
デジタルとクラウドを中心とした今日の世界では、組織や企業は膨大な量のアプリケーションとデータを作成し、業務を推進しています。ITチームはしばしば、他のアプリケーション、外部サービス、分散システム、さまざまなデータソースに依存する複雑なソフトウェアプログラムやアプリケーションを使用していることに気づきます。
これらのアプリケーションやサービスのいずれかがダウンすると、実質的な収益の損失や潜在的な評判の低下につながり、ブランドや顧客維持にとってリスクとなります。統計によると、「壊滅的なデータ損失に見舞われた企業の94%は生き残れない」とまで言われています。
アプリケーションのディザスタリカバリ(DR)計画は、予期せぬ障害や災害が発生した場合に、組織や企業が重要なデータ、アプリケーション、システムを迅速に復旧させるのに役立ちます。DRには、重要なアプリケーションを迅速かつ効率的に復旧させるための一連の手順とポリシーを作成することが含まれます。DR計画は、複数の依存関係を持つ複雑なアプリケーションにとって、しっかりとしたディザスタリカバリ計画を立てることが不可欠です。
単純なアプリケーションでも複雑なアプリケーションでも、ソフトウェア・アプリケーションのディザスタリカバリ計画を構築するためのベストプラクティスを理解することが重要です。特に、外部のソフトウェアプログラムやサービスに依存している場合はなおさらです。
状態管理、データ管理、不変(イミュータブル)なバックアップ、バックアップを複数の場所に保管することの意義など、見落とされがちな概念を探ってみましょう。また、3つのユースケースについて詳細な技術的例を示し、さまざまなシナリオに対応した効果的なディザスタリカバリ・プランを構築する際のリスクと複雑さを説明します。
ダウンタイムを最小限に抑え、大切なデータを保護し、災害時の事業継続性を確保するための災害復旧計画を立てることが重要です。
目次
シナリオ設計 外部サービスに依存する複雑なアプリケーションの管理
外部サービスに依存する複雑なアプリケーションの災害復旧計画を設計する場合、考慮すべき課題がいくつかあります。その1つは、アプリケーションの異なるコンポーネントがどのように相互作用するかを理解することです。これには、アプリケーションが依存しているすべての外部サービスと依存関係を特定し、それらがどのように連携しているかを理解することが含まれます。
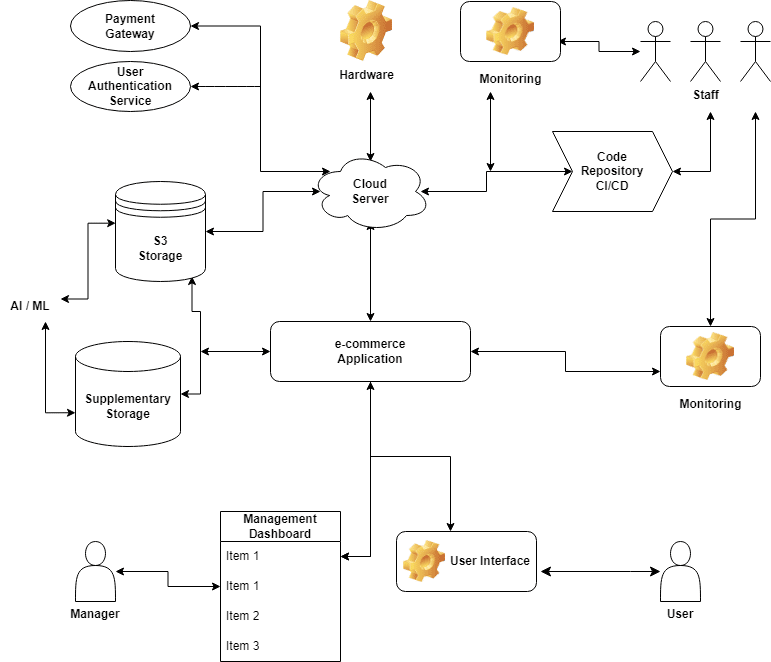
例えば、ペイメントゲートウェイにネットワーク障害が発生した場合、eコマースアプリケーションはバックアップのペイメントゲートウェイに切り替えることができます。しかし、ペイメントゲートウェイのプロバイダがアプリケーション障害を経験した場合、その復旧計画では、バックアップからデータを復元するか、ペイメントゲートウェイのインフラを再構築することになるかもしれません。
これらの課題に取り組むには、アプリケーションアーキテクチャとその異なるコンポーネント間の依存関係を理解することが不可欠です。これには、詳細なアプリケーション分析を実施し、すべての外部ソフトウェアサービス、システム、および依存関係を特定することが含まれます。
それらが特定されたら、次のステップは、起こりうるすべての障害シナリオをカバーする災害復旧計画を作成することです。これには、複数の決済ゲートウェイを使用するなど、重要なコンポーネントに冗長性を実装することや、障害発生時にデータがバックアップされ、迅速に復元できるようにすることなどが含まれます。
フロントエンドとバックエンドの状態管理
アプリケーションが災害に見舞われると、その状態(データ、構成、その他のコンテキスト情報を含む)が失われたり破損したりして、ダウンタイムにつながる可能性があります。。したがって、災害復旧計画は、アプリケーションの完全性を確保するために、状態管理を優先する必要があります。
状態管理はフロントエンドとバックエンドに分けられます。フロントエンドの状態管理は、災害時のユーザーエクスペリエンスにとって極めて重要です。対照的に、バックエンドの状態管理は分散システムにおいて重要であり、サーバやデータストア間での状態の複製と同期を保証します。
例えば、決済ゲートウェイに依存する電子商取引アプリケーションでは、災害復旧計画には、クライアント側のキャッシュのようなフロントエンドのメカニズムと、レプリケーションや同期のようなバックエンドのメカニズムを含める必要があります。さらに、バックアップのペイメントゲートウェイを統合することで、プライマリのペイメントゲートウェイがダウンしてもトランザクションが継続されるようにすることができます。
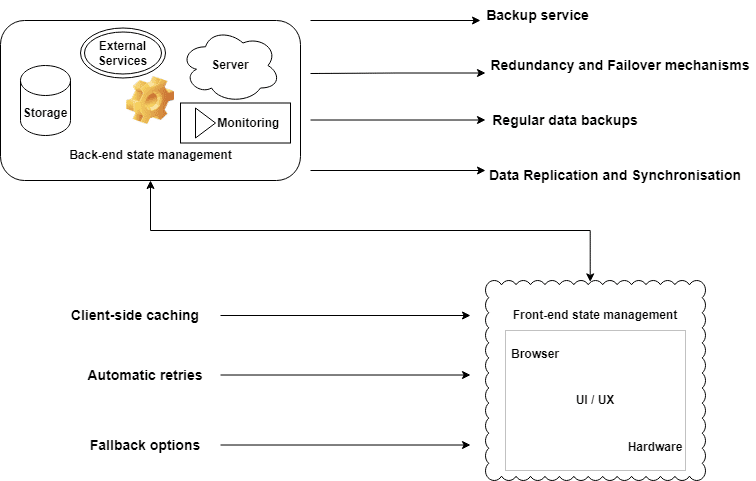
決済ゲートウェイに依存する電子商取引アプリケーションの復旧シナリオ中の状態管理を処理するために、災害復旧計画には以下を含める必要があります:
- フロントエンドの状態管理: フロントエンドの状態管理:アプリは、ユーザーが買い物を続けられるように、クライアントサイドのキャッシュ、自動再試行、フォールバックオプションを含むべきである。
- バックエンドの状態管理: 計画には、冗長性やフェイルオーバーの仕組み、定期的なデータバックアップ、複数拠点にまたがるデータ複製などのバックアップの仕組みを含める必要がある。
- バックアップ決済ゲートウェイの統合: 計画には、プライマリ決済ゲートウェイが利用できない場合でもアプリがトランザクションを処理し続けられるように、バックアップ決済ゲートウェイの統合を含めるべきである。
災害復旧時の分散システムのデータ管理要件
分散システムにおけるデータ管理は、特に多くのユーザーを抱えるeコマース・アプリケーションの場合、複雑になる可能性があります。障害発生時にデータが失われないよう、データの保存と管理を確実に行うことが不可欠です。重要なデータが失われると、金銭的な損失や会社の評判の低下など、多くの問題が発生する可能性があります。そのため、データの喪失、サービスの依存、マルウェアによる攻撃など、さまざまな種類の災害に備えたバックアップとリカバリの計画を立てることが非常に重要です。
✅ N2WS Backup & Recoveryには「リカバリシナリオ」と呼ばれる複数のAWSリソースをまとめてリスト化し、DRテストやリストアを行う機能が内蔵されており、このプロセスを簡単に行うことができます。
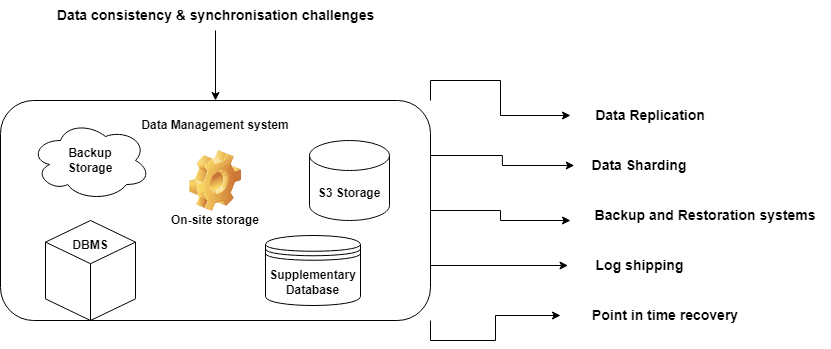
分散システムでデータを管理する際の大きな課題は、すべてを一貫性のある最新の状態に保つことです。複数の場所にデータを保存することは、更新がどこにでもコピーされるようにするために不可欠です。また、データが異なる時間に生成されたとしても、すべてのデータが同期されていることを確認することも重要です。
災害復旧時にデータを管理するには、複数の場所にデータを複製する、データをシャーディングする、定期的にバックアップするなど、さまざまな方法があります。これらの戦略は、重要なデータが利用可能な状態に保たれ、何か問題が発生した場合に迅速に復旧できるようにするのに役立ちます。綿密な計画を立て、適切な戦略を実施することで、当社のeコマース・プラットフォームのような分散型システムであっても、データの安全性を確保することが可能です。
運用パターンとしての不変(イミュータブル)・アーティファクト
アプリケーションにイミュータブル・アーティファクトを使用することで、ディザスタリカバリ・シナリオ時の耐障害性を高めることができます。イミュータブル・アーティファクトとは、アプリケーション・コード、コンフィギュレーション、依存関係の自己完結型の単位で、イミュータブルなエンティティとして作成され、バージョン管理されます。アーティファクトは一度構築されると、そのライフサイクルを通じて変更されません。つまり、アプリケーションに変更や更新を加えるには、既存のアーティファクトを修正するのではなく、新しいアーティファクトを作成する必要があります。
アプリケーションの一部が故障したり破損したりしても、迅速かつ安全に置き換えることができます。これは、1つの部分の障害がアプリケーション全体に影響を及ぼしかねない複雑なシステムでは特に重要です。
例えば、eコマース・アプリケーションに保存されているデータが破損したとする。イミュータブルなアーティファクトがあれば、事態を悪化させることなく、悪いデータを良いコピーに素早く置き換えることができます。これにより、ダウンタイムやデータ損失を少なくして、アプリケーションを再稼働させることができます。
イミュータブル・アーティファクトのもう1つの利点は、ランサムウェアのような攻撃からアプリケーションを守るのに役立つことだ。攻撃者がイミュータブル・コンポーネントを変更できなければ、それほど大きなダメージを与えることはできません。これは、アプリケーションをより安全に保ち、データ損失を防ぐのに役立ちます。
しかし、イミュータブル・アーティファクトを使うことには、いくつかの欠点があります。慎重にセットアップしなければならないし、変更があれば、影響を受ける部分を完全に再デプロイしなければなりません。これには時間がかかり、より複雑になる可能性があります。アプリケーションの機能によっては、定期的な更新が必要なものなど、イミュータブルとしてできないものもあります。
アプリケーションのディザスタリカバリのユースケースとシナリオ
1. データ損失 – 削除
データ損失は、複雑なアプリケーションにおいて壊滅的な打撃を与え、重大なビジネスの中断につながる可能性 があります。データ損失は、人為的ミス、システム障害、サイバー攻撃など様々な理由で発生します。データ損失から回復するためには、定期的なバックアップ、データの複製、異なる場所にあるデータの複数のコピーを含む災害復旧計画を実施する必要があります。
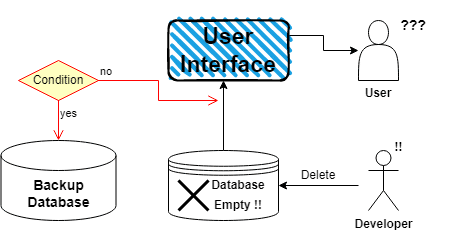
例えば、開発者がeコマース・アプリケーションのデータベースを誤って削除してしまったとします。このデータ損失から回復するために、開発者は以下のステップを踏むことができます:
- データ損失の範囲を特定する: どのデータが失われ、アプリケーションとユーザーにどのような影響を与えたかを特定する。
- バックアップから復元する: アプリケーションのバックアップを既に取っている場合は、削除が発生する前の時点に復元する。
- 復旧の検証: データベースの復元を検証し、必要なデータがすべて利用可能で、正しく機能していることを確認します。
- 復旧後の検証: アプリケーションの機能を検証し、すべてのシステムが正しく動作することを確認する。
データ損失からの復旧には、いくつかの潜在的なリスクと課題があります。これには、バックアップからのデータ復元に関連する時間とコスト、 復旧プロセス中のデータ破損、不完全なデータバックアップなどがあります。
✅ ヒント: N2WS Backup & Recoveryを使用して、EC2やRDSなどの主要アプリケーション(およびインフラストラクチャ設定)を1クリックでリカバリします。
2. 依存サービスの損失
依存サービス損失は、アプリケーションに重大な中断を引き起こし、収益損失につながる可能性があります。依存サービスの損失から回復するには、冗長システムと代替サービスプロバイダを含む災害復旧計画を実施する必要があります。
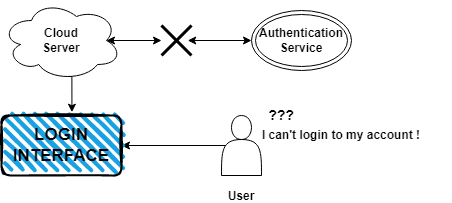
例えば、eコマース・アプリケーションがユーザーをログインさせるために使用している認証サービスが、長時間の停止に見舞われたとしよう。この依存的なサービス損失から回復するために、以下のステップを踏むことができます:
- サービス損失の範囲を特定する: どのサービスが利用できず、アプリケーションとユーザーにどのような影響があるかを特定する。
- バックアップサービスプロバイダに切り替える: バックアップ・サービス・プロバイダーが利用可能な場合は、アプリケーションとユーザーへの影響を最小限に抑えるために、バックアップ・サービス・プロバイダーに切り替える。
- サービス復旧の検証: バックアップ・サービス・プロバイダが正常に動作し、必要なサービスがすべてアプリケーションで利用できることを確認します。
- 復旧後の検証: アプリケーションの機能を検証し、すべてのシステムが正しく動作することを確認する。
依存するサービス損失から復旧する場合、バックアップサービスプロバイダへの切り替え、サービス停止によるデータの不完全性や欠落、切り替え中のデータ一貫性の問題など、いくつかの潜在的なリスクや課題があります。
✅ N2WS Backup & Recovery は、アプリケーション一貫性のあるEC2のバックアップをサポートしています。
3. マルウェア/ランサムウェア
マルウェアやランサムウェアの攻撃は、アプリケーションのデータ、機能、組織の評判に壊滅的な影響を与えます。これらの攻撃は、データやコードの侵害、データ損失、金銭的損失につながる可能性があります。
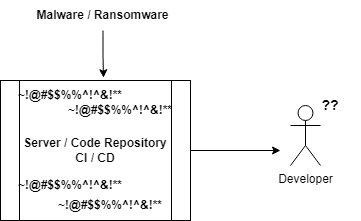
このような攻撃から復旧するためには、次のような手順を踏むとよい:
- 影響を受けるシステムを特定し、隔離する: 攻撃が検知されるとすぐに、ランサムウェア攻撃の最初のステップは、感染したシステムを特定し、感染のさらなる拡大を防ぐために、他のネットワークから隔離する。
- 被害を評価する: 次のステップは、データの損失や重要なシステムの侵害など、攻撃による被害の程度を評価することです。この評価により、復旧戦略を決定する。
- バックアップからの復元: バックアップがあれば、それを使ってシステムを以前の状態に復元することができます。データの完全性とシステムの機能性を確保するため、復旧プロセスを徹底的にテストする必要がる。
- 影響を受けたシステムを再構築する: バックアップが利用できない場合、またはデータが破損した場合は、影響を受けるシステムをゼロから再構築する必要があります。このプロセスには、オペレーティング・システム、アプリケーション、データをゼロから再構築することが含まれ、時間と困難が伴う。
- セキュリティ対策の改善: システムの復旧や再構築が完了したら、今後の攻撃を防ぐためにセキュリティ体制を改善することが不可欠です。これには、より優れたアクセス・コントロール、ネットワーク・セグメンテーション、侵入検知・防止システムの導入などが含まれる。
マルウェアやランサムウェア攻撃からの復旧に伴う潜在的なリスクや課題には、重要データの損失、システムのダウンタイム、金銭的損失、風評被害などがある。また、復旧プロセスには時間がかかり、リソースが集中し、専門的な知識が必要になることもあります。
こうしたリスクを軽減するためには、定期的なバックアップ、テスト、こうした攻撃を防ぐためのセキュリティ対策など、強固な災害復旧計画を策定することが不可欠です。関係者に状況と復旧状況を伝えるためには、明確なコミュニケーション・プランが不可欠です。
✅ ヒント: N2WS Backup & Recoveryを使用して、EC2やRDSなどの主要アプリケーションのバックアップを、不変(イミュータブル)な保存先に取得し、ランサムウェアなどの悪意ある攻撃からバックアップを守ることができます。
教訓
継続的なテストとモニタリングの重要性はいくら強調してもしすぎることはありません。定期的な災害復旧テストとモニタリングは、災害復旧計画が最新かつ適切で、効果的であることを保証する。また、計画のギャップや弱点を特定し、迅速に対処することができます。
プロアクティブアプローチを使用することで、アプリケーションはいかなる災害や停止からも迅速に回復することができ、ダウンタイムを最小限に抑え、ビジネスの継続性を維持することができます。分散システムと数百万人のユーザーを抱える複雑な電子商取引アプリケーションでは、継続的なテストと監視が、アプリケーションの信頼性と回復力を確保するために不可欠です。
ユースケースと全体的な災害復旧計画プロセスから得られた主な教訓は以下の通りです:
●データ損失 – 削除、依存サービス損失、マルウェア/ランサムウェア攻撃、その他の潜在的シナリオに備えること。
●アプリケーションの継続性を確保するために、フロントエンドおよびバックエンドシステムの状態管理を実施する。
●復旧シナリオ中の分散システムのデータ管理要件を実装する。
●運用パターンとして不変の成果物を使用し、アプリケーションの一貫性を確保し、ダウンタイムを最小限に抑える。
●特に複雑なアプリケーション環境では、冗長性と可用性を確保するために、成果物を複数の場所に保管する。
●継続的なテストとモニタリングは、ディザスタリカバリ計画の有効性を確保するために極めて重要である。
ユーザの目標は、これらの教訓をアプリケーションとビジネス要件に照らし合わせることです。アプリケーションには事欠きません。
アプリケーションの災害復旧:結論として
どのような組織やビジネスにおいても、複雑なアプリケーション、特に外部のソフトウェアに依存する分散システムを設計する際には、災害復旧計画を立てることが極めて重要です。災害には、データ損失、サービス損失、マルウェア攻撃などがあります。ビジネスの継続性を確保し、ダウンタイムを削減するために、ディザスタリカバリ計画は、状態管理、データ管理、および不変の成果物で構成されなければならない。また、これらの成果物を複数の場所に保管し、復旧計画を定期的にテスト・監視することも不可欠となります。
これらのベスト・プラクティスに従うことで、クラウド・アーキテクト、システム管理者、DevOps、IT管理者、その他の関係者は、あらゆる災害からの復旧能力に自信を持ち、ビジネスを円滑に継続させることができます。今日のデジタル環境では、災害復旧計画はオプションではなく、必須です。そして、N2WS Backup & Recoveryは、AWS上でアプリケーションを実行したり、重要なデータを保存したりするすべての人にとって必須です。
関連トピックス
- [Zerto]アプリケーション整合性のあるチェックポイント作成、PowerShell、REST APIコマンド紹介
- Veeam B&R v12+Kasten K10 v6でインスタントリカバリ、K8sアプリケーションを数分で復旧
- RDSサーバ上のアプリケーション追加手順[Accops]
- VeeamON 2022 セッション情報速報⑧
- バックアップとレプリケーションの動作の違いについて【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- Veeam Backup & Replication Ver4.1がリリースされました。【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- Restore -Failback機能 [Veeam Backup & Replication]
- アプリケーション(DBMoto)実行中にバックアップ【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- バックアップの復旧検証機能によるランサムウェア対策 [Veeam SureBackup]
- ホワイトペーパー: Kubernetesバックアップの5大ベストプラクティス (コンテナ ネイティブ環境のデータ管理ニーズに応える)







 RSSフィードを取得する
RSSフィードを取得する
