

動的なWebチャートを作成・配信するJavaツール
EspressChart -導入・製品
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
EspressReport と Java EEとの連携について
EspressReport は、Java EE (Enterprise Edition) の標準技術に基づいて構築されたレポートツールであるため、Java EE アプリケーションサーバー環境との連携は完全に可能です。EspressReport は Java エコシステムと密接に連携しているため、Java EE/Jakarta EE 環境での利用は設計上の前提となっています。
☕ EspressReport と Java EE の連携方法
EspressReport を Java EE 環境で利用する際の主なポイントと連携方法は以下の通りです。
1. アプリケーションサーバーへのデプロイ
EspressReport のサーバーコンポーネントである EspressReport ES (Enterprise Server) は、標準的な Java EE の Web アプリケーションとして提供されます。
- デプロイメント: EspressReport ES の WAR (Web Application Archive) ファイルを、Java EE に準拠したアプリケーションサーバー(例: Apache Tomcat、Oracle WebLogic、IBM WebSphere、JBoss/WildFly、GlassFish など)にデプロイします。
- 動作環境: Java EE の標準仕様(Servlet、JSP、JNDI、JDBCなど)を利用して動作します。
2. Java EE アプリケーションからの利用
Java EE 環境で開発された独自のアプリケーションから EspressReport の機能を利用する方法はいくつかあります。
- Web サービス/API 連携:
- RESTful API: EspressReport ES は、外部アプリケーションからレポートの実行、パラメータの受け渡し、出力形式の指定などを行うための RESTful API を提供しています。Java EE アプリケーションはこの API を HTTP 経由で呼び出すことで連携します。
- Java API: 直接 EspressReport の Java API を利用し、Java EE アプリケーションのビジネスロジック内でレポート生成を組み込むことも可能です。
- JDBC 連携:
- EspressReport は、JDBC (Java Database Connectivity) を通じて、Java EE アプリケーションと同じデータソース(データベース)にアクセスし、レポートのデータを取得します。Java EE の標準機能である JNDI を通じてデータソースを設定することも可能です。
- 認証・認可:
- Java EE のセキュリティ機能や、LDAP/Active Directory と連携させることで、EspressReport のユーザー認証やアクセス制御を Java EE 環境と統合できます。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
EspressChart -ライセンス
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが2CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
EspressChart -購入サポート
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
EspressChart -評価
Y軸を無視してただの文字項目として扱うことは可能ですか?
To make just the y-axis disappear while keeping the axis labels:
QbChart chart = new QbChart(…..);
chart.gethYAxis().setVisible(false);
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
EspressChart -機能
Java/Jakarta EE仕様に準拠した企業向けアプリケーションサーバにはどのような製品がありますか?
Java/Jakarta EE仕様に準拠した企業向けアプリケーションサーバーは多数存在します。これらの製品は、それぞれ異なる出自や特徴を持ち、企業の多様なニーズ(コスト、サポート体制、クラウド親和性など)に対応しています。
これらのアプリケーション・サーバは、Webコンテナ機能(サーブレット、JSPなど)を提供し、クライアント(Webブラウザ)からのリクエストに応じてEspressChart/Reportの機能(データベース接続、グラフ生成、Webへの配信)を実行します。
| 製品名 | 提供元 | 特徴 |
| JBoss Enterprise Application Platform (JBoss EAP) | Red Hat (IBM傘下) |
オープンソースのWildFlyをベースにした商用版。長期サポートとサブスクリプションが提供され、エンタープライズLinux環境との親和性が高い。
|
| Oracle WebLogic Server | Oracle |
非常に長い歴史を持つ、世界をリードする商用Java EEサーバーの一つ。特にOracle製品群(データベースなど)との連携が強力で、大規模金融システムなどに採用例が多い。
|
| IBM WebSphere Application Server (WAS) | IBM |
伝統的な企業システムで広く使われる商用サーバー。近年は軽量なクラウドネイティブ版のWebSphere Libertyに力を入れており、PayaraやOpen Libertyの競合となっています。
|
| FUJITSU Software Interstage Application Server | 富士通 |
国内で多くの実績を持つ、日本の企業システムに特化したアプリケーションサーバー。近年はFUJITSU Software Enterprise Application PlatformとしてJakarta EE対応を進めている。
|
| WebOTX Application Server | NEC |
NECが提供する、日本の商習慣やミッションクリティカルな要件に対応したアプリケーションサーバー。
|
EspressChartでのバージョン確認方法
EspressChartのバージョン、リビジョン番号の確認方法について:
APIコードに以下の行を追加してください。
System.out.println(QbChart.getVersion());
AS/400でのX-Serverを購入後の EspressChart のセットアップ方法:
[質問]
カード購入後、セットアップが必要となると思いますが、 PCサーバカードをAS/400に組み込んだ後どうすればよいのでしょうか?
AS/400上の設定は行ったとしてそれだけでよいのでしょうか?
PCサーバ上にWebsphereを入れて、その上にEspressChartを入れて、とかという作業が 必要になりませんか?
[回答]
IBM AIX機械については、X-Server起動後
(WebSphere起動後かもしれません)
管理者としてログインしてください。
その後
export DISPLAY=IP_address:0.0
のコマンドを打ってください。
ディスプレイ環境変数の設定が必要になります。
チャートビューアでSQL文書を可変に
[質問]
> 現在、弊社にてEspressChartApiを利用して2次元のコンビネーショングラフを
表示させております。
> しかし、メンテナンスを考えるとチャートビューアを利用したく考えております。
> 弊社で、チャートビューアを使用したテストが正常に作動しました。
>
> このchtファイルにはデータ取得用のSQLがかかれておりますが、このSQLを可変にするこ
> とはできるのでしょうか?
> また、その場合にはどのようにすればよいのでしょうか?
—————————————————————-
[回答]
を以下のように変更願います
chtファイルは図表データを含んでいます。
しかし、tplはデータを含んでおらず、それがhtmlページに開かれるごとに、
データ・ベースから新しいデータを検索します。
espresschart¥ヘルプ¥マニュアル¥Chp_5.htmlでは、
それがさらにクエリーをそれ自身変更するためにコードを持っています。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
使用できるフォントを教えてください。
一般的なJavaアプリケーション同様に、オペレーティングシステムに登録されたフォントを使用することができます。
チャートをどのような形式で出力できますか?
EspressChart専用のチャート形式(CHT)、テンプレート形式(TPL)
一般的な画像形式(BMP・GIF・JPG・PNG)、PDF形式
チャートからデータのみを出力するテキスト形式、XML形式
その他SVG、SWF、WMF形式で出力可能です。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのようなチャートの種類がありますか?
2D形式が20種類、3D形式が14種類の計34種類あります。また、5種類200パターンを超えるゲージチャートにも対応してます。
詳細はチャートギャラリーのページをご参照ください。
チャートに対してクリックイベントを設定することは可能ですか?
はい、可能です。
クリックイベントによって、ハイパーリンク(URLにアクセス)を設定したり、ドリルダウン(関連する別のチャートへリンク)を設定することができます。
チャートのアニメーション表示は可能ですか?
はい、可能です。
SWFまたはSVG形式で出力する際、チャートにアニメーション効果を付けることができます。棒グラフの棒や折れ線グラフの線をフェードインで表示することができます。
2つのチャートを上下に並べて表示できますか?
はい、可能です。
折れ線グラフと棒グラフなど、X軸を共有する2つのチャートを上下に並べて表示できます。
折れ線グラフと棒グラフなど複数のチャート種を1つのチャートに表示できますか?
はい、可能です。
1つのチャートに折れ線グラフ、棒グラフ、エリアグラフなど、複数のチャート種を同時に表示できます。ただし、円グラフなど表示形式の異なる一部のチャート種は同時に表示できません。
日付や通貨などの形式を変更することは可能ですか?
はい、可能です。各国独自のフォーマットをサポートしております。
チャートとは別にレポート(表)を入れることは可能ですか?
簡易的なものであれば可能です。詳細なカスタマイズをご希望の場合は、EspressReportをご検討ください。
チャートにオリジナルのタイトルやテキストを挿入することは可能ですか?
はい、可能です。
グラフ領域の任意の位置に装飾付きテキストを配置できる「フリーラベル機能」を使用可能です。
保存形式で「cht」と「tpl」の違いが分かりません。
chtは実際のデータを含めたチャート形式ファイルです。(サイズ大きめ)
tplは実際のデータが含まれないチャート形式です。(サイズ小さめ)
画像に出力する際、圧縮率の指定は可能ですか?
JPEG/PNG形式の場合は可能です。
Y軸を左側に複数配置させることは可能ですか?
チャートの種類が「オーバーレイ」の場合のみ可能です。
対数表示には対応しておりますか?
対応しております。
Y軸の最大値・最小値・表示間隔はどのような基準で決められるのでしょうか?
「自動」と「手動」の2種類の設定があります。
「自動」の場合はグラフ表示範囲内の実データの最大値・最小値から適切なY軸の最大値・最小値・表示間隔が自動設定されます。
「手動」の場合は実データに関係なく意図的にY軸の最大値・最小値・表示間隔を任意設定可能です。
ただし手動の場合にはY軸の最大値・最小値を実データが超過する場合にエラーが発生しますので、超過しないように調整が必要です。
チャートの色やプロットの形を指定することは可能ですか?
はい、可能です。
チャートデザイナ → 保存形式「cht」で保存することで指定できます。
チャートAPI → setPointShapes()やsetColors()を使用することで指定できます。
詳細はこちら
EspressChart -トラブル
作成したチャートのY軸に小数点以下が表示されない。
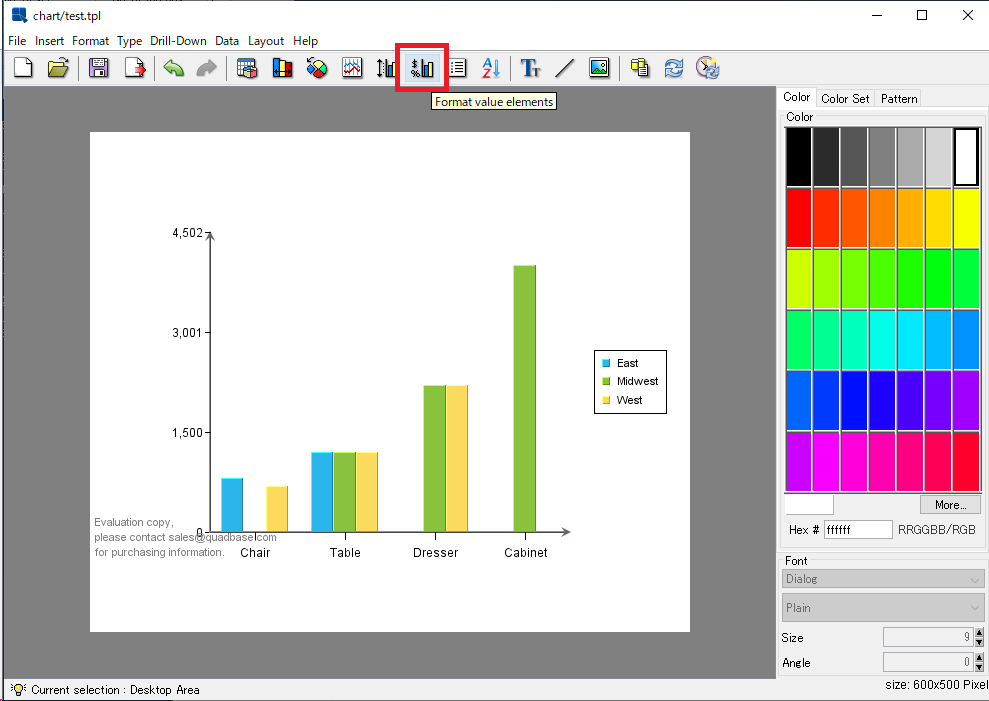
Chart Designerから以下の設定をご確認ください。
1)チャートファイルをChart Designerで開き、
「Format value elements」を開きます。
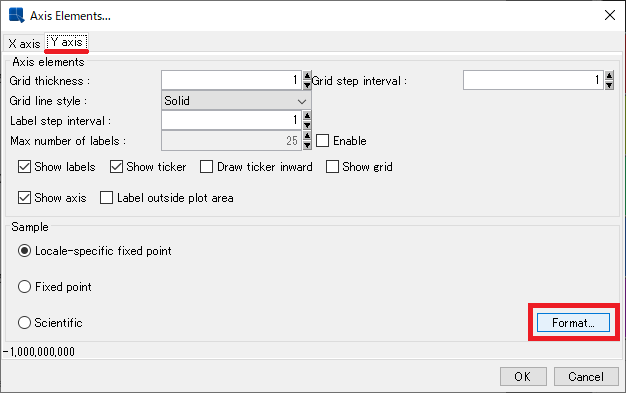
2)Y axisタブのFormatを開きます。
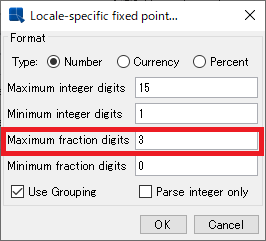
3)「Maximum fraction digits」に「1」以上の値を入れます。
ここで表示する小数点以下の桁数を指定します。
「3」とした場合、最大3桁まで表示します。
開発環境と運用環境で文字(フォント)が変わってしまう場合どうすればいいですか?
グラフで使用しているフォントが両環境で使用できない場合、自動的にデフォルトのフォントが使用されます。
そのため両環境で共通のフォントを使用してください。
また環境によってDPIの設定が異なる場合、一部設定が反映されない場合があります。
その場合は両環境でDPIをあわせる、もしくはAPIからグラフを出力する際に以下のメソッドを実行しDPIをあわせる必要があります。(DPI_value:設定するDPIの値)
QbUtil.setPixelPerInchForExport(int DPI_value);
APIでTPLファイルからチャート作成時に”警告: Failed to load chart data, using backup data.”が表示される。
これはデザイナーで指定した場所にデータソースがない場合に警告が出力されることがあります。
この警告を出力しないようにするためには以下の3つの方法がございます。
①デザイナーで保存する際にCHTファイルを使用する。
②APIでからデータソースの場所を上書きした形で再度TPLファイルをエクスポートする。
③ダミーとなるデータをデザイナー指定の場所と同一の場所に作成する。
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
Y軸の最大値又は最小値を超える値が存在する場合にエラーが出ます。
EspressChartの使用となります。Y軸の最大値・最小値を超えないように調整をお願いいたします。
バッチファイル「Patch6.jar」を適用することでエラーの回避は可能ですが、非推奨です。
「java.lang.OutOfMemoryError: Java heap space」エラーが出ます。
-Xmxオプションの追加でJVMの最大ヒープサイズを変更し、改善されるかどうかご確認ください。DBから取得するレコードが大量な場合や、Y軸X軸の表示目盛間隔が小さすぎて大量表示している場合に発生したケースがあります。

