
前回はRDBMSからNoSQLへの連携を行うためにGluesyncのデプロイと単純なレプリケーションを構成しました。
しかし、RDBMSからNoSQLにデータを連携する際の大きな課題はそのデータ形式の違いです。テーブル構造でデータを保持しているRDBMSからNoSQLのJSON形式にどのように落とし込んでいくかといった点が課題になります。
- 不要カラムの除外
- 長すぎるカラム名などの変更
- 複数カラム、複数テーブルにわたるデータの結合
- ネストしたJSONへの連携
このような課題をGluesyncのデータモデリングは解決します。また、データモデリングはローカル キャッシュや Gluesync 内のいかなる形式の永続化も必要とせずにオンザフライで実行されるため、プロセス全体がより高速で、安全で、一貫性のあるものになります。
フィールドスキップと名前変更
レプリケーション設定にmappingを追加すると、そこで指定されたカラムのみが、指定したキー名へレプリケーションされます。これにより、mappingに追加しなかったカラムは処理からスキップされ、ソースのカラム名が長くとも、別名に対応づけできます。
例えばソーステーブルが下記のように日本語のカラム名をもつテーブルの場合、
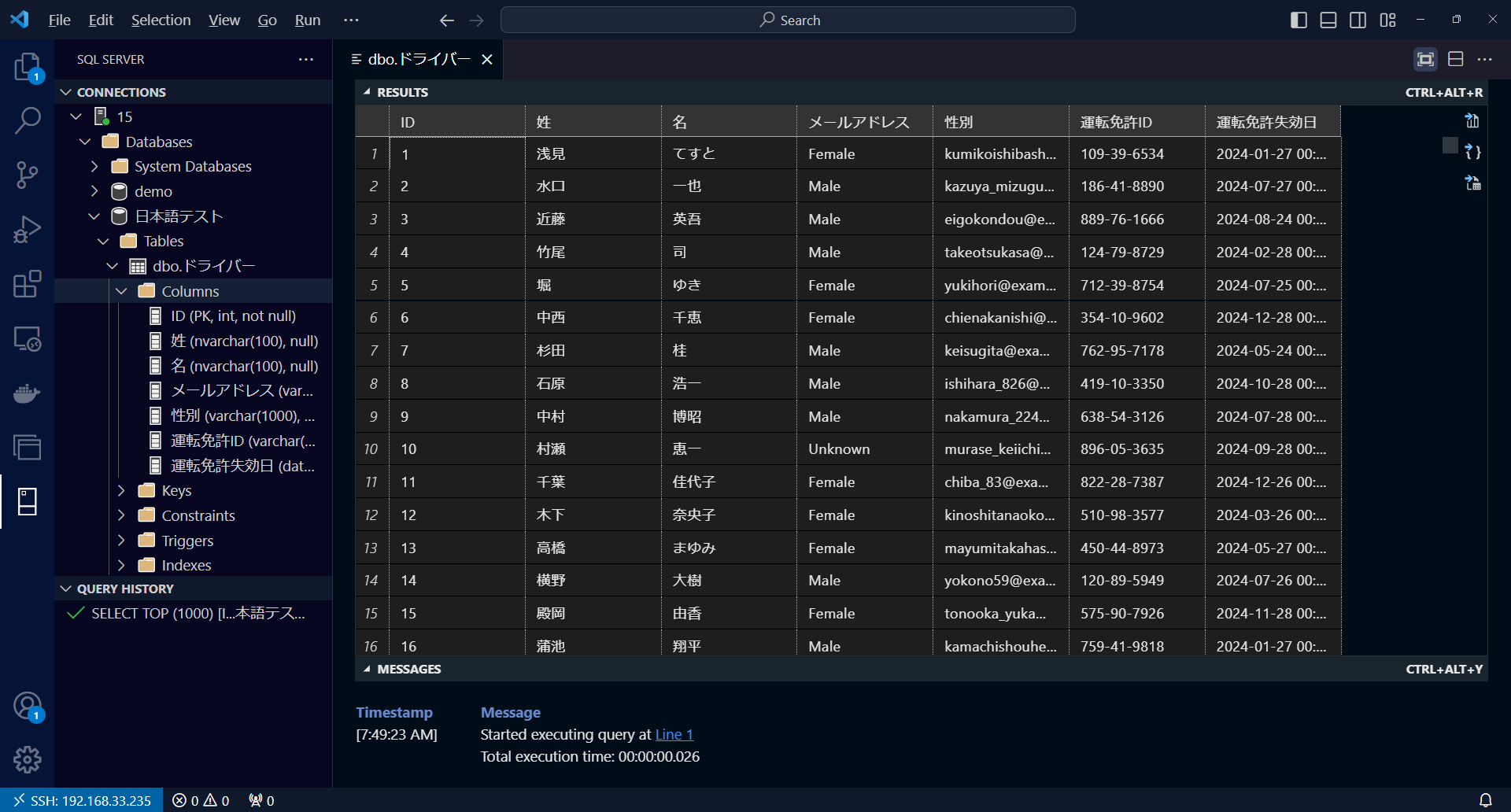
以下のようにマッピングを設定すれば、
"sourceEntities": {
"tableSync": {
"schema": "dbo",
"table": "ドライバー",
"type": "drivers",
"scope": "data",
"mapping": {
"ID": "id",
"名": "fname",
"姓": "lname",
"メールアドレス": "email"
}
}
},IDと姓、名、メールアドレスのみをレプリケーションし、JSON上のキー名を異なるものに対応づけできます。
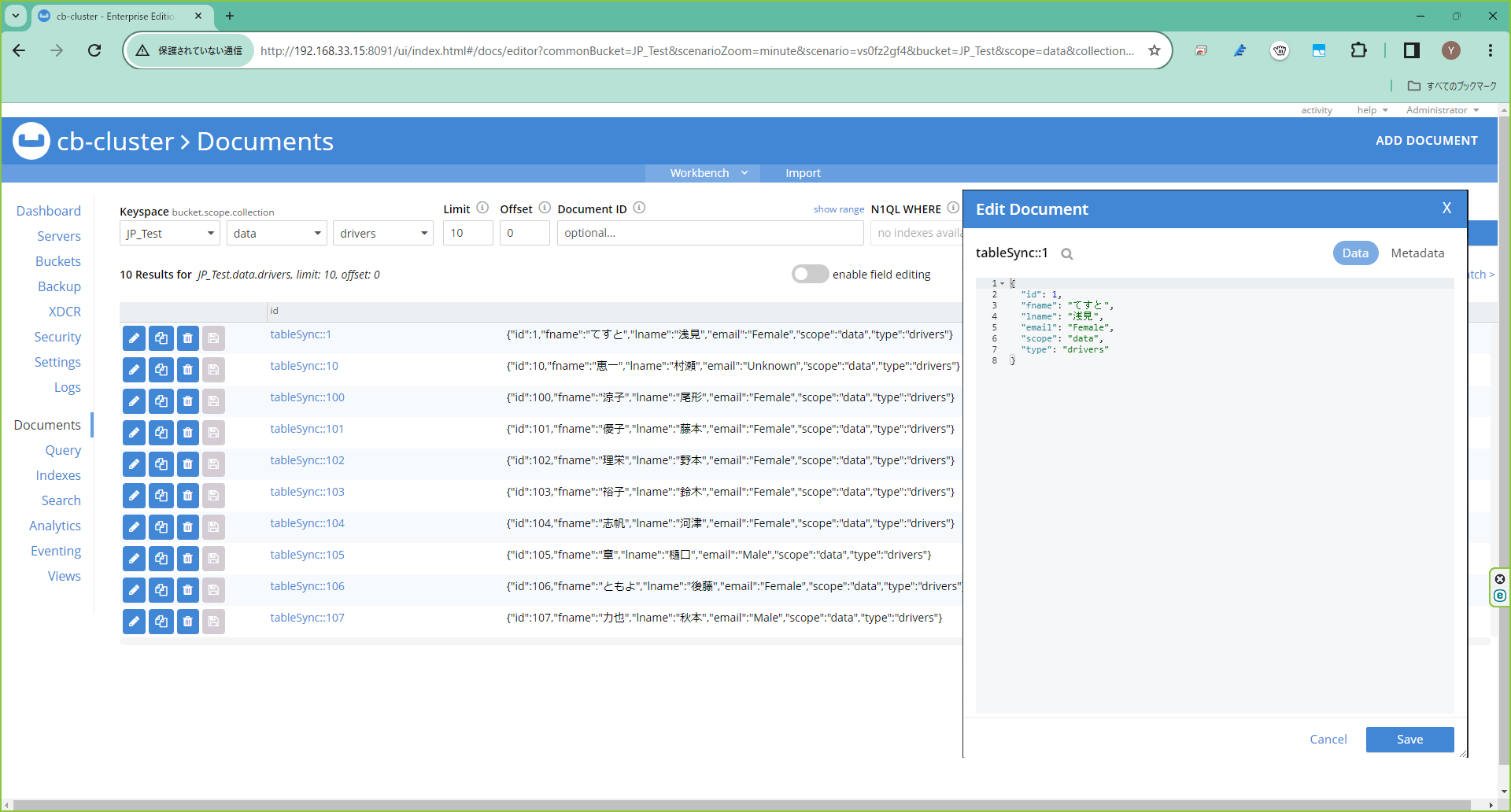
SQLクエリJSONモデリング
SQLクエリの実行結果をJSONに落とし込むこともできます。Gluesync エンジンには、リレーショナルデータベースがサポートする SQL クエリエンジンのバージョンまたは言語と互換性があるため、新しい SQL クエリ言語を学ぶ必要も、特定のプラットフォーム機能を制限する必要もありません。
対応SQLコマンド
| SQLコマンド | Gluesyncの互換性 |
INNER JOIN | ✔ |
OUTER JOIN | ✔ |
LEFT JOIN | ✔ |
WHERE | ✔ |
foo + ' ' + barのような文字列連結 | ✔ |
* + - /のような算術演算子 | ✔ |
UNION | 複数エンティティで同じ宛先(typeとscope)を使用すると同様の結果を得られます。 |
※サブクエリは今後のリリースでサポート予定です。
例えば、以下のような複数テーブルから、配送に必要な情報のみを抽出するために以下のようなクエリを使用しているとします。
SELECT o.ID as id,
o.注文番号,
o.注文日時,
c.氏名 as お客様氏名,
c.ふりがな,
c.メールアドレス,
c.電話番号,
a.都道府県 + a.市区町村 + a.番地 as 送り先住所,
a.建物名・部屋番号 as 建物名,
a.郵便番号 as 郵便番号,
d.姓 + ' ' + d.名 as 担当ドライバー
FROM dbo.注文ヘッダー o
INNER JOIN dbo.住所 a on a.ID = o.住所ID
INNER JOIN dbo.ドライバー d on d.ID = o.ドライバーID
INNER JOIN dbo.顧客情報 c on c.ID = o.顧客ID
where o.ステータス = 1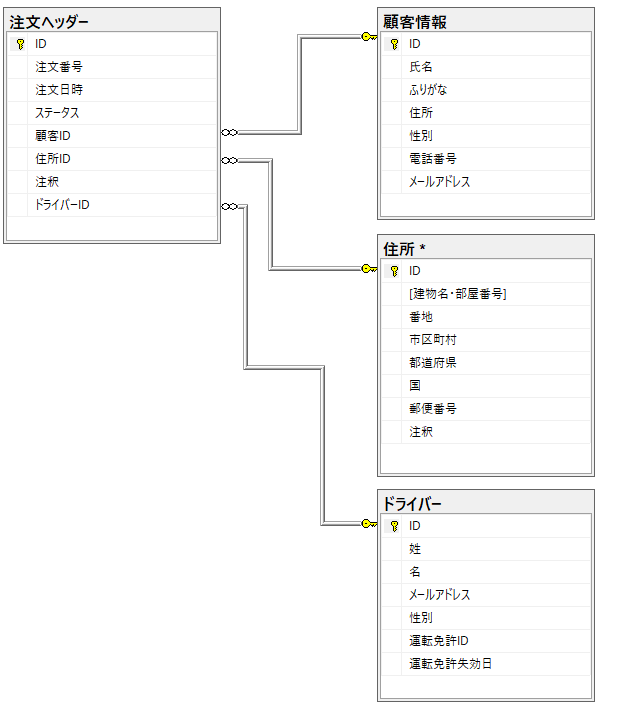
このクエリ実行結果の形式でNoSQL上にはデータを保持したい場合、以下のようにそのクエリを1行で記述するのみです。
※テーブル名にはエイリアスを使用する必要があります。
"sourceEntities": {
"INNER_JOIN": {
"type": "INNER_JOIN",
"schema": "dbo",
"scope": "data",
"query": "SELECT o.ID, o.注文番号, o.注文日時, c.氏名 as お客様名, c.ふりがな, c.メールアドレス, c.電話番号, a.都道府県 + a.市区町村 + a.番地 as 送り先住所, d.姓 + ' ' + d.名 as 担当ドライバー FROM dbo.注文ヘッダー o INNER JOIN dbo.顧客情報 c on c.ID = o.顧客ID INNER JOIN dbo.住所 a on a.ID = o.住所ID INNER JOIN dbo.ドライバー d on d.ID = o.ドライバーID where o.ステータス = 1"
}
},これを同期するとNoSQL上では以下のようにデータが保持されます。
{
"ID": 111,
"注文番号": "SO-97411111",
"注文日時": "2021-10-30T02:06:03",
"お客様名": "クライム 太郎",
"ふりがな": "くらいむ たろう",
"メールアドレス": "climbtest@climb.co.jp",
"電話番号": "03-9336-3660",
"送り先住所": "東京都中央区日本橋蛎殻町1丁目36−7蛎殻町千葉ビル4F",
"担当ドライバー": "クライム配達員",
"scope": "data",
"type": "INNER_JOIN"
}また、SQLクエリJSONモデリングを実施していたとしても、初期同期後は変更点のみがリアルタイムに同期されます。
アドバンスドデータモデリング
アドバンスデータモデリングはネスト(入れ子)構造をもつJSONドキュメントを作成するために使用できます。
例えば以下のように外部キーを持つテーブル群から
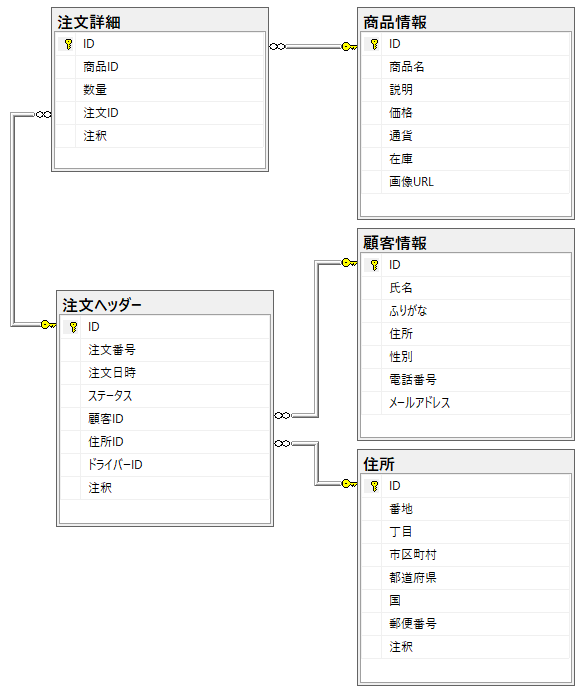
一部のデータのみを取り出し、以下のようなネスト構造で深さを持つJSONドキュメントを作成したいとします。
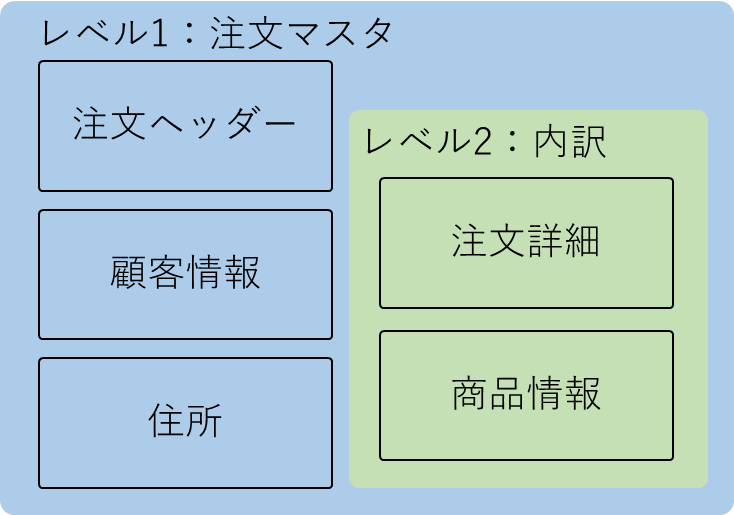
この場合、以下のようにレベルごとに参照するテーブルとフィールドを指定します。
"sourceEntities": {
"order": {
"type": "order",
"scope": "data",
"dataModeling": [
{
"level": 1,
"name": "注文",
"tables": [
{
"table":"dbo.注文ヘッダー",
"keys": {
"ID":"oh_ID"
},
"fields": {
"ID":"oh_ID",
"注文番号": "注文番号",
"注釈": "注釈"
},
"alias": "oh",
"where": "ステータス = 1",
"fromTable": true
},
{
"table": "dbo.顧客情報",
"keys": {
"ID": "c_ID"
},
"fields": {
"ID": "c_ID",
"氏名": "お客様名",
"ふりがな": "ふりがな",
"電話番号": "TEL"
},
"alias": "c",
"join": {
"with": "dbo.注文ヘッダー"
}
}
]
},
{
"level": 1,
"name": "住所",
"tables": [
{
"table": "dbo.住所",
"keys": {
"ID": "ad_ID"
},
"fields": {
"ID": "ad_ID",
"都道府県": "都道府県",
"市区町村": "市区町村",
"丁目": "丁目",
"番地": "番地",
"郵便番号": "郵便番号"
},
"alias": "ad",
"join": {
"with": "dbo.注文ヘッダー"
}
}
]
},
{
"level": 2,
"name": "注文詳細",
"tables": [
{
"table": "dbo.注文詳細",
"keys": {
"ID": "o_ID"
},
"fields": {
"ID": "o_ID",
"数量": "数量",
"注釈": "詳細注釈"
},
"alias": "o",
"join": {
"with": "dbo.注文ヘッダー"
}
},
{
"table": "dbo.商品情報",
"keys": {
"ID": "a_ID"
},
"fields": {
"ID": "a_ID",
"商品名": "商品名",
"説明": "商品説明"
},
"alias": "a",
"join": {
"with": "dbo.注文詳細"
}
}
]
}
]
}
},これを同期させると、NoSQL上では以下のようにJSONドキュメントが保持されます。
{
"oh_ID": 107,
"注文番号": "SO-!IAMNEW!-03",
"注釈": "置き配指定あり",
"c_ID": 4,
"お客様名": "クライム花子",
"ふりがな": "くらいむはなこ",
"TEL": "03-3660-9336",
"ad_ID": 2,
"都道府県": "東京都",
"市区町村": "中央区",
"丁目": "日本橋蛎殻町1丁目",
"番地": "36-7",
"郵便番号": "103-0014",
"注文詳細": [
{
"o_ID": 1010,
"数量": 10,
"詳細注釈": "コンテナでデプロイ",
"a_ID": 5,
"商品名": "グルーシンク",
"商品説明": "主要RDBMSとNoSQL間でリアルタイムなクラウドネイティブデータレプリケーションを実現"
},
{
"o_ID": 1011,
"数量": 1,
"詳細注釈": "Windowsへインストール",
"a_ID": 10,
"商品名": "スィニティレプリケート",
"商品説明": "異種データベース間の双方向に対応したリアルタイムレプリケーション"
}
],
"scope": "data",
"type": "order"
}dataModelingでの定義情報:
| キー | 説明 | 値 |
level | JSONオブジェクトの親子関係の深さレベル | 1または2 |
name | エンティティの名前 | 文字列 |
tables | JOIN-likeステートメントに含まれるテーブルの配列 | 次の表を参照 |
tablesでの定義情報:
| キー | 説明 | 値 |
table | テーブルの名前 | 文字列 |
fields | 対象となるカラムのリスト(mappingと同様) | 文字列 |
alias | (オプション)同コンテキスト内の繰り返し使用される同テーブルを区別するために使用される別名 | 文字列 |
where | (オプション)標準SQL言語と同様に、フィルタとして適用されるWhere句を指定 | 文字列 例: status = 1 |
fromTable | クエリでマスターとして使用されるテーブルで指定 | ブール値 (trueまたはfalse)、デフォルトはfalse |
join(外部キー有り) | 標準SQLのようにJOINステートメントを呼び出し、このコンテキストで結合する必要があるテーブルを指定します。テーブル間の外部キーを自動的に処理します。 | { |
join(外部キーなし) | 標準SQLのようにJOINステートメントを呼び出し、このコンテキストで結合する必要があるテーブルを指定します。”on “句を使用して、指定されたステートメントで関係するテーブル間のデータを集約するようにエンジンに強制します。これは、テーブルに外部キーが宣言されていない場合に使用できます。注意: 定義したエイリアスを使用してください。 | { |
keys | テーブルの主キーとそのエイリアスを表すキー/値の対応付け | { |
このようにシンプルな同期から構造の異なる複雑な同期まで、データモデリングで柔軟に対応いただけます。ご興味ありましたら是非弊社までお問い合わせください。
https://www.climb.co.jp/soft/contact/contact.php
関連したトピックス
- GlueSyncでNoSQL活用を加速:導入編
- GlueSyncでNoSQL活用を加速:通知アラート、ログ、モニタリング
- GlueSyncがAWS S3(互換も含む)に対応:分析、データレイク、コールドストレージ向けに、AWS S3 へのリアルタイムデータレプリケーションがシンプルに
- Web UI日本語化でもっと簡単にデータ同期[Gluesync 2.0.9]
- Gluesyncのレプリケーションソース(CDC付)およびレプリケーションターゲットとしてのDynamoDBのサポート
- NoSQLクラウドデータベース: メリットと特徴
- ドキュメント・データベースは何か?
- Parquetで連携し、より効率的なデータ分析を簡単に実現【Gluesync】
- Gluesync Bootstrapper:数千のデータ統合を数秒で自動化するオープンソースツール
- Gluesyncの評価手順(Windows版:2025/11/13現在)

 RSSフィードを取得する
RSSフィードを取得する


