
前回のブログから引き続き、 Veeam Live 2020 で紹介されたVeeam Backup & Replication v11で搭載予定の新機能を紹介していきます。
※あくまでも実装予定機能となるため、場合によっては実装時期が延期されることがございます。
※2020/10/25現在の情報となります、最新情報については随時アップデートしていきます。
今回は、Linuxマシンのバックアップデータから、ファイルレベルでリストアする際のアーキテクチャがv11からどのように変わるのかご紹介します。
もともと、Veeamは物理Linuxマシン、vSphere/Hyper-V/Nutanix AHV上の仮想Linuxマシン、AWS/Azure上のLinux EC2インスタンスをバックアップすることができ、マシン単位、ボリューム単位、ファイル単位、アプリケーション単位でのリストアが提供されています。
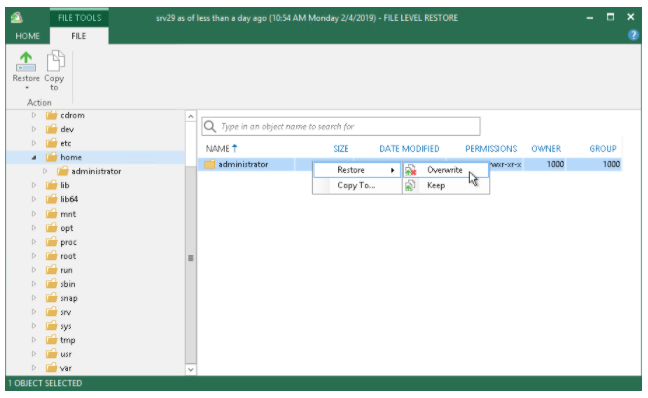
このファイルレベルでのリストアでは、Linuxマシンの場合でも下の画像にあるようにWindowsのエクスプローラーライクな画面から、元々ファイルが存在していたフォルダ/ファイルパスにOverride(上書き)してのリストア、Keep(元のファイルを残して)のリストア、またはCopy to(指定したサーバのパスへの)リストアができ、非常に使い勝手が良いものとなります。
このLinuxマシンのバックアップデータからファイルレベルでリストアを行う場合、Veeamではヘルパーアプライアンスと呼ばれる非常に小さいVMを仮想環境にデプロイし、バックアップデータを透過的に参照することで、多くのファイルシステムやダイナミックディスクなど複数ディスクで構成される場合でもリストアが可能となります。
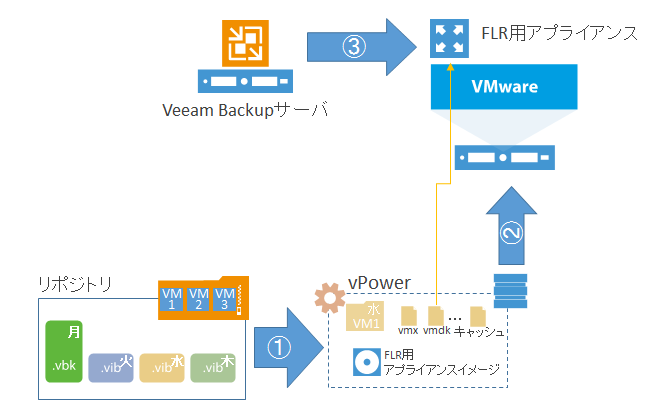
このヘルパーアプライアンスは非常に小さいマシン(1vCPU/1024MB RAM)となり、本番仮想環境へも影響を与えることなく、数秒~数分で立ち上がるものとなり、同技術はVeeamが特許を取得しているもので、どれだけ大きなマシンでも即時復旧が可能なインスタントVMリカバリでも使用されています。
ただ、これは言い換えればLinux OSからのファイルレベルリストア時には、ヘルパーアプライアンスを立てるために仮想環境へのアクセスは必須となり、ヘルパーアプライアンスの立ち上げにはハイパーバイザーの状態(例えば応答がない状態やデータストアのマウントが失敗するような状態など)に大きく依存し、また一時的にVMとして立ち上がるため、IPアドレス競合を防ぐためにフリーなIPアドレスの用意が必要となっておりました。
更には物理Linuxマシンのみ運用しているケースで万が一仮想環境がない場合には、手動でVeeamエージェントのコンソールからバックアップデータをマウント、対象のファイルを見つけてcpコマンドからコピー操作を実施しなくてはならないなど、いくつか制約がありました。
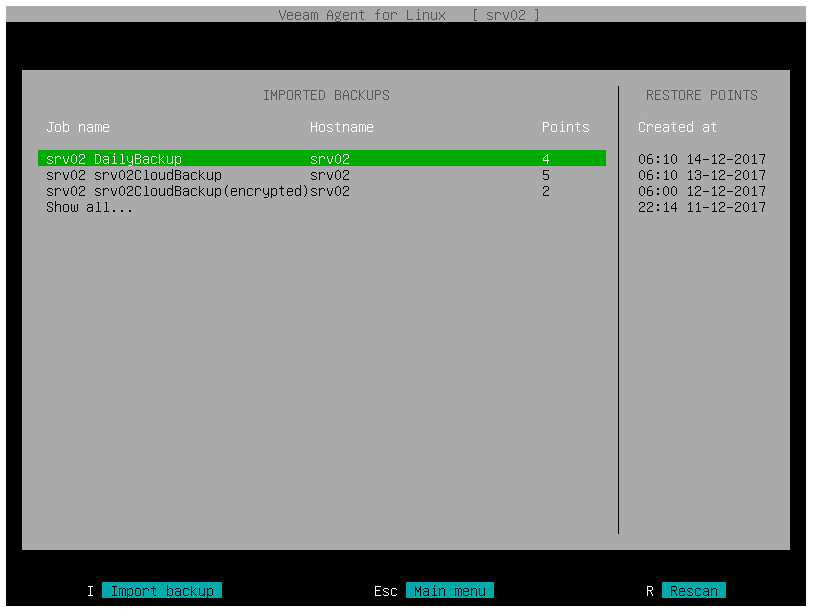
これがv11からは、これまでのヘルパーアプライアンスを利用したファイルレベルリストアも勿論実装されておりますが、Veeamに登録されたLinuxサーバを指定してバックアップデータをマウントすることで、仮想環境へのアクセスおよびヘルパーアプライアンス作成を行うことなく、既存のLinuxマシンリソースを活用してリストア操作を行うことができるようになる予定です。

そして、Linuxサーバへのマウントがサポートされたことによって、Veeamのデータ統合APIによるバックアップデータを本番VMへリストアすることなく、データを参照しデータマイニングやデータフォレンジックに活用する際にも、仮想環境へのアクセス(一時的なVM作成)なく実現できるようになる予定です。

関連トピックス
- Linux系OSのファイルの権限、Owner、Groupを保持したファイルレベルリストア【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- ファイルレベルリストアでサポートしているファイルシステム【Veeam Backup & Replication】
- Linuxサーバーへの接続について【VMWare専用 バックアップ & レプリケーションソフト Veeam】
- Veeam Backup & Replication v11新機能予定:Linuxプロキシサーバの機能改善
- Linux VMのファイルインデックスとVSSのプレテスト【Veeam B&R Ver8新機能予告⑨】
- Linux版 ZVM (ZVM on Linux)を構築してみました [Zerto Virtual Replication]
- 認証情報の登録いらず!証明書ベースでLinux物理マシンのバックアップを取る方法[Veeam Backup & Replication]
- 【Veeam Backup for AWS 3.0新機能】ファイルレベルリストアの対応強化
- Veeam Backup & Replicationで取得した物理マシンの全体リストアのながれ
- Ver9.5 新機能予告 バックアップファイルからAzure VMとしてリストア [Veeam Backup & Replication]








 RSSフィードを取得する
RSSフィードを取得する
