マイクロソフトTeams バックアップ
Microsoft Teamsのバックアップに関する3つ目のベストプラクティスは、作業に適したツールを使用していることを確認することです。Microsoft 365のエコシステムの中には、保持ポリシーや、バックアップの実行を支援する機能などがあります。
保持ポリシーと訴訟ホールドは擬似的なバックアップとして機能することができます。しかし、これらのツールは、データ保護ではなく、コンプライアンス目的のために存在します。そのため、Microsoft Teamsのデータを適切に保護することはできません。
データ保持ポリシーと訴訟ホールドは、データの保護方法に関して矛盾やカバーギャップを生じさせる可能性があります。Microsoft Teamsのすべてのデータを確実に保護する唯一の方法とは、以下のとおりです。Microsoft 365を保護するために特別に設計された専用のバックアップアプリケーションを使用することで、ビジネス要件と法的義務に一致した方法で保護することができます。
マイクロソフトTeams バックアップ
Office 365は、非常に多くの異なるMicrosoft 365コンポーネントを活用しているため、バックアップが最も困難なアプリケーションです。Exchange OnlineやSharePoint Onlineなどのアプリケーションとは異なり、Teamsは、すべてのデータを1つの場所に保存していません。その代わり、Microsoft Teamsのデータは異なるMicrosoft 365アプリケーションを使用されています。Microsoft 365のバックアップアプリケーションであれば、Teamsのデータをバックアップできるはずですが、アプリケーションがMicrosoft Teamsをサポートするように特別に設計されていない限り、復元プロセスが非常に困難になる可能性があります。
MicrosoftはTeamsのバックアップのためのAPIを提供していますが、このAPIは最近リリースされたばかりです。そのため現時点では、すべてのバックアップベンダーがTeamsバックアップAPIを製品に組み込んでいるわけではありません。
いずれは主要ななバックアップソリューションがMicrosoft Teamsをネイティブにサポートするようになると思われますが、当面はバックアップ製品に現在そのようなサポートを含んでいるかどうかを確認することが重要です。
マイクロソフトTeams バックアップ
Microsoft Teamsのバックアップに関する最良の方法は、Microsoft Teams(およびその他のMicrosoft 365アプリ)を実際にバックアップしていることを確認することです。
Microsoftは、Teamsとその他のMicrosoft 365アプリケーションに責任共有モデルを採用しています。この責任共有モデルは、基本的に Microsoft 365 アプリケーションと基盤となるインフラストラクチャを健全に保つ責任は Microsoft にあるが、Microsoft 365 の加入者は以下の責任を負うというものです。自分のデータを安全に保護する責任があります。このデータ保護責任には、データのバックアップを確認することも含まれます。
AWSスナップショット
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
AWSスナップショット
単一のAWSアカウントと比較的少数のリソースを持つユーザーにとって、バックアップの自動化と一貫したポリシーの適用は簡単なプロセスです。しかし、複数の地域に多数のAWSアカウントを持つユーザーにとって、バックアップを監視しながらすべてのアカウントで一貫したデータ保護を実施することは、非常に困難でコストがかかる可能性があります。Kubernetesのようなアプリケーションでは、ITチームはより洗練されたデータ保護メカニズムを必要とし、スナップショットだけに頼っていては復旧目標を達成できないかもしれないので、問題はさらに複雑になります。
さらに、すべてのバックアップが異なる地域の異なるアカウントにコピーされることを保証する問題もあります。地域間で何千ものバックアップを移行するのは非常に高価であり、一般的なエグレス・チャージよりは低いものの、AWSは地域間のデータコピーに課金することになります。最後に、AWSのスナップショットはストレージ効率が良いが、長期間保存するとかなりコストがかかる可能性があります。
AWSスナップショット
効果的なバックアップとリカバリのシステムは、バックアップの古典的な3-2-1ルールに従っています – データのコピーを少なくとも3つ、少なくとも2つの異なるタイプのメディアに保存し、そのうち1つはオフサイトに保存します。
2つの異なるストレージシステムにデータを保存することは、プライマリシステムがダウンした場合にコピーが破損しないようにするためのリスク管理戦術です。このため、常に別のバックアップシステムを持ち、プライマリとバックアップの両方に同じストレージを使用しないようにします。スナップショットを作成した時点で、データのコピーを別のシステムに保存していることになるので、このルールの一部はAWSスナップショットを使用して簡単に遵守することができます。
少なくとも1つのバックアップコピーをオフサイトに保存することが、厄介な部分です。AWSスナップショットを別のリージョンにコピーすることは可能ですが、自動化するのは難しく、コストもかかります。あるリージョンから別のリージョンにデータをコピーすると、イグレスチャージが発生し、コストのかかる不要なコピーが作成されます。また、この概念をすべてのAWSアカウントに一貫して適用し、一元的な管理とレポーティングを維持することは困難です。
AWSスナップショット
AWSスナップショットとは、EC2インスタンスやEBSボリュームなどのリソースのイメージコピーで、AWSアカウント内のオブジェクトストレージに保存される。フルまたはベースラインスナップショットは、保護されたリソースの単一時点からの同一コピーである。最初のスナップショットが作成されると、それ以降の増分スナップショットには、最後のスナップショットが取得された後に変更されたすべてのブロックが含まれるようになります。
AWSスナップショットは完全なコピーであるため、破損または削除されたリソースを復元するために使用することができ、一般的にプライマリコピーが破損した場合、ITが最初に検索するものです。例えば、EC2インスタンスやEBSボリュームが破損しても、スナップショットには影響しないので、チームは簡単に復旧することができます。
これは、AWSスナップショットがバックアップのための理想的なデータソースであることを意味します 。 それは、異なるシステムに格納されているデータの独立したコピーを提供します。そらは、AWSで損傷したリソースを回復するための最も簡単で迅速な方法であり、シンプルでスピーディな災害復旧のための素晴らしいリソースを示しています。
<<続き>>
https://www.climb.co.jp/faq/faq-category/aws-snapshot
クライムAWSソリューション群
AWSコスト
AWSのコスト最適化モデルを最大限に活用するために適切な計画を立てるヒントなどを特集しています。
https://www.climb.co.jp/faq/faq-category/aws-cost
AWSコスト
EC2サービスは、おそらくAWSでのクラウドの旅で最初に選ぶものの1つだろう。60以上のインスタンスタイプがあり、最適なものを選ぶのは至難の業です。まずは、インスタンスの目的を考えてみてください。それを元に、以下のリストを見て最適なタイプを絞り込むことができます。
使用ケース |汎用機、計算、ストレージ、ネットワークでバランスが取れている必要がある
例 | Apache、NGINX、Kubernetes、Docker、VDI、開発環境など。
好ましいインスタンスタイプ|T3
使用ケース |高性能CPUの恩恵を受けるコンピュートバインドアプリケーション
例 | 高性能ウェブサーバー、拡張性の高いマルチプレイヤーゲーム、動画エンコーディングなど
好ましいインスタンスタイプ|C4、C5
使用ケース |大容量のデータセットをメモリ上で処理するアプリケーション
例 | 高性能データベース(SAP HANAなど)、ビッグデータ処理エンジン(Apache SparkやPrestoなど)、ハイパフォーマンス・コンピューティング(HPC)など
好ましいインスタンスタイプ|X1およびR5
使用ケース |浮動小数点数の計算、集中的なグラフィックス処理、またはデータのパターンマッチング
例 | 機械学習/深層学習アプリケーション、計算金融、音声認識、自律走行車、または創薬
好ましいインスタンスタイプ|G4、F1、P3
使用ケース |大量のシーケンシャルリード/ライト操作、または大規模なデータセットの処理
例 | NoSQLデータベース(例:Cassandra、MongoDB、Redis)、スケールアウト・トランザクション・データベース、データウェアハウス
好ましいインスタンスタイプ|D2とi3
ライトサイジングとは、性能要件を満たした上で、最も安価なオプションを選択することであることを忘れないでください。経験則では、長期間にわたってインスタンスのリソース使用率が80%になるようにすることです。
AWSコスト
パブリッククラウドの柔軟性とCAPEXからOPEXへの移行について紹介しますが、請求書を減らすAWSの機能であるリザーブドインスタンス(RI)と節約プランのいくつかは、皮肉にもCAPEXに戻るように見えます。しかし、実際に50%以上の割引が得られるのですから、誰もが「導入のベストプラクティス」リストに挙げるべきものでしょう。
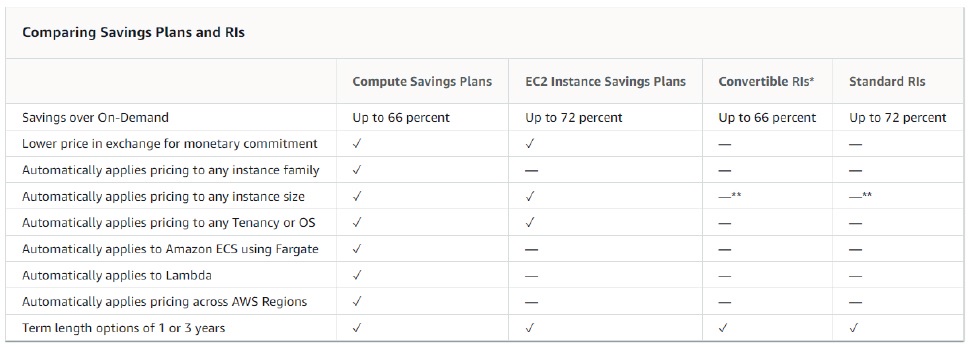
RIは、EC2インスタンスの時間単位の割引料金とオプションの容量予約を提供するもので、まずRIを検討することから始めます。1年または3年のコミットメントと引き換えに、インスタンスコストの割引を受けることができます。オンデマンドインスタンスは、無制限の柔軟性でワークロードをプロビジョニングしたい人には良い選択肢です。しかし、負荷が予測可能なワークロード(Webサービスなど)を常時稼働させる場合は、RIの方がはるかに優れています。
AWSコスト
AWSは、パフォーマンス、可用性、耐久性の要件を満たすように設計された複数のストレージ階層を、異なる価格で提供しています。提供されるストレージサービスは、大きく3つに分類されます。オブジェクトストレージ、ブロックストレージ、ファイルストレージです。Amazonが提供するオブジェクトストレージ、Simple Storage Service(S3)は、3つのストレージカテゴリの中で最もコスト効率が高いです。Amazon S3内では、さらに先のストレージクラス間でデータを簡単に移動させ、アクセス頻度と価格のバランスを取りながら、ストレージコストを最適化することができます。すべてのストレージタイプで利用シーンが異なり、その価格設定も様々です。
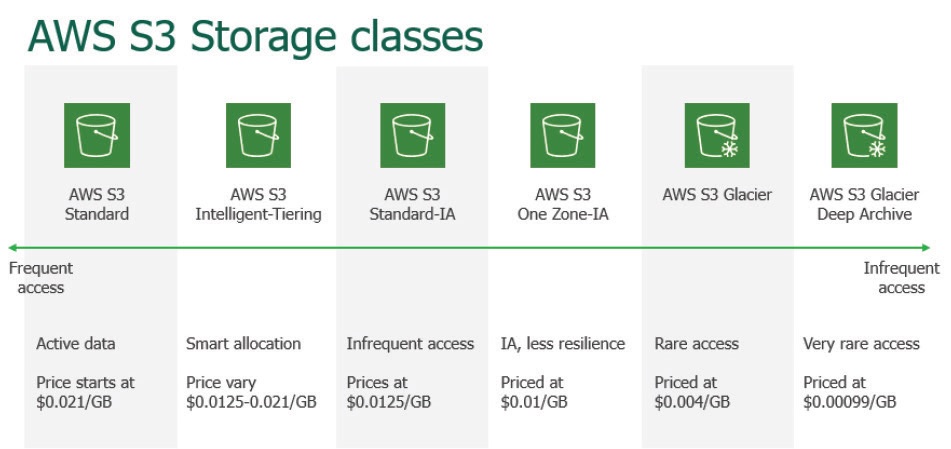
AWS S3ストレージクラス部分比較
ここでの賢い方法は、タスクの種類、オブジェクトの性質、アクセス頻度に応じて、それらを組み合わせることです。目的のS3バケットをクリックし、「管理」→「分析」を選択し、「ストレージクラス分析」を追加すると、アクセスパターンを確認するのに便利です。One Zone-IAやS3 Glacierへの移行を推奨するものではありませんが、データをより深く可視化することができます。
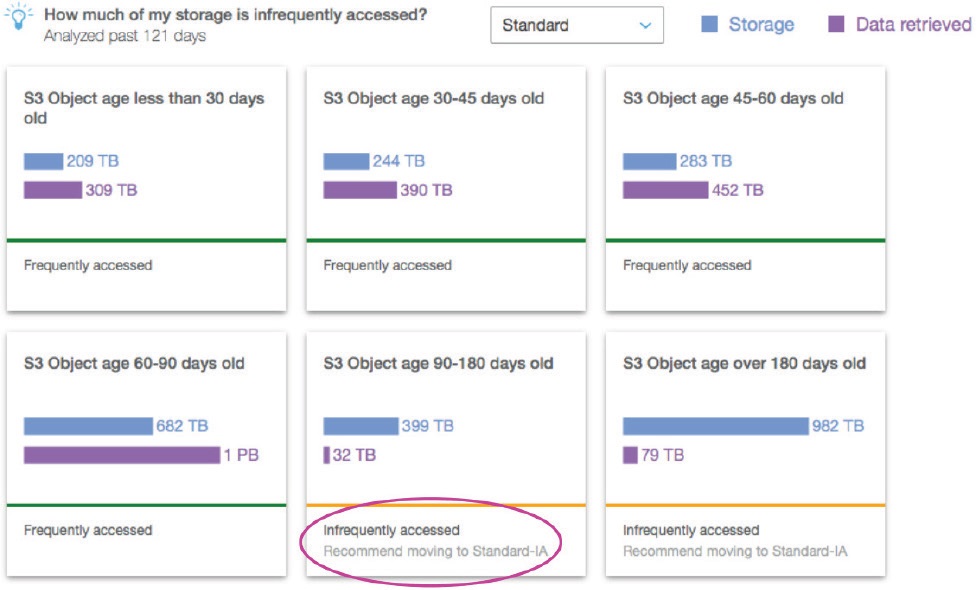
S3 バケット・ストレージ・クラス分析
新規者についてもしっかり検討しましょう。S3 Intelligent Tiering。少額の追加料金で、アマゾンは自動的にアクセスデータのパターンを検出し、オブジェクトの人気度に応じて、標準的なアクセスと不定期なアクセスの2つの層の間でそれらを移動させます。人気のないオブジェクト(連続30日間アクセスされていないもの)は、アクセス頻度の低い階層に移動され、要求があれば後で戻されます。この仕組みでは検索料がかからないため、オブジェクトは永遠に行き来することができます。実際のシナリオでは、20%の節約になります。このような監視のための費用を支払うことで、理論上は部分的に低くなりますが、それでも見逃すにはあまりに魅力的だからです。S3 APIまたはCLIを使用してストレージクラス “INTELLIGENT_TIERING “を指定するか、ライフサイクルルールを設定することでこの技術を有効にすることができます。
しかし、これはすべてに有効なわけではないです。128KB未満のオブジェクトは、インフリークエントアクセス層に移行されることがないため、フリークエントアクセス層の通常料金で課金されることになります。また、30日未満のオブジェクトは、最低30日間課金されるため、この方法は使えません。
AWSコスト
ライフサイクルポリシーといえば、AWS S3を使って運用する際には必ず必要なものです。とはいえ、ライフサイクルポリシーを実装するには、インフラ上で有効にする前に、ある程度の学習とドキュメントを読むことが必要です。
ポリシーは、使用パターンが明確に定義されたオブジェクトに対するルールの組み合わせなので、以下のことが可能です。
●ライフサイクル・ルールを使用して、オブジェクトをそのライフタイムを通じて管理する。
●階層型ストレージへの移行を自動化し、コスト削減を図る
●保管の必要性やサービスレベルアグリーメント(SLA)に基づき、オブジェクトを失効させる。
これは、適切に設定すれば非常に強力なツールです。S3ストレージクラスの違いを学び、より組織のニーズに合うようにライフサイクル・ルールに慣れることです。
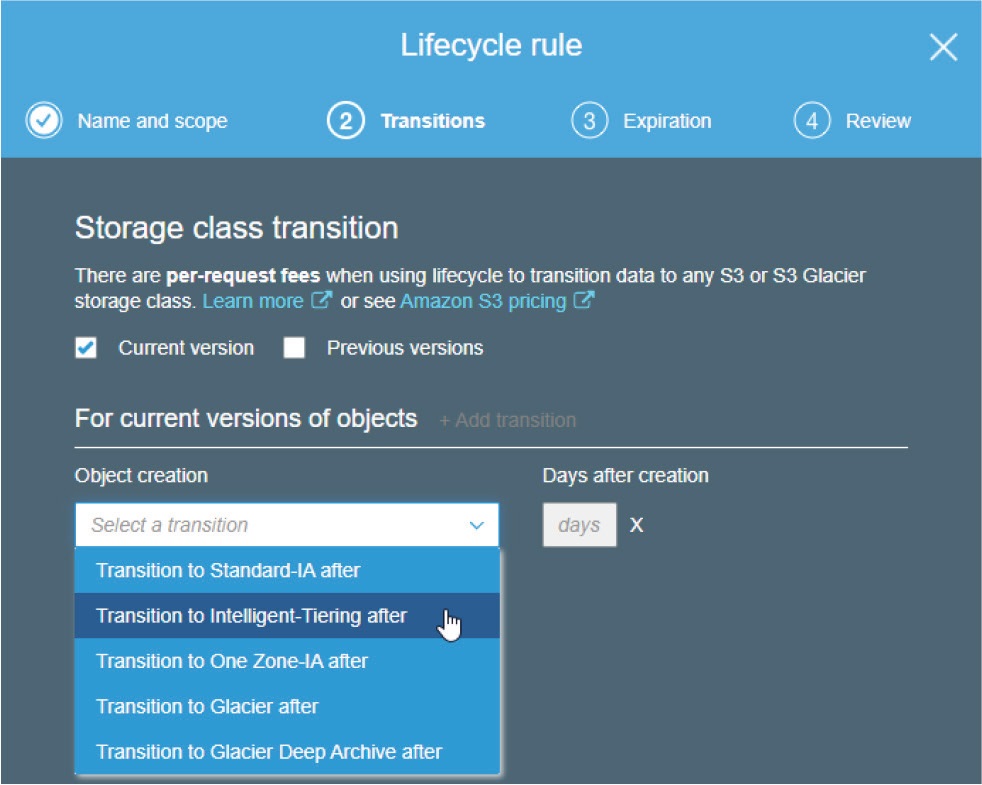
ライフサイクルルールの作成
AWSコスト
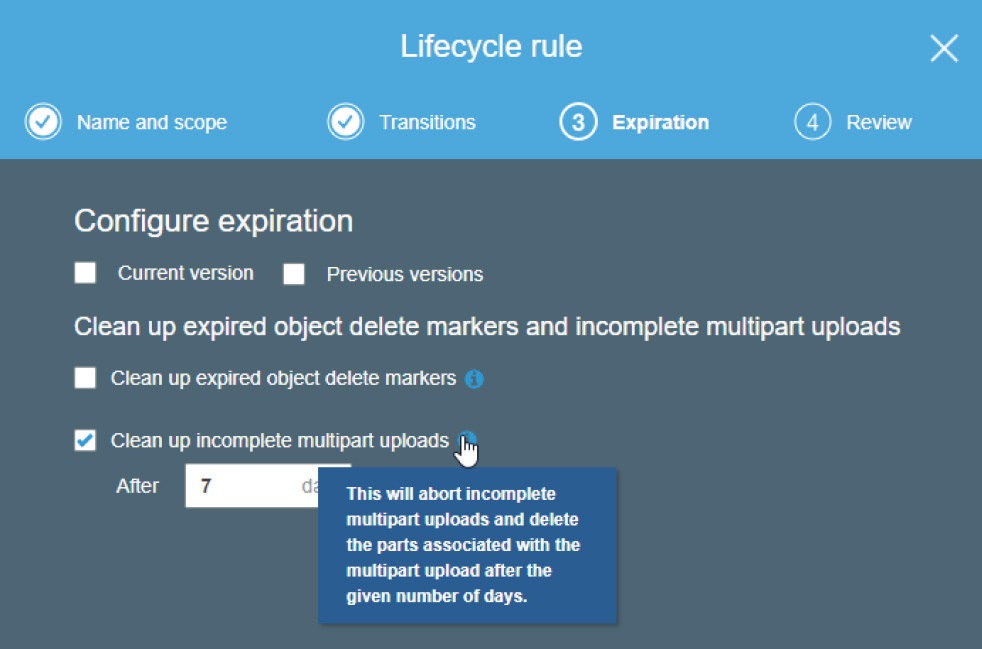
S3のマルチパートアップロード機能は、デフォルトで有効になっており、大きなオブジェクトを論理的な部分に分割して並行してアップロードすることで、アップロードを高速化します。問題は、これらのアップロードが何らかの理由で終わらない場合です。アップロードが完了しないデータはバケットに表示されず、自動的に削除されることもないので、毎月の請求額が大きくなる場合を除いては、特に気にする必要はないでしょう。これを防ぐには、「バケット管理」の設定で、新しいライフサイクルルールを作成し、「不完全なマルチパートのアップロードをクリーンアップする」オプションを有効にしてください。
AWSコスト
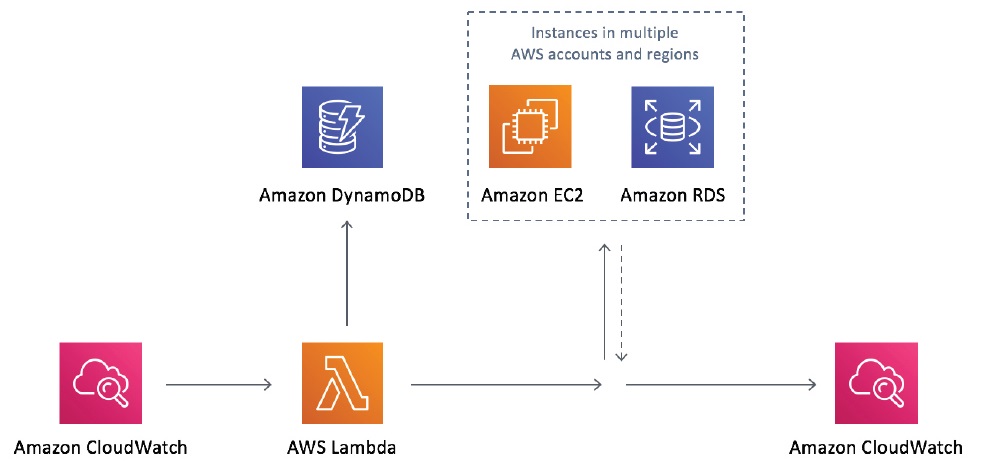
アイドル状態のリソースは、AWSの請求書の大きなコスト要因になり得ます。未使用のインスタンスやデータベースをアイドル状態にしておくことは、使用されていないものに対して料金を発生させることを意味します。例えば、平日の日中しかアクセスしない開発環境がある場合、24時間365日稼働させないことが最良の選択です。夜間に停止し、翌朝と週明けに起動する(ヒント:Auto Instance Schedulerを参照)ことで、コストをほぼ半分に抑えることができます。また、Amazon CloudWatchのアラームを有効にして、指定期間以上アイドル状態だったインスタンスを自動的に停止または終了させるのも良い戦略です。
 Amazon CloudWatch diagram
Amazon CloudWatch diagram
AWSコスト
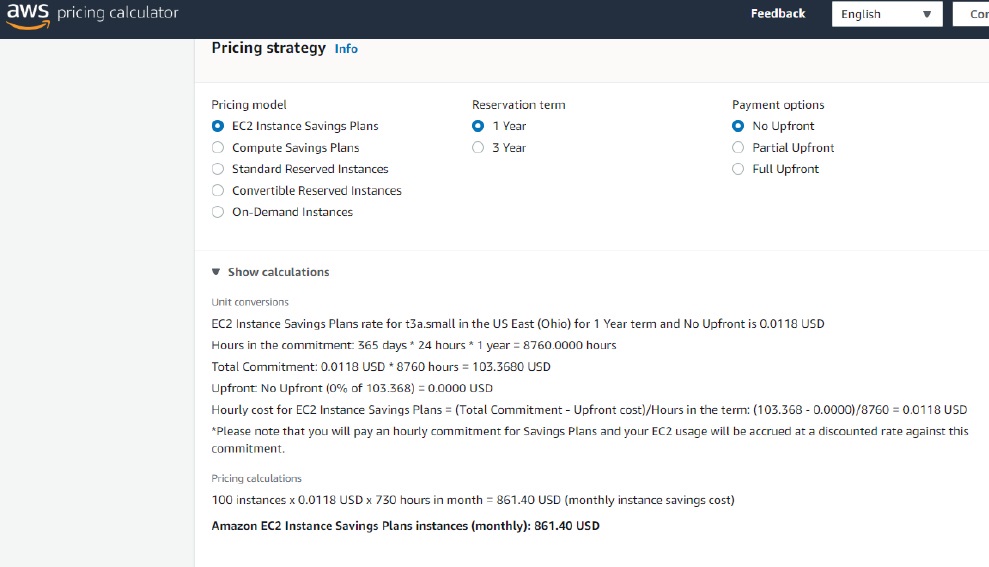
AWS Pricing Calculatorは40以上のAWSサービスに対するアカウント支出を見積もることができるツールです。しかし、時には他の競争戦略を決定するのに非常に役立つことがあります。例えば、オンデマンドEC2インスタンスからRIやSavings Planのオファリングに切り替える場合、各機能が提供する割引を確認することができる。表に値が追加されるたびに、結果的に計算が表示され、実際のサービスを選択するのに役立ちます。
AWSコスト
AWS Cost Explorerは、すべてのお金がどこに行くのかを可視化し、最も消費されるサービスに対応することが非常に簡単にできるため、あなたの頼りになるはずです。これは、実施された分析に基づいて、興味深いパターンを特定し、根本的な原因まで掘り下げることができます。
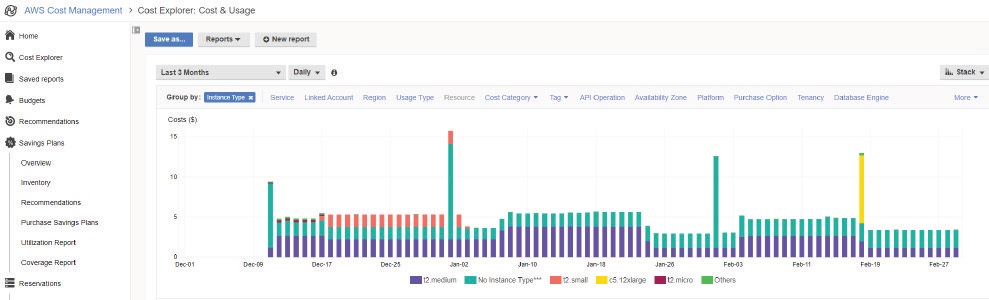
コストエクスプローラー インスタンスタイプの消費を表示
AWS Compute Optimizerは、アカウント(またはマスター1つ下のすべてのアカウント)に対して収集され分析されたデータに基づいて、AWSリソースの最適化の機会の概要を提供します。

AWS Compute Optimizer:EC2インスタンスに対する推奨事項。
AWSコスト
組織内で複数の人がAWSを操作する必要がある場合、統合課金によって支払いが簡単になるだけでなく、ある閾値に達すると、S3などの消費リソースを割引くことができます。また、AWSのティアによっては、使用量が多いほど価格が下がったり、事前にインスタンスを購入することで割引が適用されたりするものもあります(上記のRIやSaving Plansのようなもの)。さらに、未使用のリソースは、ある子アカウントから別の子アカウントに再配布することができます。ここで先に述べたコスト最適化ツールを適用し、多数のアカウントを運用する際の組織の混乱を防いでください。
AWSコスト
AWSのネットワークは独自のものですが、物事をシンプルに保つために、あまり深入りせず、とにかくここでいくつかの重要なヒントに触れます。
1)オンプレミスサイトとAWSの間で大量のトラフィックがやり取りされる場合、Direct Connection機能を使えば、より安定したネットワーク体験、帯域スループットの向上、接続の安全性を確保することができます。
2)静的コンテンツ(画像、動画、音楽など)は、S3とCloudFrontの組み合わせでより良く、より安価に配信することができます。世界の様々な地域にある素晴らしいエッジサーバーのセットで、エンドユーザーはより近い場所にあるサービスキャッシュから来るデータを得ることができます。
3)異なるAWSサービス間のトラフィックフローを分析する。VPCからS3のような他のサービスへのトラフィックがエンドポイントを経由するようにVPCエンドポイントを構成することで、インターネットや公共ネットワークをバイパスし、より安全で安価な接続を実現します。
4)可用性ゾーン間のトラフィックについても、別の費用がかかるので、忘れないようにしましょう。フォールトトレランス・アーキテクチャを再考してください。すべてのサービスに必要でない場合もありますし、他の技術で実現できる場合もあります。
Azureバックアップ
災害がどのような規模で発生し、どのようなシステムに影響が及ぶかを予測することは不可能です。そのため、バックアップソリューションでは、データを異なるシステムやクラウドにリストアできることを確認することが重要です。また、精度の高いリストアが可能であることも重要です。例えば、仮想マシンの場合、仮想マシン全体をリストアできる必要がありますが、仮想マシン内の1つのファイルも同様に簡単にリストアできる必要があります。
Azureバックアップ
バックアップソリューションが複雑でなければないほど、必要なときに動作する可能性が高くなります。複雑すぎるバックアップソリューションは、ヒューマンエラー、誤った設定、パッチのリリースに伴う互換性の問題が発生しやすくなります。そのため、シンプルな管理インターフェイスを持つだけでなく、エージェントを必要とせず、実際のデータ保護プロセスを簡素化するソリューションを探すとよいでしょう。つまり、管理者が新しいワークロードごとに手動でエージェントを展開したり、自動化スクリプトを書いたりする必要がなく、あらゆる規模の環境に対して拡張できるソリューションを探すということです。
Azureバックアップ
現在、多くの企業が複数のバックアップ製品を使用しています。オンプレミスのリソースを保護するために1つのバックアップツールを使用し、Azureにあるリソースを保護するために別のツールを使用している場合があります。可能であれば、バックアップ操作を1つのバックアップツールに統合するのがベストです。これにより、バックアップのサイロ化を解消し、クラウドと自社データセンター間でシームレスにデータを移動させることができます。同時に、単一のバックアップソリューションを使用することで、バックアップオペレーションを大幅に簡素化し、ライセンスコストを削減し、組織のデータ保護戦略におけるギャップの可能性を低減することができます。
Azureバックアップ
クラウドバックアップの設置場所は重要です。ハイブリッド/マルチクラウドのサポートに関するビジネス要件は増加傾向にあり、特定のクラウドベンダーの選択と離脱の両方に関して、柔軟性が重視されています。
そのため、共通のコントロールペインとポータブルなバックアップフォーマットが可能なバックアップソリューションが必要とされています。これにより、異なるプラットフォーム間でデータを移動することが容易になります(オンプレミスからクラウドへ。クラウドからオンプレミスへ、クラウドから別のクラウドへ)、プラットフォームのロックインを回避することができます。
Azureバックアップ
バックアップを保護するために組織ができる最も重要なことの1つは、バックアップをオンラインで維持しないことです。ランサムウェアの亜種は、特にバックアップサーバーをターゲットに設計されているため、被害者は身代金を支払う以外に選択肢がありません。以前は、テープは、空隙のあるバックアップを作成したい組織にとって、最適なメカニズムでした。バックアップが作成されると、テープはテープドライブから取り外されるだけでよかったのです。しかし、クラウドバックアップの場合、テープという選択肢はありません。Azureのアーカイブ層はオフラインに保たれ、レイテンシは2時間です。また、クラウドストレージへのアクセスは、多要素認証を使用したアカウントに限定することもできます。これにより、犯罪者が漏れたパスワードや総当たりパスワード攻撃でバックアップにアクセスすることを防ぐことができます。
Azureバックアップ
Azureのバックアップストレージのオプションを評価するとき、必然的にストレージ階層を選択する必要があります。利用可能な階層は、コスト、可用性、およびパフォーマンスに関してかなり異なっています。パフォーマンスの高いストレージ層は、一般的にコストが高くなります。
バックアップの保存期間によっては、ギガバイトあたりのコストが最も低い階層が、必ずしも全体のコストを低く抑えられるとは限らないことに留意する必要があります。これは、Cool Tier の最低データ保存期間が 30 日間であるのに対し、Archive Tier の最低保存期間が 180 日間であるためです。つまり、これらの階層にデータを保存する場合、実際にはそれほど長期間バックアップを保持する必要がない場合でも、少なくとも最低期間データを保存するために費用を支払うことになります。



