

Apache Hadoopは大量のデータを手軽に複数のマシンに分散して処理できるオープンソースのプラットフォームです。Javaで書かれているため、弊社のBIツー「EspressReport ES」(以下ERES)に対応しており、HadoopのデータをERESを介してグラフ化、レポート化、ダッシュボードへの展開が可能です。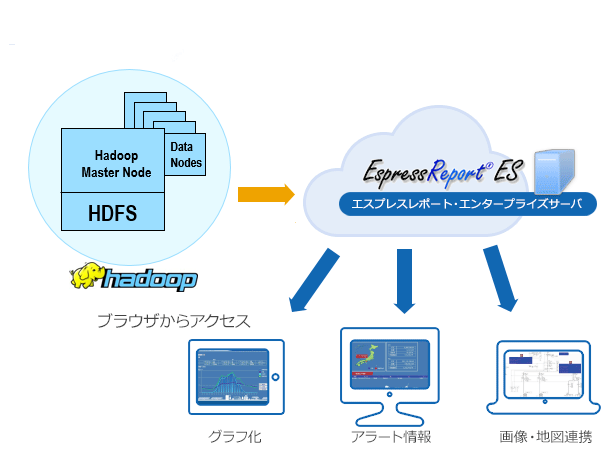
ERESとHadoopを連携するためには以下が必要です。
・ERES本体(Javaが稼働するマシンであればOK)
・Hadoop: Apache Hadoopはオープンソースのソフトウェアフレームワークで、汎用サーバーのクラスタ間で大規模なデータセットを分散処理することができます。
更に非常に高度なフォールト・トレランス(耐障害性)とスケーラビリティで、あらゆる種類のデータ、膨大な処理能力、事実上無限の並行タスクやジョブを処理する能力を備えた膨大なストレージを提供します。
・Hive: HiveはオリジナルのSQL-on-Hadoopソリューションで、コマンド-ライン・クライアントを含むMySQLの動作、構文、およびインターフェイスをエミュレートします。また、MySQLスタイルのクエリを実行するJavaアプリケーションへ対応するためのJava APIおよびJDBCドライバも含まれています。Hiveは相対的にシンプルで使い易いにもかかわらず、速度が遅く、読み込み専用になっています。
Hadoopによるビッグデータ解析では一般的にJavaを使い、MapReduceの実装をしますが、実際にロジックにするのは結構大変な作業です。
しかしHiveはHDFS上に保存されたデータをテーブルとしてみなすことが可能でHiveQLというSQLライクな言語を使うことで、MapReduceを意識することなく、データを操作することができます。ERESではSQLでデータを操作するため、このHiveが必要となります。
・Spark ( Databricksを含む):Apache Sparkは、オープンソースのクラスタ・コンピューティング・フレームワークです。高度な大規模データ処理用の汎用エンジンです。Hadoopの2段階ディスク・ベースのMapReduceパラダイムとは対照的に、Sparkは中間結果をメモリに保持します。そのインメモリ・プリミティブは、特定のアプリケーションで最高100倍のパフォーマンスを提供します。SparkはHadoop, Mesos,スタンドアローン、クラウドで稼働します。HDFS、Cassandra、HBase、S3などのさまざまなデータソースにアクセスできます。
ERESからHadoopへ接続する際の設定画面です。基本的には接続に必要なIPアドレス、ポート、データベース名です。
Hadoopデータソースへの接続は簡単に設定できます。HiveとSparkを含む設定は必要です。 この構成をサポートするJDBCドライブは、Espress製品にバンドルされています。 データ・レジストリでHadoopデータソースを選択し、ドライバとURLを次の形式で指定します。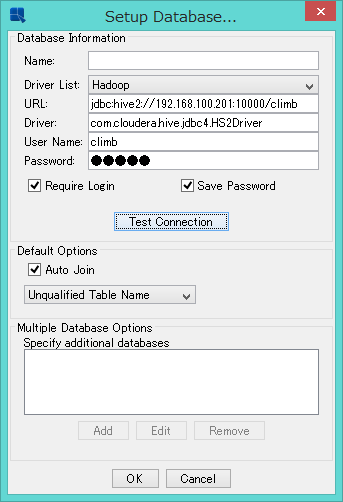
JDBCドライバクラス名:
org.apache.hive.jdbc.HiveDriver(Sparkを使用しない場合)
com.cloudera.hive.jdbc4.HS2Driver(Sparkを使用する場合)
URL:jdbc:hive2://<サーバ名>:<ポート>/<DB名>
以下のようにERESでHadoopのデータをダッシュボード化することができます。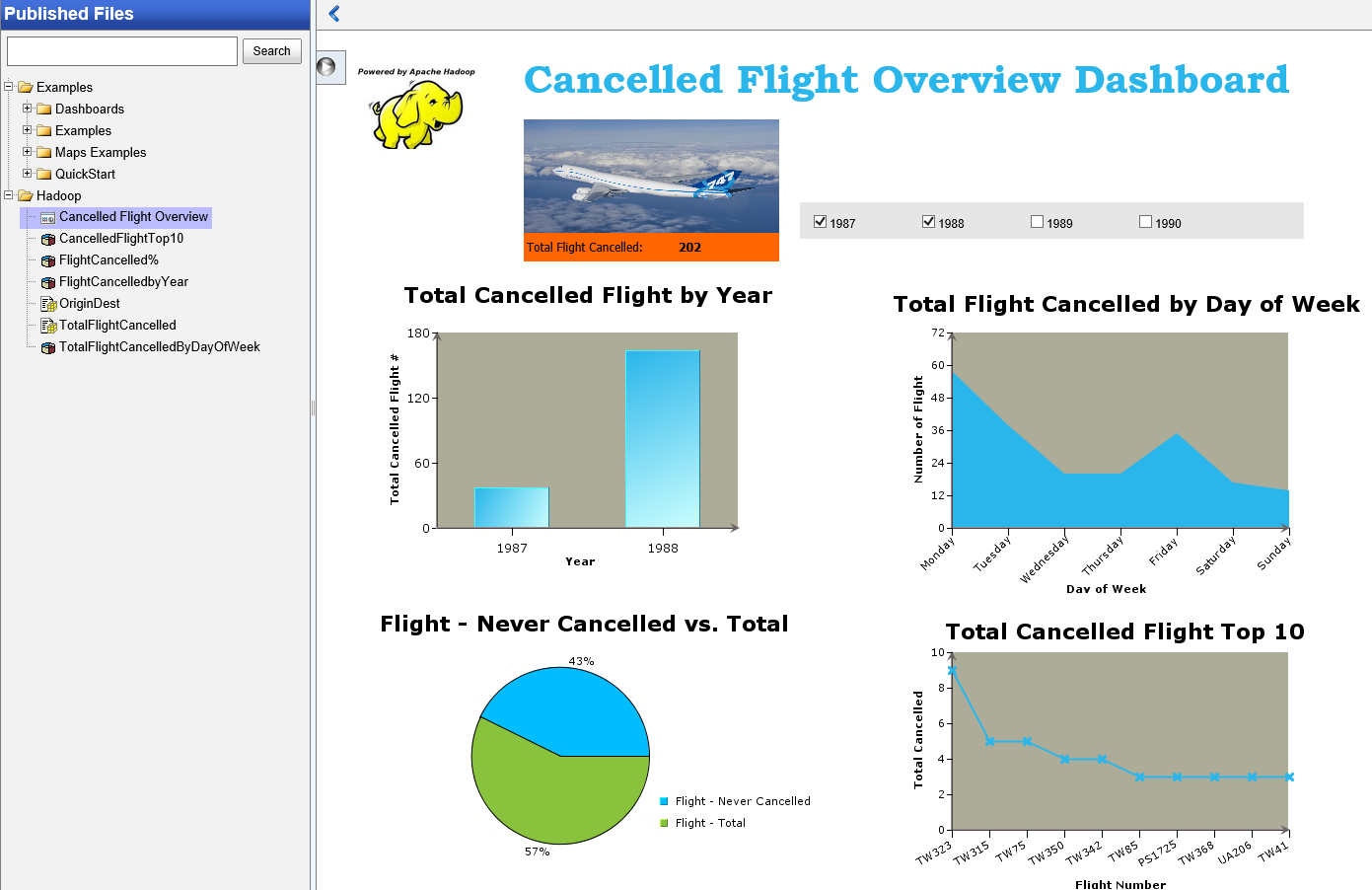
ここではERESでのHadoopの可視化を紹介していますが、他のEspressシリーズでも同様な可視化が可能です。
(注)HiveQL:Hiveは,HDFS上のデータをHiveQLと呼ばれるSQLライクなクエリ言語で処理できるようにしたもので,CDHにも含まれています。 HiveQLで記述した命令が,自動でMapReduceに変換されるため,ユーザ自身がMapReduceジョブプログラムを記述する必要がなく,データ解析が簡便に行えます。
関連するトピックス:
- 複数のデータソースの利用 (Ver6.0)【Javaチャート・グラフ作成ツールEspressChart】
- Teradataのデータをダッシュボード化してデータ分析・活用!EspressReport ESとの連携可能!
- EspressDashboard for Azure Synapse Analytics
- EspressReport ES Cloud からAmazon Redshiftに接続しビッグデータを活用、そして自社Webへチャート/レポート/ダッシュボードで可視化
- Espress API経由でREST APIから取得したJSONデータによるチャートの作成
- DatabricksとEspressReport ES (ERES) との連携確認
- Databricks、大躍進のわけ
- IBM DB2 for i データの見える化を実現-グラフ・レポート・ダッシュボードへ簡単展開
- ERES + Fluentd かんたんログ活用術 – その④ EspressReport ESによる可視化
- ダッシュボード上のチャート、レポートをフォームから指定

 RSSフィードを取得する
RSSフィードを取得する

汎用RDBからHadoopへのデータ連係をサポートするDBMoto Ver9 について:https://www.climb.co.jp/blog_dbmoto/archives/3231
MongoDBデータの可視化手法: EspressChart/Reportとの連携について:
https://www.climb.co.jp/blog_espress/archives/1468