
N2WS Backup and Recovery Ver3.1におけるS3 レプリケーション・プロセスについて紹介します。
N2WS Backup and Recovery の最新版(Ver3.1)を開くと、新ダッシュボードが現れます。この例ではトライアルアカウントを使用しています。
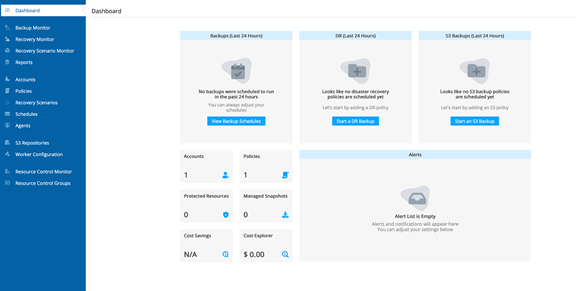
S3レプリケーションを開始するには、ポリシーセクションに移動します。
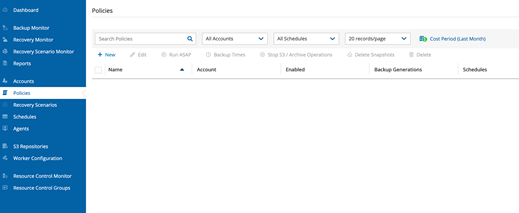
ここでは、例としての新しいポリシーを作成します。
ポリシーに名前を付け、このポリシーに使用するN2WSのユーザとアカウントを選択します(複数のユーザがある場合)。このタスクの事前定義されたスケジュールが既にある場合は、ここで指定します。この例では、レプリケーションジョブを手動でトリガーします。
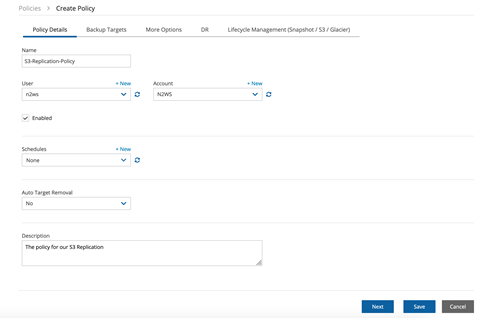
次に”Backup Targets “タブに移動し、”Add Backup Targets “をクリックします。
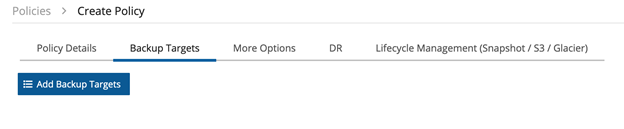
最後のオプションで “S3 Bucket Sync “をクリックします。

ウィンドウがポップアップしたら、レプリケートしたいバケットを選択します。ここでは、”n2ws-s3-repo “バケットを使用します。
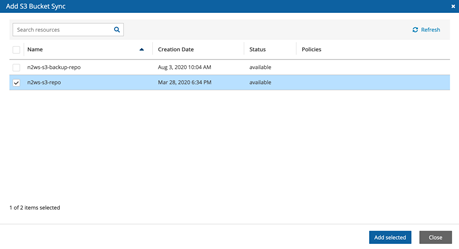
バケットが追加されたら、”Configure “をクリックしてレプリケーションの設定を開始します。
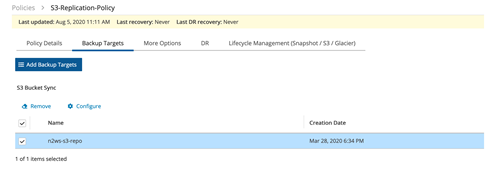
このような構成になります。
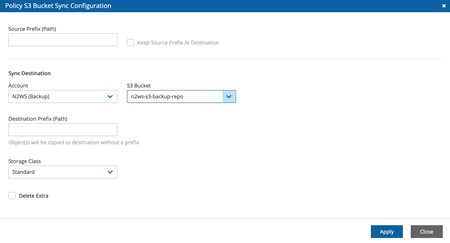
ここでは、バケット全体が同期されるように、ソースのプレフィックス(または使用したいパス)を空のままにしておきます。特定のプレフィックスを選択した場合は、送信元のプレフィックスを送信先に保持するオプションにチェックを入れることができます。これは、長期でプレフィックスを使用している場合や、常に同じ場所に同期する場合に便利です。
“Sync Destination”で、レプリケーションを実行するターゲットS3バケットと、必要に応じてデスティネーションのプレフィックスを選択します。また、S3ストレージクラスを選択することもできます。これにより、例えば、コストを管理するためにS3 スタンダード・ティアのオブジェクトをS3 Infrequent Accessとしてコピーすることができます。
最後のオプションは”Delete Extra”ボックスです。この機能を使用すると、宛先バケットが常にソースバケットに同期されていることを確認することができます。このボックスにチェックを入れると、宛先バケットにあるファイルのうち、ソースバケットにないファイルはレプリケーション・ジョブ実行中に削除されます。宛先バケットには他のバックアップやファイルが含まれている可能性があるため、このオプションは避けた方が良い場合が多いです。これらの手順が完了したら、「適用」をクリックします。あとは、”Run ASAP “をクリックして、このタスクを実行するだけです(事前に定義されたスケジュールを選択していない場合)。

他のバックアップ・タスクと同様に、Backup Monitorを使ってレプリケーションの進行状況を確認することができます。次のスクリーンショットでは、タスクが初期化されていることがわかります。

バックアップのS3バケットに行くと、以下のようにまだ空になっていることがわかります。
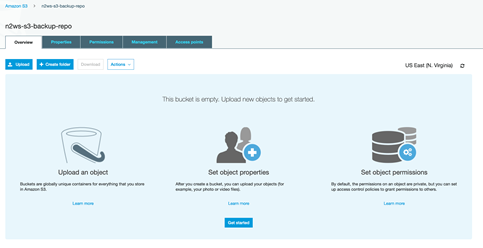
数秒後にタスクが実行されます。

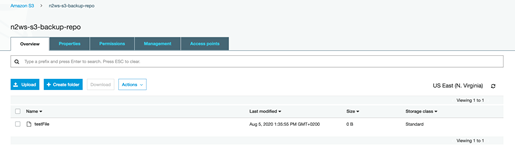
バックアップS3バケットに戻ると、新しいファイルがあり、N2WS Backup and Recovery経由でレプリケートされたことが確認できます。
関連トピックス
- Amazon S3へのバックアップに必要な権限【CloudBerry(MSP360)】
- WasabiがHot Cloud Storage with Object Lockをリリース、Veeamでバックアップの不変性(Immutability )を実現
- Amazon S3 Glacierにバックアップする方法
- ランサムウェア対策としてWasabi Cloud Storage を利用したCloudBerry(MSP360) Backup とのイミュータブル設定方法
- Amazon S3 RRSでのオブジェクトの損失:その通知設定とクラウドへの再アップロード【CloudBerry Backup】
- AWS S3 Glacier Vaultsに代わり、AWS S3 Glacierストレージクラスの活用
- Zerto 9.0: LTR(Long-Term Retention)のAmazon S3との新たな強化
- Amazon Glacierへのアーカイブがもたらす大きなコストメリット [N2WS Backup & Recovery v3.0]
- レプリケーションの動作について【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- 別メーカーのCPUを搭載したvSphereへの仮想マシンのレプリケーション【VMWare専用 バックアップ & レプリケーションソフト Veeam】







 RSSフィードを取得する
RSSフィードを取得する
