
Microsoftのワークロードをエンタープライズ規模でバックアップすることは、単に複雑であるだけでなく、パフォーマンス、スケール、そしてAPIスロットリングという見えない上限の間の、重大なバランスを取る行為でもあります。
企業がMicrosoft 365、Dynamics 365、Azure製品全体でペタバイト単位のデータを生成する中、ITチームはボトルネックや遅延を発生させることなく、高速で信頼性が高く、SLAに準拠したバックアップを確保するよう強いられています。また、MicrosoftはAPIの使用制限を厳しく定めているため、どんなに優れたバックアップ戦略でも負荷に耐えられなくなる可能性があります。
そこで登場するのがDruvaです。
10年にわたるクラウドネイティブの専門知識と拡張性を考慮したプラットフォームを持つDruvaは、何千社もの企業がストレスや妥協なく、Microsoftのワークロードを効率的にバックアップできるよう支援しています。本ブログでは、Druvaがどのような方法で、あらゆる規模のMicrosoft環境にシームレスでインテリジェントな拡張可能なバックアップと復元を提供しているのかをご紹介します。
目次
エンタープライズバックアップの課題
エンタープライズ規模では、Microsoftワークロードの保護は、高速かつ信頼性の高いバックアップとSLAの遵守のバランスを取る行為です。
何十万ものMicrosoft 365ユーザーとSharePointサイトにわたるペタバイト単位のデータを管理するIT管理者であれば、このタスクの複雑さをすでに理解しているでしょう。環境が拡大するにつれ、リスクも高まり、検討すべき質問も増えます。
- Microsoft 365のすべてのオブジェクトの初回バックアップを完了するのにどれくらいの時間がかかるのか?
- 日々生成されるデータが増え続ける中でも、バックアップソリューションは日々のSLAを満たすために拡張できるのか?
- Microsoftがバックアップを許可している容量の上限に達した場合はどうなるのか?
これらは、企業ITチームが日々直面するパフォーマンス上の現実です。Microsoftのワークロード(Exchange OnlineやOneDriveからSharePointやTeamsまで)は、絶え間なくデータを生成します。このデータをバックアップする必要性は明らかですが、定義されたSLAの範囲内で、中断することなく、規模を拡大してバックアップを行うことは、決して容易なことではありません。問題は、バックアップツール自体にあるとは限りません。すべての企業が最終的に直面する目に見えない限界、つまりMicrosoft APIの制限です。
バックアップソリューションがAPIコールをあまりにも頻繁に、あまりにも迅速に行うと、Microsoftはインフラを保護するために制限を課します。このスロットリングは、バックアップのパフォーマンスを低下させ、復元時間を遅らせ、Microsoft 365サービスの通常の使用にまで支障をきたす可能性があります。
そのため、スケールだけでは十分ではありません。クラウドネイティブであるだけでなく、APIを認識するバックアップソリューションが必要です。つまり、環境に影響を与える前に、インテリジェントに適応してスロットリングを回避するソリューションです。スロットリングとは何か、そしてそれがエンタープライズ規模のバックアップの重要な要素である理由について詳しく見ていきましょう。
Microsoft APIスロットリングとは何か(そしてなぜ重要なのか)
API スロットリングは、Microsoft によるクラウド保護の手段ですが、企業 IT チームにとっては、バックアップパフォーマンスの「サイレントキラー」となる可能性があります。
Microsoft ワークロードのバックアップを行う際、Druva は Microsoft Graph API を使用して、Exchange、SharePoint、OneDrive、Teams、Entra ID、Dynamics 365 などのサービスにわたるデータにアクセスします。 これらの API は強力ですが、制限があります。Microsoft は、共有バックエンドリソースの公平かつ一貫した利用を確保するために、テナント固有のクォータを適用しています。テナントの規模、アクティビティ、および動作に基づいて割り当てられたクォータを超過すると、MicrosoftはAPIコールの速度を低下させたり、拒否したりします。これは「スロットリング」と呼ばれ、Microsoftのインフラストラクチャを保護し、すべてのユーザーのパフォーマンス低下を防止し、数百万のテナントにわたって公平な利用を徹底することを目的としています。
しかし、バックアップジョブの場合、スロットリングは次のようなことを意味します。
- 不完全なバックアップや失敗したバックアップ
- 遅い復元操作や停止した復元操作
- SLAの未達成や復旧時間の増加
- 同じテナントで実行されている他のMicrosoftサービスへの障害
課題は次のとおりです。 スロットリングを無効にすることはできず、また完全に予測することもできません。 スロットリングはテナントごとに異なり、時間とともに変化し、Microsoft 365の全サービスで発生しているアクティビティの量によっても異なります。 これが、従来のバックアップツール(クラウド用に構築されたものも含む)が規模の拡大に追いつくのに苦労する理由です。
その答えは、スロットリングを回避することではなく、スロットリングを凌駕することです。そして、まさにそれがDruvaのアーキテクチャが構築されている理由なのです。
Druvaのソリューション:エンタープライズ規模のバックアップのためのクラウドネイティブアーキテクチャ
エンタープライズバックアップの課題を解決するには、クラウド専用に設計されたスマートでスケーラブルなアーキテクチャが必要です。
Druvaのアプローチは、従来のバックアップソリューションとは根本的に異なります。Druvaは、最初から100%クラウドで稼働するように設計されており、ハードウェア、エージェント、管理するインフラストラクチャは一切ありません。これにより、企業はパフォーマンス、柔軟性、および多様なMicrosoftワークロード全体にわたる制御を維持しながら、容易に拡張することができます。
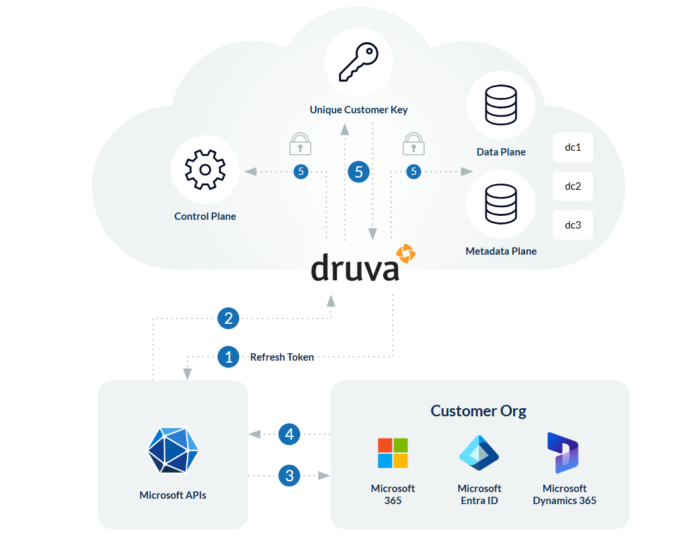
Druvaがストレスなく大規模なバックアップを実現する方法は次の通りです。
- クラウドネイティブ設計:Druvaは、クラウドの弾力性と回復力を活用して、お客様のデータ使用状況とアクティビティに基づいてリソースを動的に拡張します。1,000ユーザーでも100,000ユーザーでも、プラットフォームは自動的に拡張します。つまり、プロビジョニングやサイズの推測、メンテナンスのオーバーヘッドは不要です。シームレスな拡張性のみです。
- エージェントレスで集中管理:Druvaは、エージェントレスアーキテクチャにより、バックアップ操作を簡素化します。各エンドポイントやサーバーにソフトウェアをインストールしたり、メンテナンスする必要がなくなります。代わりに、すべてを集中管理コンソールから管理し、ITチームはすべてのMicrosoftワークロード、テナント、およびサブスクリプションを完全に可視化し、制御することができます。ポリシー主導の自動化により、保護の標準化、SLAの適用、新しいユーザーやワークロードの追加を数分で(数週間ではなく)簡単に行うことができます。
この360度保護により、規模に関係なく、ユーザのMicrosoft環境全体が安全で、コンプライアンスを遵守し、簡単に復元できることが保証されます。つまり、Druvaは企業向けにクラウドで構築されています。スマートなアーキテクチャ、インテリジェントな自動化、Microsoftワークロードへの深いサポートにより、Druvaはバックアップの複雑さを排除し、本当に重要なものに集中できるようにします。つまり、回復力、俊敏性、安心感です。
リアルタイムのテレメトリとスマートな機能がインテリジェントなバックアップの決定を可能に
企業規模のバックアップでは、スピードだけが重要なのではありません。 適切なタイミングで適切な判断を下す必要があります。 そこで威力を発揮するのが、Druvaのインテリジェンスです。 Druvaのプラットフォームは、世界中の顧客ベース全体でリアルタイムのテレメトリを継続的に収集・分析します。 このデータ主導のアプローチにより、特にMicrosoft APIクォータやデータ容量が常に変動する環境において、バックアップとリストアの処理をプロアクティブに調整し、効率性と信頼性を最大限に高めることができます。
Druvaがリアルタイムで監視しているのは以下の項目です。
- 各Microsoft 365テナントのライセンスユーザー数
- バックアップの複雑さを評価するためのSharePointサイト数とデータサイズ
- 最もアクティブなユーザーまたはワークロードを特定するための日次データ変更率
- 遅延やエラーの傾向を含むMicrosoft Graph APIの応答
- コンピューティングリソースの健全性チェック
この豊富なデータセットにより、Druvaはデータに基づく先を見越した意思決定を行い、バックアップのパフォーマンスをリアルタイムで最適化することができます。インテリジェンスがよりスマートなバックアップを実現する方法は次のとおりです。
1. インテリジェントなスケジュール:ピーク時とオフピーク時の使用状況を分析することで、Druvaは競合を減らし、不要なスロットリングを回避するために最適なタイミングでバックアップを動的にスケジュールします。たとえば、利用可能なAPI帯域幅を最大限に活用するために、業務時間外に積極的なバックアップ活動をスケジュールすることができます。
2. 最適化されたAPIの利用:Druvaは、自社アプリとMicrosoft 365 APIの消費を継続的に追跡し、リアルタイムで利用状況を最適化します。しきい値に近づいている場合、Druvaは、重要なバックアップや復元タスクのクォータを確保するために、見積もりジョブなどの非クリティカルな操作をインテリジェントに削減または一時停止します。
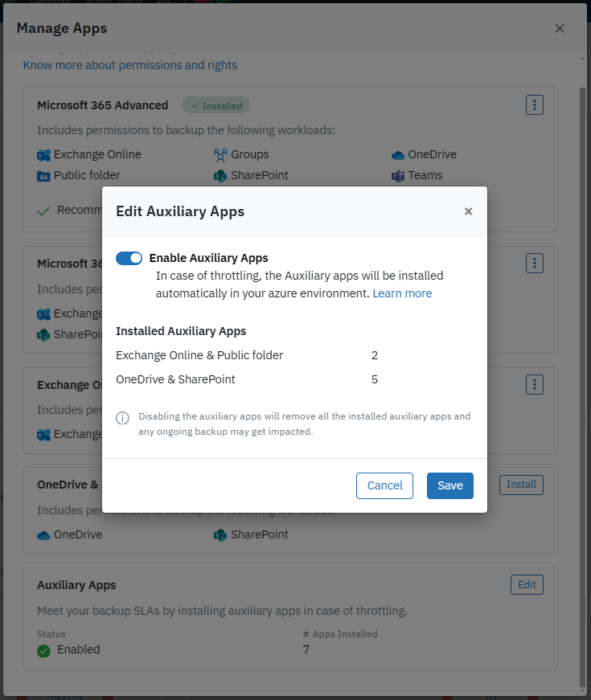
3. 動的負荷分散:ユーザーアクティビティ、データサイズ、ワークロードの分散を可視化することで、Druvaは動的に展開されるマイクロサービスである補助アプリを使用してバックアップ操作を拡張します。これにより、単一のプロセスに過剰な負荷がかかることを防ぎ、高負荷時でも一貫したパフォーマンスを確保します。
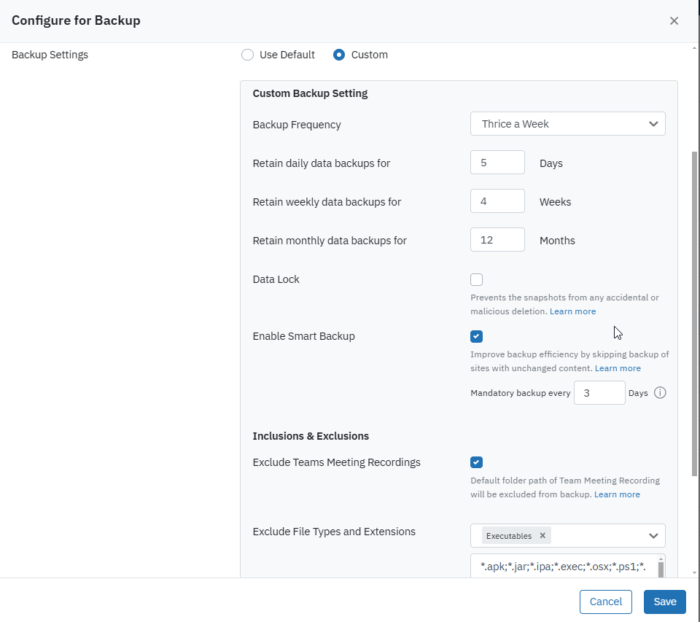
4. スマートなバックアップの最適化:APIの使用量を節約し、処理を高速化するために、Druvaのスマートバックアップ機能は増分バックアップ時に変更のないSharePointサイトを自動的にスキップします。これにより、データ保護ポリシーを遵守しながら、不要なAPIの消費を大幅に削減できます。
結果:99%のバックアップSLAを実現
結局のところ、最も重要なのは、SLAを毎回確実に達成することです。DruvaのインテリジェントでAPI対応のクラウドネイティブなアーキテクチャは、理論上だけでなく、実運用でもその賢さを証明しています。
4,000社を超える企業顧客に対して、Druvaは常に以下のことを実現しています。
●業務ピーク時でも影響ゼロのリストア操作
●99%以上のバックアップSLA遵守
●1日あたり30TB以上の増分データ変更を管理
●1,400万人以上のMicrosoft 365ユーザーを保護
これらの結果は異常値ではなく、拡張性、適応性、そして現実の厳しい企業環境におけるデータ保護を目的として設計されたプラットフォームの成果です。
結論:エンタープライズ規模のMicrosoft 365バックアップの簡素化
エンタープライズ規模のMicrosoftワークロードのバックアップは、常に消火活動やSLAの未達、スロットリングの頭痛の種を意味するものではありません。Druvaを使用すると、クラウドネイティブであるだけでなく、クラウドに精通したプラットフォームが手に入ります。最も要求の厳しい環境でも、ストレスフリーでスロットリングのないデータ保護を実現するように、一から設計されています。
インテリジェントなワークロードスケジューリングやリアルタイムの遠隔測定から、自動スケーリングのマイクロサービスやAPIの最適化まで、DruvaはMicrosoftのバックアップと復元の複雑性を排除します。数千人のユーザーを管理している場合でも、グローバルテナント全体でペタバイト単位のデータを保護している場合でも、Druvaは次のような機能を提供します。
●信頼性の高い復元を毎回実現
●高速で信頼性の高いバックアップ
●APIを認識し、自動的にスケーリング
関連トピックス
- Druva Phoenix:多種多様なバックアップ対象
- エンドポイント端末紛失時のデータ漏洩を防ぐバックアップ【Druva inSync】
- Amazon S3への直接バックアップでコスト削減!データ保護のお悩みは『Druva Phoenix』で解決! 2019/09/26開催Webセミナー
- Druva Phoenix:ハード不要でAWSへダイレクト バックアップ – 3つの特長
- Druva Phoenixの基本的な機能【Businessエディション】
- データ損失を抑えたランサムウェア攻撃からの復旧【Druva】
- Druva Phoenixの統合データ保護機能【Enterpriseエディション】
- DruvaクラウドをAWS Outpostsでオンプレミスに
- [関連記事まとめ] Webセミナー報告記事
- VMware仮想環境をクラウド(AWS)へダイレクト・バックアップとアーカイブ : Druva Phoenix






 RSSフィードを取得する
RSSフィードを取得する
