理情報を保持するスコープ
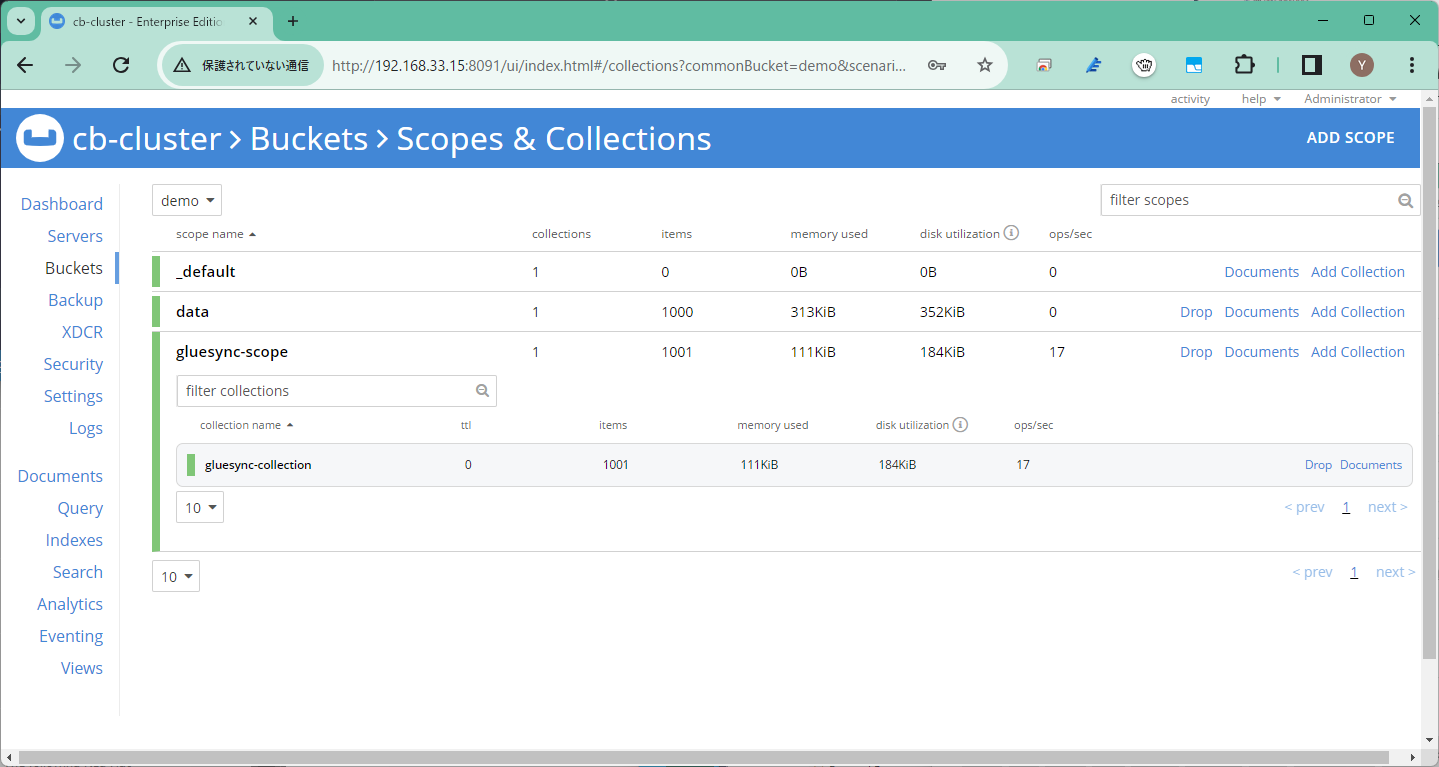
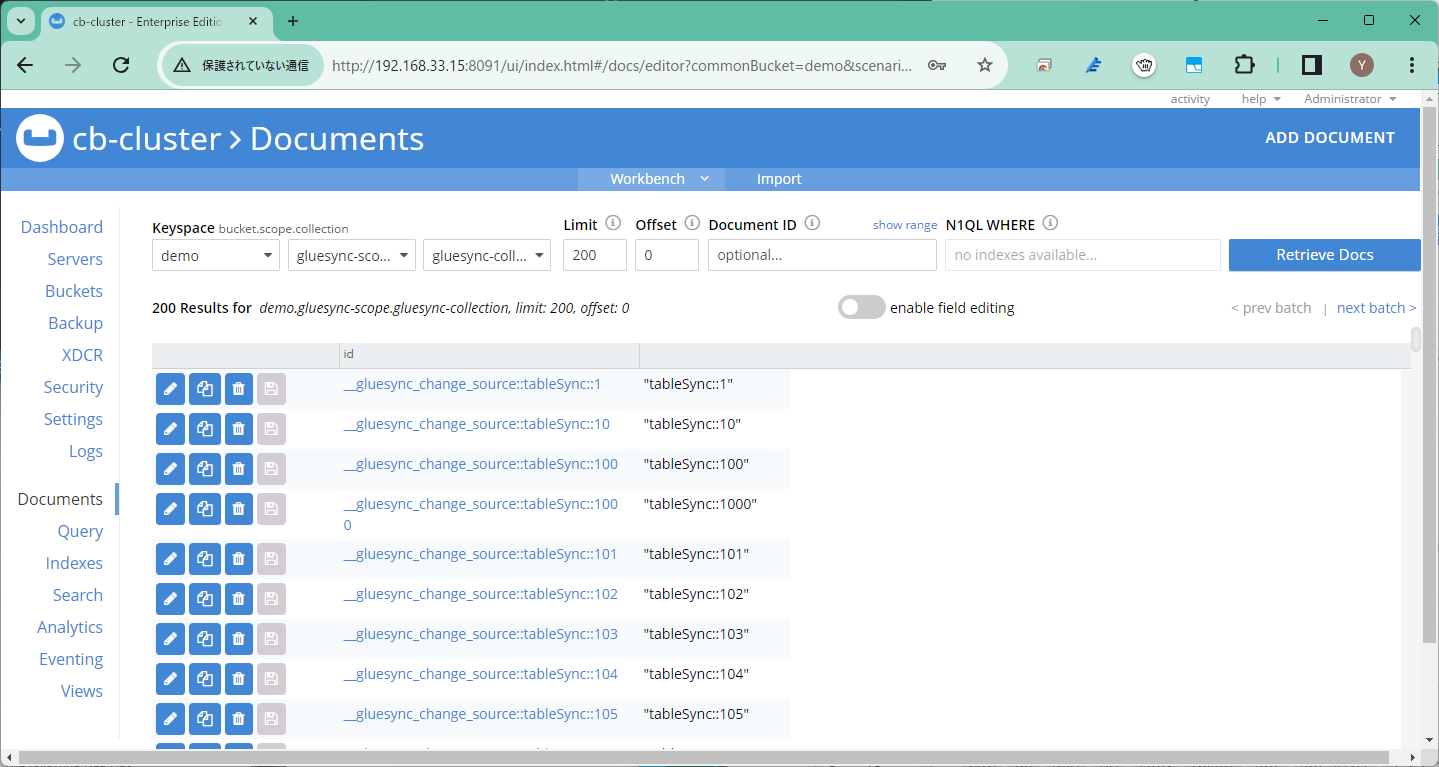
このため、GlueSyncが再起動した際にはこれらの管理情報を読み取って再開しますので、初期同期からやり直す必要もありません。
また、今回はMicrosoft SQL ServerからCouchBaseへのレプリレーションの組み合わせをご紹介しましたが、他にも、ソースとしてIBM Db2、IBM i (AS/400)、Microsoft SQL Server、 Oracle Database、 MariaDB、 MySQL、PostgreSQL、 Sybase ASE / SAP SQL Anywhere、Couchbase、 Amazon DynamoDB、Apache HBase、MongoDB、ターゲットとしてAerospike、Apache Kafka、 Amazon S3 、 Google Cloud Storage、RavenDB、 Solace PubSub+などもサポートしています。
具体的なサポート構成に関しては下記をご参照ください。
https://www.climb.co.jp/soft/gluesync/#system
このように簡単に構成してNoSQLに同期できるGlueSync、ご興味ありましたら是非弊社までお問い合わせください。
https://www.climb.co.jp/soft/contact/contact.php
関連したトピックス
- Gluesyncの評価手順(Windows版:2025/11/13現在)
- GlueSyncでNoSQL活用を加速:通知アラート、ログ、モニタリング
- オフライン環境のDockerでGluesyncを実行
- Gluesyncの評価手順(Linux版:2025/11/13現在)
- [Gluesyncブログ] タイムゾーン変更方法
- [Gluesync 2.1.4] WindowsネイティブビルドのGluesyncコンテナサポート!
- Gluesyncのバージョンアップ方法
- Gluesync 2.1.7 リリース: Conductor がエージェントオーケストレーションと新たな Kubernetes サポートを実現
- GlueSyncでNoSQL活用を加速:データモデリング編
- Dockerfilesを使用してSQL Server Dockerコンテナを構成

 RSSフィードを取得する
RSSフィードを取得する


