

Syniti DR (17)
Data Replicatorが強制停止することがある
本エラーは例えばOracle 11.2のクライアントを使用している場合「oracore11.dll」にて障害が発生した旨Windowsイベントログに記録されている可能性があります。
一部の条件下にて本事象が発生するケースがあり、エラー発生までの流れは以下の通りです。
1. DBMoto から Oracle へ Oracle クライアントで接続するためコネクションをオープンする
2. このオープンしたタイミングで Oracle クライアント側のoracore11.dll というファイル関連で何らかの障害が発生しエラーとなる可能性がある
3. 2に引きずられて DBMoto の Data Replicator が強制終了する
つまり、発生トリガーは1の「Oracle へのコネクションを確立した際」です。
これまで発生事例から Windows のダンプファイルの解析、マイクロソフト社のダンプ解析ツール ADPlus でさらに詳細を解析するなどし下記のことが判明しております。
・エラーは Oracle 側の DLL で発生している
・エラーは .NET Framework の外で発生している
・DBMoto はすべて .NET Framework 内で動作するので本エラーが DBMoto 起因である可能性は極めて低い
(DBMoto が原因の場合は .NET Framework 内でエラー発生する)
・再現するマシンが一部に限られている
回避策としてレプリケーション毎に Oracle への接続をオープンにしないようコネクションプールを有効にする方法がございます。設定手順は以下の通りです。
1. Data Replicator サービスを停止します
2. ターゲットの Oracle 接続を右クリック→「プロパティ」を開きます。
3. 接続 Oracle .NET Driver の右にあるボタンをクリックします。
4. Pooling が False になっているので True へ変更します。
これにより Oracle へのコネクションプーリングが有効となり、
本事象は発生しなくなります。
AS/400のレプリケーションで「レプリケーション検証機能」を使用すると文字変換が正しくないとのエラーが出ます。
DBMotoの機能に、レプリケーションのソースとターゲット双方のテーブル間で差異が生じていないかを確認するレプリケーション検証機能があります。
AS/400のテーブルで、VARGRAPHIC型もしくはGRAPHIC型があるテーブルで検証を行うと、「CCSID 65535とCCSID 13488の間の文字変換は正しくない」とのエラーメッセージが出力されることがあります。
このエラーメッセージは通常のレプリケーション中には発生せず、データは問題なくレプリケーションできていることが多いです。

これは、このレプリケーション検証機能使用時に限り、DBMotoの「検証のソート・シーケンステーブル」設定が有効であるため、GRAPHIC型が文字変換を行おうとして失敗しています。
対処法は、この設定個所の部分を空欄にすることです。(設定変更時はData Replicatorの停止が必要です。)
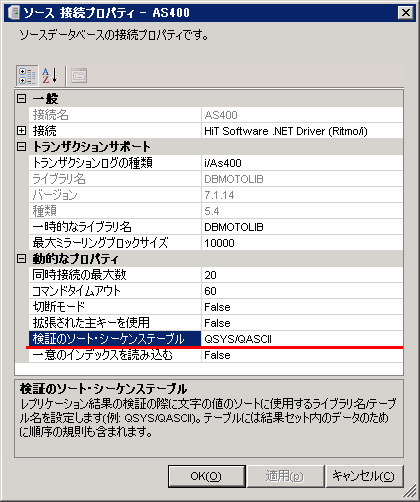
なお、通常のレプリケーションは、前述の通りこの設定を使用していないので、問題なく変換され動作します。
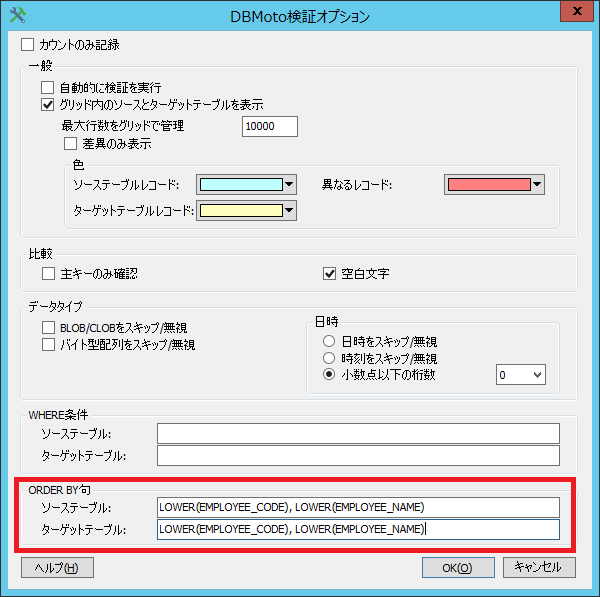
レプリケーション検証機能で正常なレコードがソースのみ、ターゲットのみのレコードとして表示されます。
レプリケーションの検証をすることで、ソースのみのレコード、ターゲットのみのレコード、ソースとターゲットで差異のあるレコードを確認できます。
しかし、本来、ソースにもターゲットにも存在し、差異のないレコードがソースのみ、ターゲットのみに存在するレコードとして表示されることがあります。
これは、DBMotoはソースとターゲットのレコードを比較する前に主キーをベースにレコードのソートを行いますが、このときのソースDBとターゲットDBのソートの仕様の違いによるものです。
例えば、Oracleの場合、大文字、小文字を区別してソートするため、D→aの順番でソートされ、MySQLの場合、大文字、小文字を区別せずソートするため、a→Dの順番でソートされます。
このソートの順番が異なるため、このような結果が生じます。
この事象を回避するため、検証機能のオプション「ORDER BY句」の「ソーステーブル」「ターゲットテーブル」に「LOWER(主キー)」を入力してください。こうすることで、大文字、小文字の区別なくソートが行えるため、問題なく検証することが可能です。
シンクロナイゼーション レプリケーション作成時にエラーが発生します。 「接続’DB接続名’用に定義されたユーザ’sa’はsysadminであり、シンクロナイゼーションでは有効ではありません。sysadmin以外のユーザでログインを定義してください。また、ディストリビュータを作成し、トランザクションログを読むためにsysadminのログインIDを供給しています。」
SQL Serverの接続設定に「sa」以外のユーザをご利用ください。
シンクロナイゼーションでは、更新がループしないようにするため、接続設定に使用したユーザでの更新はレプリケーション対象として検出しない仕様となっております。
そのため、シンクロナイゼーションを行う場合には、DBMoto専用ユーザを用意する必要がございます。
「sa」はDBMoto専用とすることができないため、このようなエラーが発生します。
CHARの代わりにVARCHARを使用してRedshiftにレプリケートすることで、より多くの文字をサポートし、予期しない文字の混在を防ぐことができます。
Version: Syniti Data Replication 9.6.0 以上
Amazon Redshiftのクラウドデータウェアハウスにレプリケートする際、データタイプがCHARのフィールドにエラーや予期せぬ文字が現れることがあります。 この現象の説明については、以下のURLを参照してください。
https://docs.amazonaws.cn/en_us/redshift/latest/dg/multi-byte-character-load-errors.html
エラーや予期せぬ文字を避けるために、RedshiftのターゲットのデータタイプをCHARではなくVARCHARに設定してください。
データベーススキーマの設計方法
データベーススキーマの設計は、データの書式が一貫していること、すべての項目が主キーを持つこと、重要なデータが除外されていないことを保証します。データベーススキーマは、視覚的なものと論理的なものがあり、データベースを管理するための公式のセットを含んでいます。開発者は、これらの公式とデータ定義を使用して、データベーススキーマを作成します。
最も一般的なデータベーススキーマの種類を以下に概説します。
階層的モデル: 階層型:ルートノードに子ノードが付随するツリー状の構造を持つデータベーススキーマを階層型という。このデータベーススキーマモデルは、家系図などのネストされたデータを格納することができる。
フラットモデル:フラットモデル: データを単次元または二次元の配列に整理したもので、行と列を持つスプレッドシートのようなモデル。このモデルは、複雑な関係を持たない単純なデータを表形式で整理するのに適している。
リレーショナルモデル:リレーショナルモデルは、データが表、行、列に整理されるフラットモデルに似ている。ただし、このモデルでは、異なるエンティティ間の関係を定義することができる。
スタースキーマ: スターデータベーススキーマは、データを「ディメンション」と「ファクト」に整理します。ディメンジョンには説明的なデータが含まれ、ファクトには数値が含まれる。
スノーフレークスキーマ: スノーフレーク(雪片)型データベーススキーマは、データベース内のデータを論理的に表現したものである。このタイプのスキーマの表現はスノーフレークに似ており、複数のディメンジョンが1つの集中ファクトテーブルにくっ付いている。
ネットワークモデル: ネットワークデータベーススキーマは、データを接続された複数のノードとして含みます。このモデルは、多対多の関係などの複雑な接続を可能にするため、特定のタスクを達成するために使用されます。
データベーススキーマ設計のベストプラクティス
データベーススキーマを最大限に活用するためのベストプラクティスを以下に紹介します。
セキュリティ: 効果的なデータベーススキーマの設計は、データセキュリティに重点を置く必要があります。また、ログイン情報、個人を特定できる情報(PII)、パスワードなどの機密データを保護するために、高度な暗号化を使用します。
名前の規則: スキーマ設計をより効果的にするために、データベースで適切な命名規則を定義することができます。テーブル、カラム、フィールド名には、複雑な名前、特殊文字、予約語を使用しないようにします。
正規化: 正規化とは、独立したエンティティやリレーションシップが、同じテーブルやカラムにまとめられないようにすることで、冗長性を排除するものです。これにより、データの整合性が向上し、開発者が情報を取得しやすくなります。また、正規化により、データベースのパフォーマンスを最適化することもできます。
ドキュメンテーション: データベーススキーマは、開発者とドキュメンテーションの作成にとって非常に重要です。データベーススキーマの設計は、説明書、コメント、スクリプトなどとともに文書化する必要があります。
データベースのスキーマには、大きく分けてどのような種類があるのでしょうか。
物理データベーススキーマ: 物理データベーススキーマは、データの物理的な配置と、ファイル、インデックス、キーと値のペアなどのストレージのブロックへの格納方法を表します。
論理データベーススキーマ:論理データベーススキーマはデータの論理的な表現を記述し、論理的な制約を伝達する。データはある種のデータレコードとして記述することができ、異なるデータ構造として格納される。ただし、データの実装などの内部的な詳細はこのレベルでは隠されている。
データベーススキーマは何に使うのですか?
データベーススキーマは、情報を体系的に整理するために設計された認知的な枠組みや概念です。スキーマがあれば、膨大な量の情報を素早く解釈することができる。未整理のデータベースは混乱しやすく、維持・管理も困難です。きれいで、効率的で、一貫性のあるデータベーススキーマの設計により、組織のデータを最大限に活用することができます。リレーショナルデータベースは、データの冗長性を排除し、データの不整合を防ぎ、データの検索と分析を容易にし、データの整合性を確保し、不正なアクセスからデータを保護するために、データベーススキーマ設計に大きく依存します。強力なテスト環境でデータをテーブルとカラムに整理することが極めて重要です。データの整合性を管理し、データベースとソースコードを更新する計画が必要です。
データベース・スキーマ設計とは?
データベーススキーマ設計は、データベースのアーキテクチャを開発するための設計図を提供することで、膨大な情報を体系的に格納することができる。また、データベースの構築に関わる戦略やベストプラクティスを指します。データベーススキーマ設計は、データを個別のエンティティに整理し、整理されたエンティティ間の関係を決定することによって、データの消費、解釈、取得をはるかに容易にします。
データベースのスキーマはどのように設計されているのですか?
データベース設計者は、プログラマーが効率的にデータベースを操作できるように、データベーススキーマを作成します。データベースを作成するプロセスは、データモデリングとして知られています。データベーススキーマを設計するためには、情報を収集し、それらをテーブル、行、列に並べる必要があります。情報を整理することで、理解しやすく、関連付けやすく、使いやすくする必要があります。
データベーススキーマの定義
データベーススキーマとは、リレーショナルデータベース全体の論理的、視覚的な構成のことである。データベースのオブジェクトは、テーブル、関数、リレーションとしてグループ化され表示されることが多い。スキーマは、データベース内のデータの構成と格納を記述し、さまざまなテーブル間の関係を定義します。データベーススキーマは、スキーマ図を通して描くことができるデータベースの記述的な詳細を含んでいます。
Syniti Data Replication (DR)とDBMotoはどう違いますか?
DBMotoはVer9.7から名称をSyniti Data Replication (略: Syniti DR)に変更しました。
名称のみの変更で機能に変更はありません。
今後名称をSyniti Data Replicationに変更してまいります。
Oracleからのミラーリングで「Record to update not found in target table」の後にターゲットへの補管INSERTでNOT NULL制約違反が発生する
まず更新対象レコードがターゲットに存在しない場合に「Record to update not found in target table」警告が発生し、その後DBMotoは補完INSERTを行います(行わないようにすることも可能です)
しかし Oracle のトランザクションログモードがLog Readerの場合、REDOログから取得できる情報は更新したカラムとPKのみとなります。
このため更新していないカラムはNULLとしてターゲットへのINSERTを行い、結果NOT NULL制約のカラムがあるとエラーになります。
対処方法は以下の2通りです。
1. Oracle のトランザクションログモードを「トリガー」にする(Oracle 10gかつDBMoto v9以降)
2. Oracle に対して以下のクエリを発行し、すべてのカラム情報をREDOログから取得できるようにする。
>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
パーティション化したテーブルからミラーリングできますか?
可能です。
ただし、DBMotoではDML文のみレプリケーションするため、パーティションがDDL文で削除されたときはそれを反映できません。
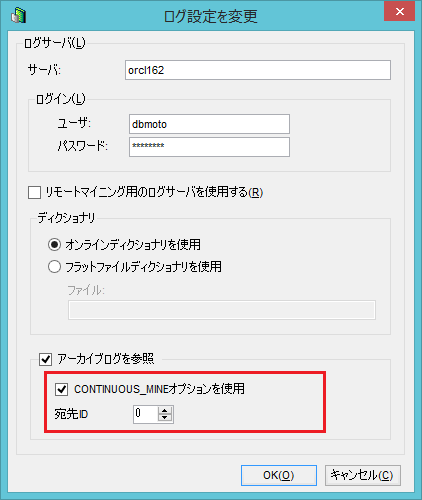
Oracleからのミラーリングタイミングが更新が起きていない時間帯でもバラバラです。
Oracleからのミラーリング時にはデフォルトでアーカイブログを参照し、またその際にCONTINIOUS_MINEオプションを有効にしています。
一部のOracle環境ではCONTINIOUS_MINEオプションをオンにしているとミラーリングタイミングがバラバラになることがあります。
CONTINIOUS_MINEオプションを外すとこの事象が解消することがあります。
オプションの切り替えにより、レプリケーションの性能劣化やOracleに対する負荷増加が発生することはほとんどありません。
DB2のHADR構成のスタンバイサーバからミラーリングは可能ですか?
トリガー形式およびログ参照形式のいずれも不可です。
DB2側の仕様でトリガーに必要な機能もログ参照に必要なAPIもスタンバイサーバでは利用できません。
SQL Serverでログ配布を受けているスレーブ側サーバからレプリケーションできますか?
SQL Serverの仕様上の制約によりできません。
MySQLへのミラーリングが反映されません
MySQLへミラーリングを行うためには、MySQLでautocommitが有効になっている必要があります。以下のクエリで確認が可能です。
mysql>SELECT @@autocommit;
もしもこの結果が0の場合、autocommitが無効になっているので、有効化してください。
もしアプリの都合で有効化が困難な場合は、以下の対応を行ってください。
1. Data Replicator を停止し、Management Center を閉じます。
2. 以下のファイルをダウンロードし、ExecuteList.xml を開きます。
https://www.climb.co.jp/soft/download/DBMoto/ExecuteList.zip
3. <connection name=”ここ”> に DBMoto で設定済みのMySQL 接続名を指定します。
4. ExecuteList.xml を DBMoto インストールディレクトリに配置します。
5. Data Replicator を開始し、正常にレプリケーションされることを確認します。
これによりMySQL への接続毎に「SET autocommit=1;」のコマンドを発行して一時的にautocommitを有効化してレプリケーションを行うようになります。
RDSのAurora/MySQLでバイナリログ(binlog)を使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【DBMotoでの設定】
「DBMySqlUtil.dll」をDBMotoインストールディレクトリに配置する必要があります。
お手元にない場合はお問合せください。
RDSのAurora/MySQLでトリガーを使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatが「OFF」になってる場合はそのままトリガーを使用可能です。
binlog_formatが有効化されている場合は、DB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
Sybase ASEから差分レプリケーションは可能ですか?
トリガーを使用することで可能です。
ただし、Sybase ASEでは1つのテーブルにおいて1つのトリガーのみしか使用できない仕様のため、既存でテーブルにトリガーを設定している場合は、DBMotoから差分レプリケーションを実施することはできません。
メール設定において、SMTPポート番号465番で指定したが、エラーでメールが送信されない。
こちらはDBMotoで使用している.NET Frameworkの仕様による問題です。
仕様上SMTP over SSLのポート番号である465番を使用したメールの送信ができないようになっております。
別のポート番号をご利用ください。
スクリプトで、.Net Frameworkの○○という関数が動きません。
スクリプトに記述した、.Net Frameworkの関数が動作しないことがあります。
これは、その関数の動作に必要な.Net FrameworkのライブラリがDBMotoに読み込まれていないのが原因です。
DBMotoでは本体の動作に不要な.Net Frameworkのライブラリは読み込まないようになっております。
適宜リファレンスで必要な.Net Frameworkのライブラリを読み込んでください。
■例
SHA256CryptoServiceProvider関数を利用する場合、System.Core.dllというライブラリを呼び出す必要があります。
Microsoft公式のSHA256CryptoServiceProvider解説ページ
このDLLファイルは、C:\Windows\Microsoft.NET\Framework64\vX.X.XXXX(Xは任意のバージョン数値)にありますので、ここへのリファレンスを追加してください。(64bit版の場合)
DBMotoでOracleのマテリアライズドビューはレプリケーションできますか?
リフレッシュとミラーリングが可能です。
ミラーリング時の注意点として、DBMotoは差分データの取得にトランザクションログを用いていますが、マテリアライズビューにあるレコードに対するUPDATE操作をOracleが内部で行う際、UPDATEではなくDELETEとINSERTを組み合わせて行っているため、トランザクションログの数が1つではなく、2つになっています。
DBMotoのレコード処理件数表示はトランザクションログをベースにしている都合上、マテリアライズドビューのリフレッシュモードが「完全」の場合は、ビュー上の全レコード数×2、「部分」の場合は、UPDATE対象レコードの数×2の数が、レコード処理件数として表示されます。これはOracle側の仕様によるものです。
Amazon EC2上のDBMotoからAmazon Redshiftへの接続ができません。
EC2上のWindowsに用意したDBMotoからRedshiftに接続しようとするとフリーズすることがあります。
これは、EC2上のインスタンスのNIC設定に由来する問題です。レジストリ上からMTU値を設定します。
次の場所にあるレジストリ内にMTU値を示すレジストリエントリーを追加します。
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\Interfaces\(アダプタのID)
追加するレジストリは、DWORD型で、値の名前は MTU 、データの値は 1500 に設定します。設定後コンピュータを再起動して、新しい値を適用します。
詳細は下記Amazon様ページをご覧いただきますよう、お願いいたします。
データベースへの接続が中断された – Amazon Redshift
マルチメンバーファイル(テーブル)からレプリケーションができません。
AS400上のマルチメンバーファイルとなっているテーブルからレプリケーションしようとすると、ステータスは成功なのに処理件数が0件のまま動かないことがあります。
これはマルチメンバーファイルの仕様上の制限でSELECTクエリが実行できないためです。
テーブルのエイリアスを作成していただければSELECTクエリで結果が取得できるため、レプリケーションできるようになります。
エイリアスを作成するクエリの一例は以下の通りです。
CREATE ALIAS MYLIB.FILE1MBR1 FOR MYLIB.MYFILE(MBR1)
CREATE ALIAS MYLIB.FILE1MBR2 FOR MYLIB.MYFILE(MBR2)
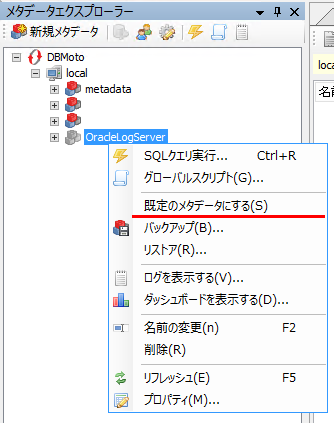
メタデータは複数作成できますか?同時に使用できますか?
DBMotoのメタデータは、複数作成することは可能です。
これにより運用環境とテスト環境それぞれのメタデータを用意できます。
しかし、複数のメタデータを同時に使用することはできません。それぞれのメタデータ内にあるレプリケーションは、それぞれのメタデータを有効化していない限り動作しません。
メタデータの切り替えは、メタデータ上で右クリックして表示されるメニューの、「既定のメタデータにする」で可能です。
MySQLレプリケーションのスレーブ側サーバからミラーリングをしたいのですが、必要な設定はなんですか?
スレーブ側MySQLのmy.iniの[mysqld]に次の一行を付け加えます。
log_slave_updates=TRUE
これは、スレーブサーバがマスターサーバから受け取った更新をスレーブサーバ自身のバイナリログに反映する設定となります。
デフォルトですと設定がされていない(FALSE)ため、DBMotoからスレーブ側のバイナリログを読み込みにいっても、マスター側の更新が記録されず、変更を検知できません。
ビューのレプリケーションに対応していますか?
参照するベースのテーブルが1つの場合かつSQLServerのビュー更新条件(特定の関数が使用されていないこと)を満たしている場合に限り、リフレッシュのみ可能です。
複数のベーステーブルを参照するビューの場合は、ビューの仕様でinsert, update, deleteが行えず、selectのみ可能となりますので、DBMotoでも同様にレプリケーションは行えなくなります。
DBMotoをどのマシンにインストールすればよいですか?
Windows OSのマシン(物理/仮想)にインストールします。
インストールしたマシンからソースDB・ターゲットDBのマシンに接続してレプリケーションの設定・実行を行います。
システム要件:https://www.climb.co.jp/soft/dbmoto/outline/system.html
DBMotoのインストール要件は?
Windows OSでMicrosoft .NET Frameworkがインストールされている必要があります。詳細は下記をご確認ください。
https://www.climb.co.jp/soft/dbmoto/outline/system.html
複数のテーブル内のレコードを1つのテーブルに結合可能ですか?
可能ですが注意が必要です。
ミラーリング時はPKが各テーブルで重複していなければ問題ありませんが、リフレッシュ時はそのまま実行してしまいますとリフレッシュ前に一度レコードを削除する処理(DBMotoの仕様)が行われます。これを回避するためにスクリプトでリフレッシュ時にレコードを削除しないようブロックする必要があります。
なお、各テーブル内のレコードが結合後に重複する可能性がある場合は、PK代わりのフィールドを新規で作成することでPK重複エラーを回避可能です。
DBMotoを仮想マシンにインストールすることは可能ですか?
VMwareのvSphere ESX/ESXiやMicrosoftのHyper-Vなど、仮想マシン上にもインストール可能です。
エージェント導入が必要ですか?
ソースDB・ターゲットDB・DBMotoマシンいずれに対してもエージェントを導入する必要はありません。
サポートしているDBの種類とバージョンは?
AS/400をはじめとする非常に多くのDBをサポートしております。また、DBのプラットフォーム(OS)には依存しません。
詳細な対応DB一覧は下記をご覧ください。
対応データベース一覧
どのようなレプリケーションモードがありますか?
下記の3つのモードをサポートしております。
・リフレッシュ(レコード全件レプリケーション)
・ミラーリング(片方向差分レプリケーション)
・シンクロナイゼーション(双方向差分レプリケーション)
ライセンス体系はどのようになっていますか?
ソースDBとターゲットDBの種類とマシンのスペックに依存します。
詳細はこちらをご参照ください。
使用する レプリケーションモードによって価格は異なるのでしょうか?
シンクロナイゼーション(双方向)を使用せず、ミラーリング(片方向)のみを使用する場合は、割引がございます。詳細はお問合せください。
開発環境やHA環境でも使用したいのですが、その場合は2倍の価格になりますか?
開発環境, バックアップ、HA環境、RACなどの構成で使用する場合は、価格が変わりますのでお問い合わせください。
お問合せはコチラ
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語メニューに対応していますか?
操作画面は日本語化しております。
製品の操作マニュアルも日本語版を用意しております。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから15日間となります。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
評価するには何が必要になりますか?
下記の環境をご用意ください。
・DBMotoインストール用のWindowsPC(仮想マシンでも可)
・ソースDBとターゲットDB、及び評価の際に使用するテストデータ
※インストールするサーバについては、システム要件をご確認ください。
※インストールや設定方法についてのマニュアルやデモ動画を事前にご確認ください。
ミラーリング時の更新サイクルはどのくらいですか?
デフォルト値は60秒です。変更可能ですが、30秒~5分が推奨値となっております。
古いジャーナルは削除しても問題ないですか?
DBMotoから参照しているジャーナルより前のものについては削除して問題ありません。
AS/400にはどのドライバで接続するのでしょうか?
Ritmo/iというドライバを使用します。DBMotoに同梱されております。
ジャーナルレシーバはテーブル単位で作成する必要がありますか?それともまとめて1つでも問題ないですか?
1つにまとめても問題ありません。DBMotoではテーブル単位でレプリケーション定義を作成し、定義ごとにトランザクションIDを管理することが可能なためです。
DBMOTOLIBにジャーナルレシーバを作成してもよいですか?
可能ですが非推奨です。DBMOTOLIBにはDBMotoからAS/400のジャーナルを参 照するためのプロシージャが存在しますので、DBMOTOLIBにプロシージャ以外のデータが存在するとレプリケーションのパフォーマンスに影響が出る場合があります。
どのようにして差分レプリケーションが行われますか?
Redoログを参照します。事前にサプリメンタルロギングの設定が必要ですが、DBMotoから行うことが可能です。
Oracle10gのレプリケーション設定時にドライバエラーが出ます
DBMoto側のOracleクライアントドライバを最新の11gにしてください。Oracle側の既知不具合です。
Oracle RACに対応していますか?
対応しております。
データタイプBLOB/CLOBには対応していますか?
対応しておりますが、ミラーリングとシンクロナイゼーションについては、
Log Server経由のみ対応しています。
ビューはレプリケーションに対応していますか?
対応しておりません。
Oracleへ接続するドライバのダウンロード先を教えてください。
以下のサイトからOracleクライアント又はODACをダウンロード可能です。
http://www.oracle.com/technetwork/jp/database/windows/downloads/index.html
また、Oracleデータベースのバージョンに関わらず、ドライバのバージョンは11を使用してください。
どのようにして差分レプリケーションが行われますか?
DB2 Logを参照する方法と、トリガーログテーブルを作成する方法があります。DB2 Logを使用する場合、予めdb2udbreadlogという拡張ファイル(DBMotoに同梱済み)をDB2側に格納する必要があります。
DB2 UDBにはどのドライバで接続するのでしょうか?
Ritmo/DB2というドライバを使用します。DBMotoに同梱されております。
どのようにして差分レプリケーションが行われますか?
Distributorを参照する方法と、トリガーログテーブルを作成する方法があります。
SQL Server Express Editionに対応していますか?
対応しております。ただし差分レプリケーションの際にDistributorを使用することはできず、トリガーテーブルを作成する必要があります。
どのようにして差分レプリケーションが行われますか?
MySQLのバイナリログを参照する方法と、トリガーログテーブルを作成する方法があります。MySQLのバイナリログを使用する場合、拡張ファイルが必要となりますので別途お問い合わせください。
バイナリデータはレプリケーション可能ですか?
可能です。
AS/400からのミラーリングでトランザクションID取得のためにReadボタンを押下するとエラーになります
DBMotoからAS/400のジャーナルレシーバを参照するためのプロシージャを手動で作成した場合に、正しく作成されていない可能性があります。
カタログ・技術資料一覧から以下をご参照ください。
[DBMoto共通]AS400ジャーナル・プロシージャ作成手順書
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
OracleからのレプリケーションでORA-01291(ログ・ファイルがありません)が表示される。
OracleのRedoログが1周してDBMotoが参照しに行くIDが既になくなってしまった際に発生するエラーです。
復旧はリフレッシュするか、最新のトランザクションIDを取得する必要があります。
また、このエラーが頻発する場合はRedoログのサイズ設定を見直す必要があります。
Transaction Latency StatusにThreshold Warningが出る
この Warning は現在時刻と最後にレプリケーションした際の時刻がしきい値を超えたときに「レプリケーションが遅延しています」と警告を出すものです。
複数のソースサーバから1つのターゲットサーバに結合レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
https://www.climb.co.jp/soft/dbmoto/outline/example.html
1つのソースサーバから複数のターゲットサーバに分散レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
AS/400のエラー「資源の限界を超えた」が発生しましたが原因はなんでしょうか?
下記ブログ記事をご参照ください。
リフレッシュ実行中にソースに更新があった場合はどうなりますか?
リフレッシュ完了後にミラーリングモードに移行し、更新分が差分レプリケーションされます。
シンクロナイゼーションで同一フィールドの同じ値を更新した時にコンフリクト扱いになりますか?
同じ値を更新した場合はコンフリクトとはみなされません。
サプリメンタルロギングを設定時の「Minimal Level」と「Database Level」は何が違うのでしょうか?また、実行されるSQLを教えてください。
●Minimal Level
レプリケーションするテーブルのみ(最低限)にサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA
・レプリケーション作成時
ALTER TABLE テーブル名 ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
●Database Level
データベース全体(すべてのテーブル)に対してサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
レプリケーション定義を一括で作成する方法はありますか?
予めソース・ターゲットの接続設定を済ませたうえで「マルチレプリケーション作成」を選択することで可能です。
ジャーナルが切り替わった場合、DBMotoもちゃんと切り替えて追ってくれますか?
はい、AS/400側のジャーナルに合わせてDBMotoが参照するジャーナルも自動で切り替わります。
ターゲット→ソースへのリフレッシュは可能ですか?
リフレッシュはソース→ターゲット方向のみサポートしております。
サプリメンタルロギングの設定でOracle9iでは「Minimal Level」だけにチェックを入れても「Database Level」にも自動でチェックが入ってしまう
Oracle9iの仕様によるものです。
SQLServerへのレプリケーションで以下のエラーが発生しました。 System.Data.SqlClient.SqlException: IDENTITY_INSERT が OFF に設定されているときは、テーブル ‘XXXX’ の ID 列に明示的な値を挿入できません。
SQLServerのフィールドIdentityの仕様によるものです。Identity以外のPKフィールドを用意するかIdentity自体をOFFにする必要があります。
ミラーリング開始後すぐに終了してしまいます。再開してもすぐ終了します。
ミラーリング時にはPKの設定が必要です。DBに設定されているかご確認ください。もしされていない場合は、DBMotoから疑似PKを設定することも可能です。
レプリケーション定義を作成してもステータスがstoppedのままでレプリケーションが動いてくれません。
レプリケーション定義を作成した後に、Data Replicatorを起動する必要があります。
DBMotoインストーラ起動時にライセンスエラーが表示されます。
.NET Framework 2.0 SP2がインストールされていないのが原因です。
WindowsXPやWindowsServer2003・2003R2の場合、デフォルトではインストールされていないので、別途インストールが必要です。また、.NET Framework4.0単独では動作いたしません。
シンクロナイゼーション(双方向)における処理シーケンスを教えてください。
以下の流れとなります。
ソースのトランザクションログを検索⇒ターゲットのトランザクションログを検索⇒ソースからターゲットへの更新処理⇒ターゲットからソースへの更新処理
ミラーリングの真っ最中にスケジュールリフレッシュの時間になった場合はどのような挙動になりますか?
ミラーリングプロセス終了後にリフレッシュされます。強引に割り込むことはありません。
ミラーリング・シンクロナイゼーションの処理速度を上げる方法はありますか?
Data Replicator Option画面にある「Thread Execution Factor」の値を増やすことで処理速度の向上が期待できます。
UPDATE時のみレプリケーション対象外とすることは可能ですか?
スクリプトで対応可能です。
大量トランザクション時、レプリケーションステータスが「Mirroring」で成功数、合計数は0のままで何も動作していないように見える状態がかなり長い時間続いている。
ステータスがMirroringで動いていないように見えるときは、実際にはトランザクションログの参照を行っています。大量トランザクション処理時は時間がかかるケースがあります。
万が一の障害発生時の復旧方法は?
リフレッシュをする方法と、トランザクションIDを任意の位置に戻す方法の2通りあります。
Oracleでエラー「ORA-03113」が発生しました。
OracleとDBMoto間のネットワーク障害によるものです。
DBMotoの疑似PKを使ってレプリケーションしていますが、キーが重複していても重複キーエラーが発生しません。
疑似PKの重複キーチェックは行われません。重複キーエラーが出るのはDBのPK使用時に重複していた場合のみです。
リフレッシュ時にはまずターゲットのレコードを一度削除するようですが、削除しないようにできますか?
スクリプトで実現可能です。
DBMoto導入によってDBにかかる負荷はどの程度でしょうか?
DBMotoはDBに対するクライアントツールとしてのアクセスしか行わないため大きな負荷はかかりません。DBに対するエージェント導入も不要です。
ネットワーク障害が発生した場合、復旧処理は自動で行われますか?
自動で行われます。
必要とされる回線の帯域の目安はありますか?
回線が速ければレプリケーション速度も向上しますが、回線が遅くてもレプリケーションは十分可能です。ISDN回線を使用しているお客様もいらっしゃいます。
ログ出力先をWindowsイベントログにした場合historyファイルはどこにありますか?
Windowsイベントログでの運用の場合、historyファイルはご使用いただけません。
レコードの全消去時に他データべースへのレプリケーションをどのように行いますか?
AS/400でレコードの全消去を含む操作(CLRPFMやCPYF(REPLACEオプション))を行った場合、他データベースに対してこの変更をTRUNCATEとして他データベースに反映します。しかしレコードが対象ではなく、ファイルそのものを置き換えている場合など(RSTOBJ等)の場合、変更は他データベースへ反映されません。
シンクロナイゼーション時に双方の同じレコードを更新した場合にはどうなりますか?
下記のオプションから選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する(先勝ち)
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
なお、「TimeStampの遅いほうを優先(後勝ち)」としたい場合には、カスタムスクリプトの記述が必要となります。
ソースDBとターゲットDBで文字コードが異なっていても大丈夫?
問題ありません。DBMotoで文字コード変換を吸収します。
DBMoto内部ではUnicodeで処理され、双方のDBに対して文字コード変換を行います。
シンクロナイゼーションでレコードを更新してもレプリケーションされないことがあり、エラーも出力されません。
シンクロナイゼーションではDBMotoでの接続ユーザでレコードの更新をかけた場合にはレプリケーションされず、エラーも出力されません。これは無限ループを回避するための仕様です。シンクロナイゼーションを利用する場合、DBMotoで使用する接続ユーザは他のアプリケーションでは使用しないDBMoto専用のユーザを用意してください。
レプリケーション中にSQLServer側のコネクション数が最大値に達したというエラーが出ます。
SQL Server側とDBMoto側のMax Pool Sizeをご確認ください。DBMoto側のデフォルト値は100です。
スケジュール機能はありますか?
はい、あります。
リフレッシュを定期的に実行するリフレッシュスケジュール、ミラーリングを実行する日時を制限するミラーリングスケジュールの設定が可能です。
スケジュールは時・分・秒、年・月・日・曜日単位で細かく設定でき、複数設定も可能です。
DB障害が発生してレプリケーションが停止した際の復旧が心配です。データの不整合が発生してしまうのでは?
DBMotoは最後に更新したトランザクションIDを常に保持しておりますので、DB障害復旧後には、障害発生前の最後のトランザクションIDからレプリケーションを再開します。よって通常はデータの不整合が発生することはまずありません。
ミラーリングでソースに対してレコードの更新や削除を行った際に、ターゲット側にレコードが存在しなかった場合にはどのような挙動になりますか?
エラーメッセージ「ターゲットにレコードが存在しません」をログファイルに出力し、更新時にはターゲットに対して登録処理が行われます。オプション設定変更により登録処理を行わないようにもできます。
DBMotoで使用する通信の種類とポートを教えてください。
TCP/IPで通信し、DB で使用するデフォルトポートを使用します。例えばOracleの場合はデフォルトで1521を使用します。
データを加工したり変換してレプリケーションすることは可能ですか?
可能です。Expressionという機能を使用し、VB.NET の関数を使用できます。
自前の関数を定義して使用することは可能ですか?
可能です。スクリプトとしてオリジナルの関数を定義し、Expression という機能で呼び出すことが可能です。
レプリケーション対象外のフィールドがある場合に固定の値を必ず挿入する設定は可能ですか?
可能です。Expressionという機能を使用し、固定値を入れることも可能ですし、現在日時を挿入するなど、関数を使用することも可能です
マルチシンクロナイゼーションにおいて、ソースとターゲットの複数で同じタイミングで同一レコードの更新をかけた場合、どのサーバのレコードが優先されますか?
ソースとターゲットで同一レコードの更新があった場合の挙動は以下から選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
さらにターゲットの複数サーバで同一レコードの更新があった場合には、TimeStampの早いほうが優先されます。
ミラーリングモードでも初回でリフレッシュは可能ですか?
可能です。下記の弊社ブログをご参照ください。
DBMotoでの全件リフレッシュ・差分ミラーリングの再設定手順
nullを特定の値に変換してレプリケーションすることは可能でしょうか?
スクリプトを使用することで実現可能です。詳細は下記をご参照ください。
https://www.climb.co.jp/blog_dbmoto/archives/452
https://www.climb.co.jp/blog_dbmoto/archives/460
Veeam Backup&Replication (152)
複数の仮想マシンをまとめてバックアップは可能ですか?
はい、可能です。下記の単位でのバックアップが可能です。
・クラスタ
・フォルダ
・リソースプール
・Virual App
・ホスト
・ユーザーが選択した仮想マシン
NutanixはVeeamに対応していますか?
はい、対応しています。
Veeam Backup for Nutanix AHVを導入することで
Nutanix AHV上仮想マシンのバックアップを簡単に実施することができます。
◇Veeam Backup for Nutanix AHV製品ページ
https://www.climb.co.jp/soft/veeam/van/
スケジュールで指定していない曜日にフルバックアップが実行される。
Active Full Backupの設定をご確認ください。
ジョブのスケジュールとは別に、Active Full Backupを実行するよう設定した曜日にもジョブが実行されます。
例えば、毎週土曜日 20:00にジョブを実行するようスケジュールしており、
Active Full Backupを日~土までの全て曜日で有効にしている場合、
土曜日以外の日~金も20:00にジョブが実行されます。
Veeamで作成したレプリカVMをバックアップできますか?
バックアップすることは可能ですが、CBT機能を有効にできないため、毎回、VMの全データを読み取り、増分の検出を行います。
そのため、増分バックアップは可能ですが、フルバックアップと同程度の時間がかかってしまうかもしれません。
ジョブのスケジュールをAfter this jobとしたとき、先に実行されたジョブが失敗した場合に、後続のジョブが実行されるか。
ジョブの成功、失敗問わず、後続のジョブは実行されます。
インスタンスとはなんでしょうか?
保護対象の単位です。1インスタンスにつき10個まで、以下のバックアップ対象を割り当てることができます。
●1仮想マシン(vSphere/Hyper-V/AHV)
●1物理サーバ(Windows/Linuxなど)
●1クラウドインスタンス(AWS/Azure/GCP)
●500 GB分のNASデータ
詳しくはお問合せください。
お問合せフォームはコチラ
Veeam Essentials/ Veeam Backup Essentialsとは何ですか?
Veeam Backup & ReplicationとVeeam ONEとのパッケージ製品(Veeam Availability Suite)の廉価版で、中小規模向けの仮想環境統合ソリューションです。
1ライセンスにつき5インスタンス保護できます。
※1管理サーバあたり、10ライセンス(50インスタンス)の制限があります。
詳細はこちらをご参照ください。
Veeamサーバのウィルススキャン時に、ApplicationDataフォルダ階層がループし、Windows側で警告が発生する
Veeamサーバのウィルススキャン時に、Windowsイベントログに以下の警告が発生することがあります。
———————————————————————————————————
ソース “SpntLog” からのイベント ID 212 の説明が見つかりません。このイベントを発生させるコンポーネントがローカル コンピューターにインストールされていないか、インストールが壊れています。ローカル コンピューターにコンポーネントをインストールするか、コンポーネントを修復してください。
イベントが別のコンピューターから発生している場合、イベントと共に表示情報を保存する必要があります。
イベントには次の情報が含まれています:
C:\ProgramData\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\Application Data\veeam.log
———————————————————————————————————
これはWindows側の無限ループ問題です。
基本的にProgramDataフォルダはデフォルトでApplication Data内にシンボリックリンク(ショートカット)されています。
これはWindows側の仕様となっており、このシンボリックリンクがウィルス対策ソフトにてスキャンされたとき、
フォルダ階層の無限ループが発生することがあります。
また、ウィルス対策ソフトのスキャンアルゴリズムのバグ等でも発生することがあります。
Veeamの動作としては問題はありませんが、Application DataとProgramDataフォルダ配下はウィルス対策ソフトの対象から除外することでこの警告を回避できます。
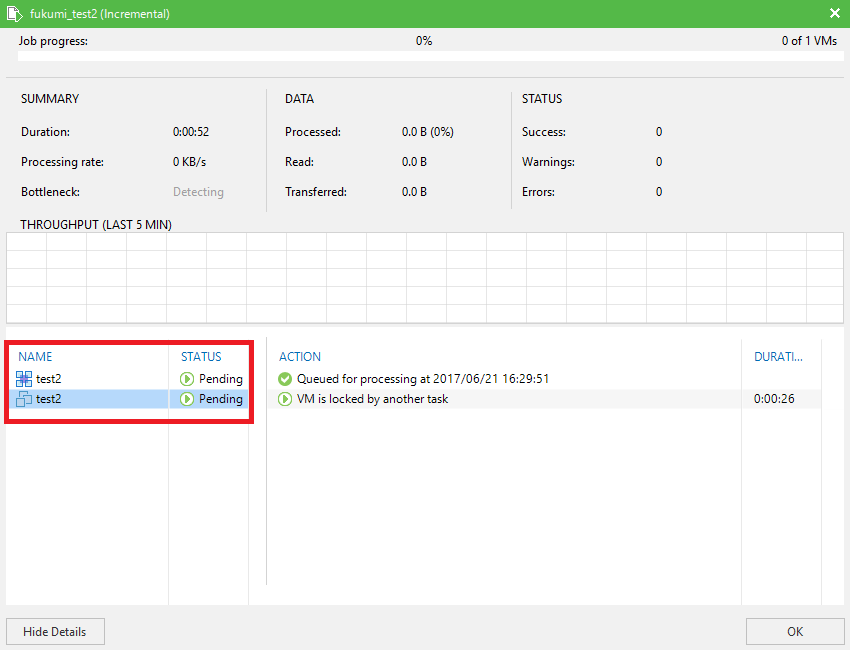
vCloud Backupのジョブを複数同時に実行したが、片方しかバックアップが処理されていないように見える。
各ジョブのバックアップ対象が同じvApp内のVMか確認してください。
その場合、現在処理中のジョブによってvAppがロックされているため、
もう片方のジョブは待ち状態となります。
現在処理中のジョブが終了後、処理が開始されます。
Veeam Backup & Replicationは仮想マシンにインストール可能ですか?
可能です。
要件を満たしていれば、物理/仮想問わずインストールできます。
システム要件はコチラのページの管理サーバ(Veeamインストール先)をご確認ください。
物理サーバのバックアップも行えますか。
はい、Veeam Backup & Replication Universalライセンスをご利用いただくことで、
仮想サーバに限らず、物理サーバも併せてバックアップ可能です。
Universalライセンスにつきましては、こちらをご参照ください。
レプリケーションが”The operation is not allowed in the current state.”または”その操作は、現在の状態では実行できません。”で失敗します。
以下をご確認ください。
・レプリケーション元ESXiホスト
・レプリケーション先ESXiホスト
・レプリケーション対象VMのハードウェアバージョン
レプリケーション先のESXiホストがVMのハードウェアバージョンと互換性がない場合に、
このエラーによってレプリケーションが失敗します。
互換性のある状態にする必要があるため、
対処法としては、以下の2通りの方法があります。
・レプリケーション先ESXiホストをバージョンアップする。
・VMのハードウェアバージョンをダウングレードする。
Enterprise ManagerでROLES設定を行いVMを選択するときに、一部ホストが表示されない。
以下に該当していないかご確認ください。
・vCenter経由とスタンドアロンホストの両方で同一ホストを登録している。
・どちらもホスト名で登録されている。
このとき、名前解決が行えず、Enterprise Managerが情報を正常に収集できません。
以下の対応を実施することで、全てのホストが表示されるようになります。
1.以下のいずれかを実施します。
・スタンドアロンホストをホスト名ではなく、IPアドレスで登録しなおす。
・Veeamサーバのhostsファイルにスタンドアロンホストのホスト名をIPアドレスを記載する。
2.Veeamコンソールで上記のホストをRescanします。
3.Enterprise ManagerでVeeamサーバの情報を収集します。
レプリケーションしたいVMのクローンVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションを行えますか?
オリジナルの仮想マシンとクローンの仮想マシンをマッピングすることで、
差分レプリケーションからジョブを開始することができます。
参考: レプリカシーディング・レプリカマッピング機能について
関連トピック
Veeam Universal License (VUL)はどんなライセンス体系ですか?
Veeam Universal License(VUL)は、サブスクリプション(年額前払)形態でご利用いただけます。インスタンス数(保護対象数)または保護容量で課金するライセンス体系で、以下が保護対象となります。
●仮想マシン(vSphere/Hyper-V/AHV)
●物理サーバ(Windows/Linuxなど)
●クラウドインスタンス(AWS/Azure/GCP)
●NASデータ
詳細は:
Veeam Universal License (VUL)について | クライム情報発信ブログ:ClimbMeUp
詳しくはお問合せください。
お問合せフォームはコチラ
Veeam Availability Suiteとは、どんなライセンスでしょうか?
Veeam Backup & Replication とVeeam ONEとのパッケージ製品です。
Veeam (Backup) Essentialsのような数量制限はありません。
詳しくはこちらのサイトを参照ください。
Veeam静止点処理において必要な認証情報をVM個別に指定する方法はありますか?
はい、あります。
Guest Processingステップの「Credentials…」にて個別に認証設定を行うことが可能です。
詳細は、以下URLをご参照ください。
関連トピック
Job作成時のオプション “Enable application-aware image processing” はどんな機能ですか?
DRサイトから運用サイトへフェイルバックする際に、DRサイト側にライセンスは必要ですか
必要ありません。
ライセンスはレプリケーション元となるオリジナルの仮想マシンのみ必要になります。
フェイルオーバーやフェイルバックの際、DR環境に作成した仮想マシンにライセンスは必要ありません。
スナップショット&イメージレベルバックアップ
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
Veeam Backup for Azure V3を詳しく見てみましょう。
Veeam Backup for Azure の最新版v3で何が追加されたのか、少し掘り下げてみましょう。
既にVeeam Backup for Azureを使用している場合は、内蔵のアップデーターを使用して以前のインストールをアップグレードすることができます。
何が含まれているか?
毎回のリリースと同様に、いくつかの主要な機能強化があり、細かい改善と同様に多くのアンダーザフードのものがあります。
最初の大きな特徴は、Azure SQLのサポートです。Veeam Backup for Microsoft Azureは、SQL ServerまたはAzure SQL Managed Instanceとして実行されているSQLデータベースをバックアップおよびリストアすることができるようになりました。
AWSのVeeam BackupがS3 Glacierを使用した長期アーカイブのサポートを追加したように、Veeamは、Azureにもこの機能を追加しました。バックアップを長期間保存するために、ホットまたはクール・ストレージを使用しなければならないのは嫌ではありませんか?もう心配する必要はありません! 今日からAzure Archiveへのバックアップの階層化を始めましょう! 今こそコスト削減のチャンスです(クラウドでは何にでもお金がかかります)。
複数のAzureアカウントに対応
今回のリリースで大きな特徴のひとつは、実は複数のAzureアカウントをサポートしたことです。これはVeeamのAWSとGCPのソリューションで既に可能でしたが、Azureは1つのAzureアカウントに限定されていました。これを強化し、複数のアカウントを許可することで、1枚のガラスからすべてのアカウントを管理および保護することが容易になります。
セキュリティ強化の追加
セキュリティは重要なテーマであり、ここでも需要の高まりが感じられます。そこで、2つの新機能を追加しました。
●ロールベースのアクセスコントロール:ロールベースのアクセスコントロール:ビルトインのロールを使用して特定のユーザーにアクセスを委任することにより、組織内でより高いセキュリティを確保するために範囲を制限することができます。現在、3つの異なるロールがサポートされており、アプライアンス内でそれぞれのロールが独自の範囲を持ちます。
●シングルサインオンをサポート:外部のIDプロバイダーを登録し、ローカル・ユーザーを作成する必要はありません。既存のユーザー・アカウントを再利用して、Veeam Backup for Azureで日常的なタスクを実行するだけです。
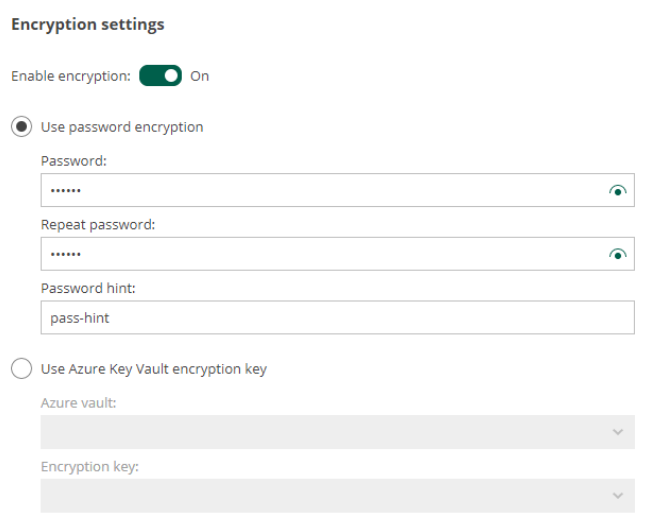
●Azure Key Vaultのサポート。バックアップ・データを暗号化するためにAzure Key Vaultを使用することができるようになりました。もうパスワードをメモして保管庫に入れる必要はありません
その他の追加機能
Azure、AWS、GCPを問わず、リリースするたびに、ユーザーインターフェイスとエクスペリエンスの改善に努めています。
更新されたウィザード(例えば、リポジトリとポリシーウィザード)では、全画面を使って構成設定を明確に表示するようになり、ウィザードを簡単に進めることができるようになりました。初めてログインすると、製品の最新情報を紹介する「What’s New」が表示されます。
Veeamは、ログイン画面を更新し、Veeam Backup for Azureで作成したアカウントでログインするか、シングルサインオンの恩恵を受けるかを簡単に選択することができます。
バックアップ対象(VM01, VM02)からVM02を除外した場合、VM02のリストアポイントは指定した世代数を保持しますか?
いいえ、保持しません。
例えば、リストアポイントを4世代とした場合、バックアップを取得するたびに世代数が減っていきます。
11/1, 11/2, 11/3, 11/4とバックアップを取得し、11/5にVM02が除外されたバックアップを取得した場合、VM02のリストアポイントは11/2, 11/3, 11/4となり、11/1のリストアポイントは消されます。
最終的には11/4のリストアポイントがフルバックアップファイル内に残り続けます。
これを消すにはフルバックアップの再作成や再構成(Compact full)が必要です。
Veeam V12新機能:オブジェクトストレージへの直接バックアップ
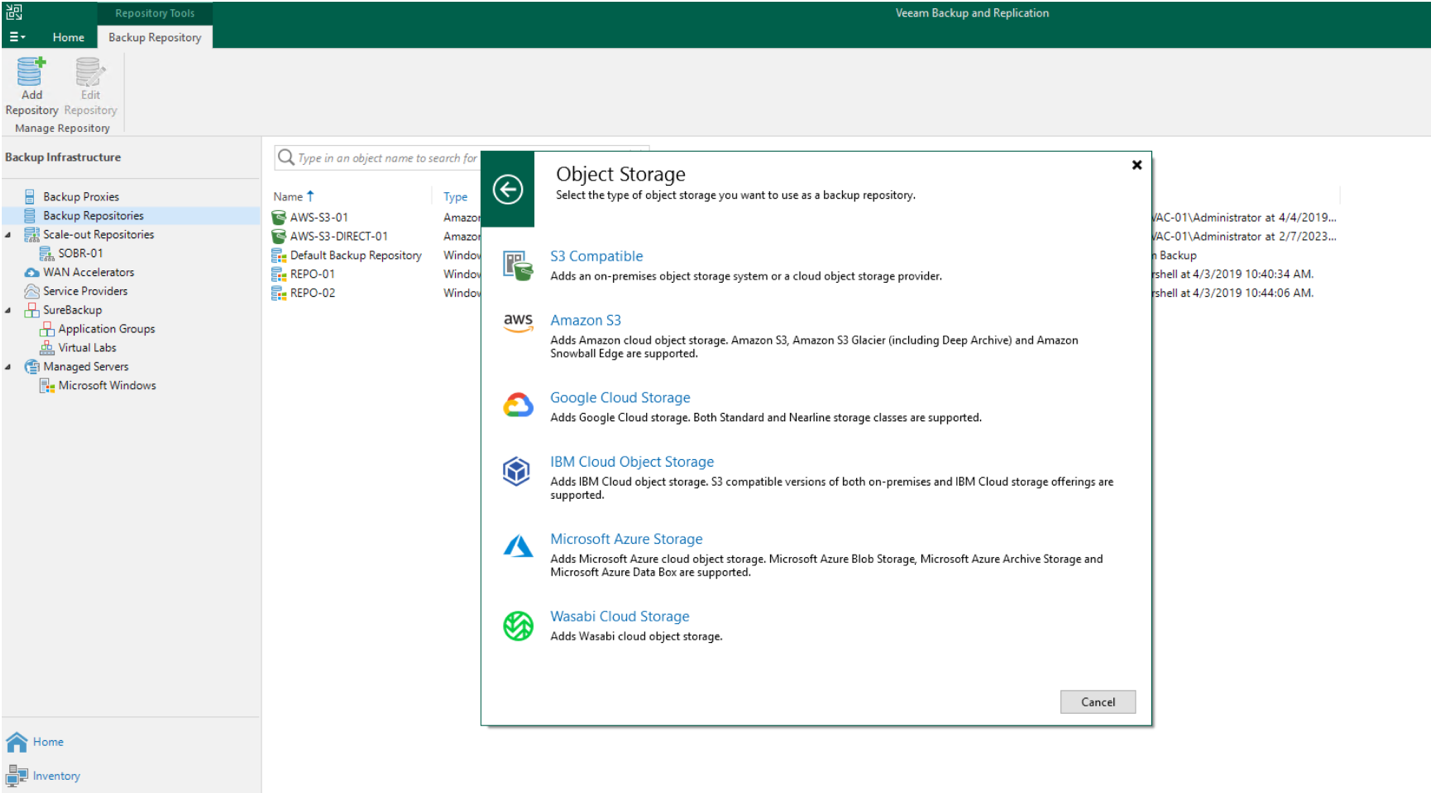
V12では、Direct-to-ObjectとDirect-to-Cloudの2つの主要な機能を提供しています。最初の機能は、バックアッププロキシやエージェントからオブジェクトストレージに直接バックアップを送信することで、中間ステップを回避することができます。さらに、このようなストレージへの直接接続が不可能な場合、トラフィックはゲートウェイサーバーの弾力的なプールを介してリダイレクトされることができます。さらに、ROBO(Remote Office Branch Office)環境を含め、より効率的なクラウドへの直接バックアップを実装しています。
また、新しいSmart Object Storage API(SOSAPI)ソフトウェア・インターフェースにより、オブジェクト・ストレージ・ベンダーがVeeam Backup & Replication v12と深く統合できるようになったことも特筆に値する(パフォーマンスの向上とユーザー・エクスペリエンスの改善に向けて)。
Veeam V12新機能:イミュータビリティ機能の強化
イミュータブル(Immutable)バックアップ機能は、ランサムウェアからバックアップを保護する手段を実装しています。この機能は、オンプレミスとクラウドネイティブの両方のワークロードで利用でき、ストレージのライフサイクルを通じてバックアップを保護し、管理者側の操作からも保護します。また、バックアップだけでなく、アラームにも不変性を持たせることができるため、より高度なインフラ保護が可能です。
イメージレベルでのバックアップのサポートに加え、NASストレージ、スタンドアロンエージェント、AWSとMicrosoft Azureのバックアップ(Azure Blob Storageも)、HPE StoreOnceストレージでバックアップのイミュータビリティが利用可能です。また、トランザクションログやエンタープライズアプリケーションに対しても、プラグインを介して利用することができます。
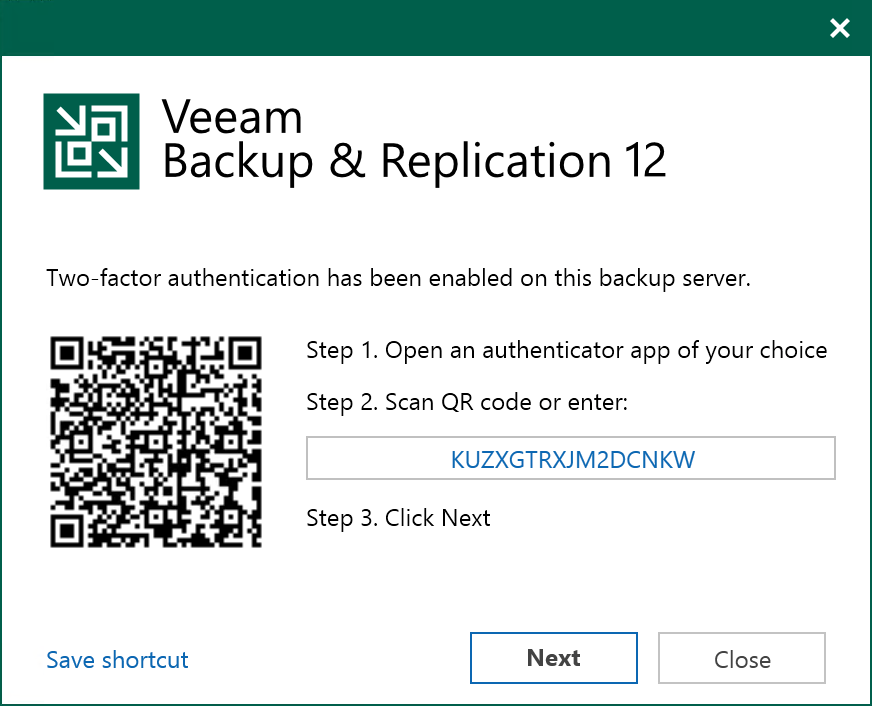
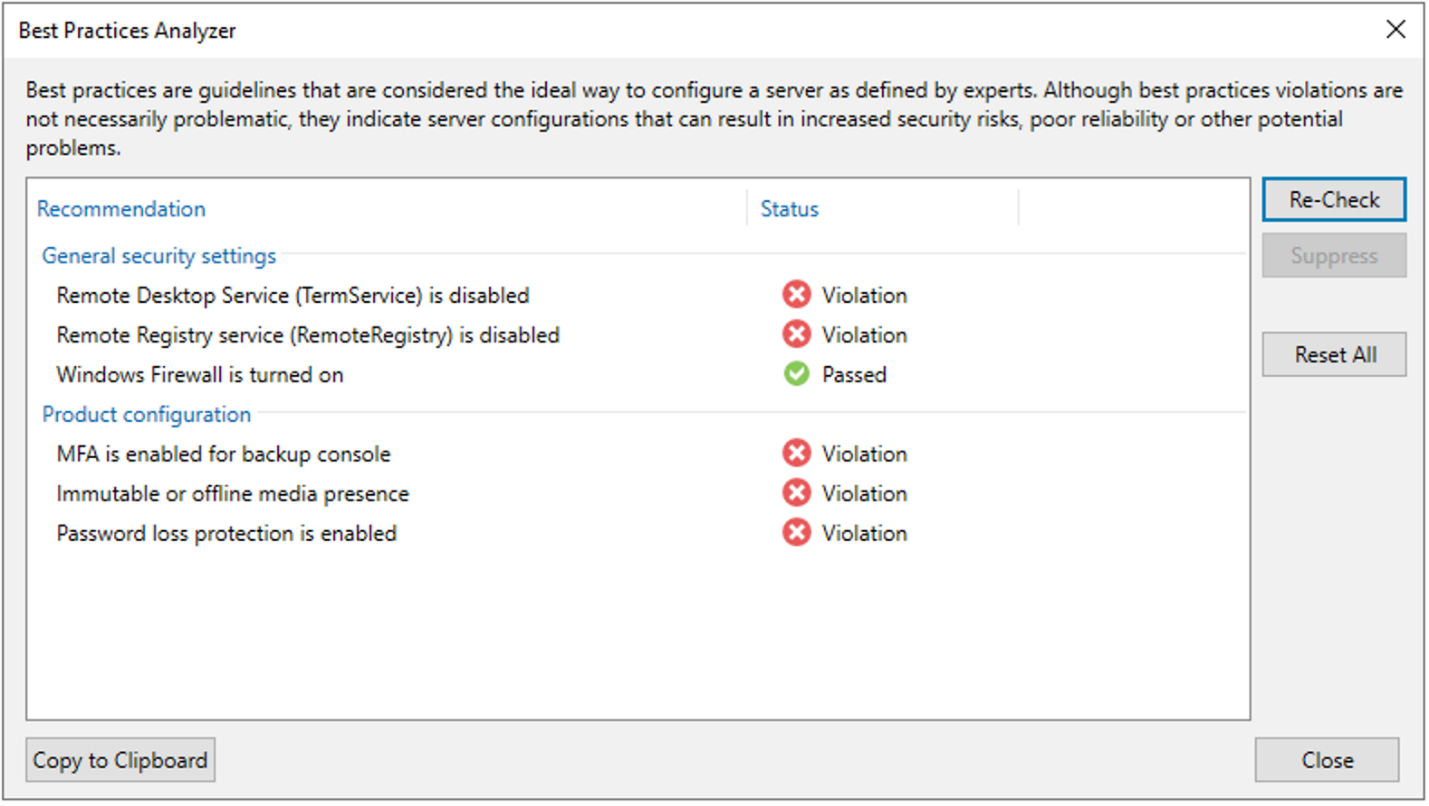
Veeam V12新機能:多要素認証とベストプラクティスアナライザー
これらの高度なセキュリティ機能により、管理者は2つの新しいツールを手に入れることができます:
多要素認証は、RFC 6238に基づくTOTP(Time-Based One-Time Passwords)の仕組みに基づく2要素認証(2FA)機能を通じてコンソールへのアクセスを可能にします。個々のアカウントに対して有効にすることができます。
Best Practices Analyzerコンポーネントは、バックアップサーバーと製品の構成をチェックし、セキュリティと復旧成功の可能性を向上させるための重要な変更を管理者に提案します。
Veeam V12新機能:バックアップのインフラ整備
回転メディアに切り替えると、ディスクは自動的に既存の古いバックアップからクリアされます。さらに、ユーザは既存のバックアップチェーンを使い続けることもでき、現在のタスクにのみ属するバックアップを削除するか、メディア上のすべてのバックアップを削除するかの2つのオプションのうち1つを選択することができます。
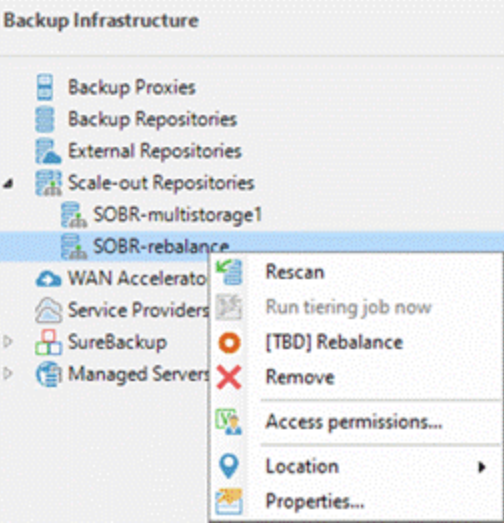
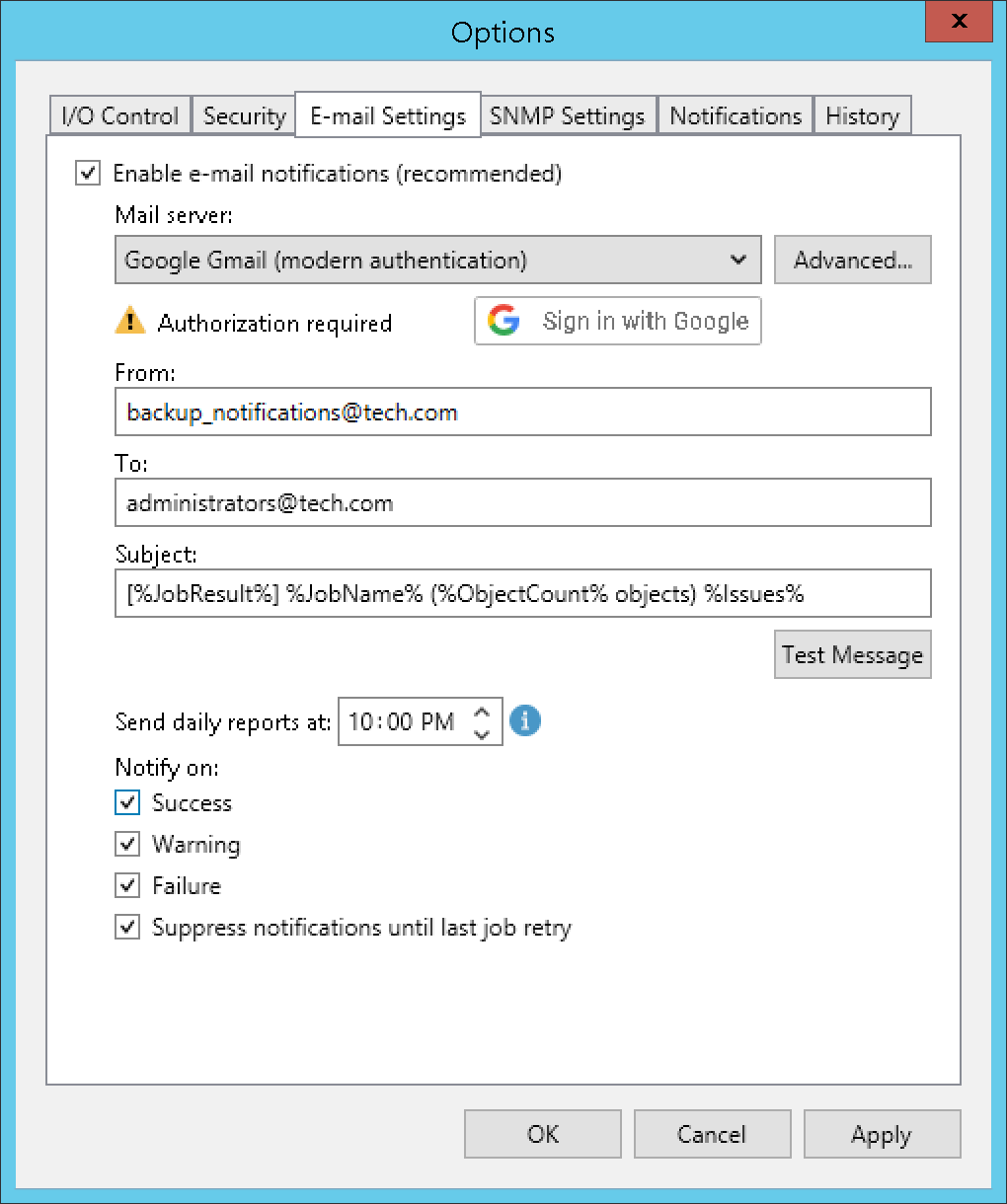
v12では、SOBRリバランス機能が導入されました。Performance Tierエクステントのブロックおよびファイルストレージレベルでストレージ消費をリバランスし、エクステント間のデータ分散を均等にすることができるようになりました。この操作は、新しいエクステントを追加するときに実行する必要がありますが、常に実行する必要はありません。エクステント退避とSOBRリバランスの操作は、前述した新しいVeeaMoverエンジンを使用して、エクステント間でより効率的にバックアップを移動させます。
また、ユーザーの要望により、マルチサイトやネットワーク環境でのトラフィックを管理するためのいくつかのインターネットルールが追加されました:
最後に、メール通知のOAuth 2.0対応です。SMTPによる認証に加え、Google GmailとMicrosoft 365のOAuthプロトコルによる認証をVBR V12がサポートするようになりました:
Veeam V12新機能:バックアップとリカバリー
新しいBackup Copyジョブは、新しいプラットフォームの機能との互換性を確保するために、個々のVMに基づく新しいフォーマットでチェーンを作成します(Per-machine backup chain)。既存のジョブはこのアップデートの影響を受けません。
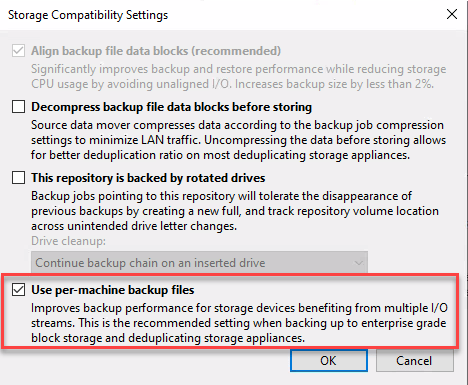
アプリケーショングループについては、仮想テストラボで起動する前に、Windowsファイアウォールのネットワーク接続を自動的に無効化するオプションが追加されました。これは、リストアプロセスのテストが必要なバックアップで、ファイアウォールが外部接続をブロックするのを防ぐために必要です。
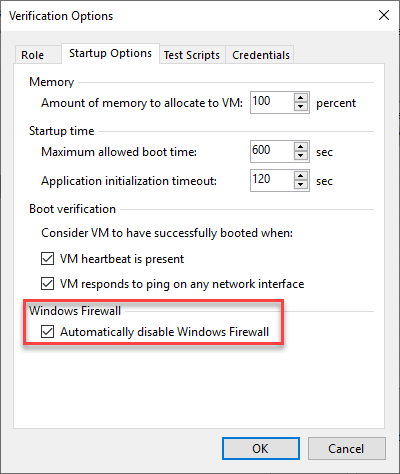
そして最後の非常に便利な機能です。これからは、更新されたBackup Browserを使って、復元ポイントと本番機のファイルを比較することができ、選択したバックアップが取られた後にどのファイルが変更または削除されたかを表示します。
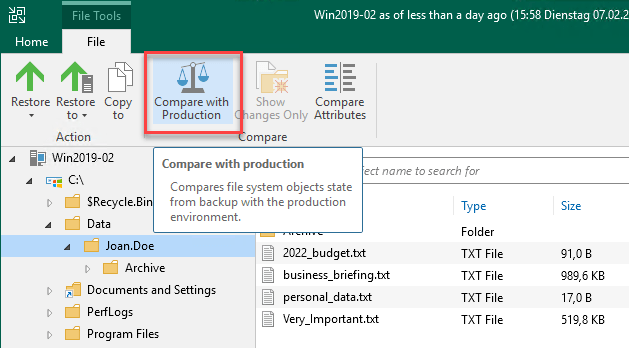
また、バックアップシステムと本番システムの間で、個々のファイルやフォルダの属性の違いを、新しいダイアログボックスを使って1画面で確認するオプションが追加されました:
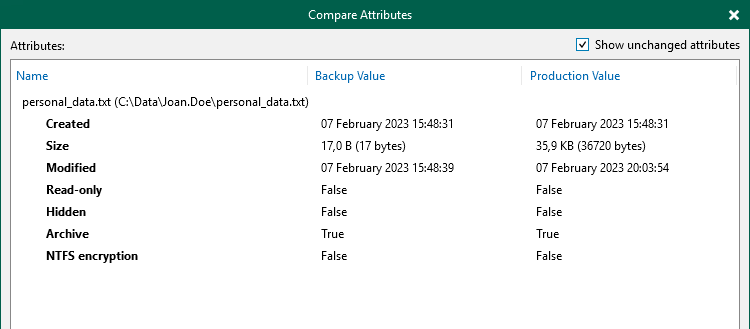
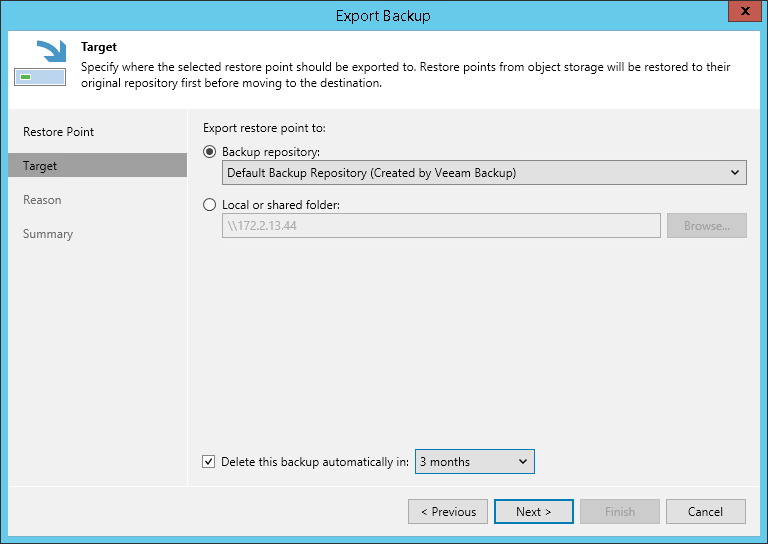
もう一つの新機能は、ファイルやフォルダーのアクセスコントロールリスト(ACL)だけを復元する機能です。これは、管理者が誤ってフォルダやファイルのパーミッションを一括で変更してしまった場合に必要になることがあります。また、v12では、Windowsファイルを直接復元する際に、異なるターゲットマシンを選択できるようになりました(これまではLinuxのみ)。最後に、バックアップのエクスポートの機能が向上し、元のバックアップがあった同じリポジトリだけでなく、エクスポートしたポイントの保存先を任意に選択できるようになりました:
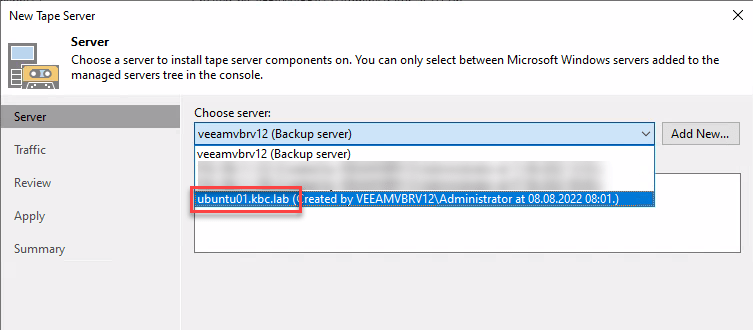
Veeam V12新機能:テープバックアップの改善
WindowsとLinuxの両サーバーに接続されたテープライブラリーやメディアをテープバックアップ用に登録することが可能に:
Backup-to-Tapeタスクは、ワークロードの種類に関係なく、即時モードまたは定期モードの新しいマルチプラットフォームBackup Copyジョブタイプによって作成されたすべてのバックアップコピーのエクスポートをサポートするようになりました。
すべてのテープ機能で、LTO-9テープの初期化プロセスをサポートし、初期化に時間がかかるとタイムアウトするのではなく、初期化が完了するまで正しく待機するようになりました。カセットテープを誤って消去しないように、InventoryとCatalogの操作後にテープメディアが自動的にテープライブラリードライブから排出されるようになりました。
Veeam V12新機能:CDP(Continuous Data Protection)の改善
CDPプロキシはLinuxサーバー上で動作するため、Windowsのライセンスを節約することができます。通常のバックアップ作業に加え、任意のクラウドホストサービスプロバイダを使用して、CDPポリシー内でレプリケーションを実行することができます。そして、VMやvAppモジュールのインスタントリカバリ機能を持つCloud Directorインスタンス内でレプリケーションを使用することができます。また、CDPはvVolスナップショットのネイティブサポートを提供するようになり、そこに保存されるオブジェクトの数を減らし、vVolボリュームのスケーリングに小さな制限があるデバイスでの信頼性を向上させます。
Veeam V12新機能:Veeam Agentの改良
Windows Serverに加え、保護グループウィザードに、Windows 10以降を実行しているワークステーションにVeeam changed block tracking (CBT) ドライバをインストールし、より高速な増分バックアップを行うオプションが追加されました。また、管理者はBare Metal Recoveryのリストアタスクのためにユーザーに与えることができる一時的なアクセスキーまたはリカバートークンを生成することができます。
v12のリリースに伴い、ゲストOS用の利用可能なすべてのエージェントがソリューション内で更新されたことに留意してください:
- Veeam Agent for Microsoft Windows
- Veeam Agent for Linux
- Veeam Agent for Mac
- Veeam Agent for AIX
- Veeam Agent for Solaris
Veeam V12新機能:アプリケーションプラグイン
保護グループウィザードが改善され、グループに含まれるサーバーのアプリケーションプラグインのインストールとアップデートを制御するための設定が追加されました。アプリケーションのトポロジーに関する情報収集と、スキャンおよび再スキャン時のOracle RACおよびSAP HANAシステムの検出ができるようになりました。
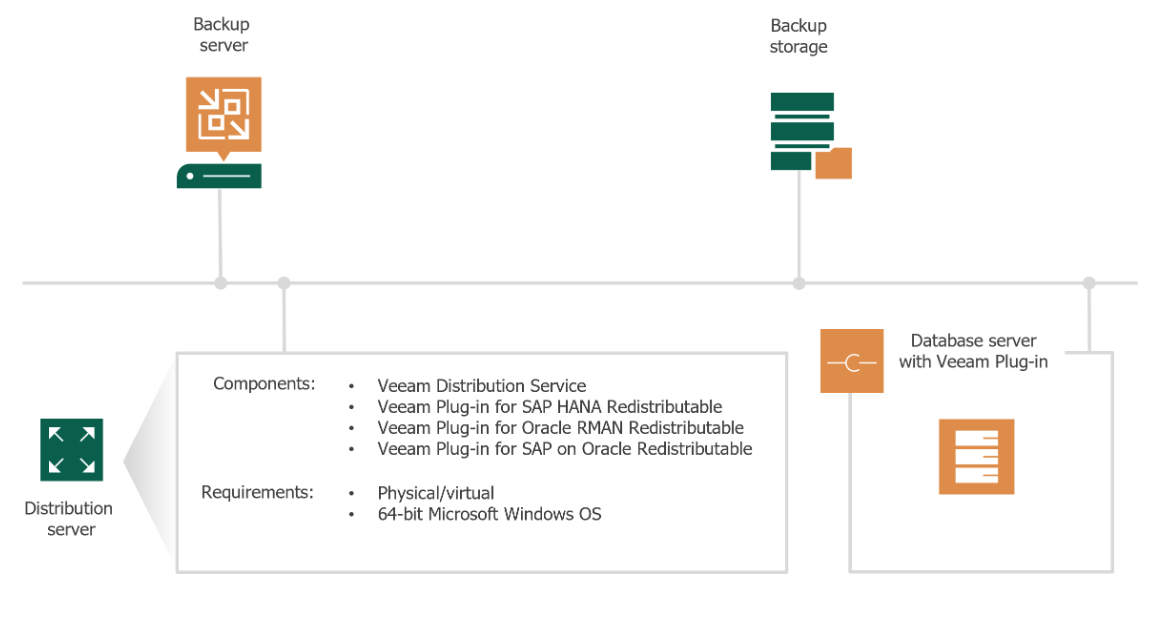
アプリケーションのバックアップポリシーには、各サーバーのバックアップ処理をリアルタイムで監視し、データベースやREDOログのバックアップの統計やレポートを可視化するツールがあります。
また、Oracle RMAN、SAP HANA、SAP on Oracleのバックアップをバックアップコンソールからポリシーに基づいてオーケストレーションする機能があり、各データベースサーバーのプラグイン設定やバックアップシナリオを手動で整備する必要がなくなりました。また、Version12では、これらのプラグインによるバックアップと復旧の速度が最大で3倍に向上しています。
Microsoft SQL Server用の新しいプラグインは完全に刷新され、SQL Server(VDIプラグイン)との深い統合を実現し、Veeamリポジトリへの直接バックアップを可能にしました。VDIプラグインは、バックアップの一貫性を確保するためにネイティブな手段を使用し、スナップショットベースのバックアップとは異なり、Microsoft VSSに依存しないため、共有ボリュームを持つWindows Server Failover Clustersなど、異なるSQL Server構成のバックアップを可能にします。
Veeam V12新機能:PostgreSQLのサポート

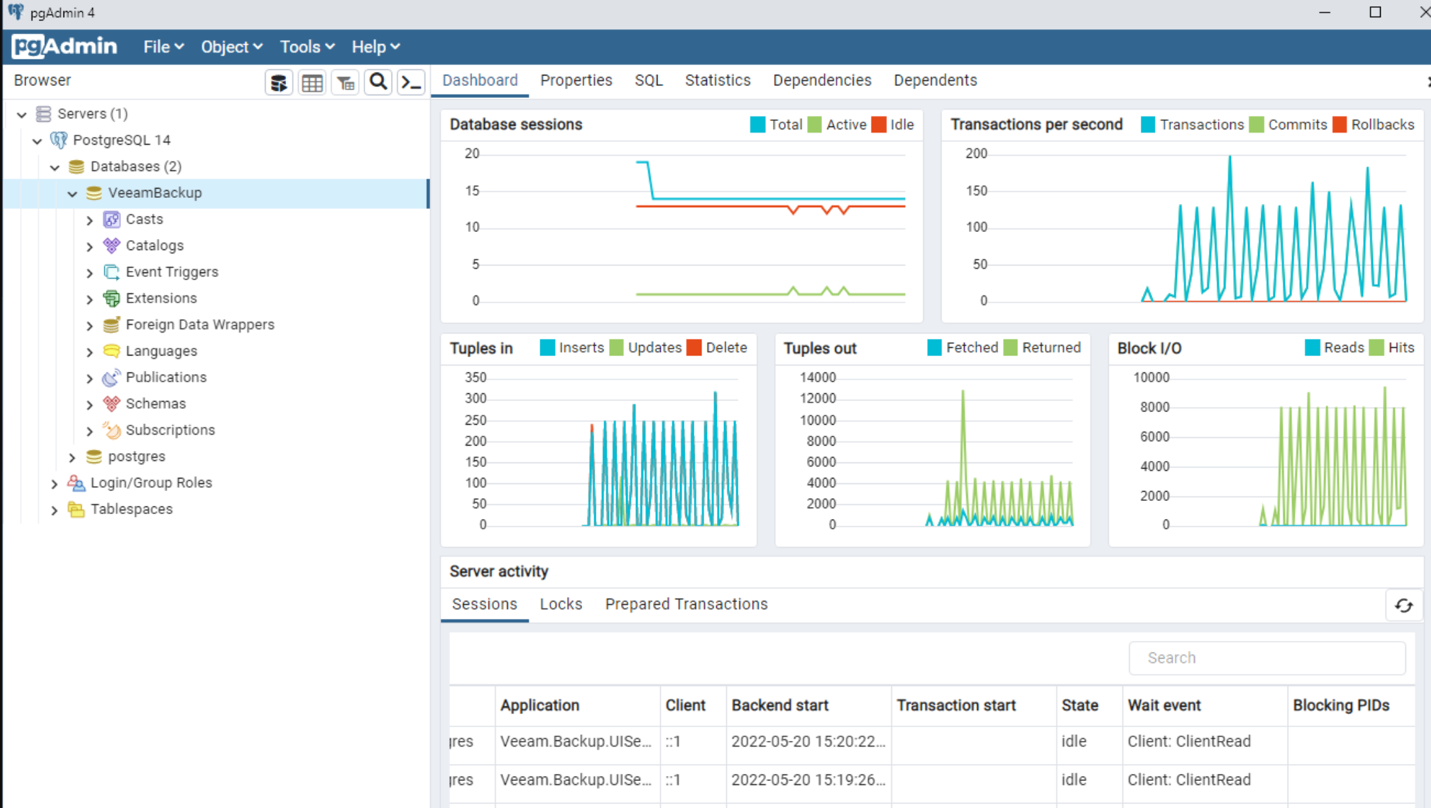
マルチプラットフォームのPostgreSQLエンジンがサポートされ、Microsoft SQL Server Express Editionのデータベースサイズ(10GB)の制限を回避することができるようになりました。SQL Server Express Editionはまだサポートされていますが、Veeam Backup and Replication製品に含まれなくなりました。
PGAdminでPostgreSQLデータベースがどのように見えるかをご紹介します:
さらに、Linux上のPostgreSQLデータベースのポイントインタイムリカバリーのためのトランザクションログのアプリケーションアウェアバックアップがサポートされるようになりました。同じ機能は、Microsoft SQL ServerやOracleではすでに提供されていました。
また、PostgreSQLの経験を持つ管理者でなくてもインスタンスをリストアできる「Veeam Explorer for PostgreSQL」という製品も登場しました。インスタンスの任意のポイントインタイム状態をバックアップから指定されたDev/Testサーバに直接公開することができ、その後、公開されたデータベースに加えられた変更をエクスポートまたは元に戻すことができます。
Veeam V12新機能:新規VeeaMover エンジン
VeeaMoverを使用すれば、異なるタイプのリポジトリ間でデータを移動することができます。ソースとターゲットリポジトリのタイプを気にする必要はもうありません – VeeaMoverが自動的にデータ移動のすべての作業を処理します。
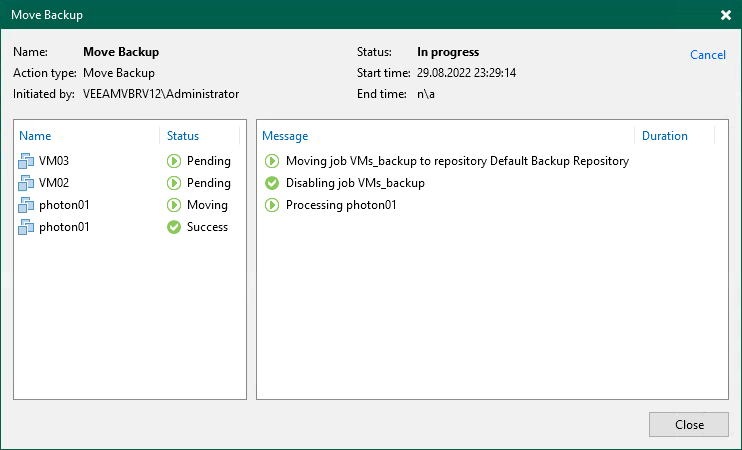
さらに、バックアップはタスク間で簡単に移動できるようになり、関連するすべての操作が自動的に実行されます(例えば、包含リストや除外リストの操作など)。また、保持ポリシーを保持したまま(変更も可能)、数回のクリックでバックアップチェーン全体を別の場所に移動させることができます。
Veeam V12新機能:バックアップコンソールの改良
タスクセッションで対応するマシンをクリックすることで、タスク内のすべてのマシンに対してこの操作を開始することなく、個々のマシンに対して処理の再開やアクティブフルバックアップの実行ができるようになりました。また、誤ってタスクに追加された場合でも、処理から完全に除外したいマシンのマスターリストを指定することで、恒久的または一時的な除外の管理がより簡単になりました。Global Exclusionsダイアログはメインメニューから利用でき、これらのマシンはインベントリータブでDisable processingオプションが選択されています。
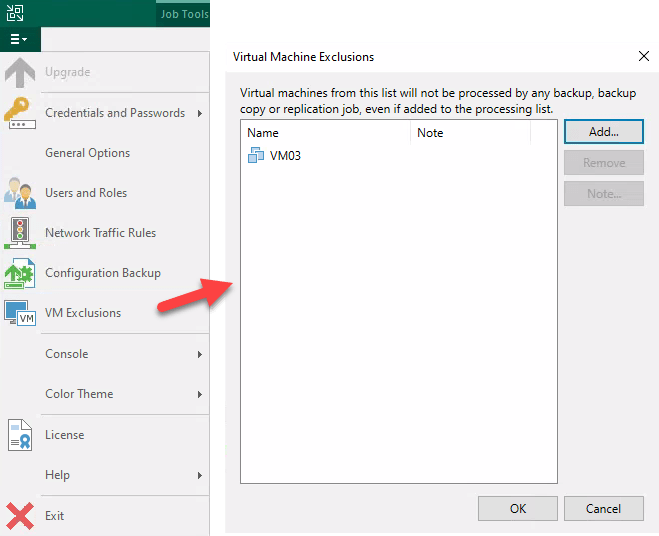
また、便利な機能として、既存のバックアップをタスクから切り離すことができ、次のフルバックアップ実行時に新しいバックアップチェーンが開始されます。切断されたバックアップは、「バックアップ」タブの「孤児」セクションに、最新の保持ポリシーとともに表示されます。
Veeam V12新機能:プライマリーとセカンダリーのストレージの改善
バックアップタスクは、既存のストレージレプリケーションリンクを使用して、追加のリカバリポイントとしてストレージベースのスナップショットに基づくレプリカを作成できるようになりました。これにより、プライマリストレージへの負荷を避けるために、セカンダリストレージアレイからバックアップを取ることができます。
さらに、Veeam のUniversal Storage APIのVer2が導入され、スナップショットレプリケーションとアーカイブのオーケストレーション機能、および同期レプリケーションのサポートが含まれています。Cisco HyperFlex、IBM Spectrum Virtualize、NetApp All SAN Array(ASA)、Dell Data Domain、Infinidat InfiniGuard、富士通 CS800、HPE StoreOnce、HPE Nimble、HPE Alletra 5000/6000ストレージアレイ向けに、バックアップの不変性など多くの重要機能が追加されています。ネイティブブロッククローニング機能の拡張サポートがExaGridストレージアレイに追加されました。
Wasabi Object Lock for Veeam Backup & Replication
オブジェクト・ロック(Object Lock)の利点
オブジェクト・ロックは、指定された期間に達するまで、データがストレージから削除または変更されるのを防ぎます。これは、誰も誤って、または悪意を持って、Veeamバックアップを変更または暗号化できないことを意味します。本質的に、これはランサムウェアに対する究極の保護を提供します。
データ保護の課題
オフサイトに保存されていても、バックアップは危険にさらされています。データを保護するためにデータをエアギャップする従来の方法は、組織のデータが電源から切り離されたLTOテープ・カートリッジやHDDにオフラインで保存されることを意味しました。この方法で保存されたデータを取り出すには数時間から数日かかり、ビットの腐敗や損傷が起こりやすく、最終的にはデータが破壊される可能性がありました。バックアップをイミュータブルにすることで、オブジェクト・ロックはこの脆弱性を排除し、データが保存された場所に正確に残るようにします。データが保存された場所に正確に残ることを保証します。
なぜオブジェクト・ロックが重要なのか?
なぜなら、物事は変化するからです。イミュータブルオブジェクトにより、情報は偶発的または意図的な削除や改ざんから保護されます。一度情報がWasabiホットストレージクラウドに保存されると、ロックの有効期限が切れるか、バケットが完全に削除されるまで(これはまた別の問題ですが)、保存され続けることが保証されます。
サイバー犯罪者はランサムウェアキャンペーンの一環としてバックアップやアーカイブを攻撃するからです。プライマリ・システムをダウンさせるだけでは不十分で、ランサムウェアへのアクセスを確保するためにセカンダリ/バックアップ・システムも攻撃します
なぜなら、規制当局はこれらを定期的にチェックしているからです。コンプライアンスと消費者保護基準のために、規制業界のデータを保護することは必須です。
監視ビデオのようなデジタル証拠に関しては、偽造または改ざんされた映像が今や司法に対する脅威となっているため、法的手続きは親権の連鎖と不変性に依存しています。オブジェクトロック機能は、HIPAA、FINRA、CJISのような特定の政府および業界の規制に対応する組織であり、電子記録、取引データ、および活動ログを安全に提供することができます。
Veeam Backup & Replicationとのオブジェクトロック機能
Wasabiのオブジェクトロック機能は、Veeam Backup & Replication v10以上のEnterpriseおよびEnterprise Plusエディションの両方をサポートします。
WasabiとVeeamによる最も復元力のあるデータ保護ソリューション
業界をリードするバックアップとリストアと不変のホットクラウドストレージを組み合わせて、最高のハイブリッドクラウドデータ保護を実現
データ量とデータ速度は指数関数的なペースで増加し続けており、業界によっては年複利で20%、40%、80%の成長を経験しています。従来のオンプレミスバックアップアプローチは、コストのかかるスケールアップアーキテクチャとクラウド接続性を備えていないため、コンプライアンス規制を満たしたり、ランサムウェア攻撃と戦うために必要なデータ量と増え続ける保持時間に追いつくことができません。
VeeamとWasabiを組み合わせることで、オンプレミスおよびクラウドネイティブなワークロードのための完全なデータ保護ソリューションを提供します。Veeam Backup & Replication (v9.5.4、v10、v11、v12)、Veeam Backup for Microsoft Office 365、Wasabiのホットクラウドストレージ、Object Lockによるバックアップの不変性が含まれます。Veeamの単一的なインターフェースは、バックアップの運用管理をシンプルにし、Wasabiの無制限クラウドストレージは、卓越したセキュリティとデータの不変性を提供します。
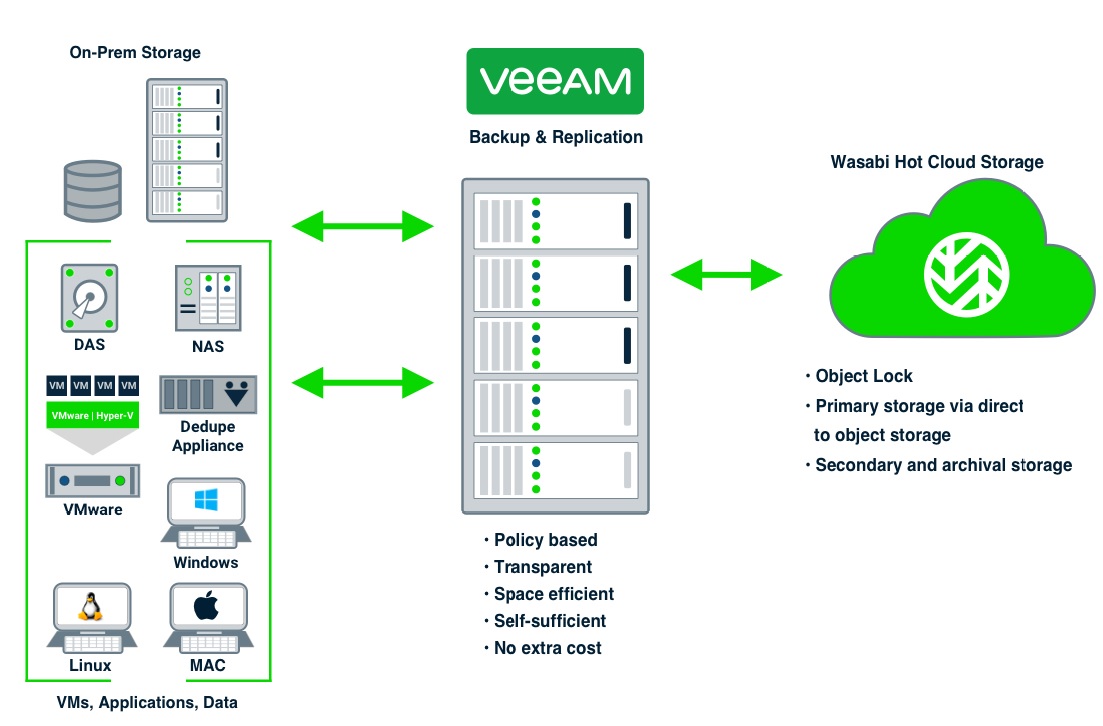
データ保護戦略で最も重要なのは、正確なデータを迅速にリストアし、通常業務を再開する能力です。そのためには、信頼できるバックアップデータと、復旧時間目標(RTO)を満たすストレージ性能が必要です。WasabiのS3 Object Lock APIの実装により、データが改ざんされていないことを確認できます。S3 Object Lockは、組織内外の誰によってもデータが削除されたり変更されたりしないことを保証します。ロックされたデータセットは不変であり、ユーザが定義した期間保持されます。
データ損失の可能性を想定して演習するには、頻繁にリストアの演習をする必要があります。クラウドストレージを使用する場合、データをダウンロードする必要があり、場合によってはギガバイトやマルチテラバイトの規模になることもあります。Wasabiのホットクラウドストレージでは、追加料金はかかりません。部分的または完全なリストアでバックアップデータの完全性を検証する場合、その作業に必要な時間と人以外にコストはかかりません。このため、Wasabiは他のクラウドストレージプロバイダーとは一線を画し、このような作業をより簡単に、低コストで頻繁に実行することができます。
Microsoft Office 365用バックアップ
Veeam Backup for Microsoft 365は、Exchange、SharePoint、OneDrive、Teamsのバックアップとリカバリを可能にします。また、Veeam Backup for Microsoft Office 365は、プライマリ・バックアップ・ストレージ・システムとしてWasabiホット・クラウド・オブジェクト・ストレージをサポートし、大企業および中小企業が短期および長期の保持のため、クラウドの無限の容量を経済的に活用することを可能にします。
Veeam Backup and Replicationがデータ保護を合理化 :バックアップ・ジョブとクラウドへの移行をさらに簡単にします。
Veeam Backup and Recoveryは、古いオンプレミス・バックアップをコピー・ジョブでクラウドに移動するように自動的にスケジュールすることができます。このセット・アンド・フォーゲット機能は、オンプレミスシステムが常に利用可能なディスクスペースを維持し、最高のRTOのためにリストアパフォーマンスを最大化することを保証します。また、バックアップをローカルストレージとクラウドに同時に送信するように設定することもできます。これにより、オフサイト・バックアップが劇的に簡素化され、3-2-1-1-0ガイドラインに準拠することができます。
Veeam Backup and Replicationは、異なるクラウド・オブジェクト・ストレージ・レポジトリ間のデータ移行をサポートします。例えば、AWS S3を使用していたが、Wasabiホット・クラウド・ストレージに変更することを決定したとします。この機能を使えば、AWSからWasabiにデータを移行することができます。
非構造化データの保護を簡素化
WasabiはVeeam Ready Objectとして、またVeeam Ready Object – Object Lockとして認定されています。Wasabiは現在、Veeam Backup and Recoveryの名前付きクラウドストレージサービスです。
Wasabiホットクラウドストレージが画期的な経済性とデータセキュリティを実現
Wasabiホットクラウドストレージは、低コスト、高速、信頼性の高いクラウドストレージをオンデマンドで提供します。Wasabiは、全てのデータを「ホット」に保ち、数ミリ秒でアクセスできるようにします。すべてのVeeamとWasabiのユーザは、データをホットデータとして扱うことができるため、バックアップウィンドウを短縮し、データに素早くアクセスして、リストア時間を短縮することができます。
バックアップ対象の仮想マシン名は日本語でも問題ないですか?
仮想マシン名に日本語が含まれている影響で、バックアップやリストア中に予期せぬ動作を引き起こす可能性があります。
※例えば、38文字以上のVM名(日本語)の VMからファイルリストアを行う際に失敗する可能性があります。
そのため仮想マシン名やネットワーク名等はなるべく英数字での記載をお願いいたします。
Hyper-Vでパススルーディスクは処理可能ですか?
Hyper-V上の仮想マシンに接続されたパススルーディスク(物理ディスク)のバックアップおよびレプリケーションはHyper-V側の制約により行うことができません。処理はスキップされます。
仮想ディスク部分は正常に処理されます。
バックアップを取得している仮想マシンのデータストアを、ストレージvMotionで別のデータストアに移動した場合、差分バックアップを継続できますか?
VMware 5.5 Update 2以降でしたら、継続して差分バックアップを行うことが可能です。
それ以前のバージョンですと、VMwareの制限に引っかかり、CBTがリセットされてしまいます。
■ Change Block Tracking が vSphere 5.x でのストレージ vMotion 操作の後でリセットされる
関連トピック
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
バックアップ対象の仮想マシンをStorage vMotionで移動した後、バックアップジョブを作り直す必要がありますか?
バックアップが不可能なディスクタイプはありますか?(VMware)
Veeamはバックアップの際にスナップショット機能を利用します。そのためこの機能が利用できない物理モードのRow Device Mappingではバックアップが行えません。
またリストアやレプリケーションの際に作成するVMにつきましてはThickもしくはThinディスクでの作成が可能です。
アップデートや再インストール時にVeeamの設定情報を引き継げますか?
はい、引き継げます。
Veeam Backup & Replicationの設定情報はSQL Serverに保存されているため、既にあるVeeam Backup & Replicationのインスタンスを再利用することで設定情報等の引き継ぎが行えます。
しかしバージョンアップに伴い表の構造等が変更されますので、基本的には同一バージョンもしくは上位のバージョンでのみ再利用が可能です。古いバージョンを再インストールした際に、インスタンスの再利用が行えない場合もございますので、お気をつけください。
Hyper-Vの無償版(Microsoft Hyper-V Server) には対応していますか?
はい。Veeam Backup & Replication は、Hyper-V のすべてのバージョンをサポートします。
Veeam Backup & Replication と vCenter Serverを同じマシンに導入してもいいですか?
技術的にはVeeam Backup & Replication(Veeam B&R)とvCenter Serverを同じWindowsマシンに導入することは問題ありません。
しかし、この2つのソフトウェアを同居させることは推奨しておりません。
理由として以下の3点があげられます。
- 双方ともにリソースを消費しやすいソフトウェアであり、リソースの適切なプロヴィジョニングが難しいこと
- 片方に障害が発生しマシンの再起動が必要となった場合、もう片方の動作に影響をおよぼすこと
- 双方ともにデフォルトのインストールではSQL Server Express Editionをインストールし使用しますが、Express Editionは使用可能なリソースに制限が加えられており、VeeamとvCenter双方からの激しいアクセスに耐え切れず双方の挙動に影響を及ぼすことがあること
これらの理由のため、可能であれば別々のマシンにインストールしていただくことを推奨しております。
Veeam Backup & Replicationのインストール先で物理マシンと仮想マシンの違いはありますか?
基本的にはどちらも同様に使用できます。
しかし、仮想マシンでは物理接続のデバイスが使用できません。
また、Veeamサーバの負荷がホストにも影響します。
Contract No.とは何ですか?
Contract No.はユーザがVeeam/クライムとのサポート・保守に加入した最新(または最後)の追跡番号です。
この番号はユーザのライセンス・ポータルでも確認することができます。
サポート・保守更新時には必ず必要になりますので、Contract No.をお問合せください。
サポート・保守が更新されますと、暫くした後、新たなContract No.がアサインされます。
以前のContract No.では追跡ができなくなります。
バックアップ対象の仮想マシンについて、OSの違いによるバックアップの可/不可はありますか?また、仮想マシンの電源ON/OFFの違いによるバックアップの可/不可はありますか?
仮想マシンの電源ON/OFFの違いやOSの違いによるバックアップの可/不可はありません。
また、OSをインストールしていない状態の仮想マシンであってもバックアップ可能です。
関連トピック
Veeam Backup & Replicationを物理サーバにインストールする場合に自身のバックアップは 他のソリューションで行うことになりますか?
Veeam Backup & Replicationサーバは仮想または物理環境のどちらでもインストール可能です。
自身のバックアップについては接続情報や構成情報のみであればConfiguration Backup機能でバックアップ可能です。
https://www.climb.co.jp/blog_veeam/veeam-backup-7953
OSのイメージごとバックアップする場合は、仮想マシンにインストールしていればVeem自身でバックアップ可能です。
物理環境にインストールした時にはVeeam Agentを導入することでバックアップが可能です。
Windows Storage Server をVeeamサーバとして利用可能ですか?
Windows Storage ServerとWindows Serverは同じコードを元に構築されているため、基本的には全てのVeeamのコンポーネントをStorage Server OS上にインストール可能です。
Veeam Server console
Veeam Backup Proxy
Vpower NFS server
WAN accelerator
Backup repository
しかし、Windows Storage Serverはベンダーによってカスタマイズされていることが多く、.NETの機能が有効化されていない場合や.NET Frameworkのインストールに問題がある場合があります。このような場合にはVeeam ServerのGUIは.NETコンポーネントに依存しているため、インストールすることができません。
.NETコンポーネントについてWindows Storage Serverのエンドユーザライセンス(EULA)のご確認やベンダーへのお問い合わせをお願いいたします。
EULAのパス C:\windows\system32\license.rtf
開発元KB http://www.veeam.com/kb1923
vCloud Directorに対応していますか?
はい、対応しています。
サポートするプラットフォームについてはこちらをご参照ください。
vCenter Serverの登録は必ず必要ですか?
スタンドアロンのvSphereホストの登録が可能なので、必須ではありません。
vCenter Serverを登録しておくと、VMwareのHAやDRSで仮想マシンが移動した場合も、
移動先を追跡しJobの継続実行が可能です。
EMC DataDomainをリポジトリにする場合、EMC DataDomain Boostは必須ですか?
必須ではございません。
ただし、Veeamとの連携機能は使用できないため、通常の重複排除ストレージとして使用します。
その場合には、リポジトリの種類は「Dedupe Storage」ではなく、「CIFS」として登録します。
差分リストアはできますか?
Veeam Backup & Replication Ver8からQuick Rollbackという機能が追加されました。
これは差分データ・リストア機能です。
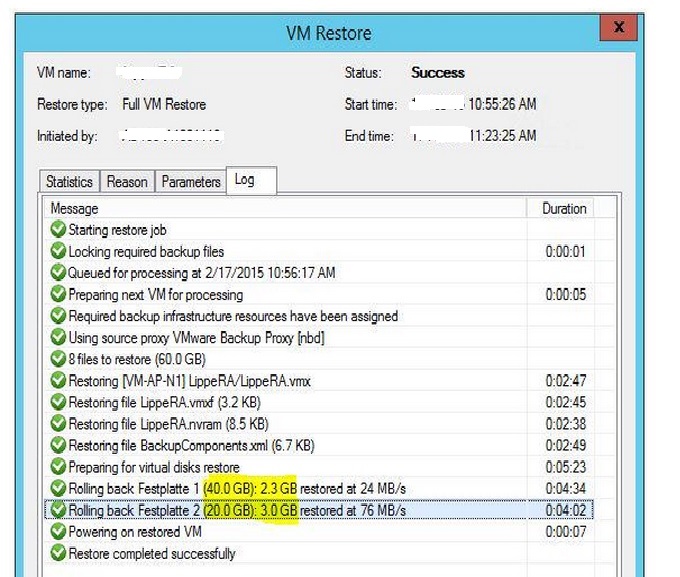
このQuick Rollback機能の使用制限:
1. Network または Virtual Appliance モードのみで使用可能。VMwareサイドの制限でDirect SAN Accessモードでは使用できません。
2.続けて2つの差分リストア・セッションを実行することは出来ません。VMまたはVMディスクに対して差分リストアを実行した後にそのVM上のCBTはリセットされます。差分リストアが再度実行できるように最低1回の差分バックアップを実行する必要があります。
Version 9で作成したバックアップファイルをVersion 8で使えますか?
使用できません。
古いバージョンから新しいバージョンへアップグレードした際には、
そのままバックアップファイルを使い続けることが可能ですが、
新しいバージョンのファイルを古いバージョンで扱うことはできません。
LVM構成のLinuxからファイル単位でリストアできますか?
可能です。
その他対応しているファイルシステムの詳細は下記弊社ブログ記事をご覧ください。
Veeamのファイルレベルリストアはここが違う!多くのファイルシステムをサポートできる理由とは?
IDEとSCSIが混在しているVMをバックアップした時、SCSIもVirtual Applianceモードで処理できない。
IDEとSCSIが混在しているVMの場合、すべてのディスクでVirtual Applianceモードが使用できないのは仕様となります。
バックアップ処理が開始される前にすべてのディスクをチェックしており、一つでもHotAddが使用できないディスクがあるとすべてのディスクがNetworkモードで処理されるようになっています。これはVDDKの制限です。
サポートの回数に制限はありますか?
回数に制限はありません。
レプリケーション先にはどの程度のディスクスペースがあれば良いですか?
仮想マシンのディスクタイプにはシンプロビジョニングとシックプロビジョニングがありますが、
それぞれに必要なディスクスペースに違いがあります。
これはシンとシックではストレージ領域の確保方法に違いがあるためです。
シンプロビジョニングで作成した仮想マシンの場合は
ストレージ領域が必要になるごとに領域を確保するため、
レプリケーション元の仮想マシンで使用済みのディスクサイズ分の
フリースペースがレプリケーション先に必要です。
シックプロビジョニングで作成した仮想マシンの場合は
仮想マシン作成時に指定したサイズ分の領域を確保するため、
レプリケーション元の仮想マシン全体のディスクサイズ分の
フリースペースがレプリケーション先に必要です。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
VMware と Hyper-V の両方で、Veeam Backup & Replication の同等の機能を使用できますか?
VMwareとHyper-Vではアーキテクチャが異なるため、完全に同等とまではいきませんが、ほぼ全ての機能を1つの統合されたコンソールから利用可能です。
日本語対応していますか?
ソフトのメニュー類は日本語には未対応です。
しかし、直観的なクリック操作で簡単に扱える製品となっておりますし、
日本語の製品マニュアルもご用意しておりますので使用には問題ありません。
“Commit Failback” と “Undo Failback” の処理の違いを詳しく知りたい。
■Commit Failback
レプリケーション先の VM をレプリケーションジョブを実行できる状態(“Failover” を実行する前の状態)にします。
■Undo Failback
レプリケーション先の VM を “Failback” を実行する前の状態(“Failover” を実行している状態)に戻します。
どちらもレプリケーション先の VM の状態を変更する機能です。
そのため、”Undo Failback” を実行した場合でも、
レプリケーション元の VM は変更が反映された状態(“Failback” 実行後の状態)のままになります。
Veeam Server 自身のレプリカを作成して、本番機が破損したときにレプリカの Veeam Server でジョブの実行などを継続できますか?
可能です。
当然ながら、各ジョブのリストアポイントはレプリケーションジョブを実行したタイミング(レプリカへ本番機のデータをコピーしたタイミング)のものになりますが、レプリカのほうからバックアップ、レプリケーション、フェイルオーバーなどが実行できます。
ただし、本番機への切り戻しは行えませんので、以降はレプリカを本番機として使用する必要がございます。
製品には初年度保守が含まれますか?
はい、含まれます。
サブスクリプションライセンス期間内は保守サポートのご利用が可能です。
ジョブ実行時にCBT(Change Block Tracking)が有効になっているか確認する方法はありますか?
Veeamのコンソール画面からジョブを右クリックして “Statistics” を開きます。
“Action” ログの中に “Changed block tracking is ~” と書かれており、有効化されていれば “enabled”、無効化されていれば “disabled” となります。
ジョブ実行前からゲストOSにスナップショットが存在するなどの理由で、CBTが有効にできなかった場合、ジョブ終了後にワーニングとして表示されます。

既存のレプリカVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションが行えますか?
オリジナルの仮想マシンとレプリカの仮想マシンをマッピングすることで、
差分レプリケーションからジョブを開始することができます。
参考: レプリカシーディング・レプリカマッピング機能について
関連トピック
レプリケーションしたいVMのクローンVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションを行えますか?
サポートは最新バージョンのみですか? 古い(前の)バージョンもサポートしてもらえますか?
最新バージョン以外の古いバージョンのサポートも承っております。
しかし、開発元(Veeam 社)の正式サポートは最新バージョンとその1つ前のバージョンまでとなります。(例:2022年1月現在のVeeam Backup & ReplicationのバージョンはVer11.0、10.0、9.5、9.0、8.0、7.0、6.5…と存在していますが、このときの正式サポート対象はVer11.0、10.0 となります。)
そのため、古いバージョンの場合、いただいたご質問の内容によっては開発元からのサポートを受けられず、アップグレードをお願いすることになりますので、ご了承ください。
Veeamでバックアップを行ったとき、どの時点の状態でバックアップファイルが作成されますか?
ジョブ実行後、スナップショットが作成され、それを元にバックアップを取得します。
そのため、スナップショットを作成した時点の状態でバックアップファイルは作成されます。
ライセンス体系はどのようになっていますか?
サブスクリプション(年額前払)形式となります。
1ライセンスにつき10個まで以下対象を保護できます。
●1仮想マシン(vSphere/Hyper-V/AHV)
●1物理サーバ(Windows/Linuxなど)
●1クラウドインスタンス(AWS/Azure/GCP)
●500 GB分のNASデータ
※Veeam Backup Essentials の場合
1ライセンスで5台(1環境につき50台の制限)
詳細はこちら
Veeamでバックアップする際に、バックアップ対象の仮想マシンのデータは直接リポジトリ(バックアップ保存先)へ転送・保存されますか?
Veeamではプロキシサーバ(デフォルトではVeeamをインストールしたサーバ)で重複排除や圧縮を行ったあと、リポジトリ(バックアップ保存先)に転送して保存されます。そのため、直接ではなくプロキシサーバを経由することになります。
独自のスクリプトで静止点を取得している場合、どこで終了を確認していますか?
スクリプト終了時に返される終了コードでスクリプトの成功、失敗を判断しています。
終了コードが0以外の場合は静止点の作成に失敗したものとして、スナップショットの取得に失敗します。
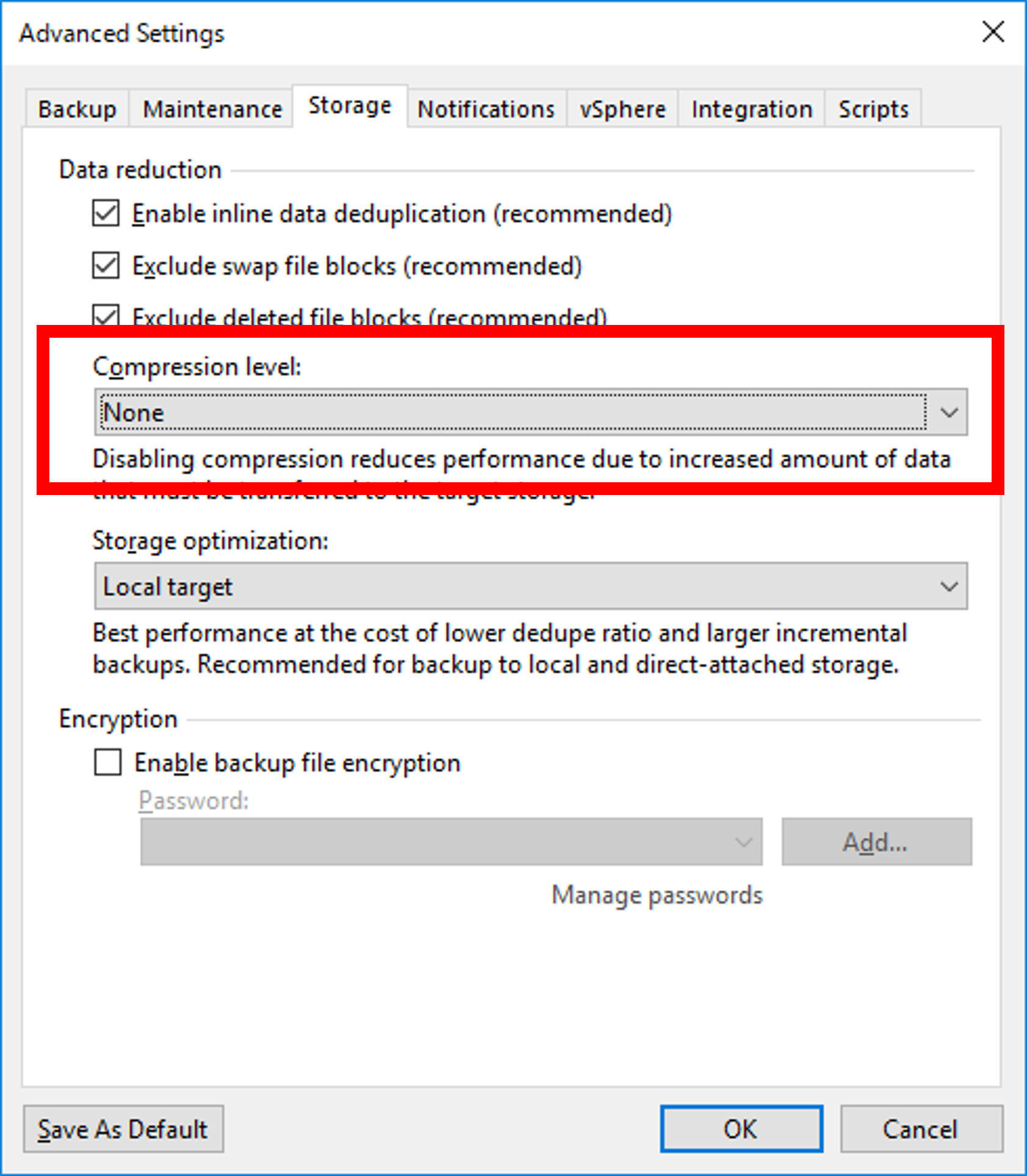
バックアップファイルの圧縮を無効にできますか?
可能です。
Veeamでは圧縮率に関するオプションが用意されており、
バックアップジョブごとに設定が可能となっております。
対象のジョブを右クリック > Edit > Storage > Advanced > Storage
“Failover” と “Undo Failover” の動きの違いを教えてほしい。
■Failover
ターゲットホストのレプリカVMを起動する機能です。
オリジナルのVMに障害が発生した場合に、レプリカ VM で処理を引き継ぎます。
■Undo Failover
Failover機能により電源ON状態となったレプリカVMを電源OFF状態に戻す機能です。
レプリカVMへ行われた変更は破棄されます。
リストア時の処理方法について教えてください。
Veeamには3つの処理モードが用意されております。
・ダイレクトストレージアクセスモード
・バーチャルアプライアンスモード
・ネットワークモード
参考
バックアップ、レプリケーション時の処理モードX 3
VMware環境での3つの転送モード方式と処理の流れ
処理モードの中では一番の高速バックアップ【Veeam Backup & Replication:Direct SANモード】
手間とコストをかけずに簡単に高速バックアップ【Veeam Backup & Replication:Virtual Applianceモード】
特別な条件の必要ない簡単・確実なバックアップ【Veeam Backup & Replication:Networkモード】
バックアップ時、リストア時にどの条件を満たしているかによって処理モードが変更されます。
しかし、リストアの場合は処理モードがVirtual ApplianceモードとNetworkモードのみ使用可能となっております。
関連トピック
VMwareのHot add機能を利用したバックアップは可能か?
SAN内の仮想マシンを別のSANにバックアップする際にモード選択でSANモードで処理可能か?
RDMで構成された仮想マシンのバックアップは行えますか?
Veeamでバックアップを取得するためには仮想マシンのスナップショットが取得できる必要がございます。そのため、スナップショットをサポートしていない物理互換のRDMはバックアップが行えませんが、仮想互換のRDMであればバックアップを取得可能です。
RDMで構成された仮想マシンのリストアはどのように行われますか?
Veeamでは仮想互換のRDMであればバックアップ/リストアが可能です。
仮想マシンのバックアップを取得時にRDM領域はvmdkファイルに変換されます。そのため、リストア時にはRDM領域はvmdkファイルに置き換えられてリストアされます。
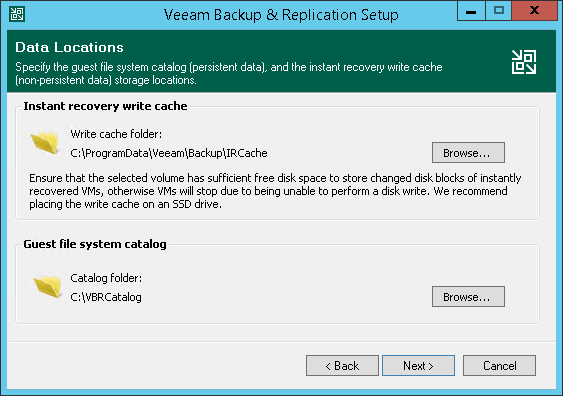
インストール時にカタログファイルの保存先を変更したい。
カタログファイルの保存先はWindowsの共有設定が行える必要がございます。そのため、ネットワークドライブなどは指定するとインストール中にエラーとなり、インストールが終了できません。
複数のジョブを同時に実行中、次のメッセージが表示され実行されないジョブがあります。「Waiting for backup infrastructure resources availability」
これは、複数ジョブを実行するためのリソースが不足しているため、処理中のジョブが終了し、リソースが解放されるまで待機状態になっていることを表しています。
そのため、複数のジョブを同時刻に実行したいということであれば、ジョブごとにプロキシサーバ(処理サーバ)を用意していただくか、プロキシサーバのスペックをあげていただく必要がございます。デフォルトではVeeamサーバがプロキシサーバとして動作します。
インスタントVMリカバリ実行中に元の仮想マシンに対してバックアップを行えますか?
Veeamには2つのバックアップモード(増分・差分)があり、増分バックアップであれば実行中にもバックアップ可能ですが、差分バックアップの場合は行えません。
差分バックアップは毎回フルバックアップファイル(vbk)に差分をマージするのでvbkに書き込みを行います。しかし、インスタントVMリカバリではバックアップファイルから直接仮想マシンを作成するため、フルバックアップファイル(vbk)をロックします。そのため、vbkに書き込みが行えずエラーとなります。
増分バックアップでは増分ファイル(vib)の作成は行いますが、vbkに対して書き込みを行わないためバックアップ可能となります。しかし、バックアップファイルの変換オプション(Transform previous full backup chains into rollbacks)を有効にした場合は、増分バックアップは問題ありませんが、フルバックアップ時には増分ファイルを差分ファイルへ変換する処理が入りますので、ファイルがロックされるインスタントVMリカバリ中にフルバックアップは行えません。
vSphereのVMFS領域をバックアップ先として使用できますか?
バックアップ先ストレージとして利用可能なのはWindows、Linux、共有フォルダとなっています。
登録可能なデータ保存先(リポジトリ)
ESXにはLinuxをベースとした管理用OSが搭載されているため、Linuxのバックアップ先ストレージとして利用可能でした。
しかし、ESXi(vSphere5.1)はこの管理用OSを削除しており、直接バックアップ先ストレージとして利用できなくなっております。そのため、vSphere5.1上に仮想マシンを登録し、その仮想マシンをバックアップ先として利用する必要があります。
ジョブの複製はできますか?
Enterprise / Enterprise Plusエディションで可能です。
通常のVeeam Backup & ReplicationコンソールとEnterprise ManagerのWebコンソールから行えます。
しかし、Standardエディションでは対応しておりません。
ジョブのパラレルタスク(複数ディスク同時処理)の数に制限はありますか?
制限はありません。
ジョブを実行するプロキシサーバの性能に依存します。
おおよそ、1タスクに1CPUです。
ネットワークの帯域制限は行えますか?
はい、行えます。
Veeamではプロキシ – プロキシ間、プロキシ – リポジトリ間で帯域制限を行います。
そのため、vSphereホストからバックアップを行う際にネットワーク経由で以下のように処理を行っておりますと、vSphereホスト – プロキシ間では帯域制限は実施されず上限までネットワークを使用します。プロキシ – リポジトリ間では帯域制限が実施されます。
例) vSphereホスト – プロキシ – レポジトリ
Veeam Backup & ReplicationサーバをVMware FT(Fault Tolerance)で構成したい。
VeeamサーバをVMware FT構成にすることは、基本的には問題ありません。
しかし、いくつか注意点がございます。
1.Veeamのコンソールとして使用するのは問題ないですが、プロキシとして使用するのは非推奨となります。もし、Virtual Applianceモードでバックアップを実行していた場合、処理途中で仮想マシンが切り替わるとVirtual Applianceモードが動作しなくなります。
2.バックアップ保存先への接続はNASかCIFSを使用する必要があります。Veeamサーバに直接接続されたディスクを使用すると、切り替わった際に機能しなくなります。
サポートしているテープの種類は何ですか?
テープ・ライブラリ・コンパチブル・リスト(Unofficial)
ADIC Scalar 100
Dell PowerVault 124T
Dell PowerVault 136T
Dell PowerVault TL2000
FalconStor (VTL) [VERIFIED]
Fujitsu Eternus LT40
HP ESL 712e
HP MSL G3 Series 4048
HP MSL G3 Series 8096
HP MSL 6030
HP MSL 6480
HP StorageWorks 1/8 G2 LTO-3 Ultrium 920
HP StorageWorks LTO-4 Ultrium 1840 SCSI
HP StoreOnce (VTL) [MSL series emulation]
IBM TS3100
IBM TS3200
IBM TS3310
IBM TS3500
IBM ProtectTier 7650 (VTL)
IBM ULTRIUM HH5 SCSI
Overland NEO 100s [VERIFIED]
Overland NEO 200s [VERIFIED]
Overland NEO 400s [VERIFIED]
Overland NEO 2000e [VERIFIED]
Overland NEO 4000e [VERIFIED]
Overland NEO 8000e [VERIFIED]
Quantum Scalar i40
Quantum Scalar i80
Quantum Scalar i500
Quantum Scalar i6000
QUADStor (VTL) [IBM TS3100/3580 emulation] [VERIFIED]
Qualstar RLS
Spectra Logic T50e [Quantum P7000 emulation]
Tandberg T24 [VERIFIED]
Tandberg T40+ [VERIFIED]
Tandberg T80+ [VERIFIED]
Tandberg T120+ [VERIFIED]
Tandberg T160+ [VERIFIED]
Tandberg RDX Quikstation (VTL) [T80+ emulation] [VERIFIED]
mhVTL (VTL) [64KB block size] [VERIFIED]
プロキシサーバの設置台数に制限はありますか?
プロキシはVeeamのライセンスに依存せず、台数制限もございません。
バックアップ対象の仮想マシンをStorage vMotionで移動した後、バックアップジョブを作り直す必要がありますか?
バックアップジョブにvCenter経由で仮想マシンを登録していれば、Veeamは仮想マシンに割り振られた参照IDを追跡しますので、ジョブの作り直しは必要ありません。
参考: vMotionやStorage vMotionに対応したジョブの作成
しかし、Storage vMotion実施後は仮想マシンのCBTがリセットされるため、実施後最初のバックアップはフルバックアップになります。
参考: Change Block Tracking is reset after a storage vMotion operation in vSphere 5.x
関連トピック
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
バックアップを取得している仮想マシンのデータストアを、ストレージvMotionで別のデータストアに移動した場合、差分バックアップを継続できますか?
並列処理(Parallel Processing)が利用可能なジョブは何ですか?
Veeamの並列処理が利用可能なジョブは、バックアップジョブとレプリケーションジョブ、バックアップコピージョブとなりますが、WANアクセラレータを使用したバックアップコピージョブは逐次処理になります。
※バックアップコピージョブが並列処理になったのはver9.0以降になります。
ジョブに失敗したときにリトライする設定にしている場合、通知メールは毎回リトライの度に送信されますか?
自動リトライを設定している場合、通知メールはジョブがSuccess/Warningになるか、指定回数分のリトライ処理が終わった時にまとめて送信されます。
警告(warning)と失敗(failure)のときに通知を行い、成功(success)のときは通知しない設定にしている場合、最初のジョブで失敗、リトライジョブで成功したらメール通知はされますか?
通知されません。
通知メールはリトライも含めた最終的なジョブ結果に基づいて送信されますので、リトライの結果、ジョブがSuccessになれば通知されません。
バックアップデータからのリストアでできることは何ですか?
バックアップデータからは、下記リストアが可能です。
・新規の仮想マシンの作成
・VMDK、VMX等の仮想マシンの構成ファイルのリストア
・Amazon EC2やAzure VMとしてクラウド環境へ仮想マシンをリストア
・ファイルレベルのリストア
・一部アプリケーションのアイテム
Active Directory、SQL Server、Exchange など
※Standardエディションでは制限がございます。
https://www.climb.co.jp/soft/veeam/outline/price.html#price02
https://www.climb.co.jp/soft/veeam/detail/restore.html#detail4
既にバックアップを実施している仮想マシンの名前を変更しても処理に影響はありませんか?
影響ありません。
問題なくバックアップ、リストア、レプリケーション等を行えます。
レプリケーションデータからのリストアでできることは何ですか?
レプリケーションデータからは、下記リストアが可能です。
・レプリケーション(複製)した仮想マシンの起動
・ファイルレベルのリストア
・一部アプリケーションのアイテム
Active Directory、SQL Server、Exchange など
※Standardエディションでは制限がございます。
https://www.climb.co.jp/soft/veeam/outline/price.html#price02
https://www.climb.co.jp/soft/veeam/detail/restore.html#detail4
関連トピック
バックアップデータからのリストアでできることは何ですか?
Windows Server 2012のファイルシステムReFSとNTFSはファイルレベルリストアでサポートしていますか?
サポートしています。
但し、VeeamサーバをWindows Server 2012以降で構築する必要があります。
バックアップ格納先を外付けのディスク(NAS、USB)にして定期的にディスクの交換は可能ですか?
はい、可能です。ただしディスク交換後の初回のバックアップはフルバックアップを行う必要があります。
管理できる世代数はどのくらいですか?
ジョブごとにバックアップで1~999世代、レプリケーションで1~28世代取得可能です。
HTMLレポートの”Data read”、”Dedupe”、”Compression”から”Backup size”を計算してみたが、誤差があるのはなぜか?
重複排除率や圧縮率は細かい値が丸められているため、計算した場合多少の誤差が発生します。
バックアップ/レプリケーションの対象となっているゲストOSのディスクサイズを拡張したらどうなりますか?
【バックアップ】
ディスクサイズが変更されたことによりCBTがリセットされます。
そのため、変更後最初の一回は全データを読み込むことになります。
二回目以降は差分でのバックアップが可能です。
【レプリケーション】
既存のリストアポイントがすべて削除され、
新たなリストアポイントが作成されます。
レプリケーションやリストアで作成したHyper-V仮想マシンのMACアドレスが、動的から静的に変更されます。
MACアドレスが動的から静的に変更されるのは、Veeam B&Rの仕様になります。
ソースマシンのMACアドレスを保持するために静的に変更しています。
Veeamが使用するSMBのバージョンは何ですか?
Veeam自身はSMBに関する機能は持っておらず、インストールされているWindowsのSMB機能を利用します。
そのため、使用するSMBのバージョンはVeeamがインストールされているWindowsのバージョンおよびデータ転送先のデバイスの対応状況に依存します。
レプリケーション途中でネットワーク接続が切断されたとき、どのような挙動となりますか。
バージョン7.0のパッチ2(R2)より、レプリケーション中に、ソースとターゲットのサイト間のネットワーク接続が切断されたとき、ソースとターゲットのプロキシサーバの再接続を試行し、レプリケーションを途中から再開する機能が追加されています。
デフォルトでは切断から5分の間、10秒ごとに接続のリトライを行います。
この時間を過ぎますと、エラーとなります。
Backup Job作成時のオプション “Retention policy” で設定した数以上のリストアポイントが作成されてしまいます。
Backup Job作成時に「Backup Mode」がIncrementalモードで、「Synthetic full」が有効になっている場合、設定した世代数をキープするため、設定したリストアポイント数より多くのリストアポイントが作成されます。
※バージョンによっては”Restore points to keep on disk”と表記されております。
参考:
増分・差分による保持するバックアップファイルの違い
世代を管理するバックアップチェーン
バックアップモードによる保持するバックアップファイルの違い【Veeam Backup & Replication】
8時間毎にバックアップを行うよう、スケジュールを設定できますか?
はい、設定可能です。スケジュール設定画面にてPeriodically every(定期的)の時間を設定すると、指定時間毎に動作します。
参考
Job作成時のスケジュール(除外設定機能)について【VMWare専用 バックアップ & レプリケーションソフト Veeam】
複数の仮想マシンをまとめてバックアップは可能ですか?
はい、可能です。下記の単位でのバックアップが可能です。
・クラスタ
・フォルダ
・リソースプール
・Virual App
・ホスト
・ユーザーが選択した仮想マシン
テープへ直接バックアップできますか?
Veeamはテープへの2次バックアップをサポートしております。
一度ディスク上にバックアップしていただき、そのバックアップファイルをテープへ2次バックアップします。
Veeam製品(Backup & Replication、ONE)を1台のマシンにインストールする際の注意点はありますか?
どちらもSQL Serverを使用するため、SQL Serverへの負荷が高くなり、それによってバックアップジョブへ影響が出る可能性もございます。特にデフォルトでは、Expressエディションがインストールされるため、影響が出やすいかもしれません。
レプリケーションで作成された仮想マシンは障害時に自動で起動させることはできますか?
自動で起動させる機能はありません。VeeamコンソールもしくはvSphere (Web) Clientから手動でのフェイルオーバーが必要です。
Jobの終了時にバックアップ先のディスクの空き容量が不足していると警告が表示されます。
Veeam Backup & Replicationではバックアップ先のディスクの空き容量が設定した容量より少なくなった際に警告を表示します。
デフォルト設定では、空き容量が10%以下になった場合、警告を表示します。
また、バックアップ先のディスクの空き容量が設定したしきい値よりも下回った場合、VMのスナップショット取得の処理を行わずにジョブを終了させる設定もございます。
※デフォルト設定では、しきい値は5%となっております。
この設定はVeeamの管理コンソールから「Options」>「Notifications」タブで設定可能です。
特定のジョブ終了後に次のジョブを起動させることは可能か?
可能です。スケジュール設定時に “After this job” を選択してください。
指定したジョブ終了後に作成したジョブを実行します。

レプリケーション処理の2回目以降は差分処理を行いたいが、Job作成時に設定する必要はありますか?
Job作成時のデフォルト設定のままで2回目以降が差分処理になります。
レプリケーションのJobスケジュール設定で、”Continuously” とあるが、これはどのような機能ですか?
これはJobを常に実行し続けます。Jobが終了するとすぐにJobを開始するという機能です。
仮想マシンのバックアップまたはレプリケーションをできる限り最新の情報を取得したい場合に使用するモードですが、常に動作しますので、リソースや容量に注意が必要です。
レプリケーション時にvSphere(A)にのみ存在するネットワークラベルをもつ仮想マシンをvSphere(B)にレプリケーションした場合、仮想マシンにはvSphere(B)に存在するネットワークラベルが自動で設定されますか?
Replication Job設定時にレプリカVMのネットワーク設定を行うことができます。
Job実行時の暗号化方式はどのように行っていますか?
SSLで暗号化しています。
平日の指定した時間にバックアップするようにスケジュールを設定できますか?
はい、設定可能です。スケジュール設定画面にて Daily at this time を on week-days と設定すると、平日のみ動作します。
また、on these days にて任意の曜日を選択することも可能です。
バックアップ処理を起動しない時間の指定(除外時間設定)は可能ですか?
はい、設定可能です。スケジュール設定画面にてPeriodically every(定期的)の設定で除外時間設定ができます。
アプリケーション実行中にバックアップは可能ですか?
はい、バックアップ可能です。
但し、アプリケーション側で制約がある場合、リストアした際、不具合が発生する可能性があります。
処理終了後に、バッチ処理を行うことは可能ですか?
はい、バックアップ、レプリケーション時は処理終了後、コマンド実行することができ、別の処理を行うことが可能です。
2TBを超える仮想マシンのバックアップは可能でしょうか?
はい、可能です。ディスクの作り方によって2TBを超える仮想マシンのバックアップ、レプリケーションを行うことができます。
詳しくはブログへ記載してあります。 ≫
レプリケーション後のレプリカVMの起動をvSphere Clientから行いたい。
はい、可能です。
任意の時点のスナップショットに戻してからレプリカVMを起動してください。
しかし、vSphere clientから起動することでVeeamから管理を行うことができなくなり、Failback(オリジナルへの切り戻し)が行えなくなります。プライマリサイト復旧後は、新規にレプリケーションジョブを作成してDRサイト⇒プライマリサイトの方向にレプリケーションを行う必要があります。レプリカVMを停止することでまたVeeamから管理することが可能になりますが、レプリカVMに対して行われた変更は反映されません。
バックアップとレプリケーションを同時に実行することは可能か?
はい、可能です。但し、同じ仮想マシンに対して同時に複数の処理を行うことはできません。
また、レプリケーションジョブ実行中に処理中のレプリカVM起動(Failover to Replica)やSureBackupで実行中のバックアップジョブを指定して実行するようなこともできません。
レプリケーション機能で作成した仮想マシンのIPアドレスは複製元と同じになりますか?
ソースVMが静的IPアドレスで設定されている場合、同じIPアドレスで複製のVMが作成されます。
レプリケーションジョブのオプション機能で、ジョブ作成時に複製VMのIPアドレスを指定することも可能です。
バックアップ時にできる差分ファイル(vib, vrb)のサイズはどうやって決まるか?
仮想マシンのサイズや変更分に影響し、指定したリストアポイント数分差分ファイルを作成します。
起動中のバックアップJobをユーザー側で停止後にJobを再開させることは可能ですか?
可能です。
例)起動中のJob(A)をユーザーが停止後にJob(A)を再開した場合にはJob(A)が正常終了して作成しているバックアップファイルからの変更部分(増分、差分)のバックアップファイルを作成します。
関連トピック
プロキシサーバの台数を増やせば処理速度は向上しますか?
Veeamは仮想ディスク単位で並列処理が可能なため、プロキシサーバを増設したり、プロキシサーバの性能を上げることで、同時に処理するVM数を増やすことが可能になるので、処理速度の向上が望めます。
仮想マシンのスナップショットまでリストアできますか?
スナップショットはリストアできません。
バックアップ・レプリケーションではスナップショットの構成や情報を保持しているわけではないため、スナップショットの情報は保持されません。
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
VMwareのStorage vMotionを実行する条件の1つに「仮想マシンがスナップショットを保持していないこと」があります。
Veeam Backup & Replicationではバックアップ時に処理対象の仮想マシン内にスナップショットを取得しますが、処理の最後にスナップショットを削除します。
※Veeamの処理中(仮想マシンにスナップショットが残っている時)にStorage vMotionが実行された場合にはStorage vMotionは失敗します。
Job作成時にCBT機能を無効にした場合には処理にどのよう影響がありますか?
CBT機能を無効にした場合、前回のバックアップからの変更箇所を追跡できないため、毎回VMの全データを読み取る必要があります。
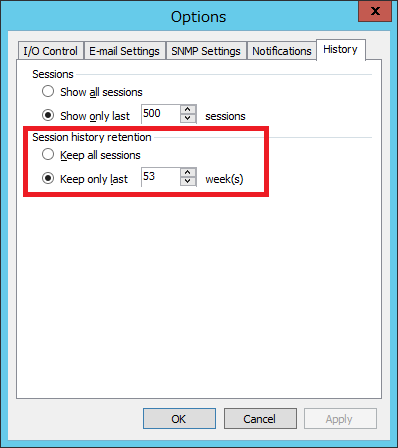
Historyはどの位保持されますか?
デフォルトでは53週間(1年間)保持します。コンソールから変更可能です。
Backup Jobのオプション “Remove deleted items data after” はどのような機能ですか?
仮想環境から削除された仮想マシンを、バックアップデータ内で保持する期間の設定です。
VM削除時のバックアップファイル自動削除機能
※バージョンによっては、”Deleted VMs data retention period”と表記されております。
通信時に使用するポート番号は?
開発元ドキュメントをご参照ください。
インストール時に指定したVBRCatalogのパスを変更する方法はありますか?
ございます。弊社ブログをご参照ください。
参考:
VBRCatalogフォルダの変更方法【Veeam KB】
How to Move the VBRCatalog Folder
Job作成時の “Advanced Settings” ボタンの “vSphere” タブの “Enable VMware Tools quiescence” にチェックを入れることでどのような動作をしますか?
「Enable VMware Tools quiescence」を有効にするとVMware Toolsの静止点作成機能を使用します。アプリケーションレベルでの静止点作成には向いていませんがVMware Toolsの静止点作成機能では静止点作成時に仮想マシン内にユーザが配置したbatファイルを実行可能です。
■参考ブログ
Windows OSのオンラインバックアップ手順【Veeam Backup & Replication】
※方法②カスタムスクリプトを利用したオンラインバックアップをご参照下さい。
Job作成時のオプション “Enable application-aware image processing” はどんな機能ですか?
オプション「Enable application-aware image processing」を有効にしてJobを実行するとVeeam独自にカスタマイズした方式でMicrosoftのVSSを利用してアプリケーションレベルでの静止点作成処理を行います。
しかし、Linuxや下記WindowsはMicrosft VSSをサポートしていません。
・Windows 95 ・Windows 98 ・Windows NT
そのため、静止点を取得する際にはカスタムスクリプトを使用していただく必要があります。
■技術ブログ
Windows OSのオンラインバックアップ手順【VMWare専用 バックアップ & レプリケーションソフト Veeam】
batと連携しての仮想マシンのバックアップ手順(MySQLの起動・停止)
オンラインダンプを使った仮想マシンのバックアップ方法【Veeam Backup & Replication】
関連トピック
Job作成時のオプション “Enable guest file system indexing” はどんな機能ですか?
Veeam静止点処理において必要な認証情報をVM個別に指定する方法はありますか?
Job作成時のオプション “Enable guest file system indexing” はどんな機能ですか?
「Enable guest file system indexing」を有効にした場合、Veeam Enterprise ManagerでWebブラウザからファイルレベルリストアが可能です(Enterpriseエディション機能)。
■技術ブログ
Backup Searchの紹介【VMWare専用 バックアップ & レプリケーションソフト Veeam】
特定の日付や月末にVeeamのJobを実行するようにスケジュールを設定したい。
VeeamのJobを実行するスクリプトをWinodws Serverの「タスク スケジューラー 」から実行することを特定の日付や月末のタイミングにVeeamのJobを起動可能です。
■タスク スケジューラー画面
同一ホストに対して同時に実行できるバックアップジョブの上限はありますか?
上限はありません。
プロキシサーバーを複数台設置した場合、ジョブの情報などはプロキシサーバー間で同期されるのでしょうか?
ジョブの管理は管理サーバーで行われるため、プロキシ間でジョブの情報等は同期されません。
ホストやジョブ数、バックアップ対象とする仮想マシン等、各種登録データについて上限値はあるのでしょうか?
上限値はありません。
しかし、ホストはライセンスの CPU 数に依存します。
Backup Mode を途中で変更した場合どうなりますか?
増分バックアップから差分バックアップに、差分バックアップから増分バックアップにモードを変更するかによって、バックアップファイルの保持のされ方が異なります。
弊社ブログをご参照ください。
参考: ジョブ設定変更後のバックアップファイルの変化
一定間隔でのスケジュール設定を行った際に、次回のジョブはどのように時間を決めていますか?
ジョブ設定時を基準とし、一定間隔後、リソース収集を行った後に1回目のジョブが開始します。2回目のジョブは1回目のジョブ開始時から一定間隔後リソース収集を行った後に開始されます。
SNMPで使用する管理情報ベース(MIB)はありますか?
はい、ございます。下記フォルダにあるVeeamBackup.mibをご利用ください。
—–
C:\Program Files\Veeam\Backup and Replication\Backup
—–
バックアップを取得した仮想マシンを削除して、バックアップ元と全く同じ設定でリストアしました。ジョブを継続して使用可能ですか?
いいえ、使用できません。
既存のジョブにバックアップ対象の仮想マシンを追加しなおすか、
新規にジョブを作成する必要があります。
VMware HA, VMware FT構成でもバックアップ可能ですか?
VMware HA構成のバックアップは可能です。
バックアップにはスナップショットが必要なため、スナップショットが利用できないVMware FT構成の場合、バックアップは行えません。
しかし、vSphere 6.0からはVMware FT構成のVMもスナップショットが利用できるようになったため、バックアップを取得可能になりました。
Hyper-Vには対応していますか?
はい、対応しています。
サポートするプラットフォームはこちらをご参照ください。
vSphereには対応していますか?
はい、対応しています。
サポートするプラットフォームはこちらをご参照ください。
エディションの違いを教えてください。
Standard、Enterprise、Enterprise Plusのエディションによって、利用できる機能が異なります。
詳細はこちらをご参照ください。
エージェント導入が必要ですか?
いいえ、ユーザがESX(i)、仮想マシンにエージェントを導入する必要はありません。
バックアップスケジュールを設定できますか?
はい、設定できます。時間指定、曜日指定、月指定の他、指定時間毎や指定日(第1週の水曜日等)の設定が可能です。また、除外設定も可能です。
ディザスタリカバリ(障害復旧)に使用できますか?
はい、使用することができます。
Veeam Backup & Reokicationのレプリケーション機能を使用することで障害復旧が可能です。
例)ESX(i)(A)で障害発生時にESX(i)(B)にレプリケーション(複製)しておいた仮想マシンを電源ONすることで復旧
※レプリケーション(複製)しておいた仮想マシンを電源ONする作業はユーザーがマニュアルで行う必要があります。
ディザスタリカバリ構成について ≫
ファイルレベルでのリストアは可能ですか?
はい、可能です。(Windows系、Linux系、Macに対応しています。)
ファイルレベルリストアでサポートしているファイルシステム >>
バックアップ先はどこが選択できますか?
バックアップ先には、Veeam Backup & Replicationインストールサーバ、接続しているESX(i)のローカルディスクが選択できます。
また、SAN、NAS、DAS、Linuxサーバもバックアップ先に選択可能です。
さらに、2次バックアップ先としてテープデバイスやクラウドをバックアップの保存先として指定することが可能です。
関連トピック
サポートするバックアップ保存先
VMware vSphere Hypervisor(ESXi無償版)はサポートしていますか?
VMware vSphere Hypervisor(ESXi無償版)は使用できません。
VMware vSphere EssentialsやVMware vSphere ESX(i)へアップグレードが必要となります。導入前の評価を行いたい方はVMware vSphere評価版をお使いください。
Linux系OSの仮想マシンのバックアップは可能ですか?
はい、可能です。
他にはWindows、Unix、FreeBSD、Solaris、MacOSがバックアップ可能です。
関連トピック
バックアップ対象の仮想マシンについて、OSの違いによるバックアップの可/不可はありますか?また、仮想マシンの電源ON/OFFの違いによるバックアップの可/不可はありますか?
OSをインストールしていない、又はVMDKファイルなしの仮想マシンをバックアップできますか?
Enterprise Managerとはどんなソフトですか?
Veeam Backup Enterprise Managerを使用することで、ユーザはWEBブラウザから複数のVeeamインストールマシンで作成したJobの管理(Jobの起動、停止)が可能です。
また、リストア可能なユーザを制限できるリストア委任オプションなどを行うために必要です。
参考: Veeam Backup Enterprise ManagerによるVeeam Backupサーバの統合管理
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから30日間となります。
30日間の評価用ライセンス期間終了後、機能が制限されたCommunity Edition(無償版)に切り替わります。
評価版に機能制限はありますか?
評価版に機能制限はありません。
Veeam Backup & Replicationの全機能を30日間無償でご使用いただけます。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
Veeam Backup & ReplicationをLinux系OSにインストール可能ですか?
Veeam Backup & ReplicationはWinodws系OSにのみインストール可能です。
Veeamインストール先環境(ソフトウェア)
サポートするバックアップ保存先
リポジトリサーバのローカル(内部)ストレージ
リポジトリサーバに直接接続されたストレージ(DAS)
※外部のUSB/eSATAドライブ、USBパススルー、RAWデバイスマッピング(RDM)ボリュームなどを含みます。
ストレージエリアネットワーク(SAN)
※バックアップリポジトリにハードウェアまたは仮想HBA、ソフトウェアiSCSIイニシエータを介してSANファブリックに接続する必要があります。
ネットワーク接続ストレージ(NAS)
-SMB(CIFS)共有:リポジトリとして直接登録することが可能です。
-NFS共有:Linuxのリポジトリサーバにマウントする必要があります。
高度な連携が可能な重複排除ストレージアプラインス
-Dell EMC Data Domain(DD OSバージョン5.6、5.7、6.0、6.1)
-ExaGrid(ファームウェアバージョン5.0.0以降)
-HPE StoreOnce(ファームウェアバージョン3.15.1以降)
-Quantum DXi(ファームウェアバージョン3.4.0以降)
関連トピック
バックアップ先はどこが選択できますか?
Veeam Backup & Replication Enterprise Managerに推奨される環境
※Veeam Backup & Replication Enterprise ManagerはWebブラウザからVeeam Backup & Replicationのバックアップ・レプリケーションジョブ等を管理するためのソフトウェアです。またEnterprise版の機能であるU-Airや1 Click File Restoreでも使用いたします。
ハードウェア
・CPU: x86-x64 プロセッサ
・メモリ: 4 GB RAM (推奨する最小構成)
・ディスク容量: システムディスク上に 2 GB
・ネットワーク: 1Gbit/sec
対応OS(下記のの64bit OSにインストール可能です)
●Mictosoft Windows Server 2022(Veeam Backup Enterprise Manager 11a以降で対応)
●Microsoft Windows Server 2019
●Microsoft Windows Server 2016
●Microsoft Windows Server 2012 R2
●Microsoft Windows Server 2012
●Microsoft Windows 2008 R2 SP1
●Microsoft Windows 2008 SP2
●Microsoft Windows 10
●Microsoft Windows 8.x
●Microsoft Windows 7 SP1
SQL Server(有償版もしくはExpressエディション)
●Microsoft SQL Server 2019
●Microsoft SQL Server 2017
●Microsoft SQL Server 2016
●Microsoft SQL Server 2014
●Microsoft SQL Server 2012
●Microsoft SQL Server 2008 R2
●Microsoft SQL Server 2008
※インストーラにはMicrosoft SQL Server 2012のExpressが含まれています。
ソフトウェア
Microsoft .NET Framework 4.7.2 ※インストーラに含まれます。
Microsoft Internet Information Services 7.5 以降
※IIS 8.0の場合、ASP.NET 4.5、.NET 4.5拡張機能を含みます。
※IIS8.5の場合、Veeam Self-Service Backup PortalとvSphere Self-Service Backup Portalを使用する際には、URL書き換えモジュールが必要です。
※これらのコンポーネントがインストールされていない場合、セットアップ中に自動的に構成することも可能です。
ブラウザ
Internet Explorer 11.0以上
Microsoft Edge
Mozilla Firefox、Google Chromeの最新版
※JavaScriptとWebSocketを有効にする必要があります。
※Enterprise Managerからエクスポートしたレポートを表示するためにMicrosoft Excel 2003以上が必要です。
EspressReport (0)
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
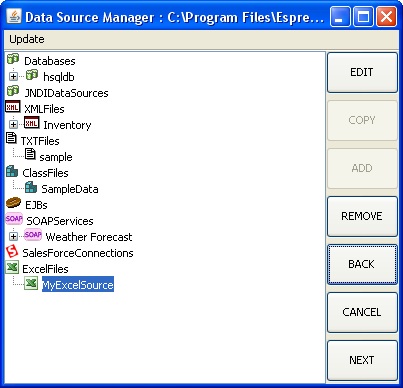
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
Excelへの出力時に結合されたセルではなく1つのセルに出力する方法はありますか?
Excelへの出力時に「Fit numeric values into a single cell」にチェックを入れることで結合されず1つのセルへ出力されます。

API から使用する場合は下記を指定してください。
QbReport.setExcelExportFitCell(true);
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したレポートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
使用できるフォントを教えてください。
一般的なJavaアプリケーション同様に、オペレーティングシステムに登録されたフォントを使用することができます。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ReportのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
開発と運用に必要なライセンスを教えてください。
初回にご購入する基本パック(サーバライセンス、開発キット)で開発と運用が可能です。
その他サーバを追加する際には追加サーバライセンス、サーバが1CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したレポートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
・評価するマシン
・JDK 5.0以上
・データソースとして使用するデータ
・開発環境(Eclipseなど)
web公開時ににレポートもチャートも表示されません。
サーブレットマッピングが必要です。以下のコードを追加してください。
// サーブレットのディレクトリ名
QbReport#setServletDirectory(“ER/”);
// サーバURLとポート
QbReport#setDynamicExport(true, “127.0.0.1”, 8080);
web公開時にレポートは表示されるのにチャートが表示されません。
RPTImageGenerator.classが必要です。
ImageGeneratorディレクトリ内のRPTImageGenerator.classをサーバに配置してください。
データが多い時にレポート出力のパフォーマンスを向上させる方法はありますか?
以下の方法でパフォーマンスの向上が見込めます。
http://data.quadbase.com/Docs/eres/help/manual/ERESChartAPI.html
メモリ上に保持されるレコードの数と一時ディレクトリを指定し、メモリ内に保持する指定されたレコードの数を超えると、データを指定した一時ディレクトリに保存します。
QbReport.setTempDirectory
(
QbReport.setMaxFieldSize(int fieldSize);
QbReport.setPagingThreshold(int pagingThreshold);
QbReport.setPageBufferSize(int bufferSize);
QbReport.setTotalPageBufferSize(int totalBufferSize);
レポートをどのような形式で出力できますか?
HTML、DHTML、PDF、CSV、ExcelおよびXMLフォーマットに
出力可能です。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのようなレポートの種類がありますか?
シンプルな段組によるレポート、概要説明レポート、クロスタブ レポート、総合及び詳細レポート、メール・ラベルのレイアウトとなります。
レポートに対してクリックイベントを設定することは可能ですか?
はい、可能です。
クリックイベントによって、ハイパーリンク(URLにアクセス)の設定やドリルダウン(関連する別のレポートやチャートへリンク)を設定できます。
レポートとは別にチャートを入れることは可能ですか?
はい、可能です。EspressReportにはEspressChartの全機能が包括されております。別途EspressChartをご購入いただく必要はありません。
レポート形式のファイル「rpt」とチャート形式「tpl」のファイルをまとめて管理したいのですが
保存する際に「PAK」形式で保存することで、レポート形式とチャート形式のファイルを1つにまとめることが可能です。Javaから利用する際もPAK形式を読み込めます。
Syniti DR -導入・製品 (9)
Syniti Data Replication (DR)とDBMotoはどう違いますか?
DBMotoはVer9.7から名称をSyniti Data Replication (略: Syniti DR)に変更しました。
名称のみの変更で機能に変更はありません。
今後名称をSyniti Data Replicationに変更してまいります。
DBMotoをどのマシンにインストールすればよいですか?
Windows OSのマシン(物理/仮想)にインストールします。
インストールしたマシンからソースDB・ターゲットDBのマシンに接続してレプリケーションの設定・実行を行います。
システム要件:https://www.climb.co.jp/soft/dbmoto/outline/system.html
DBMotoのインストール要件は?
Windows OSでMicrosoft .NET Frameworkがインストールされている必要があります。詳細は下記をご確認ください。
https://www.climb.co.jp/soft/dbmoto/outline/system.html
DBMotoを仮想マシンにインストールすることは可能ですか?
VMwareのvSphere ESX/ESXiやMicrosoftのHyper-Vなど、仮想マシン上にもインストール可能です。
エージェント導入が必要ですか?
ソースDB・ターゲットDB・DBMotoマシンいずれに対してもエージェントを導入する必要はありません。
サポートしているDBの種類とバージョンは?
AS/400をはじめとする非常に多くのDBをサポートしております。また、DBのプラットフォーム(OS)には依存しません。
詳細な対応DB一覧は下記をご覧ください。
対応データベース一覧
どのようなレプリケーションモードがありますか?
下記の3つのモードをサポートしております。
・リフレッシュ(レコード全件レプリケーション)
・ミラーリング(片方向差分レプリケーション)
・シンクロナイゼーション(双方向差分レプリケーション)
DBMoto導入によってDBにかかる負荷はどの程度でしょうか?
DBMotoはDBに対するクライアントツールとしてのアクセスしか行わないため大きな負荷はかかりません。DBに対するエージェント導入も不要です。
必要とされる回線の帯域の目安はありますか?
回線が速ければレプリケーション速度も向上しますが、回線が遅くてもレプリケーションは十分可能です。ISDN回線を使用しているお客様もいらっしゃいます。
Syniti DR -ライセンス (3)
ライセンス体系はどのようになっていますか?
ソースDBとターゲットDBの種類とマシンのスペックに依存します。
詳細はこちらをご参照ください。
使用する レプリケーションモードによって価格は異なるのでしょうか?
シンクロナイゼーション(双方向)を使用せず、ミラーリング(片方向)のみを使用する場合は、割引がございます。詳細はお問合せください。
開発環境やHA環境でも使用したいのですが、その場合は2倍の価格になりますか?
開発環境, バックアップ、HA環境、RACなどの構成で使用する場合は、価格が変わりますのでお問い合わせください。
お問合せはコチラ
Syniti DR -購入サポート (7)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語メニューに対応していますか?
操作画面は日本語化しております。
製品の操作マニュアルも日本語版を用意しております。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
Syniti DR -評価 (4)
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから15日間となります。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
評価するには何が必要になりますか?
下記の環境をご用意ください。
・DBMotoインストール用のWindowsPC(仮想マシンでも可)
・ソースDBとターゲットDB、及び評価の際に使用するテストデータ
※インストールするサーバについては、システム要件をご確認ください。
※インストールや設定方法についてのマニュアルやデモ動画を事前にご確認ください。
Syniti DR -機能 (8)
レプリケーション検証機能で正常なレコードがソースのみ、ターゲットのみのレコードとして表示されます。
レプリケーションの検証をすることで、ソースのみのレコード、ターゲットのみのレコード、ソースとターゲットで差異のあるレコードを確認できます。
しかし、本来、ソースにもターゲットにも存在し、差異のないレコードがソースのみ、ターゲットのみに存在するレコードとして表示されることがあります。
これは、DBMotoはソースとターゲットのレコードを比較する前に主キーをベースにレコードのソートを行いますが、このときのソースDBとターゲットDBのソートの仕様の違いによるものです。
例えば、Oracleの場合、大文字、小文字を区別してソートするため、D→aの順番でソートされ、MySQLの場合、大文字、小文字を区別せずソートするため、a→Dの順番でソートされます。
このソートの順番が異なるため、このような結果が生じます。
この事象を回避するため、検証機能のオプション「ORDER BY句」の「ソーステーブル」「ターゲットテーブル」に「LOWER(主キー)」を入力してください。こうすることで、大文字、小文字の区別なくソートが行えるため、問題なく検証することが可能です。
複数のテーブル内のレコードを1つのテーブルに結合可能ですか?
可能ですが注意が必要です。
ミラーリング時はPKが各テーブルで重複していなければ問題ありませんが、リフレッシュ時はそのまま実行してしまいますとリフレッシュ前に一度レコードを削除する処理(DBMotoの仕様)が行われます。これを回避するためにスクリプトでリフレッシュ時にレコードを削除しないようブロックする必要があります。
なお、各テーブル内のレコードが結合後に重複する可能性がある場合は、PK代わりのフィールドを新規で作成することでPK重複エラーを回避可能です。
UPDATE時のみレプリケーション対象外とすることは可能ですか?
スクリプトで対応可能です。
リフレッシュ時にはまずターゲットのレコードを一度削除するようですが、削除しないようにできますか?
スクリプトで実現可能です。
データを加工したり変換してレプリケーションすることは可能ですか?
可能です。Expressionという機能を使用し、VB.NET の関数を使用できます。
自前の関数を定義して使用することは可能ですか?
可能です。スクリプトとしてオリジナルの関数を定義し、Expression という機能で呼び出すことが可能です。
レプリケーション対象外のフィールドがある場合に固定の値を必ず挿入する設定は可能ですか?
可能です。Expressionという機能を使用し、固定値を入れることも可能ですし、現在日時を挿入するなど、関数を使用することも可能です
nullを特定の値に変換してレプリケーションすることは可能でしょうか?
スクリプトを使用することで実現可能です。詳細は下記をご参照ください。
https://www.climb.co.jp/blog_dbmoto/archives/452
https://www.climb.co.jp/blog_dbmoto/archives/460
Syniti DR -IBM DB2 for AS/400 (13)
AS/400のレプリケーションで「レプリケーション検証機能」を使用すると文字変換が正しくないとのエラーが出ます。
DBMotoの機能に、レプリケーションのソースとターゲット双方のテーブル間で差異が生じていないかを確認するレプリケーション検証機能があります。
AS/400のテーブルで、VARGRAPHIC型もしくはGRAPHIC型があるテーブルで検証を行うと、「CCSID 65535とCCSID 13488の間の文字変換は正しくない」とのエラーメッセージが出力されることがあります。
このエラーメッセージは通常のレプリケーション中には発生せず、データは問題なくレプリケーションできていることが多いです。
これは、このレプリケーション検証機能使用時に限り、DBMotoの「検証のソート・シーケンステーブル」設定が有効であるため、GRAPHIC型が文字変換を行おうとして失敗しています。
対処法は、この設定個所の部分を空欄にすることです。(設定変更時はData Replicatorの停止が必要です。)
なお、通常のレプリケーションは、前述の通りこの設定を使用していないので、問題なく変換され動作します。
マルチメンバーファイル(テーブル)からレプリケーションができません。
AS400上のマルチメンバーファイルとなっているテーブルからレプリケーションしようとすると、ステータスは成功なのに処理件数が0件のまま動かないことがあります。
これはマルチメンバーファイルの仕様上の制限でSELECTクエリが実行できないためです。
テーブルのエイリアスを作成していただければSELECTクエリで結果が取得できるため、レプリケーションできるようになります。
エイリアスを作成するクエリの一例は以下の通りです。
CREATE ALIAS MYLIB.FILE1MBR1 FOR MYLIB.MYFILE(MBR1)
CREATE ALIAS MYLIB.FILE1MBR2 FOR MYLIB.MYFILE(MBR2)
古いジャーナルは削除しても問題ないですか?
DBMotoから参照しているジャーナルより前のものについては削除して問題ありません。
AS/400にはどのドライバで接続するのでしょうか?
Ritmo/iというドライバを使用します。DBMotoに同梱されております。
ジャーナルレシーバはテーブル単位で作成する必要がありますか?それともまとめて1つでも問題ないですか?
1つにまとめても問題ありません。DBMotoではテーブル単位でレプリケーション定義を作成し、定義ごとにトランザクションIDを管理することが可能なためです。
DBMOTOLIBにジャーナルレシーバを作成してもよいですか?
可能ですが非推奨です。DBMOTOLIBにはDBMotoからAS/400のジャーナルを参 照するためのプロシージャが存在しますので、DBMOTOLIBにプロシージャ以外のデータが存在するとレプリケーションのパフォーマンスに影響が出る場合があります。
AS/400からのミラーリングでトランザクションID取得のためにReadボタンを押下するとエラーになります
DBMotoからAS/400のジャーナルレシーバを参照するためのプロシージャを手動で作成した場合に、正しく作成されていない可能性があります。
カタログ・技術資料一覧から以下をご参照ください。
[DBMoto共通]AS400ジャーナル・プロシージャ作成手順書
AS/400のエラー「資源の限界を超えた」が発生しましたが原因はなんでしょうか?
下記ブログ記事をご参照ください。
ジャーナルが切り替わった場合、DBMotoもちゃんと切り替えて追ってくれますか?
はい、AS/400側のジャーナルに合わせてDBMotoが参照するジャーナルも自動で切り替わります。
レコードの全消去時に他データべースへのレプリケーションをどのように行いますか?
AS/400でレコードの全消去を含む操作(CLRPFMやCPYF(REPLACEオプション))を行った場合、他データベースに対してこの変更をTRUNCATEとして他データベースに反映します。しかしレコードが対象ではなく、ファイルそのものを置き換えている場合など(RSTOBJ等)の場合、変更は他データベースへ反映されません。
Syniti DR -Oracle (17)
Data Replicatorが強制停止することがある
本エラーは例えばOracle 11.2のクライアントを使用している場合「oracore11.dll」にて障害が発生した旨Windowsイベントログに記録されている可能性があります。
一部の条件下にて本事象が発生するケースがあり、エラー発生までの流れは以下の通りです。
1. DBMoto から Oracle へ Oracle クライアントで接続するためコネクションをオープンする
2. このオープンしたタイミングで Oracle クライアント側のoracore11.dll というファイル関連で何らかの障害が発生しエラーとなる可能性がある
3. 2に引きずられて DBMoto の Data Replicator が強制終了する
つまり、発生トリガーは1の「Oracle へのコネクションを確立した際」です。
これまで発生事例から Windows のダンプファイルの解析、マイクロソフト社のダンプ解析ツール ADPlus でさらに詳細を解析するなどし下記のことが判明しております。
・エラーは Oracle 側の DLL で発生している
・エラーは .NET Framework の外で発生している
・DBMoto はすべて .NET Framework 内で動作するので本エラーが DBMoto 起因である可能性は極めて低い
(DBMoto が原因の場合は .NET Framework 内でエラー発生する)
・再現するマシンが一部に限られている
回避策としてレプリケーション毎に Oracle への接続をオープンにしないようコネクションプールを有効にする方法がございます。設定手順は以下の通りです。
1. Data Replicator サービスを停止します
2. ターゲットの Oracle 接続を右クリック→「プロパティ」を開きます。
3. 接続 Oracle .NET Driver の右にあるボタンをクリックします。
4. Pooling が False になっているので True へ変更します。
これにより Oracle へのコネクションプーリングが有効となり、
本事象は発生しなくなります。
Oracleからのミラーリングで「Record to update not found in target table」の後にターゲットへの補管INSERTでNOT NULL制約違反が発生する
まず更新対象レコードがターゲットに存在しない場合に「Record to update not found in target table」警告が発生し、その後DBMotoは補完INSERTを行います(行わないようにすることも可能です)
しかし Oracle のトランザクションログモードがLog Readerの場合、REDOログから取得できる情報は更新したカラムとPKのみとなります。
このため更新していないカラムはNULLとしてターゲットへのINSERTを行い、結果NOT NULL制約のカラムがあるとエラーになります。
対処方法は以下の2通りです。
1. Oracle のトランザクションログモードを「トリガー」にする(Oracle 10gかつDBMoto v9以降)
2. Oracle に対して以下のクエリを発行し、すべてのカラム情報をREDOログから取得できるようにする。
>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
パーティション化したテーブルからミラーリングできますか?
可能です。
ただし、DBMotoではDML文のみレプリケーションするため、パーティションがDDL文で削除されたときはそれを反映できません。
Oracleからのミラーリングタイミングが更新が起きていない時間帯でもバラバラです。
Oracleからのミラーリング時にはデフォルトでアーカイブログを参照し、またその際にCONTINIOUS_MINEオプションを有効にしています。
一部のOracle環境ではCONTINIOUS_MINEオプションをオンにしているとミラーリングタイミングがバラバラになることがあります。
CONTINIOUS_MINEオプションを外すとこの事象が解消することがあります。
オプションの切り替えにより、レプリケーションの性能劣化やOracleに対する負荷増加が発生することはほとんどありません。
DBMotoでOracleのマテリアライズドビューはレプリケーションできますか?
リフレッシュとミラーリングが可能です。
ミラーリング時の注意点として、DBMotoは差分データの取得にトランザクションログを用いていますが、マテリアライズビューにあるレコードに対するUPDATE操作をOracleが内部で行う際、UPDATEではなくDELETEとINSERTを組み合わせて行っているため、トランザクションログの数が1つではなく、2つになっています。
DBMotoのレコード処理件数表示はトランザクションログをベースにしている都合上、マテリアライズドビューのリフレッシュモードが「完全」の場合は、ビュー上の全レコード数×2、「部分」の場合は、UPDATE対象レコードの数×2の数が、レコード処理件数として表示されます。これはOracle側の仕様によるものです。
どのようにして差分レプリケーションが行われますか?
Redoログを参照します。事前にサプリメンタルロギングの設定が必要ですが、DBMotoから行うことが可能です。
Oracle10gのレプリケーション設定時にドライバエラーが出ます
DBMoto側のOracleクライアントドライバを最新の11gにしてください。Oracle側の既知不具合です。
Oracle RACに対応していますか?
対応しております。
データタイプBLOB/CLOBには対応していますか?
対応しておりますが、ミラーリングとシンクロナイゼーションについては、
Log Server経由のみ対応しています。
ビューはレプリケーションに対応していますか?
対応しておりません。
Oracleへ接続するドライバのダウンロード先を教えてください。
以下のサイトからOracleクライアント又はODACをダウンロード可能です。
http://www.oracle.com/technetwork/jp/database/windows/downloads/index.html
また、Oracleデータベースのバージョンに関わらず、ドライバのバージョンは11を使用してください。
OracleからのレプリケーションでORA-01291(ログ・ファイルがありません)が表示される。
OracleのRedoログが1周してDBMotoが参照しに行くIDが既になくなってしまった際に発生するエラーです。
復旧はリフレッシュするか、最新のトランザクションIDを取得する必要があります。
また、このエラーが頻発する場合はRedoログのサイズ設定を見直す必要があります。
サプリメンタルロギングを設定時の「Minimal Level」と「Database Level」は何が違うのでしょうか?また、実行されるSQLを教えてください。
●Minimal Level
レプリケーションするテーブルのみ(最低限)にサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA
・レプリケーション作成時
ALTER TABLE テーブル名 ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
●Database Level
データベース全体(すべてのテーブル)に対してサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
サプリメンタルロギングの設定でOracle9iでは「Minimal Level」だけにチェックを入れても「Database Level」にも自動でチェックが入ってしまう
Oracle9iの仕様によるものです。
Oracleでエラー「ORA-03113」が発生しました。
OracleとDBMoto間のネットワーク障害によるものです。
Syniti DR -IBM DB2 for Linux, Windows, AIX (3)
DB2のHADR構成のスタンバイサーバからミラーリングは可能ですか?
トリガー形式およびログ参照形式のいずれも不可です。
DB2側の仕様でトリガーに必要な機能もログ参照に必要なAPIもスタンバイサーバでは利用できません。
どのようにして差分レプリケーションが行われますか?
DB2 Logを参照する方法と、トリガーログテーブルを作成する方法があります。DB2 Logを使用する場合、予めdb2udbreadlogという拡張ファイル(DBMotoに同梱済み)をDB2側に格納する必要があります。
DB2 UDBにはどのドライバで接続するのでしょうか?
Ritmo/DB2というドライバを使用します。DBMotoに同梱されております。
Syniti DR -SQL Server (8)
SQL Serverでログ配布を受けているスレーブ側サーバからレプリケーションできますか?
SQL Serverの仕様上の制約によりできません。
シンクロナイゼーション レプリケーション作成時にエラーが発生します。 「接続’DB接続名’用に定義されたユーザ’sa’はsysadminであり、シンクロナイゼーションでは有効ではありません。sysadmin以外のユーザでログインを定義してください。また、ディストリビュータを作成し、トランザクションログを読むためにsysadminのログインIDを供給しています。」
SQL Serverの接続設定に「sa」以外のユーザをご利用ください。
シンクロナイゼーションでは、更新がループしないようにするため、接続設定に使用したユーザでの更新はレプリケーション対象として検出しない仕様となっております。
そのため、シンクロナイゼーションを行う場合には、DBMoto専用ユーザを用意する必要がございます。
「sa」はDBMoto専用とすることができないため、このようなエラーが発生します。
ビューのレプリケーションに対応していますか?
参照するベースのテーブルが1つの場合かつSQLServerのビュー更新条件(特定の関数が使用されていないこと)を満たしている場合に限り、リフレッシュのみ可能です。
複数のベーステーブルを参照するビューの場合は、ビューの仕様でinsert, update, deleteが行えず、selectのみ可能となりますので、DBMotoでも同様にレプリケーションは行えなくなります。
どのようにして差分レプリケーションが行われますか?
Distributorを参照する方法と、トリガーログテーブルを作成する方法があります。
SQL Server Express Editionに対応していますか?
対応しております。ただし差分レプリケーションの際にDistributorを使用することはできず、トリガーテーブルを作成する必要があります。
バイナリデータはレプリケーション可能ですか?
可能です。
SQLServerへのレプリケーションで以下のエラーが発生しました。 System.Data.SqlClient.SqlException: IDENTITY_INSERT が OFF に設定されているときは、テーブル ‘XXXX’ の ID 列に明示的な値を挿入できません。
SQLServerのフィールドIdentityの仕様によるものです。Identity以外のPKフィールドを用意するかIdentity自体をOFFにする必要があります。
レプリケーション中にSQLServer側のコネクション数が最大値に達したというエラーが出ます。
SQL Server側とDBMoto側のMax Pool Sizeをご確認ください。DBMoto側のデフォルト値は100です。
Syniti DR -MySQL (5)
パーティション化したテーブルからミラーリングできますか?
可能です。
ただし、DBMotoではDML文のみレプリケーションするため、パーティションがDDL文で削除されたときはそれを反映できません。
MySQLへのミラーリングが反映されません
MySQLへミラーリングを行うためには、MySQLでautocommitが有効になっている必要があります。以下のクエリで確認が可能です。
mysql>SELECT @@autocommit;
もしもこの結果が0の場合、autocommitが無効になっているので、有効化してください。
もしアプリの都合で有効化が困難な場合は、以下の対応を行ってください。
1. Data Replicator を停止し、Management Center を閉じます。
2. 以下のファイルをダウンロードし、ExecuteList.xml を開きます。
https://www.climb.co.jp/soft/download/DBMoto/ExecuteList.zip
3. <connection name=”ここ”> に DBMoto で設定済みのMySQL 接続名を指定します。
4. ExecuteList.xml を DBMoto インストールディレクトリに配置します。
5. Data Replicator を開始し、正常にレプリケーションされることを確認します。
これによりMySQL への接続毎に「SET autocommit=1;」のコマンドを発行して一時的にautocommitを有効化してレプリケーションを行うようになります。
MySQLレプリケーションのスレーブ側サーバからミラーリングをしたいのですが、必要な設定はなんですか?
スレーブ側MySQLのmy.iniの[mysqld]に次の一行を付け加えます。
log_slave_updates=TRUE
これは、スレーブサーバがマスターサーバから受け取った更新をスレーブサーバ自身のバイナリログに反映する設定となります。
デフォルトですと設定がされていない(FALSE)ため、DBMotoからスレーブ側のバイナリログを読み込みにいっても、マスター側の更新が記録されず、変更を検知できません。
どのようにして差分レプリケーションが行われますか?
MySQLのバイナリログを参照する方法と、トリガーログテーブルを作成する方法があります。MySQLのバイナリログを使用する場合、拡張ファイルが必要となりますので別途お問い合わせください。
DB2 Connectivity (Syniti DC) (10)
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから14日間となります。
Syniti Data Connectivity (略: Syniti DC)て何ですか?
『DB2 Connectivity』はVer9.7から名称を『Syniti(スィニティ)Data Connectivity(略称:Syniti DC)』に変更しました。
名称のみの変更で機能に変更はありません。
今後名称をSyniti Data Connectivityに変更してまいります。
HiT Db2 Connectivity製品の選択方法 ( ID:1635)
○もしアプリケーションがADO.NET または Visual Studioで構築されたいれば、Ritmo (.NET)を選択
○もしアプリケーションがJavaで構築されていればHiT JDBCを選択
○もしアプリケーションが Powerbuilder等の他で構築されていればHiT ODBC か HiT OLEDBを選択
ただしHiT ODBCはリレーショナル・データベース形式のみをサポートし、HiT OLEDBはリレーショナル+他のすべてのデータ形式にサポートします。
ODBC/400 と ODBC/Db2の異差
●HiT ODBC/DB2およびHiT ODBC Server/DB2はIBM Db2 on z/OS, Linux, Unix, Windowsサーバとの通信でDRDAプロトコールを使用します。 HiT ODBC/DB2およびHiT ODBC Server/DB2は、以下のIBM Db2環境で動作します。
· IBM Db2 LUW
· IBM Db2 for z/OS (OS/390)
· IBM Db2 for i – supporting IBM OS/400 Operating Systems V4R2 or higher
●HiT ODBC / 400およびHiT ODBC Server / 400は、ODBSプロトコルを使用し、IBM iオペレーティング・システムV3R1以上を必要とします。
HiT DB2 Connectivity Developer Edition (DE: 開発者版)について
IBMのi5, System i, iSeries, AS/400上で稼動するDB2データをWindowsでのActive Server Page(ASP)に利用したり、Visual Basicアプリケーションに利用したりすることは通常は簡単ではありません。HiT ODBC Server/400 Developer EditionとHiT OLEDB Server/400 Developer Editionに含まれるHiT ASPと HiT VBツールキットを利用することにより、それらの開発時間を大幅に短縮できます。
○ HiT ODBC Server/400 Developer Edition (DE: 開発者版)はi5, System i, iSeries, AS/400上で稼動するIBM DB2をアクセスするためのSQLミドルウェアで、Windowsプラットフォーム上で稼動し、ユーザまたはサードパーティのアプリケーションで利用されます。HiT ODBC Server/400 DEはDB2データのアクセス、リトリーブ、アップデートにWindows Open Database Connectivity (ODBC)をサポートします。またActive Server Page(ASP)と Visual Basic のツールキットを含みADO経由でDB2データを接続、クエリー、リトリーブ、アップデートが可能なソースコードを含むサンプル・アプリケーションが含まれます。
またIBM Optimized Database Server (ODBS)プロトコール標準を利用しているので、HiT ODBC Server/400 DEはネイティブなIBM OS/400サーバ・プログラムを使用し、i5, System i, iSeries, AS/400プラットフォームに特別なソフトウェアは必要ありません。
○ HiT OLEDB Server/400 Developer Edition (DE)は同様にi5, System i, iSeries, AS/400上で稼動するIBM DB2をアクセスするためのSQLミドルウェアで、Windowsプラットフォーム上で稼動し、ユーザまたはサードパーティのアプリケーションで利用されます。HiT OLEDB Server/400 DEはADO v2.x経由、またはOEL DBオブジェクト・プロパティ経由での直接にアプリケーションSQLステートメントが可能で、そしてDB2データのアクセス、リトリーブ、アップデートが可能です。また同様にHiT ASPと HiT VBツールキットを含みます。
●HiT ASP ツールキット
Webアプリケーションの開発の高速化に最適
Microsoft IIS Web開発用のHiT Active Server Page (ASP) ツールキットはHiT ODBC Serverミドルウェアとの組合せでIIS ASP開発環境でのDB2のWeb統合に有益なスタートをもたらします。
HiT ASPツールキットに含まれるWebアプリケーションからDB2テーブルに対するクエリー、アップデートの検証済ASPサンプルを開発者が利用することでWebアプリケーション・開発時間を大幅に削減できます。サンプルにはADOレコードセットを使用しての接続確立方法、ストアード・プロシージャ実行、テーブル・データのリトリーブとインサート、HTML経由での結果表示などがあります。すべてのサンプルは各種のDB2サーバとプラットフォームで検証されています。HiT ASPツールキットはWindowsフラットフォームで稼動し、HiT ODBCサーバ製品経由でDB2サーバとコミュニケーションを行います。
●HiT VBツールキット
高速VBアプリケーション開発に最適
HiT VBツールキットはすべてのHiT ODBC と OLE DB開発者版製品に含まれMicrosoft Visual Basicを使用する開発者をサポートします。HiT ODBC と OLE DBミドルウェア製品と組み合わせて使用することにより、Visual Basic開発環境でのDB2アプリケーション・インテグレーションに有益なスタートをもたらします。
HiT VBツールキットでADO, RDO, DAO, ODBCDirectインターフェイスを使用してDB2テーブル・データにアクセスするためのソース・コード・サンプルを開発者に提供することにより、アプリケーションの開発時間を削減することができます。サンプルはレコードセットを使用しての接続確立、ストアード・プロシージャの実行、DB2データのアップデートなどが含まれます。すべてのサンプルは各種のDB2サーバとプラットフォームで検証されています。HiT VBツールキットはWindowsフラットフォームで稼動し、HiT ODBCとOLE DB製品経由でDB2サーバとのコミュニケーションを行います。
Ritmo を使用してDB2 をアクセスC# や VB.NET のサンプル・コードはどこか にありますか?
Q:Ritmo を使用してDB2 をアクセスC# や VB.NET のサンプル・コードはどこか
にありますか?
A:基本的なSELECT/INSERT/UPDATE/DELETE を実行できるようにRitmo はC# と
VB.NET コード・サンプルを準備しています。さらにストアード・プロシージ
ャ・コール作成やパラメトリック・クエリもカバーします。Ritmo ToolBox Help
メニューの下にサンプル・コードがあります。Ritmo ToolBox のプルダウン・メ
ニューからHelp/Contents を選択してサンプルコードを選びます。
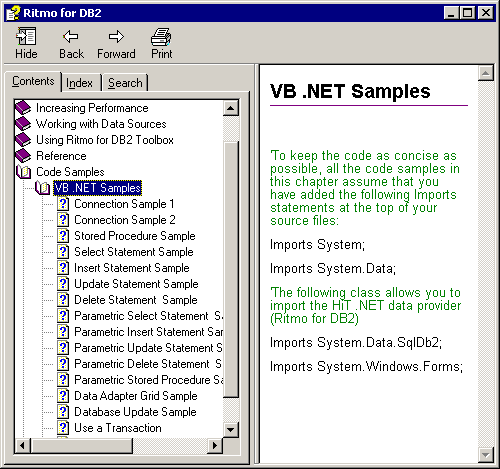
Q: 各プラットフォームでのDB2用のデフォルトHost Code Pageとポート・ナンバーは?
A:
AIX
Host Code Page – 819 Latin
Port Number – 446
Linux
Host Code Page – 819
Port Number – 50000
OS390
Host Code Page – 037
Port Number – 446
OS400 (AS/400)
Host Code Page 037
Port Number 8471
Windows Server
Host Code Page – 1252
Port Number – 50000
.NET経由でAS/400に接続する時にHiT OLEDB/400を選択するのかRitmo/iを選択するのか?
.NETアプリケーション開発者はAS/400サーバへアクセスするためにはマイクロソフトが提供するADO.NET-to-OLE DBまたは-ODBC 使用してODBC または OLEDBのどちらかを経由してそのリモートのデータベースに接続します。しかしこれらのブリッジ・ソリューションはパフォーマンスに影響し、CLR(Common Language Run-time)開発環境を利用する根本のプロバイダとドライバを阻害します。
Ritmo/i はこれらのブリッジ手法より優れた選択になります。それはブリッジを除外し、高いパフォーマンス、CLR機能、アプリケーションに対するオペレーティング。システムスケーラブルな管理を提供します
Q:Visual C++ を使用して AS/400への接続をどのようにイニシエイトしますか?
A: サンプルコードは:
///////////////////////////////////////////////////////////////////////////////
// OLE400 Test Sample – 07-07-2000
//
// Standard sample for testing HiT OLEDB400 Provider.
// Initialization phases can be used in any other connect exercise.
//
///////////////////////////////////////////////////////////////////////////////
#include
//You may derive a class from CComModule and use it if you want to override
//something, but do not change the name of _Module
extern CComModule _Module;
#include
#include
#include “atldb.h”
#include
#include
#include #define SAFE_RELEASE(pv) if(pv) { (pv)->Release(); (pv) = NULL; } WCHAR* A2WSTR(LPCSTR lp, int nLen) { USES_CONVERSION; int nConvertedLen = MultiByteToWideChar(_acp, str = ::SysAllocStringLen(NULL, nConvertedLen); if ( str != NULL ) { LPSTR WSTR2A(LPSTR cBuf, LPCWSTR lpw, LPCSTR lpDef) { USES_CONVERSION; int nConvertedLen = WideCharToMultiByte(_acp, if ( cBuf != NULL ) { return cBuf; CComPtr // MAIN TEST FUNCTION void main () IDBInitialize* pIDBInitialize = NULL; hr = CoInitialize(NULL); // retrieve pMalloc interface hr = CoCreateInstance(CLSID_MSDAINITIALIZE, /////////////////////////////////////////////////////// memset (lpItemText, 0, 200); printf (“Open connection to HiT OLE DB Provider for DB2\r\n”); printf (“UDL File\t: “); printf (“User ID \t: “); printf (“Password\t: “); /////////////////////////////////////////////////////// hr = pIDataInitialize->LoadStringFromStorage(pwszTemp, &pwszInitString); SysFreeString (pwszTemp); /////////////////////////////////////////////////////// hr = pDataSource->QueryInterface(IID_IDBInitialize, (void**)&pIDBInitialize); if (pIDBProperties == NULL) hr = pIDBProperties->GetProperties(0, NULL, &cPropSets, &prgPropSets); // Set edit data link properties rgProps[0].dwPropertyID = DBPROP_INIT_PROMPT; rgProps[1].dwPropertyID = DBPROP_AUTH_USERID; rgProps[2].dwPropertyID = DBPROP_AUTH_PASSWORD; PropSet.cProperties = 3; hr = pIDBProperties->SetProperties (1, &PropSet); // Free memory // free all properties // now free the property set /////////////////////////////////////////////////////// hr = pIDBInitialize->Initialize(); printf (“CONNECTED\r\n\r\n”); // to do: put any code here /////////////////////////////////////////////////////// // Release any references and continue. SAFE_RELEASE(pIDBInitialize); SAFE_RELEASE (pIDBProperties); SAFE_RELEASE (pIDataInitialize); CoUninitialize(); SAFE_RELEASE (pIDBInitialize);
#define TESTC(hr) { if(FAILED(hr)) goto CLEANUP; }
BSTR str = NULL;
0,
lp,
nLen,
NULL,
NULL) – 1;
MultiByteToWideChar(_acp,
0,
lp,
-1,
str,
nConvertedLen);
}
return str;
}
0,
lpw,
-1,
NULL,
0,
lpDef,
NULL) – 1;
if (nConvertedLen>0) {
WideCharToMultiByte(_acp,
0,
lpw,
-1,
cBuf,
nConvertedLen,
lpDef,
NULL);
}
}
}
MEMORYSTATUS lpBuffer;
///////////////////////////////////////////////////////////////////////////////
{
IDataInitialize* pIDataInitialize = NULL;
DWORD dwCLSCTX = CLSCTX_INPROC_SERVER;
DBPROPSET* prgPropSets = NULL;
ULONG cPropSets;
IUnknown* pDataSource = NULL;
IDBProperties* pIDBProperties = NULL;
WCHAR* pwszTemp;
WCHAR* pwszInitString;
HRESULT hr = S_OK;
if (FAILED(hr))
return;
hr = ::CoGetMalloc(1, (LPMALLOC *) &pMalloc);
if (FAILED(hr))
return;
NULL,
CLSCTX_INPROC_SERVER,
IID_IDataInitialize,
(void**)&pIDataInitialize);
// Prompt data
char lpItemText [200];
char lpUDL [50];
char lpUserID [30];
char lpPassword [30];
int nLen = -1;
memset (lpUDL, 0, 50);
memset (lpUserID, 0, 30);
memset (lpPassword, 0, 30);
printf (“==================================================\r\n”);
scanf (“%s”, lpUDL);
sprintf (lpItemText, “C:\\Program Files\\Common Files\\System\\OLE DB\\Data Links\\%s”, lpUDL);
printf (“\r\n”);
scanf (“%s”, lpUserID);
printf (“\r\n”);
scanf (“%s”, lpPassword);
printf (“\r\n”);
// Get connection string from Data Link file
nLen = strlen(lpItemText);
pwszTemp = A2WSTR(lpItemText, nLen + 1 );
// Get Data Source object
hr = pIDataInitialize->GetDataSource(NULL,
dwCLSCTX,
pwszInitString,
IID_IDBInitialize,
(IUnknown**)&pDataSource);
hr = pIDBInitialize->QueryInterface (IID_IDBProperties,
(void**)&pIDBProperties);
DBPROP rgProps[3];
DBPROPSET PropSet;
rgProps[0].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[0].vValue.vt = VT_I2;
rgProps[0].vValue.iVal = DBPROMPT_NOPROMPT;
rgProps[1].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[1].vValue.vt = VT_BSTR;
nLen = strlen(lpUserID);
pwszTemp = A2WSTR(lpUserID, nLen + 1 );
V_BSTR(&(rgProps[1].vValue))= SysAllocStringLen (pwszTemp, wcslen(pwszTemp));
rgProps[2].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[2].vValue.vt = VT_BSTR;
nLen = strlen(lpPassword);
pwszTemp = A2WSTR(lpPassword, nLen + 1 );
rgProps[2].vValue.bstrVal = SysAllocStringLen (pwszTemp, wcslen(pwszTemp));
PropSet.rgProperties = rgProps;
PropSet.guidPropertySet = DBPROPSET_DBINIT;
SysFreeString (rgProps[1].vValue.bstrVal);
SysFreeString (rgProps[2].vValue.bstrVal);
pMalloc->Free (prgPropSets->rgProperties);
pMalloc->Free (prgPropSets);
// Initialize connection
printf (“Connecting…\r\n\r\n”);
if (FAILED(hr))
return;
// …
// Disconnect
printf (“Disconnecting…\r\n”);
hr = pIDBInitialize->Uninitialize ();
SAFE_RELEASE (pDataSource);
}
Host Code Pageについて(KBFAQ 1024)
HiT ODBC/400, HiT OLEDB/400 and Ritmo for iSeries
IDS_CODEPAGE_037_1 “037 – US/Can./Australia/N.Z.”
IDS_CODEPAGE_037_2 “037 – Netherlands”
IDS_CODEPAGE_037_3 “037 – Portugal/Brazil”
IDS_CODEPAGE_273 “273 – German/Austrian”
IDS_CODEPAGE_277 “277 – Danish/Norwegian”
IDS_CODEPAGE_278 “278 – Finnish/Swedish”
IDS_CODEPAGE_280 “280 – Italian”
IDS_CODEPAGE_284 “284 – Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_285 “285 – UK”
IDS_CODEPAGE_297 “297 – French”
IDS_CODEPAGE_424 “424 – Hebrew”
IDS_CODEPAGE_500 “500 – Belgian/Swiss/Can.”
IDS_CODEPAGE_870 “870 – Eastern Europe”
IDS_CODEPAGE_871 “871 – Icelandic”
IDS_CODEPAGE_875 “875 – Greek”
IDS_CODEPAGE_1026 “1026 – Turkey”
IDS_CODEPAGE_290 “290 – Jpn. Katakana Host SBCS”
IDS_CODEPAGE_1027 “1027 – Jpn. Latin Host SBCS”
IDS_CODEPAGE_933 “933 – Korean”
IDS_CODEPAGE_935 “935 – Simplified Chinese”
IDS_CODEPAGE_937 “937 – Traditional Chinese”
IDS_CODEPAGE_4396 “4396 – Jpn. Host DBCS”
IDS_CODEPAGE_5026 “5026 – Jpn. Katakana-Kanji Host Mix.”
IDS_CODEPAGE_5035 “5035 – Jpn. Latin-Kanji Host Mix.”
IDS_CODEPAGE_1140_1 “1140 – (Euro) US/Can./Australia”
IDS_CODEPAGE_1140_2 “1140 – (Euro) N.Z./Netherlands”
IDS_CODEPAGE_1140_3 “1140 – (Euro) Portugal/Brazil”
IDS_CODEPAGE_1141 “1141 – (Euro) German/Austrian”
IDS_CODEPAGE_1142 “1142 – (Euro) Danish/Norwegian”
IDS_CODEPAGE_1143 “1143 – (Euro) Finnish/Swedish”
IDS_CODEPAGE_1144 “1144 – (Euro) Italian”
IDS_CODEPAGE_1145 “1145 – (Euro) Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_1146 “1146 – (Euro) UK”
IDS_CODEPAGE_1147 “1147 – (Euro) French”
IDS_CODEPAGE_1148 “1148 – (Euro) Belgian/Swiss/Can.”
IDS_CODEPAGE_1149 “1149 – (Euro) Icelandic”
IDS_CODEPAGE_420 “420 – Arabic”
IDS_CODEPAGE_838 “838 – Thai”
HiT ODBC/DB2, HiT OLEDB/DB2, and Ritmo for DB2
IDS_CODEPAGE_037_1 “037 – US/Canada/Australia/N.Z.”
IDS_CODEPAGE_037_2 “037 – Netherlands”
IDS_CODEPAGE_037_3 “037 – Portugal/Brazil”
IDS_CODEPAGE_273 “273 – German/Austrian”
IDS_CODEPAGE_277 “277 – Danish/Norwegian”
IDS_CODEPAGE_278 “278 – Finnish/Swedish”
IDS_CODEPAGE_280 “280 – Italian”
IDS_CODEPAGE_284 “284 – Spanish”
IDS_CODEPAGE_285 “285 – UK”
IDS_CODEPAGE_297 “297 – French”
IDS_CODEPAGE_420 “420 – Arabic”
IDS_CODEPAGE_424 “424 – Hebrew”
IDS_CODEPAGE_500 “500 – Belgian/Swiss”
IDS_CODEPAGE_819 “819 – Latin”
IDS_CODEPAGE_870 “870 – Eastern Europe”
IDS_CODEPAGE_871 “871 – Icelandic”
IDS_CODEPAGE_875 “875 – Greek”
IDS_CODEPAGE_290 “290 – Jpn. Katakana Host SBCS”
IDS_CODEPAGE_932 “932 – Jpn. PC Mixed incl. 1880 UDC”
IDS_CODEPAGE_933 “933 – Korean”
IDS_CODEPAGE_935 “935 – S. Chinese”
IDS_CODEPAGE_937 “937 – T. Chinese”
IDS_CODEPAGE_943 “943 – Jpn. PC Mixed for Open Env.”
IDS_CODEPAGE_954 “954 – Jpn. EUC”
IDS_CODEPAGE_1026 “1026 – Turkey”
IDS_CODEPAGE_1027 “1027 – Jpn. Latin Host SBCS”
IDS_CODEPAGE_1140_1 “1140 – (Euro) US/Can./Australia”
IDS_CODEPAGE_1140_2 “1140 – (Euro) N.Z./Netherlands”
IDS_CODEPAGE_1140_3 “1140 – (Euro) Portugal/Brazil”
IDS_CODEPAGE_1141 “1141 – (Euro) German/Austrian”
IDS_CODEPAGE_1142 “1142 – (Euro) Danish/Norwegian”
IDS_CODEPAGE_1143 “1143 – (Euro) Finnish/Swedish”
IDS_CODEPAGE_1144 “1144 – (Euro) Italian”
IDS_CODEPAGE_1145 “1145 – (Euro) Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_1146 “1146 – (Euro) UK”
IDS_CODEPAGE_1147 “1147 – (Euro) French”
IDS_CODEPAGE_1148 “1148 – (Euro) Belgian/Swiss/Can.”
IDS_CODEPAGE_1149 “1149 – (Euro) Icelandic”
IDS_CODEPAGE_1252 “1252 – Windows ANSI”
IDS_CODEPAGE_4396 “4396 – Jpn. Host DBCS”
IDS_CODEPAGE_5026 “5026 – Jpn. Katakana-Kanji Host Mixed”
IDS_CODEPAGE_5035 “5035 – Jpn. Latin-Kanji Host Mixed”
HiT JDBC/400 API サポート
| Methods: | Return Types: | Supported: |
Interface Blob |
| getBinaryStream() | InputStream | Yes |
| getBytes(long pos, int length) | byte[] | Yes |
| length() | long | Yes |
| position(Blob pattern, long start) | long | No |
| position(byte[] pattern, long start) | long | No |
| Methods: | Return Types: | Supported: |
Interface CallableStatement |
| getArray(int i) | Array | No |
| getBigDecimal(int parameterIndex) | BigDecimal | Yes |
| getBigDecimal(int parameterIndex, int scale) | BigDecimal | Yes |
| getBlob(int i) | Blob | No (soon) |
| getBoolean(int parameterIndex) | boolean | Yes |
| getByte(int parameterIndex) | byte | Yes |
| getBytes(int parameterIndex) | byte[] | Yes |
| getClob(int i) | Clob | No (soon) |
| getDate(int parameterIndex) | Date | Yes |
| getDate(int parameterIndex, Calendar cal) | Date | No (soon) |
| getDouble(int parameterIndex) | double | Yes |
| getFloat(int parameterIndex) | float | Yes |
| getInt(int parameterIndex) | int | Yes |
| getLong(int parameterIndex) | long | Yes |
| getObject(int parameterIndex) | Object | Yes |
| getObject(int i, Map map) | Object | No |
| getRef(int i) | Ref | No |
| getShort(int parameterIndex) | short | Yes |
| getString(int parameterIndex) | String | Yes |
| getTime(int parameterIndex) | Time | Yes |
| getTime(int parameterIndex, Calendar cal) | Time | Yes |
| getTimestamp(int parameterIndex) | Timestamp | Yes |
| getTimestamp(int parameterIndex, Calendar cal) | Timestamp | No |
| registerOutParameter(int parameterIndex, int sqlType) | void | Yes |
| registerOutParameter(int parameterIndex, int sqlType, int scale) | void | No |
| registerOutParameter(int paramIndex, int sqlType, String typeName) | void | No |
| wasNull() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface Clob |
| getAsciiStream() | InputStream | No |
| getCharacterStream() | Reader | Yes |
| getSubString(long pos, int length) | String | Yes |
| length() | long | Yes |
| position(Clob searchstr, long start) | long | No |
| position(String searchstr, long start) | long | No |
| Methods: | Return Types: | Supported: |
Interface Connection |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| commit() | void | Yes |
| createStatement() | Statement | Yes |
| createStatement(int resultSetType, int resultSetConcurrency) | Statement | Yes |
| getAutoCommit() | boolean | Yes |
| getCatalog() | String | Yes |
| getMetaData() | DatabaseMetaData | Yes |
| getTransactionIsolation() | int | Yes |
| getTypeMap() | Map | No |
| getWarnings() | SQLWarning | Yes |
| isClosed() | boolean | Yes |
| isReadOnly() | boolean | Yes |
| nativeSQL(String sql) | String | Yes |
| prepareCall(String sql) | CallableStatement | Yes |
| prepareCall(String sql, int resultSetType, int resultSetConcurrency) | CallableStatement | Yes |
| prepareStatement(String sql) | PreparedStatement | Yes |
| prepareStatement(String sql, int resultSetType, int resultSetConcurrency) | PreparedStatement | Yes |
| rollback() | void | Yes |
| setAutoCommit(boolean autoCommit) | void | Yes |
| setCatalog(String catalog) | void | Yes |
| setReadOnly(boolean readOnly) | void | Yes |
| setTransactionIsolation(int level) | void | Yes |
| setTypeMap(Map map) | void | No |
| Methods: | Return Types: | Supported: |
Interface DatabaseMetaData |
| allProceduresAreCallable() | boolean | Yes |
| allTablesAreSelectable() | boolean | Yes |
| dataDefinitionCausesTransactionCommit() | boolean | Yes |
| dataDefinitionIgnoredInTransactions() | boolean | Yes |
| deletesAreDetected(int type) | boolean | Yes |
| doesMaxRowSizeIncludeBlobs() | boolean | Yes |
| getBestRowIdentifier(String catalog, String schema, String table, int scope, boolean nullable) | ResultSet | Yes |
| getCatalogs() | ResultSet | Yes |
| getCatalogSeparator() | String | Yes |
| getCatalogTerm() | String | Yes |
| getColumnPrivileges(String catalog, String schema, String table, String columnNamePattern) | ResultSet | Yes |
| getColumns(String catalog, String schemaPattern, String tableNamePattern, String columnNamePattern) | ResultSet | Yes |
| getConnection() | Connection | Yes |
| getCrossReference(String primaryCatalog, String primarySchema, String primaryTable, String foreignCatalog, String foreignSchema, String foreignTable) | ResultSet | Yes |
| getDatabaseProductName() | String | Yes |
| getDatabaseProductVersion() | String | Yes |
| getDefaultTransactionIsolation() | int | Yes |
| getDriverMajorVersion() | int | Yes |
| getDriverMinorVersion() | int | Yes |
| getDriverName() | String | Yes |
| getDriverVersion() | String | Yes |
| getExportedKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getExtraNameCharacters() | String | Yes |
| getIdentifierQuoteString() | String | Yes |
| getImportedKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getIndexInfo(String catalog, String schema, String table, boolean unique, boolean approximate) | ResultSet | Yes |
| getMaxBinaryLiteralLength() | int | Yes |
| getMaxCatalogNameLength() | int | Yes |
| getMaxCharLiteralLength() | int | Yes |
| getMaxColumnNameLength() | int | Yes |
| getMaxColumnsInGroupBy() | int | Yes |
| getMaxColumnsInIndex() | int | Yes |
| getMaxColumnsInOrderBy() | int | Yes |
| getMaxColumnsInSelect() | int | Yes |
| getMaxColumnsInTable() | int | Yes |
| getMaxConnections() | int | Yes |
| getMaxCursorNameLength() | int | Yes |
| getMaxIndexLength() | int | Yes |
| getMaxProcedureNameLength() | int | Yes |
| getMaxRowSize() | int | Yes |
| getMaxSchemaNameLength() | int | Yes |
| getMaxStatementLength() | int | Yes |
| getMaxStatements() | int | Yes |
| getMaxTableNameLength() | int | Yes |
| getMaxTablesInSelect() | int | Yes |
| getMaxUserNameLength() | int | Yes |
| getNumericFunctions() | String | Yes |
| getPrimaryKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getProcedureColumns(String catalog, String schemaPattern, String procedureNamePattern, String columnNamePattern) | ResultSet | Yes |
| getProcedures(String catalog, String schemaPattern, String procedureNamePattern) | ResultSet | Yes |
| getProcedureTerm() | String | Yes |
| getSchemas() | ResultSet | Yes |
| getSchemaTerm() | String | Yes |
| getSearchStringEscape() | String | Yes |
| getSQLKeywords() | String | Yes |
| getStringFunctions() | String | Yes |
| getSystemFunctions() | String | Yes |
| getTablePrivileges(String catalog, String schemaPattern, String tableNamePattern) | ResultSet | Yes |
| getTables(String catalog, String schemaPattern, String tableNamePattern, String[] types) | ResultSet | Yes |
| getTableTypes() | ResultSet | Yes |
| getTimeDateFunctions() | String | Yes |
| getTypeInfo() | ResultSet | Yes |
| getUDTs(String catalog, String schemaPattern, String typeNamePattern, int[] types) | ResultSet | Yes |
| getURL() | String | Yes |
| getUserName() | String | Yes |
| getVersionColumns(String catalog, String schema, String table) | ResultSet | Yes |
| insertsAreDetected(int type) | boolean | Yes |
| isCatalogAtStart() | boolean | Yes |
| isReadOnly() | boolean | Yes |
| nullPlusNonNullIsNull() | boolean | Yes |
| nullsAreSortedAtEnd() | boolean | Yes |
| nullsAreSortedAtStart() | boolean | Yes |
| nullsAreSortedHigh() | boolean | Yes |
| nullsAreSortedLow() | boolean | Yes |
| othersDeletesAreVisible(int type) | boolean | Yes |
| othersInsertsAreVisible(int type) | boolean | Yes |
| othersUpdatesAreVisible(int type) | boolean | Yes |
| ownDeletesAreVisible(int type) | boolean | Yes |
| ownInsertsAreVisible(int type) | boolean | Yes |
| ownUpdatesAreVisible(int type) | boolean | Yes |
| storesLowerCaseIdentifiers() | boolean | Yes |
| storesLowerCaseQuotedIdentifiers() | boolean | Yes |
| storesMixedCaseIdentifiers() | boolean | Yes |
| storesMixedCaseQuotedIdentifiers() | boolean | Yes |
| storesUpperCaseIdentifiers() | boolean | Yes |
| storesUpperCaseQuotedIdentifiers() | boolean | Yes |
| supportsAlterTableWithAddColumn() | boolean | Yes |
| supportsAlterTableWithDropColumn() | boolean | Yes |
| supportsANSI92EntryLevelSQL() | boolean | Yes |
| supportsANSI92FullSQL() | boolean | Yes |
| supportsANSI92IntermediateSQL() | boolean | Yes |
| supportsBatchUpdates() | boolean | Yes |
| supportsCatalogsInDataManipulation() | boolean | Yes |
| supportsCatalogsInIndexDefinitions() | boolean | Yes |
| supportsCatalogsInPrivilegeDefinitions() | boolean | Yes |
| supportsCatalogsInProcedureCalls() | boolean | Yes |
| supportsCatalogsInTableDefinitions() | boolean | Yes |
| supportsColumnAliasing() | boolean | Yes |
| supportsConvert() | boolean | No |
| supportsConvert(int fromType, int toType) | boolean | No |
| supportsCoreSQLGrammar() | boolean | Yes |
| supportsCorrelatedSubqueries() | boolean | Yes |
| supportsDataDefinitionAndDataManipulationTransactions() | boolean | Yes |
| supportsDataManipulationTransactionsOnly() | boolean | Yes |
| supportsDifferentTableCorrelationNames() | boolean | Yes |
| supportsExpressionsInOrderBy() | boolean | Yes |
| supportsExtendedSQLGrammar() | boolean | Yes |
| supportsFullOuterJoins() | boolean | Yes |
| supportsGroupBy() | boolean | Yes |
| supportsGroupByBeyondSelect() | boolean | Yes |
| supportsGroupByUnrelated() | boolean | Yes |
| supportsIntegrityEnhancementFacility() | boolean | Yes |
| supportsLikeEscapeClause() | boolean | Yes |
| supportsLimitedOuterJoins() | boolean | Yes |
| supportsMinimumSQLGrammar() | boolean | Yes |
| supportsMixedCaseIdentifiers() | boolean | Yes |
| supportsMixedCaseQuotedIdentifiers() | boolean | Yes |
| supportsMultipleResultSets() | boolean | Yes |
| supportsMultipleTransactions() | boolean | Yes |
| supportsNonNullableColumns() | boolean | Yes |
| supportsOpenCursorsAcrossCommit() | boolean | Yes |
| supportsOpenCursorsAcrossRollback() | boolean | Yes |
| supportsOpenStatementsAcrossCommit() | boolean | Yes |
| supportsOpenStatementsAcrossRollback() | boolean | Yes |
| supportsOrderByUnrelated() | boolean | Yes |
| supportsOuterJoins() | boolean | Yes |
| supportsPositionedDelete() | boolean | Yes |
| supportsPositionedUpdate() | boolean | Yes |
| supportsResultSetConcurrency(int type, int concurrency) | boolean | Yes |
| supportsResultSetType(int type) | boolean | Yes |
| supportsSchemasInDataManipulation() | boolean | Yes |
| supportsSchemasInIndexDefinitions() | boolean | Yes |
| supportsSchemasInPrivilegeDefinitions() | boolean | Yes |
| supportsSchemasInProcedureCalls() | boolean | Yes |
| supportsSchemasInTableDefinitions() | boolean | Yes |
| supportsSelectForUpdate() | boolean | Yes |
| supportsStoredProcedures() | boolean | Yes |
| supportsSubqueriesInComparisons() | boolean | Yes |
| supportsSubqueriesInExists() | boolean | Yes |
| supportsSubqueriesInIns() | boolean | Yes |
| supportsSubqueriesInQuantifieds() | boolean | Yes |
| supportsTableCorrelationNames() | boolean | Yes |
| supportsTransactionIsolationLevel(int level) | boolean | Yes |
| supportsTransactions() | boolean | Yes |
| supportsUnion() | boolean | Yes |
| supportsUnionAll() | boolean | Yes |
| updatesAreDetected(int type) | boolean | Yes |
| usesLocalFilePerTable() | boolean | Yes |
| usesLocalFiles() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface PreparedStatement |
| addBatch() | void | Yes |
| clearParameters() | void | Yes |
| execute() | boolean | Yes |
| executeQuery() | ResultSet | Yes |
| executeUpdate() | int | Yes |
| getMetaData() | ResultSetMetaData | Yes |
| setArray(int i, Array x) | void | No |
| setAsciiStream(int parameterIndex, InputStream x, int length) | void | Yes |
| setBigDecimal(int parameterIndex, BigDecimal x) | void | Yes |
| setBinaryStream(int parameterIndex, InputStream x, int length) | void | Yes |
| setBlob(int i, Blob x) | void | Yes |
| setBoolean(int parameterIndex, boolean x) | void | Yes |
| setByte(int parameterIndex, byte x) | void | Yes |
| setBytes(int parameterIndex, byte[] x) | void | Yes |
| setCharacterStream(int parameterIndex, Reader reader, int length) | void | Yes |
| setClob(int i, Clob x) | void | Yes |
| setDate(int parameterIndex, Date x) | void | Yes |
| setDate(int parameterIndex, Date x, Calendar cal) | void | Yes |
| setDouble(int parameterIndex, double x) | void | Yes |
| setFloat(int parameterIndex, float x) | void | Yes |
| setInt(int parameterIndex, int x) | void | Yes |
| setLong(int parameterIndex, long x) | void | Yes |
| setNull(int parameterIndex, int sqlType) | void | yes |
| setNull(int paramIndex, int sqlType, String typeName) | void | no |
| setObject(int parameterIndex, Object x) | void | Yes |
| setObject(int parameterIndex, Object x, int targetSqlType) | void | Yes |
| setObject(int parameterIndex, Object x, int targetSqlType, int scale) | void | Yes |
| setRef(int i, Ref x) | void | No |
| setShort(int parameterIndex, short x) | void | Yes |
| setString(int parameterIndex, String x) | void | Yes |
| setTime(int parameterIndex, Time x) | void | Yes |
| setTime(int parameterIndex, Time x, Calendar cal) | void | Yes |
| setTimestamp(int parameterIndex, Timestamp x) | void | Yes |
| setTimestamp(int parameterIndex, Timestamp x, Calendar cal) | void | Yes |
| setUnicodeStream(int parameterIndex, InputStream x, int length) | void | Yes |
| Methods: | Return Types: | Supported: |
Interface ResultSet |
| absolute(int row) | boolean | Yes |
| afterLast() | void | Yes |
| beforeFirst() | void | Yes |
| cancelRowUpdates() | void | Yes |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| deleteRow() | void | Yes |
| findColumn(String columnName) | int | Yes |
| first() | boolean | Yes |
| getArray(int i) | Array | No |
| getArray(String colName) | Array | Yes |
| getAsciiStream(int columnIndex) | InputStream | Yes |
| getAsciiStream(String columnName) | InputStream | Yes |
| getBigDecimal(int columnIndex) | BigDecimal | Yes |
| getBigDecimal(int columnIndex, int scale) | BigDecimal | Yes |
| getBigDecimal(String columnName) | BigDecimal | Yes |
| getBigDecimal(String columnName, int scale) | BigDecimal | Yes |
| getBinaryStream(int columnIndex) | InputStream | Yes |
| getBinaryStream(String columnName) | InputStream | Yes |
| getBlob(int i) | Blob | Yes |
| getBlob(String colName) | Blob | Yes |
| getBoolean(int columnIndex) | boolean | Yes |
| getBoolean(String columnName) | boolean | Yes |
| getByte(int columnIndex) | byte | Yes |
| getByte(String columnName) | byte | Yes |
| getBytes(int columnIndex) | byte[] | Yes |
| getBytes(String columnName) | byte[] | Yes |
| getCharacterStream(int columnIndex) | Reader | Yes |
| getCharacterStream(String columnName) | Reader | Yes |
| getClob(int i) | Clob | Yes |
| getClob(String colName) | Clob | Yes |
| getConcurrency() | int | Yes |
| getCursorName() | String | Yes |
| getDate(int columnIndex) | Date | Yes |
| getDate(int columnIndex, Calendar cal) | Date | Yes |
| getDate(String columnName) | Date | Yes |
| getDate(String columnName, Calendar cal) | Date | Yes |
| getDouble(int columnIndex) | double | Yes |
| getDouble(String columnName) | double | Yes |
| getFetchDirection() | int | Yes |
| getFetchSize() | int | Yes |
| getFloat(int columnIndex) | float | Yes |
| getFloat(String columnName) | float | Yes |
| getInt(int columnIndex) | int | Yes |
| getInt(String columnName) | int | Yes |
| getLong(int columnIndex) | long | Yes |
| getLong(String columnName) | long | Yes |
| getMetaData() | ResultSetMetaData | Yes |
| getObject(int columnIndex) | Object | Yes |
| getObject(int i, Map map) | Object | No |
| getObject(String columnName) | Object | Yes |
| getObject(String colName, Map map) | Object | No |
| getRef(int i) | Ref | No |
| getRef(String colName) | Ref | No |
| getRow() | int | Yes |
| getShort(int columnIndex) | short | Yes |
| getShort(String columnName) | short | Yes |
| getStatement() | Statement | Yes |
| getString(int columnIndex) | String | Yes |
| getString(String columnName) | String | Yes |
| getTime(int columnIndex) | Time | Yes |
| getTime(int columnIndex, Calendar cal) | Time | Yes |
| getTime(String columnName) | Time | Yes |
| getTime(String columnName, Calendar cal) | Time | Yes |
| getTimestamp(int columnIndex) | Timestamp | Yes |
| getTimestamp(int columnIndex, Calendar cal) | Timestamp | Yes |
| getTimestamp(String columnName) | Timestamp | Yes |
| getTimestamp(String columnName, Calendar cal) | Timestamp | Yes |
| getType() | int | Yes |
| getUnicodeStream(int columnIndex) | InputStream | Yes |
| getUnicodeStream(String columnName) | InputStream | Yes |
| getWarnings() | SQLWarning | Yes |
| insertRow() | void | Yes |
| isAfterLast() | boolean | Yes |
| isBeforeFirst() | boolean | Yes |
| isFirst() | boolean | Yes |
| isLast() | boolean | Yes |
| last() | boolean | Yes |
| moveToCurrentRow() | void | Yes |
| moveToInsertRow() | void | Yes |
| next() | boolean | Yes |
| previous() | boolean | Yes |
| refreshRow() | void | Yes |
| relative(int rows) | boolean | Yes |
| rowDeleted() | boolean | Yes |
| rowInserted() | boolean | Yes |
| rowUpdated() | boolean | Yes |
| setFetchDirection(int direction) | void | Yes |
| setFetchSize(int rows) | void | Yes |
| updateAsciiStream(int columnIndex, InputStream x, int length) | void | Yes |
| updateAsciiStream(String columnName, InputStream x, int length) | void | Yes |
| updateBigDecimal(int columnIndex, BigDecimal x) | void | Yes |
| updateBigDecimal(String columnName, BigDecimal x) | void | Yes |
| updateBinaryStream(int columnIndex, InputStream x, int length) | void | Yes |
| updateBinaryStream(String columnName, InputStream x, int length) | void | Yes |
| updateBoolean(int columnIndex, boolean x) | void | Yes |
| updateBoolean(String columnName, boolean x) | void | Yes |
| updateByte(int columnIndex, byte x) | void | Yes |
| updateByte(String columnName, byte x) | void | Yes |
| updateBytes(int columnIndex, byte[] x) | void | Yes |
| updateBytes(String columnName, byte[] x) | void | Yes |
| updateCharacterStream(int columnIndex, Reader x, int length) | void | Yes |
| updateCharacterStream(String columnName, Reader reader, int length) | void | Yes |
| updateDate(int columnIndex, Date x) | void | Yes |
| updateDate(String columnName, Date x) | void | Yes |
| updateDouble(int columnIndex, double x) | void | Yes |
| updateDouble(String columnName, double x) | void | Yes |
| updateFloat(int columnIndex, float x) | void | Yes |
| updateFloat(String columnName, float x) | void | Yes |
| updateInt(int columnIndex, int x) | void | Yes |
| updateInt(String columnName, int x) | void | Yes |
| updateLong(int columnIndex, long x) | void | Yes |
| updateLong(String columnName, long x) | void | Yes |
| updateNull(int columnIndex) | void | Yes |
| updateNull(String columnName) | void | Yes |
| updateObject(int columnIndex, Object x) | void | Yes |
| updateObject(int columnIndex, Object x, int scale) | void | Yes |
| updateObject(String columnName, Object x) | void | Yes |
| updateObject(String columnName, Object x, int scale) | void | Yes |
| updateRow() | void | Yes |
| updateShort(int columnIndex, short x) | void | Yes |
| updateShort(String columnName, short x) | void | Yes |
| updateString(int columnIndex, String x) | void | Yes |
| updateString(String columnName, String x) | void | Yes |
| updateTime(int columnIndex, Time x) | void | Yes |
| updateTime(String columnName, Time x) | void | Yes |
| updateTimestamp(int columnIndex, Timestamp x) | void | Yes |
| updateTimestamp(String columnName, Timestamp x) | void | Yes |
| wasNull() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface ResultSetMetaData |
| getCatalogName(int column) | String | Yes |
| getColumnClassName(int column) | String | No |
| getColumnCount() | int | Yes |
| getColumnDisplaySize(int column) | int | Yes |
| getColumnLabel(int column) | String | Yes |
| getColumnName(int column) | String | Yes |
| getColumnType(int column) | int | Yes |
| getColumnTypeName(int column) | String | Yes |
| getPrecision(int column) | int | Yes |
| getScale(int column) | int | Yes |
| getSchemaName(int column) | String | Yes |
| getTableName(int column) | String | Yes |
| isAutoIncrement(int column) | boolean | Yes |
| isCaseSensitive(int column) | boolean | Yes |
| isCurrency(int column) | boolean | Yes |
| isDefinitelyWritable(int column) | boolean | Yes |
| isNullable(int column) | int | Yes |
| isReadOnly(int column) | boolean | Yes |
| isSearchable(int column) | boolean | Yes |
| isSigned(int column) | boolean | Yes |
| isWritable(int column) | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface Statement |
| addBatch(String sql) | void | Yes |
| cancel() | void | No |
| clearBatch() | void | Yes |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| execute(String sql) | boolean | Yes |
| executeBatch() | int[] | Yes |
| executeQuery(String sql) | ResultSet | Yes |
| executeUpdate(String sql) | int | Yes |
| getConnection() | Connection | Yes |
| getFetchDirection() | int | Yes |
| getFetchSize() | int | Yes |
| getMaxFieldSize() | int | Yes |
| getMaxRows() | int | Yes |
| getMoreResults() | boolean | Yes |
| getQueryTimeout() | int | Yes |
| getResultSet() | ResultSet | Yes |
| getResultSetConcurrency() | int | Yes |
| getResultSetType() | int | Yes |
| getUpdateCount() | int | Yes |
| getWarnings() | SQLWarning | Yes |
| setCursorName(String name) | void | no |
| setEscapeProcessing(boolean enable) | void | Yes |
| setFetchDirection(int direction) | void | no |
| setFetchSize(int rows) | void | no |
| setMaxFieldSize(int max) | void | Yes |
| setMaxRows(int max) | void | Yes |
| setQueryTimeout(int seconds) | void | Yes |
| Methods: | Return Types: | Supported: |
Interface Array |
No | |
Interface Struct |
No | |
Interface SQLOutput |
No | |
Interface SQLInput |
No | |
Interface SQLData |
No | |
Interface Ref |
No | |
Interface Driver |
Support but not to public |
ライセンス体系はどのようになっていますか?
ワークステーション(クライアント)、またはサーバ・ベースでライセンスされます。クライアント・ライセンスは各PCごとにライセンスされます。クライント・ライセンスをWindowsサーバで稼動させることはできません。
サーバライセンスには次の2種類があります。
1) Open Connectionサーバ・ライセンスは 同時接続数には制限はありませんが、プロセッサ毎の価格になります。
2) Limited Connectionサーバライセンスは同時接続数です。 Processor数には依存しません。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
クライアント版はWindows Server上で使用できますか?
できません。Windows XP/Vista/7でのみで使用可能です。WindowsServer上で稼働させる場合は「サーバ版」が必要となります。
サーバライセンスはどの様になっていますか?
サーバライセンスは同時接続(アプリケーション・サーバとDB2サーバ間)の数または無制限接続の両方があります。
サーバライセンスの同時接続数制限版はどの様にライセンスされますか?
プロセッサ数には依存しませんが、同時接続数が5, 10, 25等に制限されます。
無制限接続のサーバライセンスはどの様にライセンスされますか?
無制限接続のサーバライセンスはアップリケーション・サーバのプロセッサ数に依存します。
開発者(ディベロッパ)・エディションはどの様な製品ですか?
開発者エディションはサンプル・ソースコード・コードが含まれ、自社アプリケーションに組み込む権利を有します。
ODBCとOLEDBは64ビットWindows をサポートしますか?
はい、64ビット版を準備しています。
HiT ODBC/400とIBM Client Accessを比較した時のパフォーマンスは?
Client AccessはClient Access機能(ODBC, Terminal Emulatorなど)を使用した最初の時のみ認証によって接続時間を最適化する一方、HiT ODBC/400は、結果セット検索時間を最適化します。
結果として小さなテーブル(検索時間が非常に短くなる。)を使用している場合は接続認証が一回のみ行われるので、Client Accessを使用した方がパホーマンスの向上が見れます。しかし3000レコード以上の大きなテーブルで結果セットを使用する場合は結果セット検索時間では HiT ODBC/400の方がClient Accessよりパフォーマンスは優れています。
またHiTのDB2ワイアー・プロトコール・ドライバはDB2クライント・ライブラリを必要としないため、直接DB2サーバに接続するためにコミュニケーション・オーバが無く、アプリケーション・パフォーマンスを非常に向上させます。
HiT OLEDB と HiT ODBCのパフォーマンスを向上させる方法は?
いくつかの手法があります。
1.ユニーク・インデックス
もし、AS/400のファイルがユニーク・インデックスであれば、パフォーマンスは改善されます。特に大きなテーブルからデータをselectしたり、同じクエリでいくつかのテーブルをJOINする場合です。その場合はファイルにプライマリ・キーを設定し、CREATE UNIQUE INDEXを1度だけ稼動させます。
2.ストアード・プロシージャ
AS/400に送るクエリがいつも同じで、アプリケーションが同じステートメントのクエリを何度も繰り返し、いくつかのパラメータを変更しているのみの場合はAS/400のストアード・プロシージャにそれらのステートメント・クエリをストアしていくつかのSELECT, INSERT, UPDATEなどの代わりに1つのCALLを発行します。
3.カーサ
ADOを使用してVisual BasicやASP/VBSのアプリケーションを開発しているときはConnection や Recordsetオブジェクト用にカーサ・ロケーション・プロパティ設定を選択することができます。
4.パラメトリック・クエリ
パフォーマンスでもっとも重要な要素はパラメトリック・クエリを使用することです。パラメトリック・クエリは「テンプレート・クエリ」として説明されることがあり、同じ規模の大きいテーブルで何度の実行できるクエリです。パラメトリック・クエリは一度準備をすることで、パラメータをパスすることで何度も実行することができます。これによりサーバにその都度送られるオーバーヘッドを削減し、「実行可能なフォーマット」でのクエリにコンパイルし、リクエストにてきせつに応じるためにデータをメモリ・スペースにアロケートし、アクセス・パスを準備します。
詳しくは:http://www.hitsw.com/support/kbase/optimization/Performance_OLEDBandODBC.htm
ODBCで日本語が文字化けします。
日本語文字化けが発生する場合、CCSIDに問題がある場合がほとんどです。
まずは、ODBC設定画面にて、Host Code Pageが「5026」または「5035」であるかどうかをご確認ください。
もしAS/400側で日本語文字を扱っているCCSIDが1027などの本来シングルバイト用のフィールドの場合は、ODBC設定画面にて、「Use Host Code Page to override column CCSIDs」にチェックを入れてください。これはフィールドのCCSIDを「Host Code Page」のものに変換する機能です。
[HiT][HiT ODBC/400][SQL/400][ODBS Error][SQL0010]エラーが発生します。
以下をご確認ください。
・SQLクエリの最後のセミコロン”;”を削除してください。
・SQLクエリで2バイト文字を扱う箇所は、パラメータSQLを使用してください。
ExcelやAccessから、設定したODBCを呼出す事ができません。
ODBCとExcel/Accessはともに32bitもしくは64bitかで一致されている必要があります。
例えば、ODBC64bit版をご利用いただく場合は、Excel/Accessも64bit版が必要です。ただし、Excel/Accessの64bit版はOffice2010からの対応になっておりますので、Office2007以前の場合はODBCの32bit版をご利用ください。OSが64bitの場合でも32bit版のODBCは問題なく動作いたします。
VBScriptで明示的にトランザクションの開始(BeginTrans)・終了(CommitTrans)をしたのですがExecuteコマンドを実行すると、[HiT][HiT ODBC/400][SQL/400][ODBS Error][SQL7008] 操作にはXXXXXXのM7CPが正しくない、というエラーメッセージが出力され登録出来ませんでした。トランザクションを自動(BeginTrans・CommitTransをコメント)にすると正常に登録されます。
Insert処理を行なうテーブルにジャーナルを作成して動作確認をお願いします。
BeginTrans()、CommitTrans()を使用する際にはジャーナルの作成が必要となります。
Veeam -導入・製品 (27)
複数の仮想マシンをまとめてバックアップは可能ですか?
はい、可能です。下記の単位でのバックアップが可能です。
・クラスタ
・フォルダ
・リソースプール
・Virual App
・ホスト
・ユーザーが選択した仮想マシン
NutanixはVeeamに対応していますか?
はい、対応しています。
Veeam Backup for Nutanix AHVを導入することで
Nutanix AHV上仮想マシンのバックアップを簡単に実施することができます。
◇Veeam Backup for Nutanix AHV製品ページ
https://www.climb.co.jp/soft/veeam/van/
Veeam Backup & Replicationは仮想マシンにインストール可能ですか?
可能です。
要件を満たしていれば、物理/仮想問わずインストールできます。
システム要件はコチラのページの管理サーバ(Veeamインストール先)をご確認ください。
物理サーバのバックアップも行えますか。
はい、Veeam Backup & Replication Universalライセンスをご利用いただくことで、
仮想サーバに限らず、物理サーバも併せてバックアップ可能です。
Universalライセンスにつきましては、こちらをご参照ください。
バックアップ対象の仮想マシン名は日本語でも問題ないですか?
仮想マシン名に日本語が含まれている影響で、バックアップやリストア中に予期せぬ動作を引き起こす可能性があります。
※例えば、38文字以上のVM名(日本語)の VMからファイルリストアを行う際に失敗する可能性があります。
そのため仮想マシン名やネットワーク名等はなるべく英数字での記載をお願いいたします。
バックアップが不可能なディスクタイプはありますか?(VMware)
Veeamはバックアップの際にスナップショット機能を利用します。そのためこの機能が利用できない物理モードのRow Device Mappingではバックアップが行えません。
またリストアやレプリケーションの際に作成するVMにつきましてはThickもしくはThinディスクでの作成が可能です。
アップデートや再インストール時にVeeamの設定情報を引き継げますか?
はい、引き継げます。
Veeam Backup & Replicationの設定情報はSQL Serverに保存されているため、既にあるVeeam Backup & Replicationのインスタンスを再利用することで設定情報等の引き継ぎが行えます。
しかしバージョンアップに伴い表の構造等が変更されますので、基本的には同一バージョンもしくは上位のバージョンでのみ再利用が可能です。古いバージョンを再インストールした際に、インスタンスの再利用が行えない場合もございますので、お気をつけください。
Veeam Backup & Replicationのインストール先で物理マシンと仮想マシンの違いはありますか?
基本的にはどちらも同様に使用できます。
しかし、仮想マシンでは物理接続のデバイスが使用できません。
また、Veeamサーバの負荷がホストにも影響します。
バックアップ対象の仮想マシンについて、OSの違いによるバックアップの可/不可はありますか?また、仮想マシンの電源ON/OFFの違いによるバックアップの可/不可はありますか?
仮想マシンの電源ON/OFFの違いやOSの違いによるバックアップの可/不可はありません。
また、OSをインストールしていない状態の仮想マシンであってもバックアップ可能です。
関連トピック
Veeam Backup & Replicationを物理サーバにインストールする場合に自身のバックアップは 他のソリューションで行うことになりますか?
Veeam Backup & Replicationサーバは仮想または物理環境のどちらでもインストール可能です。
自身のバックアップについては接続情報や構成情報のみであればConfiguration Backup機能でバックアップ可能です。
https://www.climb.co.jp/blog_veeam/veeam-backup-7953
OSのイメージごとバックアップする場合は、仮想マシンにインストールしていればVeem自身でバックアップ可能です。
物理環境にインストールした時にはVeeam Agentを導入することでバックアップが可能です。
vCenter Serverの登録は必ず必要ですか?
スタンドアロンのvSphereホストの登録が可能なので、必須ではありません。
vCenter Serverを登録しておくと、VMwareのHAやDRSで仮想マシンが移動した場合も、
移動先を追跡しJobの継続実行が可能です。
バックアップデータからのリストアでできることは何ですか?
バックアップデータからは、下記リストアが可能です。
・新規の仮想マシンの作成
・VMDK、VMX等の仮想マシンの構成ファイルのリストア
・Amazon EC2やAzure VMとしてクラウド環境へ仮想マシンをリストア
・ファイルレベルのリストア
・一部アプリケーションのアイテム
Active Directory、SQL Server、Exchange など
※Standardエディションでは制限がございます。
https://www.climb.co.jp/soft/veeam/outline/price.html#price02
https://www.climb.co.jp/soft/veeam/detail/restore.html#detail4
レプリケーションデータからのリストアでできることは何ですか?
レプリケーションデータからは、下記リストアが可能です。
・レプリケーション(複製)した仮想マシンの起動
・ファイルレベルのリストア
・一部アプリケーションのアイテム
Active Directory、SQL Server、Exchange など
※Standardエディションでは制限がございます。
https://www.climb.co.jp/soft/veeam/outline/price.html#price02
https://www.climb.co.jp/soft/veeam/detail/restore.html#detail4
関連トピック
バックアップデータからのリストアでできることは何ですか?
バックアップ格納先を外付けのディスク(NAS、USB)にして定期的にディスクの交換は可能ですか?
はい、可能です。ただしディスク交換後の初回のバックアップはフルバックアップを行う必要があります。
Veeam製品(Backup & Replication、ONE)を1台のマシンにインストールする際の注意点はありますか?
どちらもSQL Serverを使用するため、SQL Serverへの負荷が高くなり、それによってバックアップジョブへ影響が出る可能性もございます。特にデフォルトでは、Expressエディションがインストールされるため、影響が出やすいかもしれません。
Hyper-Vには対応していますか?
はい、対応しています。
サポートするプラットフォームはこちらをご参照ください。
vSphereには対応していますか?
はい、対応しています。
サポートするプラットフォームはこちらをご参照ください。
エディションの違いを教えてください。
Standard、Enterprise、Enterprise Plusのエディションによって、利用できる機能が異なります。
詳細はこちらをご参照ください。
エージェント導入が必要ですか?
いいえ、ユーザがESX(i)、仮想マシンにエージェントを導入する必要はありません。
バックアップスケジュールを設定できますか?
はい、設定できます。時間指定、曜日指定、月指定の他、指定時間毎や指定日(第1週の水曜日等)の設定が可能です。また、除外設定も可能です。
ディザスタリカバリ(障害復旧)に使用できますか?
はい、使用することができます。
Veeam Backup & Reokicationのレプリケーション機能を使用することで障害復旧が可能です。
例)ESX(i)(A)で障害発生時にESX(i)(B)にレプリケーション(複製)しておいた仮想マシンを電源ONすることで復旧
※レプリケーション(複製)しておいた仮想マシンを電源ONする作業はユーザーがマニュアルで行う必要があります。
ディザスタリカバリ構成について ≫
ファイルレベルでのリストアは可能ですか?
はい、可能です。(Windows系、Linux系、Macに対応しています。)
ファイルレベルリストアでサポートしているファイルシステム >>
バックアップ先はどこが選択できますか?
バックアップ先には、Veeam Backup & Replicationインストールサーバ、接続しているESX(i)のローカルディスクが選択できます。
また、SAN、NAS、DAS、Linuxサーバもバックアップ先に選択可能です。
さらに、2次バックアップ先としてテープデバイスやクラウドをバックアップの保存先として指定することが可能です。
関連トピック
サポートするバックアップ保存先
VMware vSphere Hypervisor(ESXi無償版)はサポートしていますか?
VMware vSphere Hypervisor(ESXi無償版)は使用できません。
VMware vSphere EssentialsやVMware vSphere ESX(i)へアップグレードが必要となります。導入前の評価を行いたい方はVMware vSphere評価版をお使いください。
Linux系OSの仮想マシンのバックアップは可能ですか?
はい、可能です。
他にはWindows、Unix、FreeBSD、Solaris、MacOSがバックアップ可能です。
関連トピック
バックアップ対象の仮想マシンについて、OSの違いによるバックアップの可/不可はありますか?また、仮想マシンの電源ON/OFFの違いによるバックアップの可/不可はありますか?
OSをインストールしていない、又はVMDKファイルなしの仮想マシンをバックアップできますか?
Enterprise Managerとはどんなソフトですか?
Veeam Backup Enterprise Managerを使用することで、ユーザはWEBブラウザから複数のVeeamインストールマシンで作成したJobの管理(Jobの起動、停止)が可能です。
また、リストア可能なユーザを制限できるリストア委任オプションなどを行うために必要です。
参考: Veeam Backup Enterprise ManagerによるVeeam Backupサーバの統合管理
Veeam Backup & ReplicationをLinux系OSにインストール可能ですか?
Veeam Backup & ReplicationはWinodws系OSにのみインストール可能です。
Veeamインストール先環境(ソフトウェア)
Veeam -ライセンス (8)
Veeam Universal License (VUL)はどんなライセンス体系ですか?
Veeam Universal License(VUL)は、サブスクリプション(年額前払)形態でご利用いただけます。インスタンス数(保護対象数)または保護容量で課金するライセンス体系で、以下が保護対象となります。
●仮想マシン(vSphere/Hyper-V/AHV)
●物理サーバ(Windows/Linuxなど)
●クラウドインスタンス(AWS/Azure/GCP)
●NASデータ
詳細は:
Veeam Universal License (VUL)について | クライム情報発信ブログ:ClimbMeUp
詳しくはお問合せください。
お問合せフォームはコチラ
Veeam Availability Suiteとは、どんなライセンスでしょうか?
Veeam Backup & Replication とVeeam ONEとのパッケージ製品です。
Veeam (Backup) Essentialsのような数量制限はありません。
詳しくはこちらのサイトを参照ください。
インスタンスとはなんでしょうか?
保護対象の単位です。1インスタンスにつき10個まで、以下のバックアップ対象を割り当てることができます。
●1仮想マシン(vSphere/Hyper-V/AHV)
●1物理サーバ(Windows/Linuxなど)
●1クラウドインスタンス(AWS/Azure/GCP)
●500 GB分のNASデータ
詳しくはお問合せください。
お問合せフォームはコチラ
Veeam Essentials/ Veeam Backup Essentialsとは何ですか?
Veeam Backup & ReplicationとVeeam ONEとのパッケージ製品(Veeam Availability Suite)の廉価版で、中小規模向けの仮想環境統合ソリューションです。
1ライセンスにつき5インスタンス保護できます。
※1管理サーバあたり、10ライセンス(50インスタンス)の制限があります。
詳細はこちらをご参照ください。
DRサイトから運用サイトへフェイルバックする際に、DRサイト側にライセンスは必要ですか
必要ありません。
ライセンスはレプリケーション元となるオリジナルの仮想マシンのみ必要になります。
フェイルオーバーやフェイルバックの際、DR環境に作成した仮想マシンにライセンスは必要ありません。
ライセンス体系はどのようになっていますか?
サブスクリプション(年額前払)形式となります。
1ライセンスにつき10個まで以下対象を保護できます。
●1仮想マシン(vSphere/Hyper-V/AHV)
●1物理サーバ(Windows/Linuxなど)
●1クラウドインスタンス(AWS/Azure/GCP)
●500 GB分のNASデータ
※Veeam Backup Essentials の場合
1ライセンスで5台(1環境につき50台の制限)
詳細はこちら
Veeam -評価 (4)
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから30日間となります。
30日間の評価用ライセンス期間終了後、機能が制限されたCommunity Edition(無償版)に切り替わります。
評価版に機能制限はありますか?
評価版に機能制限はありません。
Veeam Backup & Replicationの全機能を30日間無償でご使用いただけます。
Veeam -購入サポート (8)
Contract No.とは何ですか?
Contract No.はユーザがVeeam/クライムとのサポート・保守に加入した最新(または最後)の追跡番号です。
この番号はユーザのライセンス・ポータルでも確認することができます。
サポート・保守更新時には必ず必要になりますので、Contract No.をお問合せください。
サポート・保守が更新されますと、暫くした後、新たなContract No.がアサインされます。
以前のContract No.では追跡ができなくなります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
ソフトのメニュー類は日本語には未対応です。
しかし、直観的なクリック操作で簡単に扱える製品となっておりますし、
日本語の製品マニュアルもご用意しておりますので使用には問題ありません。
製品には初年度保守が含まれますか?
はい、含まれます。
サブスクリプションライセンス期間内は保守サポートのご利用が可能です。
サポートは最新バージョンのみですか? 古い(前の)バージョンもサポートしてもらえますか?
最新バージョン以外の古いバージョンのサポートも承っております。
しかし、開発元(Veeam 社)の正式サポートは最新バージョンとその1つ前のバージョンまでとなります。(例:2022年1月現在のVeeam Backup & ReplicationのバージョンはVer11.0、10.0、9.5、9.0、8.0、7.0、6.5…と存在していますが、このときの正式サポート対象はVer11.0、10.0 となります。)
そのため、古いバージョンの場合、いただいたご質問の内容によっては開発元からのサポートを受けられず、アップグレードをお願いすることになりますので、ご了承ください。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
Veeam -機能 (113)
スケジュールで指定していない曜日にフルバックアップが実行される。
Active Full Backupの設定をご確認ください。
ジョブのスケジュールとは別に、Active Full Backupを実行するよう設定した曜日にもジョブが実行されます。
例えば、毎週土曜日 20:00にジョブを実行するようスケジュールしており、
Active Full Backupを日~土までの全て曜日で有効にしている場合、
土曜日以外の日~金も20:00にジョブが実行されます。
レプリケーションしたいVMのクローンVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションを行えますか?
オリジナルの仮想マシンとクローンの仮想マシンをマッピングすることで、
差分レプリケーションからジョブを開始することができます。
参考: レプリカシーディング・レプリカマッピング機能について
関連トピック
vCloud Backupのジョブを複数同時に実行したが、片方しかバックアップが処理されていないように見える。
各ジョブのバックアップ対象が同じvApp内のVMか確認してください。
その場合、現在処理中のジョブによってvAppがロックされているため、
もう片方のジョブは待ち状態となります。
現在処理中のジョブが終了後、処理が開始されます。
レプリケーションが”The operation is not allowed in the current state.”または”その操作は、現在の状態では実行できません。”で失敗します。
以下をご確認ください。
・レプリケーション元ESXiホスト
・レプリケーション先ESXiホスト
・レプリケーション対象VMのハードウェアバージョン
レプリケーション先のESXiホストがVMのハードウェアバージョンと互換性がない場合に、
このエラーによってレプリケーションが失敗します。
互換性のある状態にする必要があるため、
対処法としては、以下の2通りの方法があります。
・レプリケーション先ESXiホストをバージョンアップする。
・VMのハードウェアバージョンをダウングレードする。
Enterprise ManagerでROLES設定を行いVMを選択するときに、一部ホストが表示されない。
以下に該当していないかご確認ください。
・vCenter経由とスタンドアロンホストの両方で同一ホストを登録している。
・どちらもホスト名で登録されている。
このとき、名前解決が行えず、Enterprise Managerが情報を正常に収集できません。
以下の対応を実施することで、全てのホストが表示されるようになります。
1.以下のいずれかを実施します。
・スタンドアロンホストをホスト名ではなく、IPアドレスで登録しなおす。
・Veeamサーバのhostsファイルにスタンドアロンホストのホスト名をIPアドレスを記載する。
2.Veeamコンソールで上記のホストをRescanします。
3.Enterprise ManagerでVeeamサーバの情報を収集します。
Veeamで作成したレプリカVMをバックアップできますか?
バックアップすることは可能ですが、CBT機能を有効にできないため、毎回、VMの全データを読み取り、増分の検出を行います。
そのため、増分バックアップは可能ですが、フルバックアップと同程度の時間がかかってしまうかもしれません。
ジョブのスケジュールをAfter this jobとしたとき、先に実行されたジョブが失敗した場合に、後続のジョブが実行されるか。
ジョブの成功、失敗問わず、後続のジョブは実行されます。
Veeam静止点処理において必要な認証情報をVM個別に指定する方法はありますか?
はい、あります。
Guest Processingステップの「Credentials…」にて個別に認証設定を行うことが可能です。
詳細は、以下URLをご参照ください。
関連トピック
Job作成時のオプション “Enable application-aware image processing” はどんな機能ですか?
バックアップ対象(VM01, VM02)からVM02を除外した場合、VM02のリストアポイントは指定した世代数を保持しますか?
いいえ、保持しません。
例えば、リストアポイントを4世代とした場合、バックアップを取得するたびに世代数が減っていきます。
11/1, 11/2, 11/3, 11/4とバックアップを取得し、11/5にVM02が除外されたバックアップを取得した場合、VM02のリストアポイントは11/2, 11/3, 11/4となり、11/1のリストアポイントは消されます。
最終的には11/4のリストアポイントがフルバックアップファイル内に残り続けます。
これを消すにはフルバックアップの再作成や再構成(Compact full)が必要です。
Veeam V12新機能:オブジェクトストレージへの直接バックアップ
V12では、Direct-to-ObjectとDirect-to-Cloudの2つの主要な機能を提供しています。最初の機能は、バックアッププロキシやエージェントからオブジェクトストレージに直接バックアップを送信することで、中間ステップを回避することができます。さらに、このようなストレージへの直接接続が不可能な場合、トラフィックはゲートウェイサーバーの弾力的なプールを介してリダイレクトされることができます。さらに、ROBO(Remote Office Branch Office)環境を含め、より効率的なクラウドへの直接バックアップを実装しています。
また、新しいSmart Object Storage API(SOSAPI)ソフトウェア・インターフェースにより、オブジェクト・ストレージ・ベンダーがVeeam Backup & Replication v12と深く統合できるようになったことも特筆に値する(パフォーマンスの向上とユーザー・エクスペリエンスの改善に向けて)。
Veeam V12新機能:イミュータビリティ機能の強化
イミュータブル(Immutable)バックアップ機能は、ランサムウェアからバックアップを保護する手段を実装しています。この機能は、オンプレミスとクラウドネイティブの両方のワークロードで利用でき、ストレージのライフサイクルを通じてバックアップを保護し、管理者側の操作からも保護します。また、バックアップだけでなく、アラームにも不変性を持たせることができるため、より高度なインフラ保護が可能です。
イメージレベルでのバックアップのサポートに加え、NASストレージ、スタンドアロンエージェント、AWSとMicrosoft Azureのバックアップ(Azure Blob Storageも)、HPE StoreOnceストレージでバックアップのイミュータビリティが利用可能です。また、トランザクションログやエンタープライズアプリケーションに対しても、プラグインを介して利用することができます。
Veeam V12新機能:多要素認証とベストプラクティスアナライザー
これらの高度なセキュリティ機能により、管理者は2つの新しいツールを手に入れることができます:
多要素認証は、RFC 6238に基づくTOTP(Time-Based One-Time Passwords)の仕組みに基づく2要素認証(2FA)機能を通じてコンソールへのアクセスを可能にします。個々のアカウントに対して有効にすることができます。
Best Practices Analyzerコンポーネントは、バックアップサーバーと製品の構成をチェックし、セキュリティと復旧成功の可能性を向上させるための重要な変更を管理者に提案します。
Veeam V12新機能:バックアップのインフラ整備
回転メディアに切り替えると、ディスクは自動的に既存の古いバックアップからクリアされます。さらに、ユーザは既存のバックアップチェーンを使い続けることもでき、現在のタスクにのみ属するバックアップを削除するか、メディア上のすべてのバックアップを削除するかの2つのオプションのうち1つを選択することができます。
v12では、SOBRリバランス機能が導入されました。Performance Tierエクステントのブロックおよびファイルストレージレベルでストレージ消費をリバランスし、エクステント間のデータ分散を均等にすることができるようになりました。この操作は、新しいエクステントを追加するときに実行する必要がありますが、常に実行する必要はありません。エクステント退避とSOBRリバランスの操作は、前述した新しいVeeaMoverエンジンを使用して、エクステント間でより効率的にバックアップを移動させます。
また、ユーザーの要望により、マルチサイトやネットワーク環境でのトラフィックを管理するためのいくつかのインターネットルールが追加されました:
最後に、メール通知のOAuth 2.0対応です。SMTPによる認証に加え、Google GmailとMicrosoft 365のOAuthプロトコルによる認証をVBR V12がサポートするようになりました:
Veeam V12新機能:バックアップとリカバリー
新しいBackup Copyジョブは、新しいプラットフォームの機能との互換性を確保するために、個々のVMに基づく新しいフォーマットでチェーンを作成します(Per-machine backup chain)。既存のジョブはこのアップデートの影響を受けません。
アプリケーショングループについては、仮想テストラボで起動する前に、Windowsファイアウォールのネットワーク接続を自動的に無効化するオプションが追加されました。これは、リストアプロセスのテストが必要なバックアップで、ファイアウォールが外部接続をブロックするのを防ぐために必要です。
そして最後の非常に便利な機能です。これからは、更新されたBackup Browserを使って、復元ポイントと本番機のファイルを比較することができ、選択したバックアップが取られた後にどのファイルが変更または削除されたかを表示します。
また、バックアップシステムと本番システムの間で、個々のファイルやフォルダの属性の違いを、新しいダイアログボックスを使って1画面で確認するオプションが追加されました:
もう一つの新機能は、ファイルやフォルダーのアクセスコントロールリスト(ACL)だけを復元する機能です。これは、管理者が誤ってフォルダやファイルのパーミッションを一括で変更してしまった場合に必要になることがあります。また、v12では、Windowsファイルを直接復元する際に、異なるターゲットマシンを選択できるようになりました(これまではLinuxのみ)。最後に、バックアップのエクスポートの機能が向上し、元のバックアップがあった同じリポジトリだけでなく、エクスポートしたポイントの保存先を任意に選択できるようになりました:
Veeam V12新機能:テープバックアップの改善
WindowsとLinuxの両サーバーに接続されたテープライブラリーやメディアをテープバックアップ用に登録することが可能に:
Backup-to-Tapeタスクは、ワークロードの種類に関係なく、即時モードまたは定期モードの新しいマルチプラットフォームBackup Copyジョブタイプによって作成されたすべてのバックアップコピーのエクスポートをサポートするようになりました。
すべてのテープ機能で、LTO-9テープの初期化プロセスをサポートし、初期化に時間がかかるとタイムアウトするのではなく、初期化が完了するまで正しく待機するようになりました。カセットテープを誤って消去しないように、InventoryとCatalogの操作後にテープメディアが自動的にテープライブラリードライブから排出されるようになりました。
Veeam V12新機能:CDP(Continuous Data Protection)の改善
CDPプロキシはLinuxサーバー上で動作するため、Windowsのライセンスを節約することができます。通常のバックアップ作業に加え、任意のクラウドホストサービスプロバイダを使用して、CDPポリシー内でレプリケーションを実行することができます。そして、VMやvAppモジュールのインスタントリカバリ機能を持つCloud Directorインスタンス内でレプリケーションを使用することができます。また、CDPはvVolスナップショットのネイティブサポートを提供するようになり、そこに保存されるオブジェクトの数を減らし、vVolボリュームのスケーリングに小さな制限があるデバイスでの信頼性を向上させます。
Veeam V12新機能:Veeam Agentの改良
Windows Serverに加え、保護グループウィザードに、Windows 10以降を実行しているワークステーションにVeeam changed block tracking (CBT) ドライバをインストールし、より高速な増分バックアップを行うオプションが追加されました。また、管理者はBare Metal Recoveryのリストアタスクのためにユーザーに与えることができる一時的なアクセスキーまたはリカバートークンを生成することができます。
v12のリリースに伴い、ゲストOS用の利用可能なすべてのエージェントがソリューション内で更新されたことに留意してください:
- Veeam Agent for Microsoft Windows
- Veeam Agent for Linux
- Veeam Agent for Mac
- Veeam Agent for AIX
- Veeam Agent for Solaris
Veeam V12新機能:アプリケーションプラグイン
保護グループウィザードが改善され、グループに含まれるサーバーのアプリケーションプラグインのインストールとアップデートを制御するための設定が追加されました。アプリケーションのトポロジーに関する情報収集と、スキャンおよび再スキャン時のOracle RACおよびSAP HANAシステムの検出ができるようになりました。
アプリケーションのバックアップポリシーには、各サーバーのバックアップ処理をリアルタイムで監視し、データベースやREDOログのバックアップの統計やレポートを可視化するツールがあります。
また、Oracle RMAN、SAP HANA、SAP on Oracleのバックアップをバックアップコンソールからポリシーに基づいてオーケストレーションする機能があり、各データベースサーバーのプラグイン設定やバックアップシナリオを手動で整備する必要がなくなりました。また、Version12では、これらのプラグインによるバックアップと復旧の速度が最大で3倍に向上しています。
Microsoft SQL Server用の新しいプラグインは完全に刷新され、SQL Server(VDIプラグイン)との深い統合を実現し、Veeamリポジトリへの直接バックアップを可能にしました。VDIプラグインは、バックアップの一貫性を確保するためにネイティブな手段を使用し、スナップショットベースのバックアップとは異なり、Microsoft VSSに依存しないため、共有ボリュームを持つWindows Server Failover Clustersなど、異なるSQL Server構成のバックアップを可能にします。
Veeam V12新機能:PostgreSQLのサポート
マルチプラットフォームのPostgreSQLエンジンがサポートされ、Microsoft SQL Server Express Editionのデータベースサイズ(10GB)の制限を回避することができるようになりました。SQL Server Express Editionはまだサポートされていますが、Veeam Backup and Replication製品に含まれなくなりました。
PGAdminでPostgreSQLデータベースがどのように見えるかをご紹介します:
さらに、Linux上のPostgreSQLデータベースのポイントインタイムリカバリーのためのトランザクションログのアプリケーションアウェアバックアップがサポートされるようになりました。同じ機能は、Microsoft SQL ServerやOracleではすでに提供されていました。
また、PostgreSQLの経験を持つ管理者でなくてもインスタンスをリストアできる「Veeam Explorer for PostgreSQL」という製品も登場しました。インスタンスの任意のポイントインタイム状態をバックアップから指定されたDev/Testサーバに直接公開することができ、その後、公開されたデータベースに加えられた変更をエクスポートまたは元に戻すことができます。
Veeam V12新機能:新規VeeaMover エンジン
VeeaMoverを使用すれば、異なるタイプのリポジトリ間でデータを移動することができます。ソースとターゲットリポジトリのタイプを気にする必要はもうありません – VeeaMoverが自動的にデータ移動のすべての作業を処理します。
さらに、バックアップはタスク間で簡単に移動できるようになり、関連するすべての操作が自動的に実行されます(例えば、包含リストや除外リストの操作など)。また、保持ポリシーを保持したまま(変更も可能)、数回のクリックでバックアップチェーン全体を別の場所に移動させることができます。
Veeam V12新機能:バックアップコンソールの改良
タスクセッションで対応するマシンをクリックすることで、タスク内のすべてのマシンに対してこの操作を開始することなく、個々のマシンに対して処理の再開やアクティブフルバックアップの実行ができるようになりました。また、誤ってタスクに追加された場合でも、処理から完全に除外したいマシンのマスターリストを指定することで、恒久的または一時的な除外の管理がより簡単になりました。Global Exclusionsダイアログはメインメニューから利用でき、これらのマシンはインベントリータブでDisable processingオプションが選択されています。
また、便利な機能として、既存のバックアップをタスクから切り離すことができ、次のフルバックアップ実行時に新しいバックアップチェーンが開始されます。切断されたバックアップは、「バックアップ」タブの「孤児」セクションに、最新の保持ポリシーとともに表示されます。
Veeam V12新機能:プライマリーとセカンダリーのストレージの改善
バックアップタスクは、既存のストレージレプリケーションリンクを使用して、追加のリカバリポイントとしてストレージベースのスナップショットに基づくレプリカを作成できるようになりました。これにより、プライマリストレージへの負荷を避けるために、セカンダリストレージアレイからバックアップを取ることができます。
さらに、Veeam のUniversal Storage APIのVer2が導入され、スナップショットレプリケーションとアーカイブのオーケストレーション機能、および同期レプリケーションのサポートが含まれています。Cisco HyperFlex、IBM Spectrum Virtualize、NetApp All SAN Array(ASA)、Dell Data Domain、Infinidat InfiniGuard、富士通 CS800、HPE StoreOnce、HPE Nimble、HPE Alletra 5000/6000ストレージアレイ向けに、バックアップの不変性など多くの重要機能が追加されています。ネイティブブロッククローニング機能の拡張サポートがExaGridストレージアレイに追加されました。
Hyper-Vでパススルーディスクは処理可能ですか?
Hyper-V上の仮想マシンに接続されたパススルーディスク(物理ディスク)のバックアップおよびレプリケーションはHyper-V側の制約により行うことができません。処理はスキップされます。
仮想ディスク部分は正常に処理されます。
バックアップを取得している仮想マシンのデータストアを、ストレージvMotionで別のデータストアに移動した場合、差分バックアップを継続できますか?
VMware 5.5 Update 2以降でしたら、継続して差分バックアップを行うことが可能です。
それ以前のバージョンですと、VMwareの制限に引っかかり、CBTがリセットされてしまいます。
■ Change Block Tracking が vSphere 5.x でのストレージ vMotion 操作の後でリセットされる
関連トピック
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
バックアップ対象の仮想マシンをStorage vMotionで移動した後、バックアップジョブを作り直す必要がありますか?
EMC DataDomainをリポジトリにする場合、EMC DataDomain Boostは必須ですか?
必須ではございません。
ただし、Veeamとの連携機能は使用できないため、通常の重複排除ストレージとして使用します。
その場合には、リポジトリの種類は「Dedupe Storage」ではなく、「CIFS」として登録します。
差分リストアはできますか?
Veeam Backup & Replication Ver8からQuick Rollbackという機能が追加されました。
これは差分データ・リストア機能です。
このQuick Rollback機能の使用制限:
1. Network または Virtual Appliance モードのみで使用可能。VMwareサイドの制限でDirect SAN Accessモードでは使用できません。
2.続けて2つの差分リストア・セッションを実行することは出来ません。VMまたはVMディスクに対して差分リストアを実行した後にそのVM上のCBTはリセットされます。差分リストアが再度実行できるように最低1回の差分バックアップを実行する必要があります。
Version 9で作成したバックアップファイルをVersion 8で使えますか?
使用できません。
古いバージョンから新しいバージョンへアップグレードした際には、
そのままバックアップファイルを使い続けることが可能ですが、
新しいバージョンのファイルを古いバージョンで扱うことはできません。
LVM構成のLinuxからファイル単位でリストアできますか?
可能です。
その他対応しているファイルシステムの詳細は下記弊社ブログ記事をご覧ください。
Veeamのファイルレベルリストアはここが違う!多くのファイルシステムをサポートできる理由とは?
IDEとSCSIが混在しているVMをバックアップした時、SCSIもVirtual Applianceモードで処理できない。
IDEとSCSIが混在しているVMの場合、すべてのディスクでVirtual Applianceモードが使用できないのは仕様となります。
バックアップ処理が開始される前にすべてのディスクをチェックしており、一つでもHotAddが使用できないディスクがあるとすべてのディスクがNetworkモードで処理されるようになっています。これはVDDKの制限です。
レプリケーション先にはどの程度のディスクスペースがあれば良いですか?
仮想マシンのディスクタイプにはシンプロビジョニングとシックプロビジョニングがありますが、
それぞれに必要なディスクスペースに違いがあります。
これはシンとシックではストレージ領域の確保方法に違いがあるためです。
シンプロビジョニングで作成した仮想マシンの場合は
ストレージ領域が必要になるごとに領域を確保するため、
レプリケーション元の仮想マシンで使用済みのディスクサイズ分の
フリースペースがレプリケーション先に必要です。
シックプロビジョニングで作成した仮想マシンの場合は
仮想マシン作成時に指定したサイズ分の領域を確保するため、
レプリケーション元の仮想マシン全体のディスクサイズ分の
フリースペースがレプリケーション先に必要です。
VMware と Hyper-V の両方で、Veeam Backup & Replication の同等の機能を使用できますか?
VMwareとHyper-Vではアーキテクチャが異なるため、完全に同等とまではいきませんが、ほぼ全ての機能を1つの統合されたコンソールから利用可能です。
“Commit Failback” と “Undo Failback” の処理の違いを詳しく知りたい。
■Commit Failback
レプリケーション先の VM をレプリケーションジョブを実行できる状態(“Failover” を実行する前の状態)にします。
■Undo Failback
レプリケーション先の VM を “Failback” を実行する前の状態(“Failover” を実行している状態)に戻します。
どちらもレプリケーション先の VM の状態を変更する機能です。
そのため、”Undo Failback” を実行した場合でも、
レプリケーション元の VM は変更が反映された状態(“Failback” 実行後の状態)のままになります。
Veeam Server 自身のレプリカを作成して、本番機が破損したときにレプリカの Veeam Server でジョブの実行などを継続できますか?
可能です。
当然ながら、各ジョブのリストアポイントはレプリケーションジョブを実行したタイミング(レプリカへ本番機のデータをコピーしたタイミング)のものになりますが、レプリカのほうからバックアップ、レプリケーション、フェイルオーバーなどが実行できます。
ただし、本番機への切り戻しは行えませんので、以降はレプリカを本番機として使用する必要がございます。
ジョブ実行時にCBT(Change Block Tracking)が有効になっているか確認する方法はありますか?
Veeamのコンソール画面からジョブを右クリックして “Statistics” を開きます。
“Action” ログの中に “Changed block tracking is ~” と書かれており、有効化されていれば “enabled”、無効化されていれば “disabled” となります。
ジョブ実行前からゲストOSにスナップショットが存在するなどの理由で、CBTが有効にできなかった場合、ジョブ終了後にワーニングとして表示されます。
既存のレプリカVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションが行えますか?
オリジナルの仮想マシンとレプリカの仮想マシンをマッピングすることで、
差分レプリケーションからジョブを開始することができます。
参考: レプリカシーディング・レプリカマッピング機能について
関連トピック
レプリケーションしたいVMのクローンVMを利用して初回のフルレプリケーションを行わず、差分レプリケーションを行えますか?
Veeamでバックアップを行ったとき、どの時点の状態でバックアップファイルが作成されますか?
ジョブ実行後、スナップショットが作成され、それを元にバックアップを取得します。
そのため、スナップショットを作成した時点の状態でバックアップファイルは作成されます。
Veeamでバックアップする際に、バックアップ対象の仮想マシンのデータは直接リポジトリ(バックアップ保存先)へ転送・保存されますか?
Veeamではプロキシサーバ(デフォルトではVeeamをインストールしたサーバ)で重複排除や圧縮を行ったあと、リポジトリ(バックアップ保存先)に転送して保存されます。そのため、直接ではなくプロキシサーバを経由することになります。
独自のスクリプトで静止点を取得している場合、どこで終了を確認していますか?
スクリプト終了時に返される終了コードでスクリプトの成功、失敗を判断しています。
終了コードが0以外の場合は静止点の作成に失敗したものとして、スナップショットの取得に失敗します。
バックアップファイルの圧縮を無効にできますか?
可能です。
Veeamでは圧縮率に関するオプションが用意されており、
バックアップジョブごとに設定が可能となっております。
対象のジョブを右クリック > Edit > Storage > Advanced > Storage
“Failover” と “Undo Failover” の動きの違いを教えてほしい。
■Failover
ターゲットホストのレプリカVMを起動する機能です。
オリジナルのVMに障害が発生した場合に、レプリカ VM で処理を引き継ぎます。
■Undo Failover
Failover機能により電源ON状態となったレプリカVMを電源OFF状態に戻す機能です。
レプリカVMへ行われた変更は破棄されます。
リストア時の処理方法について教えてください。
Veeamには3つの処理モードが用意されております。
・ダイレクトストレージアクセスモード
・バーチャルアプライアンスモード
・ネットワークモード
参考
バックアップ、レプリケーション時の処理モードX 3
VMware環境での3つの転送モード方式と処理の流れ
処理モードの中では一番の高速バックアップ【Veeam Backup & Replication:Direct SANモード】
手間とコストをかけずに簡単に高速バックアップ【Veeam Backup & Replication:Virtual Applianceモード】
特別な条件の必要ない簡単・確実なバックアップ【Veeam Backup & Replication:Networkモード】
バックアップ時、リストア時にどの条件を満たしているかによって処理モードが変更されます。
しかし、リストアの場合は処理モードがVirtual ApplianceモードとNetworkモードのみ使用可能となっております。
関連トピック
VMwareのHot add機能を利用したバックアップは可能か?
SAN内の仮想マシンを別のSANにバックアップする際にモード選択でSANモードで処理可能か?
RDMで構成された仮想マシンのバックアップは行えますか?
Veeamでバックアップを取得するためには仮想マシンのスナップショットが取得できる必要がございます。そのため、スナップショットをサポートしていない物理互換のRDMはバックアップが行えませんが、仮想互換のRDMであればバックアップを取得可能です。
RDMで構成された仮想マシンのリストアはどのように行われますか?
Veeamでは仮想互換のRDMであればバックアップ/リストアが可能です。
仮想マシンのバックアップを取得時にRDM領域はvmdkファイルに変換されます。そのため、リストア時にはRDM領域はvmdkファイルに置き換えられてリストアされます。
インストール時にカタログファイルの保存先を変更したい。
カタログファイルの保存先はWindowsの共有設定が行える必要がございます。そのため、ネットワークドライブなどは指定するとインストール中にエラーとなり、インストールが終了できません。
複数のジョブを同時に実行中、次のメッセージが表示され実行されないジョブがあります。「Waiting for backup infrastructure resources availability」
これは、複数ジョブを実行するためのリソースが不足しているため、処理中のジョブが終了し、リソースが解放されるまで待機状態になっていることを表しています。
そのため、複数のジョブを同時刻に実行したいということであれば、ジョブごとにプロキシサーバ(処理サーバ)を用意していただくか、プロキシサーバのスペックをあげていただく必要がございます。デフォルトではVeeamサーバがプロキシサーバとして動作します。
インスタントVMリカバリ実行中に元の仮想マシンに対してバックアップを行えますか?
Veeamには2つのバックアップモード(増分・差分)があり、増分バックアップであれば実行中にもバックアップ可能ですが、差分バックアップの場合は行えません。
差分バックアップは毎回フルバックアップファイル(vbk)に差分をマージするのでvbkに書き込みを行います。しかし、インスタントVMリカバリではバックアップファイルから直接仮想マシンを作成するため、フルバックアップファイル(vbk)をロックします。そのため、vbkに書き込みが行えずエラーとなります。
増分バックアップでは増分ファイル(vib)の作成は行いますが、vbkに対して書き込みを行わないためバックアップ可能となります。しかし、バックアップファイルの変換オプション(Transform previous full backup chains into rollbacks)を有効にした場合は、増分バックアップは問題ありませんが、フルバックアップ時には増分ファイルを差分ファイルへ変換する処理が入りますので、ファイルがロックされるインスタントVMリカバリ中にフルバックアップは行えません。
vSphereのVMFS領域をバックアップ先として使用できますか?
バックアップ先ストレージとして利用可能なのはWindows、Linux、共有フォルダとなっています。
登録可能なデータ保存先(リポジトリ)
ESXにはLinuxをベースとした管理用OSが搭載されているため、Linuxのバックアップ先ストレージとして利用可能でした。
しかし、ESXi(vSphere5.1)はこの管理用OSを削除しており、直接バックアップ先ストレージとして利用できなくなっております。そのため、vSphere5.1上に仮想マシンを登録し、その仮想マシンをバックアップ先として利用する必要があります。
ジョブの複製はできますか?
Enterprise / Enterprise Plusエディションで可能です。
通常のVeeam Backup & ReplicationコンソールとEnterprise ManagerのWebコンソールから行えます。
しかし、Standardエディションでは対応しておりません。
ジョブのパラレルタスク(複数ディスク同時処理)の数に制限はありますか?
制限はありません。
ジョブを実行するプロキシサーバの性能に依存します。
おおよそ、1タスクに1CPUです。
ネットワークの帯域制限は行えますか?
はい、行えます。
Veeamではプロキシ – プロキシ間、プロキシ – リポジトリ間で帯域制限を行います。
そのため、vSphereホストからバックアップを行う際にネットワーク経由で以下のように処理を行っておりますと、vSphereホスト – プロキシ間では帯域制限は実施されず上限までネットワークを使用します。プロキシ – リポジトリ間では帯域制限が実施されます。
例) vSphereホスト – プロキシ – レポジトリ
Veeam Backup & ReplicationサーバをVMware FT(Fault Tolerance)で構成したい。
VeeamサーバをVMware FT構成にすることは、基本的には問題ありません。
しかし、いくつか注意点がございます。
1.Veeamのコンソールとして使用するのは問題ないですが、プロキシとして使用するのは非推奨となります。もし、Virtual Applianceモードでバックアップを実行していた場合、処理途中で仮想マシンが切り替わるとVirtual Applianceモードが動作しなくなります。
2.バックアップ保存先への接続はNASかCIFSを使用する必要があります。Veeamサーバに直接接続されたディスクを使用すると、切り替わった際に機能しなくなります。
サポートしているテープの種類は何ですか?
テープ・ライブラリ・コンパチブル・リスト(Unofficial)
ADIC Scalar 100
Dell PowerVault 124T
Dell PowerVault 136T
Dell PowerVault TL2000
FalconStor (VTL) [VERIFIED]
Fujitsu Eternus LT40
HP ESL 712e
HP MSL G3 Series 4048
HP MSL G3 Series 8096
HP MSL 6030
HP MSL 6480
HP StorageWorks 1/8 G2 LTO-3 Ultrium 920
HP StorageWorks LTO-4 Ultrium 1840 SCSI
HP StoreOnce (VTL) [MSL series emulation]
IBM TS3100
IBM TS3200
IBM TS3310
IBM TS3500
IBM ProtectTier 7650 (VTL)
IBM ULTRIUM HH5 SCSI
Overland NEO 100s [VERIFIED]
Overland NEO 200s [VERIFIED]
Overland NEO 400s [VERIFIED]
Overland NEO 2000e [VERIFIED]
Overland NEO 4000e [VERIFIED]
Overland NEO 8000e [VERIFIED]
Quantum Scalar i40
Quantum Scalar i80
Quantum Scalar i500
Quantum Scalar i6000
QUADStor (VTL) [IBM TS3100/3580 emulation] [VERIFIED]
Qualstar RLS
Spectra Logic T50e [Quantum P7000 emulation]
Tandberg T24 [VERIFIED]
Tandberg T40+ [VERIFIED]
Tandberg T80+ [VERIFIED]
Tandberg T120+ [VERIFIED]
Tandberg T160+ [VERIFIED]
Tandberg RDX Quikstation (VTL) [T80+ emulation] [VERIFIED]
mhVTL (VTL) [64KB block size] [VERIFIED]
プロキシサーバの設置台数に制限はありますか?
プロキシはVeeamのライセンスに依存せず、台数制限もございません。
バックアップ対象の仮想マシンをStorage vMotionで移動した後、バックアップジョブを作り直す必要がありますか?
バックアップジョブにvCenter経由で仮想マシンを登録していれば、Veeamは仮想マシンに割り振られた参照IDを追跡しますので、ジョブの作り直しは必要ありません。
参考: vMotionやStorage vMotionに対応したジョブの作成
しかし、Storage vMotion実施後は仮想マシンのCBTがリセットされるため、実施後最初のバックアップはフルバックアップになります。
参考: Change Block Tracking is reset after a storage vMotion operation in vSphere 5.x
関連トピック
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
バックアップを取得している仮想マシンのデータストアを、ストレージvMotionで別のデータストアに移動した場合、差分バックアップを継続できますか?
並列処理(Parallel Processing)が利用可能なジョブは何ですか?
Veeamの並列処理が利用可能なジョブは、バックアップジョブとレプリケーションジョブ、バックアップコピージョブとなりますが、WANアクセラレータを使用したバックアップコピージョブは逐次処理になります。
※バックアップコピージョブが並列処理になったのはver9.0以降になります。
ジョブに失敗したときにリトライする設定にしている場合、通知メールは毎回リトライの度に送信されますか?
自動リトライを設定している場合、通知メールはジョブがSuccess/Warningになるか、指定回数分のリトライ処理が終わった時にまとめて送信されます。
警告(warning)と失敗(failure)のときに通知を行い、成功(success)のときは通知しない設定にしている場合、最初のジョブで失敗、リトライジョブで成功したらメール通知はされますか?
通知されません。
通知メールはリトライも含めた最終的なジョブ結果に基づいて送信されますので、リトライの結果、ジョブがSuccessになれば通知されません。
既にバックアップを実施している仮想マシンの名前を変更しても処理に影響はありませんか?
影響ありません。
問題なくバックアップ、リストア、レプリケーション等を行えます。
Windows Server 2012のファイルシステムReFSとNTFSはファイルレベルリストアでサポートしていますか?
サポートしています。
但し、VeeamサーバをWindows Server 2012以降で構築する必要があります。
管理できる世代数はどのくらいですか?
ジョブごとにバックアップで1~999世代、レプリケーションで1~28世代取得可能です。
HTMLレポートの”Data read”、”Dedupe”、”Compression”から”Backup size”を計算してみたが、誤差があるのはなぜか?
重複排除率や圧縮率は細かい値が丸められているため、計算した場合多少の誤差が発生します。
バックアップ/レプリケーションの対象となっているゲストOSのディスクサイズを拡張したらどうなりますか?
【バックアップ】
ディスクサイズが変更されたことによりCBTがリセットされます。
そのため、変更後最初の一回は全データを読み込むことになります。
二回目以降は差分でのバックアップが可能です。
【レプリケーション】
既存のリストアポイントがすべて削除され、
新たなリストアポイントが作成されます。
レプリケーションやリストアで作成したHyper-V仮想マシンのMACアドレスが、動的から静的に変更されます。
MACアドレスが動的から静的に変更されるのは、Veeam B&Rの仕様になります。
ソースマシンのMACアドレスを保持するために静的に変更しています。
Veeamが使用するSMBのバージョンは何ですか?
Veeam自身はSMBに関する機能は持っておらず、インストールされているWindowsのSMB機能を利用します。
そのため、使用するSMBのバージョンはVeeamがインストールされているWindowsのバージョンおよびデータ転送先のデバイスの対応状況に依存します。
レプリケーション途中でネットワーク接続が切断されたとき、どのような挙動となりますか。
バージョン7.0のパッチ2(R2)より、レプリケーション中に、ソースとターゲットのサイト間のネットワーク接続が切断されたとき、ソースとターゲットのプロキシサーバの再接続を試行し、レプリケーションを途中から再開する機能が追加されています。
デフォルトでは切断から5分の間、10秒ごとに接続のリトライを行います。
この時間を過ぎますと、エラーとなります。
Backup Job作成時のオプション “Retention policy” で設定した数以上のリストアポイントが作成されてしまいます。
Backup Job作成時に「Backup Mode」がIncrementalモードで、「Synthetic full」が有効になっている場合、設定した世代数をキープするため、設定したリストアポイント数より多くのリストアポイントが作成されます。
※バージョンによっては”Restore points to keep on disk”と表記されております。
参考:
増分・差分による保持するバックアップファイルの違い
世代を管理するバックアップチェーン
バックアップモードによる保持するバックアップファイルの違い【Veeam Backup & Replication】
8時間毎にバックアップを行うよう、スケジュールを設定できますか?
はい、設定可能です。スケジュール設定画面にてPeriodically every(定期的)の時間を設定すると、指定時間毎に動作します。
参考
Job作成時のスケジュール(除外設定機能)について【VMWare専用 バックアップ & レプリケーションソフト Veeam】
複数の仮想マシンをまとめてバックアップは可能ですか?
はい、可能です。下記の単位でのバックアップが可能です。
・クラスタ
・フォルダ
・リソースプール
・Virual App
・ホスト
・ユーザーが選択した仮想マシン
テープへ直接バックアップできますか?
Veeamはテープへの2次バックアップをサポートしております。
一度ディスク上にバックアップしていただき、そのバックアップファイルをテープへ2次バックアップします。
レプリケーションで作成された仮想マシンは障害時に自動で起動させることはできますか?
自動で起動させる機能はありません。VeeamコンソールもしくはvSphere (Web) Clientから手動でのフェイルオーバーが必要です。
Jobの終了時にバックアップ先のディスクの空き容量が不足していると警告が表示されます。
Veeam Backup & Replicationではバックアップ先のディスクの空き容量が設定した容量より少なくなった際に警告を表示します。
デフォルト設定では、空き容量が10%以下になった場合、警告を表示します。
また、バックアップ先のディスクの空き容量が設定したしきい値よりも下回った場合、VMのスナップショット取得の処理を行わずにジョブを終了させる設定もございます。
※デフォルト設定では、しきい値は5%となっております。
この設定はVeeamの管理コンソールから「Options」>「Notifications」タブで設定可能です。
特定のジョブ終了後に次のジョブを起動させることは可能か?
可能です。スケジュール設定時に “After this job” を選択してください。
指定したジョブ終了後に作成したジョブを実行します。
レプリケーション処理の2回目以降は差分処理を行いたいが、Job作成時に設定する必要はありますか?
Job作成時のデフォルト設定のままで2回目以降が差分処理になります。
レプリケーションのJobスケジュール設定で、”Continuously” とあるが、これはどのような機能ですか?
これはJobを常に実行し続けます。Jobが終了するとすぐにJobを開始するという機能です。
仮想マシンのバックアップまたはレプリケーションをできる限り最新の情報を取得したい場合に使用するモードですが、常に動作しますので、リソースや容量に注意が必要です。
レプリケーション時にvSphere(A)にのみ存在するネットワークラベルをもつ仮想マシンをvSphere(B)にレプリケーションした場合、仮想マシンにはvSphere(B)に存在するネットワークラベルが自動で設定されますか?
Replication Job設定時にレプリカVMのネットワーク設定を行うことができます。
Job実行時の暗号化方式はどのように行っていますか?
SSLで暗号化しています。
平日の指定した時間にバックアップするようにスケジュールを設定できますか?
はい、設定可能です。スケジュール設定画面にて Daily at this time を on week-days と設定すると、平日のみ動作します。
また、on these days にて任意の曜日を選択することも可能です。
バックアップ処理を起動しない時間の指定(除外時間設定)は可能ですか?
はい、設定可能です。スケジュール設定画面にてPeriodically every(定期的)の設定で除外時間設定ができます。
アプリケーション実行中にバックアップは可能ですか?
はい、バックアップ可能です。
但し、アプリケーション側で制約がある場合、リストアした際、不具合が発生する可能性があります。
処理終了後に、バッチ処理を行うことは可能ですか?
はい、バックアップ、レプリケーション時は処理終了後、コマンド実行することができ、別の処理を行うことが可能です。
2TBを超える仮想マシンのバックアップは可能でしょうか?
はい、可能です。ディスクの作り方によって2TBを超える仮想マシンのバックアップ、レプリケーションを行うことができます。
詳しくはブログへ記載してあります。 ≫
レプリケーション後のレプリカVMの起動をvSphere Clientから行いたい。
はい、可能です。
任意の時点のスナップショットに戻してからレプリカVMを起動してください。
しかし、vSphere clientから起動することでVeeamから管理を行うことができなくなり、Failback(オリジナルへの切り戻し)が行えなくなります。プライマリサイト復旧後は、新規にレプリケーションジョブを作成してDRサイト⇒プライマリサイトの方向にレプリケーションを行う必要があります。レプリカVMを停止することでまたVeeamから管理することが可能になりますが、レプリカVMに対して行われた変更は反映されません。
バックアップとレプリケーションを同時に実行することは可能か?
はい、可能です。但し、同じ仮想マシンに対して同時に複数の処理を行うことはできません。
また、レプリケーションジョブ実行中に処理中のレプリカVM起動(Failover to Replica)やSureBackupで実行中のバックアップジョブを指定して実行するようなこともできません。
レプリケーション機能で作成した仮想マシンのIPアドレスは複製元と同じになりますか?
ソースVMが静的IPアドレスで設定されている場合、同じIPアドレスで複製のVMが作成されます。
レプリケーションジョブのオプション機能で、ジョブ作成時に複製VMのIPアドレスを指定することも可能です。
バックアップ時にできる差分ファイル(vib, vrb)のサイズはどうやって決まるか?
仮想マシンのサイズや変更分に影響し、指定したリストアポイント数分差分ファイルを作成します。
起動中のバックアップJobをユーザー側で停止後にJobを再開させることは可能ですか?
可能です。
例)起動中のJob(A)をユーザーが停止後にJob(A)を再開した場合にはJob(A)が正常終了して作成しているバックアップファイルからの変更部分(増分、差分)のバックアップファイルを作成します。
関連トピック
プロキシサーバの台数を増やせば処理速度は向上しますか?
Veeamは仮想ディスク単位で並列処理が可能なため、プロキシサーバを増設したり、プロキシサーバの性能を上げることで、同時に処理するVM数を増やすことが可能になるので、処理速度の向上が望めます。
仮想マシンのスナップショットまでリストアできますか?
スナップショットはリストアできません。
バックアップ・レプリケーションではスナップショットの構成や情報を保持しているわけではないため、スナップショットの情報は保持されません。
バックアップ対象の仮想マシンをStorage vMotionで移動する際にスナップショットエラーは発生しますか?
VMwareのStorage vMotionを実行する条件の1つに「仮想マシンがスナップショットを保持していないこと」があります。
Veeam Backup & Replicationではバックアップ時に処理対象の仮想マシン内にスナップショットを取得しますが、処理の最後にスナップショットを削除します。
※Veeamの処理中(仮想マシンにスナップショットが残っている時)にStorage vMotionが実行された場合にはStorage vMotionは失敗します。
Job作成時にCBT機能を無効にした場合には処理にどのよう影響がありますか?
CBT機能を無効にした場合、前回のバックアップからの変更箇所を追跡できないため、毎回VMの全データを読み取る必要があります。
Historyはどの位保持されますか?
デフォルトでは53週間(1年間)保持します。コンソールから変更可能です。
Backup Jobのオプション “Remove deleted items data after” はどのような機能ですか?
仮想環境から削除された仮想マシンを、バックアップデータ内で保持する期間の設定です。
VM削除時のバックアップファイル自動削除機能
※バージョンによっては、”Deleted VMs data retention period”と表記されております。
通信時に使用するポート番号は?
開発元ドキュメントをご参照ください。
インストール時に指定したVBRCatalogのパスを変更する方法はありますか?
ございます。弊社ブログをご参照ください。
参考:
VBRCatalogフォルダの変更方法【Veeam KB】
How to Move the VBRCatalog Folder
Job作成時の “Advanced Settings” ボタンの “vSphere” タブの “Enable VMware Tools quiescence” にチェックを入れることでどのような動作をしますか?
「Enable VMware Tools quiescence」を有効にするとVMware Toolsの静止点作成機能を使用します。アプリケーションレベルでの静止点作成には向いていませんがVMware Toolsの静止点作成機能では静止点作成時に仮想マシン内にユーザが配置したbatファイルを実行可能です。
■参考ブログ
Windows OSのオンラインバックアップ手順【Veeam Backup & Replication】
※方法②カスタムスクリプトを利用したオンラインバックアップをご参照下さい。
Job作成時のオプション “Enable application-aware image processing” はどんな機能ですか?
オプション「Enable application-aware image processing」を有効にしてJobを実行するとVeeam独自にカスタマイズした方式でMicrosoftのVSSを利用してアプリケーションレベルでの静止点作成処理を行います。
しかし、Linuxや下記WindowsはMicrosft VSSをサポートしていません。
・Windows 95 ・Windows 98 ・Windows NT
そのため、静止点を取得する際にはカスタムスクリプトを使用していただく必要があります。
■技術ブログ
Windows OSのオンラインバックアップ手順【VMWare専用 バックアップ & レプリケーションソフト Veeam】
batと連携しての仮想マシンのバックアップ手順(MySQLの起動・停止)
オンラインダンプを使った仮想マシンのバックアップ方法【Veeam Backup & Replication】
関連トピック
Job作成時のオプション “Enable guest file system indexing” はどんな機能ですか?
Veeam静止点処理において必要な認証情報をVM個別に指定する方法はありますか?
Job作成時のオプション “Enable guest file system indexing” はどんな機能ですか?
「Enable guest file system indexing」を有効にした場合、Veeam Enterprise ManagerでWebブラウザからファイルレベルリストアが可能です(Enterpriseエディション機能)。
■技術ブログ
Backup Searchの紹介【VMWare専用 バックアップ & レプリケーションソフト Veeam】
特定の日付や月末にVeeamのJobを実行するようにスケジュールを設定したい。
VeeamのJobを実行するスクリプトをWinodws Serverの「タスク スケジューラー 」から実行することを特定の日付や月末のタイミングにVeeamのJobを起動可能です。
■タスク スケジューラー画面
同一ホストに対して同時に実行できるバックアップジョブの上限はありますか?
上限はありません。
プロキシサーバーを複数台設置した場合、ジョブの情報などはプロキシサーバー間で同期されるのでしょうか?
ジョブの管理は管理サーバーで行われるため、プロキシ間でジョブの情報等は同期されません。
ホストやジョブ数、バックアップ対象とする仮想マシン等、各種登録データについて上限値はあるのでしょうか?
上限値はありません。
しかし、ホストはライセンスの CPU 数に依存します。
Backup Mode を途中で変更した場合どうなりますか?
増分バックアップから差分バックアップに、差分バックアップから増分バックアップにモードを変更するかによって、バックアップファイルの保持のされ方が異なります。
弊社ブログをご参照ください。
参考: ジョブ設定変更後のバックアップファイルの変化
一定間隔でのスケジュール設定を行った際に、次回のジョブはどのように時間を決めていますか?
ジョブ設定時を基準とし、一定間隔後、リソース収集を行った後に1回目のジョブが開始します。2回目のジョブは1回目のジョブ開始時から一定間隔後リソース収集を行った後に開始されます。
SNMPで使用する管理情報ベース(MIB)はありますか?
はい、ございます。下記フォルダにあるVeeamBackup.mibをご利用ください。
—–
C:\Program Files\Veeam\Backup and Replication\Backup
—–
バックアップを取得した仮想マシンを削除して、バックアップ元と全く同じ設定でリストアしました。ジョブを継続して使用可能ですか?
いいえ、使用できません。
既存のジョブにバックアップ対象の仮想マシンを追加しなおすか、
新規にジョブを作成する必要があります。
VMware HA, VMware FT構成でもバックアップ可能ですか?
VMware HA構成のバックアップは可能です。
バックアップにはスナップショットが必要なため、スナップショットが利用できないVMware FT構成の場合、バックアップは行えません。
しかし、vSphere 6.0からはVMware FT構成のVMもスナップショットが利用できるようになったため、バックアップを取得可能になりました。
EspressChart (3)
作成したチャートのY軸に小数点以下が表示されない。
Chart Designerから以下の設定をご確認ください。
1)チャートファイルをChart Designerで開き、
「Format value elements」を開きます。
2)Y axisタブのFormatを開きます。
3)「Maximum fraction digits」に「1」以上の値を入れます。
ここで表示する小数点以下の桁数を指定します。
「3」とした場合、最大3桁まで表示します。
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
EspressChartでのバージョン確認方法
EspressChartのバージョン、リビジョン番号の確認方法について:
APIコードに以下の行を追加してください。
System.out.println(QbChart.getVersion());
AS/400でのX-Serverを購入後の EspressChart のセットアップ方法:
[質問]
カード購入後、セットアップが必要となると思いますが、 PCサーバカードをAS/400に組み込んだ後どうすればよいのでしょうか?
AS/400上の設定は行ったとしてそれだけでよいのでしょうか?
PCサーバ上にWebsphereを入れて、その上にEspressChartを入れて、とかという作業が 必要になりませんか?
[回答]
IBM AIX機械については、X-Server起動後
(WebSphere起動後かもしれません)
管理者としてログインしてください。
その後
export DISPLAY=IP_address:0.0
のコマンドを打ってください。
ディスプレイ環境変数の設定が必要になります。
チャートビューアでSQL文書を可変に
[質問]
> 現在、弊社にてEspressChartApiを利用して2次元のコンビネーショングラフを
表示させております。
> しかし、メンテナンスを考えるとチャートビューアを利用したく考えております。
> 弊社で、チャートビューアを使用したテストが正常に作動しました。
>
> このchtファイルにはデータ取得用のSQLがかかれておりますが、このSQLを可変にするこ
> とはできるのでしょうか?
> また、その場合にはどのようにすればよいのでしょうか?
—————————————————————-
[回答]
を以下のように変更願います
chtファイルは図表データを含んでいます。
しかし、tplはデータを含んでおらず、それがhtmlページに開かれるごとに、
データ・ベースから新しいデータを検索します。
espresschart¥ヘルプ¥マニュアル¥Chp_5.htmlでは、
それがさらにクエリーをそれ自身変更するためにコードを持っています。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
Y軸を無視してただの文字項目として扱うことは可能ですか?
To make just the y-axis disappear while keeping the axis labels:
QbChart chart = new QbChart(…..);
chart.gethYAxis().setVisible(false);
開発環境と運用環境で文字(フォント)が変わってしまう場合どうすればいいですか?
グラフで使用しているフォントが両環境で使用できない場合、自動的にデフォルトのフォントが使用されます。
そのため両環境で共通のフォントを使用してください。
また環境によってDPIの設定が異なる場合、一部設定が反映されない場合があります。
その場合は両環境でDPIをあわせる、もしくはAPIからグラフを出力する際に以下のメソッドを実行しDPIをあわせる必要があります。(DPI_value:設定するDPIの値)
QbUtil.setPixelPerInchForExport(int DPI_value);
APIでTPLファイルからチャート作成時に”警告: Failed to load chart data, using backup data.”が表示される。
これはデザイナーで指定した場所にデータソースがない場合に警告が出力されることがあります。
この警告を出力しないようにするためには以下の3つの方法がございます。
①デザイナーで保存する際にCHTファイルを使用する。
②APIでからデータソースの場所を上書きした形で再度TPLファイルをエクスポートする。
③ダミーとなるデータをデザイナー指定の場所と同一の場所に作成する。
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
使用できるフォントを教えてください。
一般的なJavaアプリケーション同様に、オペレーティングシステムに登録されたフォントを使用することができます。
Y軸の最大値又は最小値を超える値が存在する場合にエラーが出ます。
EspressChartの使用となります。Y軸の最大値・最小値を超えないように調整をお願いいたします。
バッチファイル「Patch6.jar」を適用することでエラーの回避は可能ですが、非推奨です。
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが2CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
「java.lang.OutOfMemoryError: Java heap space」エラーが出ます。
-Xmxオプションの追加でJVMの最大ヒープサイズを変更し、改善されるかどうかご確認ください。DBから取得するレコードが大量な場合や、Y軸X軸の表示目盛間隔が小さすぎて大量表示している場合に発生したケースがあります。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
チャートをどのような形式で出力できますか?
EspressChart専用のチャート形式(CHT)、テンプレート形式(TPL)
一般的な画像形式(BMP・GIF・JPG・PNG)、PDF形式
チャートからデータのみを出力するテキスト形式、XML形式
その他SVG、SWF、WMF形式で出力可能です。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのようなチャートの種類がありますか?
2D形式が20種類、3D形式が14種類の計34種類あります。また、5種類200パターンを超えるゲージチャートにも対応してます。
詳細はチャートギャラリーのページをご参照ください。
チャートに対してクリックイベントを設定することは可能ですか?
はい、可能です。
クリックイベントによって、ハイパーリンク(URLにアクセス)を設定したり、ドリルダウン(関連する別のチャートへリンク)を設定することができます。
チャートのアニメーション表示は可能ですか?
はい、可能です。
SWFまたはSVG形式で出力する際、チャートにアニメーション効果を付けることができます。棒グラフの棒や折れ線グラフの線をフェードインで表示することができます。
2つのチャートを上下に並べて表示できますか?
はい、可能です。
折れ線グラフと棒グラフなど、X軸を共有する2つのチャートを上下に並べて表示できます。
折れ線グラフと棒グラフなど複数のチャート種を1つのチャートに表示できますか?
はい、可能です。
1つのチャートに折れ線グラフ、棒グラフ、エリアグラフなど、複数のチャート種を同時に表示できます。ただし、円グラフなど表示形式の異なる一部のチャート種は同時に表示できません。
日付や通貨などの形式を変更することは可能ですか?
はい、可能です。各国独自のフォーマットをサポートしております。
チャートとは別にレポート(表)を入れることは可能ですか?
簡易的なものであれば可能です。詳細なカスタマイズをご希望の場合は、EspressReportをご検討ください。
チャートにオリジナルのタイトルやテキストを挿入することは可能ですか?
はい、可能です。
グラフ領域の任意の位置に装飾付きテキストを配置できる「フリーラベル機能」を使用可能です。
保存形式で「cht」と「tpl」の違いが分かりません。
chtは実際のデータを含めたチャート形式ファイルです。(サイズ大きめ)
tplは実際のデータが含まれないチャート形式です。(サイズ小さめ)
画像に出力する際、圧縮率の指定は可能ですか?
JPEG/PNG形式の場合は可能です。
Y軸を左側に複数配置させることは可能ですか?
チャートの種類が「オーバーレイ」の場合のみ可能です。
対数表示には対応しておりますか?
対応しております。
Y軸の最大値・最小値・表示間隔はどのような基準で決められるのでしょうか?
「自動」と「手動」の2種類の設定があります。
「自動」の場合はグラフ表示範囲内の実データの最大値・最小値から適切なY軸の最大値・最小値・表示間隔が自動設定されます。
「手動」の場合は実データに関係なく意図的にY軸の最大値・最小値・表示間隔を任意設定可能です。
ただし手動の場合にはY軸の最大値・最小値を実データが超過する場合にエラーが発生しますので、超過しないように調整が必要です。
チャートの色やプロットの形を指定することは可能ですか?
はい、可能です。
チャートデザイナ → 保存形式「cht」で保存することで指定できます。
チャートAPI → setPointShapes()やsetColors()を使用することで指定できます。
詳細はこちら
EspressChart -導入・製品 (10)
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
EspressChart -機能 (22)
EspressChartでのバージョン確認方法
EspressChartのバージョン、リビジョン番号の確認方法について:
APIコードに以下の行を追加してください。
System.out.println(QbChart.getVersion());
AS/400でのX-Serverを購入後の EspressChart のセットアップ方法:
[質問]
カード購入後、セットアップが必要となると思いますが、 PCサーバカードをAS/400に組み込んだ後どうすればよいのでしょうか?
AS/400上の設定は行ったとしてそれだけでよいのでしょうか?
PCサーバ上にWebsphereを入れて、その上にEspressChartを入れて、とかという作業が 必要になりませんか?
[回答]
IBM AIX機械については、X-Server起動後
(WebSphere起動後かもしれません)
管理者としてログインしてください。
その後
export DISPLAY=IP_address:0.0
のコマンドを打ってください。
ディスプレイ環境変数の設定が必要になります。
チャートビューアでSQL文書を可変に
[質問]
> 現在、弊社にてEspressChartApiを利用して2次元のコンビネーショングラフを
表示させております。
> しかし、メンテナンスを考えるとチャートビューアを利用したく考えております。
> 弊社で、チャートビューアを使用したテストが正常に作動しました。
>
> このchtファイルにはデータ取得用のSQLがかかれておりますが、このSQLを可変にするこ
> とはできるのでしょうか?
> また、その場合にはどのようにすればよいのでしょうか?
—————————————————————-
[回答]
を以下のように変更願います
chtファイルは図表データを含んでいます。
しかし、tplはデータを含んでおらず、それがhtmlページに開かれるごとに、
データ・ベースから新しいデータを検索します。
espresschart¥ヘルプ¥マニュアル¥Chp_5.htmlでは、
それがさらにクエリーをそれ自身変更するためにコードを持っています。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
使用できるフォントを教えてください。
一般的なJavaアプリケーション同様に、オペレーティングシステムに登録されたフォントを使用することができます。
チャートをどのような形式で出力できますか?
EspressChart専用のチャート形式(CHT)、テンプレート形式(TPL)
一般的な画像形式(BMP・GIF・JPG・PNG)、PDF形式
チャートからデータのみを出力するテキスト形式、XML形式
その他SVG、SWF、WMF形式で出力可能です。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのようなチャートの種類がありますか?
2D形式が20種類、3D形式が14種類の計34種類あります。また、5種類200パターンを超えるゲージチャートにも対応してます。
詳細はチャートギャラリーのページをご参照ください。
チャートに対してクリックイベントを設定することは可能ですか?
はい、可能です。
クリックイベントによって、ハイパーリンク(URLにアクセス)を設定したり、ドリルダウン(関連する別のチャートへリンク)を設定することができます。
チャートのアニメーション表示は可能ですか?
はい、可能です。
SWFまたはSVG形式で出力する際、チャートにアニメーション効果を付けることができます。棒グラフの棒や折れ線グラフの線をフェードインで表示することができます。
2つのチャートを上下に並べて表示できますか?
はい、可能です。
折れ線グラフと棒グラフなど、X軸を共有する2つのチャートを上下に並べて表示できます。
折れ線グラフと棒グラフなど複数のチャート種を1つのチャートに表示できますか?
はい、可能です。
1つのチャートに折れ線グラフ、棒グラフ、エリアグラフなど、複数のチャート種を同時に表示できます。ただし、円グラフなど表示形式の異なる一部のチャート種は同時に表示できません。
日付や通貨などの形式を変更することは可能ですか?
はい、可能です。各国独自のフォーマットをサポートしております。
チャートとは別にレポート(表)を入れることは可能ですか?
簡易的なものであれば可能です。詳細なカスタマイズをご希望の場合は、EspressReportをご検討ください。
チャートにオリジナルのタイトルやテキストを挿入することは可能ですか?
はい、可能です。
グラフ領域の任意の位置に装飾付きテキストを配置できる「フリーラベル機能」を使用可能です。
保存形式で「cht」と「tpl」の違いが分かりません。
chtは実際のデータを含めたチャート形式ファイルです。(サイズ大きめ)
tplは実際のデータが含まれないチャート形式です。(サイズ小さめ)
画像に出力する際、圧縮率の指定は可能ですか?
JPEG/PNG形式の場合は可能です。
Y軸を左側に複数配置させることは可能ですか?
チャートの種類が「オーバーレイ」の場合のみ可能です。
対数表示には対応しておりますか?
対応しております。
Y軸の最大値・最小値・表示間隔はどのような基準で決められるのでしょうか?
「自動」と「手動」の2種類の設定があります。
「自動」の場合はグラフ表示範囲内の実データの最大値・最小値から適切なY軸の最大値・最小値・表示間隔が自動設定されます。
「手動」の場合は実データに関係なく意図的にY軸の最大値・最小値・表示間隔を任意設定可能です。
ただし手動の場合にはY軸の最大値・最小値を実データが超過する場合にエラーが発生しますので、超過しないように調整が必要です。
チャートの色やプロットの形を指定することは可能ですか?
はい、可能です。
チャートデザイナ → 保存形式「cht」で保存することで指定できます。
チャートAPI → setPointShapes()やsetColors()を使用することで指定できます。
詳細はこちら
EspressChart -トラブル (6)
作成したチャートのY軸に小数点以下が表示されない。
Chart Designerから以下の設定をご確認ください。
1)チャートファイルをChart Designerで開き、
「Format value elements」を開きます。
2)Y axisタブのFormatを開きます。
3)「Maximum fraction digits」に「1」以上の値を入れます。
ここで表示する小数点以下の桁数を指定します。
「3」とした場合、最大3桁まで表示します。
開発環境と運用環境で文字(フォント)が変わってしまう場合どうすればいいですか?
グラフで使用しているフォントが両環境で使用できない場合、自動的にデフォルトのフォントが使用されます。
そのため両環境で共通のフォントを使用してください。
また環境によってDPIの設定が異なる場合、一部設定が反映されない場合があります。
その場合は両環境でDPIをあわせる、もしくはAPIからグラフを出力する際に以下のメソッドを実行しDPIをあわせる必要があります。(DPI_value:設定するDPIの値)
QbUtil.setPixelPerInchForExport(int DPI_value);
APIでTPLファイルからチャート作成時に”警告: Failed to load chart data, using backup data.”が表示される。
これはデザイナーで指定した場所にデータソースがない場合に警告が出力されることがあります。
この警告を出力しないようにするためには以下の3つの方法がございます。
①デザイナーで保存する際にCHTファイルを使用する。
②APIでからデータソースの場所を上書きした形で再度TPLファイルをエクスポートする。
③ダミーとなるデータをデザイナー指定の場所と同一の場所に作成する。
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
Y軸の最大値又は最小値を超える値が存在する場合にエラーが出ます。
EspressChartの使用となります。Y軸の最大値・最小値を超えないように調整をお願いいたします。
バッチファイル「Patch6.jar」を適用することでエラーの回避は可能ですが、非推奨です。
「java.lang.OutOfMemoryError: Java heap space」エラーが出ます。
-Xmxオプションの追加でJVMの最大ヒープサイズを変更し、改善されるかどうかご確認ください。DBから取得するレコードが大量な場合や、Y軸X軸の表示目盛間隔が小さすぎて大量表示している場合に発生したケースがあります。
EspressChart -ライセンス (4)
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが2CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
EspressChart -評価 (6)
Y軸を無視してただの文字項目として扱うことは可能ですか?
To make just the y-axis disappear while keeping the axis labels:
QbChart chart = new QbChart(…..);
chart.gethYAxis().setVisible(false);
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
EspressChart -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressReport -導入・製品 (10)
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ReportのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
EspressReport -機能 (11)
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
Excelへの出力時に結合されたセルではなく1つのセルに出力する方法はありますか?
Excelへの出力時に「Fit numeric values into a single cell」にチェックを入れることで結合されず1つのセルへ出力されます。
API から使用する場合は下記を指定してください。
QbReport.setExcelExportFitCell(true);
使用できるフォントを教えてください。
一般的なJavaアプリケーション同様に、オペレーティングシステムに登録されたフォントを使用することができます。
データが多い時にレポート出力のパフォーマンスを向上させる方法はありますか?
以下の方法でパフォーマンスの向上が見込めます。
http://data.quadbase.com/Docs/eres/help/manual/ERESChartAPI.html
メモリ上に保持されるレコードの数と一時ディレクトリを指定し、メモリ内に保持する指定されたレコードの数を超えると、データを指定した一時ディレクトリに保存します。
QbReport.setTempDirectory
(
QbReport.setMaxFieldSize(int fieldSize);
QbReport.setPagingThreshold(int pagingThreshold);
QbReport.setPageBufferSize(int bufferSize);
QbReport.setTotalPageBufferSize(int totalBufferSize);
レポートをどのような形式で出力できますか?
HTML、DHTML、PDF、CSV、ExcelおよびXMLフォーマットに
出力可能です。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのようなレポートの種類がありますか?
シンプルな段組によるレポート、概要説明レポート、クロスタブ レポート、総合及び詳細レポート、メール・ラベルのレイアウトとなります。
レポートに対してクリックイベントを設定することは可能ですか?
はい、可能です。
クリックイベントによって、ハイパーリンク(URLにアクセス)の設定やドリルダウン(関連する別のレポートやチャートへリンク)を設定できます。
レポートとは別にチャートを入れることは可能ですか?
はい、可能です。EspressReportにはEspressChartの全機能が包括されております。別途EspressChartをご購入いただく必要はありません。
レポート形式のファイル「rpt」とチャート形式「tpl」のファイルをまとめて管理したいのですが
保存する際に「PAK」形式で保存することで、レポート形式とチャート形式のファイルを1つにまとめることが可能です。Javaから利用する際もPAK形式を読み込めます。
EspressReport -トラブル (3)
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
web公開時ににレポートもチャートも表示されません。
サーブレットマッピングが必要です。以下のコードを追加してください。
// サーブレットのディレクトリ名
QbReport#setServletDirectory(“ER/”);
// サーバURLとポート
QbReport#setDynamicExport(true, “127.0.0.1”, 8080);
web公開時にレポートは表示されるのにチャートが表示されません。
RPTImageGenerator.classが必要です。
ImageGeneratorディレクトリ内のRPTImageGenerator.classをサーバに配置してください。
EspressReport -ライセンス (4)
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したレポートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
開発と運用に必要なライセンスを教えてください。
初回にご購入する基本パック(サーバライセンス、開発キット)で開発と運用が可能です。
その他サーバを追加する際には追加サーバライセンス、サーバが1CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したレポートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
EspressReport -評価 (6)
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
・評価するマシン
・JDK 5.0以上
・データソースとして使用するデータ
・開発環境(Eclipseなど)
EspressReport -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
Syniti DR -トラブル (11)
AS/400のレプリケーションで「レプリケーション検証機能」を使用すると文字変換が正しくないとのエラーが出ます。
DBMotoの機能に、レプリケーションのソースとターゲット双方のテーブル間で差異が生じていないかを確認するレプリケーション検証機能があります。
AS/400のテーブルで、VARGRAPHIC型もしくはGRAPHIC型があるテーブルで検証を行うと、「CCSID 65535とCCSID 13488の間の文字変換は正しくない」とのエラーメッセージが出力されることがあります。
このエラーメッセージは通常のレプリケーション中には発生せず、データは問題なくレプリケーションできていることが多いです。
これは、このレプリケーション検証機能使用時に限り、DBMotoの「検証のソート・シーケンステーブル」設定が有効であるため、GRAPHIC型が文字変換を行おうとして失敗しています。
対処法は、この設定個所の部分を空欄にすることです。(設定変更時はData Replicatorの停止が必要です。)
なお、通常のレプリケーションは、前述の通りこの設定を使用していないので、問題なく変換され動作します。
レプリケーション検証機能で正常なレコードがソースのみ、ターゲットのみのレコードとして表示されます。
レプリケーションの検証をすることで、ソースのみのレコード、ターゲットのみのレコード、ソースとターゲットで差異のあるレコードを確認できます。
しかし、本来、ソースにもターゲットにも存在し、差異のないレコードがソースのみ、ターゲットのみに存在するレコードとして表示されることがあります。
これは、DBMotoはソースとターゲットのレコードを比較する前に主キーをベースにレコードのソートを行いますが、このときのソースDBとターゲットDBのソートの仕様の違いによるものです。
例えば、Oracleの場合、大文字、小文字を区別してソートするため、D→aの順番でソートされ、MySQLの場合、大文字、小文字を区別せずソートするため、a→Dの順番でソートされます。
このソートの順番が異なるため、このような結果が生じます。
この事象を回避するため、検証機能のオプション「ORDER BY句」の「ソーステーブル」「ターゲットテーブル」に「LOWER(主キー)」を入力してください。こうすることで、大文字、小文字の区別なくソートが行えるため、問題なく検証することが可能です。
メール設定において、SMTPポート番号465番で指定したが、エラーでメールが送信されない。
こちらはDBMotoで使用している.NET Frameworkの仕様による問題です。
仕様上SMTP over SSLのポート番号である465番を使用したメールの送信ができないようになっております。
別のポート番号をご利用ください。
Transaction Latency StatusにThreshold Warningが出る
この Warning は現在時刻と最後にレプリケーションした際の時刻がしきい値を超えたときに「レプリケーションが遅延しています」と警告を出すものです。
ミラーリング開始後すぐに終了してしまいます。再開してもすぐ終了します。
ミラーリング時にはPKの設定が必要です。DBに設定されているかご確認ください。もしされていない場合は、DBMotoから疑似PKを設定することも可能です。
レプリケーション定義を作成してもステータスがstoppedのままでレプリケーションが動いてくれません。
レプリケーション定義を作成した後に、Data Replicatorを起動する必要があります。
DBMotoインストーラ起動時にライセンスエラーが表示されます。
.NET Framework 2.0 SP2がインストールされていないのが原因です。
WindowsXPやWindowsServer2003・2003R2の場合、デフォルトではインストールされていないので、別途インストールが必要です。また、.NET Framework4.0単独では動作いたしません。
大量トランザクション時、レプリケーションステータスが「Mirroring」で成功数、合計数は0のままで何も動作していないように見える状態がかなり長い時間続いている。
ステータスがMirroringで動いていないように見えるときは、実際にはトランザクションログの参照を行っています。大量トランザクション処理時は時間がかかるケースがあります。
万が一の障害発生時の復旧方法は?
リフレッシュをする方法と、トランザクションIDを任意の位置に戻す方法の2通りあります。
DBMotoの疑似PKを使ってレプリケーションしていますが、キーが重複していても重複キーエラーが発生しません。
疑似PKの重複キーチェックは行われません。重複キーエラーが出るのはDBのPK使用時に重複していた場合のみです。
シンクロナイゼーションでレコードを更新してもレプリケーションされないことがあり、エラーも出力されません。
シンクロナイゼーションではDBMotoでの接続ユーザでレコードの更新をかけた場合にはレプリケーションされず、エラーも出力されません。これは無限ループを回避するための仕様です。シンクロナイゼーションを利用する場合、DBMotoで使用する接続ユーザは他のアプリケーションでは使用しないDBMoto専用のユーザを用意してください。
Syniti Data Workbench (ERP2) (0)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressDashboard (4)
ダッシュボード・レポーティンを成功させるには?
ダッシュボード・レポーティングを成功させるには、4つのステップに従うことが重要です。
1. 明確な目的を持ってダッシュボードを計画し、追跡すべき関連KPIを特定する。
2. データソースを評価するためにデータディスカバリーを実施する。
3. ユーザ・フレンドリーなビジュアル要素でデザインする。
4. ダッシュボードを実装し、その機能をテストする。
注:「データ・ディスカバリ」は、 昨今の目まぐるしく変わる市場環境や、予測困難な外部環境の変化に対応するためには、従来のBIシステムよりも迅速で手軽にデータを分析でき、かつ、ビジネス上の課題を発見できる仕組み。
ダッシュボードとウェブページの違いは何でしょうか?
どちらもコンピュータの画面上で開くことができますが、類似点はそこまでです。
ダッシュボードはデータを素早く処理するためのもので、組織や個人レベルのKPIの概要を簡単に把握できる重要な視覚化ツールです。チャート、グラフ、表、ゲージなどのインタラクティブな視覚的要素の助けを借りて、ダッシュボードは、ユーザーが分析し、情報に基づいたデータ駆動型の意思決定を行うのに役立つように設計されています。
また、ウェブページはウェブブラウザ上に表示される文書であり、重要な情報を提供するテキスト、画像、ビデオ、その他のマルチメディア要素を含んでいます。多くの場合、製品やサービスを宣伝します。他のウェブページへのリンクがある場合もあり、ユーザーはフォームに入力したり、オンラインで購入したり、その他のアクションを行うことでウェブページと相互作用することができます。
ダッシュボードにはいくつまでのビジュアルを載せるべきでしょうか?
視覚的にわかりやすくするために、ダッシュボードに含まれるビジュアルの数は2つか3つに制限しましょう。ビジュアルが多すぎると、ごちゃごちゃした印象になり、解釈が難しくなります。
ダッシュボードUIキットとは何ですか?
ダッシュボードUIキットは、EspressDashboardのようにユーザーインターフェイス要素、テンプレート、コンポーネントの設計済みコレクションです。ダッシュボードの設計と構築のために特別に作成されています。これらのキットは、開発者やデザイナーが視覚的に魅力的で機能的なダッシュボードを迅速かつ簡単に作成するための基盤を提供します。
これらのキットには通常、ダッシュボードのデザインで一般的に使用されるさまざまなチャート、グラフ、テーブル、ボタン、アイコン、およびその他の UI 要素が含まれています。これらのキットは、ダッシュボードの目的に応じて高度にカスタマイズすることができます。これにより、ユーザは特定のデザインプロジェクトの要件に合わせてコンポーネントを変更し、適合させることができます。これらのキットは、デザインプロセスを合理化するために、ウェブやモバイルアプリの開発でよく使用されます。ダッシュボードの全体的なルック&フィールに一貫性を持たせるのに役立ちます。
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
ゲージ: (Gauge)とは
ゲージはプロット・バックグラウンド・イメージとプロット・フォアーグラウンド・イメージの両方、またはどちらかを含むダイアル・チャートの特別なタイプです。
ユーザが簡単にゲージが作成できるように前もって定義済のゲージ・テンプレート用のタブをいくつか準備しています。またテンプレートを作成して、ユーザ独自の作成し、フォルダに保存しておくこともできます。
例:/gauges/templates/Custom/ フォルダ
このテンプレートを[カスタム]タブに追加するには、<ERESインストール> / gauges / screenshots / selected / Customに配置されたテンプレートのスクリーンショットと、<ERESに配置されたテンプレートのディマーバージョン インストール> / gauges / screenshots / unselected / Custom /をクリックします。 スクリーンショットを作成する簡単な方法は、通常のスクリーンショット用にテンプレートをgifに書き出し、100ピクセル×100ピクセルにサイズ変更することです。 その後、背景を暗い色に変更し、調光版のために再度エクスポートしてサイズを変更します。
またダイアル・チャートへゲージ・テンプレートを適応させることも可能です。ダイアル・チャートを使用時に適応させるテンプレートを選択することにより、新しいチャートを作成するようにゲージ・タブを表示することができます。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
Android端末に対応していますか?
はい、モバイル端末としてAndroid, iPad, iPhoneに対応しております。
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが2CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressReport ES (4)
ダッシュボード・レポーティンを成功させるには?
ダッシュボード・レポーティングを成功させるには、4つのステップに従うことが重要です。
1. 明確な目的を持ってダッシュボードを計画し、追跡すべき関連KPIを特定する。
2. データソースを評価するためにデータディスカバリーを実施する。
3. ユーザ・フレンドリーなビジュアル要素でデザインする。
4. ダッシュボードを実装し、その機能をテストする。
注:「データ・ディスカバリ」は、 昨今の目まぐるしく変わる市場環境や、予測困難な外部環境の変化に対応するためには、従来のBIシステムよりも迅速で手軽にデータを分析でき、かつ、ビジネス上の課題を発見できる仕組み。
ダッシュボードとウェブページの違いは何でしょうか?
どちらもコンピュータの画面上で開くことができますが、類似点はそこまでです。
ダッシュボードはデータを素早く処理するためのもので、組織や個人レベルのKPIの概要を簡単に把握できる重要な視覚化ツールです。チャート、グラフ、表、ゲージなどのインタラクティブな視覚的要素の助けを借りて、ダッシュボードは、ユーザーが分析し、情報に基づいたデータ駆動型の意思決定を行うのに役立つように設計されています。
また、ウェブページはウェブブラウザ上に表示される文書であり、重要な情報を提供するテキスト、画像、ビデオ、その他のマルチメディア要素を含んでいます。多くの場合、製品やサービスを宣伝します。他のウェブページへのリンクがある場合もあり、ユーザーはフォームに入力したり、オンラインで購入したり、その他のアクションを行うことでウェブページと相互作用することができます。
ダッシュボードにはいくつまでのビジュアルを載せるべきでしょうか?
視覚的にわかりやすくするために、ダッシュボードに含まれるビジュアルの数は2つか3つに制限しましょう。ビジュアルが多すぎると、ごちゃごちゃした印象になり、解釈が難しくなります。
ダッシュボードUIキットとは何ですか?
ダッシュボードUIキットは、EspressDashboardのようにユーザーインターフェイス要素、テンプレート、コンポーネントの設計済みコレクションです。ダッシュボードの設計と構築のために特別に作成されています。これらのキットは、開発者やデザイナーが視覚的に魅力的で機能的なダッシュボードを迅速かつ簡単に作成するための基盤を提供します。
これらのキットには通常、ダッシュボードのデザインで一般的に使用されるさまざまなチャート、グラフ、テーブル、ボタン、アイコン、およびその他の UI 要素が含まれています。これらのキットは、ダッシュボードの目的に応じて高度にカスタマイズすることができます。これにより、ユーザは特定のデザインプロジェクトの要件に合わせてコンポーネントを変更し、適合させることができます。これらのキットは、デザインプロセスを合理化するために、ウェブやモバイルアプリの開発でよく使用されます。ダッシュボードの全体的なルック&フィールに一貫性を持たせるのに役立ちます。
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが1CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
ゲージ: (Gauge)とは
ゲージはプロット・バックグラウンド・イメージとプロット・フォアーグラウンド・イメージの両方、またはどちらかを含むダイアル・チャートの特別なタイプです。
ユーザが簡単にゲージが作成できるように前もって定義済のゲージ・テンプレート用のタブをいくつか準備しています。またテンプレートを作成して、ユーザ独自の作成し、フォルダに保存しておくこともできます。
例:/gauges/templates/Custom/ フォルダ
このテンプレートを[カスタム]タブに追加するには、<ERESインストール> / gauges / screenshots / selected / Customに配置されたテンプレートのスクリーンショットと、<ERESに配置されたテンプレートのディマーバージョン インストール> / gauges / screenshots / unselected / Custom /をクリックします。 スクリーンショットを作成する簡単な方法は、通常のスクリーンショット用にテンプレートをgifに書き出し、100ピクセル×100ピクセルにサイズ変更することです。 その後、背景を暗い色に変更し、調光版のために再度エクスポートしてサイズを変更します。
またダイアル・チャートへゲージ・テンプレートを適応させることも可能です。ダイアル・チャートを使用時に適応させるテンプレートを選択することにより、新しいチャートを作成するようにゲージ・タブを表示することができます。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
Android端末に対応していますか?
はい、モバイル端末としてAndroid, iPad, iPhoneに対応しております。
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressDashboard -導入・製品 (10)
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
EspressDashboard -ライセンス (4)
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが2CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
EspressDashboard -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressDashboard -評価 (5)
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
EspressDashboard -機能 (8)
ダッシュボード・レポーティンを成功させるには?
ダッシュボード・レポーティングを成功させるには、4つのステップに従うことが重要です。
1. 明確な目的を持ってダッシュボードを計画し、追跡すべき関連KPIを特定する。
2. データソースを評価するためにデータディスカバリーを実施する。
3. ユーザ・フレンドリーなビジュアル要素でデザインする。
4. ダッシュボードを実装し、その機能をテストする。
注:「データ・ディスカバリ」は、 昨今の目まぐるしく変わる市場環境や、予測困難な外部環境の変化に対応するためには、従来のBIシステムよりも迅速で手軽にデータを分析でき、かつ、ビジネス上の課題を発見できる仕組み。
ゲージ: (Gauge)とは
ゲージはプロット・バックグラウンド・イメージとプロット・フォアーグラウンド・イメージの両方、またはどちらかを含むダイアル・チャートの特別なタイプです。
ユーザが簡単にゲージが作成できるように前もって定義済のゲージ・テンプレート用のタブをいくつか準備しています。またテンプレートを作成して、ユーザ独自の作成し、フォルダに保存しておくこともできます。
例:/gauges/templates/Custom/ フォルダ
このテンプレートを[カスタム]タブに追加するには、<ERESインストール> / gauges / screenshots / selected / Customに配置されたテンプレートのスクリーンショットと、<ERESに配置されたテンプレートのディマーバージョン インストール> / gauges / screenshots / unselected / Custom /をクリックします。 スクリーンショットを作成する簡単な方法は、通常のスクリーンショット用にテンプレートをgifに書き出し、100ピクセル×100ピクセルにサイズ変更することです。 その後、背景を暗い色に変更し、調光版のために再度エクスポートしてサイズを変更します。
またダイアル・チャートへゲージ・テンプレートを適応させることも可能です。ダイアル・チャートを使用時に適応させるテンプレートを選択することにより、新しいチャートを作成するようにゲージ・タブを表示することができます。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
Android端末に対応していますか?
はい、モバイル端末としてAndroid, iPad, iPhoneに対応しております。
ダッシュボードとウェブページの違いは何でしょうか?
どちらもコンピュータの画面上で開くことができますが、類似点はそこまでです。
ダッシュボードはデータを素早く処理するためのもので、組織や個人レベルのKPIの概要を簡単に把握できる重要な視覚化ツールです。チャート、グラフ、表、ゲージなどのインタラクティブな視覚的要素の助けを借りて、ダッシュボードは、ユーザーが分析し、情報に基づいたデータ駆動型の意思決定を行うのに役立つように設計されています。
また、ウェブページはウェブブラウザ上に表示される文書であり、重要な情報を提供するテキスト、画像、ビデオ、その他のマルチメディア要素を含んでいます。多くの場合、製品やサービスを宣伝します。他のウェブページへのリンクがある場合もあり、ユーザーはフォームに入力したり、オンラインで購入したり、その他のアクションを行うことでウェブページと相互作用することができます。
ダッシュボードUIキットとは何ですか?
ダッシュボードUIキットは、EspressDashboardのようにユーザーインターフェイス要素、テンプレート、コンポーネントの設計済みコレクションです。ダッシュボードの設計と構築のために特別に作成されています。これらのキットは、開発者やデザイナーが視覚的に魅力的で機能的なダッシュボードを迅速かつ簡単に作成するための基盤を提供します。
これらのキットには通常、ダッシュボードのデザインで一般的に使用されるさまざまなチャート、グラフ、テーブル、ボタン、アイコン、およびその他の UI 要素が含まれています。これらのキットは、ダッシュボードの目的に応じて高度にカスタマイズすることができます。これにより、ユーザは特定のデザインプロジェクトの要件に合わせてコンポーネントを変更し、適合させることができます。これらのキットは、デザインプロセスを合理化するために、ウェブやモバイルアプリの開発でよく使用されます。ダッシュボードの全体的なルック&フィールに一貫性を持たせるのに役立ちます。
ダッシュボードにはいくつまでのビジュアルを載せるべきでしょうか?
視覚的にわかりやすくするために、ダッシュボードに含まれるビジュアルの数は2つか3つに制限しましょう。ビジュアルが多すぎると、ごちゃごちゃした印象になり、解釈が難しくなります。
EspressDashboard -トラブル (1)
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
EspressReport ES -導入・製品 (10)
システムの提供形態は何がありますか?
クラウド、オンプレミスのどちらでもご利用形態に合わせて提供が可能です。。詳細はお問い合わせください。
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
対応している動作環境について教えてください。
Windows、Linuxなど、Java 8以上が稼動するOSに対応しております。
また、Apache Tomcat、Weblogic、WebSphere、JBossなど、JavaをサポートするWebアプリケーションサーバ下での実行にも対応しています。
仮想マシン(VM)上でも動作しますか?
動作します。
VMWareのESX(i)やMicrosoftのHyper-Vなどでも問題なく動作します。
どのようなデータソースをサポートしていますか?
システム要件をご参照ください。
どのような形式のアプリケーションで利用できますか?
Javaのアプリケーションであれば、サーバーサイド、クライアントサイドのどちらでも利用できます。
サーバーサイドの場合には、サーブレット・JSP上でEspress ChartのAPIを使用し、チャートイメージをWebブラウザへ転送することが出来ます。
クライアントサイドの場合には、一般的なJavaのアプレットの他、Swingもサポートしております。
EspressReport ES -ライセンス (4)
開発と運用に必要なライセンスを教えてください。
初回ご購入時は基本パック(開発ライセンス×1、サーバライセンス×1)で開発と運用が可能です。その他サーバを追加する際には追加サーバライセンス、サーバが1CPUを超過する際には追加CPUライセンス、開発環境を追加する際には追加開発ライセンスが必要です。
ライセンスを登録するサイトへアクセスしましたが、正常に表示されずライセンスが登録できません。
以下へアクセスできる必要があるため、ポート:8444がブロックされていないかご確認ください。
https://data.quadbase.com:8444/
トライアル版は製品版と比較して、機能面や性能面で違いがありますか?
トライアル版で出力したチャートには、評価目的のモジュールであることを表すメッセージが表示されます。
それ以外は機能・性能とも製品版とまったく同様にお試しいただけます。なお、トライアル版は45日間の試用期限を設けています。
評価版で作成したチャートモジュールや設定などを、製品版購入時に引き継ぐことは可能でしょうか?
可能です。ライセンスファイルを評価版のものから製品版のものに変更することで製品版になります。
EspressReport ES -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
データソースに含まれる日本語等のマルチバイト文字に対応しています。GUIはデフォルトで英語ですが、日本語化マッピングファイルを適用いただくことで日本語UIに変更可能です。また、日本語の製品ドキュメントをご用意しております。
導入支援は行っていますか?
有償サービスとなりますが、弊社にて設計、インストール、設定を行うことも可能です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
EspressReport ES -評価 (5)
操作講習会などはありますか?
定期的な講習はありませんが、導入検討中のお客様および購入済みのお客様向け無償オンライン講習会の準備は可能です。詳細はお問い合わせください。
評価版から製品版データ移行することが出来ますか
はい、可能です。評価版システムに製品キー・ファイルを製品にディプロイすることで可能になります。
評価期間は何日間ですか?
評価用アプリケーションインストール後45日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。ただし、出力されたチャート・グラフに評価版のロゴマークが表示されます。
EspressReport ES -機能 (8)
ゲージ: (Gauge)とは
ゲージはプロット・バックグラウンド・イメージとプロット・フォアーグラウンド・イメージの両方、またはどちらかを含むダイアル・チャートの特別なタイプです。
ユーザが簡単にゲージが作成できるように前もって定義済のゲージ・テンプレート用のタブをいくつか準備しています。またテンプレートを作成して、ユーザ独自の作成し、フォルダに保存しておくこともできます。
例:/gauges/templates/Custom/ フォルダ
このテンプレートを[カスタム]タブに追加するには、<ERESインストール> / gauges / screenshots / selected / Customに配置されたテンプレートのスクリーンショットと、<ERESに配置されたテンプレートのディマーバージョン インストール> / gauges / screenshots / unselected / Custom /をクリックします。 スクリーンショットを作成する簡単な方法は、通常のスクリーンショット用にテンプレートをgifに書き出し、100ピクセル×100ピクセルにサイズ変更することです。 その後、背景を暗い色に変更し、調光版のために再度エクスポートしてサイズを変更します。
またダイアル・チャートへゲージ・テンプレートを適応させることも可能です。ダイアル・チャートを使用時に適応させるテンプレートを選択することにより、新しいチャートを作成するようにゲージ・タブを表示することができます。
ダッシュボード・レポーティンを成功させるには?
ダッシュボード・レポーティングを成功させるには、4つのステップに従うことが重要です。
1. 明確な目的を持ってダッシュボードを計画し、追跡すべき関連KPIを特定する。
2. データソースを評価するためにデータディスカバリーを実施する。
3. ユーザ・フレンドリーなビジュアル要素でデザインする。
4. ダッシュボードを実装し、その機能をテストする。
注:「データ・ディスカバリ」は、 昨今の目まぐるしく変わる市場環境や、予測困難な外部環境の変化に対応するためには、従来のBIシステムよりも迅速で手軽にデータを分析でき、かつ、ビジネス上の課題を発見できる仕組み。
他システムとの連携は可能ですか?
外部システムとの連携用の備え付けのAPIを利用して外部システムとの連携が可能です。詳細はお問い合わせください。
Android端末に対応していますか?
はい、モバイル端末としてAndroid, iPad, iPhoneに対応しております。
ダッシュボードUIキットとは何ですか?
ダッシュボードUIキットは、EspressDashboardのようにユーザーインターフェイス要素、テンプレート、コンポーネントの設計済みコレクションです。ダッシュボードの設計と構築のために特別に作成されています。これらのキットは、開発者やデザイナーが視覚的に魅力的で機能的なダッシュボードを迅速かつ簡単に作成するための基盤を提供します。
これらのキットには通常、ダッシュボードのデザインで一般的に使用されるさまざまなチャート、グラフ、テーブル、ボタン、アイコン、およびその他の UI 要素が含まれています。これらのキットは、ダッシュボードの目的に応じて高度にカスタマイズすることができます。これにより、ユーザは特定のデザインプロジェクトの要件に合わせてコンポーネントを変更し、適合させることができます。これらのキットは、デザインプロセスを合理化するために、ウェブやモバイルアプリの開発でよく使用されます。ダッシュボードの全体的なルック&フィールに一貫性を持たせるのに役立ちます。
ダッシュボードにはいくつまでのビジュアルを載せるべきでしょうか?
視覚的にわかりやすくするために、ダッシュボードに含まれるビジュアルの数は2つか3つに制限しましょう。ビジュアルが多すぎると、ごちゃごちゃした印象になり、解釈が難しくなります。
ダッシュボードとウェブページの違いは何でしょうか?
どちらもコンピュータの画面上で開くことができますが、類似点はそこまでです。
ダッシュボードはデータを素早く処理するためのもので、組織や個人レベルのKPIの概要を簡単に把握できる重要な視覚化ツールです。チャート、グラフ、表、ゲージなどのインタラクティブな視覚的要素の助けを借りて、ダッシュボードは、ユーザーが分析し、情報に基づいたデータ駆動型の意思決定を行うのに役立つように設計されています。
また、ウェブページはウェブブラウザ上に表示される文書であり、重要な情報を提供するテキスト、画像、ビデオ、その他のマルチメディア要素を含んでいます。多くの場合、製品やサービスを宣伝します。他のウェブページへのリンクがある場合もあり、ユーザーはフォームに入力したり、オンラインで購入したり、その他のアクションを行うことでウェブページと相互作用することができます。
EspressReport ES -トラブル (1)
Windows版のインストールに失敗します
Espress 6.6 においてWinodws版の対応OSは、Windows7までとなっております。
Windows7以降のWindowsOSにインストールする際は、互換モードに設定しインストーラを実行してください。
ERP2 -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
ERP2 -評価 (2)
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
DB2Connectivity -導入・製品 (3)
HiT DB2 Connectivity Developer Edition (DE: 開発者版)について
IBMのi5, System i, iSeries, AS/400上で稼動するDB2データをWindowsでのActive Server Page(ASP)に利用したり、Visual Basicアプリケーションに利用したりすることは通常は簡単ではありません。HiT ODBC Server/400 Developer EditionとHiT OLEDB Server/400 Developer Editionに含まれるHiT ASPと HiT VBツールキットを利用することにより、それらの開発時間を大幅に短縮できます。
○ HiT ODBC Server/400 Developer Edition (DE: 開発者版)はi5, System i, iSeries, AS/400上で稼動するIBM DB2をアクセスするためのSQLミドルウェアで、Windowsプラットフォーム上で稼動し、ユーザまたはサードパーティのアプリケーションで利用されます。HiT ODBC Server/400 DEはDB2データのアクセス、リトリーブ、アップデートにWindows Open Database Connectivity (ODBC)をサポートします。またActive Server Page(ASP)と Visual Basic のツールキットを含みADO経由でDB2データを接続、クエリー、リトリーブ、アップデートが可能なソースコードを含むサンプル・アプリケーションが含まれます。
またIBM Optimized Database Server (ODBS)プロトコール標準を利用しているので、HiT ODBC Server/400 DEはネイティブなIBM OS/400サーバ・プログラムを使用し、i5, System i, iSeries, AS/400プラットフォームに特別なソフトウェアは必要ありません。
○ HiT OLEDB Server/400 Developer Edition (DE)は同様にi5, System i, iSeries, AS/400上で稼動するIBM DB2をアクセスするためのSQLミドルウェアで、Windowsプラットフォーム上で稼動し、ユーザまたはサードパーティのアプリケーションで利用されます。HiT OLEDB Server/400 DEはADO v2.x経由、またはOEL DBオブジェクト・プロパティ経由での直接にアプリケーションSQLステートメントが可能で、そしてDB2データのアクセス、リトリーブ、アップデートが可能です。また同様にHiT ASPと HiT VBツールキットを含みます。
●HiT ASP ツールキット
Webアプリケーションの開発の高速化に最適
Microsoft IIS Web開発用のHiT Active Server Page (ASP) ツールキットはHiT ODBC Serverミドルウェアとの組合せでIIS ASP開発環境でのDB2のWeb統合に有益なスタートをもたらします。
HiT ASPツールキットに含まれるWebアプリケーションからDB2テーブルに対するクエリー、アップデートの検証済ASPサンプルを開発者が利用することでWebアプリケーション・開発時間を大幅に削減できます。サンプルにはADOレコードセットを使用しての接続確立方法、ストアード・プロシージャ実行、テーブル・データのリトリーブとインサート、HTML経由での結果表示などがあります。すべてのサンプルは各種のDB2サーバとプラットフォームで検証されています。HiT ASPツールキットはWindowsフラットフォームで稼動し、HiT ODBCサーバ製品経由でDB2サーバとコミュニケーションを行います。
●HiT VBツールキット
高速VBアプリケーション開発に最適
HiT VBツールキットはすべてのHiT ODBC と OLE DB開発者版製品に含まれMicrosoft Visual Basicを使用する開発者をサポートします。HiT ODBC と OLE DBミドルウェア製品と組み合わせて使用することにより、Visual Basic開発環境でのDB2アプリケーション・インテグレーションに有益なスタートをもたらします。
HiT VBツールキットでADO, RDO, DAO, ODBCDirectインターフェイスを使用してDB2テーブル・データにアクセスするためのソース・コード・サンプルを開発者に提供することにより、アプリケーションの開発時間を削減することができます。サンプルはレコードセットを使用しての接続確立、ストアード・プロシージャの実行、DB2データのアップデートなどが含まれます。すべてのサンプルは各種のDB2サーバとプラットフォームで検証されています。HiT VBツールキットはWindowsフラットフォームで稼動し、HiT ODBCとOLE DB製品経由でDB2サーバとのコミュニケーションを行います。
HiT Db2 Connectivity製品の選択方法 ( ID:1635)
○もしアプリケーションがADO.NET または Visual Studioで構築されたいれば、Ritmo (.NET)を選択
○もしアプリケーションがJavaで構築されていればHiT JDBCを選択
○もしアプリケーションが Powerbuilder等の他で構築されていればHiT ODBC か HiT OLEDBを選択
ただしHiT ODBCはリレーショナル・データベース形式のみをサポートし、HiT OLEDBはリレーショナル+他のすべてのデータ形式にサポートします。
ODBC/400 と ODBC/Db2の異差
●HiT ODBC/DB2およびHiT ODBC Server/DB2はIBM Db2 on z/OS, Linux, Unix, Windowsサーバとの通信でDRDAプロトコールを使用します。 HiT ODBC/DB2およびHiT ODBC Server/DB2は、以下のIBM Db2環境で動作します。
· IBM Db2 LUW
· IBM Db2 for z/OS (OS/390)
· IBM Db2 for i – supporting IBM OS/400 Operating Systems V4R2 or higher
●HiT ODBC / 400およびHiT ODBC Server / 400は、ODBSプロトコルを使用し、IBM iオペレーティング・システムV3R1以上を必要とします。
DB2Connectivity -ライセンス (6)
ライセンス体系はどのようになっていますか?
ワークステーション(クライアント)、またはサーバ・ベースでライセンスされます。クライアント・ライセンスは各PCごとにライセンスされます。クライント・ライセンスをWindowsサーバで稼動させることはできません。
サーバライセンスには次の2種類があります。
1) Open Connectionサーバ・ライセンスは 同時接続数には制限はありませんが、プロセッサ毎の価格になります。
2) Limited Connectionサーバライセンスは同時接続数です。 Processor数には依存しません。
クライアント版はWindows Server上で使用できますか?
できません。Windows XP/Vista/7でのみで使用可能です。WindowsServer上で稼働させる場合は「サーバ版」が必要となります。
サーバライセンスはどの様になっていますか?
サーバライセンスは同時接続(アプリケーション・サーバとDB2サーバ間)の数または無制限接続の両方があります。
サーバライセンスの同時接続数制限版はどの様にライセンスされますか?
プロセッサ数には依存しませんが、同時接続数が5, 10, 25等に制限されます。
無制限接続のサーバライセンスはどの様にライセンスされますか?
無制限接続のサーバライセンスはアップリケーション・サーバのプロセッサ数に依存します。
開発者(ディベロッパ)・エディションはどの様な製品ですか?
開発者エディションはサンプル・ソースコード・コードが含まれ、自社アプリケーションに組み込む権利を有します。
DB2Connectivity -購入サポート (6)
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
DB2Connectivity -評価 (2)
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
DB2Connectivity -機能 (2)
Q: 各プラットフォームでのDB2用のデフォルトHost Code Pageとポート・ナンバーは?
A:
AIX
Host Code Page – 819 Latin
Port Number – 446
Linux
Host Code Page – 819
Port Number – 50000
OS390
Host Code Page – 037
Port Number – 446
OS400 (AS/400)
Host Code Page 037
Port Number 8471
Windows Server
Host Code Page – 1252
Port Number – 50000
Host Code Pageについて(KBFAQ 1024)
HiT ODBC/400, HiT OLEDB/400 and Ritmo for iSeries
IDS_CODEPAGE_037_1 “037 – US/Can./Australia/N.Z.”
IDS_CODEPAGE_037_2 “037 – Netherlands”
IDS_CODEPAGE_037_3 “037 – Portugal/Brazil”
IDS_CODEPAGE_273 “273 – German/Austrian”
IDS_CODEPAGE_277 “277 – Danish/Norwegian”
IDS_CODEPAGE_278 “278 – Finnish/Swedish”
IDS_CODEPAGE_280 “280 – Italian”
IDS_CODEPAGE_284 “284 – Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_285 “285 – UK”
IDS_CODEPAGE_297 “297 – French”
IDS_CODEPAGE_424 “424 – Hebrew”
IDS_CODEPAGE_500 “500 – Belgian/Swiss/Can.”
IDS_CODEPAGE_870 “870 – Eastern Europe”
IDS_CODEPAGE_871 “871 – Icelandic”
IDS_CODEPAGE_875 “875 – Greek”
IDS_CODEPAGE_1026 “1026 – Turkey”
IDS_CODEPAGE_290 “290 – Jpn. Katakana Host SBCS”
IDS_CODEPAGE_1027 “1027 – Jpn. Latin Host SBCS”
IDS_CODEPAGE_933 “933 – Korean”
IDS_CODEPAGE_935 “935 – Simplified Chinese”
IDS_CODEPAGE_937 “937 – Traditional Chinese”
IDS_CODEPAGE_4396 “4396 – Jpn. Host DBCS”
IDS_CODEPAGE_5026 “5026 – Jpn. Katakana-Kanji Host Mix.”
IDS_CODEPAGE_5035 “5035 – Jpn. Latin-Kanji Host Mix.”
IDS_CODEPAGE_1140_1 “1140 – (Euro) US/Can./Australia”
IDS_CODEPAGE_1140_2 “1140 – (Euro) N.Z./Netherlands”
IDS_CODEPAGE_1140_3 “1140 – (Euro) Portugal/Brazil”
IDS_CODEPAGE_1141 “1141 – (Euro) German/Austrian”
IDS_CODEPAGE_1142 “1142 – (Euro) Danish/Norwegian”
IDS_CODEPAGE_1143 “1143 – (Euro) Finnish/Swedish”
IDS_CODEPAGE_1144 “1144 – (Euro) Italian”
IDS_CODEPAGE_1145 “1145 – (Euro) Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_1146 “1146 – (Euro) UK”
IDS_CODEPAGE_1147 “1147 – (Euro) French”
IDS_CODEPAGE_1148 “1148 – (Euro) Belgian/Swiss/Can.”
IDS_CODEPAGE_1149 “1149 – (Euro) Icelandic”
IDS_CODEPAGE_420 “420 – Arabic”
IDS_CODEPAGE_838 “838 – Thai”
HiT ODBC/DB2, HiT OLEDB/DB2, and Ritmo for DB2
IDS_CODEPAGE_037_1 “037 – US/Canada/Australia/N.Z.”
IDS_CODEPAGE_037_2 “037 – Netherlands”
IDS_CODEPAGE_037_3 “037 – Portugal/Brazil”
IDS_CODEPAGE_273 “273 – German/Austrian”
IDS_CODEPAGE_277 “277 – Danish/Norwegian”
IDS_CODEPAGE_278 “278 – Finnish/Swedish”
IDS_CODEPAGE_280 “280 – Italian”
IDS_CODEPAGE_284 “284 – Spanish”
IDS_CODEPAGE_285 “285 – UK”
IDS_CODEPAGE_297 “297 – French”
IDS_CODEPAGE_420 “420 – Arabic”
IDS_CODEPAGE_424 “424 – Hebrew”
IDS_CODEPAGE_500 “500 – Belgian/Swiss”
IDS_CODEPAGE_819 “819 – Latin”
IDS_CODEPAGE_870 “870 – Eastern Europe”
IDS_CODEPAGE_871 “871 – Icelandic”
IDS_CODEPAGE_875 “875 – Greek”
IDS_CODEPAGE_290 “290 – Jpn. Katakana Host SBCS”
IDS_CODEPAGE_932 “932 – Jpn. PC Mixed incl. 1880 UDC”
IDS_CODEPAGE_933 “933 – Korean”
IDS_CODEPAGE_935 “935 – S. Chinese”
IDS_CODEPAGE_937 “937 – T. Chinese”
IDS_CODEPAGE_943 “943 – Jpn. PC Mixed for Open Env.”
IDS_CODEPAGE_954 “954 – Jpn. EUC”
IDS_CODEPAGE_1026 “1026 – Turkey”
IDS_CODEPAGE_1027 “1027 – Jpn. Latin Host SBCS”
IDS_CODEPAGE_1140_1 “1140 – (Euro) US/Can./Australia”
IDS_CODEPAGE_1140_2 “1140 – (Euro) N.Z./Netherlands”
IDS_CODEPAGE_1140_3 “1140 – (Euro) Portugal/Brazil”
IDS_CODEPAGE_1141 “1141 – (Euro) German/Austrian”
IDS_CODEPAGE_1142 “1142 – (Euro) Danish/Norwegian”
IDS_CODEPAGE_1143 “1143 – (Euro) Finnish/Swedish”
IDS_CODEPAGE_1144 “1144 – (Euro) Italian”
IDS_CODEPAGE_1145 “1145 – (Euro) Spanish/Latin Amer. Sp.”
IDS_CODEPAGE_1146 “1146 – (Euro) UK”
IDS_CODEPAGE_1147 “1147 – (Euro) French”
IDS_CODEPAGE_1148 “1148 – (Euro) Belgian/Swiss/Can.”
IDS_CODEPAGE_1149 “1149 – (Euro) Icelandic”
IDS_CODEPAGE_1252 “1252 – Windows ANSI”
IDS_CODEPAGE_4396 “4396 – Jpn. Host DBCS”
IDS_CODEPAGE_5026 “5026 – Jpn. Katakana-Kanji Host Mixed”
IDS_CODEPAGE_5035 “5035 – Jpn. Latin-Kanji Host Mixed”
DB2Connectivity -ODBC (2)
ODBCで日本語が文字化けします。
日本語文字化けが発生する場合、CCSIDに問題がある場合がほとんどです。
まずは、ODBC設定画面にて、Host Code Pageが「5026」または「5035」であるかどうかをご確認ください。
もしAS/400側で日本語文字を扱っているCCSIDが1027などの本来シングルバイト用のフィールドの場合は、ODBC設定画面にて、「Use Host Code Page to override column CCSIDs」にチェックを入れてください。これはフィールドのCCSIDを「Host Code Page」のものに変換する機能です。
ExcelやAccessから、設定したODBCを呼出す事ができません。
ODBCとExcel/Accessはともに32bitもしくは64bitかで一致されている必要があります。
例えば、ODBC64bit版をご利用いただく場合は、Excel/Accessも64bit版が必要です。ただし、Excel/Accessの64bit版はOffice2010からの対応になっておりますので、Office2007以前の場合はODBCの32bit版をご利用ください。OSが64bitの場合でも32bit版のODBCは問題なく動作いたします。
DB2Connectivity -OLE DB (1)
Q:Visual C++ を使用して AS/400への接続をどのようにイニシエイトしますか?
A: サンプルコードは:
///////////////////////////////////////////////////////////////////////////////
// OLE400 Test Sample – 07-07-2000
//
// Standard sample for testing HiT OLEDB400 Provider.
// Initialization phases can be used in any other connect exercise.
//
///////////////////////////////////////////////////////////////////////////////
#include
//You may derive a class from CComModule and use it if you want to override
//something, but do not change the name of _Module
extern CComModule _Module;
#include
#include
#include “atldb.h”
#include
#include
#include #define SAFE_RELEASE(pv) if(pv) { (pv)->Release(); (pv) = NULL; } WCHAR* A2WSTR(LPCSTR lp, int nLen) { USES_CONVERSION; int nConvertedLen = MultiByteToWideChar(_acp, str = ::SysAllocStringLen(NULL, nConvertedLen); if ( str != NULL ) { LPSTR WSTR2A(LPSTR cBuf, LPCWSTR lpw, LPCSTR lpDef) { USES_CONVERSION; int nConvertedLen = WideCharToMultiByte(_acp, if ( cBuf != NULL ) { return cBuf; CComPtr // MAIN TEST FUNCTION void main () IDBInitialize* pIDBInitialize = NULL; hr = CoInitialize(NULL); // retrieve pMalloc interface hr = CoCreateInstance(CLSID_MSDAINITIALIZE, /////////////////////////////////////////////////////// memset (lpItemText, 0, 200); printf (“Open connection to HiT OLE DB Provider for DB2\r\n”); printf (“UDL File\t: “); printf (“User ID \t: “); printf (“Password\t: “); /////////////////////////////////////////////////////// hr = pIDataInitialize->LoadStringFromStorage(pwszTemp, &pwszInitString); SysFreeString (pwszTemp); /////////////////////////////////////////////////////// hr = pDataSource->QueryInterface(IID_IDBInitialize, (void**)&pIDBInitialize); if (pIDBProperties == NULL) hr = pIDBProperties->GetProperties(0, NULL, &cPropSets, &prgPropSets); // Set edit data link properties rgProps[0].dwPropertyID = DBPROP_INIT_PROMPT; rgProps[1].dwPropertyID = DBPROP_AUTH_USERID; rgProps[2].dwPropertyID = DBPROP_AUTH_PASSWORD; PropSet.cProperties = 3; hr = pIDBProperties->SetProperties (1, &PropSet); // Free memory // free all properties // now free the property set /////////////////////////////////////////////////////// hr = pIDBInitialize->Initialize(); printf (“CONNECTED\r\n\r\n”); // to do: put any code here /////////////////////////////////////////////////////// // Release any references and continue. SAFE_RELEASE(pIDBInitialize); SAFE_RELEASE (pIDBProperties); SAFE_RELEASE (pIDataInitialize); CoUninitialize(); SAFE_RELEASE (pIDBInitialize);
#define TESTC(hr) { if(FAILED(hr)) goto CLEANUP; }
BSTR str = NULL;
0,
lp,
nLen,
NULL,
NULL) – 1;
MultiByteToWideChar(_acp,
0,
lp,
-1,
str,
nConvertedLen);
}
return str;
}
0,
lpw,
-1,
NULL,
0,
lpDef,
NULL) – 1;
if (nConvertedLen>0) {
WideCharToMultiByte(_acp,
0,
lpw,
-1,
cBuf,
nConvertedLen,
lpDef,
NULL);
}
}
}
MEMORYSTATUS lpBuffer;
///////////////////////////////////////////////////////////////////////////////
{
IDataInitialize* pIDataInitialize = NULL;
DWORD dwCLSCTX = CLSCTX_INPROC_SERVER;
DBPROPSET* prgPropSets = NULL;
ULONG cPropSets;
IUnknown* pDataSource = NULL;
IDBProperties* pIDBProperties = NULL;
WCHAR* pwszTemp;
WCHAR* pwszInitString;
HRESULT hr = S_OK;
if (FAILED(hr))
return;
hr = ::CoGetMalloc(1, (LPMALLOC *) &pMalloc);
if (FAILED(hr))
return;
NULL,
CLSCTX_INPROC_SERVER,
IID_IDataInitialize,
(void**)&pIDataInitialize);
// Prompt data
char lpItemText [200];
char lpUDL [50];
char lpUserID [30];
char lpPassword [30];
int nLen = -1;
memset (lpUDL, 0, 50);
memset (lpUserID, 0, 30);
memset (lpPassword, 0, 30);
printf (“==================================================\r\n”);
scanf (“%s”, lpUDL);
sprintf (lpItemText, “C:\\Program Files\\Common Files\\System\\OLE DB\\Data Links\\%s”, lpUDL);
printf (“\r\n”);
scanf (“%s”, lpUserID);
printf (“\r\n”);
scanf (“%s”, lpPassword);
printf (“\r\n”);
// Get connection string from Data Link file
nLen = strlen(lpItemText);
pwszTemp = A2WSTR(lpItemText, nLen + 1 );
// Get Data Source object
hr = pIDataInitialize->GetDataSource(NULL,
dwCLSCTX,
pwszInitString,
IID_IDBInitialize,
(IUnknown**)&pDataSource);
hr = pIDBInitialize->QueryInterface (IID_IDBProperties,
(void**)&pIDBProperties);
DBPROP rgProps[3];
DBPROPSET PropSet;
rgProps[0].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[0].vValue.vt = VT_I2;
rgProps[0].vValue.iVal = DBPROMPT_NOPROMPT;
rgProps[1].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[1].vValue.vt = VT_BSTR;
nLen = strlen(lpUserID);
pwszTemp = A2WSTR(lpUserID, nLen + 1 );
V_BSTR(&(rgProps[1].vValue))= SysAllocStringLen (pwszTemp, wcslen(pwszTemp));
rgProps[2].dwOptions = DBPROPOPTIONS_REQUIRED;
rgProps[2].vValue.vt = VT_BSTR;
nLen = strlen(lpPassword);
pwszTemp = A2WSTR(lpPassword, nLen + 1 );
rgProps[2].vValue.bstrVal = SysAllocStringLen (pwszTemp, wcslen(pwszTemp));
PropSet.rgProperties = rgProps;
PropSet.guidPropertySet = DBPROPSET_DBINIT;
SysFreeString (rgProps[1].vValue.bstrVal);
SysFreeString (rgProps[2].vValue.bstrVal);
pMalloc->Free (prgPropSets->rgProperties);
pMalloc->Free (prgPropSets);
// Initialize connection
printf (“Connecting…\r\n\r\n”);
if (FAILED(hr))
return;
// …
// Disconnect
printf (“Disconnecting…\r\n”);
hr = pIDBInitialize->Uninitialize ();
SAFE_RELEASE (pDataSource);
}
DB2Connectivity -.NET(Ritmo) (2)
Ritmo を使用してDB2 をアクセスC# や VB.NET のサンプル・コードはどこか にありますか?
Q:Ritmo を使用してDB2 をアクセスC# や VB.NET のサンプル・コードはどこか
にありますか?
A:基本的なSELECT/INSERT/UPDATE/DELETE を実行できるようにRitmo はC# と
VB.NET コード・サンプルを準備しています。さらにストアード・プロシージ
ャ・コール作成やパラメトリック・クエリもカバーします。Ritmo ToolBox Help
メニューの下にサンプル・コードがあります。Ritmo ToolBox のプルダウン・メ
ニューからHelp/Contents を選択してサンプルコードを選びます。
.NET経由でAS/400に接続する時にHiT OLEDB/400を選択するのかRitmo/iを選択するのか?
.NETアプリケーション開発者はAS/400サーバへアクセスするためにはマイクロソフトが提供するADO.NET-to-OLE DBまたは-ODBC 使用してODBC または OLEDBのどちらかを経由してそのリモートのデータベースに接続します。しかしこれらのブリッジ・ソリューションはパフォーマンスに影響し、CLR(Common Language Run-time)開発環境を利用する根本のプロバイダとドライバを阻害します。
Ritmo/i はこれらのブリッジ手法より優れた選択になります。それはブリッジを除外し、高いパフォーマンス、CLR機能、アプリケーションに対するオペレーティング。システムスケーラブルな管理を提供します
DB2Connectivity -JDBC (1)
HiT JDBC/400 API サポート
| Methods: | Return Types: | Supported: |
Interface Blob |
| getBinaryStream() | InputStream | Yes |
| getBytes(long pos, int length) | byte[] | Yes |
| length() | long | Yes |
| position(Blob pattern, long start) | long | No |
| position(byte[] pattern, long start) | long | No |
| Methods: | Return Types: | Supported: |
Interface CallableStatement |
| getArray(int i) | Array | No |
| getBigDecimal(int parameterIndex) | BigDecimal | Yes |
| getBigDecimal(int parameterIndex, int scale) | BigDecimal | Yes |
| getBlob(int i) | Blob | No (soon) |
| getBoolean(int parameterIndex) | boolean | Yes |
| getByte(int parameterIndex) | byte | Yes |
| getBytes(int parameterIndex) | byte[] | Yes |
| getClob(int i) | Clob | No (soon) |
| getDate(int parameterIndex) | Date | Yes |
| getDate(int parameterIndex, Calendar cal) | Date | No (soon) |
| getDouble(int parameterIndex) | double | Yes |
| getFloat(int parameterIndex) | float | Yes |
| getInt(int parameterIndex) | int | Yes |
| getLong(int parameterIndex) | long | Yes |
| getObject(int parameterIndex) | Object | Yes |
| getObject(int i, Map map) | Object | No |
| getRef(int i) | Ref | No |
| getShort(int parameterIndex) | short | Yes |
| getString(int parameterIndex) | String | Yes |
| getTime(int parameterIndex) | Time | Yes |
| getTime(int parameterIndex, Calendar cal) | Time | Yes |
| getTimestamp(int parameterIndex) | Timestamp | Yes |
| getTimestamp(int parameterIndex, Calendar cal) | Timestamp | No |
| registerOutParameter(int parameterIndex, int sqlType) | void | Yes |
| registerOutParameter(int parameterIndex, int sqlType, int scale) | void | No |
| registerOutParameter(int paramIndex, int sqlType, String typeName) | void | No |
| wasNull() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface Clob |
| getAsciiStream() | InputStream | No |
| getCharacterStream() | Reader | Yes |
| getSubString(long pos, int length) | String | Yes |
| length() | long | Yes |
| position(Clob searchstr, long start) | long | No |
| position(String searchstr, long start) | long | No |
| Methods: | Return Types: | Supported: |
Interface Connection |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| commit() | void | Yes |
| createStatement() | Statement | Yes |
| createStatement(int resultSetType, int resultSetConcurrency) | Statement | Yes |
| getAutoCommit() | boolean | Yes |
| getCatalog() | String | Yes |
| getMetaData() | DatabaseMetaData | Yes |
| getTransactionIsolation() | int | Yes |
| getTypeMap() | Map | No |
| getWarnings() | SQLWarning | Yes |
| isClosed() | boolean | Yes |
| isReadOnly() | boolean | Yes |
| nativeSQL(String sql) | String | Yes |
| prepareCall(String sql) | CallableStatement | Yes |
| prepareCall(String sql, int resultSetType, int resultSetConcurrency) | CallableStatement | Yes |
| prepareStatement(String sql) | PreparedStatement | Yes |
| prepareStatement(String sql, int resultSetType, int resultSetConcurrency) | PreparedStatement | Yes |
| rollback() | void | Yes |
| setAutoCommit(boolean autoCommit) | void | Yes |
| setCatalog(String catalog) | void | Yes |
| setReadOnly(boolean readOnly) | void | Yes |
| setTransactionIsolation(int level) | void | Yes |
| setTypeMap(Map map) | void | No |
| Methods: | Return Types: | Supported: |
Interface DatabaseMetaData |
| allProceduresAreCallable() | boolean | Yes |
| allTablesAreSelectable() | boolean | Yes |
| dataDefinitionCausesTransactionCommit() | boolean | Yes |
| dataDefinitionIgnoredInTransactions() | boolean | Yes |
| deletesAreDetected(int type) | boolean | Yes |
| doesMaxRowSizeIncludeBlobs() | boolean | Yes |
| getBestRowIdentifier(String catalog, String schema, String table, int scope, boolean nullable) | ResultSet | Yes |
| getCatalogs() | ResultSet | Yes |
| getCatalogSeparator() | String | Yes |
| getCatalogTerm() | String | Yes |
| getColumnPrivileges(String catalog, String schema, String table, String columnNamePattern) | ResultSet | Yes |
| getColumns(String catalog, String schemaPattern, String tableNamePattern, String columnNamePattern) | ResultSet | Yes |
| getConnection() | Connection | Yes |
| getCrossReference(String primaryCatalog, String primarySchema, String primaryTable, String foreignCatalog, String foreignSchema, String foreignTable) | ResultSet | Yes |
| getDatabaseProductName() | String | Yes |
| getDatabaseProductVersion() | String | Yes |
| getDefaultTransactionIsolation() | int | Yes |
| getDriverMajorVersion() | int | Yes |
| getDriverMinorVersion() | int | Yes |
| getDriverName() | String | Yes |
| getDriverVersion() | String | Yes |
| getExportedKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getExtraNameCharacters() | String | Yes |
| getIdentifierQuoteString() | String | Yes |
| getImportedKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getIndexInfo(String catalog, String schema, String table, boolean unique, boolean approximate) | ResultSet | Yes |
| getMaxBinaryLiteralLength() | int | Yes |
| getMaxCatalogNameLength() | int | Yes |
| getMaxCharLiteralLength() | int | Yes |
| getMaxColumnNameLength() | int | Yes |
| getMaxColumnsInGroupBy() | int | Yes |
| getMaxColumnsInIndex() | int | Yes |
| getMaxColumnsInOrderBy() | int | Yes |
| getMaxColumnsInSelect() | int | Yes |
| getMaxColumnsInTable() | int | Yes |
| getMaxConnections() | int | Yes |
| getMaxCursorNameLength() | int | Yes |
| getMaxIndexLength() | int | Yes |
| getMaxProcedureNameLength() | int | Yes |
| getMaxRowSize() | int | Yes |
| getMaxSchemaNameLength() | int | Yes |
| getMaxStatementLength() | int | Yes |
| getMaxStatements() | int | Yes |
| getMaxTableNameLength() | int | Yes |
| getMaxTablesInSelect() | int | Yes |
| getMaxUserNameLength() | int | Yes |
| getNumericFunctions() | String | Yes |
| getPrimaryKeys(String catalog, String schema, String table) | ResultSet | Yes |
| getProcedureColumns(String catalog, String schemaPattern, String procedureNamePattern, String columnNamePattern) | ResultSet | Yes |
| getProcedures(String catalog, String schemaPattern, String procedureNamePattern) | ResultSet | Yes |
| getProcedureTerm() | String | Yes |
| getSchemas() | ResultSet | Yes |
| getSchemaTerm() | String | Yes |
| getSearchStringEscape() | String | Yes |
| getSQLKeywords() | String | Yes |
| getStringFunctions() | String | Yes |
| getSystemFunctions() | String | Yes |
| getTablePrivileges(String catalog, String schemaPattern, String tableNamePattern) | ResultSet | Yes |
| getTables(String catalog, String schemaPattern, String tableNamePattern, String[] types) | ResultSet | Yes |
| getTableTypes() | ResultSet | Yes |
| getTimeDateFunctions() | String | Yes |
| getTypeInfo() | ResultSet | Yes |
| getUDTs(String catalog, String schemaPattern, String typeNamePattern, int[] types) | ResultSet | Yes |
| getURL() | String | Yes |
| getUserName() | String | Yes |
| getVersionColumns(String catalog, String schema, String table) | ResultSet | Yes |
| insertsAreDetected(int type) | boolean | Yes |
| isCatalogAtStart() | boolean | Yes |
| isReadOnly() | boolean | Yes |
| nullPlusNonNullIsNull() | boolean | Yes |
| nullsAreSortedAtEnd() | boolean | Yes |
| nullsAreSortedAtStart() | boolean | Yes |
| nullsAreSortedHigh() | boolean | Yes |
| nullsAreSortedLow() | boolean | Yes |
| othersDeletesAreVisible(int type) | boolean | Yes |
| othersInsertsAreVisible(int type) | boolean | Yes |
| othersUpdatesAreVisible(int type) | boolean | Yes |
| ownDeletesAreVisible(int type) | boolean | Yes |
| ownInsertsAreVisible(int type) | boolean | Yes |
| ownUpdatesAreVisible(int type) | boolean | Yes |
| storesLowerCaseIdentifiers() | boolean | Yes |
| storesLowerCaseQuotedIdentifiers() | boolean | Yes |
| storesMixedCaseIdentifiers() | boolean | Yes |
| storesMixedCaseQuotedIdentifiers() | boolean | Yes |
| storesUpperCaseIdentifiers() | boolean | Yes |
| storesUpperCaseQuotedIdentifiers() | boolean | Yes |
| supportsAlterTableWithAddColumn() | boolean | Yes |
| supportsAlterTableWithDropColumn() | boolean | Yes |
| supportsANSI92EntryLevelSQL() | boolean | Yes |
| supportsANSI92FullSQL() | boolean | Yes |
| supportsANSI92IntermediateSQL() | boolean | Yes |
| supportsBatchUpdates() | boolean | Yes |
| supportsCatalogsInDataManipulation() | boolean | Yes |
| supportsCatalogsInIndexDefinitions() | boolean | Yes |
| supportsCatalogsInPrivilegeDefinitions() | boolean | Yes |
| supportsCatalogsInProcedureCalls() | boolean | Yes |
| supportsCatalogsInTableDefinitions() | boolean | Yes |
| supportsColumnAliasing() | boolean | Yes |
| supportsConvert() | boolean | No |
| supportsConvert(int fromType, int toType) | boolean | No |
| supportsCoreSQLGrammar() | boolean | Yes |
| supportsCorrelatedSubqueries() | boolean | Yes |
| supportsDataDefinitionAndDataManipulationTransactions() | boolean | Yes |
| supportsDataManipulationTransactionsOnly() | boolean | Yes |
| supportsDifferentTableCorrelationNames() | boolean | Yes |
| supportsExpressionsInOrderBy() | boolean | Yes |
| supportsExtendedSQLGrammar() | boolean | Yes |
| supportsFullOuterJoins() | boolean | Yes |
| supportsGroupBy() | boolean | Yes |
| supportsGroupByBeyondSelect() | boolean | Yes |
| supportsGroupByUnrelated() | boolean | Yes |
| supportsIntegrityEnhancementFacility() | boolean | Yes |
| supportsLikeEscapeClause() | boolean | Yes |
| supportsLimitedOuterJoins() | boolean | Yes |
| supportsMinimumSQLGrammar() | boolean | Yes |
| supportsMixedCaseIdentifiers() | boolean | Yes |
| supportsMixedCaseQuotedIdentifiers() | boolean | Yes |
| supportsMultipleResultSets() | boolean | Yes |
| supportsMultipleTransactions() | boolean | Yes |
| supportsNonNullableColumns() | boolean | Yes |
| supportsOpenCursorsAcrossCommit() | boolean | Yes |
| supportsOpenCursorsAcrossRollback() | boolean | Yes |
| supportsOpenStatementsAcrossCommit() | boolean | Yes |
| supportsOpenStatementsAcrossRollback() | boolean | Yes |
| supportsOrderByUnrelated() | boolean | Yes |
| supportsOuterJoins() | boolean | Yes |
| supportsPositionedDelete() | boolean | Yes |
| supportsPositionedUpdate() | boolean | Yes |
| supportsResultSetConcurrency(int type, int concurrency) | boolean | Yes |
| supportsResultSetType(int type) | boolean | Yes |
| supportsSchemasInDataManipulation() | boolean | Yes |
| supportsSchemasInIndexDefinitions() | boolean | Yes |
| supportsSchemasInPrivilegeDefinitions() | boolean | Yes |
| supportsSchemasInProcedureCalls() | boolean | Yes |
| supportsSchemasInTableDefinitions() | boolean | Yes |
| supportsSelectForUpdate() | boolean | Yes |
| supportsStoredProcedures() | boolean | Yes |
| supportsSubqueriesInComparisons() | boolean | Yes |
| supportsSubqueriesInExists() | boolean | Yes |
| supportsSubqueriesInIns() | boolean | Yes |
| supportsSubqueriesInQuantifieds() | boolean | Yes |
| supportsTableCorrelationNames() | boolean | Yes |
| supportsTransactionIsolationLevel(int level) | boolean | Yes |
| supportsTransactions() | boolean | Yes |
| supportsUnion() | boolean | Yes |
| supportsUnionAll() | boolean | Yes |
| updatesAreDetected(int type) | boolean | Yes |
| usesLocalFilePerTable() | boolean | Yes |
| usesLocalFiles() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface PreparedStatement |
| addBatch() | void | Yes |
| clearParameters() | void | Yes |
| execute() | boolean | Yes |
| executeQuery() | ResultSet | Yes |
| executeUpdate() | int | Yes |
| getMetaData() | ResultSetMetaData | Yes |
| setArray(int i, Array x) | void | No |
| setAsciiStream(int parameterIndex, InputStream x, int length) | void | Yes |
| setBigDecimal(int parameterIndex, BigDecimal x) | void | Yes |
| setBinaryStream(int parameterIndex, InputStream x, int length) | void | Yes |
| setBlob(int i, Blob x) | void | Yes |
| setBoolean(int parameterIndex, boolean x) | void | Yes |
| setByte(int parameterIndex, byte x) | void | Yes |
| setBytes(int parameterIndex, byte[] x) | void | Yes |
| setCharacterStream(int parameterIndex, Reader reader, int length) | void | Yes |
| setClob(int i, Clob x) | void | Yes |
| setDate(int parameterIndex, Date x) | void | Yes |
| setDate(int parameterIndex, Date x, Calendar cal) | void | Yes |
| setDouble(int parameterIndex, double x) | void | Yes |
| setFloat(int parameterIndex, float x) | void | Yes |
| setInt(int parameterIndex, int x) | void | Yes |
| setLong(int parameterIndex, long x) | void | Yes |
| setNull(int parameterIndex, int sqlType) | void | yes |
| setNull(int paramIndex, int sqlType, String typeName) | void | no |
| setObject(int parameterIndex, Object x) | void | Yes |
| setObject(int parameterIndex, Object x, int targetSqlType) | void | Yes |
| setObject(int parameterIndex, Object x, int targetSqlType, int scale) | void | Yes |
| setRef(int i, Ref x) | void | No |
| setShort(int parameterIndex, short x) | void | Yes |
| setString(int parameterIndex, String x) | void | Yes |
| setTime(int parameterIndex, Time x) | void | Yes |
| setTime(int parameterIndex, Time x, Calendar cal) | void | Yes |
| setTimestamp(int parameterIndex, Timestamp x) | void | Yes |
| setTimestamp(int parameterIndex, Timestamp x, Calendar cal) | void | Yes |
| setUnicodeStream(int parameterIndex, InputStream x, int length) | void | Yes |
| Methods: | Return Types: | Supported: |
Interface ResultSet |
| absolute(int row) | boolean | Yes |
| afterLast() | void | Yes |
| beforeFirst() | void | Yes |
| cancelRowUpdates() | void | Yes |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| deleteRow() | void | Yes |
| findColumn(String columnName) | int | Yes |
| first() | boolean | Yes |
| getArray(int i) | Array | No |
| getArray(String colName) | Array | Yes |
| getAsciiStream(int columnIndex) | InputStream | Yes |
| getAsciiStream(String columnName) | InputStream | Yes |
| getBigDecimal(int columnIndex) | BigDecimal | Yes |
| getBigDecimal(int columnIndex, int scale) | BigDecimal | Yes |
| getBigDecimal(String columnName) | BigDecimal | Yes |
| getBigDecimal(String columnName, int scale) | BigDecimal | Yes |
| getBinaryStream(int columnIndex) | InputStream | Yes |
| getBinaryStream(String columnName) | InputStream | Yes |
| getBlob(int i) | Blob | Yes |
| getBlob(String colName) | Blob | Yes |
| getBoolean(int columnIndex) | boolean | Yes |
| getBoolean(String columnName) | boolean | Yes |
| getByte(int columnIndex) | byte | Yes |
| getByte(String columnName) | byte | Yes |
| getBytes(int columnIndex) | byte[] | Yes |
| getBytes(String columnName) | byte[] | Yes |
| getCharacterStream(int columnIndex) | Reader | Yes |
| getCharacterStream(String columnName) | Reader | Yes |
| getClob(int i) | Clob | Yes |
| getClob(String colName) | Clob | Yes |
| getConcurrency() | int | Yes |
| getCursorName() | String | Yes |
| getDate(int columnIndex) | Date | Yes |
| getDate(int columnIndex, Calendar cal) | Date | Yes |
| getDate(String columnName) | Date | Yes |
| getDate(String columnName, Calendar cal) | Date | Yes |
| getDouble(int columnIndex) | double | Yes |
| getDouble(String columnName) | double | Yes |
| getFetchDirection() | int | Yes |
| getFetchSize() | int | Yes |
| getFloat(int columnIndex) | float | Yes |
| getFloat(String columnName) | float | Yes |
| getInt(int columnIndex) | int | Yes |
| getInt(String columnName) | int | Yes |
| getLong(int columnIndex) | long | Yes |
| getLong(String columnName) | long | Yes |
| getMetaData() | ResultSetMetaData | Yes |
| getObject(int columnIndex) | Object | Yes |
| getObject(int i, Map map) | Object | No |
| getObject(String columnName) | Object | Yes |
| getObject(String colName, Map map) | Object | No |
| getRef(int i) | Ref | No |
| getRef(String colName) | Ref | No |
| getRow() | int | Yes |
| getShort(int columnIndex) | short | Yes |
| getShort(String columnName) | short | Yes |
| getStatement() | Statement | Yes |
| getString(int columnIndex) | String | Yes |
| getString(String columnName) | String | Yes |
| getTime(int columnIndex) | Time | Yes |
| getTime(int columnIndex, Calendar cal) | Time | Yes |
| getTime(String columnName) | Time | Yes |
| getTime(String columnName, Calendar cal) | Time | Yes |
| getTimestamp(int columnIndex) | Timestamp | Yes |
| getTimestamp(int columnIndex, Calendar cal) | Timestamp | Yes |
| getTimestamp(String columnName) | Timestamp | Yes |
| getTimestamp(String columnName, Calendar cal) | Timestamp | Yes |
| getType() | int | Yes |
| getUnicodeStream(int columnIndex) | InputStream | Yes |
| getUnicodeStream(String columnName) | InputStream | Yes |
| getWarnings() | SQLWarning | Yes |
| insertRow() | void | Yes |
| isAfterLast() | boolean | Yes |
| isBeforeFirst() | boolean | Yes |
| isFirst() | boolean | Yes |
| isLast() | boolean | Yes |
| last() | boolean | Yes |
| moveToCurrentRow() | void | Yes |
| moveToInsertRow() | void | Yes |
| next() | boolean | Yes |
| previous() | boolean | Yes |
| refreshRow() | void | Yes |
| relative(int rows) | boolean | Yes |
| rowDeleted() | boolean | Yes |
| rowInserted() | boolean | Yes |
| rowUpdated() | boolean | Yes |
| setFetchDirection(int direction) | void | Yes |
| setFetchSize(int rows) | void | Yes |
| updateAsciiStream(int columnIndex, InputStream x, int length) | void | Yes |
| updateAsciiStream(String columnName, InputStream x, int length) | void | Yes |
| updateBigDecimal(int columnIndex, BigDecimal x) | void | Yes |
| updateBigDecimal(String columnName, BigDecimal x) | void | Yes |
| updateBinaryStream(int columnIndex, InputStream x, int length) | void | Yes |
| updateBinaryStream(String columnName, InputStream x, int length) | void | Yes |
| updateBoolean(int columnIndex, boolean x) | void | Yes |
| updateBoolean(String columnName, boolean x) | void | Yes |
| updateByte(int columnIndex, byte x) | void | Yes |
| updateByte(String columnName, byte x) | void | Yes |
| updateBytes(int columnIndex, byte[] x) | void | Yes |
| updateBytes(String columnName, byte[] x) | void | Yes |
| updateCharacterStream(int columnIndex, Reader x, int length) | void | Yes |
| updateCharacterStream(String columnName, Reader reader, int length) | void | Yes |
| updateDate(int columnIndex, Date x) | void | Yes |
| updateDate(String columnName, Date x) | void | Yes |
| updateDouble(int columnIndex, double x) | void | Yes |
| updateDouble(String columnName, double x) | void | Yes |
| updateFloat(int columnIndex, float x) | void | Yes |
| updateFloat(String columnName, float x) | void | Yes |
| updateInt(int columnIndex, int x) | void | Yes |
| updateInt(String columnName, int x) | void | Yes |
| updateLong(int columnIndex, long x) | void | Yes |
| updateLong(String columnName, long x) | void | Yes |
| updateNull(int columnIndex) | void | Yes |
| updateNull(String columnName) | void | Yes |
| updateObject(int columnIndex, Object x) | void | Yes |
| updateObject(int columnIndex, Object x, int scale) | void | Yes |
| updateObject(String columnName, Object x) | void | Yes |
| updateObject(String columnName, Object x, int scale) | void | Yes |
| updateRow() | void | Yes |
| updateShort(int columnIndex, short x) | void | Yes |
| updateShort(String columnName, short x) | void | Yes |
| updateString(int columnIndex, String x) | void | Yes |
| updateString(String columnName, String x) | void | Yes |
| updateTime(int columnIndex, Time x) | void | Yes |
| updateTime(String columnName, Time x) | void | Yes |
| updateTimestamp(int columnIndex, Timestamp x) | void | Yes |
| updateTimestamp(String columnName, Timestamp x) | void | Yes |
| wasNull() | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface ResultSetMetaData |
| getCatalogName(int column) | String | Yes |
| getColumnClassName(int column) | String | No |
| getColumnCount() | int | Yes |
| getColumnDisplaySize(int column) | int | Yes |
| getColumnLabel(int column) | String | Yes |
| getColumnName(int column) | String | Yes |
| getColumnType(int column) | int | Yes |
| getColumnTypeName(int column) | String | Yes |
| getPrecision(int column) | int | Yes |
| getScale(int column) | int | Yes |
| getSchemaName(int column) | String | Yes |
| getTableName(int column) | String | Yes |
| isAutoIncrement(int column) | boolean | Yes |
| isCaseSensitive(int column) | boolean | Yes |
| isCurrency(int column) | boolean | Yes |
| isDefinitelyWritable(int column) | boolean | Yes |
| isNullable(int column) | int | Yes |
| isReadOnly(int column) | boolean | Yes |
| isSearchable(int column) | boolean | Yes |
| isSigned(int column) | boolean | Yes |
| isWritable(int column) | boolean | Yes |
| Methods: | Return Types: | Supported: |
Interface Statement |
| addBatch(String sql) | void | Yes |
| cancel() | void | No |
| clearBatch() | void | Yes |
| clearWarnings() | void | Yes |
| close() | void | Yes |
| execute(String sql) | boolean | Yes |
| executeBatch() | int[] | Yes |
| executeQuery(String sql) | ResultSet | Yes |
| executeUpdate(String sql) | int | Yes |
| getConnection() | Connection | Yes |
| getFetchDirection() | int | Yes |
| getFetchSize() | int | Yes |
| getMaxFieldSize() | int | Yes |
| getMaxRows() | int | Yes |
| getMoreResults() | boolean | Yes |
| getQueryTimeout() | int | Yes |
| getResultSet() | ResultSet | Yes |
| getResultSetConcurrency() | int | Yes |
| getResultSetType() | int | Yes |
| getUpdateCount() | int | Yes |
| getWarnings() | SQLWarning | Yes |
| setCursorName(String name) | void | no |
| setEscapeProcessing(boolean enable) | void | Yes |
| setFetchDirection(int direction) | void | no |
| setFetchSize(int rows) | void | no |
| setMaxFieldSize(int max) | void | Yes |
| setMaxRows(int max) | void | Yes |
| setQueryTimeout(int seconds) | void | Yes |
| Methods: | Return Types: | Supported: |
Interface Array |
No | |
Interface Struct |
No | |
Interface SQLOutput |
No | |
Interface SQLInput |
No | |
Interface SQLData |
No | |
Interface Ref |
No | |
Interface Driver |
Support but not to public |
Veeam ONE (24)
“Events” タブに表示されるのはどのようなイベントですか?
仮想マシンのスナップショット作成や削除、
仮想マシン自体の再構成や削除などといったイベント情報を一覧表示します。

モニターに表示するデータはどれくらいの間隔で取得しますか?
リアルタイムのデータは20秒間隔で取得して表示されます。
過去のデータを表示する場合には5分間隔または2時間間隔で表示されます。
Veeam ONEについての一般的な質問
Q: Veeam ONEでvSphere とHyper-Vのフリー版はモニターできますか?
はい。
Q: モニターできるホストとVM数は?
Veeam ONEは管理できるホストとVM数の制限はありません。
Q: Veeam ONEはエージェントを必要としますか?
いいえ、Veeam ONEはエージェントを必要としない最新のAPI技術を使用しています。
Q: Veeam ONEのインストールには専用の物理サーバが必要ですか?
いいえ、Veeam ONEは物理でも仮想サーバでもディプロイが可能です。
Q:Veeam ONは仮想環境だけでなく、Veeam Backup & Replicationの監視もできますか?
はい、仮想環境だけでなくバックアップ環境も監視できます。
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
Hyper-V にも対応していますか?
はい、対応しております。
Veeam ONE をどの PC にインストールすればいいですか?
Windows PC を用意していただき、そこに Veeam ONE をインストールします。
Veeam ONE をインストールした PC から VMware vsphere ESX(i)、VMware vSphere Hypervisor(ESXi フリー版)、Microsoft Hyper-V に接続して仮想マシンのモニタリングを行います。
ESX(i) や Hyper-V 上の仮想マシン(Windows)にもインストールできます。
Veeam ONE のインストール要件は?
Windows OS で Microsoft .NET Framework 以上が必要です。
Veeam ONE を仮想マシンにインストールすることは可能ですか?
はい、可能です。仮想マシンでもインストール要件を満たしていれば問題ありません。
エージェント導入が必要ですか?
いいえ、ユーザが ESX(i)、Hyper-V、仮想マシンにエージェントを導入する必要はありません。
Linux 系 OS の仮想マシンのモニタリング・レポートは可能ですか?
はい、対応しています。
他には Windows、Unix、FreeBSD、Solaris、Mac OS がモニタリング可能です。
ライセンス体系はどのようになっていますか?
接続する ESX(i)、Hyper-V の CPU ソケット数分のライセンスが必要となります。
CPU ソケット数がわかりません。
vSphere Client から ESX に接続して「サマリ」タブのプロセッサソケットをご確認ください。

CPU ソケットごとのコア数はライセンスに影響しますか?
いいえ、影響しません。ライセンス数はCPUソケット数のみに依存します。
https://www.climb.co.jp/soft/veeam/outline/price.html
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから30日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間をいただく場合がございます。
予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
VMware 環境の場合
1. Veeam ONE インストール用の Windows 系サーバ(仮想マシンでも可)
2. VMware vSphere ESX(i) または VMware vSphere Hypervisor(ESXi フリー版)
Hyper-V 環境の場合
1. Microsoft Windows Server または Microsoft Hyper-V Server
※インストールするサーバについては、システム要件をご確認ください。
※インストールや設定方法については、インストールマニュアルをご確認ください。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
電話サポートは24時間対応ですか?
電話での対応は営業時間内(10:00~18:00)です。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
ソフトのメニュー類は日本語には未対応です。
しかし、製品の操作マニュアルや、Veeam ONEによって提供されているレポートの説明などのマニュアルが日本語で用意されておりますので、問題なく使用可能です。
また、Veeam ONEによって提供されているアラートに付随するナレッジベースはシンプルな英語で作成されておりますし、コピー&ペーストすることもできますので、翻訳ソフトを使用していただくことで十分、内容は理解できるかと思います。
導入支援は行っていますか?
別料金となりますが、弊社にて設計・インストール・設定を行います。
製品には初年度保守が含まれますか?
はい、含まれます。
Veeam 製品と vCneter Server を同じマシンにインストールする際に注意点はありますか?
Veeam Reporter はマイクロソフトの IIS(インタ-ネットインフォメ-ションサ-ビス) と連携して動作します。
IIS(インタ-ネットインフォメ-ションサ-ビス) を有効にしているマシンに vCenter Server をインストールするとポート番号の重複が発生します。
Veeam ONE -導入・製品 (7)
Hyper-V にも対応していますか?
はい、対応しております。
Veeam ONE をどの PC にインストールすればいいですか?
Windows PC を用意していただき、そこに Veeam ONE をインストールします。
Veeam ONE をインストールした PC から VMware vsphere ESX(i)、VMware vSphere Hypervisor(ESXi フリー版)、Microsoft Hyper-V に接続して仮想マシンのモニタリングを行います。
ESX(i) や Hyper-V 上の仮想マシン(Windows)にもインストールできます。
Veeam ONE のインストール要件は?
Windows OS で Microsoft .NET Framework 以上が必要です。
Veeam ONE を仮想マシンにインストールすることは可能ですか?
はい、可能です。仮想マシンでもインストール要件を満たしていれば問題ありません。
エージェント導入が必要ですか?
いいえ、ユーザが ESX(i)、Hyper-V、仮想マシンにエージェントを導入する必要はありません。
Linux 系 OS の仮想マシンのモニタリング・レポートは可能ですか?
はい、対応しています。
他には Windows、Unix、FreeBSD、Solaris、Mac OS がモニタリング可能です。
Veeam 製品と vCneter Server を同じマシンにインストールする際に注意点はありますか?
Veeam Reporter はマイクロソフトの IIS(インタ-ネットインフォメ-ションサ-ビス) と連携して動作します。
IIS(インタ-ネットインフォメ-ションサ-ビス) を有効にしているマシンに vCenter Server をインストールするとポート番号の重複が発生します。
Veeam ONE -ライセンス (3)
ライセンス体系はどのようになっていますか?
接続する ESX(i)、Hyper-V の CPU ソケット数分のライセンスが必要となります。
CPU ソケット数がわかりません。
vSphere Client から ESX に接続して「サマリ」タブのプロセッサソケットをご確認ください。
CPU ソケットごとのコア数はライセンスに影響しますか?
いいえ、影響しません。ライセンス数はCPUソケット数のみに依存します。
https://www.climb.co.jp/soft/veeam/outline/price.html
Veeam ONE -評価 (4)
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから30日間となります。
評価中のサポートは受けられますか?
はい、ご利用いただけます。
質問の内容により、お時間をいただく場合がございます。
予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
VMware 環境の場合
1. Veeam ONE インストール用の Windows 系サーバ(仮想マシンでも可)
2. VMware vSphere ESX(i) または VMware vSphere Hypervisor(ESXi フリー版)
Hyper-V 環境の場合
1. Microsoft Windows Server または Microsoft Hyper-V Server
※インストールするサーバについては、システム要件をご確認ください。
※インストールや設定方法については、インストールマニュアルをご確認ください。
Veeam ONE -購入サポート (8)
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
電話サポートは24時間対応ですか?
電話での対応は営業時間内(10:00~18:00)です。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語対応していますか?
ソフトのメニュー類は日本語には未対応です。
しかし、製品の操作マニュアルや、Veeam ONEによって提供されているレポートの説明などのマニュアルが日本語で用意されておりますので、問題なく使用可能です。
また、Veeam ONEによって提供されているアラートに付随するナレッジベースはシンプルな英語で作成されておりますし、コピー&ペーストすることもできますので、翻訳ソフトを使用していただくことで十分、内容は理解できるかと思います。
導入支援は行っていますか?
別料金となりますが、弊社にて設計・インストール・設定を行います。
製品には初年度保守が含まれますか?
はい、含まれます。
Veeam ONE -機能 (4)
“Events” タブに表示されるのはどのようなイベントですか?
仮想マシンのスナップショット作成や削除、
仮想マシン自体の再構成や削除などといったイベント情報を一覧表示します。
モニターに表示するデータはどれくらいの間隔で取得しますか?
リアルタイムのデータは20秒間隔で取得して表示されます。
過去のデータを表示する場合には5分間隔または2時間間隔で表示されます。
Veeam ONEについての一般的な質問
Q: Veeam ONEでvSphere とHyper-Vのフリー版はモニターできますか?
はい。
Q: モニターできるホストとVM数は?
Veeam ONEは管理できるホストとVM数の制限はありません。
Q: Veeam ONEはエージェントを必要としますか?
いいえ、Veeam ONEはエージェントを必要としない最新のAPI技術を使用しています。
Q: Veeam ONEのインストールには専用の物理サーバが必要ですか?
いいえ、Veeam ONEは物理でも仮想サーバでもディプロイが可能です。
Q:Veeam ONは仮想環境だけでなく、Veeam Backup & Replicationの監視もできますか?
はい、仮想環境だけでなくバックアップ環境も監視できます。
Database Performance Analyzer (40)
スパイクを超えた、異常ベースのデータベース監視の深化化
データベース管理者は、データベースのパフォーマンスにおけるスパイクに注目しがちです。これは問題のある動作を特定する良い方法ですが、動作のスパイクを分析することだけがパフォーマンスの変化を示す指標ではありません。実際、ほとんどの実稼働データベースでは、パフォーマンスの変動は正常であり、予期されるべきものです。データベース管理者は、予想される変動を考慮し、予期しないものを呼び出す方法を必要としています。
Database Performance Analyzer(DPA)のスマートなSQLデータベース異常検知は、スパイクを越えて、予想される変動を考慮し、何か予期せぬことが起きたときに指摘することができます。この異常検知ツールは、そのような事象をハイライト表示し、標準から逸脱した事態を知るための複数の方法を提供します。
異常検知ツールでデータベースの待ち時間動作パターンを自動学習
狭い知識に頼っていると、新しい人がそれを習得するのは難しいです。また、大規模な環境では、深く広く理解することができない場合もあります。狭い知識の必要性を排除し、Database Performance Analyzer(DPA)の機械学習アルゴリズムに正常な動作パターンの「理解」の自動化を任せましょう。重要なリソースが異動したときに知識が流出しないように、知識を自動化して保持し、チーム全員の利益につなげます。
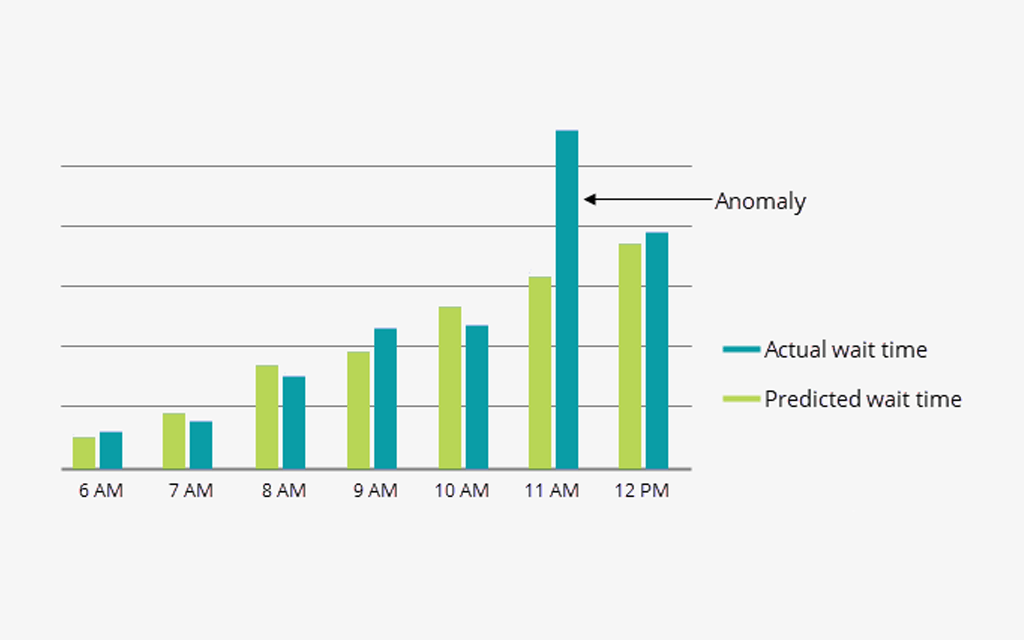
DPAの機械学習アルゴリズムは、時間の経過とともに賢くなるように設計されており、より多くのデータを収集することで予測精度を向上させます。
Database Performance Analyzer (DPA)の各種あるある機能
●Database Performance Analyzer (DPA) は、最も複雑なデータベース・パフォーマンスの問題を発見し解決するために設計されています。
●Database Performance Analyzer (DPA)データベースのパフォーマンスに問題がある箇所を一目で確認でき、さらに詳細な情報を得るために簡単に移動することができます。DPAは、単一のインストールで、すべての主要なデータベース・システムでこれを実現できます。
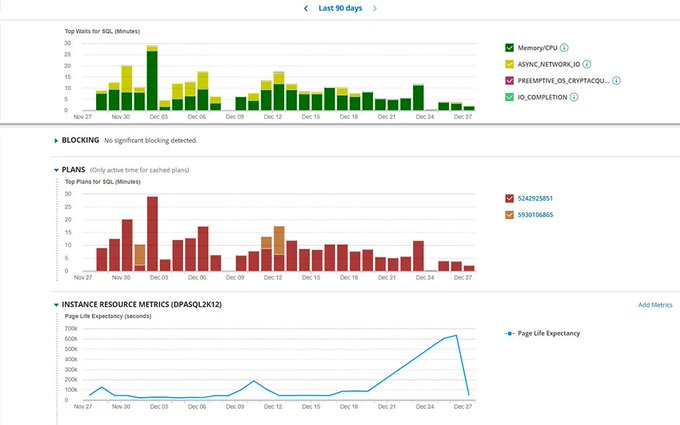
●Database Performance Analyzer (DPA) を使用して、最もリソースを消費し、最も問題を引き起こしているSQLに焦点を当てれば、SQL文のチューニングは容易になります。グラフの各色は、個別のSQLステートメントを表します。
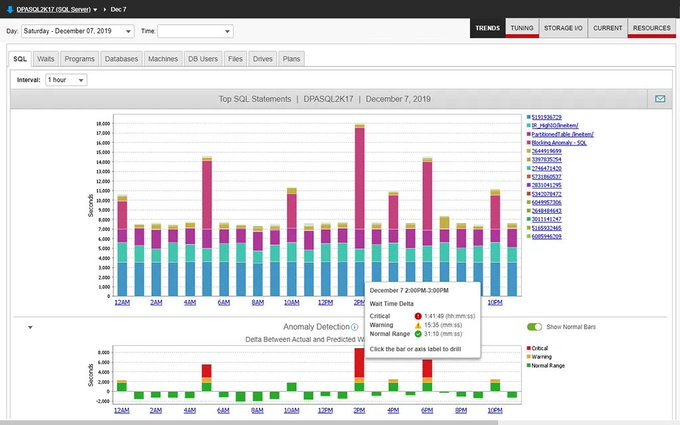
●Database Performance Analyzer (DPA)は、SQL文のテキストをドリルダウンして詳細を確認することも可能です。

●Database Performance Analyzer (DPA)のダイナミックベースラインでは、詳細なメトリクスと数年にわたる履歴を表示し、長期にわたる完全なパフォーマンスストーリーを物語るトレンドとパターンを確認することができます。

Database Performance Analyzerの総合満足度(ユーザ3の声)
使用例と導入範囲
当社では、Database Performance Analyzerを使用して、データベース全体の健全性におけるプロアクティブなパフォーマンス監視と異常検出を行っています。この製品によって、データベースパフォーマンスの全体像を初めて見ることができます。また、アラートとメール通知を設定することで、時間を大幅に節約しています。私たちが最もよく使うケースは、実行プランの変更に対応し、システムのエンドユーザーがパフォーマンスの問題や応答時間について不満を持ち始める前に適切な措置を取ることです。
長所と短所
(+)機械学習による異常検知 – バージョン12の新機能で、統計的分析が非常に便利です。
(+)日次と年次で作業量を比較することで、成長の全体像を把握し、キャパシティを考慮することができます。
(+)直感的なパフォーマンス分析 – 問題点を簡単に調べ、根本的な原因を見つけることができます。
(-)過去2回のバージョン12.0と12.1では、ソーラーウインドは素晴らしい機能拡張を行いました。現在、変更してほしいところはありません。ユーザー・インターフェースに多少の美観はありますが、問題だとは思っていません。
投資対効果
●定量的なデータは提供できませんが、実際にプラスの影響を与えた例をいくつか挙げることができます。
●インターネットバンキングのアプリケーションで、思うように動作しない点がいくつかありました。DPAを使用して、最も重いSQLクエリを特定し、ベンダーに変更依頼を開始しました。変更後、レスポンスタイムを1桁短縮することができました。
Database Performance Monitorのチューニング
私たちの組織では、テーブル・チューニング・アドバイザーを使って、ある MS SQL サーバーの統計情報を追加で作成しました。
ベストバリュー
環境のアップグレードの支援(該当する場合) – 私たちは、製品のバージョンからバージョンへのアップグレードを何度も行いました。一度だけ問題が発生しましたが、非常に迅速に修正されました。実は、その問題に対して私が推薦したのですが、彼らは最初に回避策を与えてくれました。全体的にとても満足しています。
Database Performance Analyzerの総合満足度(ユーザ1の声)
使用例と導入範囲
アラートを利用して問題を未然に防いでいます。パフォーマンスデータを使って問題を診断し、解決しています。ダッシュボードとドリルダウンを使って、現在の状況を把握し、うまくいっているかどうかを確認します。全体的なレスポンスタイムの急上昇や急降下を監視し、ユーザが体験しているUXの原因を理解しようとしています。
長所と短所
(+)この製品は、管理やパフォーマンスチューニングに必要なデータを、数秒で理解できるように可視化することに優れています。OracleのようなデータベースにはAWRレポートがあり、何ページもあり、すべてテキストで、読みにくいです。SQL Serverには動的な管理ビューがありますが、良いものですが簡単にアクセスできません。 Database Performance Analyzer (DPA)は、このようなレポートをすばやく理解し、実行できるようにレイアウトします。
(+)DPAは、実際に何が起こっているのかを教えてくれます。
例:開発者は、このストアドプロシージャはこのRDBMSでは非常に遅く実行されるが、別のRDBMSでは電光石火のように実行されると述べています。チューニングを試みたが効果がなかった。
そこで、DPAで数分かけて状況を調査したところ、ストアドプロシージャは正常に動作していることがわかりました。その代わり、アプリケーションがプロックに関するメタデータにアクセスしようとする際に、速度が低下していることがわかりました。その結果、メタデータをキャッシュするようになり、今では「遅い」プロックが快調に動作しています。DPAがなければ、微調整すべき正しいコードを探すのに長い時間がかかっていたでしょう。
(+)内蔵のアラート機能を使って、カスタムアラートを作成できるのは素晴らしいことです。カスタムアラートは、監視しているデータベースや、DPAが収集したデータから、OS、ストレージ、ネットワークなど、関連する部分まで情報を収集することができます。
(-)素晴らしい製品で、ほとんどのことがうまくいっています。必要な情報に少ないクリックでアクセスできるように、UIを改善し続けて欲しいと思います。
(-)DPAの競合他社が持っている機能で便利そうなのは、ジョブの実行時間をマッピングして、問題が発生したときに時間単位でマッピングできるようにすることです。
投資対効果
●問題発生時に対応するのではなく、問題を未然に防ぐことができるのは貴重なことです。顧客サービスのレベルも格段に上がりました。
●私が別の機会を求めて退職することを聞いた開発部の不機嫌な部長は、「今までいた最高のDBAをどうして手放すんだ」と上司を叱咤激励しました。 Database Performance Analyzerを使って提供できるサービスのレベルが、私が優れたDBAになるのに役立ちました。
Database Performance Analyzerの貴重な洞察
あるデータベースサーバーで、サードパーティの製品を使用していました。DPAのバーチャートは、1つのSQL文による多くの待ち時間を表していました。その文は実行に数ミリ秒しかかかりませんが、1日に数百万回実行されていました。どうしてその文がそんなに頻繁に実行されなければならないのか?私の上司の上司が、そのデータベースを作成している会社のオーナと知り合いで、私が見つけたものを送ってくれたのです。そして修正してもらったのです。
Database Performance Monitor のチューニング
[Table Tuning Advisors]は、全体的なガイダンスを与えてくれます。しかし、Query Advisorsは、しばしば特定の提案インデックスを持ち、それをコードウィンドウにコピー&ペーストするだけで、多くのことができます。私はしばしば、実行する前にそれらを微調整し、一部は役立ちませんでしたが、全体として、それらはパフォーマンスにとって非常に有用でした。大きなテーブルで適切なインデックスを使用すると、パフォーマンスが文字通り何百倍も、時には3,000%も向上することがあるのです。
仮想化データベース
そのためには、問題があなたのVMにあるのか、それともホストにあるのかを理解する必要があります。サーバ管理者とオーバープロビジョニングについて議論する必要があるのか、それともデータベースサーバーのVM内でよりコントロールできる問題なのかを?
DPAの1週間あたりの時間節約額
一人当たり週0-4時間の時間節約 :アラートがないと、反応モードで時間を浪費し、顧客のエクスペリエンスが損なわれます。分析と棒グラフがなければ、問題を診断して修正するために時間を浪費することになります。何度もクエリーを実行する必要がある場合、全体像を一目で把握することができず、時間を浪費してしまいます。
推薦する可能性
管理するインスタンスが何十台もある場合、ダッシュボードはとても便利です。履歴が残るので、昨日や週末に起こった問題を診断したり、毎日同じ時間に起こるのか、毎週同じ曜日に起こるのか、などのパターンを確認することができます。
DPAの待ち時間(Wait-based)を利用した分析
従来のデータベース監視ツールは、データベースの健全性指標に着目して、パフォーマンス問題のトラブルシューティングを行います。DBA(DB管理者) は、これらの指標を改善するために何時間もかけてデータベースをチューニングしますが、その変更がパフォーマンスにほとんど影響を与えないことに気付くことがあります。
DPA(Database Performance Analyzer)は、データベースの健全性指標の代わりに、アプリケーションとエンドユーザーの待ち時間に注目します。DPAは、待ち時間が最も長い場所をグラフィカルに表示し、待ち時間が予想より長い時間帯(異常)も特定します。パフォーマンス問題の根本原因を掘り下げることができ、その修正方法に関するアドバイスを得ることができます。DPAを使用して、長い待ち時間の直接の原因となっている問題を発見し修正すれば、注目されるパフォーマンス改善を実現することができます。
DPAのホームページを使用して、待ち時間の長いデータベースインスタンスや異常なインスタンスを素早く特定し、ドリルダウンして詳細を確認することができます。
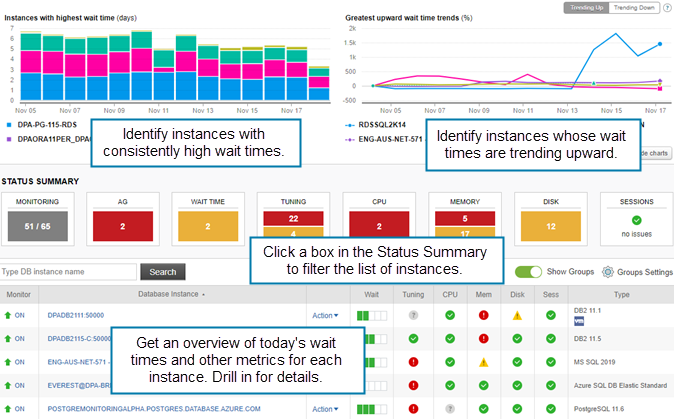
DPAのクエリー・パフォーマンス解析
クエリのパフォーマンス問題の根本原因を調査するために、DPAはクエリに関する最も関連性の高いデータをインテリジェントに収集し、「クエリの詳細」ページに表示します。この情報を使用して、次のことを行います。
●パフォーマンスに影響を及ぼしている待機の種類を確認し、各待機の種類に関する詳細情報および推奨事項を表示します。
●クエリおよびテーブルのチューニングアドバイザーを確認する
●統計およびメトリックスチャートで、クエリ待ち時間と他のイベントとの関連性を調べることができます。
DPAは、主な待ちの種類やその他の情報をもとに、最も関連性の高い統計、ブロッキング、プラン、メトリクスチャートを自動的に選択します。これらのチャートを表示するためにスクロールダウンしても、「トップウェイト」チャートは表示されたままなので、同じ時間帯の他のイベントとクエリ待ち時間を関連付けることができます。この情報は、複雑なパフォーマンス問題の根本原因を特定するために必要なコンテキストを提供します。
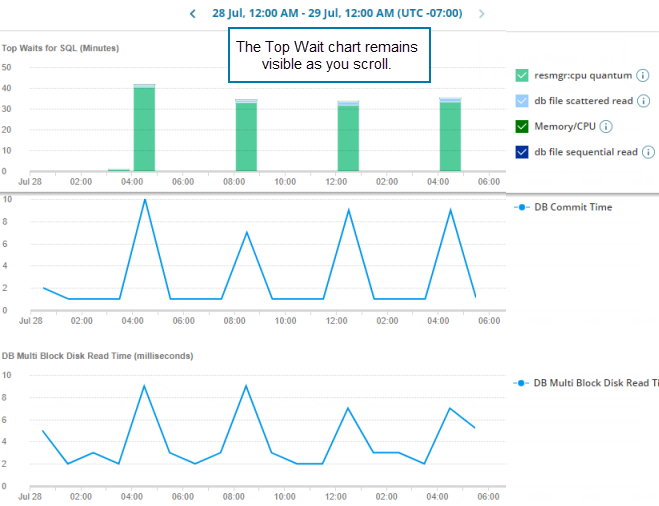
DPAのテーブル・チューニング・アドバイザー
非効率なクエリ、つまり、多くの行を読み取るが、返す行数は比較的少ないクエリのパフォーマンスを改善する方法を決定する際には、多くの要因を考慮する必要があります。DPAのテーブルチューニングアドバイザーは、十分な情報に基づいた意思決定を支援します。DPAは毎日、非効率的なクエリが実行されたテーブルを特定します。各テーブルについて、テーブル チューニング アドバイザー ページには、非効率的なクエリ、テーブル構造、および既存のインデックスに関する集約された情報が表示されます。こ の情報は、 次の よ う な質問に答 え る のに役立ち ます。
●クエリの計画をレビューする際に、どのステップに焦点を当てるべきか?
●このテーブルには現在いくつのインデックスが存在し、それらはどのようなものか?
●パフォーマンスを向上させるためにインデックスを追加することは可能か?
●統計は古くないか?
●テーブルのチャーン(挿入、更新、削除)はどの程度行われているか?
DPAの異常検知
DPAでは、異常検知アルゴリズムを用いて、予期せぬ待ち時間の増加を検知しています。ある期間では、待ち時間が多くても正常である場合があります。DPAは、過去のデータを使って正常な状態を「学習」し、そのデータに基づいて予測を行います。ある時間帯の待ち時間が予想より大幅に長い場合、DPAは異常を報告します。
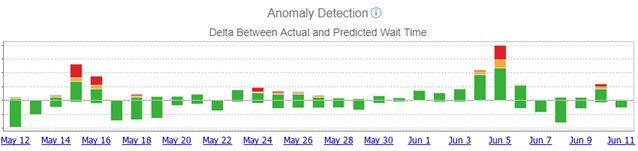
クラウドからオンプレミスへのPostgreSQLの適用範囲
PostgreSQLデータベースインスタンスは、Linux、Windows Server、VMware仮想マシン、クラウドプラットフォームのどこで実行しても、Database Performance Analyzer(DPA)でカバーすることができます。
PostgreSQLプラットフォームの広範なサポートは以下のとおりです。
- PostgreSQL
- EDB Postgres
- Azure Database for PostgreSQL
- Amazon RDS for PostgreSQL
- Amazon Aurora for PostgreSQL
- Google Cloud SQL for PostgreSQL
DPAのPostgreSQLデータベース管理へのハイブリッドアプローチは、エージェントレスアーキテクチャと1%未満のオーバーヘッドで、データベースパフォーマンスのチューニングと最適化への一面的なビューを提供します。
PostgreSQLの重要なメトリクスを可視化する
DPAは、24時間365日、秒単位のデータ収集により、ディスク、メモリ、ネットワークなどの主要なシステムメトリクスを含むPostgreSQL環境の広範なメトリクスを測定します。さらに、PostgreSQL固有の主要なメトリクスを簡単に利用できます。
キャッシュエビション
チェックポイント
レプリケーション
バキューム
行の操作
ライセンスコンプライアンス
これらの指標と、リアルタイムおよび履歴ビューを組み合わせることで、DBAはPostgreSQLのチューニング指標に簡単にアクセスすることができます。
機械学習+クエリアドバイザ=PostgreSQLの最適化
DPAの異常検知は、時間の経過とともに賢くなる機械学習をベースに、季節性を利用して何が正常で何が正常でないかを判断しています。この強力な機能により、DBAは意識していなかったものも含め、パフォーマンスの問題を通常数秒で発見することができます。
機械学習と高度な待ち時間解析の組み合わせにより、クエリが影響を受けている理由と場所を示し、従来の監視ソリューションでは実現できなかったPostgreSQLの最適化の可視性を提供します。
DPAは、パフォーマンス低下の原因を指摘するクエリアドバイザによる専門的なアドバイスによって、PostgreSQLのチューニングをさらに一歩推し進めます。
PostgreSQL Azure、AWS、Googleの徹底チューニング
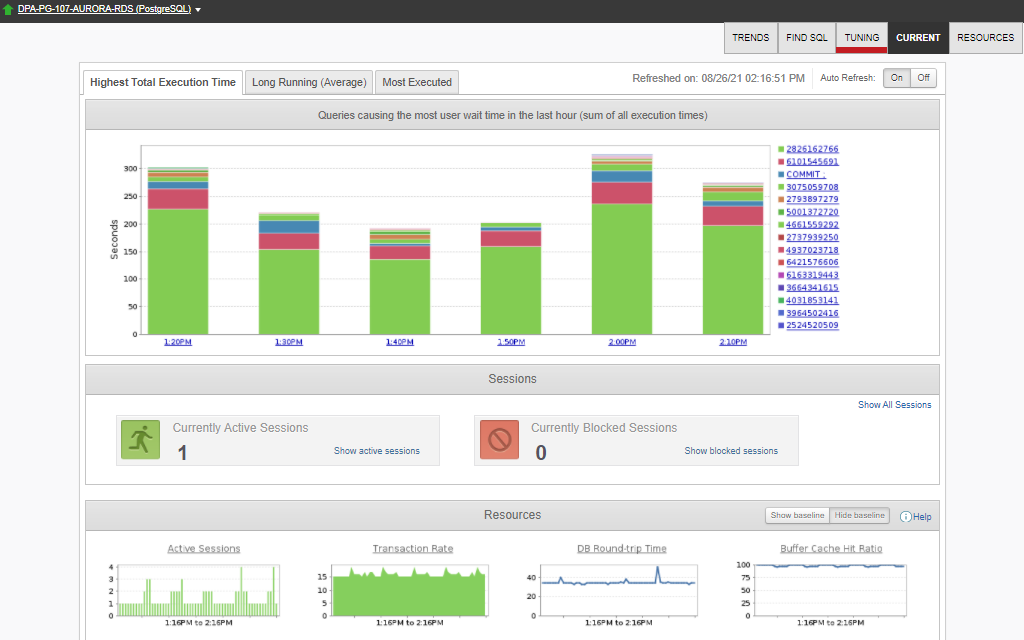
クラウドコンピューティングプラットフォーム上でPostgreSQLを実行する場合、パフォーマンスの最適化とチューニングが重要です。なぜなら、計算リソースの対価として、非効率的で不適切なクエリは、フロントエンドアプリケーションのパフォーマンスへの影響は言うまでもなく、コストにつながる可能性があるからです。
DPAは、PostgreSQLのパフォーマンス管理に対して、以下のような全体的なアプローチを提供します。
●リアルタイムおよびヒストリカルビュー
●24時間365日、秒単位のデータ収集が可能
●シンプルでエージェントレスな実装により、オーバーヘッドを1%未満に抑えることができます。
●ポストグレスに特化したレポート(アドホックまたはスケジュール型)
●機械学習による異常検知
●多角的なクエリ待ち時間分析
●問題箇所をピンポイントで特定するクエリアドバイザ
●システムおよびPostgreSQLの両方のメトリクス
●SQLテキストへのドリルダウンとライブプランの実行
●ドラッグ&ドロップでカスタマイズできるメールアラートテンプレート
●自動化統合のためのRESTful API
●DPAは、物理サーバーやVM、Azure、AWSのサービスとして実装することが可能
仮想化されたPostgreSQLの統合監視
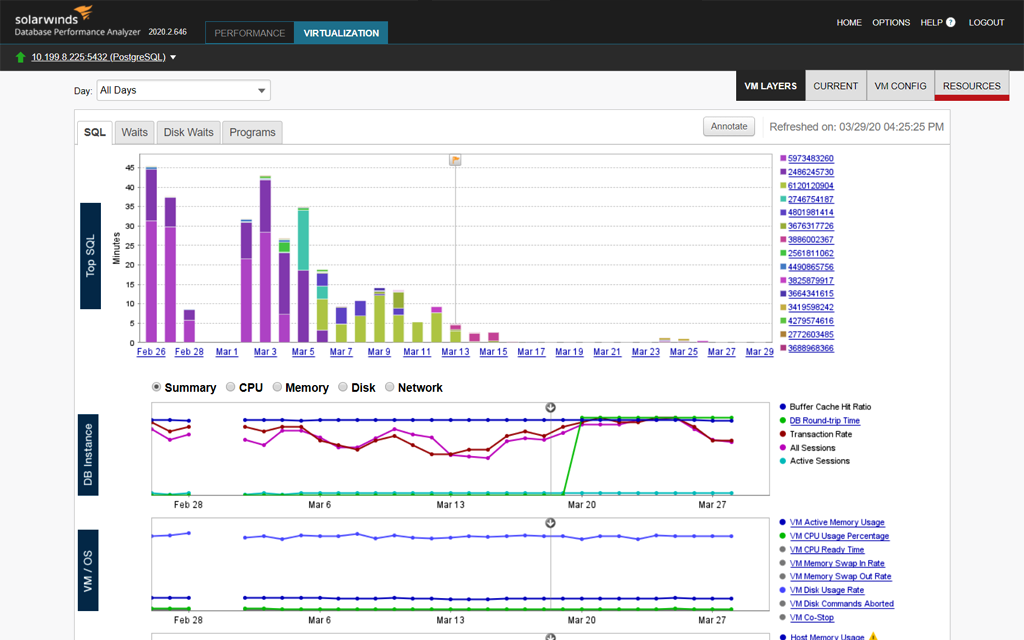
DBAは、PostgreSQLのパフォーマンスチューニングと分析に関して、しばしば指南役となります。誰かがアプリケーションのパフォーマンス低下について不満を漏らすと、データベースのバックエンドが最初に非難されることがよくあります。
しかし、PostgreSQLインスタンスがVMware仮想マシンで動作している場合はどうでしょうか。多くの場合、DBAはPostgreSQLインスタンスをサポートする仮想インフ ラの影響(もしあれば)を全く見ることができません。DPA VMオプションによる統合仮想化監視は、VMがPostgresの性能問題を引き起こしているかどうかを判断するために必要なデータをDBAに提供します。VMのメトリクスとデータベースのメトリクスを重ねた独自の「タイムスライス」ビューから、詳細なESXiホストのメトリクスまで、DBAはPostgreSQLインスタンスへの影響を判断するのに必要なデータを手に入れることができます。
Database Performance Analyzer vs. Database Performance Monitor
Database Performance Analyzer
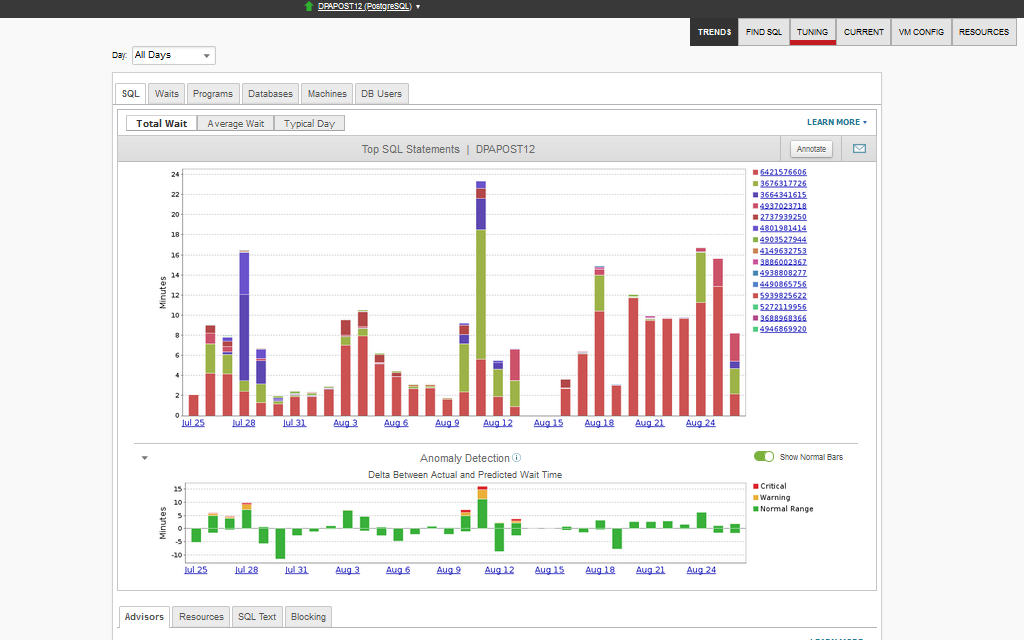
DBAは、複数のデータベースプラットフォームでより多くのデータベースインスタンスを管理する必要に迫られています。Database Performance Analyzer(DPA)を使用すれば、機械学習による異常検知や履歴およびリアルタイム分析などの機能により、数分でパフォーマンス問題をピンポイントで特定できる、データベースパフォーマンス管理への一貫したアプローチを手に入れることができます。
DPAの主な機能は以下のとおりです。
●専門家によるクエリーのアドバイス、ブロッキング、リソース利用による多次元クエリー分析
●カスタムアラート、メトリクス、レポーティング
●VMwareの監視と分析を統合
●シンプルでエージェントレスなインストールにより、オーバーヘッドを1%未満に抑えることが可能
●オンプレミス、Azure、Amazon(RDSおよびAurora)インスタンスを含む幅広いデータベースプラットフォームが対象
Database Performance Monitor
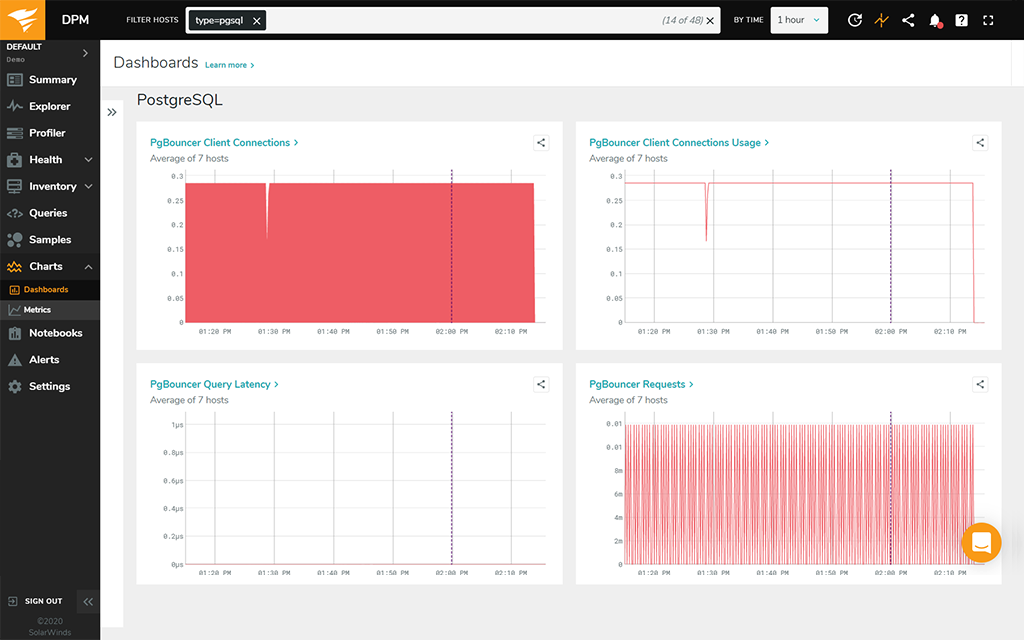
アプリケーションを所有する開発者、データベースのリアルタイムおよび過去の統計情報を必要とするSREやDBAは、すべて Database Performance Monitor(DPM)の恩恵を受けることができます。直感的なインターフェイスは、コードの展開とデータベースのパフォーマンス監視を行う部門横断的なチームの作業をサポートします。
DPMの主な機能は次のとおりです。
●パフォーマンスの前後を測定するための時間比較
●カスタムアラートとダッシュボード
●システムとデータベースの両方のメトリックスにより、全体的な健全性を洞察
●部門横断的なチーム向けに拡張性のあるSaaSプラットフォーム
●MySQL、MongoDB、Redis、Auroraなど、幅広いオープンソースデータベースプラットフォームをカバー
データベーススキーマの定義
データベーススキーマとは、リレーショナルデータベース全体の論理的、視覚的な構成のことである。データベースのオブジェクトは、テーブル、関数、リレーションとしてグループ化され表示されることが多い。スキーマは、データベース内のデータの構成と格納を記述し、さまざまなテーブル間の関係を定義します。データベーススキーマは、スキーマ図を通して描くことができるデータベースの記述的な詳細を含んでいます。
データベースのスキーマはどのように設計されているのですか?
データベース設計者は、プログラマーが効率的にデータベースを操作できるように、データベーススキーマを作成します。データベースを作成するプロセスは、データモデリングとして知られています。データベーススキーマを設計するためには、情報を収集し、それらをテーブル、行、列に並べる必要があります。情報を整理することで、理解しやすく、関連付けやすく、使いやすくする必要があります。
データベース・スキーマ設計とは?
データベーススキーマ設計は、データベースのアーキテクチャを開発するための設計図を提供することで、膨大な情報を体系的に格納することができる。また、データベースの構築に関わる戦略やベストプラクティスを指します。データベーススキーマ設計は、データを個別のエンティティに整理し、整理されたエンティティ間の関係を決定することによって、データの消費、解釈、取得をはるかに容易にします。
データベーススキーマの設計方法
データベーススキーマの設計は、データの書式が一貫していること、すべての項目が主キーを持つこと、重要なデータが除外されていないことを保証します。データベーススキーマは、視覚的なものと論理的なものがあり、データベースを管理するための公式のセットを含んでいます。開発者は、これらの公式とデータ定義を使用して、データベーススキーマを作成します。
最も一般的なデータベーススキーマの種類を以下に概説します。
階層的モデル: 階層型:ルートノードに子ノードが付随するツリー状の構造を持つデータベーススキーマを階層型という。このデータベーススキーマモデルは、家系図などのネストされたデータを格納することができる。
フラットモデル:フラットモデル: データを単次元または二次元の配列に整理したもので、行と列を持つスプレッドシートのようなモデル。このモデルは、複雑な関係を持たない単純なデータを表形式で整理するのに適している。
リレーショナルモデル:リレーショナルモデルは、データが表、行、列に整理されるフラットモデルに似ている。ただし、このモデルでは、異なるエンティティ間の関係を定義することができる。
スタースキーマ: スターデータベーススキーマは、データを「ディメンション」と「ファクト」に整理します。ディメンジョンには説明的なデータが含まれ、ファクトには数値が含まれる。
スノーフレークスキーマ: スノーフレーク(雪片)型データベーススキーマは、データベース内のデータを論理的に表現したものである。このタイプのスキーマの表現はスノーフレークに似ており、複数のディメンジョンが1つの集中ファクトテーブルにくっ付いている。
ネットワークモデル: ネットワークデータベーススキーマは、データを接続された複数のノードとして含みます。このモデルは、多対多の関係などの複雑な接続を可能にするため、特定のタスクを達成するために使用されます。
データベーススキーマ設計のベストプラクティス
データベーススキーマを最大限に活用するためのベストプラクティスを以下に紹介します。
セキュリティ: 効果的なデータベーススキーマの設計は、データセキュリティに重点を置く必要があります。また、ログイン情報、個人を特定できる情報(PII)、パスワードなどの機密データを保護するために、高度な暗号化を使用します。
名前の規則: スキーマ設計をより効果的にするために、データベースで適切な命名規則を定義することができます。テーブル、カラム、フィールド名には、複雑な名前、特殊文字、予約語を使用しないようにします。
正規化: 正規化とは、独立したエンティティやリレーションシップが、同じテーブルやカラムにまとめられないようにすることで、冗長性を排除するものです。これにより、データの整合性が向上し、開発者が情報を取得しやすくなります。また、正規化により、データベースのパフォーマンスを最適化することもできます。
ドキュメンテーション: データベーススキーマは、開発者とドキュメンテーションの作成にとって非常に重要です。データベーススキーマの設計は、説明書、コメント、スクリプトなどとともに文書化する必要があります。
データベースのスキーマには、大きく分けてどのような種類があるのでしょうか。
物理データベーススキーマ: 物理データベーススキーマは、データの物理的な配置と、ファイル、インデックス、キーと値のペアなどのストレージのブロックへの格納方法を表します。
論理データベーススキーマ:論理データベーススキーマはデータの論理的な表現を記述し、論理的な制約を伝達する。データはある種のデータレコードとして記述することができ、異なるデータ構造として格納される。ただし、データの実装などの内部的な詳細はこのレベルでは隠されている。
データベーススキーマは何に使うのですか?
データベーススキーマは、情報を体系的に整理するために設計された認知的な枠組みや概念です。スキーマがあれば、膨大な量の情報を素早く解釈することができる。未整理のデータベースは混乱しやすく、維持・管理も困難です。きれいで、効率的で、一貫性のあるデータベーススキーマの設計により、組織のデータを最大限に活用することができます。リレーショナルデータベースは、データの冗長性を排除し、データの不整合を防ぎ、データの検索と分析を容易にし、データの整合性を確保し、不正なアクセスからデータを保護するために、データベーススキーマ設計に大きく依存します。強力なテスト環境でデータをテーブルとカラムに整理することが極めて重要です。データの整合性を管理し、データベースとソースコードを更新する計画が必要です。
PostgreSQL パフォーマンス・チューニング
PostgreSQLは、新世代のエンタープライズアプリケーションのためのデータベースです。あなたのデータベースのパフォーマンス監視とチューニングのツールもエンタープライズクラスですか?
クライムとSolarWindsは、Confioからの10年以上に渡ってOracleとSQL Serverのユーザにソリューションを提供してきたため、データベースのパフォーマンス管理について多くのノウハウを持っています。ユーザの声に耳を傾けてユーザから学んでいます。そのため、現在ではオープンソースのデータベースを数多くサポートし、その数は増え続けています。
私たちは、性能監視、PostgreSQLクエリチューニング、I/Oチューニングなどに対応する2つのソリューションで、私たちの専門知識をPostgreSQLに提供します。
どちらもユーザをエンタープライズクラスとして大きく手助けします。
Database Performance Analyzer (DPA)は、Oracle、SQL Server、MySQL、その他を含む広範なデータベースプラットフォームをサポートします。PostgreSQLの深いクエリチューニングと分析に機械学習を組み合わせてエンドツーエンドのITパフォーマンス管理を実現します。
Database Performance Monitor (DPM)はPostgreSQL監視ソリューションで、開発者、SRE、DBAのいずれにも有用なSaaSベースのインターフェイスを提供します。DPMは、MySQL、MongoDB、Redisなどの主要なオープンソースデータベースのシステムおよびデータベースの監視と分析の両方を提供します。
DPAは2種類のアドバイザーを提供
●Query advisors [クエリアドバイザ]は、待ち時間の原因となっている待ちの種類、ステートメントが他のセッションによってブロックされていないか、実行プランにフルテーブルスキャンなどのコストのかかるステップが含まれていないかなど、特定のクエリのパフォーマンスを改善するのに役立つ情報を提供します。
●Table tuning advisors [テーブルチューニングアドバイザー]は、あるテーブルに対して非効率的なクエリが大量に実行された場合に生成されます。これらのアドバイザーは、テーブル、実行された非効率的なクエリ、および既存のインデックスに関する集約された情報を提供します。
DPA ホームページの [チューニング] 列には、データベース インスタンスで警告またはクリティカル ステータスのアドバイザが利用可能な場合、警告またはクリティカル アイコンが表示されます。この列の緑のチェックマークは、アドバイザーが存在しないか、すべてのアドバイザーが情報提供であることを示します。

データベースインスタンスのすべてのアドバイザーを表示する
データベースインスタンスのすべてのアドバイザーを表示するには、次のいずれかの操作を行い、[Tuning Advisors] ページを開きます。
●DPA ホームページから、[Tuning] 列のアイコンをクリックします。
●データベース インスタンスの情報を表示するためにドリルインした場合は、インスタンスの詳細ページの右上隅にある[Tuning]タブをクリックします。

Tuningタブの赤または黄色のバーは、CriticalまたはWarningアドバイザーが利用可能であることを示します。
Tuning Advisors ページには、最新のクエリおよびテーブル・チューニング・アドバイザーが表示されます。ページの上部にあるドロップダウン・メニューを使用して、以前の日付に生成されたアドバイザーを表示します。
DPAリソースメトリクスのベースラインについて
DPA の [Resources] タブでリソース メトリクスを表示しているとき、ベースラインを表示して、特定の期間の値を過去の基準値と比較することができます。ベースラインは、現在の値に対するコンテキストを提供します。ベースラインを大幅に上回ったり下回ったりするメトリック値は、チューニングや再設定が必要な領域を示している可能性があります。
ベースラインを計算する前に、少なくとも1日間モニタリングが有効でなければなりません。ベースラインは、モニタリングの日数が増えるほど、より代表的なものになります。
(注)ベースラインは、VMオプションで収集されたメトリクスでは利用できません。
ベースラインの表示/非表示
ベースラインは、選択した期間が1週間以下の場合に利用できます。デフォルトでは、ベースラインは表示されません。[Resource]タブの右上にある[Baselines]トグルスイッチをクリックすると、ベースラインの表示/非表示が切り替わります。

ベースラインを表示する場合(かつ期間が1週間以内の場合)、10%から90%の間の履歴値を網掛けで表示します。
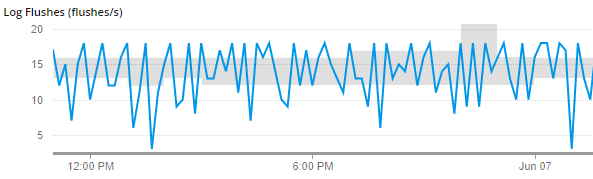
ベースラインはどのように計算されるのですか?
ベースラインは、1時間ごとに計算されます。デフォルトでは、ベースラインは平日(月~金)のデータのみを使用して計算されます。各ベースラインは、平日すべての対応する時間のデータを使用して計算されるため、特定の時間の値はすべての日にわたって同じになります。(例えば、午後1時から2時までは月曜日から金曜日まで同じ値です)。
ベースラインは、チャートに表示されている最も古い時間以前の履歴データを使用して計算されます。例えば、5月10日から始まる1週間のチャートの場合、すべてのベースラインは5月9日以前のデータを使って計算されます。このため、1週間チャートは日毎にパターンが繰り返されます。
ベースライン計算に含まれる日数を変更する
ベースライン計算に含まれる日数を変更するには、詳細オプションの 「METRICS_BASELINE_TYPICAL_HOUR_CALCULATION」 を編集します。このオプションは、グローバルまたは特定の監視対象データベースインスタンスに対して設定することができます。
以下の値のいずれかを選択してください。
●Weekday Only (M-F):平日(月~金)の対応する時間のデータを用いて、1時間ごとにベースラインを計算します。これはデフォルトです。
●All Days of the Week:ベースラインは、すべての日の対応する時間のデータを使用して、各1時間の期間について計算されます。
●Same Day of Week:各1時間の期間について、該当する日の該当する時間のデータを使用して計算されます。(例えば、月曜日の午後1-2時の値は、月曜日の対応する時間のデータを使用しており、したがって金曜日の午後1-2時の値とは異なります)。このオプションを選択すると、メトリックごとのベースラインの数が24から168に増えることに注意してください。
よりスマートなハードウェア投資とより良いビジネス上の意思決定
SSDドライブを買うべきか、より大きなサーバーを買うべきか?
Database Performance Analyzer(DPA)は、アプリケーションがディスクの読み書き、ネットワークの待ち時間、CPUの待ち時間、サスペンド状態や処理の妨げとなるアクティビティの待ち時間を正確に把握できるため、推測する必要がありません。これにより、アプリケーションのパフォーマンスを向上させるために投資する必要がある箇所や、新しいハードウェアが必要ない場合、コードやデータベース/システム構成の修正または改善によってボトルネックを解消できる箇所を把握することができます。
Database Performance Analyzerの総合満足度(ユーザ2の声)
使用例と導入範囲
データベースチームが、SQL ServerとAzure Databasesの両方で、データベースのパフォーマンスを監視し、チューニングするために使用しています。データベースの遅さ、Webサイトやサービス、アプリケーションでのタイムアウトは、データレイヤーが原因であることが多く、そのトラブルシューティングに最適なツールです。
長所と短所
(+)どのストアドプロシージャーのどのステートメントに作業が必要か、または致命的であるかを教えてくれる(該当する場合)。
(+)本当に作業が必要なものに注意を集中させることができ、非常に効率的です。
(-)監視するサーバーが多い場合、UIが不便になる。
(-)複数のサーバーにまたがる問題の順位付けができない。
投資に対するリターン
現在の勤務先ではなく、以前の勤務先での話です。データベースの変更を含む、大量のコードをデプロイしたことがありました。その翌日、そのデータベースサーバーに依存していたすべてのものがダウンし、サーバーはCPU、RAM、I/Oが100%になるまで叩かれました。何が問題なのかを正確に特定するのは非常に困難でしたが、Database Performance Analyzerを立ち上げて正確な問題を見つけるのにわずか数秒、そして問題のあった正確なprocにパッチを当てるのに1分もかかりませんでした。会社全体がビジネスに不可欠なサイトやツールからロックアウトされ、トレースやDMVなどの手段で問題を分析するのに何時間もかかったかもしれません。その代わり、ほとんど時間がかからなかった。
重大な動作の変化を警告するように設計された異常検出ツールを使用して、効果的なトラブルシューティングを行うことができます。
データベースの異常を検出することも重要ですが、24時間365日ダッシュボードを見続ける人はいないため、Database Performance Analyzer(DPA)は動作の変化を検出した際にアラートを送信することが可能です。感度を快適なレベルにカスタマイズしてノイズを減らし、DPAに監視を任せてください。
DPAはデータベースを常時監視し、動作の変化が検出されるとアラートを送信します。この異常検知ツールは、ワークロードのシフト、メンテナンスジョブの営業時間内実行、その他調査したい予期せぬ変化が発生したときに知らせることができます。
SQLデータベースの異常検知に利用可能な最新データを活用する
データベースの異常検知ツールは、そこに入力されるデータによってのみ、その性能が発揮されます。Database Performance Analyzer(DPA)は、24時間365日、異常ベースの監視を行い、機械学習アルゴリズムにより最新の洞察を提供します。30日以上監視が停止した場合、DPAのアルゴリズムは古いデータに基づいて予測を行うことはありません。代わりに、DPAは新しいデータから学習を開始し、3日後に最新のデータに基づいて再び予測を開始します。この機能により、異常検知の取り組みが最新の関連データのみによって裏付けられていることを確認することができます。
複数のデータベースタイプに対応した堅牢な異常検知ツールを利用する
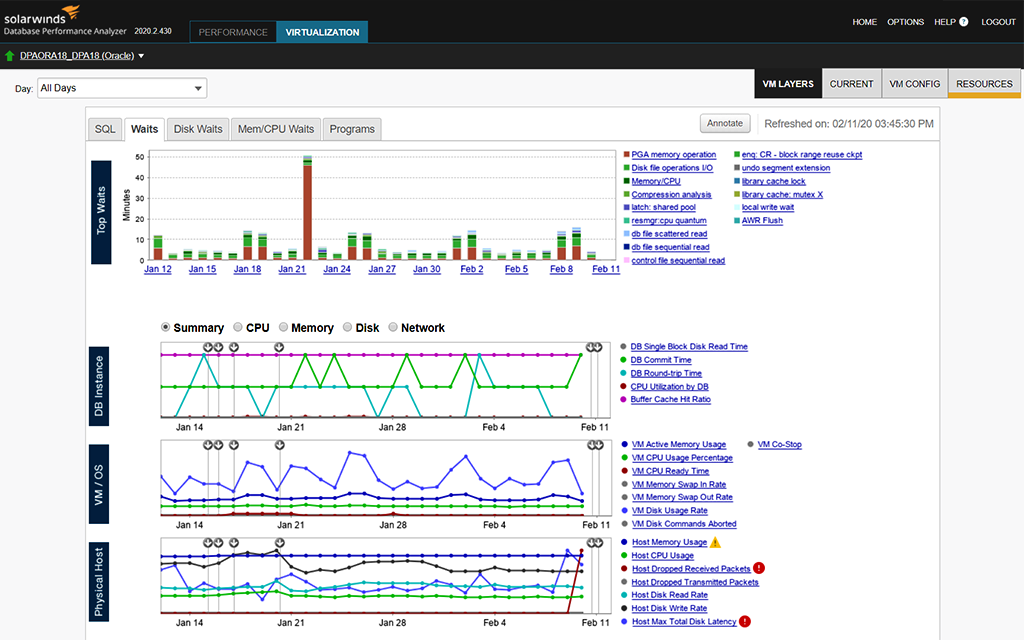
環境の大規模化・複雑化に伴い、データベース管理者は、様々な種類のデータベースを監視できる異常検知ツールを必要としています。Database Performance Analyzer(DPA)は、WindowsおよびLinuxサーバー上の仮想化、物理、クラウドベースのデータベースインスタンス、Azure、またはAWSサブスクリプションとして、1回のインストールで使用できる異常ベースのデータベース監視ツールを提供します。DPAの異常検知ツールは、Oracle、MySQL、Azure SQL Database、Microsoft SQL Serverなどをサポートするよう構築されています。また、DPAはVMオプションでVMware ESXiの可視化機能を統合しています。
1.データベース・パフォーマンスチューニングとは?
データベース・パフォーマンスチューニングは、データベース管理者がデータベースを可能な限り効率的に実行する方法を指す広義用語です。DBMSチューニングは、通常、MySQLやOracleなどの一般的なデータベース管理システムのクエリをチューニングすることを指します。
データベースのチューニングは、全体的なパフォーマンスを向上させるために、データベースシステムを上から下まで、ソフトウェアからハードウェアまで、再最適化することを支援します。このチューニングには、最適な使用方法に応じたオペレーティングシステムの再構成、クラスタの展開、システム機能とエンドユーザー体験をサポートする最適なデータベース性能への取り組みが含まれます。
2.SQLパフォーマンスチューニングとは何ですか?
SQLパフォーマンス・チューニングは、データベース・パフォーマンス・チューニングと似ていますが、より狭い範囲に限定されます。SQLパフォーマンス・チューニングは、リレーショナル・データベースが可能な限り効率的に動作するように設計されたベストプラクティスや手順のことを指します。これには主に、SQLクエリーとインデックスのチューニング、管理、および最適化が含まれます。
定期的な SQL パフォーマンス・チューニングは、SQL パフォーマンス問題の一般的な原因である非効率的なインデックスと SQL クエリに取り組む費用対効果の高い方法であり、リソースを再割り当てしてシステムを自助努力で使用することによって実現できます
3. データベースのパフォーマンスを向上させるにはどうすればよいですか?
ここでは、データベース全体のパフォーマンスを向上させるために役立つヒントをいくつか紹介します。
●インデックスが論理的なデータ構造を実装していることを確認し、データ検索プロセスをより効率的にする。
●コンピューティングシステムのメモリーの予備を再割り当てする。十分なメモリがない場合、データベースはしばしば最も大きな打撃を受けます。
●MySQLやOracleの最新版を使用していますか? データベースを最新に保つだけで、データベースのパフォーマンスが向上することがあります。
●ループのコーディングや相関性のあるSQLサブクエリのような一般的なSQLインデックスの落とし穴を避ける。
●データをデフラグすることで、データベースのスピードアップにつながるかもしれません。十分なディスク容量があることを確認する。
●効果的なデータベースチューニングとパフォーマンス監視は、洞察とピンポイントでのパフォーマンス最適化の推奨事項を提供するのに役立ちます。
4. データベースのチューニングはどのように行われるのでしょうか。
データベースのパフォーマンスチューニングのベストプラクティスに関して、ここでは簡単なチュートリアルを紹介します。
1)過去のデータを使って「正常」であることを確認し、データベースのベースラインに関する情報を収集します。ベースラインの指標を収集することで、データベースに何か異常があるかどうかを簡単に(そしてはるかに速く)確認することができます。
2)実行プランに目を通す。MySQL では、データベース管理者がクエリおよびデータベースのパフォーマンスを調査するためのさまざまな方法を提供しています。実行プランに目を通し、可能な限り効率的であることを確認します。
3)すべてのテーブル、インデックス、クエリに非効率性がないかを確認します。待ち時間の増加やインデックスのカラムアライメントを確認します。
4)ボトルネックを特定し、解消する。問題のあるSQLクエリとその原因を特定し、ボトルネックを解決する。
5)効果的な監視を実施する。非効率的なクエリは、データベースのパフォーマンス問題の主な原因であるため、データベースのチューニングの大部分はクエリパフォーマンスの監視に費やされます。たとえば、SolarWinds Database Performance Analyzerは待機ベースの分析機能を備えています。これは、時間関連の問題がデータベースパフォーマンスチューニングの最も顕著な問題点の1つであるためです。この方法は、データベースパフォーマンスチューニングの問題をより正確に切り分け、特定し、調査するのに役立ちます。
5. なぜデータベースのチューニングが重要なのか?
データベースクエリーの数ミリ秒の遅れは、あっという間に大きなボトルネックとなり、修正するのに長い時間がかかることがあります。データベースのチューニングが重要なのは、クエリの応答時間を数秒単位で短縮できるため、必要な情報を必要な場所にすばやく届けることができるからです。定期的なチューニングは、データベースパフォーマンスのベストプラクティスの重要な部分であり、アプリケーションのパフォーマンスを加速させる手っ取り早い方法となります。
6. データベースチューニングツールはどのように機能するのですか?
データベースチューニングツールは、通常データベースチューニングに時間がかかる手動プロセスの多くを自動化することによって、チューニングプロセスを容易にするように設計されています。
また、データベース・チューニング・ソフトウェアは、問題のある箇所を正確に把握できるため、クエリーやアプリケーションの中を探し回る必要がなく、効果的なトラブルシューティングの手段にもなります。見えない問題を解決することはできません。これらのツールは、データベースがどのように動作しているかを概観することができます
7. Database Performance Analyzer (DPA)でデータベースのチューニングはどのように行われるのですか?
Database Performance Analyzer (DPA)は、ユーザーがデータベースパフォーマンスの問題を監視、発見、解決できるように構築された、俊敏でスケーラブルなデータベースチューニングツールです。
DPAは、データベースアクティビティ、待機時間、SQLステートメント、アプリケーションリクエスト、およびその他のディメンションを相関させ、データベース速度低下の原因を正確に突き止めることができるように設計されています。 DPAでは、IBM DB2、SQL Server、SAP Adaptive Server Enterprise(SAP ASE)などの主要な商用データベースについて、SQLステートメントの迅速な分析、パフォーマンス問題の根本原因の特定、専門家のチューニングアドバイスを受けることも可能です。
Database Performance Analyzer (DPA):2024.3
Database Performance Analyzer (DPA)と の最新統合機能として、ServiceNow®とPagerDuty®を発表できることを嬉しく思います。この機能強化は、多くの要望に応えるもので、アラート通知を拡張し、IT運用をこれまで以上に効率的かつ迅速に行うことを可能にします。
DPAは、ServiceNow®とPagerDuty®に直接アラートを送信できるようになり、より効率的なワークフローが可能になりました。これにより、インシデントとイベントをより効果的に管理できるようになり、ITイベントの適切な通知、追跡、論理的なワークフローを確保できます。
動作方法
この統合により、SolarWinds Platform Connect 経由で SQL Sentry と DPA が貴社の ServiceNow® および PagerDuty® アカウントに接続されます。 設定が完了すると、DPA によって生成されたアラートは自動的にこれらのチャネルに送信され、IT チームはリアルタイム通知を受け取ることができ、問題が発生するとすぐに適切な優先順位付けと対処が行われるようになります。
統合のメリット
対応の迅速化:ServiceNow®とPagerDuty®にリアルタイムのアラートが送信されるため、チームはインシデントに迅速に対応でき、ダウンタイムを削減し、システムの信頼性を向上させることができます。
●インシデント管理の一元化:この統合により、すべてのITイベントを一元的に管理できるようになります。一元化によりワークフローが簡素化され、問題の追跡と解決が容易になります。
●業務の合理化:新しい統合により、適切なタイミングで適切な担当者にアラートが送信されることが保証されます。これにより、ITイベントやインシデントの優先順位付けと管理がより効果的に行われ、リソースが最適に利用されることが保証されます。
●すべてのサブスクリプション顧客が利用可能
この機能は、追加費用なしで、すべてのサブスクリプション顧客が利用可能です。これは、お客様のITインフラストラクチャを効率的に管理するための最高のツールと統合を提供するという、当社の継続的な取り組みの一環です。
Database Performance Analyzer (DPA): 2024.4

Database Performance Analyzer (DPA) 2024.4 ソフトウェアの提供のお知らせです。
- 柔軟なデータベースライセンス: セルフホスト型データベース製品に対するライセンスの付与方法を変更しました。 セルフホスト型ライセンスを1つ取得するだけで、ニーズに合わせてDPAを使用できます。 Azure SQL Databaseを監視している場合は、DBaaS環境専用の分割コストライセンスも導入しました。これにより、クラウドデータベースを簡単にコスト効率よく組み込むことができます。詳細については、担当のアカウントマネージャーまでお問い合わせください。
- MySQL/Percona MySQLワークロード分析は、SQL Server、Oracle、PostgreSQL(実行計画収集)用の強力なDPA機能、インデックスアドバイザ、テーブルチューニングアドバイザなど、人気の高い機能が含まれています。
- また、MySQL に関するセキュリティ対策も改善し、caching_sha2_password 認証をサポートするようになりました。チューニングアドバイザと併用することで、MySQL ユーザーの大幅な増加が見込まれます。
- セキュリティを念頭に置き、お客様からご要望のあった Windows のグループ管理サービスアカウント(gMSA)認証もサポートするようになりました。
- Oracle 関連では、Oracle のマルチテナント・アーキテクチャ上のターゲットとしてCDB をサポートするようになりました。これにより、より広範なアラート機能と可視性機能を備えた PDB を活用するインスタンスの全体像が完成しました。
Veeam -システム要件 (8)
Hyper-Vの無償版(Microsoft Hyper-V Server) には対応していますか?
はい。Veeam Backup & Replication は、Hyper-V のすべてのバージョンをサポートします。
Veeam Backup & Replication と vCenter Serverを同じマシンに導入してもいいですか?
技術的にはVeeam Backup & Replication(Veeam B&R)とvCenter Serverを同じWindowsマシンに導入することは問題ありません。
しかし、この2つのソフトウェアを同居させることは推奨しておりません。
理由として以下の3点があげられます。
- 双方ともにリソースを消費しやすいソフトウェアであり、リソースの適切なプロヴィジョニングが難しいこと
- 片方に障害が発生しマシンの再起動が必要となった場合、もう片方の動作に影響をおよぼすこと
- 双方ともにデフォルトのインストールではSQL Server Express Editionをインストールし使用しますが、Express Editionは使用可能なリソースに制限が加えられており、VeeamとvCenter双方からの激しいアクセスに耐え切れず双方の挙動に影響を及ぼすことがあること
これらの理由のため、可能であれば別々のマシンにインストールしていただくことを推奨しております。
Windows Storage Server をVeeamサーバとして利用可能ですか?
Windows Storage ServerとWindows Serverは同じコードを元に構築されているため、基本的には全てのVeeamのコンポーネントをStorage Server OS上にインストール可能です。
Veeam Server console
Veeam Backup Proxy
Vpower NFS server
WAN accelerator
Backup repository
しかし、Windows Storage Serverはベンダーによってカスタマイズされていることが多く、.NETの機能が有効化されていない場合や.NET Frameworkのインストールに問題がある場合があります。このような場合にはVeeam ServerのGUIは.NETコンポーネントに依存しているため、インストールすることができません。
.NETコンポーネントについてWindows Storage Serverのエンドユーザライセンス(EULA)のご確認やベンダーへのお問い合わせをお願いいたします。
EULAのパス C:\windows\system32\license.rtf
開発元KB http://www.veeam.com/kb1923
vCloud Directorに対応していますか?
はい、対応しています。
サポートするプラットフォームについてはこちらをご参照ください。
サポートするバックアップ保存先
リポジトリサーバのローカル(内部)ストレージ
リポジトリサーバに直接接続されたストレージ(DAS)
※外部のUSB/eSATAドライブ、USBパススルー、RAWデバイスマッピング(RDM)ボリュームなどを含みます。
ストレージエリアネットワーク(SAN)
※バックアップリポジトリにハードウェアまたは仮想HBA、ソフトウェアiSCSIイニシエータを介してSANファブリックに接続する必要があります。
ネットワーク接続ストレージ(NAS)
-SMB(CIFS)共有:リポジトリとして直接登録することが可能です。
-NFS共有:Linuxのリポジトリサーバにマウントする必要があります。
高度な連携が可能な重複排除ストレージアプラインス
-Dell EMC Data Domain(DD OSバージョン5.6、5.7、6.0、6.1)
-ExaGrid(ファームウェアバージョン5.0.0以降)
-HPE StoreOnce(ファームウェアバージョン3.15.1以降)
-Quantum DXi(ファームウェアバージョン3.4.0以降)
関連トピック
バックアップ先はどこが選択できますか?
Veeam Backup & Replication Enterprise Managerに推奨される環境
※Veeam Backup & Replication Enterprise ManagerはWebブラウザからVeeam Backup & Replicationのバックアップ・レプリケーションジョブ等を管理するためのソフトウェアです。またEnterprise版の機能であるU-Airや1 Click File Restoreでも使用いたします。
ハードウェア
・CPU: x86-x64 プロセッサ
・メモリ: 4 GB RAM (推奨する最小構成)
・ディスク容量: システムディスク上に 2 GB
・ネットワーク: 1Gbit/sec
対応OS(下記のの64bit OSにインストール可能です)
●Mictosoft Windows Server 2022(Veeam Backup Enterprise Manager 11a以降で対応)
●Microsoft Windows Server 2019
●Microsoft Windows Server 2016
●Microsoft Windows Server 2012 R2
●Microsoft Windows Server 2012
●Microsoft Windows 2008 R2 SP1
●Microsoft Windows 2008 SP2
●Microsoft Windows 10
●Microsoft Windows 8.x
●Microsoft Windows 7 SP1
SQL Server(有償版もしくはExpressエディション)
●Microsoft SQL Server 2019
●Microsoft SQL Server 2017
●Microsoft SQL Server 2016
●Microsoft SQL Server 2014
●Microsoft SQL Server 2012
●Microsoft SQL Server 2008 R2
●Microsoft SQL Server 2008
※インストーラにはMicrosoft SQL Server 2012のExpressが含まれています。
ソフトウェア
Microsoft .NET Framework 4.7.2 ※インストーラに含まれます。
Microsoft Internet Information Services 7.5 以降
※IIS 8.0の場合、ASP.NET 4.5、.NET 4.5拡張機能を含みます。
※IIS8.5の場合、Veeam Self-Service Backup PortalとvSphere Self-Service Backup Portalを使用する際には、URL書き換えモジュールが必要です。
※これらのコンポーネントがインストールされていない場合、セットアップ中に自動的に構成することも可能です。
ブラウザ
Internet Explorer 11.0以上
Microsoft Edge
Mozilla Firefox、Google Chromeの最新版
※JavaScriptとWebSocketを有効にする必要があります。
※Enterprise Managerからエクスポートしたレポートを表示するためにMicrosoft Excel 2003以上が必要です。
CloudBerry (MSP360) Backup (12)
ウィザードの表示がおかしくて、ウィザードの先に進めない。
以下のようになっている場合は、Windowsのコントロールパネル > デザイン > ディスプレイに移動し、項目のサイズをご確認ください。
項目のサイズが「小(100%)」ではない場合は、「小(100%)」へ変更をお願いいたします。
Amazon S3 Glacierへバックアップは出来ますか
vaultへの直接のバックアップはv6.3.2からサポートされなくなりました。
Amazon S3のストレージクラスとしてGlacierを指定することでバックアップ可能です。
コンソール再起動時に左上の更新ボタンが増える
古いバージョンにて発生する日本語GUI使用時にコンソールを再起動すると更新ボタンが増える既知の不具合です。最新版では改善されておりますので、アップグレードをお願いいたします。
Amazon S3 Transfer Accelerationをサポートしていますか?
CloudBerry Backup V4.8.2 からサポートしています。
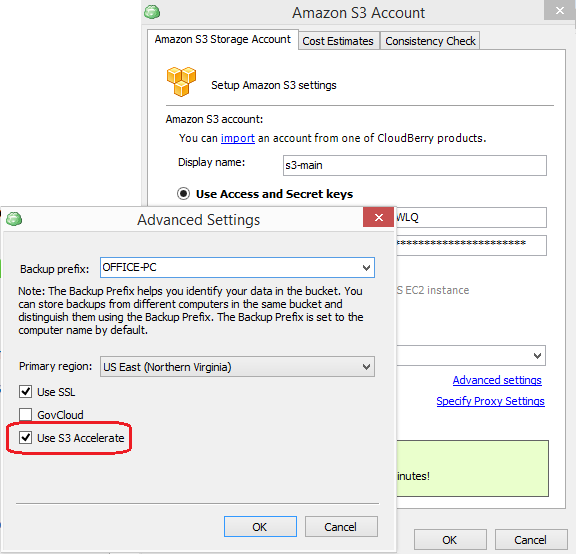
[重要]CloudBerry Backupの一般的なサポートについて
開発元のCloudBerry Lab社はすべてのクラウド・サービスを詳細に検証している訳ではありません。特にAWS互換サービス, OpenStack/CloudStackベースのサービス等がそれらに該当します。
それらのトラブルに関して当社として100%対応することが困難なことがあることをご理解ください。ケースによっては対応が不可とご連絡することもあります。
「パス’~’の一部が見つかりませんでした。」「ファイル’~’が見つかりませんでした。」エラーに関して
このエラーはフォルダ名の末尾にスペース文字(全角スペースも含む)が含まれている場合に発生します。対象のフォルダの最後にスペースが存在するか確認し、存在する場合にはそのスペースを削除したフォルダ名に変更することでエラーは解消します。
※スペースを削除した名前に直接変更すると、「送り側と受け側のファイル名が同じです。」のエラーで失敗する場合があります。一度別名に変更すると、スペースを除去した名前に変更できます。
日本リージョンに対応したクラウドにバックアップ出来ますか。
CloudBerryで使用可能なクラウドストレージは日本リージョン含めほとんどのリージョンに対応しています。
日本リージョン対応クラウド例:
Amazon S3
Asia Pacific(Tokyo)
Asia Pacific(Osaka-Local)
Azure
Japan East(Tokyo)
Japan West(Osaka)
Wasabi
Ap-northeast-1(東京リージョン)
Google Cloud
Asia-northeast1(東京)
Asia-northeast2(大阪)
他のCloudBerry製品(CloudBerry ExplorerやCloudBerry Drive)は取り扱っていますか?
いいえ、弊社ではCloudBerry Backup for Windowsのみ取り扱っています。
保守更新後にライセンス期限切れと表示されます
保守更新後に、CloudBerryのConsole にて、「ライセンス期限切れ」と表示されることがあります。
![]()
左上のメニュ > ヘルプ > この製品について を選択し、
アップデートライセンスを行うことで対処することが可能です。
対応方法の詳細は、下記URLをご参照ください。
https://www.climb.co.jp/blog_veeam/cloud-berry-backup-19666
CloudBerryの販売について
当社はMSP360社と正式販売契約を結び、CloudBerry Backupを国内で販売、日本語技術サポート、日本語マニュアルを提供しております。当社以外で購入されたCloudBerry Backupについてのサポートは一切いたしません。海外ソフトウェア・ハードウェアの調達のみを行う企業とは一切関係ありません。
5TB storage limitとはどういう意味ですか?
5TBの制限とは、CloudBerry Backupが管理するクラウドアカウントにいつでも最大5TBのデータを保存できることを意味します。例えば、800GBをアップロードし、さらに200GBをアップロードし、300GBを削除することができますが、この制限を超えることはできません。
より多くのデータをバックアップしたい場合は、CloudBerry Backup Ultimateが必要になります。
ネットワークロケーションとは何ですか?
ネットワーク上の場所とは、「 \\computer1\share\」のようなUNCパスで定義されたネットワーク共有や、ネットワーク共有にリンクされたマップドドライブのことです。
1つのライセンスを購入した場合、2台のコンピュータでCloudBerry Backupを起動できますか?
CloudBerry Backupはコンピュータごとにライセンスされています。2台のコンピュータで動作させたい場合は、2つのライセンスを購入する必要があります。
Ultimate, Server(Bare Metal), の違いは、ネットワーク上の場所の違いですか?
CloudBerry Backup Ultimate Editionは、複数のコンピュータからネットワーク共有(UNCパス)を使ってデータをバックアップする場合に必要です。Server (Bare Metal) Editionでは1つのネットワーク共有、、Ultimate Editionでは無制限です。
コンソールの日本語化する方法について
「Tools タブ」 の「Language」より日本語を選択すると
コンソールを日本語化ができます。
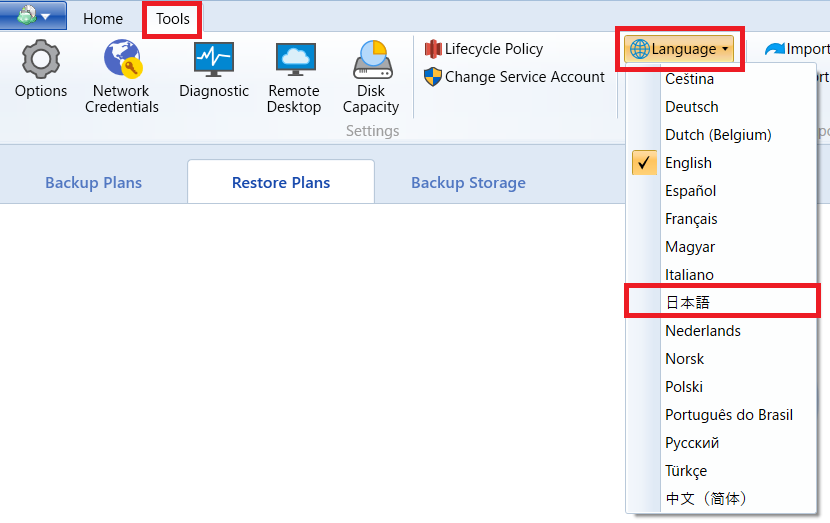 また、コンソールの日本語化により
また、コンソールの日本語化により
ウィザードの表示がおかしくなった場合の対処法は、こちらをご参照ください。
【重要】CludBerry Backup 永久ライセンスのEOLとサブスクリプション販売開始について
2021/11/30付でCloudBerry Backupの永久ライセンスはEOLとなりました。
2021/12/01以上はCloudBerry Backupのライセンスは1年間毎のサブスクリプションに変更となりました。
当社からすでにCloudBerry Backupの永久ライセンスと年間メンテナンスを同時に購入されたユーザは引き続き年間メンテナンスを規定に従って更新することができます。
CloudBerry Backupはどのようにユーザのデータを保護しますか?
CloudBerry Backupはユーザのデータを保護するために、いくつかの業界標準の強力な暗号化アルゴリズムを提供しています。また、オプションでマスターパスワードを用いてCloudBerry Backupへのアクセスを保護することができます。さらに、この機能を実装しているストレージクラスに対しては、Server-Side Encryptionをサポートしています。
Amazon EC2へのリストア制限はありますか?
Amazon側の仕様で1TB以上のディスクのリストアはできません。
詳細は下記FAQのVM Import/Exportの項目をご参照ください。
https://aws.amazon.com/jp/ec2/faqs/
設定したバージョン(世代)保持数よりも多くのファイルを保持していることがあります
変更ブロックのみのバックアップを行うblock level backupの場合は
初回は指定された全てのファイルをフルバックアップ(全てのブロック)し、
2回目以降は変更ブロックのみをバックアップします。
したがって、フルバックアップからのつながりがある限り、古い世代を削除できません。
世代数を制限するためには定期的なフルバックアップの実施が必要です。
メールアドレス変更後に、バックアップレポートが通知されません
「CloudBerry通知サービスを使用」を使用している場合は、CloudBerry側のSMTPサーバを使用しているため、通知されるアドレスを変更した後に送られる確認メールを承認いただく必要があります。確認メールはバックアップ計画のメール通知設定でアドレスを入力した後に”次へ”を押すことで、入力したアドレスに送信されます。
バックアップ対象のファイル名に制限はありますか?
特にございません。
ただ、バックアップ元・バックアップ先のファイルシステムに依存しますので、ご利用の際はご確認お願いします。
CloudBerry Backupはオープンファイルをコピーしますか?
はい、CloudBerry BackupはMicrosoft Volume Shadow Copy Technologyを利用してオープンファイルをバックアップします。
CloudBerry Backupは、実行するたびにすべてのファイルをコピーしますか?
いいえ、CloudBerry Backupは前回のバックアップ以降に変更されたファイルを識別し、そのようなファイルのみをコピーします。これにより、次回以降のバックアップの実行がより速くなります。
CloudBerry Backupはどのようにして修正されたファイルを認識するのですか?
変更されたファイルを識別するためにタイムスタンプを使用しています。
CloudBerry Backupは、ファイルの修正部分のみをコピーすることができますか?Outlook PSTファイルをバックアップしたいのですが、2GBあり、毎回ファイル全体をコピーしたくありません。
これはブロックレベル・バックアップと呼ばれ、すべてのバージョンのCloudBerry Backupで完全にサポートされています。
CloudBerry Backupはファイルの古いバージョンを保持しますか?
はい。この機能により、ファイルを過去のある時点に復元することができます。
保存するファイルのバージョン数をコントロールできますか?
はい,「パージオプション」を使用することで制御することができます。
新バックアップ形式では日、週、月、年単位で、
Legacyバックアップ形式では、保持するバージョン数を指定することができます。
「ローカルで削除されたファイルを削除する」オプションを有効にして、ローカルコンピュータ上のファイルを削除した場合、バックアップストレージからも削除されますか?
はい、そのファイルはオンラインストレージからも削除されます。しかし、デフォルトでは、誤って削除してしまうことを防ぐために、ファイルは30日間オンラインストレージに残ります。これをSmartDelete(スマートデリート)と呼んでいます。
Smart Delete(スマート・デリート)とは
Ver 1.6から、ローカルで削除されたファイルをデフォルトで30日間バックアップストレージ上に保持し、それ以降のみバックアップストレージ上のファイルを削除するスマートデリートオプションを導入しています。以下は、バックアップウィザードの新しいオプションです。
削除が予定されているファイルがある場合、Welcome Screenに通知が表示されます。
Warning(警告)のリンクをクリックすると、削除されるファイルのリストが表示され、そのファイルをどうするか(削除するか保存するか)を決定できるウィンドウが開きます。
また、削除が予定されているオブジェクトについては、通知メールに追加のアラートが表示されます。
Wasabiはどのリージョンがサポートされていますか?
現在は、下記リージョンのみサポートされております。
us-east-1
us-east-2
eu-central-1
eu-central-2
eu-west-1
eu-west-2
us-west-1
ap-southeast-1
ap-northeast-1(東京リージョン)
ap-northeast-2(大阪リージョン)
バックアップ計画の設定が2種類ありますがどのような違いがありますか
v7.0から追加された新しいバックアップ形式と従来のバックアップ形式(Legacy)です。
新しいバックアップ形式では従来よりもバックアップやリストアが高速化し多くの新機能がございます。
詳細は下記をご参照ください。
Amazon S3互換ストレージでバックアップに失敗する。
一部のS3互換のオブジェクトストレージを利用する際に、通常S3互換ストレージであれば利用できる分割でのファイルアップロードにクラウドプロバイダ側が対応しておらず、エラーで失敗することがあります。
※CloudBerryではファイルサイズが大きい場合、下記のオプションで指定したサイズで分割してアップロードします。
左上メニュー>オプション>上級設定>ファイル群のサイズ
この値以下のファイルサイズであれば分割アップロード機能は使用されないため、値を大きく(最大5GB)することである程度の回避は可能です。
ネットワーク共有にバックアップしようとすると、「パスが見つかりません」というエラーが発生します。どうしたらいいですか?
このネットワーク共有の認証情報を変更する必要があるようです。バックアップクライアントの「ツール」→「ネットワーク認証情報」で、認証情報が有効であることを確認してください。
バックアップ・プランで選択したフォルダには約4000個のファイルが含まれていますが、バックアップ・プログレス・バーの下にある「Files copied」フィールドには1000個のファイルしかないと表示されます(例:166 of 1000)
CloudBerry Backupはファイルを1000個のチャンクに分けてコピーします。最初の1000個の準備ができたら、2番目の準備を開始します。
コンピュータを起動してもプログラムが起動しないようですが。
CloudBerry Backupは、Windowsサービスとして動作します。コンピュータの起動時にコンソールを実行する必要はなく、また実行する必要も全くありません。必要なのは設定とリストアのためだけです。サービスが全ての作業を行います。
別のコンピュータでファイルを復元しています。S3アカウントとバケットに接続しましたが、ファイルが表示されません。
同じAmazon S3アカウントを登録し、詳細設定で同じバケットとプレフィックスを選択してください。デフォルトでは、プレフィックスは以前のコンピュータ名になっています。暗号化パスワードは、ファイルをバックアップしたときと同じものを指定してください。ファイルが表示されない場合は、「ツール」→「オプション」→「詳細設定」で「リポジトリの同期」をクリックして、データベースを同期させてみてください。
CloudBerry BackupとCloudBerry Explorerの違いは何ですか?
CloudBerry Explorerは単純にエクスプローラのようにファイルの表示や手動でのファイル転送を行えるものです。
対して、CloudBerry Backupではスケジュールを組み定期的にバックアップを行うことができます。現状(株)クライムではCloudBerry Explorerの販売は行っておりません。
Bare MetalエディションとUltimateエディションの違いは何ですか?
Bare Metalエディションではバックアップ先のデータ量が1TBまでの制限があります。
Ultimate(旧Enterprise)エディションは制限がありません。
https://www.climb.co.jp/soft/cloudberry/edition/
リストア時のデータの流れを教えてください
クラウドストレージからリストアする場合には
圧縮されたデータがCloudBerryまで転送され、
インストールしたサーバ上で解凍が実施されます。
差分バックアップを設定するにはどこを設定すればよろしいでしょうか。
スケジュールを有効化し、フルバックアップと差分バックアップのスケジュールを設定することで可能です。
一つのライセンスで複数のマシンにあるCloudBerry Backupを使用できますか?
使用できません。
CloudBerry Backupのライセンスは、各マシンごとにご購入いただく必要があります。
CloudBerry Backupを使用するマシンを変更できますか?
はい、可能です。
現在使用中のCloudBerryでライセンスの解放を行っていただき、別マシンで再度ライセンスキーの登録を行うことで、変更できます。但し、この処理はライセンスを受けたユーザ様のみに適応されます。
help → Release license
ヘルプ → リリースライセンス
差分はブロックレベルの差分でしょうか?それともファイル単位でしょうか?
Use block level backupを有効にした場合にはブロックレベルで実施されます。
ライセンス体系はどのようになっていますか?
CloudBerry BackupにはBare Metal版とUltimate(旧Enterprise)版があります。CloudBerry BackupをインストールするPCの数だけライセンスが必要になります。インストール先のPCのCPU等には依存いたしません。
Windows Storage Serverには対応していますか
対応しています。Microsoft .NET Framework 4.0に対応している環境であれば利用可能です。
どれだけ圧縮されているかを確認する方法はありますか?
バックアップされたファイルの元サイズと圧縮後のサイズを
Bakup Storageタブから確認できます。
CloudBerryの保守購入と更新について
(1)初年度のCloudBerryの保守購入は任意ですが、購入される場合はライセンス購入との同時購入が必修です。またライセンス数と同数の保守更新が必要です。
(2)CloudBerryの保守更新は自動更新が原則になっています。
(3)次年度のCloudBerryの保守更新時の約2ヶ月前前後にメールで更新時期のお知らせを登録エンドユーザ様にお送りします。
(4)更新日までに当社に保守更新のご発注が無いときは、更新の意向が無いとします。
それに従い開発元に対して更新キャンセルの手続きをします。
(5)この更新キャンセル処理を行ったものは再度保守に加入することは出来ません。
但しライセンス自体は永久ライセンスなので、使用できなくなることはありません。
CloudBerry Backupのインストール要件は?
システム要件をご参照ください。
CloudBery Backup型番は何ですか?
<<新規型番(2021/12/01から)>>
●SUA-CBBM:CloudBerry Backup Bare Metal版の年間サブスクリプション・ライセンス
・1年間のサポート付き
●SUA-CBBU:CloudBerry Backup Ultimate版の年間サブスクリプション・ライセンス
・1年間のサポート付き
●SUM-CBBM:CloudBerry Backup Bare Metal版の2年目以降の年間サブスクリプション更新・ライセンス
・1年間のサポート付き
●SUM-CBBU:CloudBerry Backup Ultimate版の2年目以降の年間サブスクリプション更新・ライセンス
・1年間のサポート付き
—-旧型番——————————————————–
EOL => CloudBerry Backup Bare Metal版永久ライセンス(S-CBB)
EOL => Bare Metal版 メディア(K-CBB)
Bare Metal版 年間サポートメンテナンス(M-CBB):旧ユーザのみ使用可
EOL =>CloudBerry Ultimate版永久ライセンス(S-CBU)
EOL =>Ultimate版 メディア(K-CBU)
Ultimate版 年間サポートメンテナンス(M-CBU):旧ユーザのみ使用可
代理店で購入可能ですか?
基本的に直販はしておりません。販売代理店経由での販売になります。
現在は下記の3社のお見積り・ご購入は以下3社のいずれかからお願いいたします。
株式会社システナ http://www.systena.co.jp/
ソフトバンクコマース&サービス株式会社 http://cas.softbank.jp/
ダイワボウ情報システム株式会社 http://www.pc-daiwabo.co.jp/
評価は可能ですか?また期間はどの程度ですか?
はい、15日間の無料評価が可能です。
初回起動時にライセンス認証ウィンドウでメールアドレスのみ入力し”Request Trial”をクリックすることで評価が開始されます。延長はできません。

電話サポートは行っていますか?
電話でのサポートは行っておりません。
当社営業時間内で、メールにて対応いたします。
日本語メニューに対応していますか?
現時点ではメニュー等の大部分に対応しております。今後日本語化の範囲はさらに増える見込みです。(日本語化は当社が行っております。)
当社から購入いただいたユーザ様用に製品の操作マニュアルは日本語版を用意しております。
導入支援は行っていますか?
インストール、設定ともに簡単に行えるソフトですので、当社では行っておりません。
操作方法等でご質問がある場合にはご連絡ください。
保守費用について教えてください。
保守についてはオプションで別途購入いただく形になります。価格については販売代理店までご確認ください。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
・CloudBerryインストール用のWindowsPC(仮想マシンでも可)
・バックアップ先のクラウドストレージのアカウント、及び評価の際に使用するテストデータ
※インストールするサーバについては、システム要件をご確認ください。
Amazon Import機能とBlock Level Backup機能は併用できますか?
併用可能です。ただし、Amazon Impot用に行った初期バックアップのデータが変更されていないことが、前提ととなります。
コマンドでバックアップやリストアを行えますか?
CloudBerry Backupではバックアップやリストア、設定変更などの操作をコマンドで実行できるコマンドラインインターフェイスが実装されています。詳細は弊社までお問い合わせください。
Googleドライブには接続できますか?
GoogleCloudのみサポートしています。
CloudBerry Backupをインスールしたマシンは常に稼働する必要がありますか?
データの流れ上CloudBerry Backupをインストールしたクライアントサーバを介するため、
データを同期する際は、稼働している必要があります。
スケジュールがリアルタイムの場合の間隔はどれくらいでしょうか?
変更を確認しに行くタイミングが15分間隔であるため
ファイルを新規に配置した場合には15分後にバックアップが実施されます。
ネットワーク共有のファイルは検知できません。
※v6.2からネットワーク共有のファイルも検知可能です。
評価を開始するためにCloudberryインストール後 “Start trial”ボタンをクリックするとエラーになります
Cloudberryの評価を始める際や、新規ライセンスキーを付与する場合は、一時的にインターネット接続が必要になります。
一度行った後は、インターネット接続は必要ありません。
CloudBerry Backup -導入・ライセンスについて (20)
他のCloudBerry製品(CloudBerry ExplorerやCloudBerry Drive)は取り扱っていますか?
いいえ、弊社ではCloudBerry Backup for Windowsのみ取り扱っています。
保守更新後にライセンス期限切れと表示されます
保守更新後に、CloudBerryのConsole にて、「ライセンス期限切れ」と表示されることがあります。
![]()
左上のメニュ > ヘルプ > この製品について を選択し、
アップデートライセンスを行うことで対処することが可能です。
対応方法の詳細は、下記URLをご参照ください。
https://www.climb.co.jp/blog_veeam/cloud-berry-backup-19666
CloudBerryの販売について
当社はMSP360社と正式販売契約を結び、CloudBerry Backupを国内で販売、日本語技術サポート、日本語マニュアルを提供しております。当社以外で購入されたCloudBerry Backupについてのサポートは一切いたしません。海外ソフトウェア・ハードウェアの調達のみを行う企業とは一切関係ありません。
5TB storage limitとはどういう意味ですか?
5TBの制限とは、CloudBerry Backupが管理するクラウドアカウントにいつでも最大5TBのデータを保存できることを意味します。例えば、800GBをアップロードし、さらに200GBをアップロードし、300GBを削除することができますが、この制限を超えることはできません。
より多くのデータをバックアップしたい場合は、CloudBerry Backup Ultimateが必要になります。
ネットワークロケーションとは何ですか?
ネットワーク上の場所とは、「 \\computer1\share\」のようなUNCパスで定義されたネットワーク共有や、ネットワーク共有にリンクされたマップドドライブのことです。
1つのライセンスを購入した場合、2台のコンピュータでCloudBerry Backupを起動できますか?
CloudBerry Backupはコンピュータごとにライセンスされています。2台のコンピュータで動作させたい場合は、2つのライセンスを購入する必要があります。
Ultimate, Server(Bare Metal), の違いは、ネットワーク上の場所の違いですか?
CloudBerry Backup Ultimate Editionは、複数のコンピュータからネットワーク共有(UNCパス)を使ってデータをバックアップする場合に必要です。Server (Bare Metal) Editionでは1つのネットワーク共有、、Ultimate Editionでは無制限です。
コンソールの日本語化する方法について
「Tools タブ」 の「Language」より日本語を選択すると
コンソールを日本語化ができます。
また、コンソールの日本語化により
ウィザードの表示がおかしくなった場合の対処法は、こちらをご参照ください。
【重要】CludBerry Backup 永久ライセンスのEOLとサブスクリプション販売開始について
2021/11/30付でCloudBerry Backupの永久ライセンスはEOLとなりました。
2021/12/01以上はCloudBerry Backupのライセンスは1年間毎のサブスクリプションに変更となりました。
当社からすでにCloudBerry Backupの永久ライセンスと年間メンテナンスを同時に購入されたユーザは引き続き年間メンテナンスを規定に従って更新することができます。
CloudBerry BackupとCloudBerry Explorerの違いは何ですか?
CloudBerry Explorerは単純にエクスプローラのようにファイルの表示や手動でのファイル転送を行えるものです。
対して、CloudBerry Backupではスケジュールを組み定期的にバックアップを行うことができます。現状(株)クライムではCloudBerry Explorerの販売は行っておりません。
Bare MetalエディションとUltimateエディションの違いは何ですか?
Bare Metalエディションではバックアップ先のデータ量が1TBまでの制限があります。
Ultimate(旧Enterprise)エディションは制限がありません。
https://www.climb.co.jp/soft/cloudberry/edition/
リストア時のデータの流れを教えてください
クラウドストレージからリストアする場合には
圧縮されたデータがCloudBerryまで転送され、
インストールしたサーバ上で解凍が実施されます。
一つのライセンスで複数のマシンにあるCloudBerry Backupを使用できますか?
使用できません。
CloudBerry Backupのライセンスは、各マシンごとにご購入いただく必要があります。
CloudBerry Backupを使用するマシンを変更できますか?
はい、可能です。
現在使用中のCloudBerryでライセンスの解放を行っていただき、別マシンで再度ライセンスキーの登録を行うことで、変更できます。但し、この処理はライセンスを受けたユーザ様のみに適応されます。
help → Release license
ヘルプ → リリースライセンス
ライセンス体系はどのようになっていますか?
CloudBerry BackupにはBare Metal版とUltimate(旧Enterprise)版があります。CloudBerry BackupをインストールするPCの数だけライセンスが必要になります。インストール先のPCのCPU等には依存いたしません。
Windows Storage Serverには対応していますか
対応しています。Microsoft .NET Framework 4.0に対応している環境であれば利用可能です。
CloudBerryの保守購入と更新について
(1)初年度のCloudBerryの保守購入は任意ですが、購入される場合はライセンス購入との同時購入が必修です。またライセンス数と同数の保守更新が必要です。
(2)CloudBerryの保守更新は自動更新が原則になっています。
(3)次年度のCloudBerryの保守更新時の約2ヶ月前前後にメールで更新時期のお知らせを登録エンドユーザ様にお送りします。
(4)更新日までに当社に保守更新のご発注が無いときは、更新の意向が無いとします。
それに従い開発元に対して更新キャンセルの手続きをします。
(5)この更新キャンセル処理を行ったものは再度保守に加入することは出来ません。
但しライセンス自体は永久ライセンスなので、使用できなくなることはありません。
CloudBerry Backupのインストール要件は?
システム要件をご参照ください。
CloudBery Backup型番は何ですか?
<<新規型番(2021/12/01から)>>
●SUA-CBBM:CloudBerry Backup Bare Metal版の年間サブスクリプション・ライセンス
・1年間のサポート付き
●SUA-CBBU:CloudBerry Backup Ultimate版の年間サブスクリプション・ライセンス
・1年間のサポート付き
●SUM-CBBM:CloudBerry Backup Bare Metal版の2年目以降の年間サブスクリプション更新・ライセンス
・1年間のサポート付き
●SUM-CBBU:CloudBerry Backup Ultimate版の2年目以降の年間サブスクリプション更新・ライセンス
・1年間のサポート付き
—-旧型番——————————————————–
EOL => CloudBerry Backup Bare Metal版永久ライセンス(S-CBB)
EOL => Bare Metal版 メディア(K-CBB)
Bare Metal版 年間サポートメンテナンス(M-CBB):旧ユーザのみ使用可
EOL =>CloudBerry Ultimate版永久ライセンス(S-CBU)
EOL =>Ultimate版 メディア(K-CBU)
Ultimate版 年間サポートメンテナンス(M-CBU):旧ユーザのみ使用可
代理店で購入可能ですか?
基本的に直販はしておりません。販売代理店経由での販売になります。
現在は下記の3社のお見積り・ご購入は以下3社のいずれかからお願いいたします。
株式会社システナ http://www.systena.co.jp/
ソフトバンクコマース&サービス株式会社 http://cas.softbank.jp/
ダイワボウ情報システム株式会社 http://www.pc-daiwabo.co.jp/
CloudBerry Backup -購入サポート (5)
代理店で購入可能ですか?
基本的に直販はしておりません。販売代理店経由での販売になります。
現在は下記の3社のお見積り・ご購入は以下3社のいずれかからお願いいたします。
株式会社システナ http://www.systena.co.jp/
ソフトバンクコマース&サービス株式会社 http://cas.softbank.jp/
ダイワボウ情報システム株式会社 http://www.pc-daiwabo.co.jp/
電話サポートは行っていますか?
電話でのサポートは行っておりません。
当社営業時間内で、メールにて対応いたします。
日本語メニューに対応していますか?
現時点ではメニュー等の大部分に対応しております。今後日本語化の範囲はさらに増える見込みです。(日本語化は当社が行っております。)
当社から購入いただいたユーザ様用に製品の操作マニュアルは日本語版を用意しております。
導入支援は行っていますか?
インストール、設定ともに簡単に行えるソフトですので、当社では行っておりません。
操作方法等でご質問がある場合にはご連絡ください。
保守費用について教えてください。
保守についてはオプションで別途購入いただく形になります。価格については販売代理店までご確認ください。
CloudBerry Backup -評価 (6)
CloudBerry Backupはどのようにユーザのデータを保護しますか?
CloudBerry Backupはユーザのデータを保護するために、いくつかの業界標準の強力な暗号化アルゴリズムを提供しています。また、オプションでマスターパスワードを用いてCloudBerry Backupへのアクセスを保護することができます。さらに、この機能を実装しているストレージクラスに対しては、Server-Side Encryptionをサポートしています。
評価は可能ですか?また期間はどの程度ですか?
はい、15日間の無料評価が可能です。
初回起動時にライセンス認証ウィンドウでメールアドレスのみ入力し”Request Trial”をクリックすることで評価が開始されます。延長はできません。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価するには何が必要になりますか?
下記の環境をご用意ください。
・CloudBerryインストール用のWindowsPC(仮想マシンでも可)
・バックアップ先のクラウドストレージのアカウント、及び評価の際に使用するテストデータ
※インストールするサーバについては、システム要件をご確認ください。
評価を開始するためにCloudberryインストール後 “Start trial”ボタンをクリックするとエラーになります
Cloudberryの評価を始める際や、新規ライセンスキーを付与する場合は、一時的にインターネット接続が必要になります。
一度行った後は、インターネット接続は必要ありません。
CloudBerry Backup -機能 (26)
Amazon S3 Transfer Accelerationをサポートしていますか?
CloudBerry Backup V4.8.2 からサポートしています。
Amazon S3 Glacierへバックアップは出来ますか
vaultへの直接のバックアップはv6.3.2からサポートされなくなりました。
Amazon S3のストレージクラスとしてGlacierを指定することでバックアップ可能です。
ウィザードの表示がおかしくて、ウィザードの先に進めない。
以下のようになっている場合は、Windowsのコントロールパネル > デザイン > ディスプレイに移動し、項目のサイズをご確認ください。
項目のサイズが「小(100%)」ではない場合は、「小(100%)」へ変更をお願いいたします。
Amazon EC2へのリストア制限はありますか?
Amazon側の仕様で1TB以上のディスクのリストアはできません。
詳細は下記FAQのVM Import/Exportの項目をご参照ください。
https://aws.amazon.com/jp/ec2/faqs/
設定したバージョン(世代)保持数よりも多くのファイルを保持していることがあります
変更ブロックのみのバックアップを行うblock level backupの場合は
初回は指定された全てのファイルをフルバックアップ(全てのブロック)し、
2回目以降は変更ブロックのみをバックアップします。
したがって、フルバックアップからのつながりがある限り、古い世代を削除できません。
世代数を制限するためには定期的なフルバックアップの実施が必要です。
メールアドレス変更後に、バックアップレポートが通知されません
「CloudBerry通知サービスを使用」を使用している場合は、CloudBerry側のSMTPサーバを使用しているため、通知されるアドレスを変更した後に送られる確認メールを承認いただく必要があります。確認メールはバックアップ計画のメール通知設定でアドレスを入力した後に”次へ”を押すことで、入力したアドレスに送信されます。
バックアップ対象のファイル名に制限はありますか?
特にございません。
ただ、バックアップ元・バックアップ先のファイルシステムに依存しますので、ご利用の際はご確認お願いします。
CloudBerry Backupはオープンファイルをコピーしますか?
はい、CloudBerry BackupはMicrosoft Volume Shadow Copy Technologyを利用してオープンファイルをバックアップします。
CloudBerry Backupは、実行するたびにすべてのファイルをコピーしますか?
いいえ、CloudBerry Backupは前回のバックアップ以降に変更されたファイルを識別し、そのようなファイルのみをコピーします。これにより、次回以降のバックアップの実行がより速くなります。
CloudBerry Backupはどのようにして修正されたファイルを認識するのですか?
変更されたファイルを識別するためにタイムスタンプを使用しています。
CloudBerry Backupは、ファイルの修正部分のみをコピーすることができますか?Outlook PSTファイルをバックアップしたいのですが、2GBあり、毎回ファイル全体をコピーしたくありません。
これはブロックレベル・バックアップと呼ばれ、すべてのバージョンのCloudBerry Backupで完全にサポートされています。
CloudBerry Backupはファイルの古いバージョンを保持しますか?
はい。この機能により、ファイルを過去のある時点に復元することができます。
保存するファイルのバージョン数をコントロールできますか?
はい,「パージオプション」を使用することで制御することができます。
新バックアップ形式では日、週、月、年単位で、
Legacyバックアップ形式では、保持するバージョン数を指定することができます。
「ローカルで削除されたファイルを削除する」オプションを有効にして、ローカルコンピュータ上のファイルを削除した場合、バックアップストレージからも削除されますか?
はい、そのファイルはオンラインストレージからも削除されます。しかし、デフォルトでは、誤って削除してしまうことを防ぐために、ファイルは30日間オンラインストレージに残ります。これをSmartDelete(スマートデリート)と呼んでいます。
Smart Delete(スマート・デリート)とは
Ver 1.6から、ローカルで削除されたファイルをデフォルトで30日間バックアップストレージ上に保持し、それ以降のみバックアップストレージ上のファイルを削除するスマートデリートオプションを導入しています。以下は、バックアップウィザードの新しいオプションです。
削除が予定されているファイルがある場合、Welcome Screenに通知が表示されます。
Warning(警告)のリンクをクリックすると、削除されるファイルのリストが表示され、そのファイルをどうするか(削除するか保存するか)を決定できるウィンドウが開きます。
また、削除が予定されているオブジェクトについては、通知メールに追加のアラートが表示されます。
Wasabiはどのリージョンがサポートされていますか?
現在は、下記リージョンのみサポートされております。
us-east-1
us-east-2
eu-central-1
eu-central-2
eu-west-1
eu-west-2
us-west-1
ap-southeast-1
ap-northeast-1(東京リージョン)
ap-northeast-2(大阪リージョン)
日本リージョンに対応したクラウドにバックアップ出来ますか。
CloudBerryで使用可能なクラウドストレージは日本リージョン含めほとんどのリージョンに対応しています。
日本リージョン対応クラウド例:
Amazon S3
Asia Pacific(Tokyo)
Asia Pacific(Osaka-Local)
Azure
Japan East(Tokyo)
Japan West(Osaka)
Wasabi
Ap-northeast-1(東京リージョン)
Google Cloud
Asia-northeast1(東京)
Asia-northeast2(大阪)
バックアップ計画の設定が2種類ありますがどのような違いがありますか
v7.0から追加された新しいバックアップ形式と従来のバックアップ形式(Legacy)です。
新しいバックアップ形式では従来よりもバックアップやリストアが高速化し多くの新機能がございます。
詳細は下記をご参照ください。
差分バックアップを設定するにはどこを設定すればよろしいでしょうか。
スケジュールを有効化し、フルバックアップと差分バックアップのスケジュールを設定することで可能です。
差分はブロックレベルの差分でしょうか?それともファイル単位でしょうか?
Use block level backupを有効にした場合にはブロックレベルで実施されます。
どれだけ圧縮されているかを確認する方法はありますか?
バックアップされたファイルの元サイズと圧縮後のサイズを
Bakup Storageタブから確認できます。
Amazon Import機能とBlock Level Backup機能は併用できますか?
併用可能です。ただし、Amazon Impot用に行った初期バックアップのデータが変更されていないことが、前提ととなります。
コマンドでバックアップやリストアを行えますか?
CloudBerry Backupではバックアップやリストア、設定変更などの操作をコマンドで実行できるコマンドラインインターフェイスが実装されています。詳細は弊社までお問い合わせください。
Googleドライブには接続できますか?
GoogleCloudのみサポートしています。
CloudBerry Backupをインスールしたマシンは常に稼働する必要がありますか?
データの流れ上CloudBerry Backupをインストールしたクライアントサーバを介するため、
データを同期する際は、稼働している必要があります。
スケジュールがリアルタイムの場合の間隔はどれくらいでしょうか?
変更を確認しに行くタイミングが15分間隔であるため
ファイルを新規に配置した場合には15分後にバックアップが実施されます。
ネットワーク共有のファイルは検知できません。
※v6.2からネットワーク共有のファイルも検知可能です。
CloudBerry Backup -トラブル (8)
コンソール再起動時に左上の更新ボタンが増える
古いバージョンにて発生する日本語GUI使用時にコンソールを再起動すると更新ボタンが増える既知の不具合です。最新版では改善されておりますので、アップグレードをお願いいたします。
[重要]CloudBerry Backupの一般的なサポートについて
開発元のCloudBerry Lab社はすべてのクラウド・サービスを詳細に検証している訳ではありません。特にAWS互換サービス, OpenStack/CloudStackベースのサービス等がそれらに該当します。
それらのトラブルに関して当社として100%対応することが困難なことがあることをご理解ください。ケースによっては対応が不可とご連絡することもあります。
「パス’~’の一部が見つかりませんでした。」「ファイル’~’が見つかりませんでした。」エラーに関して
このエラーはフォルダ名の末尾にスペース文字(全角スペースも含む)が含まれている場合に発生します。対象のフォルダの最後にスペースが存在するか確認し、存在する場合にはそのスペースを削除したフォルダ名に変更することでエラーは解消します。
※スペースを削除した名前に直接変更すると、「送り側と受け側のファイル名が同じです。」のエラーで失敗する場合があります。一度別名に変更すると、スペースを除去した名前に変更できます。
Amazon S3互換ストレージでバックアップに失敗する。
一部のS3互換のオブジェクトストレージを利用する際に、通常S3互換ストレージであれば利用できる分割でのファイルアップロードにクラウドプロバイダ側が対応しておらず、エラーで失敗することがあります。
※CloudBerryではファイルサイズが大きい場合、下記のオプションで指定したサイズで分割してアップロードします。
左上メニュー>オプション>上級設定>ファイル群のサイズ
この値以下のファイルサイズであれば分割アップロード機能は使用されないため、値を大きく(最大5GB)することである程度の回避は可能です。
ネットワーク共有にバックアップしようとすると、「パスが見つかりません」というエラーが発生します。どうしたらいいですか?
このネットワーク共有の認証情報を変更する必要があるようです。バックアップクライアントの「ツール」→「ネットワーク認証情報」で、認証情報が有効であることを確認してください。
バックアップ・プランで選択したフォルダには約4000個のファイルが含まれていますが、バックアップ・プログレス・バーの下にある「Files copied」フィールドには1000個のファイルしかないと表示されます(例:166 of 1000)
CloudBerry Backupはファイルを1000個のチャンクに分けてコピーします。最初の1000個の準備ができたら、2番目の準備を開始します。
コンピュータを起動してもプログラムが起動しないようですが。
CloudBerry Backupは、Windowsサービスとして動作します。コンピュータの起動時にコンソールを実行する必要はなく、また実行する必要も全くありません。必要なのは設定とリストアのためだけです。サービスが全ての作業を行います。
別のコンピュータでファイルを復元しています。S3アカウントとバケットに接続しましたが、ファイルが表示されません。
同じAmazon S3アカウントを登録し、詳細設定で同じバケットとプレフィックスを選択してください。デフォルトでは、プレフィックスは以前のコンピュータ名になっています。暗号化パスワードは、ファイルをバックアップしたときと同じものを指定してください。ファイルが表示されない場合は、「ツール」→「オプション」→「詳細設定」で「リポジトリの同期」をクリックして、データベースを同期させてみてください。
Syniti DR - AWS (4)
RDSのAurora/MySQLでバイナリログ(binlog)を使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【DBMotoでの設定】
「DBMySqlUtil.dll」をDBMotoインストールディレクトリに配置する必要があります。
お手元にない場合はお問合せください。
RDSのAurora/MySQLでトリガーを使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatが「OFF」になってる場合はそのままトリガーを使用可能です。
binlog_formatが有効化されている場合は、DB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
CHARの代わりにVARCHARを使用してRedshiftにレプリケートすることで、より多くの文字をサポートし、予期しない文字の混在を防ぐことができます。
Version: Syniti Data Replication 9.6.0 以上
Amazon Redshiftのクラウドデータウェアハウスにレプリケートする際、データタイプがCHARのフィールドにエラーや予期せぬ文字が現れることがあります。 この現象の説明については、以下のURLを参照してください。
https://docs.amazonaws.cn/en_us/redshift/latest/dg/multi-byte-character-load-errors.html
エラーや予期せぬ文字を避けるために、RedshiftのターゲットのデータタイプをCHARではなくVARCHARに設定してください。
Amazon EC2上のDBMotoからAmazon Redshiftへの接続ができません。
EC2上のWindowsに用意したDBMotoからRedshiftに接続しようとするとフリーズすることがあります。
これは、EC2上のインスタンスのNIC設定に由来する問題です。レジストリ上からMTU値を設定します。
次の場所にあるレジストリ内にMTU値を示すレジストリエントリーを追加します。
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\Interfaces\(アダプタのID)
追加するレジストリは、DWORD型で、値の名前は MTU 、データの値は 1500 に設定します。設定後コンピュータを再起動して、新しい値を適用します。
詳細は下記Amazon様ページをご覧いただきますよう、お願いいたします。
データベースへの接続が中断された – Amazon Redshift
Syniti DR -機能(レプリケーション) (21)
ミラーリング時の更新サイクルはどのくらいですか?
デフォルト値は60秒です。変更可能ですが、30秒~5分が推奨値となっております。
複数のソースサーバから1つのターゲットサーバに結合レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
https://www.climb.co.jp/soft/dbmoto/outline/example.html
1つのソースサーバから複数のターゲットサーバに分散レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
リフレッシュ実行中にソースに更新があった場合はどうなりますか?
リフレッシュ完了後にミラーリングモードに移行し、更新分が差分レプリケーションされます。
シンクロナイゼーションで同一フィールドの同じ値を更新した時にコンフリクト扱いになりますか?
同じ値を更新した場合はコンフリクトとはみなされません。
レプリケーション定義を一括で作成する方法はありますか?
予めソース・ターゲットの接続設定を済ませたうえで「マルチレプリケーション作成」を選択することで可能です。
ターゲット→ソースへのリフレッシュは可能ですか?
リフレッシュはソース→ターゲット方向のみサポートしております。
シンクロナイゼーション(双方向)における処理シーケンスを教えてください。
以下の流れとなります。
ソースのトランザクションログを検索⇒ターゲットのトランザクションログを検索⇒ソースからターゲットへの更新処理⇒ターゲットからソースへの更新処理
ミラーリングの真っ最中にスケジュールリフレッシュの時間になった場合はどのような挙動になりますか?
ミラーリングプロセス終了後にリフレッシュされます。強引に割り込むことはありません。
ミラーリング・シンクロナイゼーションの処理速度を上げる方法はありますか?
Data Replicator Option画面にある「Thread Execution Factor」の値を増やすことで処理速度の向上が期待できます。
ネットワーク障害が発生した場合、復旧処理は自動で行われますか?
自動で行われます。
シンクロナイゼーション時に双方の同じレコードを更新した場合にはどうなりますか?
下記のオプションから選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する(先勝ち)
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
なお、「TimeStampの遅いほうを優先(後勝ち)」としたい場合には、カスタムスクリプトの記述が必要となります。
ソースDBとターゲットDBで文字コードが異なっていても大丈夫?
問題ありません。DBMotoで文字コード変換を吸収します。
DBMoto内部ではUnicodeで処理され、双方のDBに対して文字コード変換を行います。
スケジュール機能はありますか?
はい、あります。
リフレッシュを定期的に実行するリフレッシュスケジュール、ミラーリングを実行する日時を制限するミラーリングスケジュールの設定が可能です。
スケジュールは時・分・秒、年・月・日・曜日単位で細かく設定でき、複数設定も可能です。
DB障害が発生してレプリケーションが停止した際の復旧が心配です。データの不整合が発生してしまうのでは?
DBMotoは最後に更新したトランザクションIDを常に保持しておりますので、DB障害復旧後には、障害発生前の最後のトランザクションIDからレプリケーションを再開します。よって通常はデータの不整合が発生することはまずありません。
ミラーリングでソースに対してレコードの更新や削除を行った際に、ターゲット側にレコードが存在しなかった場合にはどのような挙動になりますか?
エラーメッセージ「ターゲットにレコードが存在しません」をログファイルに出力し、更新時にはターゲットに対して登録処理が行われます。オプション設定変更により登録処理を行わないようにもできます。
DBMotoで使用する通信の種類とポートを教えてください。
TCP/IPで通信し、DB で使用するデフォルトポートを使用します。例えばOracleの場合はデフォルトで1521を使用します。
マルチシンクロナイゼーションにおいて、ソースとターゲットの複数で同じタイミングで同一レコードの更新をかけた場合、どのサーバのレコードが優先されますか?
ソースとターゲットで同一レコードの更新があった場合の挙動は以下から選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
さらにターゲットの複数サーバで同一レコードの更新があった場合には、TimeStampの早いほうが優先されます。
ミラーリングモードでも初回でリフレッシュは可能ですか?
可能です。下記の弊社ブログをご参照ください。
DBMotoでの全件リフレッシュ・差分ミラーリングの再設定手順
Syniti DR -機能(オプション) (2)
メタデータは複数作成できますか?同時に使用できますか?
DBMotoのメタデータは、複数作成することは可能です。
これにより運用環境とテスト環境それぞれのメタデータを用意できます。
しかし、複数のメタデータを同時に使用することはできません。それぞれのメタデータ内にあるレプリケーションは、それぞれのメタデータを有効化していない限り動作しません。
メタデータの切り替えは、メタデータ上で右クリックして表示されるメニューの、「既定のメタデータにする」で可能です。
ログ出力先をWindowsイベントログにした場合historyファイルはどこにありますか?
Windowsイベントログでの運用の場合、historyファイルはご使用いただけません。
Syniti DR -機能(関数・スクリプト・API) (1)
スクリプトで、.Net Frameworkの○○という関数が動きません。
スクリプトに記述した、.Net Frameworkの関数が動作しないことがあります。
これは、その関数の動作に必要な.Net FrameworkのライブラリがDBMotoに読み込まれていないのが原因です。
DBMotoでは本体の動作に不要な.Net Frameworkのライブラリは読み込まないようになっております。
適宜リファレンスで必要な.Net Frameworkのライブラリを読み込んでください。
■例
SHA256CryptoServiceProvider関数を利用する場合、System.Core.dllというライブラリを呼び出す必要があります。
Microsoft公式のSHA256CryptoServiceProvider解説ページ
このDLLファイルは、C:\Windows\Microsoft.NET\Framework64\vX.X.XXXX(Xは任意のバージョン数値)にありますので、ここへのリファレンスを追加してください。(64bit版の場合)
Syniti DR -Sybase ASE (1)
Sybase ASEから差分レプリケーションは可能ですか?
トリガーを使用することで可能です。
ただし、Sybase ASEでは1つのテーブルにおいて1つのトリガーのみしか使用できない仕様のため、既存でテーブルにトリガーを設定している場合は、DBMotoから差分レプリケーションを実施することはできません。
ディザスタ・リカバリ (78)
セルフサービス型DRaaS
それは何か? セルフサービス方式で提供される場合、DRaaSプロバイダーは、災害時に必要なツールやサポート文書とともに、対象となるインフラを用意します。セルフサービスとは、初期設定と継続的な保守・監視をお客様の組織で行うことを意味します。つまり、DRaaSプロバイダーは、インフラとツールが正しく動作することを保証しますが、それだけで、ソリューション全体に対する全責任を負うわけではありません。DRaaSプロバイダーは、インフラとツールが正しく動作することを保証しますが、ソリューション全体に対する完全な責任は負いません。
このような場合に最適です。このモデルは、DR戦略を実行するためのスキルと能力を備えた大規模なITチームをすでに持っている組織に適しています。このような企業では、セルフサービス型DRaaSが、地域分散戦略、消費型モデルへの移行、OPEX支出への移行に役立ちます。
災害復旧とは?
災害復旧は、ITインフラストラクチャを復活させ、サイバー攻撃、ハードウェア障害、偶発的なデータ削除などの自然または人為的な災害の後に重要なビジネス機能を再開することを総称して意図されている手順、ツール、ポリシー、およびリソースのセットです。
これは、サービスの中断後にすべての重要なプロセスを復旧させようとするものであり、事業継続のサブセットと考えることができます。
DRaaS(Disaster Recovery as a Service)とは
DRaaS(Disaster Recovery as a Service)といえば、かつては大きなトラックの荷台にデータセンターを運んできて、そこにデータをアップロードするものでした。しかし、この面倒で時間のかかるプロセスは、かつてはディザスターリカバリーサービスのゴールドスタンダードでした。
クラウドコンピューティングの台頭により、DRaaSは新たな進化を遂げました。クラウド・ディーザスター・リカバリー・サービスの騒音は、オフィスの外でアイドリングしている大きなトラックの代わりに、利用可能なサービスの多さへの混乱から生じているのです。
DRaaSプロバイダーは、明確に定義されたカテゴリーではなく、さまざまな領域に分類される。この記事では、この領域におけるDRaaSの3つの主要な選択肢を探っていきます。しかし、ディザスターリカバリーサービスのキーワードは柔軟性である。多くのDRaaSプロバイダーが存在する中で、あなたの組織に最適なDRaaSは、次に示す選択肢の外にあるかもしれないです。
災害復旧におけるRTOとRPOとは?
災害復旧計画を作成するためには、まず、ダウンタイムが発生した場合にビジネスが引き受ける時間目標と許容可能なデータ損失を見積もる必要があります。これらの目的は、回復時間と回復ポイントの目標と呼ばれています。
RTOは、完全に、回復時間目標を指します。この測定量は事業継続のための災害の後で、ユーザのITの下部組織およびサービスを元通りにするべきである時間の量を確立します。
次に、RPO(Recovery Point Objective)は、組織が災害時に失われたデータの最大許容量を定義します。さらに、最終的なデータバックアップインスタンスから災害発生までの最大許容時間についての洞察を提供します。つまり、適切なバックアップスケジュールと頻度を決定するために使用することができます。
ディザスターリカバリーは通常のバックアップとどう違うのか?
バックアップとは、データのコピーを作成し、プライマリおよびセカンダリの場所に保存するプロセスです。あなたは、ローカルドライブ、NASデバイス、オフサイトのデータセンター、クラウドストレージ、および他の手段でファイルをバックアップすることができます。これはデータ損失を経験することが起こればあなたのデータを元通りにすることを可能にします。
一方、ディザスターリカバリーは、データとITリソースを問題から保護することを目的とした、より総合的なプロセスであり、大規模な中断後の基幹業務システムの迅速な再構築を促進します。
したがって、バックアップは災害復旧の1つのサブコンポーネントにすぎないと結論づけることができます。
災害復旧(ディザスタ・リカバリ)を管理するには?
災害復旧を管理するには、堅牢な災害復旧計画とそれに対応する事業継続計画の起草、実装、およびテストが必要です。
ビジネスインパクト分析を行う際には、理想的なリカバリーインフラ(オンプレミスかクラウドか)と、災害復旧アプローチ(マルチサイト、ウォームスタンバイ、パイロットライト、またはバックアップとリカバリーのいずれか)を考慮する必要があります。
IT災害復旧計画とは?
ITの災害復旧の計画は効果的にサイバー攻撃、停電および自然な災害のような自然な、人為的な災害によって引き起こされるサービス中断にいかに対応するかの詳しい指導を提供する構造化された文書です。
計画自体は、すべての中核となるビジネスプロセスに加えて、その過程で発生する可能性のある災害を考慮しています。その上で、各災害の影響を最小限に抑えるための戦略と、重要な業務を迅速かつシームレスに復旧するための利用可能な二次リソースの活用方法を提示します。
災害復旧計画の目的は何か。
災害復旧計画はサービス中断に迅速かつ効果的に対応するのを助けるように努めます。それは各潜在的な災害の効果を最小にすることに焦点を合わせ、基幹業務を元通りに戻します。
災害復旧計画には何が含まれるか?
IT災害復旧計画の主要な要素には、以下のものが含まれます。
●災害対応のためのすべての責任の割り当て
●災害対応の実施フレームワーク
●バックアップから新しいシステムにデータを復元するプロセス
●処理を反転させて通常の動作を再開する手順を説明
災害復旧計画を作成するには?
災害復旧計画を作成するためには、以下のことを行う必要があります。
●ビジネスリーダーと災害復旧計画の必要性について話し合う
●復旧が必要なビジネスプロセスとデータを重要度別にグループ化
●想定される災害事例を特定する
●災害復旧の目標を定義する
●目標に応じて回復できるツールや方法を定義する
●災害復旧計画とワークフローの実施
●エンドユーザーへの教育
災害復旧計画と事業継続計画の違いは?
事業継続の計画が破壊的なでき事の後で動いている事業活動を保つために必要なすべてのプロシージャおよび議定書を定義するのに使用されています。従って、一言で言えば、事業継続の計画は「いかに私達は災害が起これば私達のビジネスプロセスを維持していくか」に答えるものです。
災害復旧計画は、一方では、災害に続く重要なITインフラストラクチャおよびサービスを復元するために必要なステップおよびリソースを具体的に扱うものです。それは「いかに私達は災害の後で再開してもいいか」の質問に答えることを意味します。
しかし、災害復旧は事業継続の重要な要素の一つです。
災害復旧計画をどのようにテストするか?
災害復旧計画は、ウォークスルー・テスト、卓上テスト、および技術テストによって評価することができます。
ウォークスルー・テストは基本的に災害復旧計画のステップバイステップのレビューであり、卓上テストは各チームメンバーがどのように答えるか決定するために「what-if」のシナリオを起動させます。その後、並行テストやライブ/フル中断テストのような技術テストで補足することができます。
オンプレムよりもクラウド・オブジェクトストレージを使う理由
1. S3 Object Lockに対応したサイバー脅威対策。これにより、不変のバックアップが可能になり、ランサムウェアやハッカーだけでなく、誤って削除されたり、悪意のあるインサイダーからも防弾性のある保護を提供します。どんなオンプレミスのストレージでも、十分な大きさのハンマーを持った(またはガソリンの入ったキャニスターを持った)動揺した従業員が、最も洗練されたアクセス制御やWORM技術でさえも簡単に回避することができるため、単純にそうはいきません。
2. オフサイトバックアップ。クラウド・オブジェクト・ストレージは定義上オフサイトに位置しているため、これは「無料」で含まれており、3-2-1 バックアップ・ルールの「1」を達成することは完全に容易である。これは非常に重要なコスト要因であり、オンプレミスのオブジェクトストレージを使用する場合、オフサイトバックアップを行う方法を見つける必要があるからです。そして、どのようにアプローチするにしても、そのためだけにいくつかの余分な$$を費やす必要があります。
3. パフォーマンスとスケーラビリティ。成熟したクラウドオブジェクトストレージは、一般的に実行し、はるかに優れたスケーラビリティを持っています。実際、Amazon S3は来月で15歳になりますが、これはVeeamと同じくらい古いです。しかし、言うまでもなく、この弾丸は、最近キノコのように飛び出している新しいベンダーには適用されないかもしれません。あなたがコミットする前にデューデリジェンスを行い、広範囲にテストを行ったとしても、彼らは常に後で登録をオーバーする可能性があります…心に留めておいてください – いつものように、あなたはあなたが得たものを支払します!
クラウドよりもオンプレミスのオブジェクトストレージを利用する理由
1. コストが安くなる。ほとんどの場合、長期的にはオンプレミスのオブジェクトストレージの方が安くなります。ストレージの価格だけでなく、電気代、冷却費、その他のデータセンターのコストも考慮する必要があります。また、あまり成熟していないオブジェクト・ストレージ・ソリューションを子守するための人的資源コストも考慮に入れてください。
2. データの主権。もしあなたのデータの一部またはすべてをオンプレミスで保管することを必要とする州、業界、企業のポリシーや規制に縛られている場合、選択肢はありません!もしあなたがこれらのソリューションを利用することを決めたならば、現在は豊富にあります。
オンプレミスのオブジェクトストレージを使用してはいけない理由
1. 成熟度の低いオブジェクトストレージソリューションの信頼性とパフォーマンスの問題に対処しなければならないため、TCOが高くなる可能性があります。過去2年間、ほとんどのオブジェクトストレージベンダーが次々とHotfixを発行しているのを見てきましたが、誰がこれらの問題を発見していると思いますか?そう、あなたの仲間です。
2. バケットで100TB(場合によっては数十TB)に近づくにつれ、スケーラビリティの問題が発生する可能性があります。これは、残念ながら、多くのオンプレミスのオブジェクトストレージは、通常のファイルシステムの上に「ボルトオン」のソリューションであり、何十億ものオブジェクトに対応できるように最初から設計されているのとは対照的だからです。そのため、Veeamがバニラファイルシステムを使用するのと比較して、パフォーマンスや信頼性の面で良いことはありません。
パーシャルマネージドDRaaS
それは何か? パーシャルマネージドDRaaSは、次のステップとなる責任共有モデルです。DRaaSプロバイダーは、初期設定と継続的なメンテナンスと監視を行い、お客様はサービスにアクセスし、一部の機能にアクセスすることができます。なぜ多くの企業がこのモデルを好むのでしょうか?それは、DR戦略に対してよりカスタマイズされたアプローチと安心感を与えるからです。
最適な方法: サービスプロバイダーは、大規模なITチームやディザスターリカバリーを成功させるための社内スキルが不足している組織にこのモデルを推奨することが多いようです。また、ITチームを他のビジネスプロフェッショナルや目標に集中させたいと考えている企業も、このモデルを利用するとよいでしょう。なお、このモデルにおけるツールは通常DRaaSプロバイダーによって選択されますが、組織は復旧目標に応じて必要なツールを選択することができます。
フルマネージドDRaaS
それは何か? セルフサービスとは反対に、DRaaSプロバイダがサービスの全結果に責任を持つのがフルマネージドDRaaSソリューションである。このモデルでは、リカバリポイント目標(RPO)やリカバリ時間目標(RTO)など、財務的なSLAがリカバリの指標となる場合があります。このモデルでは、DRaaSプロバイダーは、設計、実装、保守監視、テスト、起動のすべてを行います。
以下のような場合に最適です。このモデルは、ITリソースやディザスターリカバリーのスキルが限られている、または全くない組織に最適です。また、ディザスターリカバリーの拠点となる2次、3次拠点がない場合や、ディザスターリカバリーのSLA保証の安全性を求める場合にも最適なモデルです。
バックアップとレプリケーションの違いは?
この2つの用語は大まかに言うと以下のようなものです。
バックアップとは、データのコピーを作成し、オリジナルの紛失や破損に備えてオフサイトに保管することです。
レプリケーションとは、データをコピーし、データセンター、コロケーション施設、パブリッククラウド、プライベートクラウドなど、企業のサイト間でデータを移動させることです。
バックアップとリカバリの違いは?
バックアップはデータ管理に欠かせないものです。バックアップを作成することで、データの損失、破損、マルウェアの攻撃からデータを保護することができます。バックアップコピーを作成することで、紛失や破損、マルウェアの攻撃からデータを守ることができます。
リカバリは、バックアップにアクセスし、破損または紛失したファイルを復元するプロセスです。リカバリーを効果的に行うには、バックアップ・コピーに簡単にアクセスでき、最新の状態である必要があります。最高の状態で、リカバリはシームレスかつ迅速に行われます。
なぜバックアップが重要なのか?
バックアップがなければ、デジタルデータは1台のハードディスクやクラウドなど、1つの場所にしか存在しないため、データは非常に脆弱なままです。スケッチブックを水たまりに落としたり、間違った書類をシュレッダーにかけてしまうように、たった一度の誤操作、マルウェアの攻撃、機器の故障がすべてを消し去る可能性があるのです。また、特にソフトウェアのアップグレードやデータ移行時には、データが破損する危険性があります。
なぜリカバリーがさらに重要なのか?
データのコピーを複数持つことは重要ですが、ビジネスの観点からは、障害からできるだけ早く回復する能力の方がより重要です。アプリケーション全体、アプリケーションのセット、サイト全体、あるいは単一のファイルなど、どのような場合でも迅速なリカバリが不可欠です。
必要な復旧の種類によって、復旧時点目標(RPO)と復旧時間目標(RTO)の指標にかかる性能要件が決まります。RPOは、組織が許容できるデータ損失に影響されますが、RTOは、特にデータとアプリケーションを特定の時点まで一貫して復旧する場合、復旧プロセスがどれだけ自動化されているか(手動ではなく)、復旧計画がどれだけ効果的に実施されテストされているかに依存します。
3-2-1-1-0 バックアップ・ルールとは

サイバー攻撃の数は絶えず増加しており、その頻度はますます高くなり、ハッカーは企業の機密データから利益を得るために、より多くの方法を考案しています。ガートナーの専門家は、2025年までに最大75%のIT企業が1つ以上のランサムウェア攻撃の標的になると予測しています。侵入者は、身代金を支払わないとデータを復元できないようにすることを好むため、こうした攻撃はバックアップに影響する可能性が高い。
つまり、データ保護の今までのゴールドスタンダードでさえ、実際にデータを保護するには十分でない可能性があるということです。データを安全に保つための新しい方法を導入する必要があります。そのような方法の一つが、3-2-1-1-0バックアップルールです。
3-2-1-1-0バックアップ・ルールは、5つの条件を満たすことを要求していることです。
●本番用コピーを含め、少なくとも3つのデータコピーを用意すること。
●テープとクラウドストレージのように、少なくとも2つの異なるストレージメディアを使用すること。
●少なくとも1つは、マシンが物理的に破損した場合に備えて、オフサイトで保管すること。
●少なくとも1つのコピーはオフラインで保管するか、クラウドを使用する場合はイミュータブル(不変)であること(不変とは、このコピーがいかなる状況下でも変更されないことを意味します)。
●バックアップはエラーゼロで完了すること。
この戦略では、データの復元性が最も高く、ランサムウェアからの保護が最も優れています。バックアップのエラーがゼロであれば、データを復元して作業を継続することができます。1つのコピーがオフラインであれば、インターネット経由でマルウェアが到達することはありません。1つのコピーがオフサイトにあれば、オフィスで災害が発生した場合でも、そのコピーを使用することができます。2つの異なるストレージと3つのコピーがあれば、少なくとも1つはどこかで利用可能であり、仕事を再開するのに役立つことが保証される。3-2-1-1-0のルールは、すべての卵を一つのカゴに入れておかないことで、どんな場合でもオムレツを作ることができるようにすることです。
「3-2-1」と「3-2-1-1-0」のバックアップルールの違い
つい最近まで、3-2-1ルールが業界標準であり、データを大切にする企業はこのルールに従っていて、自分たちは大丈夫だと思っていた。しかし、ランサムウェアの攻撃頻度の増加やバックアップ重視の傾向を考慮すると、バックアップにはさらなる保護が必要です。
「3-2-1」と「3-2-1-1-0」のバックアップルールの違いは、前者は本番データの保存に役立ち、後者は競合他社が持つすべての機能を提供し、さらにバックアップ保存のメカニズムを追加している点です。3-2-1-1-0ルールは、マルウェア、物理的な損傷、人的ミスなど、主要なデータセットに何が起こっても、データを取り戻す可能性を大幅に向上させるものである。これは、利用可能な最高レベルの保護機能です。
中堅企業(SMB)にとっての災害対策(DR)への挑戦は
全体的な複雑さ
第一の大きな課題は、今日の典型的な企業環境の複雑さです。最近では、データやワークロードは、さまざまなアプリケーション、コンピューター、サーバー、プラットフォームの間に分散しています。
競争力を維持するためにソフトウェアやハードウェアを見直し、刻々と変化する現実に対応させる必要があるだけでなく、最近終了したローカル環境から主にクラウド環境へのシフトのような大きなプラットフォームの変化にも直面しています。そのため、詳細かつ綿密なディザスターリカバリープランが必要となってきます。さらに、このようなシフトと複雑で変化し続ける技術環境は、計画を見直し、定期的に更新する必要があることを意味します。
増加するコスト
ディザスターリカバリーのコスト要因には3つあります。
●データのコスト まず第一に、データのコストがかかります。顧客の記録、請求書、プロジェクト、ワークフロー、データベースなど、これらすべてが失われる可能性があり、会社にとっては倒産に等しい事態を招きかねません。
●ダウンタイムのコスト:現代のビジネスは、電子リソースに大きく依存しています。そのため、これらのリソースがダウンすると、ビジネスの一部または全体が機能しなくなります。つまり、ダウンタイムが発生するたびに損失が発生することになります。
●追加のリソースと労働力のコスト。最後に、どんな複雑なインフラでも、優れた災害復旧計画を作ろうとすれば、時間とお金の両方を費やすことになります。そして、ここに費やす費用の選択肢は無限にありますが、予算はそうではありません。優れたディザスターリカバリーソリューションを開発、導入、維持するためには、より多くのハードウェア、ソフトウェア、労働力が必要になります。
最初の2つのコストの結果、通常、復旧時間と復旧ポイントの目標をかなり厳しく設定することになります。これらは、ワークロードをどれくらいの速度で復旧させるべきか、どれくらいのデータ損失が許容されるかを示す重要な指標となります。しかし、人件費とリソースにかかるコストもかなり高いので、希望と能力のバランスを取る必要があります。
不適切なディザスターリカバリープロセス
災害復旧ソリューションの設計が不十分であれば、存在しないのと同じことです。DRのワークフローで見落としがないように、以下の4つのステージに注意を向ける必要があります。
●プランニング:復旧時間と復旧ポイントの目標を設定し、ソリューションのアーキテクチャを考え、ハードウェアとソフトウェアのベンダーを選択する必要があります。
●レビュー:この段階では、技術者やCレベルとともに計画を見直し、忘れ物がないか、予算が確保されているかを確認します。
●実施:プランニングとレビューの段階で準備が整ったら、いよいよ実際にソリューションを導入します。
●定期的なテストとレビュー:新しいディザスタリカバリ環境の定期的なテストを予定し、さまざまなイベントであらゆるワークロードやデータを復旧する準備が実際にできているかどうかを確認します。テストが完了したら、計画を見直し、必要に応じて更新してください。
不十分なバックアップ保護
適切なプロセスを導入しているかもしれませんが、使用しているツールにも気を配る必要があります。すべての種類のワークロードが適切にバックアップされているかどうかを定義してください。例えば、クラウド仮想マシンを使用している場合、アーキテクチャを正常に復元できるようにするためには、特定のツールセットと異なるアプローチが必要になります。
新しいコールトゥアクション
次に、バックアップを行う場合、すべてのデータを1つのストレージに保存するのは危険とされています。
このため、最も一般的なバックアップの保存方法である「3-2-1バックアップルール」では、どの時点でも各ファイルのバージョンを最低3つ持ち、そのうち2つはバックアップ、1つはオフサイトに保存することとしています。
最後に、現代のデータセキュリティの脅威であるランサムウェアの攻撃が成功する確率が高いことを念頭に置いておく必要があります。ランサムウェアは、ファイルとバックアップの両方を暗号化することを目的としていることがあります。したがって、バックアップの1つが暗号化されても復旧できるように、3-2-1ルールを守る必要があります。
また、いわゆるエアギャップバックアップの手法を導入することもできます。これは、インフラから完全に切り離されたデータのコピーを持つことです。これは、ランサムウェアから身を守る究極の方法ですが、コストがかかります。
DR=Disaster Recovery
ランサムウェアとは何ですか?
ランサムウェアには様々な種類がありますが、ほとんどのランサムウェアは主に2つのカテゴリーに分類され、いくつかの類似した特徴を持っています。サイバー犯罪者は、通常、標的を絞った電子メール(スピアフィッシング)や、悪意のあるコードに感染したウェブサイトにユーザーを誘導することで、ユーザーのコンピュータを感染させます。
その際、ポップアップで身代金を要求してファイルへのアクセスを遮断したり(ロックスクリーン/スクリーンロッカー型ランサムウェア)、データを暗号化して読み取りやアクセスができないようにする(暗号化型ランサムウェア)などの方法をとります。いずれにしても、身代金を支払ってデータへのアクセスを回復させることが目的です。
ランサムウェアのコスト(身代金)は?
一般的に、身代金はビットコインで支払われ、支払われると復号化キーが成功する傾向にあると言われています。しかし、犯罪者の誠実さやフォローの仕方によっては、データを届けないことも知られています。ランサムウェアのコストは2020年に200億ドル、組織の規模に関わらず平均支払い額は171%増加したと言われています。
中小企業も同様にリスクがあります。評判の回復、生産性、サービスの中断、さらに身代金など、ランサムウェアから回復するためのコストは、平均で140万ドルでした。
ランサムウェアからの復旧は?
復旧ポイントと時間目標 をランサムウェアに対応したディザスターリカバリープランを考える際には、バックアップソリューションによって復元する必要のある復旧ポイントだけでなく、組織が正常な状態に戻るまでの復旧時間や、一般的な復旧能力についても考える必要があります。それだけでなく、組織が正常な状態に戻るまでにかかる回復時間や、一般的な回復能力についても考慮する必要があります。
ランサムウェアに対する予防策
プランのテストとセキュリティアップデートの実施
ディザスタリカバリプランを自社で運用している場合は、パッチやセキュリティのアップデートを怠らないようにしてください。2017年に発生したWannaCryの攻撃も、パッチの適用を怠ったことが原因と考えられます。最新のセキュリティパッチを導入していないなど、小さなことが原因で、システムがサイバー攻撃に対して脆弱な状態になっている可能性があります。このような事態を防ぐために、定期的にチェックしたり、自動パッチをオンにしたりしましょう。
防止策の追加 ランサムウェア対策の大部分は、ランサムウェアが組織のデバイスに感染し始める前に食い止めることです。以下のようなセキュリティコントロールを追加することで、悪意のあるコンテンツがユーザーベースに届く前にある程度防ぐことができます。
●エンドポイント検出と応答(EDR)
●URLフィルタリング
●Webコンテンツフィルタリング
●不審なメールを評価するためのサンドボックス環境
●スパムフィルタ
従業員の教育
不審なリンクを頻繁にクリックしてしまう従業員がいることを心配しているのであれば、彼らを教育し、テストすることも重要です。ランサムウェアがどのようなものかという情報を共有し、従業員をテストすることも必要です。これには、偽装した悪意のあるメールを使って、組織を最も危険にさらす可能性のある人物を確認することができます。
アレイベースレプリケーションとは?
データレプリケーションとは、データをコピーして別のサイトに保存することです。アレイベースレプリケーションは、物理または仮想ストレージアレイレベルで実行されるデータレプリケーションの一種で、ハイパーバイザーのスナップショットには依存しません。アレイベースレプリケーション製品は、特定のストレージベンダーによって提供されます。単一ベンダーのソリューションであるため、これらの製品はその特定のストレージソリューションとのみ互換性があります。
Zertoとアレイベースレプリケーションの違い:
Zertoのソフトウェアベースのプラットフォームは、エンタープライズクラスのレプリケーションソリューションを提供し、柔軟性が高く、仮想環境を最大限に活用することが可能です。Zertoのソリューションはベンダーに依存しないため、特定のベンダーに縛られることはありません。また、アレイベースではないため、レプリケーションプロセスがアレイリソースを消費することはありません。
Zertoは仮想インフラストラクチャ内に直接インストールされるため(個々のマシン上ではなく)、ハイパーバイザと統合してデータのあらゆる変更をレプリケートします。毎回、データはキャプチャされ、クローン化され、リカバリサイトへ送信されます。この革新的なハイパーバイザーベースのレプリケーション・ソリューションは、他のどのレプリケーション手法よりもはるかに効率的で正確、かつ迅速な対応が可能です。さらに、Zertoは継続的にデータを保護するため、ビジネスに支障をきたすようなデータ損失の心配はありません。
アプライアンスベースのレプリケーションとは?
データレプリケーションとは、データをコピーして別のサイトに保存するプロセスです。アプライアンスベースのレプリケーションは、外部の物理アプライアンスを使用し、そのアプライアンス上で直接レプリケーションコードを実行します。このタイプのレプリケーションはハードウェアベースで、1つのプラットフォームに特化しています。アプライアンスベースのレプリケーションは、両方の拠点にハードウェアを追加する必要があるため、クラウド戦略には適していない場合が多いです。
アプライアンスベースのレプリケーションはどのように機能するのか?
アプライアンス・ベースのレプリケーションは、データのローカルコピーまたはバックアップを取り、ローカルアプライアンスに保存します。その後、定期的にタスクを実行して、データをセカンダリアプライアンス(多くの場合、別のサイトにある)にコピーします。このプロセスでは、レプリケーションジョブ間のギャップが大きくなり、データセットに大きなギャップが生じるため、RPOが希望より長くなる可能性があります。
仮想環境の保護に関しては、アプライアンスベースとアレイベースの両方のオプションに、同様のデメリットがあります。
●アプライアンスベースのレプリケーションでは、仮想環境ではなく物理環境がコピーされるため、設定の変更に気づかない可能性があります。
●アプライアンスベースのレプリケーションは、仮想環境ではなく物理環境をコピーするため、構成の変化に対応できず、事業継続計画がすぐに時代遅れになる可能性があります。
●アプライアンス・ベースのレプリケーションは粒度が粗く、仮想化の要件や利点と相反します。
●アプライアンス・ベースのレプリケーションでは、物理管理コンソールと仮想化管理コンソールの2つの管理ポイントが必要であり、常に調整しなければならないため、管理が非常に煩雑になります。
仮想環境を意識したZertoプラットフォームは、仮想環境向けに構築されたエンタープライズクラスのレプリケーションソリューションを提供します。Zertoは、革新的なエンタープライズクラスの仮想レプリケーションと、データセンタとクラウドの両方に対応する事業継続およびディザスタリカバリ機能を提供する最初のソリューションです。
ビジネスレジリエンスとは?
企業・組織は、破壊的な事象に対応するだけでなく、絶え間ない変化にも業務を適応させなければならないことが多くなっています。ビジネスレジリエンスとは、組織がストレスを吸収し、重要な機能を回復し、変化する状況下で成功するための準備を整えていることを意味します。
ビジネスレジリエンス、事業継続、ITレジリエンス
ビジネスレジリエンスには、障害が発生した場合に事業を再開するためのガイドとなる事業継続計画を持つことが含まれます。しかし、組織の運用性を維持するためのプロセスに重点を置く事業継続に比べ、ビジネスレジリエンスはより戦略的で全体的なアプローチとなります。ITレジリエンスとは、データを保護し、計画外の障害発生時にシステムやデータを可能な限り迅速に復旧させることです。ITレジリエンスとビジネスレジリエンスは密接に関係しています。
フェイルバックとは?
フェイルバックとは、災害や障害によって復旧したシステムを元の場所に戻すこと、または主要な生産インフラストラクチャに戻すことです。ディザスターリカバリーに不可欠な要素であり、オンプレミスシステム間、オンプレミスシステムとクラウド間、クラウドとクラウド間、またはこれらの組み合わせでフェイルバックを設定することができます。
フェイルバックはフェイルオーバーと関連しており、メインシステムをセカンダリロケーションやインフラに切り替えることです。フェイルオーバー中は、セカンダリーシステムがお客様のシステムのオンラインと運用を維持し、プライマリーの本番環境で障害が解決されるまでの時間を確保します。障害が解決されると、元のインフラや場所にフェイルバックされます。
フェイルバックはどのように行われるのか?
フェイルバックは必要不可欠なオペレーションですが、見落とされがちです。しかし、ディザスタリカバリおよびデータ保護戦略には欠かせないものです。今日の常時接続社会では、事業継続が必須であると同時に、さまざまな不可避な原因による緊急の中断がこれまで以上に一般的になっています。
●自然災害
●デジタル強盗、ランサムウェア攻撃
●システム障害・停電
フェイルオーバーとは?
フェイルオーバーとは、プライマリサイトや本番サイトで発生した問題の影響を受けないセカンダリサイトやクラウドに、アプリケーションやインフラを復旧させることができるようにすることを指します。フェイルオーバーは事業継続と災害復旧(BCDR)の重要な要素であるため、できるだけシンプルかつ組織的に行うとともに、誤ったフェイルオーバーが発生しないように明確なアクションを設定する必要があります。
フェイルオーバーはどのように機能するのか?
フェイルオーバーは通常、データ、アプリケーションの構成、およびサポートするインフラをセカンダリサイトにリストアすることによって機能します。このプロセスは、通常、この複雑な動作を容易にする専用のソフトウェアまたはハードウェアによって実行されます。マーケットで最も優れたツールは、自動化とオーケストレーションが組み込まれており、復旧作業を簡素化します。これらのツールは、数時間前や数日前のデータではなく、わずか数秒前のデータを復元することも可能です。アプリケーションの一貫性は、フェイルオーバー時のダウンタイムを最小化する上で重要です。これを達成するためには、アプリケーションを理解し、(コンポーネントだけでなく)全体としてリストアできるツールが必要であり、その結果、通常のITオペレーションに迅速に戻ることができます。
ハイパーバイザーベースのレプリケーションとは?
ハイパーバイザーは、仮想マシンとその仮想ディスクをホストし、実行するソフトウェアベースのオペレーティング・プラットフォームです。ハイパーバイザーベースのレプリケーションは、ハイパーバイザーソフトウェアと直接統合され、仮想マシンと仮想ディスクを別のハイパーバイザーや他のストレージに複製するソフトウェアです。
ハイパーバイザーは、仮想マシンとその仮想ディスクをホストし、実行するソフトウェアベースのオペレーティング・プラットフォームです。ハイパーバイザーベースのレプリケーションは、ハイパーバイザーソフトウェアと直接統合され、仮想マシンと仮想ディスクを別のハイパーバイザーや他のストレージにレプリケートするソフトウェアである。
ハイパーバイザーベースのレプリケーションはどのように機能するのか?
仮想化は非常に優れた機能と利点を提供しますが、他の技術が進化しない限り、あるいは進化しない限り、組織はそれらを完全に受け入れることはできません。スナップショットやストレージ層バックアップを使用する旧来のレプリケーション技術を使用しながら仮想環境やハイブリッド環境を管理すると、仮想化のメリットを十分に活用することが難しくなり、クラウドへの移行が阻害されます。
Zertoのようなハイパーバイザーベースのレプリケーションは、仮想マシンや仮想ディスクの変更を監視し、アプリケーションのパフォーマンスに影響を与えることなく、継続的にジャーナルベースのレプリケーションを提供することができます。ハイパーバイザーベースのレプリケーションは、ソースとデスティネーションのストレージの種類に完全に依存しないため、すべてのストレージプラットフォームと仮想化によって可能になったすべての機能をネイティブにサポートします。また、既存のインフラストラクチャにシームレスに統合することができます。
事業継続(Business Continuity)とは?
事業継続(Business Continuity)とは、24時間365日接続・稼働していることを意味します。組織の可用性と機能性は、ブランドの信頼と従業員のモラルを維持するための基本です。事業継続には、計画外の障害に対するコンティンジェンシー・プランや、計画的なダウンタイムを削減するための投資など、戦略的なプランニングが必要です。事業継続は、オフラインの期間が長ければ、悲惨な結果を招く可能性があるため非常に重要なのです。
事業継続と災害復旧の比較
事業継続は、ディザスターリカバリー(DR)と相互に関連し、BCDRという共通の頭字語を形成しています。この2つの用語は同じ意味で使われることが多いのですが、事業継続は組織全体の運用性を維持することを意味し、災害復旧は障害発生後のITシステムの復旧に重点を置いています。
なぜ事業継続が重要なのか?
デジタル進化の今日、事業継続は、実現が困難であるにもかかわらず、当たり前のように期待されるようになりました。定期的にダウンタイムが発生すれば、従業員も顧客も不満を抱くでしょう。また、さまざまな原因により、計画外の中断がこれまで以上に一般的になっています。
●自然災害
●労働争議
●デジタル強盗、ランサムウェア攻撃
●システム障害・停電
しかし、予期せぬ障害に対する計画を怠ると、組織にとって悲惨なことになりかねません。最悪の場合、企業は永久に閉鎖される可能性さえあります。
事業継続計画(BCP)
事業継続計画とは、「組織が障害発生後に対応、回復、再開し、あらかじめ定義された業務レベルまで回復するための指針となる手順書を文書化したもの」と定義されています。災害復旧は、BCP全体のサブセットです。なぜなら、データがなければ、データセンターに入り込んだどんな障害にも翻弄されてしまうからです。
IT部門がダウンしたシステムを復旧させたら、BCPを実行するチームは、できるだけ早く業務を復旧させる計画を開始しなければならないため、事業継続計画を策定することが重要です。一分一秒を争います。
ビジネスインパクト分析(BIA)とは?
BIAは、組織の重要で時間的制約のある業務に着目し、自然災害を含むあらゆる中断、機能停止、または災害が発生した場合に何が起こるかを判断するものです。 BIAは、事業継続の要件とリソース依存に重点を置き、ダウンタイムが組織にどのような影響を与えるかを示すことで、特定のビジネス要件を正当化します。
リスクアセスメントとビジネスインパクト分析
事業継続計画の関連ステップであるリスクアセスメントでは、サイバー攻撃、ネットワーク障害、自然災害、サプライヤー障害、ユーティリティ停止など、具体的に起こりうる災害や障害を特定する。リスクアセスメントでは、これらの脆弱性を軽減することに焦点を当てます。
BIAは、リスクアセスメントの段階で明らかになったリスクが、万一発生した場合にビジネスにどのような影響を及ぼすかを予測しようとします。これにより、ビジネスへの影響を軽減し、ビジネスの継続性を確保するために、それぞれのリスクに対してどのような回復策が必要かを判断します。 BIAの結論は、ビジネスをサポートするすべてのタイプのアプリケーションとプロセスに関連するRTOとRPOの要件を推進することになります。
BIAを実施するには?
ビジネスインパクト分析の方法は業界によって異なるため、一概には言えませんが、以下のリストはBIAで評価すべき多くの分野です。
●計画外の混乱時に起こりうる変化
●計画外の混乱がもたらす法的または規制上の影響
●事業継続に必要な全事業部門のインベントリ
●主要な人材とサポートスタッフ
●障害発生後の依存関係
●テスト計画の妥当性確認
●優先順位と作業順序の決定
BIAは、これらの領域に加え、組織内の複数の部門やビジネスユニットを巻き込んで分析を行い、ユーザのニーズに合った復旧戦略の立案を支援します。
スナップショットとは?
従来のバックアップ方法では、仮想マシン(VM)を保護するためにスナップショットを使用していました。バックアップの際、目的のデータのスナップショットが取られ、専用のバックアップ・ストレージに移動されます。大規模な組織では、このストレージは、拡張性とサービスレベル契約要件を満たすために強力なリソースを必要とします。スナップショットでは、システムリソースが枯渇するため、システム管理者は深夜などの使用頻度の低い時間帯にスナップショットのスケジュールを組む必要があり、データギャップは必要不可欠なものです。
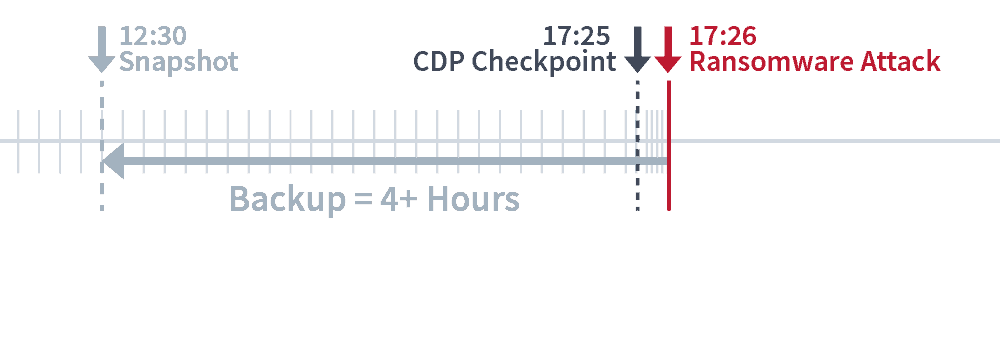
スナップショットの仕組み
スナップショットは、特定の時点から仮想マシン(VM)を複製し、災害からの復旧のために複数の復旧ポイントを維持するためによく使用されます。スナップショットは、VMレベルまたはストレージ・エリア・ネットワーク(SAN)レベルで実行できます。
VMレベルのスナップショットはハイパーバイザーで作成され、パフォーマンスに最も大きな影響を及ぼします。VMレベルのスナップショットベースのレプリケーション・システムは通常、パフォーマンスへの影響を軽減するために、毎日または毎週、業務時間外にレプリケーションを行うように構成されています。
ストレージレベルのスナップショットは、VMレベルのスナップショットに比べてパフォーマンスへの影響は少ないものの、ストレージコントローラの処理能力を必要とし、規模が大きくなるとパフォーマンスを低下させる可能性があります。そのため、ストレージレベルのスナップショットを作成する頻度は、パフォーマンスに影響を与える可能性があるため、非常に限られています。
スナップショットのデメリット
上述したように、バックアップと保護に関して、スナップショットには主に2つの欠点があります。それは、パフォーマンスへの影響と、スナップショットが提供するリカバリポイントの粒度です。
●パフォーマンスへの影響: スナップショットの作成と使用は、本番環境のパフォーマンスに悪影響を与えるため、データを保護するためには慎重な計画とスケジューリングが必要です。この悪影響を避けるため、スナップショットは通常、数時間に1回、場合によっては24時間に1回だけ取得されます。数時間おきに取得したリストアポイントは、ダウンタイムが発生した場合、最大で24時間分のデータ損失が発生するなど、大きな影響を及ぼします。
●非粒度(細かさ): スナップショットはVM単位の一貫性のみをサポートします。つまり、アプリケーションが複数のVMで構成されている場合、スナップショットはすべてのVMで一貫性を維持することができません。このため、ダウンタイムが発生した場合、すべてのVMが異なる一貫性のない時点にリカバリされる可能性があります。
IaaSとは?
IaaSは、インターネット上で必要なコンピューティングインフラを提供し、多くの種類のワークロードのための標準的なモデルとして急速に普及しました。IaaSには物理リソースと仮想リソースの両方が含まれ、クラウド上でアプリケーションやワークロードを実行するために必要なものが提供されます。
IaaSプロバイダーは、通常世界中にある大規模なデータセンターを管理しており、その中には、その上にあるさまざまな層の仮想化コンピューティングリソースを動かすのに必要な物理マシンが入っています。これらのサービスには、通常、自動スケーリングやロードバランシングなどのサポートサービスが付属しています。IaaSには、ネットワーキングとストレージのサービスも含まれます。
IaaSを選択する理由
IaaSの人気は、その柔軟性と費用対効果に大きく起因しています。IaaSは、組織のニーズや要件に応じて、コンピューティング・インフラストラクチャを簡単にスケールアップまたはスケールダウンできるため、柔軟性があります。また、サードパーティ製のディザスターリカバリーソリューションを柔軟に選択することができます。IaaSの費用対効果は、従量課金制であることと、物理的なコンポーネントやその他のプライベートインフラへの支出を削減できることの両方から生まれます。
クラウドの種類は?
パブリッククラウドは、組織がオンデマンドのコンピューティングサービスとインフラストラクチャを管理するためにプロバイダーを雇うコンピューティングモデルである。このプロバイダーは、月額または使用量に応じた料金の購入でコンピューティングリソースを提供し、複数の組織がリソースを共有するのが一般的です。
プライベートクラウドは、コンピューティングリソースが専用で専有されており、基盤となるハードウェア層が他のすべてから分離されていることを意味します。企業は、自社のデータセンター、コロケーション施設、またはプライベートクラウドプロバイダーを利用することができます。
ハイブリッドクラウドモデルは、プライベートクラウドとパブリッククラウドを組み合わせて使用し、クラウドコンピューティングの柔軟な組み合わせを作成します。ハイブリッドクラウドコンピューティングは、インフラと運用を拡張し、組織のニーズに一貫して対応します。
さまざまなクラウドの選択肢は何を提供するのか?
パブリッククラウドサービスプロバイダーは、アクセスのしやすさ、コスト効率、オプションサービスなどを提供します。企業は、データの保存や機密性の低いアプリケーションのために、パブリッククラウドサービスを利用することがよくあります。
プライベートクラウドは、コントロールしやすく、セキュリティも高いが、メンテナンス、アップグレード、ソフトウェアの管理は、通常エンドユーザーが行います。
プライベートクラウドとパブリッククラウドのリソースを組み合わせてハイブリッドクラウドを構築する場合、企業はニーズに合わせてサービスの組み合わせを選択し、運用やコストの変化に応じてアプリケーションやデータを異なるクラウド間で柔軟に移行することが可能になります。
SaaSとは?
SaaSは、ベンダーが提供する完全なソフトウェアソリューションを、通常は消費ベースで提供します。一般的な例としては、電子メール、カレンダー、オフィスツール(Microsoft Office 365など)などがあります。基本的に、お客様は組織のためにアプリケーションをレンタルし、ユーザはインターネットを介してそのアプリケーションに接続します。
インフラからアプリのデータまで、基盤となる部分はすべてサービス・プロバイダーのデータセンターに収容されます。ベンダーは、アプリケーションのアップタイムには責任を負いますが、アプリケーションでホストされているデータには責任を負いません。データに対する責任は、ユーザが負うことになります。
なぜSaaSを選ぶのか?
SaaSは、ソフトウェアとハードウェアのための最小限の初期費用で、高度なアプリケーションにアクセスする柔軟性を組織に提供します。SaaSでは、ハードウェア、ミドルウェア、ソフトウェアの購入、インストール、更新、保守の必要がないため、ERPやCRMなどの高度なエンタープライズ・アプリケーションも、あらゆる規模の組織で手頃な価格で利用することができます。通常は使用した分だけを支払います。SaaSサービスは、自動的にスケールアップとスケールダウンを行います。また、インターネットに接続できる環境であれば、どのコンピューターやモバイル機器からでもSaaSアプリケーションやデータにアクセスすることができます。
SaaSの保護
しかし、ほとんどのSaaSソリューションが責任共有モデルを採用しているため、SaaSデータの保護は組織に委ねられています。ソフトウェア・ベンダーによる基本的な保護はあるものの、SaaSのデータはベンダーの責任ではなく、ユーザの責任となります。つまり、障害、不慮の削除、ランサムウェアの攻撃は、復元不可能なデータと生産性の損失につながる可能性があるということです。
クラウドデータマネジメントとは?
クラウドデータ管理とは、データを自社のサーバーではなく、クラウド上に置くことです。クラウドデータは、オンプレミスのデータストレージを補完することができますが、すべてのデータをクラウドに置くことを選択する企業も増えています。クラウドデータマネジメントの利点は、ユーザがどこからでもデータにアクセスできることです。また、データ管理にクラウドを利用することで、バックアップ、災害復旧、アーカイブがよりシンプルになり、必要に応じてストレージを追加購入できるため、費用対効果も高くなります。ただし、クラウドによるデータ管理は、セキュリティやデータ損失などの問題が発生する可能性があるのが難点です。
なぜクラウドデータマネジメントを選ぶのか?
従来のデータストレージには、いくつかの欠点があります。
・老朽化したハードウェアのアップグレードや交換に費用がかかる
・データセンターの賃貸料の高騰
・スケーリング(拡張)に伴う追加コスト
・コンプライアンスに対応するための専門的な社内ノウハウ
・オンプレミスでのデータ保持のリスク増大
クラウドでのデータ管理は、柔軟性、内蔵のセキュリティ、手頃な価格で、これらの問題を解決します。しかし、クラウドへのデータ移行は複雑で時間がかかり、データを危険にさらすだけでなく、社内のリソースを消費してしまう可能性があります。
リスクマネジメントとは?
リスクとは、ポジティブであれネガティブであれ、組織の目標や目的に影響を与える可能性のあるあらゆる事象を指します。リスクマネジメントでは、リスクとは、これらの目標にマイナスの影響を与える可能性のある事象のことである。サイバーセキュリティの観点では、リスクとは、データ資産や業務の損傷や暴露につながる可能性があるあらゆる事象を指します。このようなリスクをうまく管理するためには、効果的なプロセスや戦略を開発する必要があります。
なぜリスクマネジメントに投資するのか?
サイバーセキュリティの例で説明すると、サイバーセキュリティのリスクはかつてないほど高まっています。例えば、ランサムウェアの攻撃はここ数年エスカレートしており、人質を取って悪質なコードを公開し、企業に破壊的な打撃を与えるケースが増えています。ランサムウェアの攻撃を受けると、企業の重要なデータは暗号化され、身代金を支払うまでアクセスできなくなります。
この攻撃から回復するためには、多額の評判と収益の損失が発生する可能性があります。リスクマネジメントは、サイバーセキュリティの脅威を認識し、事前に計画を立てます。サイバーセキュリティの脅威に対応するための十分な情報と効果的な戦略を準備しておくことで、組織の回復力が大幅に向上します。
Kubernetesのデータ保護とDR
Kubernetes (KOO-bur-NEH-teez) または K8S は、コンテナ化されたワークロードとアプリケーションの管理を支援する強力なオープンソースプラットフォームで、コンテナオーケストレーションの標準となっています。また、コンテナで実行されるマイクロサービス・アーキテクチャの人気と普及に伴い、その使用範囲は拡大する一方です。
Kubernetesの仕組み
Kubernetesは、コンテナ化されたアプリケーションのライフサイクルを管理するための完全なフレームワークを提供します。DevOpsチームは、コンテナ展開の自動化、フェイルオーバー計画の準備、すべてのアプリケーションとグループが正しく動作していることの確認などを、規模に関係なく環境全体を完全に制御するために設定されたスケーラブルなアプローチで行うことができます。コンテナがオンプレミス、クラウド、またはハイブリッドデータセンターのいずれに保存されていても、Kubernetesによってデータとリソースを完全に管理することができます。
コンテナで異なる保護方法が必要
他のデータと同様に、コンテナもバックアップし、保護し、あらゆる災害に備えなければなりませんが、基礎となるさまざまな側面がこれらのプロセスを複雑にしています。まず、コンテナとパイプラインの問題があります。コンテナ・イメージをキャプチャするだけでなく、パイプライン、つまりイメージを生成するためのファクトリーを保護することがより理にかなっています。これには、設定スクリプトやドキュメントも含まれます。また、永続的なアプリケーションデータやボリュームを保護することも重要です。
データ保護とDRのためのKubernetesのオプションは限られています。環境がより複雑になり、より多くのコンテナが組み込まれるようになると、企業はコンテナ化されたアプリケーションと、さまざまなクラウドサービスにある残りのデータとの間でディザスタリカバリのアプローチを調整できるソリューションが必要になります。
クライムはKubernetesに対する次のデータ保護とDRソリューションを提供します。
クラウドストレージ管理のヒントとベストプラクティス
効率的で費用対効果の高いクラウドストレージの管理手法を確立するために、守るべき最高のヒントとコツを紹介します。
▸ ニーズを定義する。 プロバイダーやソリューションを選択する前に、正確なニーズを定義する必要があります。そうしないと、ベンダーをウィンドウショッピングするために多くの時間とお金を費やすことになります。
データを分類する。データをタイプ別に分類し、組織にとって重要なデータセットを定義することが推奨されます。
▸ プロバイダーを綿密周到に選択する。クラウド ストレージ市場は、現代のクラウドの世界で最も競争の激しい市場の一つです。つまり、少なくとも10社の素晴らしい有名ベンダーがあり、あなたに合うかもしれないということです。したがって、コスト削減のためだけに無名業者を選択する必要はありません。大手ベンダーよりも価格が高くなる可能性もあるし、サポートが悪かったり、スタートアップ企業にありがちなトラブルに見舞われる可能性もあります。
▸ クラウド上で安全性を確保する。多くのクラウドストレージベンダーが提供するIDアクセス管理ソリューションは、一見難しそうですが、洗練された便利なものです。データの漏洩や損失を避けるためには、時間をかけて堅牢なデータアクセスポリシーを作成することが最も重要です。主なアクセスパターンとして、最小権限ルールを採用してみてください。
▸ コストをコントロールする。 ベンダーを選択したら、そのソリューション・エンジニアリング・チームと連絡を取り、シナリオに応じた最適なアプローチを検討します。これにより、初期コストを削減し、継続的なコストを監視および管理するためのドキュメントを作成することができます。さらに、ベンダーによっては、すぐに必要でないデータを、より安価なデータストレージの階層に保存することを認めてくれるところもあります。
▸ 構造を作成する。 クラウドへのデータのアップロードや、完全なデジタル文書のワークフローの作成を始める前に、図面を引いて構成図を作りましょう。その構成により、クラウドデータストレージが1年後にゴミサイトとならないようにすることができます。
Microsoft Office 365にバックアップが重要な7つの理由
1. 誤って削除してしまうこと: 1つ目の理由は、実はMicrosoft 365のデータ損失で最も多い懸念事項です。ユーザーを削除すると、その意図があったにせよなかったにせよ、その削除はネットワーク上に複製されます。バックアップを取れば、オンプレミスのExchangeでもOffice 365でも、そのユーザーを復元することができます。
2. 保持ポリシーのギャップと混乱:Microsoft 365 の保持ポリシーは、コンテンツの保持や削除を求める規制、法律、社内ポリシーに組織が準拠できるように設計されており、それらはバックアップではありません。しかし、バックアップの代わりに保持ポリシーに頼ったとしても、管理はおろか、維持することも困難です。バックアップは、より長く、よりアクセスしやすいリテンションを提供し、すべてを保護し、一箇所に保存して、簡単にリカバリできるようにします。
3. 内部セキュリティーの脅威:ビジネスに対する脅威を考えるとき、私たちは通常、外部の脅威から保護することを考えます。しかし、多くの企業は内部からの脅威を経験しており、それはあなたが考えている以上に頻繁に起こっています。ハイグレードなリカバリーソリューションがあれば、重要なデータが失われたり破壊されたりするリスクを軽減することができます。
4. 外部からのセキュリティ脅威: ランサムウェアはますます巧妙になり、犯罪者はユーザーの手を煩わせ、リンクをクリックさせ、身代金を要求するために組織全体のデータを暗号化する方法をより多く見つけてきています。バックアップを取れば、攻撃される前のインスタンスにデータを簡単に復元することができます。
5. 法的コンプライアンス要件:Microsoft 365 には eDiscovery 機能が組み込まれていますが、サードパーティのバックアップソリューションは、バックアップ内を簡単に検索し、あらゆる法規制のコンプライアンスニーズに対応したデータを迅速に復元できるように設計されています。
6. ハイブリッドメールの導入とMicrosoft 365への移行の管理:Microsoft 365 に移行する場合でも、オンプレミスの Exchange と Microsoft 365 のユーザーを混在させる場合でも、交換データは同じ方法で管理および保護する必要があり、移行元のロケーションは関係ありません。
7. Teams のデータ構造:Teams のバックエンドは、多くの人が思っているよりもはるかに複雑です。Teamsは自己完結型のアプリケーションではないため、Teamsで生成されたデータはExchange Online、SharePoint Online、OneDriveなど、他のアプリケーションに存在することになります。このように複雑なレイヤーが追加されているため、データを適切に保護することが最も重要です。
Veeam Backup for Microsoft Office 365 がそれらにお答えします。
スナップショット&イメージレベルバックアップ
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
ディザスターリカバリテストが重要な理由
分散型システムにおけるリカバリーの課題
よく設計された分散システムでは、あるコンポーネントの故障がシステム全体の故障を意味することはないはずです。むしろ、故障はそのコンポーネント自体に分離されるべきです。このような種類の障害を適切に検出し、対応するようにシステムを設計することは可能である。いずれにせよ、災害復旧テスト計画は、現実的な条件が訓練されるように、これらのニュアンスを考慮する必要があります。ここでは、復旧可能な分散型システムを設計する際に対処しなければならない課題をいくつか紹介します:
ネットワーク障害とデータレプリケーション
ネットワークトポロジーは、通常の運用中に変化することがあります。ネットワーク・パーティション、ネットワークの混雑、ポリシー、ルール、セキュリティ・グループ、その他多くの要因によって、システム内のコンポーネント間で断続的または恒久的な切断が発生することがあります。
フェイルオーバー時のプライマリーネットワークとリカバリーネットワークをどのように設計し、運用しているか?また、本番システムと並行してどのようにテストを行うかを理解することも重要です。リカバリーシステムは、オンデマンドでリカバリーできることが分かっていればそれでいいのです。
分散トランザクション管理
分散システムで実行されるトランザクションは、複数のシステムにまたがる可能性があり、それらのシステム間で調整する必要があることを意味します。この調整は、複数のマシンプロセスにまたがるトランザクションを調整することになるため、些細なことではありません。
さらに、トランザクションは、それらの他のマシン上の他のトランザクションや、データベースやファイルシステムなどの外部リソースと調整する必要がある場合があります。
サービス依存性の解決
サービス間でビジネスロジックの実行やサービスコールを連携させるためには、サービス同士を見つけることができる必要があります。ほとんどのマイクロサービス実装では、サービスディスカバリーが必要ですが、モノリシックなアーキテクチャでも応用が可能です。
データの一貫性と回復
多くの場合、ディザスタリカバリは、データの損失や破損を最小限に抑えながら、できるだけ早くサービスを回復することを目的としています。したがって、アプリケーションは、状態を失ったりデータを破損したりすることなく、障害から回復できるように設計されていなければなりません。
バックアップとディザスタリカバリの計画
バックアップは復旧計画に欠かせないもので、データのバックアップコピーがない場合は、ゼロから作り直すことも可能です。
災害復旧テスト + 復旧メカニズムの検証
リカバリープランは複雑なメカニズムに依存しており、本番環境に導入する前にテストが必要です。
ソフトウェアの新バージョンが常にリリースされ、リカバリに影響を与える可能性のある新機能が追加されるため、テストは定期的に行う必要があります。
依存関係と回復の順序の設定
分散システムに障害が発生した場合、コンポーネントやサービス間に多くの依存関係が存在する可能性があるため、どのように復旧させるか判断が難しい場合があります。ここでは、分散システムで依存関係を管理し、復旧の順序を設定するための主な考慮事項を紹介します:
重要な依存関係を特定する: 重要な依存関係の特定:まず、システム内のさまざまなサービスやコンポーネント間の依存関係をマッピングすることから始めます。システムの機能にとって最も重要な依存関係を特定し、これらの依存関係に障害が発生した場合の影響を判断します。
依存関係の優先順位付け: 重要な依存関係を特定したら、システム機能への影響と、他のサービスやコンポーネントが依存する度合いに基づいて、依存関係の優先順位を決定します。
復旧手順を確立する: 各サービスやコンポーネントの復旧手順を定義し、復旧に必要な手順と依存関係を明記します。
復旧プロセスを自動化する: 手動による介入を最小限に抑え、システムの復旧に必要な時間を短縮するため、可能な限り復旧プロセスの自動化を検討します。
復旧計画のテストと検証 :定期的にテストと検証を行い、効果的で最新の状態に保つようにします。復旧のための模擬演習を実施し、潜在的な問題を特定し、計画を改善します。
企業がMicrosoft 365のデータを保護する必要がある5つの理由
1. 誤って削除した場合
ユーザを削除すると、その意図の有無にかかわらず、その削除はビジネスアカウントとメールボックスの削除とともにネットワーク全体に複製されます。Microsoft 365 に含まれるネイティブのごみ箱とバージョン履歴では、データ損失の保護に限界があります。バックアップからの単純なリカバリは、Microsoft 365がデータを永久に削除した後、あるいは保持期間が過ぎた後に大きな問題に変わる可能性があります。
2. 保持ポリシーのギャップと混乱
保持ポリシーを含め、継続的に進化するポリシーは、管理はおろか、対応することも困難です。Microsoft 365のバックアップと保持ポリシーは限定的であり、状況に応じたデータ損失しか管理できず、包括的なバックアップソリューションとして意図されていいません。
3. 内部セキュリティの脅威
一般的にセキュリティの脅威というと、ハッカーやウイルスを思い浮かべます。しかし、企業は内部からの脅威を経験しており、それは想像以上に頻繁に起こっています。企業は、意図的であれ無意識であれ、自社の従業員による脅威の犠牲になっています。ファイルや連絡先へのアクセスはすぐに変更されるため、最も信頼してインストールしたファイルから目を離すことは困難です。マイクロソフトは、通常のユーザと、退職前に会社の重要なデータを削除しようとする解雇された従業員との違いを知る術がありません。さらに、ユーザは感染したファイルをダウンロードしたり、信頼できると思っていたサイトに誤ってユーザ名やパスワードを流出させたりすることで、知らず知らずのうちに深刻な脅威を作り出しています。
4. 外部からのセキュリティ脅威
ランサムウェアのようなマルウェアやウイルスは、世界中の企業に多大な損害を与えている。企業の評判だけでなく、社内データや顧客データのプライバシーやセキュリティも危険にさらされています。外部からの脅威は、電子メールや添付ファイルを通して忍び込む可能性があり、特に感染したメッセージが非常に説得力があるように見える場合、どのような点に注意すべきかをユーザに教育するだけでは必ずしも十分ではありません。定期的なバックアップは、感染していないデータの別コピーを確保し、データの復旧をより確実かつ簡単にするのに役立ちます。
5. 法的およびコンプライアンス要件
法的措置が取られる中で、不意に電子メールやファイル、その他の種類のデータを復元する必要が生じることがあります。マイクロソフトはいくつかのセーフティネット(訴訟ホールドとリテンション)を組み込んでいますが、これらはユーザ企業を法的トラブルから守る強固なバックアップソリューションではありません。法的要件、コンプライアンス要件、アクセス規制は業界や国によって異なり、罰金、罰則、法的紛争はどの企業も遭遇したくないものです。
株式会社クライムではMicrosoft 365ユーザのデータを保護を手助けする多くのソリューションを提供しています。
フェイルオーバーの定義
フェイルオーバーとは、信頼性の高いバックアップシステムに自動的かつシームレスに切り替える機能のことである。コンポーネントまたはプライマリ・システムに障害が発生した場合、スタンバイ運用モードまたは冗長性のいずれかでフェイルオーバーを実現し、ユーザーへの悪影響を軽減または排除する必要。
以前アクティブだったバージョンの異常な故障や終了時に冗長性を実現するには、スタンバイデータベース、システム、サーバー、その他のハードウェアコンポーネント、またはネットワークが、常に自動的に動作に切り替わる準備が整っていなければなりません。言い換えれば、フェイルオーバーはディザスタリカバリ(DR)にとって非常に重要であるため、スタンバイコンピュータサーバシステムを含むすべてのバックアップ技術は、それ自体が障害を免れるものでなければならない。
フェイルオーバーとは何ですか?
サーバーのフェイルオーバー自動化には、パルスまたはハートビート状態が含まれる。つまり、ハートビート・ケーブルは、プライマリ・サーバーが常にアクティブな状態で、ネットワーク内の2つのサーバーまたは複数のサーバーを接続する。ハートビートが続いているか、パルスを感知している限り、セカンダリー・サーバーはただ休んでいるだけである。
しかし、セカンダリー・サーバーがプライマリー・フェイルオーバー・サーバーからのパルスの変化を感知すると、インスタンスを起動し、プライマリー・サーバーのオペレーションを引き継ぐ。また、技術者やデータセンターにメッセージを送り、プライマリー・サーバーをオンラインに戻すよう要求する。手動承認構成の自動化と呼ばれるシステムでは、技術者やデータセンターに単に警告を発し、サーバーへの変更を手動で行うよう要求するものもある。
仮想化では、ホスト・ソフトウェアを実行する仮想マシンまたは擬似マシンを使用して、コンピュータ環境をシミュレートします。このようにして、フェイルオーバー・プロセスは、コンピューター・サーバー・システムの物理的なハードウェア・コンポーネントから独立することができる。
フェイルオーバーはどのように機能するのか?
アクティブ-アクティブとアクティブ-パッシブまたはアクティブ-スタンバイは、高可用性(HA)のための最も一般的な構成である。それぞれの実装手法は異なる方法でフェイルオーバーを実現しますが、どちらも信頼性を向上させます。
通常、同じ種類のサービスをアクティブに同時に実行する少なくとも2つのノードがアクティブ-アクティブ高可用性クラスタを構成します。アクティブ-アクティブ・クラスタは、すべてのノードにワークロードをより均等に分散し、単一のノードが過負荷になるのを防ぎ、負荷分散を実現します。また、より多くのノードが利用可能な状態に保たれるため、スループットと応答時間が向上します。HAクラスタがシームレスに動作し、冗長性を実現するためには、ノードの個々の構成と設定を同一にする必要があります。
対照的に、アクティブ-パッシブクラスタでは、少なくとも2つのノードが必要ですが、そのすべてがアクティブであるとは限りません。最初のノードがアクティブな2ノード・システムでは、2番目のノードはフェイルオーバー・サーバとしてパッシブまたはスタンバイのままになります。このスタンバイ運用モードでは、アクティブなプライマリ・サーバーが機能しなくなった場合でも、バックアップとして機能するように待機しておくことができます。ただし、障害が発生しない限り、クライアントはアクティブなサーバーにのみ接続します。
アクティブ-アクティブ・クラスタと同様に、アクティブ-スタンバイ・クラスタの両サーバはまったく同じ設定で構成する必要があります。こうすることで、フェイルオーバー・ルーターやサーバーが引き継がなければならない場合でも、クライアントはサービスの変化を認識することができません。
アクティブ-スタンバイ・クラスタでは、スタンバイ・ノードが常に稼働しているにもかかわらず、実際の利用率がゼロに近づくことは明らかです。
アクティブ-アクティブ・クラスタでは、各ノードが単独で全負荷を処理できるにもかかわらず、両ノードの利用率は半分ずつに近づきます。ただしこれは、アクティブ-アクティブ構成ノードの1台が負荷の半分以上を一貫して処理する場合、ノードの障害によってパフォーマンスが低下する可能性があることも意味します。
アクティブ-アクティブHA構成では、両方のパスがアクティブであるため、障害発生時の停止時間は実質的にゼロです。アクティブ-パッシブ構成では、システムが一方のノードから他方のノードに切り替わらなけ ればならず、時間がかかるため、停止時間が長くなる可能性があります。
アプリケーションサーバーのフェイルオーバーとは何ですか?
アプリケーション・サーバーは、単にアプリケーションを実行するサーバーである。つまり、アプリケーションサーバーのフェイルオーバーは、この種のサーバーを保護するためのフェイルオーバー戦略です。
最低限、これらのアプリケーション・サーバは固有のドメイン名を持つべきであり、理想的には異なるサーバ上で実行されるべきです。フェイルオーバークラスターのベストプラクティスには通常、アプリケーションサーバーのロードバランシングが含まれます。
フェイルオーバー・テストとは?
フェイルオーバー・テストでは、サーバー障害時にシステムの能力を検証し、復旧に向けて十分なリソースを割り当てる。言い換えれば、フェイルオーバー試験は、サーバーのフェイルオーバー能力を評価します。
このテストでは、何らかの異常終了や障害が発生した場合に、必要な余分なリソースを処理し、バックアップシステムに業務を移行する能力がシステムにあるかどうかを判断します。例えば、フェイルオーバーとリカバリーのテストでは、クリティカルな障害時にしばしば破られるパフォーマンスのしきい値を達成した時点で、システムが追加のCPUや複数のサーバーを管理し、電力を供給する能力を判断します。これは、フェイルオーバーテスト、回復力、およびセキュリティの間の重要な関係を浮き彫りにしています。
フェイルオーバーとフェイルバックとは?
コンピューティングやネットワークなどの関連技術において、フェイルオーバーとは、バックアップ復旧設備にオペレーションを切り替えるプロセスのことである。フェイルオーバーにおけるバックアップ・サイトは一般に、スタンバイまたは冗長化されたコンピュータ・ネットワーク、ハードウェア・コンポーネント、システム、またはサーバーであり、多くの場合、二次災害復旧(DR)ロケーションにある。通常、フェイルオーバーでは、フェイルオーバー・ツールまたはフェイルオーバー・サービスを使用して、一時的に運用を停止し、リモート・ロケーションから運用を再開します。
フェイルバック操作では、予定されたメンテナンス期間または災害の後に、本番稼動を元の場所に戻します。スタンバイ状態から完全に機能する状態に戻すことです。
通常、システム設計者は、CA、HA、または高水準の信頼性が要求されるシステム、サーバー、またはネットワークにおいて、フェイルオーバー機能を提供する。また、フェイルオーバーの実践は、仮想化ソフトウェアの使用により、サービスの中断がほとんどない物理的なハードウェアへの依存度が低くなっています。
フェイルオーバー・クラスターとは何ですか?
フェイルオーバークラスターは、フォールトトレランス(FT)、継続的可用性(CA)、または高可用性(HA)を一緒に提供するコンピュータサーバーのセットです。フェイルオーバークラスターのネットワーク構成では、仮想マシン(VM)、物理ハードウェアのみ、またはその両方を使用できます。
フェイルオーバークラスター内のサーバーの1台がダウンすると、フェイルオーバープロセスが起動します。障害が発生したコンポーネントのワークロードをクラスター内の別のノードに即座に送信することで、ダウンタイムを防ぐことができます。
アプリケーションやサービスに対してHAまたはCAのいずれかを提供することが、フェイルオーバークラスターの主な目的である。フォールトトレラント(FT)クラスタとしても知られるCAクラスタは、メインシステムやプライマリシステムに障害が発生した場合のダウンタイムを排除し、エンドユーザが中断やタイムアウトなしにアプリケーションやサービスを使い続けることを可能にします。
対照的に、HAクラスタではサービスが短時間中断する可能性があるにもかかわらず、ダウンタイムは最小限に抑えられ、自動的に復旧し、データの損失はありません。HAクラスタの復旧プロセスは、ほとんどのフェールオーバークラスタソリューションの一部として含まれているフェールオーバークラスタマネージャツールを使用して構成できます。
広義には、クラスタとは2つ以上のノードまたはサーバを指し、通常は物理的にケーブルで接続され、ソフトウェアで接続されます。並列処理または並行処理、負荷分散、クラウド・ストレージ・ソリューションなどの追加のクラスタリング技術が、一部のフェイルオーバー実装に含まれています。
インターネットフェイルオーバーは、基本的に冗長またはセカンダリのインターネット接続であり、障害発生時のフェイルオーバーリンクとして使用される。これは、サーバーにおけるフェイルオーバー機能のもう1つの部分と考えることができます。
クラウドでのディザスタリカバリー・ヒント
- クロスクラウド戦略の導入: 複数のクラウドプロバイダーを活用することで、ベンダーロックインを回避し、異なるプラットフォームやインフラにリスクを分散することで耐障害性を高める。
- フェイルオーバープロセスの自動化: 自動化ツールを使用して、フェイルオーバープロセスを迅速かつシームレスに行い、ディザスタリカバリイベント中の人的介入を最小限に抑え、エラーの可能性を低減する。
- 頻繁なDR訓練の実施: 定期的な災害復旧訓練を計画、実施し、計画の有効性をテストし、弱点を特定します。関係者全員が参加し、万全の態勢を整える。
- データ重複排除の最適化 高度なデータ重複排除技術を使用して、バックアップに必要なストレージ量を削減し、プロセスをより効率的でコスト効果の高いものにする。
- 明確なRTOとRPO指標を確立する: 復旧時間目標(RTO)と復旧時点目標(RPO)を明確に定義し、文書化することで、ディザスタリカバリ戦略が事業継続の目標に合致するように。
ユーザ・クラウドバックアップのランサムウェア対策ヒント
- バックアップの暗号化を維持 データ保護を確実にし、ランサムウェアやサイバーセキュリティの問題によるリスクを軽減するために、暗号化されたリソースのクロスリージョンバックアップを作成します。
- バックアップネットワークをセグメント化する: バックアップシステムをメインネットワークから分離します。専用のVLANを使用し、バックアップが運用システムと同じネットワークセグメントからアクセスできないように。
- バックアップの完全性を定期的に検証する: バックアップの定期的なチェックと検証を行い、データが破損していないこと、必要なときに正常にリストアできることを確認します。
- ローリングバックアップ戦略を採用する: ローリングバックアップスケジュールを実施し、複数のバージョンのデータを異なる時間枠で保持する。これにより、ランサムウェア感染前の時点に復元することができます。
- エンドポイントプロテクションを使用してバックアップエージェントを保護する: バックアップ・エージェントを実行するすべてのデバイスとサーバーが、ランサムウェアのエントリ・ポイントにならないように、堅牢なエンドポイント保護機能を備えていることを確認します。
ディザスタリカバリー vs. BCPのヒント
- フェイルオーバープロセスの自動化 重要なITシステムのフェイルオーバー・メカニズムを自動化します。フェイルオーバーを自動化することで、リカバリ時間を短縮し、手動による介入を最小限に抑えながら、重要なサービスの運用を維持できます。N2WSのリカバリシナリオ機能を使用すると、フェイルオーバーをシームレスにオーケストレーションできるため、障害が発生した場合でもシステムを迅速にオンラインに戻すことができます。
- 資産インベントリの定期的な更新 すべてのIT資産とその構成の最新のインベントリを維持します。これにより、復旧計画が正確なものとなり、復旧作業中に重要なコンポーネントがすべて計上されるようになります。
- モジュール式の復旧計画を作成する: 障害の具体的な性質に基づいて、個別に起動できるモジュール式のセグメントで復旧計画を策定します。これにより、的を絞った効率的な復旧作業が可能になります。
- 高可用性システムに投資する: 重要なアプリケーションの継続的なアップタイムを保証する高可用性ソリューションを導入する。これにより、ダウンタイムを最小限に抑え、部分的なシステム障害が発生した場合でもサービスの継続性を維持します。
- DR訓練とテストの実施 自動化された災害復旧(DR)訓練を定期的に実施して、復旧計画をテストし、意図したとおりに機能することを確認します。N2WSを使用すると、このようなDR訓練をスケジュールして自動化できるため、復旧プロセスが効果的で、チームが実際のインシデントに備えていることを確認できます。
Azureの為のディザスタリカバリ計画
- 一貫性を保つために、Azure Resource Manager(ARM)テンプレートを使用します: インフラストラクチャのデプロイメント用にARMテンプレートを作成し、維持します。これにより、ディザスタリカバリ時に重要な一貫性のある反復可能なデプロイメントプロセスが保証されます。
- コンプライアンスのためのAzure Policyの実装: Azure Policy を使用して、ディザスタリカバリの構成とコンプライアンス要件を実施し、検証します。これにより、デプロイされたすべてのリソースがディザスタリカバリの標準に準拠していることを確認できます。
- Azure Private Linkを活用したセキュアな接続性: Azure Private Linkを活用して、オンプレミスのネットワークをAzureサービスにプライベート接続することで、攻撃対象領域を減らし、フェイルオーバーおよびリカバリプロセス中の安全なデータ転送を実現します。
- Azure DevOpsによるフェイルオーバーテストの自動化:Azure DevOpsを使用して、ディザスタリカバリのテストをCI/CDパイプラインに統合します。フェイルオーバーテストを自動化することで、手動による介入なしにディザスタリカバリプランを定期的に検証できます。
- マルチテナント管理のためのAzure Lighthouseの導入: マネージドサービスプロバイダーや大企業の場合、Azure Lighthouseを使用して、複数のAzureテナントを1枚のガラスから管理し、ディザスタリカバリシナリオ中の監視と制御を改善します。
Azure Cross-Region Replication(CRR)の利点、制限、課題
- Azure Site RecoveryとCRRの併用:CRRとAzure Site Recovery(ASR)を組み合わせることで、仮想マシン(VM)のレプリケーション、フェイルオーバー、リカバリを自動化できます。ASRは、ディザスタリカバリプロセス全体をオーケストレーションすることができ、より包括的なソリューションを提供します。
- アラートでレプリケーションの健全性を監視 Azure Monitorでカスタムアラートを設定して、CRRプロセスの健全性とステータスを追跡します。このプロアクティブな監視により、あらゆる問題が迅速に検出、対処され、データの一貫性と可用性が維持されます。
- マルチクラウド戦略の導入による耐障害性の強化: Azure内だけでなく、異なるクラウドプロバイダー間で重要なデータを複製することで、ディザスタリカバリ戦略を強化します。N2WSのようなツールは、クロスクラウドレプリケーションを可能にし、クラウドプロバイダー固有の障害に対するフェイルセーフを提供します。
- レプリケートされたデータをエンドツーエンドで暗号化する: レプリケーションプロセス中、静止時と転送時の両方でデータが暗号化されていることを確認します。暗号化キーの管理とアクセスにはAzure Key Vaultを使用し、ディザスタリカバリ計画にさらなるセキュリティ層を追加します。
- レプリケーションとフェイルオーバーを定期的にテストする: Azure AutomationとASRを使用して、ディザスタリカバリ訓練を自動化します。定期的なテストにより、レプリケーションとフェイルオーバープロセスの信頼性と効率性を確保し、運用に影響が出る前に潜在的な問題を浮き彫りにすることができます。
Azure Site Recovery (ASR)活用ヒント
- ストレージ階層を活用してレプリケーションコストを最適化: Azureのストレージ階層(ホット、クール、アーカイブ)をASR内で戦略的に活用する。たとえば、アクセス頻度の低いVMにはクールストレージを使用し、ディザスタリカバリ機能を維持しながらストレージコストを最適化する。
- リカバリプランによるワークロードの優先順位付け: 重要なVMとサービスのフェイルオーバーを優先する詳細なリカバリプランを作成します。この優先順位付けにより、災害時に最も重要なアプリケーションを可能な限り迅速に利用できるようになります。
- 分離された環境でフェイルオーバーを定期的にテストする: 分離された環境で、無停止のフェイルオーバーテストを定期的に実施する。このような訓練により、稼働中のサービスに影響を与えることなく災害復旧計画を検証し、復旧プロセスが意図したとおりに機能することを確認できます。
- レプリケーションにタグベースの自動化を活用する: プロダクション」や「クリティカル」などのタグに基づいて、VM のレプリケーションを自動化します。これにより、特定のタグに一致する新しいVMにASRレプリケーション設定を自動的に適用し、手作業による介入なしにVMを確実に保護することができます。
- マルチクラウド戦略との統合による耐障害性の強化: N2WSなどのツールを使用してASRをクロスクラウド機能と統合することにより、ディザスタリカバリ戦略を拡張します。これにより、異なるクラウド環境間でのリカバリが可能になり、クラウド固有の障害から保護されるため、回復力がさらに高まります。
災害復旧コストの鍵と削減方法
- マルチクラウドDR戦略の採用: ディザスタリカバリのワークロードをクラウドプロバイダーに分散することで、ベンダーロックインを回避し、各プロバイダーのコスト効率を活用します。これにより、耐障害性が向上し、価格設定の柔軟性も高まります。
- 迅速なフェイルオーバーのためのリカバリシナリオの実装: N2WSを使用して、わずか数クリックでフェイルオーバーを自動化し、オーケストレーションします。これにより、ダウンタイムを最小限に抑え、複雑な手動リカバリプロセスの必要性を低減し、最終的に運用コストを削減します。
- 自動化されたDRテストを活用して、コストのかかるエラーを回避します: 自動DRテストツールを使用して、ディザスタリカバリ計画を定期的にテストします。これにより、多額の費用をかけずに復旧プロセスを検証し、運用を中断することなく万全の準備を整えることができます。
- イミュータブルバックアップでDRバックアップにさらなるセキュリティ層を追加します: イミュータブル・バックアップは、データの改ざんや削除を確実に防止するため、余分なコストをかけずにさらなる安全策を提供します。
- クロスリージョンDRとクロスアカウントDRで耐障害性を強化します: N2WSのクロスリージョンバックアップとクロスアカウントバックアップ機能を利用して、地域の停電から保護し、データセキュリティを向上させます。
クラウドでのディザスタリカバリの長所/短所とソリューションの選択
- クロスクラウド戦略の導入: 複数のクラウドプロバイダーを活用することで、ベンダーロックインを回避し、異なるプラットフォームやインフラにリスクを分散することで耐障害性を高める。
- フェイルオーバープロセスの自動化: 自動化ツールを使用して、フェイルオーバープロセスを迅速かつシームレスに行い、ディザスタリカバリイベント中の人的介入を最小限に抑え、エラーの可能性を低減する。
- 頻繁なDR訓練の実施: 定期的な災害復旧訓練を計画、実施し、計画の有効性をテストし、弱点を特定します。関係者全員が参加し、万全の態勢を整える。
- データ重複排除の最適化 高度なデータ重複排除技術を使用して、バックアップに必要なストレージ量を削減し、プロセスをより効率的でコスト効果の高いものにする。
- 明確なRTOとRPO指標を確立する: 復旧時間目標(RTO)と復旧時点目標(RPO)を明確に定義し、文書化することで、ディザスタリカバリ戦略が事業継続の目標に合致するようにする。
害復旧コストに影響を与える4つの要因
ディザスタリカバリ計画のコストは、組織の規模、IT インフラの複雑さ、データ保護とリカバリに対する特定の要件など、いくつかの要因によって大きく異なる可能性があります。
1. 事業規模と複雑さ
事業規模は災害復旧コストに直接影響します。大企業ほどITインフラが複雑な場合が多く、より広範で高度な復旧ソリューションが必要となります。中小企業(SMB)は通常、よりシンプルなITアーキテクチャを持ち、低コストで保護と復旧が可能です。
複雑さは規模だけの要因ではなく、事業運営の性質も影響します。複数の拠点にまたがる多面的な事業を展開する企業は、包括的かつ協調的な戦略が必要なため、復旧コストが高くなります。
2. リスク評価と許容度
リスク評価には、事業運営に対する潜在的な脅威とその発生の可能性を特定することが含まれます。リスクに対する許容度が低い組織は、継続性とデータ保護を確保するために、ディザスタリカバリに多額の投資をしなければなりません。これは通常、冗長システム、頻繁なバックアップ、より強固なセキュリティ対策にかかるコストが高くなることを意味します。
逆に、より高いリスクを受け入れようとする組織は、包括的ではないが、より手頃な災害復旧ソリューションを選ぶかもしれません。このアプローチは、初期コストを削減することができるが、特定のタイプの災害に対してビジネスが脆弱になる可能性がある。リスク許容度とコストのバランスをとることは、効果的な災害復旧計画を策定する上で極めて重要です。
3. テクノロジーの選択
ディザスタリカバリのために選択されるテクノロジーは、コストに大きく影響する。クラウドベースのDR、自動化されたフェイルオーバーシステム、リアルタイムのデータレプリケーションのような高度なテクノロジーは、ディザスタリカバリをより効率的にし、組織のリアルタイムのニーズに適応させることで、コストを削減するのに役立ちます。
テープ・ストレージや冗長化されたオンプレミス・ハードウェアのような伝統的なバックアップ方法は、より高価ですが、最新のディザスタリカバリ戦略では依然として役割を果たしています。例えば、ネットワークから切り離された冗長システムは、ランサムウェア攻撃に対する効果的な対策となります。
4. コンプライアンスと規制要件
規制への準拠は、災害復旧コストに影響する極めて重要な要素です。業界によって基準や要件はさまざまであり、多くの場合、遵守を確実にするために多額の投資が必要となります。
例えば、医療や金融の組織は、厳格なデータプライバシー法を遵守する必要があり、特定のデータ保護要件に対応する復旧ソリューションが必要となります。
災害復旧コストの最適化
災害復旧コストを最適化し、削減する方法をいくつかご紹介します。
クラウドベースの災害復旧ソリューションの活用
クラウド・サービスを利用することで、企業は物理インフラにかかる高額な初期費用を回避することができます。その代わりに、実際に使用するストレージやコンピュート・リソースに対して、多くの場合、サブスクリプションや従量課金で支払いを行います。この柔軟性により、大規模な資本支出をすることなく、変化するビジネス・ニーズに対応できるスケーラブルなソリューションが可能になります。
さらに、クラウドDRソリューションには冗長性と高可用性が組み込まれていることが多く、データとアプリケーションに複数の場所からアクセスできるようになっています。これにより、災害時のデータ損失やダウンタイムのリスクを軽減することができます。
適切なRTOとRPOの設定
RTO(Recovery Time Objective:目標復旧時間)とは、システムのダウンタイムが業務に重大な影響を与えるまでに許容される最大時間のことです。RPO(Recovery Point Objective)は、時間単位で測定したデータ損失の許容量を示す。適切なRTOとRPOを設定することは、効果的なディザスタリカバリにとって極めて重要です。
組織は、これらの目標とコストとのバランスを考慮しなければならない。RTOとRPOをゼロに近づけようと努力すると、法外なコストがかかることがあり、多くの場合、最先端の技術とインフラが必要になります。さまざまなシステムやデータの重要性を評価することは、現実的で費用対効果の高いRTOとRPOの設定を決定するのに役立ちます。
ITシステムの優先順位付け
システムとデータの重要性に基づいて復旧作業に優先順位をつけることは、費用対効果の高いディザスタリカバリに不可欠です。階層化には、IT資産を階層に分類することが含まれ、階層1が最も重要です。これにより、最も重要な要素に集中的に投資することが可能になり、重要な業務の迅速な復旧が保証されます。
重要度の低いシステムは、より低い階層に割り当てることができ、RTOとRPOの基準が高くなる可能性があります。このアプローチにより、組織はリソースをより効率的に割り当て、重要でないシステムへの不必要な支出を避けることができる。効果的な優先順位付けと階層化により、バランスの取れた財政的に持続可能なディザスタリカバリ戦略を実現します。
自動化されたフェイルオーバーとフェイルバック
自動化されたフェイルオーバーは、災害時に重要なシステムが手動で介入することなくバックアップ・インフラに切り替わることを保証し、ダウンタイムを最小限に抑えます。一方、自動化されたフェイルバックは、災害が解決されると、オペレーションをプライマリインフラストラクチャに戻します。これらの自動化されたプロセスは、信頼性とスピードを向上させ、災害による全体的な影響を軽減します。
自動化への投資には初期費用がかかりますが、ダウンタイムと手作業を減らすことで長期的なメリットが得られます。また、自動化によって復旧手順の一貫性が確保されるため、復旧プロセスを複雑にする人為的ミスを防ぐことができます。
ストレージ階層化によるコスト削減
ストレージ階層化では、データを重要度とアクセス頻度に基づいて分類し、それに応じて異なるタイプのストレージメディアに格納します。重要で頻繁にアクセスされるデータは、高価ではあるが高性能なストレージ・ソリューションに保存することができる。一方、重要度が低く、アクセス頻度の低いデータは、より低コストのストレージ層に移すことができます。
クラウドプロバイダーは、ミッションクリティカルなデータ用の高速SSDから、アーカイブデータ用の経済的なコールドストレージオプションまで、さまざまなストレージクラスを提供しています。使用パターンに基づいて階層間でデータを移動する自動化されたポリシーを実装することで、最適なストレージコスト管理が実現します。これにより、ストレージ費用を削減し、重要なデータを迅速に復旧できるようにしてディザスタリカバリを強化します。
N2WSによるクラウドベースのディザスタリカバリ
N2WSは、DR戦略の有効性を高めながら、ディザスタリカバリのコストを大幅に削減します:
- 複数のリージョン、アカウント、クラウドにまたがるDRを自動化します: 自動化されたクロスリージョン、クロスアカウント、クロスクラウド機能により、ディザスタリカバリを簡素化し、安全性を確保します。
- DRテストと訓練の実行と自動化: ゼロコストで自動化されたDRドライランにより、ディザスタリカバリのテストを簡単に実施し、万全の準備を整えることができます。
- リカバリシナリオによるフェイルオーバーのオーケストレーション: ワンクリックで複数のリソースのフェイルオーバーを管理し、復旧作業を効率化します。
- 暗号化リソースのサポート: 暗号化されたリソースのクロスリージョンおよびクロスアカウントDRを実現し、セキュリティのレイヤーを追加します。
- カスタムDR生成によるコスト削減 N2WSのカスタムDR生成オプションにより、ディザスタリカバリコストを削減します。
- イミュータブルバックアップでセキュリティを強化 DRバックアップを不変性で保護し、データの整合性を確保します。
- 頻繁なバックアップ 最短60秒間隔でバックアップを取得し、RPOを最小化します。
- ほぼゼロのRTOを達成: 重要なシステムを数秒で復旧し、業務への影響を最小限に抑えます。
- フェイルオーバーとフェイルバックの自動化 リカバリプロセスを自動化することで、ダウンタイムを短縮し、一貫した信頼性の高い結果を保証します。
- 完全に機能するDRバックアップのリストア: すべてのVPCとネットワーク設定をそのままにバックアップをリストアし、シームレスなリカバリを実現します。
ファイル、アプリケーション、イメージのバックアップの違いとは?
バックアップを管理する際には、選択肢を理解することが重要です。バックアップには、ファイルバックアップ、アプリケーションバックアップ、災害復旧またはイメージバックアップなど、いくつかの形式があり、それぞれ異なる種類のデータを異なる方法で保護するように設計されています。各タイプの主な違いと、それぞれのタイプが最も効果的なシナリオについて見ていきましょう。
バックアップとは?
詳細に入る前に、バックアップとは何か、またバックアップではないものは何かを理解することが重要です。 バックアップとは、異なる時間と場所に、暗号化された複数のバージョンのデータを保存することを指します。 同期サービスや単純なコピー作業とは異なり、バックアップはファイルの複製だけでなく、データ損失や破損からの復旧を目的として設計されています。
それでは、ファイル、アプリケーション、イメージのバックアップの違いについて見ていきましょう。
ファイルのバックアップ
ファイルのバックアップは、その名の通り、個々のファイルやフォルダの保護に重点を置いています。 これには、重要なビジネス文書、スプレッドシート、プレゼンテーション、ビデオ、その他の重要なデータが含まれます。
データの復元に関しては、ファイルバックアップは、必要な個々のファイルをバックアップから探し出し、元の場所または別の場所に復元できるため、復元プロセス中に既存のファイルを上書きしないよう注意しながら、簡単に実行できます。そのため、個々のファイルが紛失したり誤って削除された場合の優れたオプションとなります。
アプリケーションのバックアップ
アプリケーションのバックアップは、ファイルのバックアップという概念を、データベース(多くの場合、業界のソフトウェアやCRMシステムの基盤となる)やアプリケーション全体、あるいは仮想マシンのスナップショットなど、より複雑なデータにまで拡張します。
アプリケーションのバックアップでは、アプリケーションに関連するすべてのデータ(設定や依存関係を含む)が確実に保存されます。多くのビジネスバックアップソリューションでは、アプリケーションのバックアップをパッケージの一部として、あるいは追加機能として提供しています。
災害復旧とイメージバックアップ
災害復旧(DR)とは、より広義の用語であり、組織が壊滅的な事象の後にすべてのシステムとデータを復旧させる能力を指します。バックアップに関しては、災害復旧にはいくつかのオプションがあります。
イメージベースの災害復旧は、最もよく知られたオプションであり、システム全体を1つの「イメージ」として作成する方法です。通常、ブートディスク(CD/DVDまたはUSBスティック)を作成し、新しいコンピュータを起動して、イメージバックアップからすべての情報を取得し、そのシステムを再構築します。
イメージベースのバックアップにより、PCやサーバー全体を復旧することができます。これには、オペレーティングシステム、設定、ドライバ、アプリケーション、およびすべてのファイルの復元が含まれます。バックアップソリューションによっては、イメージを同一または異なるハードウェアに復元することができます。
もう一つのDRオプションは、VHDまたはVHDxファイルを作成し、それを仮想マシンとしてマウントする機能です。これは、物理サーバーを仮想マシンに変換する際に特に有用です。システム復旧に柔軟性をもたらし、システムを稼働させるまでの時間を短縮します。
インクリメンタル・フォーエバー
インクリメンタル・フォーエバー・バックアップは、増分バックアップと差分バックアップの利点を併せ持ち、欠点がないため、人気が高まっています。クラウドバックアップの人気が高まるにつれ、このタイプのバックアップは、必要なストレージ容量(したがってクラウドのコスト)を大幅に削減しながら、送信する必要のあるデータ量も削減できるため、より広く利用されるようになりました。
なぜ年末年始の休みシーズンはランサムウェア のピーク時なのか?
⛔ 誰もが休日のメールに群がり、phishing 詐欺(慈善団体への寄付を募ったり、オンライン注文になりすましたりすることを考えてください)に精通しています。
⛔ オフィスのセキュリティチームは手薄です
⛔ 組織は、ビジネスのピーク時にシステムの変更を凍結することが多いため、セキュリティパッチの適用が遅れる可能性があります。
⛔ オンラインショッピングはピークを迎えており、特に小売業のビジネスは、どんな犠牲を払ってもシステムを稼働させ続けるという大きなプレッシャーにさらされています。つまり、彼らは身代金を支払う可能性が高いということです。
最近のランサムウェアの報告では、ランサムウェアの標的となった人の86%が休暇中または週末に攻撃を受けたという話が裏付けられています。
何をすべきか? 休暇前のチェックリストを少しご紹介します。
✅ 全環境ディザスタリカバリテストの実行
• すべてのリソースを優先して、環境全体のDRテストを今すぐ完了
• テスト結果を文書化し、ギャップがあればすぐに対処
✅ すべての設定の更新
• すべてのネットワークバックアップ設定(VPC、トランジットゲートウェイ、ロードバランサ)の確認
•すべての設定を確認してDRポリシーにクローンします
✅ チームのセキュリティ意識の更新
• MFA プロトコルの確認
• フィッシング検出の練習
✅ 経営陣に情報を提供する
• 監査ログをプロアクティブに共有する
• 成功した DR テストを文書化し、正常なフェイルオーバーを実証する
災害対策 戦略の強化にお困りですか? お問い合わせは:soft@climb.co.jp
NIS2 指令への準拠: ExaGridによる 3-2-1-1-0 バックアップ戦略の実装

NIS2(ネットワークおよび情報セキュリティ指令)は、EU(欧州連合)全域のサイバーセキュリティを強化するための法律です。EU加盟国は2024年10月17日までに国内法に反映し、施行する必要があります。
NIS2命令に準拠し、堅牢なデータ保護を確保するために、組織は3-2-1-1-0バックアップ戦略を採用する必要があります。この戦略には何が含まれ、エクサグリッドがコンプライアンスの達成にどのように役立つかを次に示します。
🔹 3-2-1-1-0 バックアップ戦略の理解
3:データのコピーを3つ保持します。これには、元のデータと少なくとも 2 つのバックアップが含まれます。
2:コピーを2種類のメディアに保存します。たとえば、ローカルストレージとクラウドストレージです。
1: バックアップ コピーを 1 つオフサイトに保管します。これにより、プライマリ ロケーションでの物理的な災害から保護されます。
1: 1 つのコピーが不変であり、変更または削除できないことを確認します。これにより、ランサムウェアやその他の悪意のある活動から保護されます。
0: 定期的なテストを通じてエラーがないことを確認します。これにより、バックアップが機能し、問題なく復元できるようになります。
🔹 ExaGridが 3-2-1-1-0 戦略をどのようにサポートするか
1.複数のバックアップコピー
ExaGridは、さまざまなバックアップ アプリケーションと統合することで、データの複数のコピーの維持を容易にし、コピーをアプライアンスのさまざまなゾーンに保存し、そのうちの 1 つはネットワークに接続されていません。
2. 多様な記憶媒体
ExaGrid システムは、さまざまな種類のストレージ メディアと連携して動作し、ディスクベースのストレージとクラウドベースのソリューションの両方をサポートしているため、さまざまなメディア間でデータの冗長性を確保できます。
3. オフサイトバックアップ機能
ExaGridのレプリケーション機能により、バックアップ データをオフサイトの場所に効率的かつ安全にレプリケーションできるため、1 つのコピーが常にリモートに格納されます。このオフサイト・コピーは、サイト固有の災害から保護します。
4.不変(イミュータブル)バックアップ
ExaGridのランサムウェア リカバリ用の保持タイムロックは、データの 1 つのコピーが不変であることを保証します。つまり、データを変更したり削除したりすることはできません。この機能は、ランサムウェアから防御し、データの整合性を確保するために重要です。
5. 定期的なテストによるエラーゼロ
ExaGrid システムは、定期的なバックアップの検証とテストをサポートしています。自動化された整合性チェックと定期的な復元テストにより、バックアップにエラーがなく、回復可能であり、「エラーゼロ」の要件に準拠していることが確認されます。
💡 NIS2 コンプライアンスにエクサグリッドを選ぶ理由
3-2-1-1-0バックアップ戦略の実装は、NIS2指令に準拠し、包括的なデータ保護を確保するために不可欠です。ExaGridの独自のアーキテクチャと高度な機能により、これらの要件を満たすのに役立つ理想的なソリューションとなっています。エクサグリッドを使用すると、バックアップ戦略が堅牢で、スケーラブルで、安全であることを確認できます。
👉 ExaGridが 3-2-1-1-0 の原則を効果的に実装するのにどのように役立つかについて話し合いたい場合は、クライムまでご連絡してください
サイバー・ボゥルト(Vault;保管庫)とは?
サイバー保管庫は、堅牢なサイバーリカバリと事業継続計画の重要な構成要素です。
サイバー保管庫は様々な機能を提供し、レプリケーションだけでなくサイバーリカバリ対策を追加することで、従来のバックアップとDRソリューションを強化することができます。サイバー保管庫は、データの完全性を保証する特別な統合機能を活用することで、悪意のある特定の問題に対処する、専用に構築された統合ソリューションである場合もあります。
真のデータ保管庫は完全にオフラインであり、バックアップスナップショットを標的とした複雑化するサイバー脅威に直面しても、ミッションクリティカルなサービスを迅速かつ効率的に復旧できるクリーンルームまたは隔離された復旧環境を提供します。
エアギャップされた不変のバックアップ内にデータを集中させることで、サイバー保管庫はデータが無傷のままで適切な人がアクセスできることを保証します。
サイバー保管庫はまた、クリーンなリカバリポイントを迅速に正確に特定するという重要なステップを含むことにより、迅速なリカバリを支援することができます。オーケストレーションと自動化により、迅速なリカバリとデータ損失の最小化をさらに確実にすることができます。
真のサイバー保管庫は、データ損失とダウンタイムの最小化、不変性、クリーンルーム、真のエアギャップ、リアルタイムの検出という5つの鍵を提供することで、多層防御戦略を採用しています。
クライムとVeeamが提供するクラウドオブジェクトストレージ[Veeam Data Cloud Vault]について
ラウドストレージのコスト:その主要な要因
- マルチクラウド戦略を活用して価格交渉力を高める:複数のクラウドプロバイダーを活用して、より良い料金を比較・交渉する。競争が明らかな場合、一部のプロバイダーは長期契約や大量契約に対して割引を提供することがある。
- 地域間レプリケーションを厳選して導入する:重要なデータのみを地域間でレプリケートし、ストレージとデータ転送のコストを最小限に抑える。重要性の低いデータについては、冗長ストレージを控えめに使用し、不要なオーバーヘッドを削減する。
- 高度なモニタリングでアクセスパターンを分析:AWS CloudWatch、Azure Monitor、またはサードパーティの分析プラットフォームなどのツールを使用して、リアルタイムのデータアクセス傾向を追跡します。これにより、ティア配置を微調整し、利用度の低いリソースに対する支払いを回避することができます。
- コストの異常値に対する自動アラートを設定:ストレージや転送コストに予期せぬ急上昇があった場合にチームに通知するアラートを設定します。早期に発見することで迅速なトラブルシューティングが可能になり、予算超過を防ぐことができます。
- 効率性を高めるために事前署名付きURLを使用:事前署名付きURLを使用してクラウドオブジェクトへの一時的な直接アクセスを許可することで、共有データの帯域幅の過剰使用を回避し、不要な転送料金を削減します。
フェイルオーバーとフェイルバック:違いは何か?
フェイルオーバーとフェイルバックは、予期せぬ障害が発生した場合でもITシステムの回復力を確保する、事業継続における2つの重要な概念です。 ビジネスが中断のない運用にますます依存するようになるにつれ、高可用性を維持し、ダウンタイムを削減するためには、この2つのプロセスを理解することが不可欠です。
このガイドでは、フェイルオーバーとフェイルバックが連携してシステムを保護する方法、実際の使用例、そしてビジネスニーズに合わせてこれらのメカニズムを実装する方法について説明します。
フェイルオーバーとは?
フェイルオーバーとは、プライマリシステムに障害が発生した際に、冗長システムまたはスタンバイシステムにシームレスに切り替えることを指します。 バックアップ環境に自動的に切り替えることで、ダウンタイムを最小限に抑え、サービスの可用性を維持するように設計されています。 パンクした際に備えてスペアタイヤを用意しておくようなものです。
フェイルオーバーの目的は、問題が発生した場合でも、業務を円滑に継続することです。SAN、NAS、ネットワークの世界では、複製されたストレージシステムへの切り替え、バックアップサーバーの起動、ネットワークトラフィックの再ルーティングなどがこれに該当します。
フェイルオーバーの仕組み
フェイルオーバーは、プライマリシステムを継続的に監視し、障害の兆候を検出します。この監視には、ハートビート信号、健全性チェック、その他の診断テストが含まれます。障害が検出されると、フェイルオーバーシステムが自動的にセカンダリシステムへの切り替えを開始します。
このプロセスは通常、以下のステップで構成されます。
- 検出:システムがプライマリシステム内の障害を特定します。
- 起動:セカンダリシステムが起動し、オンラインになります。
- リダイレクト:トラフィックと操作がセカンダリシステムにリダイレクトされます。
- 検証:フェイルオーバーが検証され、セカンダリシステムが正常に機能していることが確認されます。
例えば、クラスタ化されたサーバー環境では、1台のサーバーが故障した場合、クラスタ内の他のサーバーが自動的にその負荷を引き継ぎ、アプリケーションとサービスが引き続き利用可能になります。これがフェイルオーバーの仕組みです。
最新の導入事例では、同期レプリケーションや10秒間隔でシステム指標を監視する自動ヘルスチェックなどの先進技術により、フェイルオーバー時間を1分未満に短縮している例が多く見られます。
フェールオーバーおよびフェールバック導入のメリット
フェールオーバーおよびフェールバックを導入することで、企業には以下のような重要なメリットがもたらされます。
- ダウンタイムの削減:システム障害が業務に及ぼす影響を最小限に抑え、重要なサービスの継続的な可用性を確保します。
- データ保護:データを二次システムに複製することで、停電時のデータの損失や破損を防ぎます。
- 信頼性の向上:冗長システムと自動リカバリプロセスを提供することで、ITインフラの全体的な信頼性と回復力を強化します。
これらのメリットは、顧客満足度の向上、収益損失の削減、業務効率の改善など、具体的なビジネス成果につながります。例えば、フェールオーバーとフェールバックを導入したeコマースサイトでは、プライマリサーバーが故障した場合でも顧客が引き続き購入を続けられるため、販売機会の損失を防ぎ、顧客の信頼を維持することができます。
フェールオーバーとフェールバックのベストプラクティス
フェールオーバーとフェールバックを効果的に導入するには、以下のベストプラクティスを考慮してください。
- 定期的なテスト:フェールオーバーとフェールバックのテストを定期的に実施し、システムが正常に機能していること、およびリカバリープロセスが適切に文書化され理解されていることを確認します。
- 自動化されたプロセス:フェールオーバーとフェールバックのプロセスを可能な限り自動化し、手動による介入を減らし、エラーのリスクを最小限に抑えます。
- 包括的なモニタリング:すべての重要なシステムを包括的にモニタリングし、障害を迅速に検知してフェールオーバー手順を開始します。
- 詳細な文書化:フェイルオーバーおよびフェイルバックのプロセスについて、手順、構成、連絡先情報などを含む詳細な文書を作成しておく。
- データの同期:プライマリシステムとセカンダリシステム間のデータの同期が信頼性が高く効率的であることを確認し、フェイルオーバーおよびフェイルバック時のデータ損失を防ぐ。
これらのベストプラクティスに従うことで、企業はフェイルオーバーおよびフェイルバック戦略の効果を最大限に高め、あらゆる潜在的な混乱に備えることができます。
結論
効果的な災害復旧は、今日のデジタル環境における事業継続性を維持するために不可欠です。フェイルオーバーとフェイルバックのメカニズムは、ダウンタイムの短縮、データの完全性の確保、障害発生時のサービス継続の鍵となります。定期的なテスト、自動復旧、適切な文書化などのベストプラクティスに従うことで、企業はITインフラを強化し、ハードウェアやソフトウェアの障害発生時にデータ損失を回避または完全に最小化することができます。
貴社の災害復旧は対応できますか? 第3部 – 柔軟性による回復力の向上

災害復旧において、回復力は究極の目標です。 私たちは、復旧においてスピードと整合性が果たす重要な役割について検討してきましたが、さらに重要な要素がもう一つあります。それは「柔軟性」です。
真の回復力とは、復旧のスピードや正確さだけに依存するものではありません。あらゆる状況、あらゆる環境、あらゆる課題に適応する能力に依存するものです。今日のハイブリッドかつマルチクラウドの世界では、柔軟性こそが俊敏性を引き出し、ビジネスの継続性を確保するための鍵となります。
見落とされがちなレジリエンスの要素
適応能力はレジリエンスの特長です。 企業がハイブリッドおよびマルチクラウド環境に移行するにつれ、硬直的なリカバリソリューションは足かせとなります。 現代のディザスタリカバリには、以下の機能が必要です。
- クラウドの自由: 機敏性を維持するには、複雑性を増すことなく、パブリック、プライベート、ハイブリッドクラウド間でリカバリできることが必要です。
- スケーラビリティ: ビジネスとともに成長し、進化する需要に対応するソリューション。
- 相互運用性:既存のツールやシステムとシームレスに統合し、危機発生時の混乱を最小限に抑えます。
Zerto は、これらの分野において比類ない柔軟性を提供し、お客様の復旧戦略が、必要な場所で、必要な時に、必要な方法で機能することを保証します。
柔軟性がレジリエンスの要である理由
現代のIT環境は、決して静的なものではありません。企業はオンプレミスのインフラストラクチャ、パブリッククラウド、プライベートクラウド、そしてますます増え続けるハイブリッド環境で業務を行っています。これに加えて、進化する脅威の状況、コンプライアンスの要求、そしてかつてないほど迅速なイノベーションのプレッシャーがあります。柔軟性のない災害復旧(DR)戦略では、これらの課題に対応することはできません。
柔軟性のないことによるリスク:
- ベンダーロックイン:単一のプラットフォームに縛られることで、危機的状況下での対応能力が制限されます。
- 移行中のダウンタイム:ワークロードの移動やインフラの近代化が、時間のかかる苦痛なプロセスになります。
- 機会損失:迅速な適応ができないと、適応できる競合他社に遅れをとることになります。
柔軟性の実例
柔軟性は流行語ではなく、測定可能な利点です。災害復旧戦略に柔軟性があれば、以下のような復旧が可能になります。
- どこでも
- オンプレミス、クラウド、ハイブリッドのどの環境であっても、柔軟性があれば、ビジネスにとって最も理にかなった場所でリカバリを行う自由が得られます。Zerto を使用すれば、インフラストラクチャの制約やベンダーの要件に縛られることはありません。
- いつでも
- 災害は都合の良い時を待ってはくれません。リカバリも同様です。柔軟性があれば、計画的な移行時でも、計画外の停止時でも、必要な時にリカバリを行う自信が得られます。
- 妥協なし
- 柔軟性により、データはそのまま維持され、シームレスなリカバリが実現し、業務が中断することなく継続されます。 障壁を取り除き、チームが迅速に行動できるようにすることです。
選択の自由
Zertoでは、ソリューションの核となる部分に柔軟性を組み込んでいます。 この適応性は、IT環境が進化する中で特に価値があります。BroadcomによるVMwareの買収など、業界の大きな変化により、企業は新しい選択肢を模索する必要に迫られています。
価格、パッケージング、サポートに関する不確実性と格闘しているVMwareのお客様に対して、Zertoはシンプルかつ強力な代替案を提供します。当社のソリューションは、業界をリードするRTO(目標復旧時間)とRPO(目標復旧時点)を維持しながら、お客様が選択したハイパーバイザーやクラウド環境へのシームレスな移行をサポートします。VMwareからの完全な移行であれ、マルチクラウド戦略のテストであれ、Zertoは移行に伴うダウンタイムのリスクを低減しながら、移行を可能にします。Zertoは、次のような機能を提供し、企業の復旧を支援します。
- プラットフォームに依存しない:AWS、Azure、プライベートデータセンターなど、クラウドプロバイダーやオンプレミスのインフラストラクチャへの復旧、またはそれら間の復旧、あるいはそれら内での復旧が可能です。
- シームレスなワークロードのモビリティ:災害復旧を緊急時だけでなく、計画的な移行、クラウドの導入、さらにはデータセンターの統合にも利用でき、ダウンタイムを最小限に抑えることができます。
- 中断のないテスト: 回復テストを必要なときにいつでも実行し、日常業務に影響を与えることなく、コンプライアンスと準備態勢を確保します。
- 継続的なデータ保護: 環境に関わらず、RPOとRTOを他に類を見ないレベルで確保します。
現実世界における柔軟性
例えば、多国籍繊維企業であるTenCate Protective Fabrics社では、クラウド戦略の変更の最中にあり、AWSからMicrosoft Azureへの移行が必要でした。Zertoを活用することで、同社はワークロードを移行し、地域製造拠点から水平型グローバルモデルにデータを移行しながら、6秒のRPOを実現することができました。
選択肢による回復力
柔軟性とは、今日の課題に対応するだけでなく、明日の未知の課題に備えることでもあります。Zerto を利用すれば、硬直したアーキテクチャやベンダーロックイン、時代遅れのソリューションに縛られることはありません。むしろ、リカバリ方法を選択する自由が得られ、ビジネスに適応する俊敏性と成功への自信が得られます。
自問してみてください。
- 現在の復旧戦略は変化のペースに追いついていますか?
- ダウンタイムやリスクなしに新しい環境やプラットフォームに切り替えることができますか?
- 復旧方法を選択する自由がありますか?それとも、特定の運用方法に縛られていますか?
Zertoなら、選択の自由が手に入ります。
貴社の災害復旧は間に合いますか? 第2部 – 回復における真の回復力を実現
最初の記事「災害復旧はスピードについていけるか? 第1部 – スピードの必要性」では、災害復旧(DR)におけるスピードの重要な役割について考察しました。 スピードが重要なのは間違いありませんが、それはソリューションの一部にすぎません。 本当の回復力とは、シームレスで包括的な復旧を確実にするために、スピードを超えたものです。
スピードは方程式の一部に過ぎない:真のレジリエンスを実現する復旧
災害が発生した際には、1秒1秒が重要となります。スピードは不可欠ですが、それだけでは十分ではありません。真のレジリエンス、つまりビジネス、評判、将来を守るためには、迅速な復旧だけでは不十分であり、どのような危機的状況においても、正確性、信頼性、俊敏性を備えた復旧能力が求められます。
多くの組織がここでつまずきます。 彼らは、RPOやRTOだけに注目し、スピードはパズルのほんの一部に過ぎないことに気づいていません。 回復のスピードだけでなく、「安全かつ柔軟に回復できるか」という点も重要です。 なぜなら、推測や見込みで回復作業を行うことは、回復とは言えないからです。
回復力の方程式
回復力とは、妥協することなくビジネスを継続できる形で回復する能力です。これを3つの要素からなる三角形として考えてみましょう。
- スピード: もちろん、これは非常に重要です。復旧に時間がかかれば、金銭的な損失、評判の低下、顧客の不満につながる可能性があります。
- 完全性: 復旧したデータが破損していたり、不完全であったり、信頼できないものでは、迅速な復旧も意味がありません。
- 柔軟性: デジタル環境は常に変化しており、復旧ソリューションは、新たな課題、環境、脅威に迅速に対応できなければなりません。
スピードだけではスタートラインに立つことができても、回復力があればレースを続けることができます。
リカバリギャップの危険性
多くのDRソリューションはスピードを約束しますが、データの整合性という重要なニーズには対応していません。たとえば、スナップショットベースのリカバリでは、災害発生前の特定の時点、数時間、あるいは数日前の状態にシステムを復元できるかもしれません。しかし、その欠落した数時間内に作成されたデータはどうなるのでしょうか?その過程で失われたトランザクション、顧客とのコミュニケーション、業務上の洞察はどうなるのでしょうか?
これは単なる技術的な問題ではなく、ビジネスリスクです。
- 顧客の信頼を損なう: 復旧ソリューションが十分でなかったために、顧客のデータが失われたと伝えることを想像してみてください。
- コンプライアンス違反による罰金リスクにさらされる: 規制当局は、データの紛失や誤処理を「復旧ギャップ」という言い訳として認めません。
- ビジネスがさらなる攻撃にさらされる: 復旧が不完全だと、敵対者にバックドアを開いたままにしてしまうことになります。
真のレジリエンスとは、すべてのデータ・バイトが記録され、すべてのシステムが稼働していることを確認しながら、自信を持って復旧できることを意味します。
Zertoによるレジリエンスの実現
Zertoでは、スピードは方程式の一部に過ぎないことを理解しています。そのため、当社のソリューションは以下を提供するように設計されています。
- 継続的なデータ保護:リアルタイム・レプリケーションにより、リカバリ・ギャップを削減し、データの整合性を確保します。
- 自動化されたオーケストレーション:複雑な処理を代行するツールにより、リカバリを簡素化します。
- クラウドの俊敏性:クラウドプロバイダーへの復旧、クラウドプロバイダーからの復旧、クラウドプロバイダー間の復旧を、同じレベルのスピードと信頼性で実現します。
- プロアクティブなテスト:自動化およびオーケストレーションされた無停止フェールオーバーテストにより、最も必要な時に、お客様の復旧計画が完璧に機能することを検証します。
スピード、整合性、柔軟性のいずれかを選択しなければならない競合他社とは異なり、Zertoはすべてを提供します。これにより、迅速かつ包括的な復旧が可能になります。
レジリエンスの実践
当社のお客様であるグローバルな繊維技術企業は、データと業務を脅かすランサムウェア攻撃に直面しました。Zertoを使用することで、データ損失はわずか10秒で、数分でシステムを復元することができました。Zertoを使用する前の攻撃では、12時間分のデータを失い、復旧に2週間を要しました。
不完全な復旧の真のコスト
では、なぜ組織は完全なレジリエンス(スピード、完全性、柔軟性)のソリューションを選ばないのでしょうか? 時代遅れの復旧方法に頼っている組織は、DRソリューションを最新化する初期費用に重点を置いていることが多いのです。 しかし、最新化しないことによるコストはどれほどでしょうか?
- 収益の損失:ダウンタイムが1分増えるごとに、収益が減少します。
- 評判の低下:危機的状況下で業務を継続できない企業に対して、顧客は辛抱強くありません。
- 規制による罰則:コンプライアンス違反は、特にヘルスケアや金融業界などでは、多額の罰金につながる可能性があります。
将来のためのレジリエンスの構築
最新型のDRは、単にスピードだけを追求するものではありません。 あらゆる危機に耐え、自信を持って回復し、次に何が起ころうとも適応できるビジネスを確保することが目的です。 Zertoを使用すれば、高速なリカバリが実現するだけでなく、包括的なリカバリが実現します。
そこで、自問してみてください。
- 貴社のリカバリソリューションは、回復力(スピード、整合性、柔軟性)を備えていますか?
- 今日の複雑なハイブリッド環境に適応できますか?
- 災害が発生した際に、生き残るだけでなく、成功を収める準備はできていますか?
Zertoなら、その答えはイエスです。
貴社の災害復旧はスピードについていけますか? 第1部 – スピードの必要性
誰もが経験したことがあるでしょう。ビデオのクライマックスで恐ろしいスピンホイールが回り続けるのを眺めたり、フライトの遅延が画面に表示され、空港のゲートで足止めされたり、最悪の場合、緊急時にシステムがダウンし、最も必要な時に利用できなくなることがあります。このような瞬間は単なる不都合というだけでなく、最も洗練されたシステムであってもダウンタイムに対しては脆弱であることを思い知らされる瞬間でもあります。今日のハイリスクなデジタル経済において、ダウンタイムは世界中の企業にとっての弱点です。
ランサムウェア攻撃であれ、自然災害であれ、予期せぬシステム障害であれ、災害が発生すると、秒単位で時間が経過していきます。 1秒でも損失が増えれば、それだけ収益のリスクが高まり、信頼が損なわれ、顧客が他社に流れる可能性も高まります。 問題は、災害復旧(DR)計画が試されるかどうかではなく、ビジネスを存続させるのに十分な速さと信頼性があるかどうかです。
現代の復旧の現実:スピードと信頼性のどちらを優先するか?
競合他社の中には、DRにおいてはスピードだけでは危険であると主張する企業もあります。彼らは「あまりにも急いで、あまりにも速く復旧しようとすると、状況を悪化させる可能性がある」と主張しています。この考え方は誤った選択肢を示唆しており、復旧に関してはスピードと信頼性のどちらかを選択しなければならないと示唆しています。
Zertoでは、この考え方を根本的に否定しています。RPOとRTOはオプションではなく、生命線です。迅速な対応とリカバリの整合性への信頼のどちらかを選択する必要はありません。実際、真のレジリエンスには両方が必要です。その理由は次の通りです。
- ランサムウェアは待ってくれません。攻撃はエスカレートし、バックアップを標的とし、急速に広がっています。リカバリが遅い、または不完全であると、敵対者に混乱を引き起こす時間を与えることになります。
- ためらいは高くつく:システムが停止する時間が1分増えるごとに、金銭的および評判上のダメージも増大します。復旧が遅いと、ただ痛手を被るだけでなく、事業継続と廃業の分かれ目になることもあります。
- 信頼は準備から始まる:復旧とは、単にデータを復元することではなく、信頼を回復することです。DRソリューションは、結果をあれこれ考えずに迅速に復旧できる自信を与えてくれるものでなければなりません。
妥協のない復旧スピード
Zertoが他社と一線を画しているのは、信頼できる高速リカバリを実現する能力です。 当社は、スピードとデータ整合性のトレードオフを求めません。 Zertoの継続的データ保護(CDP)により、RPOはわずか数秒に短縮され、RTOは数分単位で達成できます。
競合他社は、定期的なスナップショットからのリカバリや、面倒な手動フェールオーバープロセスに頼っているかもしれませんが、これらのアプローチにはエラーが起こる余地が大きすぎます。 データにギャップが生じたり、数時間前の情報を復旧しなければならなかったり、プレッシャーのかかる状況下でシステムの検証に奔走したりすることになります。 Zertoは、以下の方法でこれらの脆弱性を低減します。
- リカバリギャップの排除:CDPはあらゆる変更をリアルタイムで取得し、データの最新性と安全性を確保します。
- フェイルオーバーの簡素化:自動化されたプロセスにより複雑性を軽減し、ビジネス復旧に集中できます。
- リカバリ期間の短縮:ランサムウェア、人為的エラー、ハードウェア障害など、どのような問題が発生しても、Zertoはシームレスなリカバリを実現し、危機が発生したことさえ忘れてしまうほどです。
スピードと信頼:事例
例えば、グローバルな消費財メーカーである当社のエンタープライズ顧客がランサムウェア攻撃を受けた際、数分以内に業務を復旧・復元することができました。データギャップも発生せず、躊躇することもなく、何よりも顧客の信頼を損なうこともありませんでした。競合他社の場合、手動による遅い復旧プロセスや不完全なバックアップにより、数時間、あるいは数日間もオフライン状態になる可能性がありました。
何が危機に瀕しているのでしょうか?
あらゆる組織がこの現実に直面しています。次に災害が起こるのは「起こるか起こらないか」の問題ではなく、「いつ起こるか」の問題なのです。そして、災害が起こった際には、貴社のDR戦略が競争力を維持できるかどうかを決定します。DRが追いつかない場合、貴社のシステムが回復に苦戦している間に競合他社が追い越してしまい、すでに最下位に甘んじていることになります。
そこで、自問してみてください。
- 貴社のリカバリソリューションは、最新の脅威のスピードに追いつくことができますか?
- どのような状況であっても、自信を持ってデータと業務を回復する準備ができていますか?
- スピードと信頼性を両立するパートナーがいますか?
結論:今こそ加速するとき
Zertoなら、単にリカバリするだけでなく、これまで以上に迅速かつスマートに、そして高い信頼性を実現できます。 遅い、時代遅れの手動プロセスに足止めされる必要はありません。 スピードが足かせになるのではなく、競争優位性となる今日のデジタル世界に適したリカバリを採用する時が来たのです。
AWS環境の災害対策(DR)計画を立てる際に考慮すべきヒント
●DR運用にIAMポリシーを組み込む:DR運用や機密性の高いリカバリリソースへのアクセスを制限する、IAMの専門ポリシーを作成します。これによりセキュリティのレイヤーが追加され、権限のある担当者だけがフェイルオーバーを開始したり、重要なデータにアクセスしたりできるようになります。
●長期データ保持にはS3 Glacier Deep Archiveを利用:アクセス頻度の低いバックアップデータをS3 Glacier Deep Archiveに保存することで、ストレージコストを大幅に削減しながら、必要な時に数時間以内にデータを取得できる能力を維持できます。これは、DR計画の一環として重要なデータを長期間保持するのに最適です。
●重要なワークロードに対してマルチリージョンレプリケーションを実装する:Amazon S3 Cross-Region ReplicationやDynamoDB Global Tablesなどのサービスを使用して、最も重要なワークロードに対してマルチリージョンレプリケーションを設定します。これにより、AWSのリージョン全体が利用できなくなった場合でも、データとアプリケーションは利用可能な状態を維持できます。
●N2WSを活用したDRフェイルオーバーの自動化:N2WS Backup & Recoveryを使用して、新しいインスタンスの起動、DNSレコードの更新、ネットワーク設定の再構成などのフェイルオーバープロセスを自動化します。N2WSは、災害復旧の管理に合理化された信頼性の高いアプローチを提供し、手動介入を減らし、迅速な復旧を実現します。
●AWS Outposts を活用したハイブリッド DR ソリューションの検討:オンプレミスインフラストラクチャを大量に保有する組織では、AWS Outposts を使用して AWS サービスをデータセンターに拡張することを検討してください。このハイブリッドアプローチにより、オンプレミスのデータ主権とコンプライアンスを維持しながら、AWS の DR 機能を活用することができます。
1.ヒューマン・ファイアウォール/厳密調査
テクノロジーだけでは、組織のサイバーセキュリティ態勢を強化することはできません。サイバー攻撃の複雑さと脅威が増す中、組織は多層防御を構築することに注力しなければなりません。つまり、全員がセキュリティリスクと潜在的なインシデントを認識し、不審な点があれば報告することが必要です。この人的保護層の重要性は、多くの侵害が従業員のミスによるものであるという事実にあります。ハッキングの成功は、不注意や単純なミス、サイバー脅威やサイバー犯罪者のやり方に関する知識不足が原因であることが多いのです。
フィッシング、リモートアクセス(RDP)、ソフトウェアアップデートが、サイバー犯罪者が侵入する3つの主なメカニズムであることを知ることは、侵入先を絞り込む上で大きな助けになります。攻撃経路の観点から、最も労力を費やすべきものです。
従業員のサイバー意識はどうか?
サイバーセキュリティの意識向上プログラムを実施し、従業員の潜在的な知識のギャップを特定する。組織のサイバーセキュリティに対する意識の成熟度を、たとえば次のような方法で評価します。 フィッシング・シミュレーション・プログラムを使って、現在のサイバー意識のレベルを明らかにしましょう。
送った覚えのない荷物の配送状況を確認するために、リンクをクリックするようにというメールを受け取ったことはありませんか?あるいは、アカウントのパスワードを確認するためにリンクをクリックするよう求めるものがありましたか?これらはいずれもフィッシングメールである可能性があります。
ヒューマンファイアウォールは、あらゆる種類のランサムウェアに対する防御のための重要なレイヤーです。協力することで、脅威を特定し、データ漏洩を防止し、被害を軽減することができます。より多くの従業員がヒューマンファイアウォールに参加することで、より強固なものになります。
2.常に最新の事業継続計画(BCP)を持っていること
あなたの組織にとって重要なプロセスは何ですか?業務に支障をきたすような出来事があった場合、誰に連絡する必要がありますか?事業継続計画(BCP)が常に利用可能であることを確認することは、たとえすべてが失われ、ロックダウンされたとしても、組織が生き残るために非常に重要です。BCPは別の場所に保存され、不変であり、24時間365日利用可能であることを確認することがベストプラクティスです。BCPは、計画外のサービス停止時にどのように業務を継続するかを概説する必要があります。デジタルのシステムやサービスが復旧するまでの間、業務を継続できるように、手動による回避策をBCPに記載する必要があります。
3. デジタル資産へのタグ付け
サイバーセキュリティ対応計画を成功させるためには、どの資産が組織にとって重要で、どのようにすれば効果的に保護できるかを洞察することが不可欠です。保護を開始する前に、最も効果的な計画を立てるために、これらの資産を特定し、タグ付けする必要があります。デジタル資産にタグを付けることは、干し草の山から針を探すのと、簡単な検索で必要な特定の資産を見つけるのとでは、大きな違いがあります。
4. ヒューマン・ファイアウォール – 教育
ランサムウェア攻撃に対する防御レベルを上げるには、サイバーセキュリティに関するスタッフの教育やトレーニングが非常に効果的かつ効率的です。あなたの組織にはセキュリティの専門家がいないため、基本的な知識を提供し、インシデントに直面したときに取るべき適切なアクションを明確にする必要があります。また、サイバーセキュリティ教育プログラムの有効性を繰り返し検証する必要があります。
多くの組織では、セキュリティ啓発のためのトレーニングは年に1回しか行われていませんが、残念ながらこれでは十分ではありません。ヒューマン・ファイアウォールのトレーニングは継続的に行うべきであり、脅威の発生に応じて従業員は更新や新しいブリーフィングを受ける必要があります。また、従業員は、職種が変わるたびに新しい問題について教育を受ける必要があります。サイバーセキュリティの筋力は、セキュリティ事故の可能性がある前に訓練しておく必要があります。従業員への教育こそが、ランサムウェアに対する最大の防御策であり、保護策であることを忘れないでください。
9.セグメンテーション
最終的に、すべてのセキュリティは、貴重な資産を保護することです。この場合、それはデータですが、その保護には、すべてのレイヤーを含む徹底的な防御戦略が必要です。徹底的な防御戦略を行うには、最も価値のあるデータを特定し、その周りに防御の層を構築して、可用性、完全性、機密性を保護する必要があります。セグメンテーションとは、インフラストラクチャーをゾーンに分割することで、必要なアクセスレベル、共通の制限ポリシーによる制約、ゾーン内外での接続性などを考慮して、オブジェクトを論理的なゾーンにグループ化することです。
ゾーンとは、特定の特性、目的、用途、および/または特定の制限のセットを持つ領域のことです。ゾーンを使用することで、多くの種類のリスクを低減するための効果的な戦略を持つことができます。より詳細かつ効果的な方法で環境を保護しながら、それに関連するコストを削減することができます。すべてを同じレベルで保護するのではなく、システムや情報を特定のゾーンに関連付けることができるようになりました。さらに、規制遵守の対象となるシステムをサブゾーンにグループ化することで、コンプライアンスチェックの範囲を限定できるため、長時間の監査プロセスに必要なコストと時間を削減することができます。
5. 3-2-1 データ保護ルール
3-2-1ルールは、データを保護するための業界標準であり、ランサムウェアとの戦いにおいて究極の防御策となります。このルールでは、重要なデータそれぞれについて、少なくとも3つのコピーを保管し、バックアップデータを2つの異なるメディアに保存するよう求めています。また、データのコピーを1部、オフサイトに複製します。
8. 最小特権の原則
この原則は、ユーザーアカウントまたはプロセスに、その意図する機能を実行するために絶対に必要な権限のみを与えることを意味します。最小特権の原則は、障害や悪意ある行動からデータや機能を保護するための重要な設計上の考慮事項として広く認識されています。
7. K.I.S.S.(Keep it simple and straightforward principle: シンプルでわかりやすく)
複雑すぎる設計はITチームにとって管理が難しく、攻撃者が弱点を突いたり、影に隠れたりすることを容易にします。管理しやすいシンプルな設計は、基本的に安全性が高いのです。K.I.S.S.(シンプルでわかりやすく)の原則に基づき、設計を行うようにしましょう。
6. セキュア・バイ・デザイン
既存のインフラにセキュリティを追加することは、既存のインフラを強化することを考えるだけでなく、新しいインフラや刷新されたインフラを設計するよりもはるかに難しく、コストも高くつきます。仮想インフラストラクチャでは、最初からセキュリティが確保されたマスター・イメージを構築するのがベターな方法です。既知の攻撃ベクトルをすべて取り除き、コンポーネントが追加され、正しく機能するために特定のオープン化や追加ソフトウェアが必要な場合にのみアクセスを開放することが、ベストプラクティスと言えます。こうすることで、すべてのビルドに一貫性が生まれ、最新の状態に保たれるため、安全なベースラインが構築されます。
10. 職務分掌
職務分掌は、企業の持続的なリスクマネジメントと内部統制の基本的な構成要素である。これは、セキュリティに関するタスクと権限を複数の人に分散させるという考え方です。一人の人間がすべてをコントロールできるべきではありません。つまり、一人の人間がすべてを削除する能力も持ってはいけないということです。例えば、ある人が本番環境をコントロールし、別の人がバックアップ環境をコントロールすることです。バックアップの実践においても、プライマリバックアップシステムとは異なる認証と管理下にあるデータのセカンダリおよびオフサイトコピー(すなわちDR)を持つことは、ベストプラクティスと考えられています。
11. デジタル健康法
日常生活において、私たちは個人の衛生や清潔さを重要視しています。手を洗うことで感染症の蔓延を防ぐことができることは周知の事実であり、清潔さを保つことは日常生活の基本です。
しかし、脅威や脆弱性が増加し、デジタルとの接点が広がるにつれ、デジタル・インフルエンザに感染する危険性が常に存在することになります。実際のインフルエンザと同じように、いくつかの基本的なデジタル衛生習慣に従うことで、デジタル世界を移動する際のリスクを低減する方法があります。優れたデジタル衛生習慣に従うことで、データを健康に保ち、プライバシーを保護し、セキュリティを損なわないようにすることができます。
重要な実践例:
– 各ログインソースにユニークなパスワードを作成する。こうすることで、あるパスワードが破られたとしても、盗まれたパスワードで他のアカウントにアクセスされることがなくなります。
– パスワードマネージャーを使用する。100を超えるパスワードを覚えるのは大変です。優れたパスワードマネージャーを使えば、すべてのログイン情報を管理でき、固有のパスワードを簡単に作成し、使用することができます。
– 多要素認証(MFA)を利用する。MFAを設定することで、さらなるアカウントの安全性を確保することができます。
– 堅牢なパスワードポリシーを使用する
– アカウントのロックアウトポリシー
– 未使用のデバイス、アプリケーション、退職した社員、必要のないプログラムやユーティリティを削除する。
– パッチ管理:使用中のソフトウェア、ハードウェア、ファームウェアがすべて最新のソフトウェアレベルで動作していることを確認する。
12. バックアップ
デジタル健康法はレジリエンスを高めるための重要な要素です。定期的にバックアップをとっていれば、サイバー脅威は災害ではなく、むしろ不勝手なものになります。1日分の仕事を失うことはあっても、すべてを失うことはないでしょう。特定の種類のデータをどれくらいの頻度でバックアップするか、クラウドサービスを使うか、物理デバイスを使うかは、必要なサービスやセキュリティレベルに基づいて選択する必要があります。
ランサムウェアは、ファイルを暗号化することで、自分自身のデータからあなたを締め出す。このため、適切なバックアップはこの種の攻撃から回復するための優れた方法です。バックアップがあれば、暗号化されたファイルを最近のバックアップリポジトリにあるコピーと簡単に交換することができます。バックアップに戻すと、最新のデータの一部を失うかもしれませんが、サイバー犯罪者にお金を払ってファイルを復元してもらうよりは確実によいでしょう。
13. 暗号化について
暗号化により、許可された者だけがあなたの情報にアクセスできるようにします。あなたの情報が定義されたセキュリティ・ドメインから離れるとすぐに、あなたの情報があらかじめ定義された適切なレベルで暗号化されていることを確認します。暗号化自体は干渉を防ぐものではありませんが、権限のない第三者があなたの情報を読むことを禁止することができます。暗号化は、他のセキュリティ対策が失敗した場合に、機密データを保護するのに役立ちます。
0. ランサムウェア対策のための13のベスト・プラクティス
ランサムウェア対策のための13のベスト・プラクティスを紹介しています。
https://www.climb.co.jp/faq/faq-category/ransamware-best13
ブログでも各種ランサムウェア対策を紹介しています。
Veeam -トラブルシューティング (1)
クラウド・バックアップ (60)
適切なEC2インスタンスタイプの選択には
EC2サービスは、おそらくAWSでのクラウドの旅で最初に選ぶものの1つでしょう。60以上のインスタンスタイプがあり、最適なものを選ぶのは至難の業です。まずは、インスタンスの目的を考えてみてください。それを元に、以下の表を見て最適なタイプを絞り込むことができます。
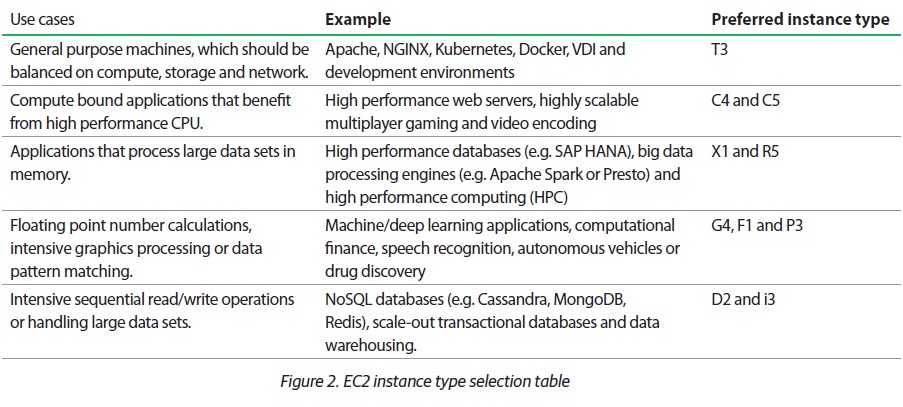
ライトサイジングとは、性能要件を満たした上で、最も安価なオプションを選択することであることを忘れないでください。経験則では、長期間にわたってインスタンスのリソース使用率が80%になるようにすることです。
常に最新のCPUを選択すること
技術は止まらず、CPUメーカーはほぼ毎年、より高性能で消費電力の少ないCPUを発表し、AWSもそれを実装しているので、必ず定期的にインスタンスタイプ表に戻ってくることです。例えば、10台のインスタンスをc4.xlargeからc5.xlargeに変更するだけで、年間約2,500ドルの節約になり、同時に各インスタンスに多くのRAM(16 -> 20GB)と約5%の性能向上を実現します。
このヒントは、AWS Compute Optimizerを確認することです。このツールは、このタイプの変更をアドバイスすることができます。
一時的なデータ用にEC2インスタンスストアを検討する
通常、AWSユーザーはEC2インスタンスを新規にセットアップする際に、EBSストレージ(つまりディスク)に注目することになります。それらのディスクは、インスタンスにアタッチしたり、インスタンスからデタッチしたり、データ保護のケースでスナップショットしたりすることができます。インスタンスが停止しても、データはディスク上に残り、どこにも行きません。
もう1つ、検討する価値のあるオプションがある。EC2インスタンスストアを経由してローカルディスクを使用します。これらのディスクの大きな違いは、対応するインスタンスが停止されると、ディスクがクリーニングされることです。ユーザーはインスタンスの使用料のみを支払っているため、「無料」です。
貴重なデータにローカルディスクを使いたくないのは理解できるが、キャッシュやログなどの一時的なデータにはぴったりなケースもあります。また、下敷きのストレージは高速なSSD、あるいはNVMeなので、十分なパフォーマンスがありますので安心ください。EC2インスタンスストアを利用することで、EBSの消費量も少なくなり、月々の請求額も小さくなります。
スポットインスタンスを活用する
スポットインスタンスのコンセプトは、パブリックマーケットと比較するとよく理解できます。価格は、利用可能な未使用のAWS EC2容量の供給と需要に基づいて変動します。AWSユーザーはそこに行き、希望する価格を入札することができす。もし需要がそれほどなければ、市場は一時的に低い価格で売ることに同意し、結果として通常価格の3倍から6倍の値下げをすることになります。
では、何が問題なのか?需要が高まる瞬間には、必要な資源を受け取れないかもしれない。価格がその希望する上限を超えると、プロビジョニングされたインスタンスは短期間で自動的に終了してしまいます。もちろん、重要なデータをこのような変動にさらしたいと思う人はいないでしょう。しかし、このモデルがうまく機能するケースも多くあります。ロードバランサーの背後にあるメディアレンダリング、ビッグデータ、分析、Webサービスなども、この機能の最初の候補の1つになるはずです。
例えば、ここにノースバージニア地域のスポットインスタンスの価格履歴があります。過去3ヶ月間のt2.largeインスタンスの需要と価格設定が示されています。

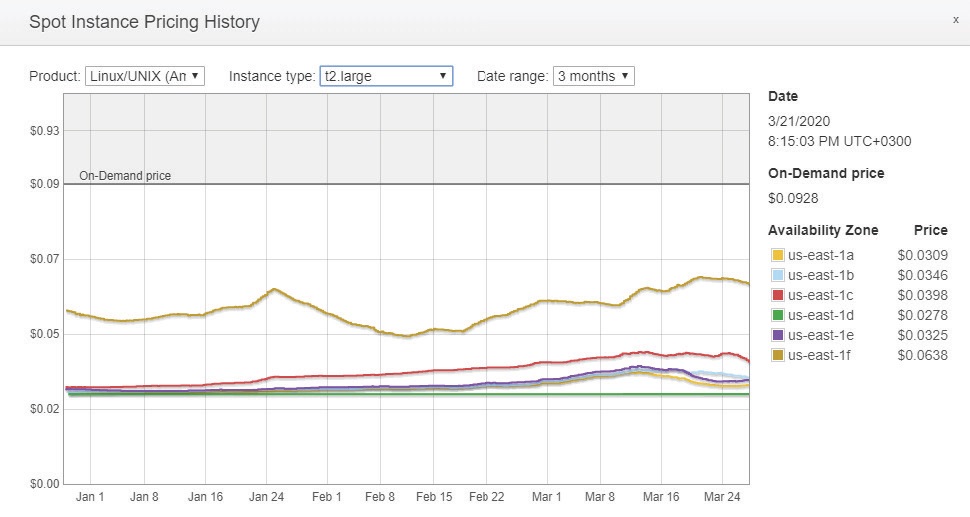
上の表からわかることは:
●実質的な価格はオンデマンドの3分の1程度になる可能性がある
●6つのAZはすべて、平等ではないものの、余裕のあるキャパシティを持っている
●価格が安定しないので、最低料金で入札しない
この技術をアクティブなCloudWatchとAuto Scalingで補完すれば、2分間の終了アラートを受信した時点で、システムは負荷をリバランスし、オンデマンドインスタンスに切り替わることができます。
忘れてはならないネットワークコスト
AWSのネットワークは独自の論文に値するものですが、物事をシンプルに保つために、あまり深入りせず、とにかくここでいくつかの重要なヒントに触れておくべきだと思います。
オンプレミスサイトとAWSの間で大量のトラフィックがやり取りされる場合、Direct Connection機能を使えば、より安定したネットワーク体験、帯域スループットの向上、接続の安全性を確保することができます。
静的コンテンツ(画像、動画、音楽など)は、S3とCloudFrontの組み合わせでより良く、より安価に配信することができます。世界の様々な地域にある素晴らしいエッジサーバーのセットで、エンドユーザーはより近い場所にあるサービスキャッシュから来るデータを得ることができます。
異なるAWSサービス間のトラフィックフローを分析する。VPCからS3のような他のサービスへのトラフィックがエンドポイントを経由するようにVPCエンドポイントを構成することで、インターネットや公共ネットワークをバイパスし、より安全で安価な接続を実現します。
可用性ゾーン間のトラフィックについても、別の費用がかかるので、忘れないようにしましょう。フォールトトレランス・アーキテクチャを再考してください。すべてのサービスに必要でない場合もありますし、他の技術で実現できる場合もあります。
それに応じて地域を検討する
AWSのサービスの価格は、データセンターが置かれている物理的な場所に依存することに気づくのは簡単です。これは当たり前のように聞こえるかもしれませんが、理にかなっている場合は価格の安いリージョンにリソースを移行してください。
現在の価格を計算して、小さな例を紹介しましょう。ヨーロッパでt3.2xlargeインスタンスを10台、それぞれ150GB SSD gp2のディスク容量で稼働させる必要があるとします。ドイツ・フランクフルトのデータセンターを選択した場合、AWSのコンピュート利用料金は0.5312ドル/時間、一方スウェーデン・ストックホルムのデータセンターでは0.4928ドル/時間となる。さらに、ストレージコストとして1GB/月あたり$0.119 vs $0.1045を加え、1年間運用します。この差は、同じサービスであれば、24*365*10*$0.0384+$0.0145*1,500GB*12m = $3,364 + $261 = $3,625 の年間コストダウンに相当し、単に安い地域を選択したことになるのである。
これは、価格の高い地域をすべて、一度に捨てなければならないということなのでしょうか?そうとは限りません。先ほども言ったように、意味があるときにやればいいのです。アジアで事業を展開し、ユーザーに最も低いレイテンシーを提供しようとする場合、アプリケーションを米国に移動させる理由はないでしょう。ただし、負荷の低いサービスや静的なコンテンツについては、米国に移すことも可能です(詳しくは後述します)。もうひとつ注意しなければならないのは、個人情報の取り扱いです。GDPR(一般データ保護規則)やCCPAのような世界的な規制が障害となる可能性があります。
サービス利用を予測し、先行コミットすることを目指す
パブリッククラウドの柔軟性、CAPEXからOPEXへの移行が言われていますが、請求書を減らすAWSの機能であるRI(Reserved Instances)や節約プランなどは、皮肉にもCAPEXに戻るように見えてしまうものです。しかし、実際に50%以上の割引が得られるのですから、誰もが「導入のベストプラクティス」リストに挙げるべきでしょう。
まずは、EC2インスタンスの時間単価の割引とオプションの容量予約を提供するRIを検討することから始めましょう。1年または3年のコミットメントと引き換えに、インスタンスコストの割引を受けることができます。オンデマンドインスタンスは、無制限の柔軟性を持ってワークロードをプロビジョニングすることを好む人にとって良い選択肢となる。しかし、負荷が予測可能なワークロード(Webサービスなど)を常時稼働させる場合は、RIの方がはるかに優れています。
節約のまとめ。
• 予約時間が長いほど、割引率がアップします。
• 前払い金額が多いほど割引率が高くなる(ただし、前払い金0円も可能)
• 標準クラスはコンバーチブルより安い(ただし、インスタンスタイプは作成後に変更できない)
コンバーチブルインスタンスは、サイズダウンやAWS Marketplaceでの販売ができないため、注意が必要です。最小のインスタンスから始め、必要に応じてアップグレードすることで、最大36ヶ月間の月々の支払いを約束させられることを避けることができます。
業務に適したツールを使用する
Azure のデータを保護するためには、Azure を意識した最新のバックアップソリューションを使用することが重要です。主にオンプレミス用に設計されたレガシーバックアップツールは、Azureデータの一部を保護できるかもしれませんが、すべてのデータを保護することはできない可能性があります。例えば、サーバーレスデータベース内にデータがある場合、レガシーバックアップアプリケーションでは、おそらくそのデータをバックアップすることはできないでしょう。
レガシーバックアップツールでは、バックアップデータを保存するためのオプションが制限されている場合があります。例えば、特定のワークロードをクラウド上で実行することを意識的に決定した場合、そのワークロードのバックアップを構内に保存することは意味をなさないかもしれません。しかし、レガシーバックアップツールの中には、クラウドベースのバックアップターゲットを使用するオプションがないものもあります。
自動化で効率的に業務をこなす
バックアップの自動化には、さまざまな形態があります。例えば、特定の時刻にバックアップを実行するようにスケジュールを組むといった簡単なものです。しかし、最新のバックアップソフトウェアでは、バックアップのスケジューリング以外の自動化も可能です。これまでITプロフェッショナルは、バックアップを作成するだけでなく、バックアップに関連する様々なタスクに対処しなければなりませんでした。しかし、今日ではこれらのタスクの多くを自動化することができます。例えば、バックアップのライフサイクル管理やバックアップのテストを自動化することができます。
ストレージ階層を効果的に利用する
Azureのバックアップストレージのオプションを評価するとき、必然的にストレージ階層を選択する必要があります。利用可能な階層は、コスト、可用性、およびパフォーマンスに関してかなり異なっています。パフォーマンスの高いストレージ層は、一般的にコストが高くなります。
バックアップの保存期間によっては、ギガバイトあたりのコストが最も低い階層が、必ずしも全体のコストを低く抑えられるとは限らないことに留意する必要があります。これは、Cool Tier の最低データ保存期間が 30 日間であるのに対し、Archive Tier の最低保存期間が 180 日間であるためです。つまり、これらの階層にデータを保存する場合、実際にはそれほど長期間バックアップを保持する必要がない場合でも、少なくとも最低期間データを保存するために費用を支払うことになります。
バックアップデータの隔離
バックアップを保護するために組織ができる最も重要なことの1つは、バックアップをオンラインで維持しないことです。ランサムウェアの亜種は、特にバックアップサーバーをターゲットに設計されているため、被害者は身代金を支払う以外に選択肢がありません。以前は、テープは、空隙のあるバックアップを作成したい組織にとって、最適なメカニズムでした。バックアップが作成されると、テープはテープドライブから取り外されるだけでよかったのです。しかし、クラウドバックアップの場合、テープという選択肢はありません。Azureのアーカイブ層はオフラインに保たれ、レイテンシは2時間です。また、クラウドストレージへのアクセスは、多要素認証を使用したアカウントに限定することもできます。これにより、犯罪者が漏れたパスワードや総当たりパスワード攻撃でバックアップにアクセスすることを防ぐことができます。
データモビリティの重要性を考える
クラウドバックアップの設置場所は重要です。ハイブリッド/マルチクラウドのサポートに関するビジネス要件は増加傾向にあり、特定のクラウドベンダーの選択と離脱の両方に関して、柔軟性が重視されています。
そのため、共通のコントロールペインとポータブルなバックアップフォーマットが可能なバックアップソリューションが必要とされています。これにより、異なるプラットフォーム間でデータを移動することが容易になります(オンプレミスからクラウドへ。クラウドからオンプレミスへ、クラウドから別のクラウドへ)、プラットフォームのロックインを回避することができます。
単一のバックアップソリューションの使用
現在、多くの企業が複数のバックアップ製品を使用しています。オンプレミスのリソースを保護するために1つのバックアップツールを使用し、Azureにあるリソースを保護するために別のツールを使用している場合があります。可能であれば、バックアップ操作を1つのバックアップツールに統合するのがベストです。これにより、バックアップのサイロ化を解消し、クラウドと自社データセンター間でシームレスにデータを移動させることができます。同時に、単一のバックアップソリューションを使用することで、バックアップオペレーションを大幅に簡素化し、ライセンスコストを削減し、組織のデータ保護戦略におけるギャップの可能性を低減することができます。
復旧のための能力を持つことが重要
災害がどのような規模で発生し、どのようなシステムに影響が及ぶかを予測することは不可能です。そのため、バックアップソリューションでは、データを異なるシステムやクラウドにリストアできることを確認することが重要です。また、精度の高いリストアが可能であることも重要です。例えば、仮想マシンの場合、仮想マシン全体をリストアできる必要がありますが、仮想マシン内の1つのファイルも同様に簡単にリストアできる必要があります。
忘れてはならないネットワークコスト
AWSのネットワークは独自のものですが、物事をシンプルに保つために、あまり深入りせず、とにかくここでいくつかの重要なヒントに触れます。
1)オンプレミスサイトとAWSの間で大量のトラフィックがやり取りされる場合、Direct Connection機能を使えば、より安定したネットワーク体験、帯域スループットの向上、接続の安全性を確保することができます。
2)静的コンテンツ(画像、動画、音楽など)は、S3とCloudFrontの組み合わせでより良く、より安価に配信することができます。世界の様々な地域にある素晴らしいエッジサーバーのセットで、エンドユーザーはより近い場所にあるサービスキャッシュから来るデータを得ることができます。
3)異なるAWSサービス間のトラフィックフローを分析する。VPCからS3のような他のサービスへのトラフィックがエンドポイントを経由するようにVPCエンドポイントを構成することで、インターネットや公共ネットワークをバイパスし、より安全で安価な接続を実現します。
4)可用性ゾーン間のトラフィックについても、別の費用がかかるので、忘れないようにしましょう。フォールトトレランス・アーキテクチャを再考してください。すべてのサービスに必要でない場合もありますし、他の技術で実現できる場合もあります。
マスターアカウントの下にユーザーを統合する
組織内で複数の人がAWSを操作する必要がある場合、統合課金によって支払いが簡単になるだけでなく、ある閾値に達すると、S3などの消費リソースを割引くことができます。また、AWSのティアによっては、使用量が多いほど価格が下がったり、事前にインスタンスを購入することで割引が適用されたりするものもあります(上記のRIやSaving Plansのようなもの)。さらに、未使用のリソースは、ある子アカウントから別の子アカウントに再配布することができます。ここで先に述べたコスト最適化ツールを適用し、多数のアカウントを運用する際の組織の混乱を防いでください。
標準ツールで消費量を監視する
AWS Cost Explorerは、すべてのお金がどこに行くのかを可視化し、最も消費されるサービスに対応することが非常に簡単にできるため、あなたの頼りになるはずです。これは、実施された分析に基づいて、興味深いパターンを特定し、根本的な原因まで掘り下げることができます。
コストエクスプローラー インスタンスタイプの消費を表示
AWS Compute Optimizerは、アカウント(またはマスター1つ下のすべてのアカウント)に対して収集され分析されたデータに基づいて、AWSリソースの最適化の機会の概要を提供します。

AWS Compute Optimizer:EC2インスタンスに対する推奨事項。
AWS Pricing Calculatorを実行に移す
AWS Pricing Calculatorは40以上のAWSサービスに対するアカウント支出を見積もることができるツールです。しかし、時には他の競争戦略を決定するのに非常に役立つことがあります。例えば、オンデマンドEC2インスタンスからRIやSavings Planのオファリングに切り替える場合、各機能が提供する割引を確認することができる。表に値が追加されるたびに、結果的に計算が表示され、実際のサービスを選択するのに役立ちます。
未使用のインスタンスやデータベースを自動でオフにする
アイドル状態のリソースは、AWSの請求書の大きなコスト要因になり得ます。未使用のインスタンスやデータベースをアイドル状態にしておくことは、使用されていないものに対して料金を発生させることを意味します。例えば、平日の日中しかアクセスしない開発環境がある場合、24時間365日稼働させないことが最良の選択です。夜間に停止し、翌朝と週明けに起動する(ヒント:Auto Instance Schedulerを参照)ことで、コストをほぼ半分に抑えることができます。また、Amazon CloudWatchのアラームを有効にして、指定期間以上アイドル状態だったインスタンスを自動的に停止または終了させるのも良い戦略です。
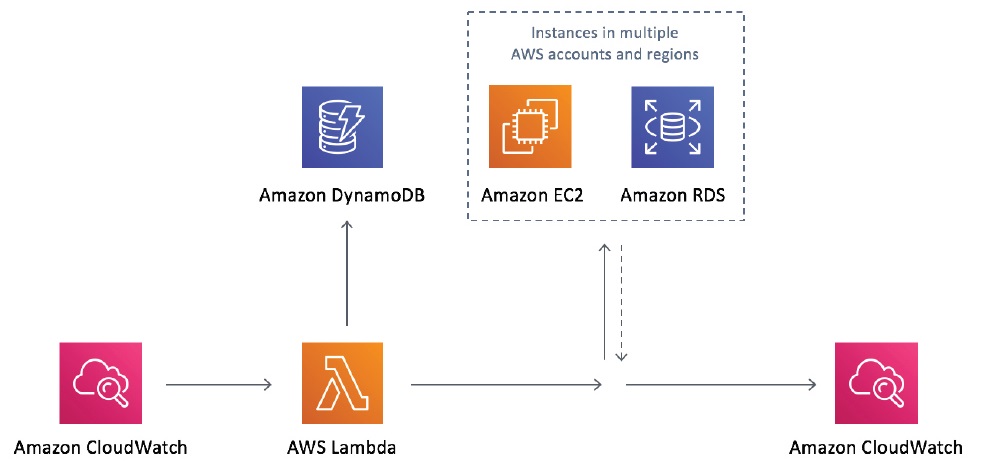 Amazon CloudWatch diagram
Amazon CloudWatch diagram
マルチパートの不完全なアップロードをクリーンアップ
S3のマルチパートアップロード機能は、デフォルトで有効になっており、大きなオブジェクトを論理的な部分に分割して並行してアップロードすることで、アップロードを高速化します。問題は、これらのアップロードが何らかの理由で終わらない場合です。アップロードが完了しないデータはバケットに表示されず、自動的に削除されることもないので、毎月の請求額が大きくなる場合を除いては、特に気にする必要はないでしょう。これを防ぐには、「バケット管理」の設定で、新しいライフサイクルルールを作成し、「不完全なマルチパートのアップロードをクリーンアップする」オプションを有効にしてください。
ライフサイクルポリシーに慣れる
ライフサイクルポリシーといえば、AWS S3を使って運用する際には必ず必要なものです。とはいえ、ライフサイクルポリシーを実装するには、インフラ上で有効にする前に、ある程度の学習とドキュメントを読むことが必要です。
ポリシーは、使用パターンが明確に定義されたオブジェクトに対するルールの組み合わせなので、以下のことが可能です。
●ライフサイクル・ルールを使用して、オブジェクトをそのライフタイムを通じて管理する。
●階層型ストレージへの移行を自動化し、コスト削減を図る
●保管の必要性やサービスレベルアグリーメント(SLA)に基づき、オブジェクトを失効させる。
これは、適切に設定すれば非常に強力なツールです。S3ストレージクラスの違いを学び、より組織のニーズに合うようにライフサイクル・ルールに慣れることです。
ライフサイクルルールの作成
オブジェクトストレージに感謝
AWSは、パフォーマンス、可用性、耐久性の要件を満たすように設計された複数のストレージ階層を、異なる価格で提供しています。提供されるストレージサービスは、大きく3つに分類されます。オブジェクトストレージ、ブロックストレージ、ファイルストレージです。Amazonが提供するオブジェクトストレージ、Simple Storage Service(S3)は、3つのストレージカテゴリの中で最もコスト効率が高いです。Amazon S3内では、さらに先のストレージクラス間でデータを簡単に移動させ、アクセス頻度と価格のバランスを取りながら、ストレージコストを最適化することができます。すべてのストレージタイプで利用シーンが異なり、その価格設定も様々です。
AWS S3ストレージクラス部分比較
ここでの賢い方法は、タスクの種類、オブジェクトの性質、アクセス頻度に応じて、それらを組み合わせることです。目的のS3バケットをクリックし、「管理」→「分析」を選択し、「ストレージクラス分析」を追加すると、アクセスパターンを確認するのに便利です。One Zone-IAやS3 Glacierへの移行を推奨するものではありませんが、データをより深く可視化することができます。
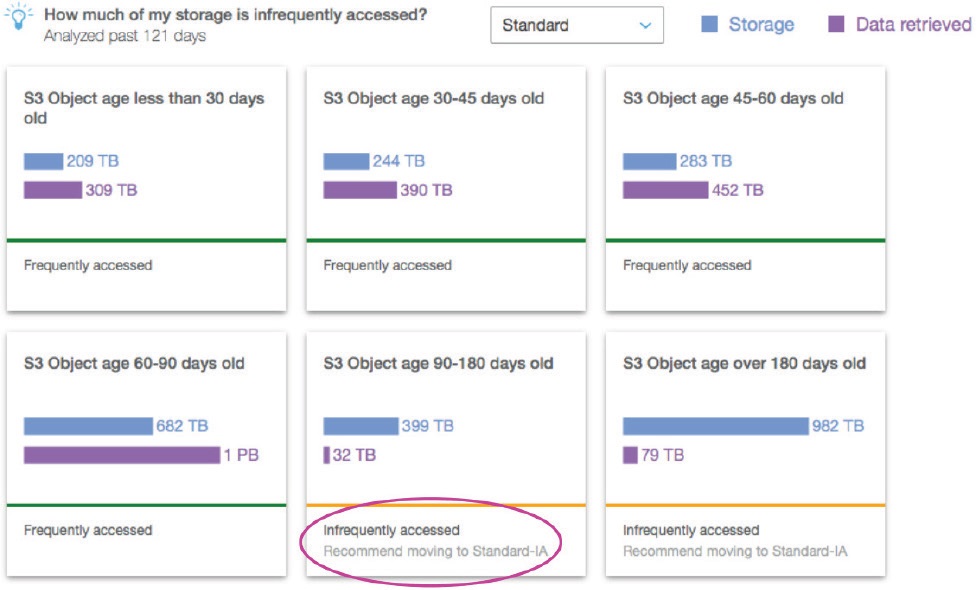
S3 バケット・ストレージ・クラス分析
新規者についてもしっかり検討しましょう。S3 Intelligent Tiering。少額の追加料金で、アマゾンは自動的にアクセスデータのパターンを検出し、オブジェクトの人気度に応じて、標準的なアクセスと不定期なアクセスの2つの層の間でそれらを移動させます。人気のないオブジェクト(連続30日間アクセスされていないもの)は、アクセス頻度の低い階層に移動され、要求があれば後で戻されます。この仕組みでは検索料がかからないため、オブジェクトは永遠に行き来することができます。実際のシナリオでは、20%の節約になります。このような監視のための費用を支払うことで、理論上は部分的に低くなりますが、それでも見逃すにはあまりに魅力的だからです。S3 APIまたはCLIを使用してストレージクラス “INTELLIGENT_TIERING “を指定するか、ライフサイクルルールを設定することでこの技術を有効にすることができます。
しかし、これはすべてに有効なわけではないです。128KB未満のオブジェクトは、インフリークエントアクセス層に移行されることがないため、フリークエントアクセス層の通常料金で課金されることになります。また、30日未満のオブジェクトは、最低30日間課金されるため、この方法は使えません。
可能な限り複雑さを避ける
バックアップソリューションが複雑でなければないほど、必要なときに動作する可能性が高くなります。複雑すぎるバックアップソリューションは、ヒューマンエラー、誤った設定、パッチのリリースに伴う互換性の問題が発生しやすくなります。そのため、シンプルな管理インターフェイスを持つだけでなく、エージェントを必要とせず、実際のデータ保護プロセスを簡素化するソリューションを探すとよいでしょう。つまり、管理者が新しいワークロードごとに手動でエージェントを展開したり、自動化スクリプトを書いたりする必要がなく、あらゆる規模の環境に対して拡張できるソリューションを探すということです。
クラウドのコストに注意
クラウドサービスプロバイダーは当初から、コストのかかるオンプレミスでのIT運用に代わる安価な選択肢として、パブリッククラウドを販売してきました。しかし、実際には、Azureやその他のクラウド環境での運用は、オンプレミスでのワークロードの維持と同じくらいコストがかかることがよくあります。
Azureのデータをバックアップする場合、IT担当者がコストを抑制するために留意すべき点がいくつかあります。まず、効果的なデータライフサイクル管理ポリシーを持つことが必要です。このようなポリシーは、バックアップされるデータの量やバックアップ自体のサイズを制限するのに役立ちます。第二に、構内や他のクラウド環境に存在するバックアップターゲットの使用には注意が必要です。マイクロソフトは、Azureクラウドからデータを取り出す際にデータ取り出し手数料を契約者に請求しており、この手数料は大きなデータセットではかなり高額になる可能性があります。
クラウドでのコスト管理の複雑さを考えると、バックアップベンダーはクラウドでのデータ移動のニュアンスを意識したバックアップコスト計算とデータ管理ツールを内蔵していることが重要です。
データのバックアップを確認する
Azureのバックアップ戦略を策定する最初のステップは、実際にバックアップする必要があるのは何なのかを把握することです。つまり、データがAzureクラウド内のどこに存在し、そのデータを保護するために何が必要かを決定することです。Azureのデータは、仮想マシンやAzure SQLのようなマネージドサービスなど、さまざまな場所に存在する可能性があります。また、データが複数のリージョンに分散している可能性もあります。
サービスの利用を予測し、前もってコミットすることを目指す
パブリッククラウドの柔軟性とCAPEXからOPEXへの移行について紹介しますが、請求書を減らすAWSの機能であるリザーブドインスタンス(RI)と節約プランのいくつかは、皮肉にもCAPEXに戻るように見えます。しかし、実際に50%以上の割引が得られるのですから、誰もが「導入のベストプラクティス」リストに挙げるべきものでしょう。
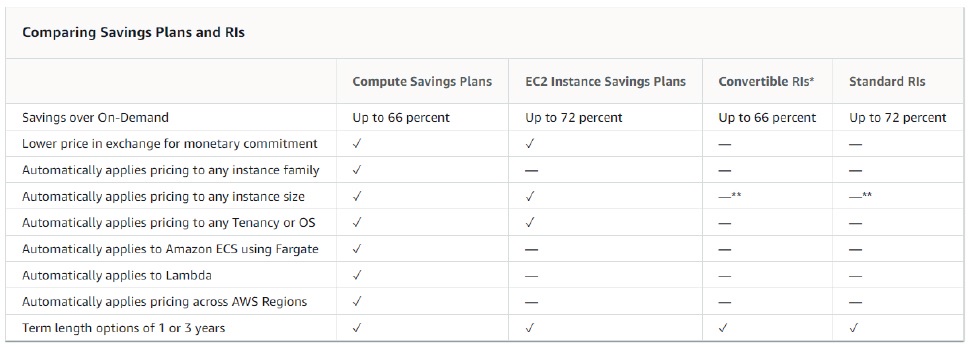
RIは、EC2インスタンスの時間単位の割引料金とオプションの容量予約を提供するもので、まずRIを検討することから始めます。1年または3年のコミットメントと引き換えに、インスタンスコストの割引を受けることができます。オンデマンドインスタンスは、無制限の柔軟性でワークロードをプロビジョニングしたい人には良い選択肢です。しかし、負荷が予測可能なワークロード(Webサービスなど)を常時稼働させる場合は、RIの方がはるかに優れています。
適切なEC2インスタンスタイプを選択する
EC2サービスは、おそらくAWSでのクラウドの旅で最初に選ぶものの1つだろう。60以上のインスタンスタイプがあり、最適なものを選ぶのは至難の業です。まずは、インスタンスの目的を考えてみてください。それを元に、以下のリストを見て最適なタイプを絞り込むことができます。
使用ケース |汎用機、計算、ストレージ、ネットワークでバランスが取れている必要がある
例 | Apache、NGINX、Kubernetes、Docker、VDI、開発環境など。
好ましいインスタンスタイプ|T3
使用ケース |高性能CPUの恩恵を受けるコンピュートバインドアプリケーション
例 | 高性能ウェブサーバー、拡張性の高いマルチプレイヤーゲーム、動画エンコーディングなど
好ましいインスタンスタイプ|C4、C5
使用ケース |大容量のデータセットをメモリ上で処理するアプリケーション
例 | 高性能データベース(SAP HANAなど)、ビッグデータ処理エンジン(Apache SparkやPrestoなど)、ハイパフォーマンス・コンピューティング(HPC)など
好ましいインスタンスタイプ|X1およびR5
使用ケース |浮動小数点数の計算、集中的なグラフィックス処理、またはデータのパターンマッチング
例 | 機械学習/深層学習アプリケーション、計算金融、音声認識、自律走行車、または創薬
好ましいインスタンスタイプ|G4、F1、P3
使用ケース |大量のシーケンシャルリード/ライト操作、または大規模なデータセットの処理
例 | NoSQLデータベース(例:Cassandra、MongoDB、Redis)、スケールアウト・トランザクション・データベース、データウェアハウス
好ましいインスタンスタイプ|D2とi3
ライトサイジングとは、性能要件を満たした上で、最も安価なオプションを選択することであることを忘れないでください。経験則では、長期間にわたってインスタンスのリソース使用率が80%になるようにすることです。
初めに:AWSスナップショットとは何ですか?
AWSスナップショットとは、EC2インスタンスやEBSボリュームなどのリソースのイメージコピーで、AWSアカウント内のオブジェクトストレージに保存される。フルまたはベースラインスナップショットは、保護されたリソースの単一時点からの同一コピーである。最初のスナップショットが作成されると、それ以降の増分スナップショットには、最後のスナップショットが取得された後に変更されたすべてのブロックが含まれるようになります。
AWSスナップショットは完全なコピーであるため、破損または削除されたリソースを復元するために使用することができ、一般的にプライマリコピーが破損した場合、ITが最初に検索するものです。例えば、EC2インスタンスやEBSボリュームが破損しても、スナップショットには影響しないので、チームは簡単に復旧することができます。
これは、AWSスナップショットがバックアップのための理想的なデータソースであることを意味します 。 それは、異なるシステムに格納されているデータの独立したコピーを提供します。そらは、AWSで損傷したリソースを回復するための最も簡単で迅速な方法であり、シンプルでスピーディな災害復旧のための素晴らしいリソースを示しています。
<<続き>>
https://www.climb.co.jp/faq/faq-category/aws-snapshot
AWSスナップショットと3-2-1バックアップルール
効果的なバックアップとリカバリのシステムは、バックアップの古典的な3-2-1ルールに従っています – データのコピーを少なくとも3つ、少なくとも2つの異なるタイプのメディアに保存し、そのうち1つはオフサイトに保存します。
2つの異なるストレージシステムにデータを保存することは、プライマリシステムがダウンした場合にコピーが破損しないようにするためのリスク管理戦術です。このため、常に別のバックアップシステムを持ち、プライマリとバックアップの両方に同じストレージを使用しないようにします。スナップショットを作成した時点で、データのコピーを別のシステムに保存していることになるので、このルールの一部はAWSスナップショットを使用して簡単に遵守することができます。
少なくとも1つのバックアップコピーをオフサイトに保存することが、厄介な部分です。AWSスナップショットを別のリージョンにコピーすることは可能ですが、自動化するのは難しく、コストもかかります。あるリージョンから別のリージョンにデータをコピーすると、イグレスチャージが発生し、コストのかかる不要なコピーが作成されます。また、この概念をすべてのAWSアカウントに一貫して適用し、一元的な管理とレポーティングを維持することは困難です。
AWSスナップショットの限界
単一のAWSアカウントと比較的少数のリソースを持つユーザーにとって、バックアップの自動化と一貫したポリシーの適用は簡単なプロセスです。しかし、複数の地域に多数のAWSアカウントを持つユーザーにとって、バックアップを監視しながらすべてのアカウントで一貫したデータ保護を実施することは、非常に困難でコストがかかる可能性があります。Kubernetesのようなアプリケーションでは、ITチームはより洗練されたデータ保護メカニズムを必要とし、スナップショットだけに頼っていては復旧目標を達成できないかもしれないので、問題はさらに複雑になります。
さらに、すべてのバックアップが異なる地域の異なるアカウントにコピーされることを保証する問題もあります。地域間で何千ものバックアップを移行するのは非常に高価であり、一般的なエグレス・チャージよりは低いものの、AWSは地域間のデータコピーに課金することになります。最後に、AWSのスナップショットはストレージ効率が良いが、長期間保存するとかなりコストがかかる可能性があります。
クラウドバックアップの社会的通念#3: クラウドバックアップは安全ではない
誤り:このような考えは、いくつかのソリューションの可視性の欠如によって助長されている。ローカルサーバーにデータを保存するのとは異なり、ローカルレベルで障害が発生しても、クラウドベースのデータで問題が発生することはありません。軍用レベルの暗号化と、大規模で安全なデータ保存のために特別に設計されたサーバーを提供するバックアップおよびアーカイブソリューションを見つけましょう。
クラウドバックアップの社会的通念#1: Google Workspace / Microsoft 365はすでにバックアップとアーカイブを行っています。
誤り:Microsoft 365は、削除したメールとファイルをごみ箱に最大90日間保存するだけです。Google Workspaceは、エンドユーザーのDriveファイルとメールを30日後にゴミ箱とスパムフォルダに削除します。どちらのソリューション/プロバイダも、ユーザーエラー、データ破損、ランサムウェアの脅威が発生した場合のデータの完全な復元を保証するものではありません。マイクロソフトでは、サードパーティによるデータのバックアップをとっておくことを推奨しています(マイクロソフト サービス契約セクション6b)。
企業がMicrosoft 365のデータを保護する必要がある5つの理由
1. 誤って削除した場合
ユーザを削除すると、その意図の有無にかかわらず、その削除はビジネスアカウントとメールボックスの削除とともにネットワーク全体に複製されます。Microsoft 365 に含まれるネイティブのごみ箱とバージョン履歴では、データ損失の保護に限界があります。バックアップからの単純なリカバリは、Microsoft 365がデータを永久に削除した後、あるいは保持期間が過ぎた後に大きな問題に変わる可能性があります。
2. 保持ポリシーのギャップと混乱
保持ポリシーを含め、継続的に進化するポリシーは、管理はおろか、対応することも困難です。Microsoft 365のバックアップと保持ポリシーは限定的であり、状況に応じたデータ損失しか管理できず、包括的なバックアップソリューションとして意図されていいません。
3. 内部セキュリティの脅威
一般的にセキュリティの脅威というと、ハッカーやウイルスを思い浮かべます。しかし、企業は内部からの脅威を経験しており、それは想像以上に頻繁に起こっています。企業は、意図的であれ無意識であれ、自社の従業員による脅威の犠牲になっています。ファイルや連絡先へのアクセスはすぐに変更されるため、最も信頼してインストールしたファイルから目を離すことは困難です。マイクロソフトは、通常のユーザと、退職前に会社の重要なデータを削除しようとする解雇された従業員との違いを知る術がありません。さらに、ユーザは感染したファイルをダウンロードしたり、信頼できると思っていたサイトに誤ってユーザ名やパスワードを流出させたりすることで、知らず知らずのうちに深刻な脅威を作り出しています。
4. 外部からのセキュリティ脅威
ランサムウェアのようなマルウェアやウイルスは、世界中の企業に多大な損害を与えている。企業の評判だけでなく、社内データや顧客データのプライバシーやセキュリティも危険にさらされています。外部からの脅威は、電子メールや添付ファイルを通して忍び込む可能性があり、特に感染したメッセージが非常に説得力があるように見える場合、どのような点に注意すべきかをユーザに教育するだけでは必ずしも十分ではありません。定期的なバックアップは、感染していないデータの別コピーを確保し、データの復旧をより確実かつ簡単にするのに役立ちます。
5. 法的およびコンプライアンス要件
法的措置が取られる中で、不意に電子メールやファイル、その他の種類のデータを復元する必要が生じることがあります。マイクロソフトはいくつかのセーフティネット(訴訟ホールドとリテンション)を組み込んでいますが、これらはユーザ企業を法的トラブルから守る強固なバックアップソリューションではありません。法的要件、コンプライアンス要件、アクセス規制は業界や国によって異なり、罰金、罰則、法的紛争はどの企業も遭遇したくないものです。
株式会社クライムではMicrosoft 365ユーザのデータを保護を手助けする多くのソリューションを提供しています。
クラウドバックアップの社会的通念#2: クラウド・バックアップとアーカイブは高すぎる
誤り: 適切なソリューションであれば、1シートあたり月額数ドルで無停止のデータ保護が可能です。データ漏洩による企業の損害は平均461万ドル(前年比10%増)であり、データ・セキュリティを確保するために必要な費用を大幅に上回っています。
クラウドバックアップの社会的通念#4:バックアップ&アーカイブ・ソリューションは、データ・セキュリティを確保するために使用するには難しすぎる。
誤り:この考え方は、特定のバックアップシステム/ソリューションが、ソフトウェアを動作させる前提として、管理者がエージェントをダウンロードしてインストールする必要があることに起因しています。しかし、あるプロバイダーはより簡単でユーザーフレンドリーなシステムを持っています。これらのプロバイダーは、顧客が独自のバックアップ自動化システムを素早くセットアップすることを可能にし、ワンクリック復元オプションと相まって、バックアップとアーカイブを可能な限り手間のかからないものにします。
クラウドバックアップの社会的通念#5: 必要なのは規制対象企業のみ
誤り:規制対象外の企業は、データのバックアップとアーカイブに価値を見出しています。以下はその使用例です:
●監査では、少なくとも 6 年前にさかのぼる完全かつ正確なデータ記録の提出が求められることが多い (IRS、SEC など)。
●訴訟や規制当局の調査により、Microsoft 365/Google Workspaceのデータを改ざんや削除できないように法的保留が必要になる場合がある。
●アーカイブシステムにある高速ユニバーサル検索ツールを使用すると、ワンクリックでソリューション全体の検索クエリを高速化できます。
クラウドバックアップの社会的通念#6:バックアップとアーカイブは大げさであり、不可欠ではない
誤り:データ漏洩により、企業(北米) は平均461万ドルを失っている。包括的なバックアップ・アーカイビング・ソリューションにかかる月々数ドルと比較すれば、バックアップ・アーカイビングがいかに不可欠であるかがわかるだろう。多くの企業(まだ存続している企業もあれば、廃業した企業もある)が、このことを痛感している。
クラウドバックアップの社会的通念#7:クラウド・バックアップとアーカイブのソリューションはすべて同だ
誤り:むしろ、下記のこれらが真実です:
市場に出回っているソリューションの多くは、UXデザインが貧弱で、使い勝手が悪い。
これらのソリューションの多くは、エージェントとしてダウンロードしなければ動作しない。
バックアップとアーカイブは別物であり、ほとんどのベンダーは一緒に提供していない。
多くのソリューションはモジュールとして販売されており、非常にコストがかかる。
バックアップとアーカイブのソリューションのうち、保存やアーカイブされたデータに基づく洞察や分析を提供するものはごく少数である。
さらに、ほとんどのソリューションは、カレンダーやタスクなど、すべてをバックアップしているわけではない。
クラウドバックアップの社会的通念#8:データを取り戻すにはお金が必要
誤り:データを人質に取らないソリューションもあります。重要なアドバイス:適切なソリューションを選択する際には、他のソリューションやサービスに移行する際にデータを取り戻すための費用が発生するかどうかをプロバイダーに確認してください。
クラウドバックアップの社会的通念#9: バックアップとアーカイブ・ソリューションは遅い
誤り:それは非効率な場合だけです。洗練されたバックアップ・アーカイブソリューションは、最近更新または追加されたファイルを優先的にバックアップし、プロセス全体を高速化します。これにより、プロセスが迅速化され、データが完全に安全にバックアップされます。
クラウドバックアップの社会的通念#10: ほとんどバックアップとアーカイブのツールは、バックアップとアーカイブのみのツールだ
誤り:ほとんどのソリューションでできることは限られていますが、バックアップやアーカイブ以上の機能を持つツールもあります。次のような高度な機能を提供するソリューションもあります:
●eDiscoveryとジャーナリングオプション
●高速検索機能
●保存およびアーカイブされたデータからのビジネス洞察と分析
クラウドバックアップについて迷いがありましたらクライムまでお問合せください。
クラウドでのディザスタリカバリー・ヒント
- クロスクラウド戦略の導入: 複数のクラウドプロバイダーを活用することで、ベンダーロックインを回避し、異なるプラットフォームやインフラにリスクを分散することで耐障害性を高める。
- フェイルオーバープロセスの自動化: 自動化ツールを使用して、フェイルオーバープロセスを迅速かつシームレスに行い、ディザスタリカバリイベント中の人的介入を最小限に抑え、エラーの可能性を低減する。
- 頻繁なDR訓練の実施: 定期的な災害復旧訓練を計画、実施し、計画の有効性をテストし、弱点を特定します。関係者全員が参加し、万全の態勢を整える。
- データ重複排除の最適化 高度なデータ重複排除技術を使用して、バックアップに必要なストレージ量を削減し、プロセスをより効率的でコスト効果の高いものにする。
- 明確なRTOとRPO指標を確立する: 復旧時間目標(RTO)と復旧時点目標(RPO)を明確に定義し、文書化することで、ディザスタリカバリ戦略が事業継続の目標に合致するように。
ユーザ・クラウドバックアップのランサムウェア対策ヒント
- バックアップの暗号化を維持 データ保護を確実にし、ランサムウェアやサイバーセキュリティの問題によるリスクを軽減するために、暗号化されたリソースのクロスリージョンバックアップを作成します。
- バックアップネットワークをセグメント化する: バックアップシステムをメインネットワークから分離します。専用のVLANを使用し、バックアップが運用システムと同じネットワークセグメントからアクセスできないように。
- バックアップの完全性を定期的に検証する: バックアップの定期的なチェックと検証を行い、データが破損していないこと、必要なときに正常にリストアできることを確認します。
- ローリングバックアップ戦略を採用する: ローリングバックアップスケジュールを実施し、複数のバージョンのデータを異なる時間枠で保持する。これにより、ランサムウェア感染前の時点に復元することができます。
- エンドポイントプロテクションを使用してバックアップエージェントを保護する: バックアップ・エージェントを実行するすべてのデバイスとサーバーが、ランサムウェアのエントリ・ポイントにならないように、堅牢なエンドポイント保護機能を備えていることを確認します。
Azure SQL Databaseバックアップのヒント
- バックアップ検証の自動化: 非本番環境へのリストアプロセスを自動化することで、バックアップを定期的にテストします。これにより、バックアップが有効であり、問題なくリストアできることを保証します。
- イミュータブル・ストレージの活用: 重要なバックアップをイミュータブル・ストレージに保存することで、ランサムウェアから保護し、指定された保存期間内にバックアップを変更または削除できないようにします。
- クロスサブスクリプション・バックアップの導入: セキュリティを強化するために、サブスクリプションレベルの問題や侵害から保護するために、バックアップのコピーを別のAzureサブスクリプションに保存することを検討します。
- バックアップ操作にプライベートエンドポイントを使用する: プライベートエンドポイントを構成して、バックアップとリストア操作がパブリックインターネットではなく、安全なプライベート接続を介して行われるようにし、セキュリティを強化します。
- バックアップデータの暗号化: 使用中のデータには透過的データ暗号化(TDE)を、保存されているバックアップデータには暗号化(at rest)を使用して、すべてのバックアップが暗号化されていることを確認し、セキュリティとコンプライアンスを強化します。
Azureの為のディザスタリカバリ計画
- 一貫性を保つために、Azure Resource Manager(ARM)テンプレートを使用します: インフラストラクチャのデプロイメント用にARMテンプレートを作成し、維持します。これにより、ディザスタリカバリ時に重要な一貫性のある反復可能なデプロイメントプロセスが保証されます。
- コンプライアンスのためのAzure Policyの実装: Azure Policy を使用して、ディザスタリカバリの構成とコンプライアンス要件を実施し、検証します。これにより、デプロイされたすべてのリソースがディザスタリカバリの標準に準拠していることを確認できます。
- Azure Private Linkを活用したセキュアな接続性: Azure Private Linkを活用して、オンプレミスのネットワークをAzureサービスにプライベート接続することで、攻撃対象領域を減らし、フェイルオーバーおよびリカバリプロセス中の安全なデータ転送を実現します。
- Azure DevOpsによるフェイルオーバーテストの自動化:Azure DevOpsを使用して、ディザスタリカバリのテストをCI/CDパイプラインに統合します。フェイルオーバーテストを自動化することで、手動による介入なしにディザスタリカバリプランを定期的に検証できます。
- マルチテナント管理のためのAzure Lighthouseの導入: マネージドサービスプロバイダーや大企業の場合、Azure Lighthouseを使用して、複数のAzureテナントを1枚のガラスから管理し、ディザスタリカバリシナリオ中の監視と制御を改善します。
Azure Cross-Region Replication(CRR)の利点、制限、課題
- Azure Site RecoveryとCRRの併用:CRRとAzure Site Recovery(ASR)を組み合わせることで、仮想マシン(VM)のレプリケーション、フェイルオーバー、リカバリを自動化できます。ASRは、ディザスタリカバリプロセス全体をオーケストレーションすることができ、より包括的なソリューションを提供します。
- アラートでレプリケーションの健全性を監視 Azure Monitorでカスタムアラートを設定して、CRRプロセスの健全性とステータスを追跡します。このプロアクティブな監視により、あらゆる問題が迅速に検出、対処され、データの一貫性と可用性が維持されます。
- マルチクラウド戦略の導入による耐障害性の強化: Azure内だけでなく、異なるクラウドプロバイダー間で重要なデータを複製することで、ディザスタリカバリ戦略を強化します。N2WSのようなツールは、クロスクラウドレプリケーションを可能にし、クラウドプロバイダー固有の障害に対するフェイルセーフを提供します。
- レプリケートされたデータをエンドツーエンドで暗号化する: レプリケーションプロセス中、静止時と転送時の両方でデータが暗号化されていることを確認します。暗号化キーの管理とアクセスにはAzure Key Vaultを使用し、ディザスタリカバリ計画にさらなるセキュリティ層を追加します。
- レプリケーションとフェイルオーバーを定期的にテストする: Azure AutomationとASRを使用して、ディザスタリカバリ訓練を自動化します。定期的なテストにより、レプリケーションとフェイルオーバープロセスの信頼性と効率性を確保し、運用に影響が出る前に潜在的な問題を浮き彫りにすることができます。
Azure Site Recovery (ASR)活用ヒント
- ストレージ階層を活用してレプリケーションコストを最適化: Azureのストレージ階層(ホット、クール、アーカイブ)をASR内で戦略的に活用する。たとえば、アクセス頻度の低いVMにはクールストレージを使用し、ディザスタリカバリ機能を維持しながらストレージコストを最適化する。
- リカバリプランによるワークロードの優先順位付け: 重要なVMとサービスのフェイルオーバーを優先する詳細なリカバリプランを作成します。この優先順位付けにより、災害時に最も重要なアプリケーションを可能な限り迅速に利用できるようになります。
- 分離された環境でフェイルオーバーを定期的にテストする: 分離された環境で、無停止のフェイルオーバーテストを定期的に実施する。このような訓練により、稼働中のサービスに影響を与えることなく災害復旧計画を検証し、復旧プロセスが意図したとおりに機能することを確認できます。
- レプリケーションにタグベースの自動化を活用する: プロダクション」や「クリティカル」などのタグに基づいて、VM のレプリケーションを自動化します。これにより、特定のタグに一致する新しいVMにASRレプリケーション設定を自動的に適用し、手作業による介入なしにVMを確実に保護することができます。
- マルチクラウド戦略との統合による耐障害性の強化: N2WSなどのツールを使用してASRをクロスクラウド機能と統合することにより、ディザスタリカバリ戦略を拡張します。これにより、異なるクラウド環境間でのリカバリが可能になり、クラウド固有の障害から保護されるため、回復力がさらに高まります。
災害復旧コストの鍵と削減方法
- マルチクラウドDR戦略の採用: ディザスタリカバリのワークロードをクラウドプロバイダーに分散することで、ベンダーロックインを回避し、各プロバイダーのコスト効率を活用します。これにより、耐障害性が向上し、価格設定の柔軟性も高まります。
- 迅速なフェイルオーバーのためのリカバリシナリオの実装: N2WSを使用して、わずか数クリックでフェイルオーバーを自動化し、オーケストレーションします。これにより、ダウンタイムを最小限に抑え、複雑な手動リカバリプロセスの必要性を低減し、最終的に運用コストを削減します。
- 自動化されたDRテストを活用して、コストのかかるエラーを回避します: 自動DRテストツールを使用して、ディザスタリカバリ計画を定期的にテストします。これにより、多額の費用をかけずに復旧プロセスを検証し、運用を中断することなく万全の準備を整えることができます。
- イミュータブルバックアップでDRバックアップにさらなるセキュリティ層を追加します: イミュータブル・バックアップは、データの改ざんや削除を確実に防止するため、余分なコストをかけずにさらなる安全策を提供します。
- クロスリージョンDRとクロスアカウントDRで耐障害性を強化します: N2WSのクロスリージョンバックアップとクロスアカウントバックアップ機能を利用して、地域の停電から保護し、データセキュリティを向上させます。
クラウドでのディザスタリカバリの長所/短所とソリューションの選択
- クロスクラウド戦略の導入: 複数のクラウドプロバイダーを活用することで、ベンダーロックインを回避し、異なるプラットフォームやインフラにリスクを分散することで耐障害性を高める。
- フェイルオーバープロセスの自動化: 自動化ツールを使用して、フェイルオーバープロセスを迅速かつシームレスに行い、ディザスタリカバリイベント中の人的介入を最小限に抑え、エラーの可能性を低減する。
- 頻繁なDR訓練の実施: 定期的な災害復旧訓練を計画、実施し、計画の有効性をテストし、弱点を特定します。関係者全員が参加し、万全の態勢を整える。
- データ重複排除の最適化 高度なデータ重複排除技術を使用して、バックアップに必要なストレージ量を削減し、プロセスをより効率的でコスト効果の高いものにする。
- 明確なRTOとRPO指標を確立する: 復旧時間目標(RTO)と復旧時点目標(RPO)を明確に定義し、文書化することで、ディザスタリカバリ戦略が事業継続の目標に合致するようにする。
N2WSによるクラウドベースのディザスタリカバリ
N2WSは、DR戦略の有効性を高めながら、ディザスタリカバリのコストを大幅に削減します:
- 複数のリージョン、アカウント、クラウドにまたがるDRを自動化します: 自動化されたクロスリージョン、クロスアカウント、クロスクラウド機能により、ディザスタリカバリを簡素化し、安全性を確保します。
- DRテストと訓練の実行と自動化: ゼロコストで自動化されたDRドライランにより、ディザスタリカバリのテストを簡単に実施し、万全の準備を整えることができます。
- リカバリシナリオによるフェイルオーバーのオーケストレーション: ワンクリックで複数のリソースのフェイルオーバーを管理し、復旧作業を効率化します。
- 暗号化リソースのサポート: 暗号化されたリソースのクロスリージョンおよびクロスアカウントDRを実現し、セキュリティのレイヤーを追加します。
- カスタムDR生成によるコスト削減 N2WSのカスタムDR生成オプションにより、ディザスタリカバリコストを削減します。
- イミュータブルバックアップでセキュリティを強化 DRバックアップを不変性で保護し、データの整合性を確保します。
- 頻繁なバックアップ 最短60秒間隔でバックアップを取得し、RPOを最小化します。
- ほぼゼロのRTOを達成: 重要なシステムを数秒で復旧し、業務への影響を最小限に抑えます。
- フェイルオーバーとフェイルバックの自動化 リカバリプロセスを自動化することで、ダウンタイムを短縮し、一貫した信頼性の高い結果を保証します。
- 完全に機能するDRバックアップのリストア: すべてのVPCとネットワーク設定をそのままにバックアップをリストアし、シームレスなリカバリを実現します。
S3バックアップ:考慮すべき5つの鍵
- リージョン間レプリケーションを活用: クロスリージョンレプリケーション(CRR)を実装して、AWSのリージョン間でオブジェクトを自動的にコピーします。 これにより、地理的に離れた場所にデータを保存することで災害復旧能力が強化されるだけでなく、データ保存要件への準拠も支援します。
- N2WSで簡単に自動化: N2WSは、複雑なコーディングや手動での介入を必要とせずに、S3バックアップを自動化するシンプルで使いやすい方法を提供します。 これにより、効率が向上し、S3データの保護が確実に維持されます。
- インテリジェント・ティアリングでコストを最適化:S3インテリジェント・ティアリング・ストレージクラスを利用して、アクセスパターンの変化に応じて、2つのアクセス層(頻繁なアクセスと頻繁ではないアクセス)間でデータを自動的に移動させます。これにより、パフォーマンスへの影響やオーバーヘッドなしにストレージコストを最適化できます。
- セキュリティを強化するMFA Delete:バージョン管理機能付きのS3バケットで多要素認証(MFA)による削除を有効にすることで、セキュリティをさらに強化できます。オブジェクトのバージョンを恒久的に削除する操作にはMFAが必要となり、削除を防止します。
- AWS S3 Storage Lensでストレージを分析:S3ストレージの使用状況とアクティビティの傾向を可視化できます。このツールは、コストの最適化、データ保護のベストプラクティスの強化、パフォーマンスの向上に役立つ洞察と推奨事項を提供します。
真のクラウドコストについて
- ストレージ階層化を動的に活用:静的なライフサイクルポリシーにとどまらず、使用パターンを自動的に分析し、動的に階層間でデータを移動するツールを使用して、パフォーマンスとコストの両方をリアルタイムで最適化することを検討してください。
- スポットフリートで高可用性を実現:スポットインスタンスはコスト削減に役立ちますが、最も安価な利用可能なスポットインスタンスを自動的に選択し、再バランスする「スポットフリート」を作成することで、コスト効率と稼働時間を確保することができます。
- カスタム価格モデルの交渉:大手クラウドプロバイダーは、大量に利用する企業向けにカスタム価格帯を提供しています。既定の料金に妥協することなく、利用量や特定のサービス要件に基づく割引を交渉しましょう。
- クラウドネイティブなコスト最適化ツールの活用:ネイティブなコスト管理ソリューションに加えて、CloudHealthやCloudabilityのようなクラウドネイティブなサードパーティプラットフォームは、より深い洞察、クロスクラウド分析、自動化されたガバナンスを提供し、競争優位性をもたらします。
- サービス固有のコスト最適化フレームワークを利用する:各クラウドプロバイダーには、それぞれに秘められた効率化があります。例えば、AWS Compute OptimizerやAzure Cost Managementの推奨事項は、特定のサービスのコスト削減に重点を置いています。手動監査と併用して、これらのサービスを活用し、支出を最適化しましょう。
- 続きはこちらまで
Amazon S3 Glacierバックアップ
●ハイブリッドストレージ戦略で取得コストを最適化:S3 GlacierをS3 StandardまたはS3 Intelligent-Tieringと組み合わせます。 頻繁にアクセスされるデータはStandard/Intelligent-Tieringに残し、長期にわたってアクセス頻度の低いデータをGlacierに移行します。 これにより、より重要なデータへの迅速なアクセスを確保しながら、ストレージコストを大幅に最適化できます。
●S3 Object Lock を活用して変更不可のバックアップを作成:S3 Object Lock を Glacier と組み合わせて使用することで、変更不可のバックアップを作成できます。これにより、重要なバックアップに WORM(Write Once Read Many)モデルを適用することで、誤って削除されたりランサムウェア攻撃を受けたりした場合でも、お客様のデータを確実に保護することができます。
●大きなファイルにはマルチパートアップロードを使用: 大きなアーカイブには、Glacierのマルチパートアップロード機能を使用します。 アップロードの効率が向上するだけでなく、管理しやすい小さな部分に分割してファイルをアップロードすることで、アップロードの失敗リスクを低減し、データの整合性を確保できます。
●DRには地域間レプリケーションを実装: 地域間レプリケーションを設定して、AWSの1つのリージョンから別のリージョンにデータを自動的に複製します。これは、地域的な障害が発生した場合に、重要なデータのコピーが常に別の地理的場所で利用可能であることを保証するため、災害復旧に不可欠です。
●異なるデータセットごとのカスタム取得プラン:異なるデータセットのビジネス上の重要度に基づいて、カスタム取得プランを定義します。例えば、優先度の高いデータについては迅速な取得、重要度は低いがサイズの大きいデータセットについては一括取得などです。これにより、コストのバランスを調整し、重要な情報が迅速に利用可能であることを保証します。
Azureでのプロセスを最大限に自動化して保護と復旧を高速化するヒント
●コスト管理にスナップショットのライフサイクルポリシーを活用:より古いスナップショットを低コストのストレージ層に移行することで、リカバリ性を損なうことなくコストを削減できます。
●代替案としてアプリケーション認識型レプリケーションを検討する:バックアップが大きなオーバーヘッドをもたらすようなシナリオでは、重要なワークロードをリアルタイムで同期し、一貫性を保証するアプリケーション認識型レプリケーションソリューションを評価します。
●バックアップ用にリードレプリカを実装する:データベースの場合、リードレプリカを作成し、そのレプリカに対してアプリケーション一貫性のあるバックアップを実行することを検討します。これにより、バックアップ中のプライマリデータベースのパフォーマンスへの影響を回避できます。
●テスト環境でバックアップをテストする:サンドボックス環境を使用して、本番環境のワークロードに影響を与えることなく、アプリケーション整合性のあるバックアップをテストします。自動化ツールを使用すると、障害をシミュレートし、リカバリ時間を検証することができます。
●変更不可ストレージでリカバリを強化する:Azureで変更不可のバックアップを設定することで、誤って削除したりランサムウェアの被害に遭うことを防ぎます。アプリケーション整合性と組み合わせることで、悪意のあるデータ損失や誤操作によるデータ損失の両方のシナリオにおいて、リカバリの整合性を確保することができます。
スナップショットのアーカイブにAmazon S3を使用のヒント
●アーカイブ前にデータの分類を優先:すべてのスナップショットが同じように重要であるわけではありません。 コンプライアンスやDRなどの重要なスナップショットと、より長い検索時間を許容できるスナップショットを区別するために、堅牢なデータ分類ポリシーを導入します。
●アーカイブからの取得に関するSLAをDR計画に統合:GlacierまたはDeep Archiveにスナップショットをアーカイブした場合、取得に数分から数時間かかる場合があります。 災害復旧(DR)計画では、こうした取得SLAを考慮して、予期せぬ遅延を回避する必要があります。
●S3 Object Lockを使用して保持の徹底を自動化:S3 Object Lockを使用して重要なスナップショットの不変性を徹底し、早期の削除を防止して、規制へのコンプライアンスを確保します。 また、誤ってまたは悪意を持って削除されることも防ぎます。
●重要アーカイブスナップショットには、クロスリージョンレプリケーションを活用:スナップショットをアーカイブする前に、クロスリージョンレプリケーション(CRR)を有効にします。これにより、リージョンがダウンした場合でも、アーカイブされたデータは別のリージョンで利用可能になります。
●AWS Cost Explorer を使用して定期的にコスト監査を実施する:S3 GlacierとDeep Archiveはコスト削減をもたらしますが、これらは長期間にわたって気づかぬうちに蓄積される可能性があります。AWS Cost Explorerを使用して定期的にアーカイブコストを監査し、スナップショットのライフサイクルポリシーが最適化されていることを確認してください。
ラウドストレージのコスト:その主要な要因
- マルチクラウド戦略を活用して価格交渉力を高める:複数のクラウドプロバイダーを活用して、より良い料金を比較・交渉する。競争が明らかな場合、一部のプロバイダーは長期契約や大量契約に対して割引を提供することがある。
- 地域間レプリケーションを厳選して導入する:重要なデータのみを地域間でレプリケートし、ストレージとデータ転送のコストを最小限に抑える。重要性の低いデータについては、冗長ストレージを控えめに使用し、不要なオーバーヘッドを削減する。
- 高度なモニタリングでアクセスパターンを分析:AWS CloudWatch、Azure Monitor、またはサードパーティの分析プラットフォームなどのツールを使用して、リアルタイムのデータアクセス傾向を追跡します。これにより、ティア配置を微調整し、利用度の低いリソースに対する支払いを回避することができます。
- コストの異常値に対する自動アラートを設定:ストレージや転送コストに予期せぬ急上昇があった場合にチームに通知するアラートを設定します。早期に発見することで迅速なトラブルシューティングが可能になり、予算超過を防ぐことができます。
- 効率性を高めるために事前署名付きURLを使用:事前署名付きURLを使用してクラウドオブジェクトへの一時的な直接アクセスを許可することで、共有データの帯域幅の過剰使用を回避し、不要な転送料金を削減します。
AWS Backup スナップショット
- 整合性を保つためにアプリケーション認識型バックアップを使用:データベースやERPシステムなどの重要なアプリケーションには、アプリケーション認識型バックアップのメカニズムを統合します。これにより、アプリケーション層での整合性が確保され、実行中のインスタンスのスナップショットによる破損を回避できます。
- ワークロードの重要度に基づくバックアップのライフサイクルポリシーを実装:例えば、重要なワークロードには、より頻繁なスナップショットとより長い保持期間が必要となる場合がありますが、重要でないワークロードは保持期間を短く設定できます。
- 最小限のベースイメージでAMIを最適化:AMIを作成する際には、不要なデータや一時ファイルを除外してベーススナップショットのサイズを縮小します。スナップショットが小さくなればストレージの消費量が減り、コストを削減し、復元時間を短縮できます。
- 災害復旧シナリオのためのテスト環境を作成: 定期的にスナップショットをテスト専用環境にリストアしてテストします。これにより、バックアップの整合性が検証されます。
- AWS Cost Explorerでスナップショットの使用状況を監視: AWS Cost Explorerを使用して、スナップショットに関連するコストの傾向を特定します。これにより、使用されていないバックアップや冗長なバックアップが明らかになり、コスト最適化のためにクリーンアップや保持ポリシーの調整を促すことができます。
フェイルオーバーとフェイルバック:違いは何か?
フェイルオーバーとフェイルバックは、予期せぬ障害が発生した場合でもITシステムの回復力を確保する、事業継続における2つの重要な概念です。 ビジネスが中断のない運用にますます依存するようになるにつれ、高可用性を維持し、ダウンタイムを削減するためには、この2つのプロセスを理解することが不可欠です。
このガイドでは、フェイルオーバーとフェイルバックが連携してシステムを保護する方法、実際の使用例、そしてビジネスニーズに合わせてこれらのメカニズムを実装する方法について説明します。
フェイルオーバーとは?
フェイルオーバーとは、プライマリシステムに障害が発生した際に、冗長システムまたはスタンバイシステムにシームレスに切り替えることを指します。 バックアップ環境に自動的に切り替えることで、ダウンタイムを最小限に抑え、サービスの可用性を維持するように設計されています。 パンクした際に備えてスペアタイヤを用意しておくようなものです。
フェイルオーバーの目的は、問題が発生した場合でも、業務を円滑に継続することです。SAN、NAS、ネットワークの世界では、複製されたストレージシステムへの切り替え、バックアップサーバーの起動、ネットワークトラフィックの再ルーティングなどがこれに該当します。
フェイルオーバーの仕組み
フェイルオーバーは、プライマリシステムを継続的に監視し、障害の兆候を検出します。この監視には、ハートビート信号、健全性チェック、その他の診断テストが含まれます。障害が検出されると、フェイルオーバーシステムが自動的にセカンダリシステムへの切り替えを開始します。
このプロセスは通常、以下のステップで構成されます。
- 検出:システムがプライマリシステム内の障害を特定します。
- 起動:セカンダリシステムが起動し、オンラインになります。
- リダイレクト:トラフィックと操作がセカンダリシステムにリダイレクトされます。
- 検証:フェイルオーバーが検証され、セカンダリシステムが正常に機能していることが確認されます。
例えば、クラスタ化されたサーバー環境では、1台のサーバーが故障した場合、クラスタ内の他のサーバーが自動的にその負荷を引き継ぎ、アプリケーションとサービスが引き続き利用可能になります。これがフェイルオーバーの仕組みです。
最新の導入事例では、同期レプリケーションや10秒間隔でシステム指標を監視する自動ヘルスチェックなどの先進技術により、フェイルオーバー時間を1分未満に短縮している例が多く見られます。
フェールオーバーおよびフェールバック導入のメリット
フェールオーバーおよびフェールバックを導入することで、企業には以下のような重要なメリットがもたらされます。
- ダウンタイムの削減:システム障害が業務に及ぼす影響を最小限に抑え、重要なサービスの継続的な可用性を確保します。
- データ保護:データを二次システムに複製することで、停電時のデータの損失や破損を防ぎます。
- 信頼性の向上:冗長システムと自動リカバリプロセスを提供することで、ITインフラの全体的な信頼性と回復力を強化します。
これらのメリットは、顧客満足度の向上、収益損失の削減、業務効率の改善など、具体的なビジネス成果につながります。例えば、フェールオーバーとフェールバックを導入したeコマースサイトでは、プライマリサーバーが故障した場合でも顧客が引き続き購入を続けられるため、販売機会の損失を防ぎ、顧客の信頼を維持することができます。
フェールオーバーとフェールバックのベストプラクティス
フェールオーバーとフェールバックを効果的に導入するには、以下のベストプラクティスを考慮してください。
- 定期的なテスト:フェールオーバーとフェールバックのテストを定期的に実施し、システムが正常に機能していること、およびリカバリープロセスが適切に文書化され理解されていることを確認します。
- 自動化されたプロセス:フェールオーバーとフェールバックのプロセスを可能な限り自動化し、手動による介入を減らし、エラーのリスクを最小限に抑えます。
- 包括的なモニタリング:すべての重要なシステムを包括的にモニタリングし、障害を迅速に検知してフェールオーバー手順を開始します。
- 詳細な文書化:フェイルオーバーおよびフェイルバックのプロセスについて、手順、構成、連絡先情報などを含む詳細な文書を作成しておく。
- データの同期:プライマリシステムとセカンダリシステム間のデータの同期が信頼性が高く効率的であることを確認し、フェイルオーバーおよびフェイルバック時のデータ損失を防ぐ。
これらのベストプラクティスに従うことで、企業はフェイルオーバーおよびフェイルバック戦略の効果を最大限に高め、あらゆる潜在的な混乱に備えることができます。
結論
効果的な災害復旧は、今日のデジタル環境における事業継続性を維持するために不可欠です。フェイルオーバーとフェイルバックのメカニズムは、ダウンタイムの短縮、データの完全性の確保、障害発生時のサービス継続の鍵となります。定期的なテスト、自動復旧、適切な文書化などのベストプラクティスに従うことで、企業はITインフラを強化し、ハードウェアやソフトウェアの障害発生時にデータ損失を回避または完全に最小化することができます。
AWSの価格設定モデルの概要
AWSは、さまざまなビジネスニーズに対応するために、複数の価格モデルを提供しています。
オンデマンドインスタンス
オンデマンドインスタンスは、インスタンスの種類に応じて、コンピューティング能力を時間単位または秒単位で支払う従量制の価格モデルです。初期費用は発生せず、ユーザーは長期的な契約を結ぶことなく、いつでもインスタンスを開始または停止することができます。このモデルは、需要が予測できない作業負荷や短期プロジェクトに最適です。
利点:
- 柔軟性:必要に応じてインスタンスの起動と停止が可能。
- 初期費用なし:使用した分だけのお支払い。
- 使いやすさ:長期契約を必要としないシンプルな請求。
短所:
- コスト高:長期契約の他の料金モデルと比較すると割高。
- コスト管理:継続的に実行されるインスタンスでは、コストが予測しにくくなる可能性がある。
リザーブドインスタンスと割引プラン
リザーブドインスタンス(RI)とセービングプランは、1年または3年間の利用を確約する代わりに、オンデマンド価格よりも割引価格で利用できるものです。RIは前払いと利用確約に基づいて割引を提供し、セービングプランはインスタンスタイプを問わず、より柔軟に同様の割引を提供します。
利点:
- コスト削減:オンデマンドと比較して最大72%のコスト削減。
- 予測可能な請求:安定したワークロードに最適。
- 柔軟なセービングプラン:従来のRIよりも適応しやすい。
短所:
- 前払い契約:事前計画と長期的な契約が必要。
- 柔軟性の制限(RI):特定のインスタンスタイプとリージョンに制限される。
スポットインスタンス
スポットインスタンスでは、ユーザーは使用されていないAWSの容量を大幅に低い価格で入札することができ、オンデマンド料金よりも最大90%も安くなる場合もあります。ただし、これらのインスタンスは、容量が他の場所で必要になった場合、AWSによって中断される可能性があります。
長所:
- 大幅なコスト削減:非クリティカルなワークロードやバッチ処理に最適です。
- 高い可用性:地域全体にわたって予備の容量に幅広くアクセスできます。
短所:
- 中断のリスク:インスタンスはわずかな通知で終了される可能性があります。
- 限定的なユースケース:クリティカルなアプリケーションや時間的制約のあるアプリケーションには不向きです。
専用ホストおよび専用インスタンス
専用ホストおよび専用インスタンスは、単一のお客様専用の物理サーバーを提供します。これらのオプションは、コンプライアンス、ライセンス、規制要件が厳しい組織向けに設計されています。
利点:
- コンプライアンス:厳しいセキュリティおよびコンプライアンス要件に対応します。
- 専用リソース:他の顧客とのリソース共有はありません。
- ライセンスの持ち込み:特定のライセンスモデルに対応。
短所:
- 高コスト:専用ハードウェアを使用するため、他のモデルよりも高価。
- 限定的な拡張性:仮想化ソリューションと比較して柔軟性が低い。
AWSコストについてのエクスパートからのアドバイス
- インスタンスファミリーの更新機会を活用する:インスタンスファミリーの更新情報を定期的に確認しましょう。新しい世代のインスタンスファミリーは、同等のパフォーマンスまたはより低いコストで、より優れたパフォーマンスを提供していることがよくあります。ワークロードを最新のインスタンスファミリーに移行することで、大幅なコスト削減を実現できます。
- 複数のアカウントを統合する:組織で複数のAWSアカウントを使用している場合は、AWS Organizationsでそれらを統合することで、ボリュームディスカウントを共有し、請求を簡素化することができます。このアプローチは、コスト最適化のための集中管理も実現します。
- 地域ごとの価格差を活用:AWSの価格は地域によって異なります。レイテンシに敏感でないワークロードの場合は、コストの低い地域にリソースを展開します。例えば、US East (N. Virginia) や US West (Oregon) のような地域は、価格競争力があることが多いです。
- 未使用のボリュームに対するライフサイクルポリシーを実装:未使用のEBSボリュームは、多額の費用が発生する可能性があります。ライフサイクルポリシーを使用して、非アクティブなボリュームのスナップショットを自動的に作成し、削除することで、未使用のストレージが不要な費用を発生させないようにします。
- データの転送を監視し、キャッシングを使用:アプリケーションが頻繁に異なるリージョンやパブリックインターネット上のデータにアクセスすると、データ転送費用が高額になる可能性があります。Amazon CloudFrontやAWS Global Acceleratorなどのキャッシングレイヤーを実装して、転送トラフィック費用を削減します。
AWS コストの管理と削減のための7つのベストプラクティス
以下のベストプラクティスを導入することで、企業はAWSにおける最適な支出を確保することができます。
1. リソースの最適化と適正化
リソースの最適化と適正化には、AWSリソースの利用状況を分析し、不要な過剰プロビジョニングを排除しながら、ワークロード要件に確実に一致させることが含まれます。 このプロセスは、過剰なインスタンスやアイドル状態のインスタンスに対する無駄な支出を排除するのに役立ちます。 ライフサイクルポリシーを使用してストレージ階層間のデータ移行を自動化することで、継続的なコスト効率性を確保することができます。
Compute OptimizerやTrusted AdvisorなどのAWSサービスは、CPUやメモリの使用率などの指標を分析して実行可能な推奨事項を提供し、企業が最もコスト効率の高いインスタンスタイプやサイズを決定するのに役立ちます。ストレージの最適化については、企業はアクセス頻度の低いデータをAmazon S3 Infrequent AccessやGlacierなどのコスト効率の高いストレージソリューションに移行することができます。
2. コスト効率を高めるためのスケジュールと自動化
AWS Instance Schedulerのようなサービスを利用すると、管理者は夜間や週末、休日など、業務時間外にインスタンスを停止するルールを作成することができます。このアプローチは、24時間365日稼働させる必要のない開発、テスト、ステージング環境に特に有効です。
AWS Lambdaのような自動化ツールをCloudWatch Eventsと組み合わせることで、アイドル状態のインスタンスの終了や未使用のEBSボリュームの削除など、リソースのクリーンアップアクションをトリガーすることができます。需要が変動するワークロードの場合、オートスケーリング機能により、コストを削減しながらパフォーマンスを維持するために実行中のインスタンスの数を動的に調整することができます。
3. コスト割り当てタグの導入
コスト割り当てタグは、AWSの費用をビジネスユニット、チーム、プロジェクトに割り当て、追跡するために不可欠です。タグはリソースに付加されるメタデータラベルとして機能し、支出のきめ細かい分析を可能にします。例えば、「Environment: Production」や「Department: Finance」などのタグを使用することで、組織はコストのかかっている分野を特定し、是正措置を取ることができます。
AWSは、タグに基づいて支出をフィルタリングし分析するためのツールとして、Cost ExplorerやBudgetsなどを提供しています。組織全体で標準化されたタグ付けポリシーを徹底することで、クラウド利用の説明責任をより適切に果たすことができます。また、タグ付けはチャージバックやショーバックのプロセスを簡素化します。
4. 定期的なコストのモニタリングとガバナンス
AWSの費用を管理するには、定期的なコストの監視とガバナンスが不可欠です。AWS Cost Explorer、コストおよび使用状況レポート、AWS Budgetsは、費用の傾向を追跡し、異常を特定し、予算のしきい値を設定するためのツールを提供します。これらのツールは、費用がサービス、アカウント、および地域にどのように分散しているかを可視化します。
AWS Organizations を通じてサービスコントロールポリシー(SCP)を実装するなどのガバナンスの実践により、リソースが組織のポリシーに準拠してプロビジョニングされることを保証します。例えば、SCP を使用して、コストの高いインスタンスタイプの使用を制限したり、リソースのデプロイを特定のリージョンに限定することができます。ガバナンスポリシーと組み合わせた定期的なコストの見直しは、組織が非効率性を特定し、コスト削減策を実施するのに役立ちます。
5. コスト管理のためのコードとしてのインフラストラクチャの利用
AWS CloudFormation、AWS CDK、TerraformなどのInfrastructure as code(IaC)ツールを使用することで、企業はコードを使用してクラウドリソースを定義および管理することができます。 IaCにより、リソースのプロビジョニングが常に一貫性のある自動化された反復可能なものとなり、コスト超過につながる可能性のある手動エラーの発生を低減できます。
IaCテンプレートでは、リソースの制限を指定したり、インスタンスの種類を制限したり、スポットインスタンスのようなコスト効率の高い構成を自動的に有効にしたりすることで、コスト管理のベストプラクティスを組み込むことができます。さらに、IaCにより、組織はインフラストラクチャのバージョン管理が可能になり、変更の追跡や構成の最適化が容易になります。
6. FinOpsの実践の採用
FinOps(財務業務)は、財務上の説明責任と業務効率を組み合わせた、クラウドコストの管理における協調的なアプローチです。 財務、業務、エンジニアリングの各チーム間の部門横断的な協力を促し、ビジネス目標に沿いつつ、クラウド支出の最適化を図ります。 FinOpsの実践には、定期的なコスト分析、予測、最適化の取り組みが含まれます。
FinOpsの重要な要素のひとつはコストの透明性であり、これによりすべての利害関係者が詳細な支出データにアクセスできるようになります。 この共有された可視性は説明責任を促し、データに基づく意思決定を推進してコスト削減を実現します。さらに、FinOps を採用する組織は、自動化と分析を活用してコスト管理戦略を改善し、継続的な改善を優先しています。
7. バックアップ管理とストレージの最適化
バックアップ管理とストレージの最適化は、データ保護と災害復旧機能を損なうことなく AWS コストを最小限に抑えるために不可欠です。 組織はバックアップ戦略を評価し、冗長なバックアップを排除し、過剰な保持を回避し、コスト効率の高いストレージソリューションを活用すべきです。
Amazon S3 GlacierやGlacier Deep ArchiveなどのAWSサービスは、アクセス頻度の低いバックアップの長期保存に最適です。ライフサイクルポリシーを適用することで、企業はあらかじめ設定した期間が経過したデータを自動的に標準ストレージ層からより低コストのアーカイブストレージに移行することができます。例えば、Amazon S3で日次バックアップを30日間保持した後、Glacierに移行することで大幅なコスト削減を実現できます。
さらに、重複排除と圧縮技術によりバックアップのサイズを縮小し、ストレージコストを削減することができます。N2Wのようなツールは、バックアップポリシーの一元管理を簡素化し、コスト効率の高い手法の自動化と徹底を容易にします。バックアップ構成の定期的な監査により、組織の保持ポリシーへの準拠が保証され、不要なデータの蓄積を防止することができます。

N2W最適化クラウドバックアップによるAWSのコスト削減
AWSのコスト管理は、価格設定を理解するだけではなく、より賢明な意思決定を迅速に行うことが重要です。そこでN2WSがサポートします。
当社のクラウドネイティブなバックアップおよび災害復旧プラットフォームは、AWS環境を推測に頼らずに管理できるようにします。 古いスナップショットの自動アーカイブ、アイドルリソースのシャットダウン、利用率の低いボリュームの監視など、すべてを直感的な単一のダッシュボードから実行できます。 AWS、Azure、Wasabiのいずれにバックアップする場合でも、N2Wはデータの安全性、不変性、コスト最適化を保証します。
N2WSがコスト削減に役立つ主な方法:
- スマートなスナップショットアーカイブにより、ストレージ費用を最大92%削減。
- 自動化されたポリシーとクロスクラウドDRにより、毎週何時間も節約。
- エアギャップストレージと不変のスナップショットにより、バックアップのセキュリティを確保。
- 内蔵のコストエクスプローラーとアラートにより、支出を可視化。
クラウドのコスト削減は、保護の妥協を意味するものであってはなりません。
スナップショット&イメージレベルバックアップ
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
Azureアプリケーションにおけるバックアップの一貫性について
- スナップショットのライフサイクルポリシーを活用してコスト管理:復旧性を損なうことなくコストを削減するために、古いスナップショットを低コストのストレージ階層に移行します。
- 代替案としてアプリケーション認識型レプリケーションを検討:バックアップが大きなオーバーヘッドをもたらすようなシナリオでは、重要なワークロードをリアルタイムで同期し、一貫性を保証するアプリケーション認識型レプリケーションソリューションを評価します。
- バックアップ用にリードレプリカを実装:データベースの場合、リードレプリカを作成し、そのレプリカに対してアプリケーション一貫性のあるバックアップを実行することを検討します。これにより、バックアップ中のプライマリデータベースのパフォーマンスへの影響を回避できます。
- テスト環境でバックアップをテスト:サンドボックス環境を使用して、本番環境のワークロードに影響を与えることなく、アプリケーション整合性のあるバックアップをテストします。自動化ツールを使用して障害をシミュレートし、リカバリ時間を検証できます。
- 不変ストレージでリカバリを強化:Azureで不変バックアップを設定することで、誤って削除されたりランサムウェアの被害に遭うことを防ぎます。アプリケーション整合性と組み合わせることで、悪意のあるデータ損失や誤って削除された場合の両方のシナリオで、リカバリの整合性を確保できます。
企業ニーズのためのAzure SQLバックアップとリカバリ
- Managed Identity を使用してバックアップを自動化: スクリプトに認証情報を埋め込む代わりに、Azure の Managed Identity を使用してストレージアカウントへの安全なアクセス権限を付与し、エクスポート/インポート操作を自動化します。
- バックアップと復元のパフォーマンスを監視:Azure Monitor を使用してバックアップ/復元操作のパフォーマンスを追跡し、障害や異常に長い操作時間に対するアラートを設定します。
- 地理的冗長ストレージを賢く使用:RA-GRS は耐久性に優れていますが、パフォーマンスとコストを最適化するには、ゾーン冗長ストレージ(ZRS)やローカル冗長ストレージ(LRS)を使用する方が適しているセキュリティの高いシナリオもあります。
- 機密データベースのバックアップ暗号化を有効にする:透過的データ暗号化(TDE)でデータベースのバックアップを暗号化します。さらにセキュリティを強化するには、Azure Key Vaultに格納された顧客管理キー(CMK)を使用します。
- 重要なバックアップに不変ストレージを組み込む:誤って削除されたりランサムウェアから保護するための長期的なバックアップ。これにより、バックアップが保持期間中に改ざんされないことが保証されます。
Azure Backupの基本について
バックアップとDRのワークフローを効率的かつ費用対効果の高いものにするために、その機能、長所、短所、考慮すべき点は:
●ライフサイクルポリシーを使用して経費を節約: 古いバックアップをAmazon S3 Glacierのような安価なストレージ・オプションに移動するライフサイクル・ポリシーを設定する。これにより、ストレージ・コストを大幅に節約できます。
●異なる地域とアカウントにバックアップする: バックアップを異なるAWSリージョンやアカウントにコピーすることで、ディザスタリカバリプランをより強固なものにする。これにより、リージョン固有の問題やセキュリティの問題からデータを保護できます。
●RTOを減らすためにバックアップを自動化する: AWS Backupを使ってバックアップ間隔を頻繁に設定しましょう。1時間ごと、あるいは数分ごとにバックアップを自動化することで、データを迅速に復旧し、ダウンタイムを最小限に抑えることができます。
●リソースのタグ付けによる容易な管理: タグを使用すると、関連するバックアップをすばやく識別してグループ化できるため、バックアップの管理やコストの監視が容易になります。また、レポートやコンプライアンスチェックも簡素化できます。
●ディザスタリカバリプランを定期的にテストします: DR訓練を自動化し、バックアップとリカバリのプロセスをチェックします。バックアップが機能し、データを迅速にリストアできることを確認し、潜在的な問題を発見して修正しましょう。
3.仕事に適したツールを使用する
Microsoft Teamsのバックアップに関する3つ目のベストプラクティスは、作業に適したツールを使用していることを確認することです。Microsoft 365のエコシステムの中には、保持ポリシーや、バックアップの実行を支援する機能などがあります。
保持ポリシーと訴訟ホールドは擬似的なバックアップとして機能することができます。しかし、これらのツールは、データ保護ではなく、コンプライアンス目的のために存在します。そのため、Microsoft Teamsのデータを適切に保護することはできません。
データ保持ポリシーと訴訟ホールドは、データの保護方法に関して矛盾やカバーギャップを生じさせる可能性があります。Microsoft Teamsのすべてのデータを確実に保護する唯一の方法とは、以下のとおりです。Microsoft 365を保護するために特別に設計された専用のバックアップアプリケーションを使用することで、ビジネス要件と法的義務に一致した方法で保護することができます。
1. Microsoft Teamsのバックアップを確認する
Microsoft Teamsのバックアップに関する最良の方法は、Microsoft Teams(およびその他のMicrosoft 365アプリ)を実際にバックアップしていることを確認することです。
Microsoftは、Teamsとその他のMicrosoft 365アプリケーションに責任共有モデルを採用しています。この責任共有モデルは、基本的に Microsoft 365 アプリケーションと基盤となるインフラストラクチャを健全に保つ責任は Microsoft にあるが、Microsoft 365 の加入者は以下の責任を負うというものです。自分のデータを安全に保護する責任があります。このデータ保護責任には、データのバックアップを確認することも含まれます。
2. Teamsを真に理解するバックアップ・ソリューションの採用
Office 365は、非常に多くの異なるMicrosoft 365コンポーネントを活用しているため、バックアップが最も困難なアプリケーションです。Exchange OnlineやSharePoint Onlineなどのアプリケーションとは異なり、Teamsは、すべてのデータを1つの場所に保存していません。その代わり、Microsoft Teamsのデータは異なるMicrosoft 365アプリケーションを使用されています。Microsoft 365のバックアップアプリケーションであれば、Teamsのデータをバックアップできるはずですが、アプリケーションがMicrosoft Teamsをサポートするように特別に設計されていない限り、復元プロセスが非常に困難になる可能性があります。
MicrosoftはTeamsのバックアップのためのAPIを提供していますが、このAPIは最近リリースされたばかりです。そのため現時点では、すべてのバックアップベンダーがTeamsバックアップAPIを製品に組み込んでいるわけではありません。
いずれは主要ななバックアップソリューションがMicrosoft Teamsをネイティブにサポートするようになると思われますが、当面はバックアップ製品に現在そのようなサポートを含んでいるかどうかを確認することが重要です。
4. バックアップのハイブリッド化
ベストプラクティスその4は、バックアップにハイブリッドなアプローチを取ることです。Microsoft 365とオンプレミスのMicrosoft Office アプリケーションを別々にバックアップするのではなく、両方の環境を同時に保護できる1つのバックアップアプリケーションを使用するのがよいでしょう。
なぜなら、バックアップを復元するということは、何か悪いことが起こったということだからです。どのような事象がデータ復旧の必要性の引き金になるかを予測するのは難しいため、バックアップアプリケーションは最大限の柔軟性を持たせることが非常に重要なのです。バックアップにハイブリッドアプローチを採用することで、この柔軟性を強化することができます。例えば、オンプレミスのメールボックスをMicrosoft 365クラウドに、またはその逆に復元することができるようなことが可能です。
5.バックアップ計画の最前線にSLAを据える
ベストプラクティスの5番目は、サービスレベルアグリーメント(SLA)をバックアップ計画の最前線に置いておくことです。具体的には、適切なRPO(Recovery Point Objective)とSLA(Service Level Agreement)を検討する必要があります。Microsoft Teams環境のRTO(Recovery Time Objective)です。RPOは、バックアップを作成する頻度を決定し、それによって、バックアップの間に失われる可能性のあるデータの最大量を決定します。RTOは、バックアップを復元するのにかかる時間の長さに関するものです。
この2つの指標は、組織の能力に直結するため、非常に重要です。災害からの迅速かつ完全な復旧組織においてRTOとRPOは恣意的な値ではなく、組織のビジネス上の要求と、その要求を反映したものであるべきです。
7.バックアップによるeDiscovery能力の強化
Microsoft 365 には以前から eDiscovery 機能があり、召喚状に応じて Microsoft 365 のエコシステムの中から特定のデータを探し出すことができます。しかし、ネイティブeDiscoveryの機能もありますが、ディスカバリプロセスではバックアップソフトを使った方が効果的な場合が多いのです。
バックアップアプリケーションに優れた検索インターフェースがあれば、組織は召喚状で要求されるデータをバックアップで検索することができます。これは、ネイティブのeDiscovery機能を使用するよりも迅速かつ簡単であるだけでなく、次のような機能も備えています。
検索結果に表示された文書をリムーバブルドライブに復元し、相手方の弁護士に提供できるようにします。
10. 使いやすさを重視
最後のベストプラクティスは、バックアップアプリケーションに関しては、使いやすさが重要であるということです。バックアップアプリケーションの中には、設定や使い方があまりにも複雑だという評判のものもあります。この問題は、複雑であればあるほどヒューマンエラーが発生する可能性が高くなることです。もし組織が直感的で使いやすいバックアップアプリケーションを選択すれば、バックアップやリカバリの失敗を高確率的に減らすことができます。
9.ストレージの柔軟性を確保する
使用するバックアップソリューションで、オンプレミスかクラウドベースかにかかわらず、データをバックアップできることが重要です。使用するストレージを自由に選択できることで、パフォーマンス、回復力、コストなどの要件に最も適したストレージ階層を選択することができます。また、イミュータブル(Immutable)ストレージのような機能を利用することもできます。
6.リカバリーの精度を見落とさない
Microsoft Teams Backupのベストプラクティスとして、よく見落とされるのがバックアップソリューションは、きめ細かなリカバリ機能を備えているかです。チーム全体(または複数のチーム)をリストアできることは重要ですが、チーム内のファイルやチャットをリストアできることも同様に重要です。
ユーザーが誤ってチームを削除した場合、多くの場合、そのチームを復元するにはPowerShell を使用して、Azure AD Recycle Binから関連する Azure Active Directory グループを復元します。
しかし、残念ながら、Teamsのネイティブ復旧は、無益な作業となります。Microsoft は削除されたチームを復元することを許可しますが、Microsoft 365 のネイティブ ツールを使用して個々のチームを復元することはできません。
8.ランサムウェアからチームを守る
もう一つのベストプラクティスは、Microsoft Teamsのデータをランサムウェアから確実に保護することです。一般的に考えられているのとは異なり、Microsoft 365に保存されているデータは、次のような方法で暗号化することができます。
ランサムウェア多くの人が個人所有のデバイスからリモートで仕事をするようになったことが、大きく影響し、ランサムウェアに感染するリスクを高めます。
ランサムウェアに感染した場合、組織のデータを復旧させるためには、通常、身代金を支払うか、バックアップを復元するかのどちらかの選択肢しかありません。身代金の支払いには高額な費用がかかる傾向があり、身代金を支払っても、実際にデータが復号化される保証はありません。たとえデータが復号化されたとしても、身代金を支払うと攻撃者が増長し、データを再暗号化し、さらに金銭を要求してくる可能性があります。バックアップを復元する方がはるかに良い選択です。バックアップは、ランサムウェアに関連するデータ損失に対する最善の防御策です。
11. クライムが提供する「マイクロソフトTeams バックアップ」ソリューション
● Veeam Backup for Microsoft Office 365
Veeam Backup for Microsoft Office 365は、Microsoft Office 365環境の包括的なバックアップを提供します。Exchange Online、SharePoint Online、OneDrive for Business, Microsoft Teamsのバックアップが可能です。
エンドポイントデバイスおよびクラウドアプリ向けのクラウドネイティブなデータ保護サービスです。社内のあらゆるエンドユーザーデータを自動的にバックアップし、データの復元、ランサムウェア/ 情報漏洩対策、データの可視化や分析など、さまざまなデータ保護機能を提供します。
0. 初めに:[マイクロソフトTeamsのバックアップ]について
10の注意事項 (プラス1)
1.徹底したプランニング
包括的な要件収集
多くの企業では、ビジネスプロセスや、ビジネスプロセスによってどのようにテクノロジーが推進されるのかについて、詳細な文書がない場合があります。このステップは、通常、計画の中で最も時間のかかる部分です。各ビジネスプロセスがどのように機能し、技術リソースとどのように相互作用するかを正確に把握することは、リソースをクラウドに移行することに意味があるのか、またどのような影響があるのかを判断するために非常に重要です。
コンピュート資源、ディスクスペース、ネットワークのニーズなどの技術的要件だけでなく、コンプライアンスや規制に関する考慮事項、リソースの可用性、他のビジネス・ワークフローとの統合も考慮する必要があります。
コストの見積
技術的なニーズとビジネスプロセスのニーズについて包括的な資料が揃ったら、ワークロードの移行、あるいはクラウドでのワークロードの再実装に関連するコストとメリットを検討し始めることができます。従来のコンピュートやストレージのニーズ以外にも、さまざまな考慮事項があります。
– バックアップのコスト、ポータビリティ、スペース
– リソースの初期転送と継続的なニーズに対応するための帯域幅
– ロードバランサー、アプリケーションゲートウェイ、スケール関連機能
– Azure AD(プレミアムの場合)およびOffice 365ユーザーのライセンスコスト
– Microsoft SQLやMicrosoft WindowsなどのVMライセンス
– 開発環境リソース
– 継続的インテグレーション/継続的デプロイメント(CI/CD)コスト
オンプレミスで購入したハードウェアの保守契約費用を除けば、ほとんどのクラウドリソースには定期的な使用費用が発生します。従来の資本支出モデルと比較すると、クラウドサービスの運用コストは複数年に渡って分散される可能性があります。短期間の利用であれば比較的リーズナブルですが、慎重に管理しないとコストオーバーにつながる可能性があります。
制約と予算のしきい値
多くの企業では、IT予算が無制限にあるわけではありません。Azureはリソースのデプロイを容易にし、それに応じて予算オーバーも容易にします。しかしAzureは「自分のペースで学べるAzure Cost Management tools」によって、クラウドのコストを計画し、コントロールすることも簡単にできます。
また、予算というと実際の金額が思い浮かぶかもしれませんが、それだけが予算ではありません。利用可能なリソースでチームを最大限に活用するために、人的資本の予算も重要です。
– 各ビジネスユニットの予算と、それが具体的なリソースにどのように関わってくるかを検討
– どの時点で、誰に、どのようなアクションを起こすべきか、予算に関する警告を行うべきかを決定する
– 拡張性のあるリソースは、無秩序な成長とコストを避けるために制約を設ける必要がある
Azureの異なるサービスやオファリングは、コストと機能価値を比較した場合、同等とは限りません。このため、利用可能な機能と関連するコストの両方を戦略的に検討し、組織にとって最も価値のあるものを選択することが重要です。
共有資産の利用可能性
類似のワークロードは、共有リソースを活用する上で魅力的なターゲットとなります。セキュリティ、セグメンテーション、パフォーマンスなどの理由で専用インスタンスを必要としないリソースは、共有のコンピュート、ストレージ、アプリケーションインスタンスを使用することでコストを削減することができます。このような基準に合致するワークロードを特定することで、統合によって使用するリソースを節約することができます。
仮想マシンの共有による統合だけが、コスト削減の手段ではありません。コンテナベースのデプロイメントを検討する場合、Azure Kubernetes Serviceのような専用の管理プラットフォームを利用すると、配置と利用を最適化でき、投資を最大限に生かすことができる場合があります。
ガバナンス戦略
IT担当に与えられた柔軟性により、クラウドは瞬く間に戦場と化す可能性があります。事前に適切なガバナンスプランと戦略を導入することで、制約のない広がりを制御すると同時に、イノベーションのための自由とコスト管理を可能にします。Azureポリシーによって、組織はIT担当者が利用できるリソースの種類、サイズ、機能を制御することができます。さらに、リソースのタグ付けを利用することで、これらのリソースをグループ化し、さまざまなチーム、リソースタイプ、プロジェクトに関連付け、レポートを作成してコストを管理することができます。すべてのリソースにタグ付けできるわけではなく、タグは継承されないため、適切なタグ付け戦略を確実に実行することが重要です。
0.Azureコスト削減のための4つの施策 (初めに)
ここでは、Azureでコストをコントロールしながら、利用可能なすべてのサービスと機能を最大限に活用するための4つのステップについて説明します。新たにクラウドを導入する企業も、以前からクラウドファーストのアプローチを取っている企業も、適切な計画、展開、監視、最適化によって、Azureの活用を成功させることができます。
2. 実装と展開
適切な計画が立てば、次のステップは必要なリソースの配備です。クラウドへの完全移行に重点を置いている場合でも、単に小規模から始める場合でも、価格と柔軟性について考慮することで、将来的に大きな違いが生まれます。計算機、ディスク、データベースには、コストを大幅に削減できるさまざまなオプションが用意されています。
コンピュート・リソース
クラウドベースの仮想マシンは、最も一般的に使用されるクラウドリソースの1つであり、多くのITプロフェッショナルが最初に検討するものの1つであると思われます。仮想マシンをデプロイする必要がある場合、Azureはいくつかのコスト削減策を提供しています。
– 予約済み仮想マシンインスタンス : 指定されたリソースの年数を事前に購入することで、企業はより低いコストで利用することができます。
– スポット価格 : 特定のマシンが常に存在する必要はありません。そのような場合は、スポット価格を使用して、未使用のコンピューティング容量を大幅な割引価格で購入することができます。アプリケーションは潜在的なシャットダウンに強いことが必要ですが、その場合は大幅なコスト削減を実現できます。
– Dev-Test Pricing – 堅牢な開発およびテスト環境を持つ組織では、これらのマシンは通常短命で使用率が低いため、これらの環境の割引料金を利用することでコストを抑えることができます。
また、コンテナやPlatforms as a Service(PaaS)は、その柔軟性と使いやすさから非常に人気が出てきています。Azure Kubernetes Service (AKS) は、コンテナのオーケストレーションに最適です。ワークロードをコンテナに移行することで、企業はリソースをより緊密にまとめ、最新のマイクロサービス・アーキテクチャを活用することでコスト削減を実現することができます。App Services などの PaaS は、Web サーバーの従来の管理負担を軽減するものです。既存のWebサイトをApp Servicesに移行することで、従来のVMを使用する必要がなくなり、管理時間やコストそのものを削減できる可能性があります。
Azureストレージ層の活用
クラウド環境のコンピューティング能力を支えるのは、大容量のデータを保存する必要性です。そのため、必要なストレージの種類を適切に計画することに時間をかければ、コストを削減することができます。このことは、組織のデータストレージのニーズが高まり、特定の種類のデータが特定のストレージ層に最適であることが判明した場合に特に顕著になります。
Azure Storageのいくつかの機能は、データの安全な転送と保存のための魅力的なオプションになります。プライベートエンドポイントを使用すると、クライアントがプライベートリンクを介してストレージデータに安全にアクセスできるようにすることができます。これにより、公共のインターネットからの露出を制限し、ストレージへのアクセスの制御を強化することができます。
Azureストレージの価格
Azureで利用できるストレージにはいくつかの種類がありますが、一般的に多くのニーズを満たすのは、マネージドディスクとブロブの2種類です。
マネージドディスクは、従来のストレージメディアで、物理サーバーにインストールされた追加のハードディスクに相当します。この拡張可能なディスクには、いくつかの異なる階層があります。どのようなディスク速度を必要とするかによって、いくつかの層から選択することができます。
– プレミアムSSD
– スタンダードSSD
– スタンダードHDD
– ウルトラディスク
ディスクの速度について語るとき、一般的には1秒間に行われる入出力操作の数であるIOPSを意味します。管理対象ディスクの階層によって保証されるIOPSが異なるため、アプリケーションのパフォーマンスに直接影響を与えることができます。P30より小さいプレミアムSSDサイズでは、バースト可能なIOPSと帯域幅を提供し、VMの起動時間とアプリケーションのパフォーマンスを大幅に向上させることができます。このタイプのバーストは、VMレベルおよびディスクレベルで独立して利用可能です。一方を有効にすれば、もう一方は必要ありません。どちらも、1日を通して使用するIOPSクレジットのバケットを蓄積して使用します。このバケットを使い切ると、パフォーマンスは基本ディスク・タイプのものに戻り、使用前に再度蓄積する必要があるため、アプリケーションやVMのパフォーマンスに悪影響を与える可能性があります。
Azure Blob は、保存すべきデータが大量にある場合に、より理にかなっていると言えるかもしれません。このデータは、常にアクセスする必要がない場合もあれば、複数のリソースで簡単に共有する必要がある場合もあります。バックアップは、Blobストレージの典型的な使用例である。このタイプのストレージは、AWS S3タイプのオブジェクトおよびメタデータストレージファイルシステムに相当する。Blobストレージにはいくつかの階層があり、価格とアクセス速度に影響します。
– プレミアム
– ホット
– クール
– アーカイブ
Azure Blobストレージのコストは、月間の1日あたりの平均保存データ量(ギガバイト(GB)単位)で決定されます。例えば、月の前半に20GBのストレージを使用し、後半は全く使用しなかった場合、平均10GBの使用量に対して請求されます。クール層とアーカイブ層から45日後に削除する場合、135日分(180日から45日を引いた日数)の早期削除料が課金されますので、計画的に利用ください。
ファイルストレージとブロックブロブストレージの両方について、冗長性に関するオプションがあります。ローカル冗長ストレージ(LRS)と地理的冗長ストレージ(GRS)のどちらを選ぶかは、コストに大きく影響し、2倍から3倍のコストになることもあります。GRSは保護とアップタイムを向上させますが、コストは高くなります。レプリケーションの設定はいつでも変更可能ですが、LRSから他のタイプのレプリケーションに移行する際には、イグレス帯域幅の料金が発生します。
また、Blobストレージのアプリケーション・プログラミング・インターフェース(API)のコストも考慮しなければなりません。読み取り、書き込み、リスト、作成の各操作には、1万トランザクションあたりのコストがかかる。オブジェクト操作の量が多い場合、これは計画上予想外のコストとなる可能性がある。Blobストレージが、大きな単一オブジェクトでアクセス頻度の低いデータにのみ使用されている場合、APIコストは無視できると思われます。
Cool層とArchive層からそれぞれ30日、180日未満でデータを取り出す場合、追加料金が発生する可能性があることに留意してください。これらのストレージは、より長期的で安価なストレージであることを意図しています。
SQLエラスティックプール
SQLサーバーはすぐに高価になります。本番データベース1つにつき1台のサーバーという従来のモデルでは、特にライセンス要件によって、コストが爆発的に上昇する可能性があります。SQL Elastic Poolsは、データベース間でコンピュートとストレージのリソースを共有し、プロビジョニングされたすべてのリソースを効率的に使用するもので、コストを劇的に削減できる拡張性のあるソリューションです。
リソースの使用量を制限することで、データベースがリソースを乱用して他のデータベースに悪影響を与えないように、さらに最適化し制限することができます。プールの価格は、設定されたリソースの量に基づき、データベースの数とは無関係に決定されます。このタイプのセットアップは、データベースごとに1台のサーバーを使用するアプローチではなく、顧客のデータベースをホスティングする場合にも最適です。
例として、30人のお客様がいて、それぞれがデータベース・インスタンスを持っているとします。最も安価な5 DTUプランを約4.8971ドル/月で購入すると、顧客データベースを格納するためのコストは結局約147ドルになります。Elastic Poolsに移行すると、50 DTUプランを73ドルで購入でき、最大100個のデータベースを扱えるようになります。また、個々のデータベースが使用するリソースを制限することで、プール全体への悪影響を抑制することができます。
Azure Functionsによるサーバーレス
多くの組織が新しい「サーバーレス」能力を活用しています。インフラを管理することなくコードやアプリケーションを実行できるため、迅速な導入と開発につながります。Azure Functionsは、C#、Java、JavaScript、Python、PowerShellでコードを記述し、オンデマンドまたはスケジュールに従ってコードを実行する機能を提供します。
使用量に応じた課金モデルを採用しているため、コードの実行に費やした時間に対してのみ料金を支払う必要があります。400,000GB/s(メモリ使用量に基づくギガバイト秒)と100万回の実行が無料であるため、消費プランでは最小限のコストで始める方法が提供されています。
バックアップソリューションの最適化
ストレージ層についてのセクションで述べたように、バックアップにBlobストレージを使用すると、特にCool層とArchive層を使用する場合、コストを削減することができます。このタイプのストレージは通常、障害発生時に迅速にリストアする必要があるフルVMスナップショットには使用されません。Microsoft Azureは、各VMに適切なスナップショットが取得されるように支援するバックアップサービスを提供している。これは、VMごとの固定コストと消費されたストレージのコストに基づいています。
どのようなビジネス環境においても必要不可欠なバックアップのコストを軽減するために、Veeam Backup for Microsoft Azureのようなサードパーティ・ソリューションを使用することで、多数のVMのバックアップや、データを長期間保持する必要がある場合のコストを節約することができます。例えば、VeeamはAzure用に構築されたクラウドネイティブバックアッププロセスにより、10台のVMを無料で提供しています。ビルトインのコスト計算機により、作成するバックアップ・ポリシーにどれだけのコストがかかるかを実装前に積極的に確認することも可能です。
さらに、Veeamはクラウドに依存しないファイル形式を使用しているため、データのポータビリティを実現します。このバックアップ・プロセスの明白でない利点は、Veeamを活用してオンプレミスのマシン・バックアップを自動的にクラウドに移動することができることです。オンプレミスサイトが突然アクセス不能になった場合、データポータビリティとクラウドネイティブソリューションにより、Veeamバックアップを活用して、以前に作成したバックアップを経由して環境を迅速に起動することができます。
コンテナのバックアップの必要性については、その刹那的な性質からあまり考えないかもしれませんが、Kubernetesクラスタにはステートフルなコンテナと関連する設定やメタデータが存在することがよくあります。すべてのコンポーネントをまとめて包括的にバックアップし、環境全体を迅速に復元できるようにすることは困難です。例えばVeeamのKasten K10は、Kubernetesクラスターのあらゆる側面をバックアップする機能を提供します。さらに、適切なポリシーとリソースのディスカバリーを定義することで、適切なガバナンスを確保し、リソースの取りこぼしがないようにします。
3. 環境、コスト、トレンドのモニタリング
環境が正常に稼働している間に、組織はすべてのリソースが監視され、計上されていることを確認し、コストの傾向を特定する必要があります。Azureは、リソースのコストを表示し、レポートするためのいくつかの異なるソリューションを提供しています。
Azureコスト管理ダッシュボードに注目する
結局のところ、リソースをどこでどのように使っているか、そしてその関連コストを本当に理解する唯一の方法は、ダッシュボードを使用して、最もお金がかかっている場所を可視化することなのです。Azureコスト管理は、お客様の組織とそのリソースの使用パターンを包括的に見ることができます。これには、Azureのサービスごとのコストと、サードパーティのMarketplace製品ごとのコストの両方が含まれます。
Azure内には非常に多くのコスト計算方法があるため、予約やAzure Hybrid Benefitの割引を考慮したコスト計算ソリューションがあれば、使用中のリソースに関してスマートな意思決定ができるようになります。
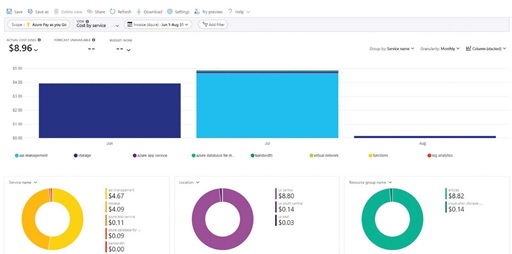 Azure Cost Management dashboard
Azure Cost Management dashboard
また、データをCSVで他の会計システムや予算管理システムに簡単にエクスポートすることができます。ただしアドバイザーの推奨、予算管理、コスト超過を防止・予測するためのコスト警告機能が組み込まれているため、その必要はありません。
法規制とコンプライアンスの監視
コスト管理と同様に重要なのが、規制やコンプライアンスに関する管理です。
があります。Azure Security Centerには、ISO 27001、PCI DSS 3.2.1、Azure CIS 1.1.0、HIPAA HITRUSTなどの規格への準拠を確認および評価するための規制遵守ダッシュボードが含まれています。
重要な規制基準への準拠を積極的に監視することで、適切なセキュリティが確保されます。また、将来の監査において、コストのかかる頭痛の種やコンプライアンス作業を軽減することができます。
4.環境とコストの最適化
環境とコストの最適化多くのクラウド環境は流動的であるため、環境のニーズ、パフォーマンス、利用状況を継続的に評価することが重要です。拡張の機会が特定されたら、さらなる対策を講じることができます。使用されているリソースの種類によっては、異なるクラスのリソースやPaaSへの移行が必要となる場合があります。
大規模な環境では、多くのワークロードが使用されていることがよくあります。多くのVMが存在するため、リソースの統合や廃棄の機会があるかどうかを判断するのは難しい場合があります。あまり使用されていないサービスを発見するのに役立つツールの1つが、モニター・サービスです。仮想マシンのインサイトセクションを利用すれば、VMの使用率に関する集計データを見つけ、最も多くのリソースを使用しているVMや最も使用していないVMを発見することができます。
適切なモニタリング戦略があれば、VMのサイズを変更するなどのさらなる措置を講じることができるかもしれませんし、従来は仮想マシン上に置かれていた特定のアプリケーションをコンテナ化して、さらにコストを削減する必要があることが分かるかもしれません。
同様に、ストレージアカウントの節約を見つけるために、「Monitor Storage Accounts Insights」セクションは、指定された期間におけるトランザクション量と使用容量を分析し、節約の機会を明らかにします。このツールは、どのアカウントが不要になり、どのアカウントを統合できるかを特定するのに役立ちます。
リソースを管理する上で見落とされがちなのが、効果的なタグ付けの方法です。使用中のリソースに適切なタグを付けることで、廃棄の対象となるリソースを容易に特定することができます。さらに、タグ付けを行うことで、リソースのライフサイクルを管理するためのレポートを作成することができます。
N2WS vs. AWS Backup
復旧シナリオ : AWS環境でのデータ保護の構成管理ツール「 N2WS 」では、災害やAWSの停止が発生したときに実行できるシナリオを作成することができます。これにより、最も重要なリソースを重要度の高い順に復旧させ、RTO/RPOを最小化することができます。この機能のドライラン機能により、テストを実施し、これらの復旧を実行するための準備がすべて整っていることを確認することができます。
クロスリージョン/アカウントディザスターリカバリー :N2WSは、最も包括的なクロスアカウント/リージョンを提供し、ボタンをクリックするだけで全環境をリカバリーすることができます。AWS Backupのバージョンは非常に基本的で、実行が複雑です。
スケジュール :AWS Backupでは、バックアップのスケジュールを1/12/24時間ごとに設定するよう制限されています。N2WSではそのような制限はなく、バックアップは1分ごとにスケジュールすることができます。
ファイルレベルリカバリー : AWS Backupは、Amazon EFSのファイルレベルリカバリーのみをサポートしています。N2WSは、EFS、EC2、S3に対してファイルレベルのリカバリを実行できます(暗号化されたボリュームに対しても)。
Start/Stop Servers (Resource Source Control) : N2WSのこの機能は、EC2インスタンスのアクティブ化と非アクティブ化のスケジュールを設定することが可能である。例えば、非生産用のインスタンスを月曜日から金曜日の午前9時に開始し、午後5時に停止するようにスケジュールすることができる。これにより、お客様はAWSのコストを数千ドル削減することができます。N2WSのお客様であるGett様は、この機能により年間60,000ドルのコスト削減を実現しています。
RDS MySQL & PostgresSQL (S3) : N2WSは、これらのRDSカテゴリをS3に保存することができ、より安価でコールド・ストレージを使用することにより、ストレージコストを大幅に節約することができます。AWS Backupにはこの機能はありません。
自動化 : N2WSによる自動化のおかげで、お客様は他の重要なトピックにエネルギーを集中させることができ、N2WSにバックアップの世話をさせることができるようになります。つまり、一度必要なポリシーとスケジュールを作成すれば、あとはツールがバックグラウンドでバックアップを行い、何か問題が発生したり、注意が必要な場合はアラートが表示されるのです。N2WSは、保存ポリシーに応じて、S3、Deep Archive、Glacierなどのコールドストレージへの保存を自動化することも可能です。これにより、AWSのコストを大幅に削減することができます。
カスタマーサポート : N2WSは、24時間365日のプレミアムサポートを提供し、必要なときにはサポートします。AWSのサポートは別途費用がかかります。
レポートログとモニタリング : AWSでは、レポートログとモニタリングは別料金で、設定が必要です。N2WSでは、バックアップ、リストア、管理、監査の全活動を監視し、追加コストなしですぐに使えるレポートを提供します。
AWS Backupの制限について
AWS Backupは基本的なバックアップの自動化に重点を置いており、災害復旧、粒度の細かい復旧、復旧のオーケストレーションやドリルなどの組み込み機能が欠けているなど、いくつかの制限があります。しかし、よりシンプルなバックアップのニーズを持つ組織にとっては、便利なソリューションとなるでしょう。より高度な要件には、N2Wのようなサードパーティのツールが、より費用対効果や効率性の面で優れているでしょう。
- ワンクリックでのリストアなし:AWS Backupを使用したリストア操作の自動化は、API操作を使用してプログラム的に行う必要があり、これはDevOpsの実践がしっかりしている企業には適しているかもしれません。より簡単なリカバリオプションを求める人にとっては、N2Wはスクリプトを必要とせず、簡単かつほぼ瞬時にワンクリックでリカバリを行うことができます。
- 粒度の細かいリカバリなし: AWS Backupは、ファイル/フォルダレベルの粒度を伴わずにサーバー全体をリカバリします。(AWS Data Lifecycle Manager やその他の AWS サービスでは、より詳細なバックアップ戦略が利用できる可能性があります。)完全な柔軟性と詳細性が必要な場合は、N2W を使用してバックアップおよびリカバリのファイル/フォルダをドリルダウンしたり、複数の世代のバックアップを検索して特定のファイルを見つけることができます。バックアップの分類について事前に計画したりインデックスを作成しておく必要はありません。N2W が自動的にドリルダウンアクセスを提供します。
- 災害復旧なし:AWS Backupでは、ユーザーが手動でスナップショットを別のリージョンにコピーすることは可能ですが、自動復旧オプションはありません。 現在、多くの企業がAWS Organizationsの一部として複数のAWSアカウントを運用しているため、アカウント間のバックアップができないことは、企業にとって大きな制限となります。 アカウント間の災害復旧は、あらゆるDR計画の重要な要素であり、ランサムウェア、内部からの悪意ある攻撃、または人為的ミスなど、AWSアカウントが侵害されるのを防ぎます。
N2Wは、クロスリージョンおよびクロスアカウントの災害復旧を完全にサポートしています。例えば、ユーザーは30秒以内に他のリージョンまたはアカウントのEC2インスタンスを完全に復旧することができ、RTO(目標復旧時間)を短縮できます。
- ネットワークの復元なし: もう一つの重要な機能として、AWSインフラ全体の可用性を確保する上で不可欠なAmazon VPCのクローン作成とキャプチャができないという点が挙げられます。一方、N2W Backup & Recoveryでは、この機能が提供されており、停電や障害が発生した場合でも、わずか数分でインフラを迅速かつ完全に復旧させることができます。
- リカバリーシナリオなし:AWSバックアップには、リカバリーシナリオ機能(スクリプト作成なし)がありません。N2Wでは、完全なDRフェイルオーバーの綿密なオーケストレーションを作成し、リカバリーシナリオ内で復元したいリソースに変更を加え、リカバリーの優先順位を決め、DR訓練を自動化することができます。
- 真のアーカイブなし:AWSバックアップでは、EBSバックアップを低価格のS3ティアリングにアーカイブすることはできません(EFSのサポートは例外)。N2W Backup and Recoveryは、実際のS3バケットにデータをアーカイブする機能があり、あらゆるS3階層にティアリングすることができます。また、N2W ZeroEBSオプションでは、AWSスナップショットを一切使用せずにバックアップをアーカイブすることも可能です。つまり、N2Wを使用することで、ストレージコストを最大98%削減できるということです。
その他の制限事項としては、
- お客様のリソースが保護されているか、されていないかがわからない
- 検索機能が限定的(リソースを検索するにはボリュームIDを知っておく必要がある
- シングル・ペイン・オブ・グラス(一元管理)機能なし – 複数のアカウントを管理することはできず、すべてのアカウントはアカウントごとに管理される。ただし、同じマスター支払者アカウント下にある場合は例外(これは、独立したユーザーやクライアントを管理するMSPにとって特に重要である
- 監査に特に重要となる、何か問題が発生した場合のレポート、日次サマリー、アラート機能なし
- 正確なバックアップ時間の知識不足(バックアップは一定の時間枠内で行われる) – N2Wでは60秒ごとにバックアップが可能ですが、AWSバックアップでは最小間隔として1時間枠しか選択できません
- 自動コールドティア/長期保存(EBSスナップショットをAmazon S3またはAmazon Glacierにコピーする)のサポートなし
- 各アカウントで100のバックアップ保管庫と100のバックアップ計画に制限されるサービス制限。
- バックアップジョブを実行する際、リソースごとに同時に実行できるジョブは1つだけ。
- 災害復旧訓練のサポートが限定的
- バックアップ自体を保存しないとバックアップログを保存できない
- リソース制御のサポートがないため、ユーザーはインスタンスの開始/停止をスケジュールしてリソースの使用を最適化/最小化できない
- ファイルまたはフォルダレベルの復旧のサポートがない
- タグ管理に大きな制限がある。通常、ほとんどの使用事例では十分な数であるにもかかわらず、リソースに50以上のタグを設定することができない。
- 他のアカウント/地域におけるAmazon S3バケットの複製に対応していない
- バックアップコピー操作の前にアプリケーションを静止状態にすることが非常に重要である場合が多いが、アプリケーションの一貫性に対応していない
- 24時間365日の無料サポートなし。通常、顧客は営業時間まで待たなければならず、チケットへの対応には数日かかることもあります。ダウンタイムの数分間が企業に数百万ドルの損失をもたらし、顧客の信頼を失い、完全に廃業する可能性さえあることを考えると、これは大きなリスクです。
きめ細かく信頼性の高いバックアップ管理を確保する方法は他にもあり、どのツールが自社のニーズを満たすかを確認するために、他のオプションを調査し、テストすることが重要です。
AWSコスト (24)
適切なEC2インスタンスタイプの選択には
EC2サービスは、おそらくAWSでのクラウドの旅で最初に選ぶものの1つでしょう。60以上のインスタンスタイプがあり、最適なものを選ぶのは至難の業です。まずは、インスタンスの目的を考えてみてください。それを元に、以下の表を見て最適なタイプを絞り込むことができます。
ライトサイジングとは、性能要件を満たした上で、最も安価なオプションを選択することであることを忘れないでください。経験則では、長期間にわたってインスタンスのリソース使用率が80%になるようにすることです。
常に最新のCPUを選択すること
技術は止まらず、CPUメーカーはほぼ毎年、より高性能で消費電力の少ないCPUを発表し、AWSもそれを実装しているので、必ず定期的にインスタンスタイプ表に戻ってくることです。例えば、10台のインスタンスをc4.xlargeからc5.xlargeに変更するだけで、年間約2,500ドルの節約になり、同時に各インスタンスに多くのRAM(16 -> 20GB)と約5%の性能向上を実現します。
このヒントは、AWS Compute Optimizerを確認することです。このツールは、このタイプの変更をアドバイスすることができます。
一時的なデータ用にEC2インスタンスストアを検討する
通常、AWSユーザーはEC2インスタンスを新規にセットアップする際に、EBSストレージ(つまりディスク)に注目することになります。それらのディスクは、インスタンスにアタッチしたり、インスタンスからデタッチしたり、データ保護のケースでスナップショットしたりすることができます。インスタンスが停止しても、データはディスク上に残り、どこにも行きません。
もう1つ、検討する価値のあるオプションがある。EC2インスタンスストアを経由してローカルディスクを使用します。これらのディスクの大きな違いは、対応するインスタンスが停止されると、ディスクがクリーニングされることです。ユーザーはインスタンスの使用料のみを支払っているため、「無料」です。
貴重なデータにローカルディスクを使いたくないのは理解できるが、キャッシュやログなどの一時的なデータにはぴったりなケースもあります。また、下敷きのストレージは高速なSSD、あるいはNVMeなので、十分なパフォーマンスがありますので安心ください。EC2インスタンスストアを利用することで、EBSの消費量も少なくなり、月々の請求額も小さくなります。
スポットインスタンスを活用する
スポットインスタンスのコンセプトは、パブリックマーケットと比較するとよく理解できます。価格は、利用可能な未使用のAWS EC2容量の供給と需要に基づいて変動します。AWSユーザーはそこに行き、希望する価格を入札することができす。もし需要がそれほどなければ、市場は一時的に低い価格で売ることに同意し、結果として通常価格の3倍から6倍の値下げをすることになります。
では、何が問題なのか?需要が高まる瞬間には、必要な資源を受け取れないかもしれない。価格がその希望する上限を超えると、プロビジョニングされたインスタンスは短期間で自動的に終了してしまいます。もちろん、重要なデータをこのような変動にさらしたいと思う人はいないでしょう。しかし、このモデルがうまく機能するケースも多くあります。ロードバランサーの背後にあるメディアレンダリング、ビッグデータ、分析、Webサービスなども、この機能の最初の候補の1つになるはずです。
例えば、ここにノースバージニア地域のスポットインスタンスの価格履歴があります。過去3ヶ月間のt2.largeインスタンスの需要と価格設定が示されています。
上の表からわかることは:
●実質的な価格はオンデマンドの3分の1程度になる可能性がある
●6つのAZはすべて、平等ではないものの、余裕のあるキャパシティを持っている
●価格が安定しないので、最低料金で入札しない
この技術をアクティブなCloudWatchとAuto Scalingで補完すれば、2分間の終了アラートを受信した時点で、システムは負荷をリバランスし、オンデマンドインスタンスに切り替わることができます。
忘れてはならないネットワークコスト
AWSのネットワークは独自の論文に値するものですが、物事をシンプルに保つために、あまり深入りせず、とにかくここでいくつかの重要なヒントに触れておくべきだと思います。
オンプレミスサイトとAWSの間で大量のトラフィックがやり取りされる場合、Direct Connection機能を使えば、より安定したネットワーク体験、帯域スループットの向上、接続の安全性を確保することができます。
静的コンテンツ(画像、動画、音楽など)は、S3とCloudFrontの組み合わせでより良く、より安価に配信することができます。世界の様々な地域にある素晴らしいエッジサーバーのセットで、エンドユーザーはより近い場所にあるサービスキャッシュから来るデータを得ることができます。
異なるAWSサービス間のトラフィックフローを分析する。VPCからS3のような他のサービスへのトラフィックがエンドポイントを経由するようにVPCエンドポイントを構成することで、インターネットや公共ネットワークをバイパスし、より安全で安価な接続を実現します。
可用性ゾーン間のトラフィックについても、別の費用がかかるので、忘れないようにしましょう。フォールトトレランス・アーキテクチャを再考してください。すべてのサービスに必要でない場合もありますし、他の技術で実現できる場合もあります。
それに応じて地域を検討する
AWSのサービスの価格は、データセンターが置かれている物理的な場所に依存することに気づくのは簡単です。これは当たり前のように聞こえるかもしれませんが、理にかなっている場合は価格の安いリージョンにリソースを移行してください。
現在の価格を計算して、小さな例を紹介しましょう。ヨーロッパでt3.2xlargeインスタンスを10台、それぞれ150GB SSD gp2のディスク容量で稼働させる必要があるとします。ドイツ・フランクフルトのデータセンターを選択した場合、AWSのコンピュート利用料金は0.5312ドル/時間、一方スウェーデン・ストックホルムのデータセンターでは0.4928ドル/時間となる。さらに、ストレージコストとして1GB/月あたり$0.119 vs $0.1045を加え、1年間運用します。この差は、同じサービスであれば、24*365*10*$0.0384+$0.0145*1,500GB*12m = $3,364 + $261 = $3,625 の年間コストダウンに相当し、単に安い地域を選択したことになるのである。
これは、価格の高い地域をすべて、一度に捨てなければならないということなのでしょうか?そうとは限りません。先ほども言ったように、意味があるときにやればいいのです。アジアで事業を展開し、ユーザーに最も低いレイテンシーを提供しようとする場合、アプリケーションを米国に移動させる理由はないでしょう。ただし、負荷の低いサービスや静的なコンテンツについては、米国に移すことも可能です(詳しくは後述します)。もうひとつ注意しなければならないのは、個人情報の取り扱いです。GDPR(一般データ保護規則)やCCPAのような世界的な規制が障害となる可能性があります。
サービス利用を予測し、先行コミットすることを目指す
パブリッククラウドの柔軟性、CAPEXからOPEXへの移行が言われていますが、請求書を減らすAWSの機能であるRI(Reserved Instances)や節約プランなどは、皮肉にもCAPEXに戻るように見えてしまうものです。しかし、実際に50%以上の割引が得られるのですから、誰もが「導入のベストプラクティス」リストに挙げるべきでしょう。
まずは、EC2インスタンスの時間単価の割引とオプションの容量予約を提供するRIを検討することから始めましょう。1年または3年のコミットメントと引き換えに、インスタンスコストの割引を受けることができます。オンデマンドインスタンスは、無制限の柔軟性を持ってワークロードをプロビジョニングすることを好む人にとって良い選択肢となる。しかし、負荷が予測可能なワークロード(Webサービスなど)を常時稼働させる場合は、RIの方がはるかに優れています。
節約のまとめ。
• 予約時間が長いほど、割引率がアップします。
• 前払い金額が多いほど割引率が高くなる(ただし、前払い金0円も可能)
• 標準クラスはコンバーチブルより安い(ただし、インスタンスタイプは作成後に変更できない)
コンバーチブルインスタンスは、サイズダウンやAWS Marketplaceでの販売ができないため、注意が必要です。最小のインスタンスから始め、必要に応じてアップグレードすることで、最大36ヶ月間の月々の支払いを約束させられることを避けることができます。
忘れてはならないネットワークコスト
AWSのネットワークは独自のものですが、物事をシンプルに保つために、あまり深入りせず、とにかくここでいくつかの重要なヒントに触れます。
1)オンプレミスサイトとAWSの間で大量のトラフィックがやり取りされる場合、Direct Connection機能を使えば、より安定したネットワーク体験、帯域スループットの向上、接続の安全性を確保することができます。
2)静的コンテンツ(画像、動画、音楽など)は、S3とCloudFrontの組み合わせでより良く、より安価に配信することができます。世界の様々な地域にある素晴らしいエッジサーバーのセットで、エンドユーザーはより近い場所にあるサービスキャッシュから来るデータを得ることができます。
3)異なるAWSサービス間のトラフィックフローを分析する。VPCからS3のような他のサービスへのトラフィックがエンドポイントを経由するようにVPCエンドポイントを構成することで、インターネットや公共ネットワークをバイパスし、より安全で安価な接続を実現します。
4)可用性ゾーン間のトラフィックについても、別の費用がかかるので、忘れないようにしましょう。フォールトトレランス・アーキテクチャを再考してください。すべてのサービスに必要でない場合もありますし、他の技術で実現できる場合もあります。
マスターアカウントの下にユーザーを統合する
組織内で複数の人がAWSを操作する必要がある場合、統合課金によって支払いが簡単になるだけでなく、ある閾値に達すると、S3などの消費リソースを割引くことができます。また、AWSのティアによっては、使用量が多いほど価格が下がったり、事前にインスタンスを購入することで割引が適用されたりするものもあります(上記のRIやSaving Plansのようなもの)。さらに、未使用のリソースは、ある子アカウントから別の子アカウントに再配布することができます。ここで先に述べたコスト最適化ツールを適用し、多数のアカウントを運用する際の組織の混乱を防いでください。
標準ツールで消費量を監視する
AWS Cost Explorerは、すべてのお金がどこに行くのかを可視化し、最も消費されるサービスに対応することが非常に簡単にできるため、あなたの頼りになるはずです。これは、実施された分析に基づいて、興味深いパターンを特定し、根本的な原因まで掘り下げることができます。
コストエクスプローラー インスタンスタイプの消費を表示
AWS Compute Optimizerは、アカウント(またはマスター1つ下のすべてのアカウント)に対して収集され分析されたデータに基づいて、AWSリソースの最適化の機会の概要を提供します。
AWS Compute Optimizer:EC2インスタンスに対する推奨事項。
AWS Pricing Calculatorを実行に移す
AWS Pricing Calculatorは40以上のAWSサービスに対するアカウント支出を見積もることができるツールです。しかし、時には他の競争戦略を決定するのに非常に役立つことがあります。例えば、オンデマンドEC2インスタンスからRIやSavings Planのオファリングに切り替える場合、各機能が提供する割引を確認することができる。表に値が追加されるたびに、結果的に計算が表示され、実際のサービスを選択するのに役立ちます。
未使用のインスタンスやデータベースを自動でオフにする
アイドル状態のリソースは、AWSの請求書の大きなコスト要因になり得ます。未使用のインスタンスやデータベースをアイドル状態にしておくことは、使用されていないものに対して料金を発生させることを意味します。例えば、平日の日中しかアクセスしない開発環境がある場合、24時間365日稼働させないことが最良の選択です。夜間に停止し、翌朝と週明けに起動する(ヒント:Auto Instance Schedulerを参照)ことで、コストをほぼ半分に抑えることができます。また、Amazon CloudWatchのアラームを有効にして、指定期間以上アイドル状態だったインスタンスを自動的に停止または終了させるのも良い戦略です。
Amazon CloudWatch diagram
マルチパートの不完全なアップロードをクリーンアップ
S3のマルチパートアップロード機能は、デフォルトで有効になっており、大きなオブジェクトを論理的な部分に分割して並行してアップロードすることで、アップロードを高速化します。問題は、これらのアップロードが何らかの理由で終わらない場合です。アップロードが完了しないデータはバケットに表示されず、自動的に削除されることもないので、毎月の請求額が大きくなる場合を除いては、特に気にする必要はないでしょう。これを防ぐには、「バケット管理」の設定で、新しいライフサイクルルールを作成し、「不完全なマルチパートのアップロードをクリーンアップする」オプションを有効にしてください。
ライフサイクルポリシーに慣れる
ライフサイクルポリシーといえば、AWS S3を使って運用する際には必ず必要なものです。とはいえ、ライフサイクルポリシーを実装するには、インフラ上で有効にする前に、ある程度の学習とドキュメントを読むことが必要です。
ポリシーは、使用パターンが明確に定義されたオブジェクトに対するルールの組み合わせなので、以下のことが可能です。
●ライフサイクル・ルールを使用して、オブジェクトをそのライフタイムを通じて管理する。
●階層型ストレージへの移行を自動化し、コスト削減を図る
●保管の必要性やサービスレベルアグリーメント(SLA)に基づき、オブジェクトを失効させる。
これは、適切に設定すれば非常に強力なツールです。S3ストレージクラスの違いを学び、より組織のニーズに合うようにライフサイクル・ルールに慣れることです。
ライフサイクルルールの作成
オブジェクトストレージに感謝
AWSは、パフォーマンス、可用性、耐久性の要件を満たすように設計された複数のストレージ階層を、異なる価格で提供しています。提供されるストレージサービスは、大きく3つに分類されます。オブジェクトストレージ、ブロックストレージ、ファイルストレージです。Amazonが提供するオブジェクトストレージ、Simple Storage Service(S3)は、3つのストレージカテゴリの中で最もコスト効率が高いです。Amazon S3内では、さらに先のストレージクラス間でデータを簡単に移動させ、アクセス頻度と価格のバランスを取りながら、ストレージコストを最適化することができます。すべてのストレージタイプで利用シーンが異なり、その価格設定も様々です。
AWS S3ストレージクラス部分比較
ここでの賢い方法は、タスクの種類、オブジェクトの性質、アクセス頻度に応じて、それらを組み合わせることです。目的のS3バケットをクリックし、「管理」→「分析」を選択し、「ストレージクラス分析」を追加すると、アクセスパターンを確認するのに便利です。One Zone-IAやS3 Glacierへの移行を推奨するものではありませんが、データをより深く可視化することができます。
S3 バケット・ストレージ・クラス分析
新規者についてもしっかり検討しましょう。S3 Intelligent Tiering。少額の追加料金で、アマゾンは自動的にアクセスデータのパターンを検出し、オブジェクトの人気度に応じて、標準的なアクセスと不定期なアクセスの2つの層の間でそれらを移動させます。人気のないオブジェクト(連続30日間アクセスされていないもの)は、アクセス頻度の低い階層に移動され、要求があれば後で戻されます。この仕組みでは検索料がかからないため、オブジェクトは永遠に行き来することができます。実際のシナリオでは、20%の節約になります。このような監視のための費用を支払うことで、理論上は部分的に低くなりますが、それでも見逃すにはあまりに魅力的だからです。S3 APIまたはCLIを使用してストレージクラス “INTELLIGENT_TIERING “を指定するか、ライフサイクルルールを設定することでこの技術を有効にすることができます。
しかし、これはすべてに有効なわけではないです。128KB未満のオブジェクトは、インフリークエントアクセス層に移行されることがないため、フリークエントアクセス層の通常料金で課金されることになります。また、30日未満のオブジェクトは、最低30日間課金されるため、この方法は使えません。
サービスの利用を予測し、前もってコミットすることを目指す
パブリッククラウドの柔軟性とCAPEXからOPEXへの移行について紹介しますが、請求書を減らすAWSの機能であるリザーブドインスタンス(RI)と節約プランのいくつかは、皮肉にもCAPEXに戻るように見えます。しかし、実際に50%以上の割引が得られるのですから、誰もが「導入のベストプラクティス」リストに挙げるべきものでしょう。
RIは、EC2インスタンスの時間単位の割引料金とオプションの容量予約を提供するもので、まずRIを検討することから始めます。1年または3年のコミットメントと引き換えに、インスタンスコストの割引を受けることができます。オンデマンドインスタンスは、無制限の柔軟性でワークロードをプロビジョニングしたい人には良い選択肢です。しかし、負荷が予測可能なワークロード(Webサービスなど)を常時稼働させる場合は、RIの方がはるかに優れています。
適切なEC2インスタンスタイプを選択する
EC2サービスは、おそらくAWSでのクラウドの旅で最初に選ぶものの1つだろう。60以上のインスタンスタイプがあり、最適なものを選ぶのは至難の業です。まずは、インスタンスの目的を考えてみてください。それを元に、以下のリストを見て最適なタイプを絞り込むことができます。
使用ケース |汎用機、計算、ストレージ、ネットワークでバランスが取れている必要がある
例 | Apache、NGINX、Kubernetes、Docker、VDI、開発環境など。
好ましいインスタンスタイプ|T3
使用ケース |高性能CPUの恩恵を受けるコンピュートバインドアプリケーション
例 | 高性能ウェブサーバー、拡張性の高いマルチプレイヤーゲーム、動画エンコーディングなど
好ましいインスタンスタイプ|C4、C5
使用ケース |大容量のデータセットをメモリ上で処理するアプリケーション
例 | 高性能データベース(SAP HANAなど)、ビッグデータ処理エンジン(Apache SparkやPrestoなど)、ハイパフォーマンス・コンピューティング(HPC)など
好ましいインスタンスタイプ|X1およびR5
使用ケース |浮動小数点数の計算、集中的なグラフィックス処理、またはデータのパターンマッチング
例 | 機械学習/深層学習アプリケーション、計算金融、音声認識、自律走行車、または創薬
好ましいインスタンスタイプ|G4、F1、P3
使用ケース |大量のシーケンシャルリード/ライト操作、または大規模なデータセットの処理
例 | NoSQLデータベース(例:Cassandra、MongoDB、Redis)、スケールアウト・トランザクション・データベース、データウェアハウス
好ましいインスタンスタイプ|D2とi3
ライトサイジングとは、性能要件を満たした上で、最も安価なオプションを選択することであることを忘れないでください。経験則では、長期間にわたってインスタンスのリソース使用率が80%になるようにすることです。
S3バックアップ:考慮すべき5つの鍵
- リージョン間レプリケーションを活用: クロスリージョンレプリケーション(CRR)を実装して、AWSのリージョン間でオブジェクトを自動的にコピーします。 これにより、地理的に離れた場所にデータを保存することで災害復旧能力が強化されるだけでなく、データ保存要件への準拠も支援します。
- N2WSで簡単に自動化: N2WSは、複雑なコーディングや手動での介入を必要とせずに、S3バックアップを自動化するシンプルで使いやすい方法を提供します。 これにより、効率が向上し、S3データの保護が確実に維持されます。
- インテリジェント・ティアリングでコストを最適化:S3インテリジェント・ティアリング・ストレージクラスを利用して、アクセスパターンの変化に応じて、2つのアクセス層(頻繁なアクセスと頻繁ではないアクセス)間でデータを自動的に移動させます。これにより、パフォーマンスへの影響やオーバーヘッドなしにストレージコストを最適化できます。
- セキュリティを強化するMFA Delete:バージョン管理機能付きのS3バケットで多要素認証(MFA)による削除を有効にすることで、セキュリティをさらに強化できます。オブジェクトのバージョンを恒久的に削除する操作にはMFAが必要となり、削除を防止します。
- AWS S3 Storage Lensでストレージを分析:S3ストレージの使用状況とアクティビティの傾向を可視化できます。このツールは、コストの最適化、データ保護のベストプラクティスの強化、パフォーマンスの向上に役立つ洞察と推奨事項を提供します。
真のクラウドコストについて
- ストレージ階層化を動的に活用:静的なライフサイクルポリシーにとどまらず、使用パターンを自動的に分析し、動的に階層間でデータを移動するツールを使用して、パフォーマンスとコストの両方をリアルタイムで最適化することを検討してください。
- スポットフリートで高可用性を実現:スポットインスタンスはコスト削減に役立ちますが、最も安価な利用可能なスポットインスタンスを自動的に選択し、再バランスする「スポットフリート」を作成することで、コスト効率と稼働時間を確保することができます。
- カスタム価格モデルの交渉:大手クラウドプロバイダーは、大量に利用する企業向けにカスタム価格帯を提供しています。既定の料金に妥協することなく、利用量や特定のサービス要件に基づく割引を交渉しましょう。
- クラウドネイティブなコスト最適化ツールの活用:ネイティブなコスト管理ソリューションに加えて、CloudHealthやCloudabilityのようなクラウドネイティブなサードパーティプラットフォームは、より深い洞察、クロスクラウド分析、自動化されたガバナンスを提供し、競争優位性をもたらします。
- サービス固有のコスト最適化フレームワークを利用する:各クラウドプロバイダーには、それぞれに秘められた効率化があります。例えば、AWS Compute OptimizerやAzure Cost Managementの推奨事項は、特定のサービスのコスト削減に重点を置いています。手動監査と併用して、これらのサービスを活用し、支出を最適化しましょう。
- 続きはこちらまで
スナップショットのアーカイブにAmazon S3を使用のヒント
●アーカイブ前にデータの分類を優先:すべてのスナップショットが同じように重要であるわけではありません。 コンプライアンスやDRなどの重要なスナップショットと、より長い検索時間を許容できるスナップショットを区別するために、堅牢なデータ分類ポリシーを導入します。
●アーカイブからの取得に関するSLAをDR計画に統合:GlacierまたはDeep Archiveにスナップショットをアーカイブした場合、取得に数分から数時間かかる場合があります。 災害復旧(DR)計画では、こうした取得SLAを考慮して、予期せぬ遅延を回避する必要があります。
●S3 Object Lockを使用して保持の徹底を自動化:S3 Object Lockを使用して重要なスナップショットの不変性を徹底し、早期の削除を防止して、規制へのコンプライアンスを確保します。 また、誤ってまたは悪意を持って削除されることも防ぎます。
●重要アーカイブスナップショットには、クロスリージョンレプリケーションを活用:スナップショットをアーカイブする前に、クロスリージョンレプリケーション(CRR)を有効にします。これにより、リージョンがダウンした場合でも、アーカイブされたデータは別のリージョンで利用可能になります。
●AWS Cost Explorer を使用して定期的にコスト監査を実施する:S3 GlacierとDeep Archiveはコスト削減をもたらしますが、これらは長期間にわたって気づかぬうちに蓄積される可能性があります。AWS Cost Explorerを使用して定期的にアーカイブコストを監査し、スナップショットのライフサイクルポリシーが最適化されていることを確認してください。
AWSの価格設定モデルの概要
AWSは、さまざまなビジネスニーズに対応するために、複数の価格モデルを提供しています。
オンデマンドインスタンス
オンデマンドインスタンスは、インスタンスの種類に応じて、コンピューティング能力を時間単位または秒単位で支払う従量制の価格モデルです。初期費用は発生せず、ユーザーは長期的な契約を結ぶことなく、いつでもインスタンスを開始または停止することができます。このモデルは、需要が予測できない作業負荷や短期プロジェクトに最適です。
利点:
- 柔軟性:必要に応じてインスタンスの起動と停止が可能。
- 初期費用なし:使用した分だけのお支払い。
- 使いやすさ:長期契約を必要としないシンプルな請求。
短所:
- コスト高:長期契約の他の料金モデルと比較すると割高。
- コスト管理:継続的に実行されるインスタンスでは、コストが予測しにくくなる可能性がある。
リザーブドインスタンスと割引プラン
リザーブドインスタンス(RI)とセービングプランは、1年または3年間の利用を確約する代わりに、オンデマンド価格よりも割引価格で利用できるものです。RIは前払いと利用確約に基づいて割引を提供し、セービングプランはインスタンスタイプを問わず、より柔軟に同様の割引を提供します。
利点:
- コスト削減:オンデマンドと比較して最大72%のコスト削減。
- 予測可能な請求:安定したワークロードに最適。
- 柔軟なセービングプラン:従来のRIよりも適応しやすい。
短所:
- 前払い契約:事前計画と長期的な契約が必要。
- 柔軟性の制限(RI):特定のインスタンスタイプとリージョンに制限される。
スポットインスタンス
スポットインスタンスでは、ユーザーは使用されていないAWSの容量を大幅に低い価格で入札することができ、オンデマンド料金よりも最大90%も安くなる場合もあります。ただし、これらのインスタンスは、容量が他の場所で必要になった場合、AWSによって中断される可能性があります。
長所:
- 大幅なコスト削減:非クリティカルなワークロードやバッチ処理に最適です。
- 高い可用性:地域全体にわたって予備の容量に幅広くアクセスできます。
短所:
- 中断のリスク:インスタンスはわずかな通知で終了される可能性があります。
- 限定的なユースケース:クリティカルなアプリケーションや時間的制約のあるアプリケーションには不向きです。
専用ホストおよび専用インスタンス
専用ホストおよび専用インスタンスは、単一のお客様専用の物理サーバーを提供します。これらのオプションは、コンプライアンス、ライセンス、規制要件が厳しい組織向けに設計されています。
利点:
- コンプライアンス:厳しいセキュリティおよびコンプライアンス要件に対応します。
- 専用リソース:他の顧客とのリソース共有はありません。
- ライセンスの持ち込み:特定のライセンスモデルに対応。
短所:
- 高コスト:専用ハードウェアを使用するため、他のモデルよりも高価。
- 限定的な拡張性:仮想化ソリューションと比較して柔軟性が低い。
AWSコストについてのエクスパートからのアドバイス
- インスタンスファミリーの更新機会を活用する:インスタンスファミリーの更新情報を定期的に確認しましょう。新しい世代のインスタンスファミリーは、同等のパフォーマンスまたはより低いコストで、より優れたパフォーマンスを提供していることがよくあります。ワークロードを最新のインスタンスファミリーに移行することで、大幅なコスト削減を実現できます。
- 複数のアカウントを統合する:組織で複数のAWSアカウントを使用している場合は、AWS Organizationsでそれらを統合することで、ボリュームディスカウントを共有し、請求を簡素化することができます。このアプローチは、コスト最適化のための集中管理も実現します。
- 地域ごとの価格差を活用:AWSの価格は地域によって異なります。レイテンシに敏感でないワークロードの場合は、コストの低い地域にリソースを展開します。例えば、US East (N. Virginia) や US West (Oregon) のような地域は、価格競争力があることが多いです。
- 未使用のボリュームに対するライフサイクルポリシーを実装:未使用のEBSボリュームは、多額の費用が発生する可能性があります。ライフサイクルポリシーを使用して、非アクティブなボリュームのスナップショットを自動的に作成し、削除することで、未使用のストレージが不要な費用を発生させないようにします。
- データの転送を監視し、キャッシングを使用:アプリケーションが頻繁に異なるリージョンやパブリックインターネット上のデータにアクセスすると、データ転送費用が高額になる可能性があります。Amazon CloudFrontやAWS Global Acceleratorなどのキャッシングレイヤーを実装して、転送トラフィック費用を削減します。
AWS コストの管理と削減のための7つのベストプラクティス
以下のベストプラクティスを導入することで、企業はAWSにおける最適な支出を確保することができます。
1. リソースの最適化と適正化
リソースの最適化と適正化には、AWSリソースの利用状況を分析し、不要な過剰プロビジョニングを排除しながら、ワークロード要件に確実に一致させることが含まれます。 このプロセスは、過剰なインスタンスやアイドル状態のインスタンスに対する無駄な支出を排除するのに役立ちます。 ライフサイクルポリシーを使用してストレージ階層間のデータ移行を自動化することで、継続的なコスト効率性を確保することができます。
Compute OptimizerやTrusted AdvisorなどのAWSサービスは、CPUやメモリの使用率などの指標を分析して実行可能な推奨事項を提供し、企業が最もコスト効率の高いインスタンスタイプやサイズを決定するのに役立ちます。ストレージの最適化については、企業はアクセス頻度の低いデータをAmazon S3 Infrequent AccessやGlacierなどのコスト効率の高いストレージソリューションに移行することができます。
2. コスト効率を高めるためのスケジュールと自動化
AWS Instance Schedulerのようなサービスを利用すると、管理者は夜間や週末、休日など、業務時間外にインスタンスを停止するルールを作成することができます。このアプローチは、24時間365日稼働させる必要のない開発、テスト、ステージング環境に特に有効です。
AWS Lambdaのような自動化ツールをCloudWatch Eventsと組み合わせることで、アイドル状態のインスタンスの終了や未使用のEBSボリュームの削除など、リソースのクリーンアップアクションをトリガーすることができます。需要が変動するワークロードの場合、オートスケーリング機能により、コストを削減しながらパフォーマンスを維持するために実行中のインスタンスの数を動的に調整することができます。
3. コスト割り当てタグの導入
コスト割り当てタグは、AWSの費用をビジネスユニット、チーム、プロジェクトに割り当て、追跡するために不可欠です。タグはリソースに付加されるメタデータラベルとして機能し、支出のきめ細かい分析を可能にします。例えば、「Environment: Production」や「Department: Finance」などのタグを使用することで、組織はコストのかかっている分野を特定し、是正措置を取ることができます。
AWSは、タグに基づいて支出をフィルタリングし分析するためのツールとして、Cost ExplorerやBudgetsなどを提供しています。組織全体で標準化されたタグ付けポリシーを徹底することで、クラウド利用の説明責任をより適切に果たすことができます。また、タグ付けはチャージバックやショーバックのプロセスを簡素化します。
4. 定期的なコストのモニタリングとガバナンス
AWSの費用を管理するには、定期的なコストの監視とガバナンスが不可欠です。AWS Cost Explorer、コストおよび使用状況レポート、AWS Budgetsは、費用の傾向を追跡し、異常を特定し、予算のしきい値を設定するためのツールを提供します。これらのツールは、費用がサービス、アカウント、および地域にどのように分散しているかを可視化します。
AWS Organizations を通じてサービスコントロールポリシー(SCP)を実装するなどのガバナンスの実践により、リソースが組織のポリシーに準拠してプロビジョニングされることを保証します。例えば、SCP を使用して、コストの高いインスタンスタイプの使用を制限したり、リソースのデプロイを特定のリージョンに限定することができます。ガバナンスポリシーと組み合わせた定期的なコストの見直しは、組織が非効率性を特定し、コスト削減策を実施するのに役立ちます。
5. コスト管理のためのコードとしてのインフラストラクチャの利用
AWS CloudFormation、AWS CDK、TerraformなどのInfrastructure as code(IaC)ツールを使用することで、企業はコードを使用してクラウドリソースを定義および管理することができます。 IaCにより、リソースのプロビジョニングが常に一貫性のある自動化された反復可能なものとなり、コスト超過につながる可能性のある手動エラーの発生を低減できます。
IaCテンプレートでは、リソースの制限を指定したり、インスタンスの種類を制限したり、スポットインスタンスのようなコスト効率の高い構成を自動的に有効にしたりすることで、コスト管理のベストプラクティスを組み込むことができます。さらに、IaCにより、組織はインフラストラクチャのバージョン管理が可能になり、変更の追跡や構成の最適化が容易になります。
6. FinOpsの実践の採用
FinOps(財務業務)は、財務上の説明責任と業務効率を組み合わせた、クラウドコストの管理における協調的なアプローチです。 財務、業務、エンジニアリングの各チーム間の部門横断的な協力を促し、ビジネス目標に沿いつつ、クラウド支出の最適化を図ります。 FinOpsの実践には、定期的なコスト分析、予測、最適化の取り組みが含まれます。
FinOpsの重要な要素のひとつはコストの透明性であり、これによりすべての利害関係者が詳細な支出データにアクセスできるようになります。 この共有された可視性は説明責任を促し、データに基づく意思決定を推進してコスト削減を実現します。さらに、FinOps を採用する組織は、自動化と分析を活用してコスト管理戦略を改善し、継続的な改善を優先しています。
7. バックアップ管理とストレージの最適化
バックアップ管理とストレージの最適化は、データ保護と災害復旧機能を損なうことなく AWS コストを最小限に抑えるために不可欠です。 組織はバックアップ戦略を評価し、冗長なバックアップを排除し、過剰な保持を回避し、コスト効率の高いストレージソリューションを活用すべきです。
Amazon S3 GlacierやGlacier Deep ArchiveなどのAWSサービスは、アクセス頻度の低いバックアップの長期保存に最適です。ライフサイクルポリシーを適用することで、企業はあらかじめ設定した期間が経過したデータを自動的に標準ストレージ層からより低コストのアーカイブストレージに移行することができます。例えば、Amazon S3で日次バックアップを30日間保持した後、Glacierに移行することで大幅なコスト削減を実現できます。
さらに、重複排除と圧縮技術によりバックアップのサイズを縮小し、ストレージコストを削減することができます。N2Wのようなツールは、バックアップポリシーの一元管理を簡素化し、コスト効率の高い手法の自動化と徹底を容易にします。バックアップ構成の定期的な監査により、組織の保持ポリシーへの準拠が保証され、不要なデータの蓄積を防止することができます。
N2W最適化クラウドバックアップによるAWSのコスト削減
AWSのコスト管理は、価格設定を理解するだけではなく、より賢明な意思決定を迅速に行うことが重要です。そこでN2WSがサポートします。
当社のクラウドネイティブなバックアップおよび災害復旧プラットフォームは、AWS環境を推測に頼らずに管理できるようにします。 古いスナップショットの自動アーカイブ、アイドルリソースのシャットダウン、利用率の低いボリュームの監視など、すべてを直感的な単一のダッシュボードから実行できます。 AWS、Azure、Wasabiのいずれにバックアップする場合でも、N2Wはデータの安全性、不変性、コスト最適化を保証します。
N2WSがコスト削減に役立つ主な方法:
- スマートなスナップショットアーカイブにより、ストレージ費用を最大92%削減。
- 自動化されたポリシーとクロスクラウドDRにより、毎週何時間も節約。
- エアギャップストレージと不変のスナップショットにより、バックアップのセキュリティを確保。
- 内蔵のコストエクスプローラーとアラートにより、支出を可視化。
クラウドのコスト削減は、保護の妥協を意味するものであってはなりません。
Azureバックアップ (18)
データのバックアップを確認する
Azureのバックアップ戦略を策定する最初のステップは、実際にバックアップする必要があるのは何なのかを把握することです。つまり、データがAzureクラウド内のどこに存在し、そのデータを保護するために何が必要かを決定することです。Azureのデータは、仮想マシンやAzure SQLのようなマネージドサービスなど、さまざまな場所に存在する可能性があります。また、データが複数のリージョンに分散している可能性もあります。
業務に適したツールを使用する
Azure のデータを保護するためには、Azure を意識した最新のバックアップソリューションを使用することが重要です。主にオンプレミス用に設計されたレガシーバックアップツールは、Azureデータの一部を保護できるかもしれませんが、すべてのデータを保護することはできない可能性があります。例えば、サーバーレスデータベース内にデータがある場合、レガシーバックアップアプリケーションでは、おそらくそのデータをバックアップすることはできないでしょう。
レガシーバックアップツールでは、バックアップデータを保存するためのオプションが制限されている場合があります。例えば、特定のワークロードをクラウド上で実行することを意識的に決定した場合、そのワークロードのバックアップを構内に保存することは意味をなさないかもしれません。しかし、レガシーバックアップツールの中には、クラウドベースのバックアップターゲットを使用するオプションがないものもあります。
自動化で効率的に業務をこなす
バックアップの自動化には、さまざまな形態があります。例えば、特定の時刻にバックアップを実行するようにスケジュールを組むといった簡単なものです。しかし、最新のバックアップソフトウェアでは、バックアップのスケジューリング以外の自動化も可能です。これまでITプロフェッショナルは、バックアップを作成するだけでなく、バックアップに関連する様々なタスクに対処しなければなりませんでした。しかし、今日ではこれらのタスクの多くを自動化することができます。例えば、バックアップのライフサイクル管理やバックアップのテストを自動化することができます。
ストレージ階層を効果的に利用する
Azureのバックアップストレージのオプションを評価するとき、必然的にストレージ階層を選択する必要があります。利用可能な階層は、コスト、可用性、およびパフォーマンスに関してかなり異なっています。パフォーマンスの高いストレージ層は、一般的にコストが高くなります。
バックアップの保存期間によっては、ギガバイトあたりのコストが最も低い階層が、必ずしも全体のコストを低く抑えられるとは限らないことに留意する必要があります。これは、Cool Tier の最低データ保存期間が 30 日間であるのに対し、Archive Tier の最低保存期間が 180 日間であるためです。つまり、これらの階層にデータを保存する場合、実際にはそれほど長期間バックアップを保持する必要がない場合でも、少なくとも最低期間データを保存するために費用を支払うことになります。
バックアップデータの隔離
バックアップを保護するために組織ができる最も重要なことの1つは、バックアップをオンラインで維持しないことです。ランサムウェアの亜種は、特にバックアップサーバーをターゲットに設計されているため、被害者は身代金を支払う以外に選択肢がありません。以前は、テープは、空隙のあるバックアップを作成したい組織にとって、最適なメカニズムでした。バックアップが作成されると、テープはテープドライブから取り外されるだけでよかったのです。しかし、クラウドバックアップの場合、テープという選択肢はありません。Azureのアーカイブ層はオフラインに保たれ、レイテンシは2時間です。また、クラウドストレージへのアクセスは、多要素認証を使用したアカウントに限定することもできます。これにより、犯罪者が漏れたパスワードや総当たりパスワード攻撃でバックアップにアクセスすることを防ぐことができます。
データモビリティの重要性を考える
クラウドバックアップの設置場所は重要です。ハイブリッド/マルチクラウドのサポートに関するビジネス要件は増加傾向にあり、特定のクラウドベンダーの選択と離脱の両方に関して、柔軟性が重視されています。
そのため、共通のコントロールペインとポータブルなバックアップフォーマットが可能なバックアップソリューションが必要とされています。これにより、異なるプラットフォーム間でデータを移動することが容易になります(オンプレミスからクラウドへ。クラウドからオンプレミスへ、クラウドから別のクラウドへ)、プラットフォームのロックインを回避することができます。
単一のバックアップソリューションの使用
現在、多くの企業が複数のバックアップ製品を使用しています。オンプレミスのリソースを保護するために1つのバックアップツールを使用し、Azureにあるリソースを保護するために別のツールを使用している場合があります。可能であれば、バックアップ操作を1つのバックアップツールに統合するのがベストです。これにより、バックアップのサイロ化を解消し、クラウドと自社データセンター間でシームレスにデータを移動させることができます。同時に、単一のバックアップソリューションを使用することで、バックアップオペレーションを大幅に簡素化し、ライセンスコストを削減し、組織のデータ保護戦略におけるギャップの可能性を低減することができます。
復旧のための能力を持つことが重要
災害がどのような規模で発生し、どのようなシステムに影響が及ぶかを予測することは不可能です。そのため、バックアップソリューションでは、データを異なるシステムやクラウドにリストアできることを確認することが重要です。また、精度の高いリストアが可能であることも重要です。例えば、仮想マシンの場合、仮想マシン全体をリストアできる必要がありますが、仮想マシン内の1つのファイルも同様に簡単にリストアできる必要があります。
可能な限り複雑さを避ける
バックアップソリューションが複雑でなければないほど、必要なときに動作する可能性が高くなります。複雑すぎるバックアップソリューションは、ヒューマンエラー、誤った設定、パッチのリリースに伴う互換性の問題が発生しやすくなります。そのため、シンプルな管理インターフェイスを持つだけでなく、エージェントを必要とせず、実際のデータ保護プロセスを簡素化するソリューションを探すとよいでしょう。つまり、管理者が新しいワークロードごとに手動でエージェントを展開したり、自動化スクリプトを書いたりする必要がなく、あらゆる規模の環境に対して拡張できるソリューションを探すということです。
クラウドのコストに注意
クラウドサービスプロバイダーは当初から、コストのかかるオンプレミスでのIT運用に代わる安価な選択肢として、パブリッククラウドを販売してきました。しかし、実際には、Azureやその他のクラウド環境での運用は、オンプレミスでのワークロードの維持と同じくらいコストがかかることがよくあります。
Azureのデータをバックアップする場合、IT担当者がコストを抑制するために留意すべき点がいくつかあります。まず、効果的なデータライフサイクル管理ポリシーを持つことが必要です。このようなポリシーは、バックアップされるデータの量やバックアップ自体のサイズを制限するのに役立ちます。第二に、構内や他のクラウド環境に存在するバックアップターゲットの使用には注意が必要です。マイクロソフトは、Azureクラウドからデータを取り出す際にデータ取り出し手数料を契約者に請求しており、この手数料は大きなデータセットではかなり高額になる可能性があります。
クラウドでのコスト管理の複雑さを考えると、バックアップベンダーはクラウドでのデータ移動のニュアンスを意識したバックアップコスト計算とデータ管理ツールを内蔵していることが重要です。
スナップショット&イメージレベルバックアップ
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
Azure SQL Databaseバックアップのヒント
- バックアップ検証の自動化: 非本番環境へのリストアプロセスを自動化することで、バックアップを定期的にテストします。これにより、バックアップが有効であり、問題なくリストアできることを保証します。
- イミュータブル・ストレージの活用: 重要なバックアップをイミュータブル・ストレージに保存することで、ランサムウェアから保護し、指定された保存期間内にバックアップを変更または削除できないようにします。
- クロスサブスクリプション・バックアップの導入: セキュリティを強化するために、サブスクリプションレベルの問題や侵害から保護するために、バックアップのコピーを別のAzureサブスクリプションに保存することを検討します。
- バックアップ操作にプライベートエンドポイントを使用する: プライベートエンドポイントを構成して、バックアップとリストア操作がパブリックインターネットではなく、安全なプライベート接続を介して行われるようにし、セキュリティを強化します。
- バックアップデータの暗号化: 使用中のデータには透過的データ暗号化(TDE)を、保存されているバックアップデータには暗号化(at rest)を使用して、すべてのバックアップが暗号化されていることを確認し、セキュリティとコンプライアンスを強化します。
Azure Cross-Region Replication(CRR)の利点、制限、課題
- Azure Site RecoveryとCRRの併用:CRRとAzure Site Recovery(ASR)を組み合わせることで、仮想マシン(VM)のレプリケーション、フェイルオーバー、リカバリを自動化できます。ASRは、ディザスタリカバリプロセス全体をオーケストレーションすることができ、より包括的なソリューションを提供します。
- アラートでレプリケーションの健全性を監視 Azure Monitorでカスタムアラートを設定して、CRRプロセスの健全性とステータスを追跡します。このプロアクティブな監視により、あらゆる問題が迅速に検出、対処され、データの一貫性と可用性が維持されます。
- マルチクラウド戦略の導入による耐障害性の強化: Azure内だけでなく、異なるクラウドプロバイダー間で重要なデータを複製することで、ディザスタリカバリ戦略を強化します。N2WSのようなツールは、クロスクラウドレプリケーションを可能にし、クラウドプロバイダー固有の障害に対するフェイルセーフを提供します。
- レプリケートされたデータをエンドツーエンドで暗号化する: レプリケーションプロセス中、静止時と転送時の両方でデータが暗号化されていることを確認します。暗号化キーの管理とアクセスにはAzure Key Vaultを使用し、ディザスタリカバリ計画にさらなるセキュリティ層を追加します。
- レプリケーションとフェイルオーバーを定期的にテストする: Azure AutomationとASRを使用して、ディザスタリカバリ訓練を自動化します。定期的なテストにより、レプリケーションとフェイルオーバープロセスの信頼性と効率性を確保し、運用に影響が出る前に潜在的な問題を浮き彫りにすることができます。
Azureでのプロセスを最大限に自動化して保護と復旧を高速化するヒント
●コスト管理にスナップショットのライフサイクルポリシーを活用:より古いスナップショットを低コストのストレージ層に移行することで、リカバリ性を損なうことなくコストを削減できます。
●代替案としてアプリケーション認識型レプリケーションを検討する:バックアップが大きなオーバーヘッドをもたらすようなシナリオでは、重要なワークロードをリアルタイムで同期し、一貫性を保証するアプリケーション認識型レプリケーションソリューションを評価します。
●バックアップ用にリードレプリカを実装する:データベースの場合、リードレプリカを作成し、そのレプリカに対してアプリケーション一貫性のあるバックアップを実行することを検討します。これにより、バックアップ中のプライマリデータベースのパフォーマンスへの影響を回避できます。
●テスト環境でバックアップをテストする:サンドボックス環境を使用して、本番環境のワークロードに影響を与えることなく、アプリケーション整合性のあるバックアップをテストします。自動化ツールを使用すると、障害をシミュレートし、リカバリ時間を検証することができます。
●変更不可ストレージでリカバリを強化する:Azureで変更不可のバックアップを設定することで、誤って削除したりランサムウェアの被害に遭うことを防ぎます。アプリケーション整合性と組み合わせることで、悪意のあるデータ損失や誤操作によるデータ損失の両方のシナリオにおいて、リカバリの整合性を確保することができます。
Azureアプリケーションにおけるバックアップの一貫性について
- スナップショットのライフサイクルポリシーを活用してコスト管理:復旧性を損なうことなくコストを削減するために、古いスナップショットを低コストのストレージ階層に移行します。
- 代替案としてアプリケーション認識型レプリケーションを検討:バックアップが大きなオーバーヘッドをもたらすようなシナリオでは、重要なワークロードをリアルタイムで同期し、一貫性を保証するアプリケーション認識型レプリケーションソリューションを評価します。
- バックアップ用にリードレプリカを実装:データベースの場合、リードレプリカを作成し、そのレプリカに対してアプリケーション一貫性のあるバックアップを実行することを検討します。これにより、バックアップ中のプライマリデータベースのパフォーマンスへの影響を回避できます。
- テスト環境でバックアップをテスト:サンドボックス環境を使用して、本番環境のワークロードに影響を与えることなく、アプリケーション整合性のあるバックアップをテストします。自動化ツールを使用して障害をシミュレートし、リカバリ時間を検証できます。
- 不変ストレージでリカバリを強化:Azureで不変バックアップを設定することで、誤って削除されたりランサムウェアの被害に遭うことを防ぎます。アプリケーション整合性と組み合わせることで、悪意のあるデータ損失や誤って削除された場合の両方のシナリオで、リカバリの整合性を確保できます。
企業ニーズのためのAzure SQLバックアップとリカバリ
- Managed Identity を使用してバックアップを自動化: スクリプトに認証情報を埋め込む代わりに、Azure の Managed Identity を使用してストレージアカウントへの安全なアクセス権限を付与し、エクスポート/インポート操作を自動化します。
- バックアップと復元のパフォーマンスを監視:Azure Monitor を使用してバックアップ/復元操作のパフォーマンスを追跡し、障害や異常に長い操作時間に対するアラートを設定します。
- 地理的冗長ストレージを賢く使用:RA-GRS は耐久性に優れていますが、パフォーマンスとコストを最適化するには、ゾーン冗長ストレージ(ZRS)やローカル冗長ストレージ(LRS)を使用する方が適しているセキュリティの高いシナリオもあります。
- 機密データベースのバックアップ暗号化を有効にする:透過的データ暗号化(TDE)でデータベースのバックアップを暗号化します。さらにセキュリティを強化するには、Azure Key Vaultに格納された顧客管理キー(CMK)を使用します。
- 重要なバックアップに不変ストレージを組み込む:誤って削除されたりランサムウェアから保護するための長期的なバックアップ。これにより、バックアップが保持期間中に改ざんされないことが保証されます。
Azure Backupの基本について
バックアップとDRのワークフローを効率的かつ費用対効果の高いものにするために、その機能、長所、短所、考慮すべき点は:
●ライフサイクルポリシーを使用して経費を節約: 古いバックアップをAmazon S3 Glacierのような安価なストレージ・オプションに移動するライフサイクル・ポリシーを設定する。これにより、ストレージ・コストを大幅に節約できます。
●異なる地域とアカウントにバックアップする: バックアップを異なるAWSリージョンやアカウントにコピーすることで、ディザスタリカバリプランをより強固なものにする。これにより、リージョン固有の問題やセキュリティの問題からデータを保護できます。
●RTOを減らすためにバックアップを自動化する: AWS Backupを使ってバックアップ間隔を頻繁に設定しましょう。1時間ごと、あるいは数分ごとにバックアップを自動化することで、データを迅速に復旧し、ダウンタイムを最小限に抑えることができます。
●リソースのタグ付けによる容易な管理: タグを使用すると、関連するバックアップをすばやく識別してグループ化できるため、バックアップの管理やコストの監視が容易になります。また、レポートやコンプライアンスチェックも簡素化できます。
●ディザスタリカバリプランを定期的にテストします: DR訓練を自動化し、バックアップとリカバリのプロセスをチェックします。バックアップが機能し、データを迅速にリストアできることを確認し、潜在的な問題を発見して修正しましょう。
Wasabi (5)
Wasabi Object Lock for Veeam Backup & Replication
オブジェクト・ロック(Object Lock)の利点
オブジェクト・ロックは、指定された期間に達するまで、データがストレージから削除または変更されるのを防ぎます。これは、誰も誤って、または悪意を持って、Veeamバックアップを変更または暗号化できないことを意味します。本質的に、これはランサムウェアに対する究極の保護を提供します。
データ保護の課題
オフサイトに保存されていても、バックアップは危険にさらされています。データを保護するためにデータをエアギャップする従来の方法は、組織のデータが電源から切り離されたLTOテープ・カートリッジやHDDにオフラインで保存されることを意味しました。この方法で保存されたデータを取り出すには数時間から数日かかり、ビットの腐敗や損傷が起こりやすく、最終的にはデータが破壊される可能性がありました。バックアップをイミュータブルにすることで、オブジェクト・ロックはこの脆弱性を排除し、データが保存された場所に正確に残るようにします。データが保存された場所に正確に残ることを保証します。
なぜオブジェクト・ロックが重要なのか?
なぜなら、物事は変化するからです。イミュータブルオブジェクトにより、情報は偶発的または意図的な削除や改ざんから保護されます。一度情報がWasabiホットストレージクラウドに保存されると、ロックの有効期限が切れるか、バケットが完全に削除されるまで(これはまた別の問題ですが)、保存され続けることが保証されます。
サイバー犯罪者はランサムウェアキャンペーンの一環としてバックアップやアーカイブを攻撃するからです。プライマリ・システムをダウンさせるだけでは不十分で、ランサムウェアへのアクセスを確保するためにセカンダリ/バックアップ・システムも攻撃します
なぜなら、規制当局はこれらを定期的にチェックしているからです。コンプライアンスと消費者保護基準のために、規制業界のデータを保護することは必須です。
監視ビデオのようなデジタル証拠に関しては、偽造または改ざんされた映像が今や司法に対する脅威となっているため、法的手続きは親権の連鎖と不変性に依存しています。オブジェクトロック機能は、HIPAA、FINRA、CJISのような特定の政府および業界の規制に対応する組織であり、電子記録、取引データ、および活動ログを安全に提供することができます。
Veeam Backup & Replicationとのオブジェクトロック機能
Wasabiのオブジェクトロック機能は、Veeam Backup & Replication v10以上のEnterpriseおよびEnterprise Plusエディションの両方をサポートします。
Wasabiはどのリージョンがサポートされていますか?
現在は、下記リージョンのみサポートされております。
us-east-1
us-east-2
eu-central-1
eu-central-2
eu-west-1
eu-west-2
us-west-1
ap-southeast-1
ap-northeast-1(東京リージョン)
ap-northeast-2(大阪リージョン)
日本リージョンに対応したクラウドにバックアップ出来ますか。
CloudBerryで使用可能なクラウドストレージは日本リージョン含めほとんどのリージョンに対応しています。
日本リージョン対応クラウド例:
Amazon S3
Asia Pacific(Tokyo)
Asia Pacific(Osaka-Local)
Azure
Japan East(Tokyo)
Japan West(Osaka)
Wasabi
Ap-northeast-1(東京リージョン)
Google Cloud
Asia-northeast1(東京)
Asia-northeast2(大阪)
WasabiとVeeamによる最も復元力のあるデータ保護ソリューション
業界をリードするバックアップとリストアと不変のホットクラウドストレージを組み合わせて、最高のハイブリッドクラウドデータ保護を実現
データ量とデータ速度は指数関数的なペースで増加し続けており、業界によっては年複利で20%、40%、80%の成長を経験しています。従来のオンプレミスバックアップアプローチは、コストのかかるスケールアップアーキテクチャとクラウド接続性を備えていないため、コンプライアンス規制を満たしたり、ランサムウェア攻撃と戦うために必要なデータ量と増え続ける保持時間に追いつくことができません。
VeeamとWasabiを組み合わせることで、オンプレミスおよびクラウドネイティブなワークロードのための完全なデータ保護ソリューションを提供します。Veeam Backup & Replication (v9.5.4、v10、v11、v12)、Veeam Backup for Microsoft Office 365、Wasabiのホットクラウドストレージ、Object Lockによるバックアップの不変性が含まれます。Veeamの単一的なインターフェースは、バックアップの運用管理をシンプルにし、Wasabiの無制限クラウドストレージは、卓越したセキュリティとデータの不変性を提供します。
データ保護戦略で最も重要なのは、正確なデータを迅速にリストアし、通常業務を再開する能力です。そのためには、信頼できるバックアップデータと、復旧時間目標(RTO)を満たすストレージ性能が必要です。WasabiのS3 Object Lock APIの実装により、データが改ざんされていないことを確認できます。S3 Object Lockは、組織内外の誰によってもデータが削除されたり変更されたりしないことを保証します。ロックされたデータセットは不変であり、ユーザが定義した期間保持されます。
データ損失の可能性を想定して演習するには、頻繁にリストアの演習をする必要があります。クラウドストレージを使用する場合、データをダウンロードする必要があり、場合によってはギガバイトやマルチテラバイトの規模になることもあります。Wasabiのホットクラウドストレージでは、追加料金はかかりません。部分的または完全なリストアでバックアップデータの完全性を検証する場合、その作業に必要な時間と人以外にコストはかかりません。このため、Wasabiは他のクラウドストレージプロバイダーとは一線を画し、このような作業をより簡単に、低コストで頻繁に実行することができます。
Microsoft Office 365用バックアップ
Veeam Backup for Microsoft 365は、Exchange、SharePoint、OneDrive、Teamsのバックアップとリカバリを可能にします。また、Veeam Backup for Microsoft Office 365は、プライマリ・バックアップ・ストレージ・システムとしてWasabiホット・クラウド・オブジェクト・ストレージをサポートし、大企業および中小企業が短期および長期の保持のため、クラウドの無限の容量を経済的に活用することを可能にします。
Veeam Backup and Replicationがデータ保護を合理化 :バックアップ・ジョブとクラウドへの移行をさらに簡単にします。
Veeam Backup and Recoveryは、古いオンプレミス・バックアップをコピー・ジョブでクラウドに移動するように自動的にスケジュールすることができます。このセット・アンド・フォーゲット機能は、オンプレミスシステムが常に利用可能なディスクスペースを維持し、最高のRTOのためにリストアパフォーマンスを最大化することを保証します。また、バックアップをローカルストレージとクラウドに同時に送信するように設定することもできます。これにより、オフサイト・バックアップが劇的に簡素化され、3-2-1-1-0ガイドラインに準拠することができます。
Veeam Backup and Replicationは、異なるクラウド・オブジェクト・ストレージ・レポジトリ間のデータ移行をサポートします。例えば、AWS S3を使用していたが、Wasabiホット・クラウド・ストレージに変更することを決定したとします。この機能を使えば、AWSからWasabiにデータを移行することができます。
非構造化データの保護を簡素化
WasabiはVeeam Ready Objectとして、またVeeam Ready Object – Object Lockとして認定されています。Wasabiは現在、Veeam Backup and Recoveryの名前付きクラウドストレージサービスです。
Wasabiホットクラウドストレージが画期的な経済性とデータセキュリティを実現
Wasabiホットクラウドストレージは、低コスト、高速、信頼性の高いクラウドストレージをオンデマンドで提供します。Wasabiは、全てのデータを「ホット」に保ち、数ミリ秒でアクセスできるようにします。すべてのVeeamとWasabiのユーザは、データをホットデータとして扱うことができるため、バックアップウィンドウを短縮し、データに素早くアクセスして、リストア時間を短縮することができます。
Wasabi クラウド・ストレージに関するベテラン・アドバイス
- ライフサイクルポリシーを活用してコストを管理:Wasabiでは最低90日間の保存期間が義務付けられているため、オブジェクトのライフサイクルポリシーを戦略的に活用することで、料金を最小限に抑えることができます。 アクセス頻度の低いデータを早まって削除するのではなく、アーカイブするか移行します。
- 出口の使用状況を注意深く監視して、予想外の請求を避ける:Wasabiでは、保存データ量までは出口の使用が無料ですが、この上限を超えると予想外のコストが発生する可能性があります。出口のパターンを追跡し、キャッシュまたはCDNソリューションを使用します。
- Wasabi Direct Connectを使用して、予測可能なパフォーマンスを実現:これにより、パフォーマンスが向上し、パブリックインターネットルーティングへの依存度が低下します。これは、大量のデータを定期的に転送する企業にとって特に有益です。
- 長期にわたる作業負荷と予約容量ストレージを組み合わせる: 予測可能なストレージのニーズがある場合、予約容量ストレージ(RCS)を利用することで大幅なコスト削減が可能になります。 アーカイブ、バックアップ、およびコンプライアンスが重視されるデータセットに最適です。
- ランサムウェア対策として変更不可バケットとWasabiを併用する: これにより、誤操作や悪意のあるデータ削除を防止できます。 医療や金融など、コンプライアンスが重視される業界に特に有効です。
Veeam Backup for Azure (1)
Veeam Backup for Azure V3を詳しく見てみましょう。
Veeam Backup for Azure の最新版v3で何が追加されたのか、少し掘り下げてみましょう。
既にVeeam Backup for Azureを使用している場合は、内蔵のアップデーターを使用して以前のインストールをアップグレードすることができます。
何が含まれているか?
毎回のリリースと同様に、いくつかの主要な機能強化があり、細かい改善と同様に多くのアンダーザフードのものがあります。
最初の大きな特徴は、Azure SQLのサポートです。Veeam Backup for Microsoft Azureは、SQL ServerまたはAzure SQL Managed Instanceとして実行されているSQLデータベースをバックアップおよびリストアすることができるようになりました。
AWSのVeeam BackupがS3 Glacierを使用した長期アーカイブのサポートを追加したように、Veeamは、Azureにもこの機能を追加しました。バックアップを長期間保存するために、ホットまたはクール・ストレージを使用しなければならないのは嫌ではありませんか?もう心配する必要はありません! 今日からAzure Archiveへのバックアップの階層化を始めましょう! 今こそコスト削減のチャンスです(クラウドでは何にでもお金がかかります)。
複数のAzureアカウントに対応
今回のリリースで大きな特徴のひとつは、実は複数のAzureアカウントをサポートしたことです。これはVeeamのAWSとGCPのソリューションで既に可能でしたが、Azureは1つのAzureアカウントに限定されていました。これを強化し、複数のアカウントを許可することで、1枚のガラスからすべてのアカウントを管理および保護することが容易になります。
セキュリティ強化の追加
セキュリティは重要なテーマであり、ここでも需要の高まりが感じられます。そこで、2つの新機能を追加しました。
●ロールベースのアクセスコントロール:ロールベースのアクセスコントロール:ビルトインのロールを使用して特定のユーザーにアクセスを委任することにより、組織内でより高いセキュリティを確保するために範囲を制限することができます。現在、3つの異なるロールがサポートされており、アプライアンス内でそれぞれのロールが独自の範囲を持ちます。
●シングルサインオンをサポート:外部のIDプロバイダーを登録し、ローカル・ユーザーを作成する必要はありません。既存のユーザー・アカウントを再利用して、Veeam Backup for Azureで日常的なタスクを実行するだけです。
●Azure Key Vaultのサポート。バックアップ・データを暗号化するためにAzure Key Vaultを使用することができるようになりました。もうパスワードをメモして保管庫に入れる必要はありません
その他の追加機能
Azure、AWS、GCPを問わず、リリースするたびに、ユーザーインターフェイスとエクスペリエンスの改善に努めています。
更新されたウィザード(例えば、リポジトリとポリシーウィザード)では、全画面を使って構成設定を明確に表示するようになり、ウィザードを簡単に進めることができるようになりました。初めてログインすると、製品の最新情報を紹介する「What’s New」が表示されます。
Veeamは、ログイン画面を更新し、Veeam Backup for Azureで作成したアカウントでログインするか、シングルサインオンの恩恵を受けるかを簡単に選択することができます。
AWSスナップショット (6)
初めに:AWSスナップショットとは何ですか?
AWSスナップショットとは、EC2インスタンスやEBSボリュームなどのリソースのイメージコピーで、AWSアカウント内のオブジェクトストレージに保存される。フルまたはベースラインスナップショットは、保護されたリソースの単一時点からの同一コピーである。最初のスナップショットが作成されると、それ以降の増分スナップショットには、最後のスナップショットが取得された後に変更されたすべてのブロックが含まれるようになります。
AWSスナップショットは完全なコピーであるため、破損または削除されたリソースを復元するために使用することができ、一般的にプライマリコピーが破損した場合、ITが最初に検索するものです。例えば、EC2インスタンスやEBSボリュームが破損しても、スナップショットには影響しないので、チームは簡単に復旧することができます。
これは、AWSスナップショットがバックアップのための理想的なデータソースであることを意味します 。 それは、異なるシステムに格納されているデータの独立したコピーを提供します。そらは、AWSで損傷したリソースを回復するための最も簡単で迅速な方法であり、シンプルでスピーディな災害復旧のための素晴らしいリソースを示しています。
<<続き>>
https://www.climb.co.jp/faq/faq-category/aws-snapshot
AWSスナップショットと3-2-1バックアップルール
効果的なバックアップとリカバリのシステムは、バックアップの古典的な3-2-1ルールに従っています – データのコピーを少なくとも3つ、少なくとも2つの異なるタイプのメディアに保存し、そのうち1つはオフサイトに保存します。
2つの異なるストレージシステムにデータを保存することは、プライマリシステムがダウンした場合にコピーが破損しないようにするためのリスク管理戦術です。このため、常に別のバックアップシステムを持ち、プライマリとバックアップの両方に同じストレージを使用しないようにします。スナップショットを作成した時点で、データのコピーを別のシステムに保存していることになるので、このルールの一部はAWSスナップショットを使用して簡単に遵守することができます。
少なくとも1つのバックアップコピーをオフサイトに保存することが、厄介な部分です。AWSスナップショットを別のリージョンにコピーすることは可能ですが、自動化するのは難しく、コストもかかります。あるリージョンから別のリージョンにデータをコピーすると、イグレスチャージが発生し、コストのかかる不要なコピーが作成されます。また、この概念をすべてのAWSアカウントに一貫して適用し、一元的な管理とレポーティングを維持することは困難です。
AWSスナップショットの限界
単一のAWSアカウントと比較的少数のリソースを持つユーザーにとって、バックアップの自動化と一貫したポリシーの適用は簡単なプロセスです。しかし、複数の地域に多数のAWSアカウントを持つユーザーにとって、バックアップを監視しながらすべてのアカウントで一貫したデータ保護を実施することは、非常に困難でコストがかかる可能性があります。Kubernetesのようなアプリケーションでは、ITチームはより洗練されたデータ保護メカニズムを必要とし、スナップショットだけに頼っていては復旧目標を達成できないかもしれないので、問題はさらに複雑になります。
さらに、すべてのバックアップが異なる地域の異なるアカウントにコピーされることを保証する問題もあります。地域間で何千ものバックアップを移行するのは非常に高価であり、一般的なエグレス・チャージよりは低いものの、AWSは地域間のデータコピーに課金することになります。最後に、AWSのスナップショットはストレージ効率が良いが、長期間保存するとかなりコストがかかる可能性があります。
スナップショット&イメージレベルバックアップ
サーバ仮想化の基本要素である、1台のホスト上に存在するすべてのVMは、物理サーバのリソースを共有し、1つのハイパーバイザによって管理されていることを忘れてはいけません。もし、これら全てのVMが同時にバックアップジョブを開始したらどうなるのでしょうか?ハイパーバイザーやホストサーバのリソースに負担がかかり、遅延が発生したり、最悪の場合バックアップが失敗したりする可能性があります。
ここでスナップショットの威力が発揮されます。スナップショットはVMのある時点のコピーを取得し、フルバックアップと比較してはるかに迅速な処理が可能です。スナップショット自体はバックアップではありませんが、イメージベースバックアップの重要な構成要素です。VMスナップショットがバックアップと同等でない主な理由は、VMから独立して保存できないからです。このため、スナップショットの取得頻度によっては、VMのストレージ容量が急速に増大し、パフォーマンスに影響を与える可能性があります。このため、取得するスナップショットの数量を認識することが重要です。
スナップショットのアーカイブにAmazon S3を使用のヒント
●アーカイブ前にデータの分類を優先:すべてのスナップショットが同じように重要であるわけではありません。 コンプライアンスやDRなどの重要なスナップショットと、より長い検索時間を許容できるスナップショットを区別するために、堅牢なデータ分類ポリシーを導入します。
●アーカイブからの取得に関するSLAをDR計画に統合:GlacierまたはDeep Archiveにスナップショットをアーカイブした場合、取得に数分から数時間かかる場合があります。 災害復旧(DR)計画では、こうした取得SLAを考慮して、予期せぬ遅延を回避する必要があります。
●S3 Object Lockを使用して保持の徹底を自動化:S3 Object Lockを使用して重要なスナップショットの不変性を徹底し、早期の削除を防止して、規制へのコンプライアンスを確保します。 また、誤ってまたは悪意を持って削除されることも防ぎます。
●重要アーカイブスナップショットには、クロスリージョンレプリケーションを活用:スナップショットをアーカイブする前に、クロスリージョンレプリケーション(CRR)を有効にします。これにより、リージョンがダウンした場合でも、アーカイブされたデータは別のリージョンで利用可能になります。
●AWS Cost Explorer を使用して定期的にコスト監査を実施する:S3 GlacierとDeep Archiveはコスト削減をもたらしますが、これらは長期間にわたって気づかぬうちに蓄積される可能性があります。AWS Cost Explorerを使用して定期的にアーカイブコストを監査し、スナップショットのライフサイクルポリシーが最適化されていることを確認してください。
AWS Backup スナップショット
- 整合性を保つためにアプリケーション認識型バックアップを使用:データベースやERPシステムなどの重要なアプリケーションには、アプリケーション認識型バックアップのメカニズムを統合します。これにより、アプリケーション層での整合性が確保され、実行中のインスタンスのスナップショットによる破損を回避できます。
- ワークロードの重要度に基づくバックアップのライフサイクルポリシーを実装:例えば、重要なワークロードには、より頻繁なスナップショットとより長い保持期間が必要となる場合がありますが、重要でないワークロードは保持期間を短く設定できます。
- 最小限のベースイメージでAMIを最適化:AMIを作成する際には、不要なデータや一時ファイルを除外してベーススナップショットのサイズを縮小します。スナップショットが小さくなればストレージの消費量が減り、コストを削減し、復元時間を短縮できます。
- 災害復旧シナリオのためのテスト環境を作成: 定期的にスナップショットをテスト専用環境にリストアしてテストします。これにより、バックアップの整合性が検証されます。
- AWS Cost Explorerでスナップショットの使用状況を監視: AWS Cost Explorerを使用して、スナップショットに関連するコストの傾向を特定します。これにより、使用されていないバックアップや冗長なバックアップが明らかになり、コスト最適化のためにクリーンアップや保持ポリシーの調整を促すことができます。
マイクロソフトTeams バックアップ (12)
3.仕事に適したツールを使用する
Microsoft Teamsのバックアップに関する3つ目のベストプラクティスは、作業に適したツールを使用していることを確認することです。Microsoft 365のエコシステムの中には、保持ポリシーや、バックアップの実行を支援する機能などがあります。
保持ポリシーと訴訟ホールドは擬似的なバックアップとして機能することができます。しかし、これらのツールは、データ保護ではなく、コンプライアンス目的のために存在します。そのため、Microsoft Teamsのデータを適切に保護することはできません。
データ保持ポリシーと訴訟ホールドは、データの保護方法に関して矛盾やカバーギャップを生じさせる可能性があります。Microsoft Teamsのすべてのデータを確実に保護する唯一の方法とは、以下のとおりです。Microsoft 365を保護するために特別に設計された専用のバックアップアプリケーションを使用することで、ビジネス要件と法的義務に一致した方法で保護することができます。
1. Microsoft Teamsのバックアップを確認する
Microsoft Teamsのバックアップに関する最良の方法は、Microsoft Teams(およびその他のMicrosoft 365アプリ)を実際にバックアップしていることを確認することです。
Microsoftは、Teamsとその他のMicrosoft 365アプリケーションに責任共有モデルを採用しています。この責任共有モデルは、基本的に Microsoft 365 アプリケーションと基盤となるインフラストラクチャを健全に保つ責任は Microsoft にあるが、Microsoft 365 の加入者は以下の責任を負うというものです。自分のデータを安全に保護する責任があります。このデータ保護責任には、データのバックアップを確認することも含まれます。
2. Teamsを真に理解するバックアップ・ソリューションの採用
Office 365は、非常に多くの異なるMicrosoft 365コンポーネントを活用しているため、バックアップが最も困難なアプリケーションです。Exchange OnlineやSharePoint Onlineなどのアプリケーションとは異なり、Teamsは、すべてのデータを1つの場所に保存していません。その代わり、Microsoft Teamsのデータは異なるMicrosoft 365アプリケーションを使用されています。Microsoft 365のバックアップアプリケーションであれば、Teamsのデータをバックアップできるはずですが、アプリケーションがMicrosoft Teamsをサポートするように特別に設計されていない限り、復元プロセスが非常に困難になる可能性があります。
MicrosoftはTeamsのバックアップのためのAPIを提供していますが、このAPIは最近リリースされたばかりです。そのため現時点では、すべてのバックアップベンダーがTeamsバックアップAPIを製品に組み込んでいるわけではありません。
いずれは主要ななバックアップソリューションがMicrosoft Teamsをネイティブにサポートするようになると思われますが、当面はバックアップ製品に現在そのようなサポートを含んでいるかどうかを確認することが重要です。
4. バックアップのハイブリッド化
ベストプラクティスその4は、バックアップにハイブリッドなアプローチを取ることです。Microsoft 365とオンプレミスのMicrosoft Office アプリケーションを別々にバックアップするのではなく、両方の環境を同時に保護できる1つのバックアップアプリケーションを使用するのがよいでしょう。
なぜなら、バックアップを復元するということは、何か悪いことが起こったということだからです。どのような事象がデータ復旧の必要性の引き金になるかを予測するのは難しいため、バックアップアプリケーションは最大限の柔軟性を持たせることが非常に重要なのです。バックアップにハイブリッドアプローチを採用することで、この柔軟性を強化することができます。例えば、オンプレミスのメールボックスをMicrosoft 365クラウドに、またはその逆に復元することができるようなことが可能です。
5.バックアップ計画の最前線にSLAを据える
ベストプラクティスの5番目は、サービスレベルアグリーメント(SLA)をバックアップ計画の最前線に置いておくことです。具体的には、適切なRPO(Recovery Point Objective)とSLA(Service Level Agreement)を検討する必要があります。Microsoft Teams環境のRTO(Recovery Time Objective)です。RPOは、バックアップを作成する頻度を決定し、それによって、バックアップの間に失われる可能性のあるデータの最大量を決定します。RTOは、バックアップを復元するのにかかる時間の長さに関するものです。
この2つの指標は、組織の能力に直結するため、非常に重要です。災害からの迅速かつ完全な復旧組織においてRTOとRPOは恣意的な値ではなく、組織のビジネス上の要求と、その要求を反映したものであるべきです。
7.バックアップによるeDiscovery能力の強化
Microsoft 365 には以前から eDiscovery 機能があり、召喚状に応じて Microsoft 365 のエコシステムの中から特定のデータを探し出すことができます。しかし、ネイティブeDiscoveryの機能もありますが、ディスカバリプロセスではバックアップソフトを使った方が効果的な場合が多いのです。
バックアップアプリケーションに優れた検索インターフェースがあれば、組織は召喚状で要求されるデータをバックアップで検索することができます。これは、ネイティブのeDiscovery機能を使用するよりも迅速かつ簡単であるだけでなく、次のような機能も備えています。
検索結果に表示された文書をリムーバブルドライブに復元し、相手方の弁護士に提供できるようにします。
10. 使いやすさを重視
最後のベストプラクティスは、バックアップアプリケーションに関しては、使いやすさが重要であるということです。バックアップアプリケーションの中には、設定や使い方があまりにも複雑だという評判のものもあります。この問題は、複雑であればあるほどヒューマンエラーが発生する可能性が高くなることです。もし組織が直感的で使いやすいバックアップアプリケーションを選択すれば、バックアップやリカバリの失敗を高確率的に減らすことができます。
9.ストレージの柔軟性を確保する
使用するバックアップソリューションで、オンプレミスかクラウドベースかにかかわらず、データをバックアップできることが重要です。使用するストレージを自由に選択できることで、パフォーマンス、回復力、コストなどの要件に最も適したストレージ階層を選択することができます。また、イミュータブル(Immutable)ストレージのような機能を利用することもできます。
6.リカバリーの精度を見落とさない
Microsoft Teams Backupのベストプラクティスとして、よく見落とされるのがバックアップソリューションは、きめ細かなリカバリ機能を備えているかです。チーム全体(または複数のチーム)をリストアできることは重要ですが、チーム内のファイルやチャットをリストアできることも同様に重要です。
ユーザーが誤ってチームを削除した場合、多くの場合、そのチームを復元するにはPowerShell を使用して、Azure AD Recycle Binから関連する Azure Active Directory グループを復元します。
しかし、残念ながら、Teamsのネイティブ復旧は、無益な作業となります。Microsoft は削除されたチームを復元することを許可しますが、Microsoft 365 のネイティブ ツールを使用して個々のチームを復元することはできません。
8.ランサムウェアからチームを守る
もう一つのベストプラクティスは、Microsoft Teamsのデータをランサムウェアから確実に保護することです。一般的に考えられているのとは異なり、Microsoft 365に保存されているデータは、次のような方法で暗号化することができます。
ランサムウェア多くの人が個人所有のデバイスからリモートで仕事をするようになったことが、大きく影響し、ランサムウェアに感染するリスクを高めます。
ランサムウェアに感染した場合、組織のデータを復旧させるためには、通常、身代金を支払うか、バックアップを復元するかのどちらかの選択肢しかありません。身代金の支払いには高額な費用がかかる傾向があり、身代金を支払っても、実際にデータが復号化される保証はありません。たとえデータが復号化されたとしても、身代金を支払うと攻撃者が増長し、データを再暗号化し、さらに金銭を要求してくる可能性があります。バックアップを復元する方がはるかに良い選択です。バックアップは、ランサムウェアに関連するデータ損失に対する最善の防御策です。
11. クライムが提供する「マイクロソフトTeams バックアップ」ソリューション
● Veeam Backup for Microsoft Office 365
Veeam Backup for Microsoft Office 365は、Microsoft Office 365環境の包括的なバックアップを提供します。Exchange Online、SharePoint Online、OneDrive for Business, Microsoft Teamsのバックアップが可能です。
エンドポイントデバイスおよびクラウドアプリ向けのクラウドネイティブなデータ保護サービスです。社内のあらゆるエンドユーザーデータを自動的にバックアップし、データの復元、ランサムウェア/ 情報漏洩対策、データの可視化や分析など、さまざまなデータ保護機能を提供します。
Azureコスト (5)
1.徹底したプランニング
包括的な要件収集
多くの企業では、ビジネスプロセスや、ビジネスプロセスによってどのようにテクノロジーが推進されるのかについて、詳細な文書がない場合があります。このステップは、通常、計画の中で最も時間のかかる部分です。各ビジネスプロセスがどのように機能し、技術リソースとどのように相互作用するかを正確に把握することは、リソースをクラウドに移行することに意味があるのか、またどのような影響があるのかを判断するために非常に重要です。
コンピュート資源、ディスクスペース、ネットワークのニーズなどの技術的要件だけでなく、コンプライアンスや規制に関する考慮事項、リソースの可用性、他のビジネス・ワークフローとの統合も考慮する必要があります。
コストの見積
技術的なニーズとビジネスプロセスのニーズについて包括的な資料が揃ったら、ワークロードの移行、あるいはクラウドでのワークロードの再実装に関連するコストとメリットを検討し始めることができます。従来のコンピュートやストレージのニーズ以外にも、さまざまな考慮事項があります。
– バックアップのコスト、ポータビリティ、スペース
– リソースの初期転送と継続的なニーズに対応するための帯域幅
– ロードバランサー、アプリケーションゲートウェイ、スケール関連機能
– Azure AD(プレミアムの場合)およびOffice 365ユーザーのライセンスコスト
– Microsoft SQLやMicrosoft WindowsなどのVMライセンス
– 開発環境リソース
– 継続的インテグレーション/継続的デプロイメント(CI/CD)コスト
オンプレミスで購入したハードウェアの保守契約費用を除けば、ほとんどのクラウドリソースには定期的な使用費用が発生します。従来の資本支出モデルと比較すると、クラウドサービスの運用コストは複数年に渡って分散される可能性があります。短期間の利用であれば比較的リーズナブルですが、慎重に管理しないとコストオーバーにつながる可能性があります。
制約と予算のしきい値
多くの企業では、IT予算が無制限にあるわけではありません。Azureはリソースのデプロイを容易にし、それに応じて予算オーバーも容易にします。しかしAzureは「自分のペースで学べるAzure Cost Management tools」によって、クラウドのコストを計画し、コントロールすることも簡単にできます。
また、予算というと実際の金額が思い浮かぶかもしれませんが、それだけが予算ではありません。利用可能なリソースでチームを最大限に活用するために、人的資本の予算も重要です。
– 各ビジネスユニットの予算と、それが具体的なリソースにどのように関わってくるかを検討
– どの時点で、誰に、どのようなアクションを起こすべきか、予算に関する警告を行うべきかを決定する
– 拡張性のあるリソースは、無秩序な成長とコストを避けるために制約を設ける必要がある
Azureの異なるサービスやオファリングは、コストと機能価値を比較した場合、同等とは限りません。このため、利用可能な機能と関連するコストの両方を戦略的に検討し、組織にとって最も価値のあるものを選択することが重要です。
共有資産の利用可能性
類似のワークロードは、共有リソースを活用する上で魅力的なターゲットとなります。セキュリティ、セグメンテーション、パフォーマンスなどの理由で専用インスタンスを必要としないリソースは、共有のコンピュート、ストレージ、アプリケーションインスタンスを使用することでコストを削減することができます。このような基準に合致するワークロードを特定することで、統合によって使用するリソースを節約することができます。
仮想マシンの共有による統合だけが、コスト削減の手段ではありません。コンテナベースのデプロイメントを検討する場合、Azure Kubernetes Serviceのような専用の管理プラットフォームを利用すると、配置と利用を最適化でき、投資を最大限に生かすことができる場合があります。
ガバナンス戦略
IT担当に与えられた柔軟性により、クラウドは瞬く間に戦場と化す可能性があります。事前に適切なガバナンスプランと戦略を導入することで、制約のない広がりを制御すると同時に、イノベーションのための自由とコスト管理を可能にします。Azureポリシーによって、組織はIT担当者が利用できるリソースの種類、サイズ、機能を制御することができます。さらに、リソースのタグ付けを利用することで、これらのリソースをグループ化し、さまざまなチーム、リソースタイプ、プロジェクトに関連付け、レポートを作成してコストを管理することができます。すべてのリソースにタグ付けできるわけではなく、タグは継承されないため、適切なタグ付け戦略を確実に実行することが重要です。
0.Azureコスト削減のための4つの施策 (初めに)
ここでは、Azureでコストをコントロールしながら、利用可能なすべてのサービスと機能を最大限に活用するための4つのステップについて説明します。新たにクラウドを導入する企業も、以前からクラウドファーストのアプローチを取っている企業も、適切な計画、展開、監視、最適化によって、Azureの活用を成功させることができます。
2. 実装と展開
適切な計画が立てば、次のステップは必要なリソースの配備です。クラウドへの完全移行に重点を置いている場合でも、単に小規模から始める場合でも、価格と柔軟性について考慮することで、将来的に大きな違いが生まれます。計算機、ディスク、データベースには、コストを大幅に削減できるさまざまなオプションが用意されています。
コンピュート・リソース
クラウドベースの仮想マシンは、最も一般的に使用されるクラウドリソースの1つであり、多くのITプロフェッショナルが最初に検討するものの1つであると思われます。仮想マシンをデプロイする必要がある場合、Azureはいくつかのコスト削減策を提供しています。
– 予約済み仮想マシンインスタンス : 指定されたリソースの年数を事前に購入することで、企業はより低いコストで利用することができます。
– スポット価格 : 特定のマシンが常に存在する必要はありません。そのような場合は、スポット価格を使用して、未使用のコンピューティング容量を大幅な割引価格で購入することができます。アプリケーションは潜在的なシャットダウンに強いことが必要ですが、その場合は大幅なコスト削減を実現できます。
– Dev-Test Pricing – 堅牢な開発およびテスト環境を持つ組織では、これらのマシンは通常短命で使用率が低いため、これらの環境の割引料金を利用することでコストを抑えることができます。
また、コンテナやPlatforms as a Service(PaaS)は、その柔軟性と使いやすさから非常に人気が出てきています。Azure Kubernetes Service (AKS) は、コンテナのオーケストレーションに最適です。ワークロードをコンテナに移行することで、企業はリソースをより緊密にまとめ、最新のマイクロサービス・アーキテクチャを活用することでコスト削減を実現することができます。App Services などの PaaS は、Web サーバーの従来の管理負担を軽減するものです。既存のWebサイトをApp Servicesに移行することで、従来のVMを使用する必要がなくなり、管理時間やコストそのものを削減できる可能性があります。
Azureストレージ層の活用
クラウド環境のコンピューティング能力を支えるのは、大容量のデータを保存する必要性です。そのため、必要なストレージの種類を適切に計画することに時間をかければ、コストを削減することができます。このことは、組織のデータストレージのニーズが高まり、特定の種類のデータが特定のストレージ層に最適であることが判明した場合に特に顕著になります。
Azure Storageのいくつかの機能は、データの安全な転送と保存のための魅力的なオプションになります。プライベートエンドポイントを使用すると、クライアントがプライベートリンクを介してストレージデータに安全にアクセスできるようにすることができます。これにより、公共のインターネットからの露出を制限し、ストレージへのアクセスの制御を強化することができます。
Azureストレージの価格
Azureで利用できるストレージにはいくつかの種類がありますが、一般的に多くのニーズを満たすのは、マネージドディスクとブロブの2種類です。
マネージドディスクは、従来のストレージメディアで、物理サーバーにインストールされた追加のハードディスクに相当します。この拡張可能なディスクには、いくつかの異なる階層があります。どのようなディスク速度を必要とするかによって、いくつかの層から選択することができます。
– プレミアムSSD
– スタンダードSSD
– スタンダードHDD
– ウルトラディスク
ディスクの速度について語るとき、一般的には1秒間に行われる入出力操作の数であるIOPSを意味します。管理対象ディスクの階層によって保証されるIOPSが異なるため、アプリケーションのパフォーマンスに直接影響を与えることができます。P30より小さいプレミアムSSDサイズでは、バースト可能なIOPSと帯域幅を提供し、VMの起動時間とアプリケーションのパフォーマンスを大幅に向上させることができます。このタイプのバーストは、VMレベルおよびディスクレベルで独立して利用可能です。一方を有効にすれば、もう一方は必要ありません。どちらも、1日を通して使用するIOPSクレジットのバケットを蓄積して使用します。このバケットを使い切ると、パフォーマンスは基本ディスク・タイプのものに戻り、使用前に再度蓄積する必要があるため、アプリケーションやVMのパフォーマンスに悪影響を与える可能性があります。
Azure Blob は、保存すべきデータが大量にある場合に、より理にかなっていると言えるかもしれません。このデータは、常にアクセスする必要がない場合もあれば、複数のリソースで簡単に共有する必要がある場合もあります。バックアップは、Blobストレージの典型的な使用例である。このタイプのストレージは、AWS S3タイプのオブジェクトおよびメタデータストレージファイルシステムに相当する。Blobストレージにはいくつかの階層があり、価格とアクセス速度に影響します。
– プレミアム
– ホット
– クール
– アーカイブ
Azure Blobストレージのコストは、月間の1日あたりの平均保存データ量(ギガバイト(GB)単位)で決定されます。例えば、月の前半に20GBのストレージを使用し、後半は全く使用しなかった場合、平均10GBの使用量に対して請求されます。クール層とアーカイブ層から45日後に削除する場合、135日分(180日から45日を引いた日数)の早期削除料が課金されますので、計画的に利用ください。
ファイルストレージとブロックブロブストレージの両方について、冗長性に関するオプションがあります。ローカル冗長ストレージ(LRS)と地理的冗長ストレージ(GRS)のどちらを選ぶかは、コストに大きく影響し、2倍から3倍のコストになることもあります。GRSは保護とアップタイムを向上させますが、コストは高くなります。レプリケーションの設定はいつでも変更可能ですが、LRSから他のタイプのレプリケーションに移行する際には、イグレス帯域幅の料金が発生します。
また、Blobストレージのアプリケーション・プログラミング・インターフェース(API)のコストも考慮しなければなりません。読み取り、書き込み、リスト、作成の各操作には、1万トランザクションあたりのコストがかかる。オブジェクト操作の量が多い場合、これは計画上予想外のコストとなる可能性がある。Blobストレージが、大きな単一オブジェクトでアクセス頻度の低いデータにのみ使用されている場合、APIコストは無視できると思われます。
Cool層とArchive層からそれぞれ30日、180日未満でデータを取り出す場合、追加料金が発生する可能性があることに留意してください。これらのストレージは、より長期的で安価なストレージであることを意図しています。
SQLエラスティックプール
SQLサーバーはすぐに高価になります。本番データベース1つにつき1台のサーバーという従来のモデルでは、特にライセンス要件によって、コストが爆発的に上昇する可能性があります。SQL Elastic Poolsは、データベース間でコンピュートとストレージのリソースを共有し、プロビジョニングされたすべてのリソースを効率的に使用するもので、コストを劇的に削減できる拡張性のあるソリューションです。
リソースの使用量を制限することで、データベースがリソースを乱用して他のデータベースに悪影響を与えないように、さらに最適化し制限することができます。プールの価格は、設定されたリソースの量に基づき、データベースの数とは無関係に決定されます。このタイプのセットアップは、データベースごとに1台のサーバーを使用するアプローチではなく、顧客のデータベースをホスティングする場合にも最適です。
例として、30人のお客様がいて、それぞれがデータベース・インスタンスを持っているとします。最も安価な5 DTUプランを約4.8971ドル/月で購入すると、顧客データベースを格納するためのコストは結局約147ドルになります。Elastic Poolsに移行すると、50 DTUプランを73ドルで購入でき、最大100個のデータベースを扱えるようになります。また、個々のデータベースが使用するリソースを制限することで、プール全体への悪影響を抑制することができます。
Azure Functionsによるサーバーレス
多くの組織が新しい「サーバーレス」能力を活用しています。インフラを管理することなくコードやアプリケーションを実行できるため、迅速な導入と開発につながります。Azure Functionsは、C#、Java、JavaScript、Python、PowerShellでコードを記述し、オンデマンドまたはスケジュールに従ってコードを実行する機能を提供します。
使用量に応じた課金モデルを採用しているため、コードの実行に費やした時間に対してのみ料金を支払う必要があります。400,000GB/s(メモリ使用量に基づくギガバイト秒)と100万回の実行が無料であるため、消費プランでは最小限のコストで始める方法が提供されています。
バックアップソリューションの最適化
ストレージ層についてのセクションで述べたように、バックアップにBlobストレージを使用すると、特にCool層とArchive層を使用する場合、コストを削減することができます。このタイプのストレージは通常、障害発生時に迅速にリストアする必要があるフルVMスナップショットには使用されません。Microsoft Azureは、各VMに適切なスナップショットが取得されるように支援するバックアップサービスを提供している。これは、VMごとの固定コストと消費されたストレージのコストに基づいています。
どのようなビジネス環境においても必要不可欠なバックアップのコストを軽減するために、Veeam Backup for Microsoft Azureのようなサードパーティ・ソリューションを使用することで、多数のVMのバックアップや、データを長期間保持する必要がある場合のコストを節約することができます。例えば、VeeamはAzure用に構築されたクラウドネイティブバックアッププロセスにより、10台のVMを無料で提供しています。ビルトインのコスト計算機により、作成するバックアップ・ポリシーにどれだけのコストがかかるかを実装前に積極的に確認することも可能です。
さらに、Veeamはクラウドに依存しないファイル形式を使用しているため、データのポータビリティを実現します。このバックアップ・プロセスの明白でない利点は、Veeamを活用してオンプレミスのマシン・バックアップを自動的にクラウドに移動することができることです。オンプレミスサイトが突然アクセス不能になった場合、データポータビリティとクラウドネイティブソリューションにより、Veeamバックアップを活用して、以前に作成したバックアップを経由して環境を迅速に起動することができます。
コンテナのバックアップの必要性については、その刹那的な性質からあまり考えないかもしれませんが、Kubernetesクラスタにはステートフルなコンテナと関連する設定やメタデータが存在することがよくあります。すべてのコンポーネントをまとめて包括的にバックアップし、環境全体を迅速に復元できるようにすることは困難です。例えばVeeamのKasten K10は、Kubernetesクラスターのあらゆる側面をバックアップする機能を提供します。さらに、適切なポリシーとリソースのディスカバリーを定義することで、適切なガバナンスを確保し、リソースの取りこぼしがないようにします。
3. 環境、コスト、トレンドのモニタリング
環境が正常に稼働している間に、組織はすべてのリソースが監視され、計上されていることを確認し、コストの傾向を特定する必要があります。Azureは、リソースのコストを表示し、レポートするためのいくつかの異なるソリューションを提供しています。
Azureコスト管理ダッシュボードに注目する
結局のところ、リソースをどこでどのように使っているか、そしてその関連コストを本当に理解する唯一の方法は、ダッシュボードを使用して、最もお金がかかっている場所を可視化することなのです。Azureコスト管理は、お客様の組織とそのリソースの使用パターンを包括的に見ることができます。これには、Azureのサービスごとのコストと、サードパーティのMarketplace製品ごとのコストの両方が含まれます。
Azure内には非常に多くのコスト計算方法があるため、予約やAzure Hybrid Benefitの割引を考慮したコスト計算ソリューションがあれば、使用中のリソースに関してスマートな意思決定ができるようになります。
Azure Cost Management dashboard
また、データをCSVで他の会計システムや予算管理システムに簡単にエクスポートすることができます。ただしアドバイザーの推奨、予算管理、コスト超過を防止・予測するためのコスト警告機能が組み込まれているため、その必要はありません。
法規制とコンプライアンスの監視
コスト管理と同様に重要なのが、規制やコンプライアンスに関する管理です。
があります。Azure Security Centerには、ISO 27001、PCI DSS 3.2.1、Azure CIS 1.1.0、HIPAA HITRUSTなどの規格への準拠を確認および評価するための規制遵守ダッシュボードが含まれています。
重要な規制基準への準拠を積極的に監視することで、適切なセキュリティが確保されます。また、将来の監査において、コストのかかる頭痛の種やコンプライアンス作業を軽減することができます。
4.環境とコストの最適化
環境とコストの最適化多くのクラウド環境は流動的であるため、環境のニーズ、パフォーマンス、利用状況を継続的に評価することが重要です。拡張の機会が特定されたら、さらなる対策を講じることができます。使用されているリソースの種類によっては、異なるクラスのリソースやPaaSへの移行が必要となる場合があります。
大規模な環境では、多くのワークロードが使用されていることがよくあります。多くのVMが存在するため、リソースの統合や廃棄の機会があるかどうかを判断するのは難しい場合があります。あまり使用されていないサービスを発見するのに役立つツールの1つが、モニター・サービスです。仮想マシンのインサイトセクションを利用すれば、VMの使用率に関する集計データを見つけ、最も多くのリソースを使用しているVMや最も使用していないVMを発見することができます。
適切なモニタリング戦略があれば、VMのサイズを変更するなどのさらなる措置を講じることができるかもしれませんし、従来は仮想マシン上に置かれていた特定のアプリケーションをコンテナ化して、さらにコストを削減する必要があることが分かるかもしれません。
同様に、ストレージアカウントの節約を見つけるために、「Monitor Storage Accounts Insights」セクションは、指定された期間におけるトランザクション量と使用容量を分析し、節約の機会を明らかにします。このツールは、どのアカウントが不要になり、どのアカウントを統合できるかを特定するのに役立ちます。
リソースを管理する上で見落とされがちなのが、効果的なタグ付けの方法です。使用中のリソースに適切なタグを付けることで、廃棄の対象となるリソースを容易に特定することができます。さらに、タグ付けを行うことで、リソースのライフサイクルを管理するためのレポートを作成することができます。
ランサムウェア対策のための13のベスト・プラクティス (14)
1.ヒューマン・ファイアウォール/厳密調査
テクノロジーだけでは、組織のサイバーセキュリティ態勢を強化することはできません。サイバー攻撃の複雑さと脅威が増す中、組織は多層防御を構築することに注力しなければなりません。つまり、全員がセキュリティリスクと潜在的なインシデントを認識し、不審な点があれば報告することが必要です。この人的保護層の重要性は、多くの侵害が従業員のミスによるものであるという事実にあります。ハッキングの成功は、不注意や単純なミス、サイバー脅威やサイバー犯罪者のやり方に関する知識不足が原因であることが多いのです。
フィッシング、リモートアクセス(RDP)、ソフトウェアアップデートが、サイバー犯罪者が侵入する3つの主なメカニズムであることを知ることは、侵入先を絞り込む上で大きな助けになります。攻撃経路の観点から、最も労力を費やすべきものです。
従業員のサイバー意識はどうか?
サイバーセキュリティの意識向上プログラムを実施し、従業員の潜在的な知識のギャップを特定する。組織のサイバーセキュリティに対する意識の成熟度を、たとえば次のような方法で評価します。 フィッシング・シミュレーション・プログラムを使って、現在のサイバー意識のレベルを明らかにしましょう。
送った覚えのない荷物の配送状況を確認するために、リンクをクリックするようにというメールを受け取ったことはありませんか?あるいは、アカウントのパスワードを確認するためにリンクをクリックするよう求めるものがありましたか?これらはいずれもフィッシングメールである可能性があります。
ヒューマンファイアウォールは、あらゆる種類のランサムウェアに対する防御のための重要なレイヤーです。協力することで、脅威を特定し、データ漏洩を防止し、被害を軽減することができます。より多くの従業員がヒューマンファイアウォールに参加することで、より強固なものになります。
2.常に最新の事業継続計画(BCP)を持っていること
あなたの組織にとって重要なプロセスは何ですか?業務に支障をきたすような出来事があった場合、誰に連絡する必要がありますか?事業継続計画(BCP)が常に利用可能であることを確認することは、たとえすべてが失われ、ロックダウンされたとしても、組織が生き残るために非常に重要です。BCPは別の場所に保存され、不変であり、24時間365日利用可能であることを確認することがベストプラクティスです。BCPは、計画外のサービス停止時にどのように業務を継続するかを概説する必要があります。デジタルのシステムやサービスが復旧するまでの間、業務を継続できるように、手動による回避策をBCPに記載する必要があります。
3. デジタル資産へのタグ付け
サイバーセキュリティ対応計画を成功させるためには、どの資産が組織にとって重要で、どのようにすれば効果的に保護できるかを洞察することが不可欠です。保護を開始する前に、最も効果的な計画を立てるために、これらの資産を特定し、タグ付けする必要があります。デジタル資産にタグを付けることは、干し草の山から針を探すのと、簡単な検索で必要な特定の資産を見つけるのとでは、大きな違いがあります。
4. ヒューマン・ファイアウォール – 教育
ランサムウェア攻撃に対する防御レベルを上げるには、サイバーセキュリティに関するスタッフの教育やトレーニングが非常に効果的かつ効率的です。あなたの組織にはセキュリティの専門家がいないため、基本的な知識を提供し、インシデントに直面したときに取るべき適切なアクションを明確にする必要があります。また、サイバーセキュリティ教育プログラムの有効性を繰り返し検証する必要があります。
多くの組織では、セキュリティ啓発のためのトレーニングは年に1回しか行われていませんが、残念ながらこれでは十分ではありません。ヒューマン・ファイアウォールのトレーニングは継続的に行うべきであり、脅威の発生に応じて従業員は更新や新しいブリーフィングを受ける必要があります。また、従業員は、職種が変わるたびに新しい問題について教育を受ける必要があります。サイバーセキュリティの筋力は、セキュリティ事故の可能性がある前に訓練しておく必要があります。従業員への教育こそが、ランサムウェアに対する最大の防御策であり、保護策であることを忘れないでください。
9.セグメンテーション
最終的に、すべてのセキュリティは、貴重な資産を保護することです。この場合、それはデータですが、その保護には、すべてのレイヤーを含む徹底的な防御戦略が必要です。徹底的な防御戦略を行うには、最も価値のあるデータを特定し、その周りに防御の層を構築して、可用性、完全性、機密性を保護する必要があります。セグメンテーションとは、インフラストラクチャーをゾーンに分割することで、必要なアクセスレベル、共通の制限ポリシーによる制約、ゾーン内外での接続性などを考慮して、オブジェクトを論理的なゾーンにグループ化することです。
ゾーンとは、特定の特性、目的、用途、および/または特定の制限のセットを持つ領域のことです。ゾーンを使用することで、多くの種類のリスクを低減するための効果的な戦略を持つことができます。より詳細かつ効果的な方法で環境を保護しながら、それに関連するコストを削減することができます。すべてを同じレベルで保護するのではなく、システムや情報を特定のゾーンに関連付けることができるようになりました。さらに、規制遵守の対象となるシステムをサブゾーンにグループ化することで、コンプライアンスチェックの範囲を限定できるため、長時間の監査プロセスに必要なコストと時間を削減することができます。
5. 3-2-1 データ保護ルール
3-2-1ルールは、データを保護するための業界標準であり、ランサムウェアとの戦いにおいて究極の防御策となります。このルールでは、重要なデータそれぞれについて、少なくとも3つのコピーを保管し、バックアップデータを2つの異なるメディアに保存するよう求めています。また、データのコピーを1部、オフサイトに複製します。
8. 最小特権の原則
この原則は、ユーザーアカウントまたはプロセスに、その意図する機能を実行するために絶対に必要な権限のみを与えることを意味します。最小特権の原則は、障害や悪意ある行動からデータや機能を保護するための重要な設計上の考慮事項として広く認識されています。
7. K.I.S.S.(Keep it simple and straightforward principle: シンプルでわかりやすく)
複雑すぎる設計はITチームにとって管理が難しく、攻撃者が弱点を突いたり、影に隠れたりすることを容易にします。管理しやすいシンプルな設計は、基本的に安全性が高いのです。K.I.S.S.(シンプルでわかりやすく)の原則に基づき、設計を行うようにしましょう。
6. セキュア・バイ・デザイン
既存のインフラにセキュリティを追加することは、既存のインフラを強化することを考えるだけでなく、新しいインフラや刷新されたインフラを設計するよりもはるかに難しく、コストも高くつきます。仮想インフラストラクチャでは、最初からセキュリティが確保されたマスター・イメージを構築するのがベターな方法です。既知の攻撃ベクトルをすべて取り除き、コンポーネントが追加され、正しく機能するために特定のオープン化や追加ソフトウェアが必要な場合にのみアクセスを開放することが、ベストプラクティスと言えます。こうすることで、すべてのビルドに一貫性が生まれ、最新の状態に保たれるため、安全なベースラインが構築されます。
10. 職務分掌
職務分掌は、企業の持続的なリスクマネジメントと内部統制の基本的な構成要素である。これは、セキュリティに関するタスクと権限を複数の人に分散させるという考え方です。一人の人間がすべてをコントロールできるべきではありません。つまり、一人の人間がすべてを削除する能力も持ってはいけないということです。例えば、ある人が本番環境をコントロールし、別の人がバックアップ環境をコントロールすることです。バックアップの実践においても、プライマリバックアップシステムとは異なる認証と管理下にあるデータのセカンダリおよびオフサイトコピー(すなわちDR)を持つことは、ベストプラクティスと考えられています。
11. デジタル健康法
日常生活において、私たちは個人の衛生や清潔さを重要視しています。手を洗うことで感染症の蔓延を防ぐことができることは周知の事実であり、清潔さを保つことは日常生活の基本です。
しかし、脅威や脆弱性が増加し、デジタルとの接点が広がるにつれ、デジタル・インフルエンザに感染する危険性が常に存在することになります。実際のインフルエンザと同じように、いくつかの基本的なデジタル衛生習慣に従うことで、デジタル世界を移動する際のリスクを低減する方法があります。優れたデジタル衛生習慣に従うことで、データを健康に保ち、プライバシーを保護し、セキュリティを損なわないようにすることができます。
重要な実践例:
– 各ログインソースにユニークなパスワードを作成する。こうすることで、あるパスワードが破られたとしても、盗まれたパスワードで他のアカウントにアクセスされることがなくなります。
– パスワードマネージャーを使用する。100を超えるパスワードを覚えるのは大変です。優れたパスワードマネージャーを使えば、すべてのログイン情報を管理でき、固有のパスワードを簡単に作成し、使用することができます。
– 多要素認証(MFA)を利用する。MFAを設定することで、さらなるアカウントの安全性を確保することができます。
– 堅牢なパスワードポリシーを使用する
– アカウントのロックアウトポリシー
– 未使用のデバイス、アプリケーション、退職した社員、必要のないプログラムやユーティリティを削除する。
– パッチ管理:使用中のソフトウェア、ハードウェア、ファームウェアがすべて最新のソフトウェアレベルで動作していることを確認する。
12. バックアップ
デジタル健康法はレジリエンスを高めるための重要な要素です。定期的にバックアップをとっていれば、サイバー脅威は災害ではなく、むしろ不勝手なものになります。1日分の仕事を失うことはあっても、すべてを失うことはないでしょう。特定の種類のデータをどれくらいの頻度でバックアップするか、クラウドサービスを使うか、物理デバイスを使うかは、必要なサービスやセキュリティレベルに基づいて選択する必要があります。
ランサムウェアは、ファイルを暗号化することで、自分自身のデータからあなたを締め出す。このため、適切なバックアップはこの種の攻撃から回復するための優れた方法です。バックアップがあれば、暗号化されたファイルを最近のバックアップリポジトリにあるコピーと簡単に交換することができます。バックアップに戻すと、最新のデータの一部を失うかもしれませんが、サイバー犯罪者にお金を払ってファイルを復元してもらうよりは確実によいでしょう。
13. 暗号化について
暗号化により、許可された者だけがあなたの情報にアクセスできるようにします。あなたの情報が定義されたセキュリティ・ドメインから離れるとすぐに、あなたの情報があらかじめ定義された適切なレベルで暗号化されていることを確認します。暗号化自体は干渉を防ぐものではありませんが、権限のない第三者があなたの情報を読むことを禁止することができます。暗号化は、他のセキュリティ対策が失敗した場合に、機密データを保護するのに役立ちます。
0. ランサムウェア対策のための13のベスト・プラクティス
ランサムウェア対策のための13のベスト・プラクティスを紹介しています。
https://www.climb.co.jp/faq/faq-category/ransamware-best13
ブログでも各種ランサムウェア対策を紹介しています。
AWSとN2WS (6)
N2WS vs. AWS Backup
復旧シナリオ : AWS環境でのデータ保護の構成管理ツール「 N2WS 」では、災害やAWSの停止が発生したときに実行できるシナリオを作成することができます。これにより、最も重要なリソースを重要度の高い順に復旧させ、RTO/RPOを最小化することができます。この機能のドライラン機能により、テストを実施し、これらの復旧を実行するための準備がすべて整っていることを確認することができます。
クロスリージョン/アカウントディザスターリカバリー :N2WSは、最も包括的なクロスアカウント/リージョンを提供し、ボタンをクリックするだけで全環境をリカバリーすることができます。AWS Backupのバージョンは非常に基本的で、実行が複雑です。
スケジュール :AWS Backupでは、バックアップのスケジュールを1/12/24時間ごとに設定するよう制限されています。N2WSではそのような制限はなく、バックアップは1分ごとにスケジュールすることができます。
ファイルレベルリカバリー : AWS Backupは、Amazon EFSのファイルレベルリカバリーのみをサポートしています。N2WSは、EFS、EC2、S3に対してファイルレベルのリカバリを実行できます(暗号化されたボリュームに対しても)。
Start/Stop Servers (Resource Source Control) : N2WSのこの機能は、EC2インスタンスのアクティブ化と非アクティブ化のスケジュールを設定することが可能である。例えば、非生産用のインスタンスを月曜日から金曜日の午前9時に開始し、午後5時に停止するようにスケジュールすることができる。これにより、お客様はAWSのコストを数千ドル削減することができます。N2WSのお客様であるGett様は、この機能により年間60,000ドルのコスト削減を実現しています。
RDS MySQL & PostgresSQL (S3) : N2WSは、これらのRDSカテゴリをS3に保存することができ、より安価でコールド・ストレージを使用することにより、ストレージコストを大幅に節約することができます。AWS Backupにはこの機能はありません。
自動化 : N2WSによる自動化のおかげで、お客様は他の重要なトピックにエネルギーを集中させることができ、N2WSにバックアップの世話をさせることができるようになります。つまり、一度必要なポリシーとスケジュールを作成すれば、あとはツールがバックグラウンドでバックアップを行い、何か問題が発生したり、注意が必要な場合はアラートが表示されるのです。N2WSは、保存ポリシーに応じて、S3、Deep Archive、Glacierなどのコールドストレージへの保存を自動化することも可能です。これにより、AWSのコストを大幅に削減することができます。
カスタマーサポート : N2WSは、24時間365日のプレミアムサポートを提供し、必要なときにはサポートします。AWSのサポートは別途費用がかかります。
レポートログとモニタリング : AWSでは、レポートログとモニタリングは別料金で、設定が必要です。N2WSでは、バックアップ、リストア、管理、監査の全活動を監視し、追加コストなしですぐに使えるレポートを提供します。
ユーザ・クラウドバックアップのランサムウェア対策ヒント
- バックアップの暗号化を維持 データ保護を確実にし、ランサムウェアやサイバーセキュリティの問題によるリスクを軽減するために、暗号化されたリソースのクロスリージョンバックアップを作成します。
- バックアップネットワークをセグメント化する: バックアップシステムをメインネットワークから分離します。専用のVLANを使用し、バックアップが運用システムと同じネットワークセグメントからアクセスできないように。
- バックアップの完全性を定期的に検証する: バックアップの定期的なチェックと検証を行い、データが破損していないこと、必要なときに正常にリストアできることを確認します。
- ローリングバックアップ戦略を採用する: ローリングバックアップスケジュールを実施し、複数のバージョンのデータを異なる時間枠で保持する。これにより、ランサムウェア感染前の時点に復元することができます。
- エンドポイントプロテクションを使用してバックアップエージェントを保護する: バックアップ・エージェントを実行するすべてのデバイスとサーバーが、ランサムウェアのエントリ・ポイントにならないように、堅牢なエンドポイント保護機能を備えていることを確認します。
S3バックアップ:考慮すべき5つの鍵
- リージョン間レプリケーションを活用: クロスリージョンレプリケーション(CRR)を実装して、AWSのリージョン間でオブジェクトを自動的にコピーします。 これにより、地理的に離れた場所にデータを保存することで災害復旧能力が強化されるだけでなく、データ保存要件への準拠も支援します。
- N2WSで簡単に自動化: N2WSは、複雑なコーディングや手動での介入を必要とせずに、S3バックアップを自動化するシンプルで使いやすい方法を提供します。 これにより、効率が向上し、S3データの保護が確実に維持されます。
- インテリジェント・ティアリングでコストを最適化:S3インテリジェント・ティアリング・ストレージクラスを利用して、アクセスパターンの変化に応じて、2つのアクセス層(頻繁なアクセスと頻繁ではないアクセス)間でデータを自動的に移動させます。これにより、パフォーマンスへの影響やオーバーヘッドなしにストレージコストを最適化できます。
- セキュリティを強化するMFA Delete:バージョン管理機能付きのS3バケットで多要素認証(MFA)による削除を有効にすることで、セキュリティをさらに強化できます。オブジェクトのバージョンを恒久的に削除する操作にはMFAが必要となり、削除を防止します。
- AWS S3 Storage Lensでストレージを分析:S3ストレージの使用状況とアクティビティの傾向を可視化できます。このツールは、コストの最適化、データ保護のベストプラクティスの強化、パフォーマンスの向上に役立つ洞察と推奨事項を提供します。
Amazon S3 Glacierバックアップ
●ハイブリッドストレージ戦略で取得コストを最適化:S3 GlacierをS3 StandardまたはS3 Intelligent-Tieringと組み合わせます。 頻繁にアクセスされるデータはStandard/Intelligent-Tieringに残し、長期にわたってアクセス頻度の低いデータをGlacierに移行します。 これにより、より重要なデータへの迅速なアクセスを確保しながら、ストレージコストを大幅に最適化できます。
●S3 Object Lock を活用して変更不可のバックアップを作成:S3 Object Lock を Glacier と組み合わせて使用することで、変更不可のバックアップを作成できます。これにより、重要なバックアップに WORM(Write Once Read Many)モデルを適用することで、誤って削除されたりランサムウェア攻撃を受けたりした場合でも、お客様のデータを確実に保護することができます。
●大きなファイルにはマルチパートアップロードを使用: 大きなアーカイブには、Glacierのマルチパートアップロード機能を使用します。 アップロードの効率が向上するだけでなく、管理しやすい小さな部分に分割してファイルをアップロードすることで、アップロードの失敗リスクを低減し、データの整合性を確保できます。
●DRには地域間レプリケーションを実装: 地域間レプリケーションを設定して、AWSの1つのリージョンから別のリージョンにデータを自動的に複製します。これは、地域的な障害が発生した場合に、重要なデータのコピーが常に別の地理的場所で利用可能であることを保証するため、災害復旧に不可欠です。
●異なるデータセットごとのカスタム取得プラン:異なるデータセットのビジネス上の重要度に基づいて、カスタム取得プランを定義します。例えば、優先度の高いデータについては迅速な取得、重要度は低いがサイズの大きいデータセットについては一括取得などです。これにより、コストのバランスを調整し、重要な情報が迅速に利用可能であることを保証します。
AWS Backupの制限について
AWS Backupは基本的なバックアップの自動化に重点を置いており、災害復旧、粒度の細かい復旧、復旧のオーケストレーションやドリルなどの組み込み機能が欠けているなど、いくつかの制限があります。しかし、よりシンプルなバックアップのニーズを持つ組織にとっては、便利なソリューションとなるでしょう。より高度な要件には、N2Wのようなサードパーティのツールが、より費用対効果や効率性の面で優れているでしょう。
- ワンクリックでのリストアなし:AWS Backupを使用したリストア操作の自動化は、API操作を使用してプログラム的に行う必要があり、これはDevOpsの実践がしっかりしている企業には適しているかもしれません。より簡単なリカバリオプションを求める人にとっては、N2Wはスクリプトを必要とせず、簡単かつほぼ瞬時にワンクリックでリカバリを行うことができます。
- 粒度の細かいリカバリなし: AWS Backupは、ファイル/フォルダレベルの粒度を伴わずにサーバー全体をリカバリします。(AWS Data Lifecycle Manager やその他の AWS サービスでは、より詳細なバックアップ戦略が利用できる可能性があります。)完全な柔軟性と詳細性が必要な場合は、N2W を使用してバックアップおよびリカバリのファイル/フォルダをドリルダウンしたり、複数の世代のバックアップを検索して特定のファイルを見つけることができます。バックアップの分類について事前に計画したりインデックスを作成しておく必要はありません。N2W が自動的にドリルダウンアクセスを提供します。
- 災害復旧なし:AWS Backupでは、ユーザーが手動でスナップショットを別のリージョンにコピーすることは可能ですが、自動復旧オプションはありません。 現在、多くの企業がAWS Organizationsの一部として複数のAWSアカウントを運用しているため、アカウント間のバックアップができないことは、企業にとって大きな制限となります。 アカウント間の災害復旧は、あらゆるDR計画の重要な要素であり、ランサムウェア、内部からの悪意ある攻撃、または人為的ミスなど、AWSアカウントが侵害されるのを防ぎます。
N2Wは、クロスリージョンおよびクロスアカウントの災害復旧を完全にサポートしています。例えば、ユーザーは30秒以内に他のリージョンまたはアカウントのEC2インスタンスを完全に復旧することができ、RTO(目標復旧時間)を短縮できます。
- ネットワークの復元なし: もう一つの重要な機能として、AWSインフラ全体の可用性を確保する上で不可欠なAmazon VPCのクローン作成とキャプチャができないという点が挙げられます。一方、N2W Backup & Recoveryでは、この機能が提供されており、停電や障害が発生した場合でも、わずか数分でインフラを迅速かつ完全に復旧させることができます。
- リカバリーシナリオなし:AWSバックアップには、リカバリーシナリオ機能(スクリプト作成なし)がありません。N2Wでは、完全なDRフェイルオーバーの綿密なオーケストレーションを作成し、リカバリーシナリオ内で復元したいリソースに変更を加え、リカバリーの優先順位を決め、DR訓練を自動化することができます。
- 真のアーカイブなし:AWSバックアップでは、EBSバックアップを低価格のS3ティアリングにアーカイブすることはできません(EFSのサポートは例外)。N2W Backup and Recoveryは、実際のS3バケットにデータをアーカイブする機能があり、あらゆるS3階層にティアリングすることができます。また、N2W ZeroEBSオプションでは、AWSスナップショットを一切使用せずにバックアップをアーカイブすることも可能です。つまり、N2Wを使用することで、ストレージコストを最大98%削減できるということです。
その他の制限事項としては、
- お客様のリソースが保護されているか、されていないかがわからない
- 検索機能が限定的(リソースを検索するにはボリュームIDを知っておく必要がある
- シングル・ペイン・オブ・グラス(一元管理)機能なし – 複数のアカウントを管理することはできず、すべてのアカウントはアカウントごとに管理される。ただし、同じマスター支払者アカウント下にある場合は例外(これは、独立したユーザーやクライアントを管理するMSPにとって特に重要である
- 監査に特に重要となる、何か問題が発生した場合のレポート、日次サマリー、アラート機能なし
- 正確なバックアップ時間の知識不足(バックアップは一定の時間枠内で行われる) – N2Wでは60秒ごとにバックアップが可能ですが、AWSバックアップでは最小間隔として1時間枠しか選択できません
- 自動コールドティア/長期保存(EBSスナップショットをAmazon S3またはAmazon Glacierにコピーする)のサポートなし
- 各アカウントで100のバックアップ保管庫と100のバックアップ計画に制限されるサービス制限。
- バックアップジョブを実行する際、リソースごとに同時に実行できるジョブは1つだけ。
- 災害復旧訓練のサポートが限定的
- バックアップ自体を保存しないとバックアップログを保存できない
- リソース制御のサポートがないため、ユーザーはインスタンスの開始/停止をスケジュールしてリソースの使用を最適化/最小化できない
- ファイルまたはフォルダレベルの復旧のサポートがない
- タグ管理に大きな制限がある。通常、ほとんどの使用事例では十分な数であるにもかかわらず、リソースに50以上のタグを設定することができない。
- 他のアカウント/地域におけるAmazon S3バケットの複製に対応していない
- バックアップコピー操作の前にアプリケーションを静止状態にすることが非常に重要である場合が多いが、アプリケーションの一貫性に対応していない
- 24時間365日の無料サポートなし。通常、顧客は営業時間まで待たなければならず、チケットへの対応には数日かかることもあります。ダウンタイムの数分間が企業に数百万ドルの損失をもたらし、顧客の信頼を失い、完全に廃業する可能性さえあることを考えると、これは大きなリスクです。
きめ細かく信頼性の高いバックアップ管理を確保する方法は他にもあり、どのツールが自社のニーズを満たすかを確認するために、他のオプションを調査し、テストすることが重要です。
AWS コストの管理と削減のための7つのベストプラクティス
以下のベストプラクティスを導入することで、企業はAWSにおける最適な支出を確保することができます。
1. リソースの最適化と適正化
リソースの最適化と適正化には、AWSリソースの利用状況を分析し、不要な過剰プロビジョニングを排除しながら、ワークロード要件に確実に一致させることが含まれます。 このプロセスは、過剰なインスタンスやアイドル状態のインスタンスに対する無駄な支出を排除するのに役立ちます。 ライフサイクルポリシーを使用してストレージ階層間のデータ移行を自動化することで、継続的なコスト効率性を確保することができます。
Compute OptimizerやTrusted AdvisorなどのAWSサービスは、CPUやメモリの使用率などの指標を分析して実行可能な推奨事項を提供し、企業が最もコスト効率の高いインスタンスタイプやサイズを決定するのに役立ちます。ストレージの最適化については、企業はアクセス頻度の低いデータをAmazon S3 Infrequent AccessやGlacierなどのコスト効率の高いストレージソリューションに移行することができます。
2. コスト効率を高めるためのスケジュールと自動化
AWS Instance Schedulerのようなサービスを利用すると、管理者は夜間や週末、休日など、業務時間外にインスタンスを停止するルールを作成することができます。このアプローチは、24時間365日稼働させる必要のない開発、テスト、ステージング環境に特に有効です。
AWS Lambdaのような自動化ツールをCloudWatch Eventsと組み合わせることで、アイドル状態のインスタンスの終了や未使用のEBSボリュームの削除など、リソースのクリーンアップアクションをトリガーすることができます。需要が変動するワークロードの場合、オートスケーリング機能により、コストを削減しながらパフォーマンスを維持するために実行中のインスタンスの数を動的に調整することができます。
3. コスト割り当てタグの導入
コスト割り当てタグは、AWSの費用をビジネスユニット、チーム、プロジェクトに割り当て、追跡するために不可欠です。タグはリソースに付加されるメタデータラベルとして機能し、支出のきめ細かい分析を可能にします。例えば、「Environment: Production」や「Department: Finance」などのタグを使用することで、組織はコストのかかっている分野を特定し、是正措置を取ることができます。
AWSは、タグに基づいて支出をフィルタリングし分析するためのツールとして、Cost ExplorerやBudgetsなどを提供しています。組織全体で標準化されたタグ付けポリシーを徹底することで、クラウド利用の説明責任をより適切に果たすことができます。また、タグ付けはチャージバックやショーバックのプロセスを簡素化します。
4. 定期的なコストのモニタリングとガバナンス
AWSの費用を管理するには、定期的なコストの監視とガバナンスが不可欠です。AWS Cost Explorer、コストおよび使用状況レポート、AWS Budgetsは、費用の傾向を追跡し、異常を特定し、予算のしきい値を設定するためのツールを提供します。これらのツールは、費用がサービス、アカウント、および地域にどのように分散しているかを可視化します。
AWS Organizations を通じてサービスコントロールポリシー(SCP)を実装するなどのガバナンスの実践により、リソースが組織のポリシーに準拠してプロビジョニングされることを保証します。例えば、SCP を使用して、コストの高いインスタンスタイプの使用を制限したり、リソースのデプロイを特定のリージョンに限定することができます。ガバナンスポリシーと組み合わせた定期的なコストの見直しは、組織が非効率性を特定し、コスト削減策を実施するのに役立ちます。
5. コスト管理のためのコードとしてのインフラストラクチャの利用
AWS CloudFormation、AWS CDK、TerraformなどのInfrastructure as code(IaC)ツールを使用することで、企業はコードを使用してクラウドリソースを定義および管理することができます。 IaCにより、リソースのプロビジョニングが常に一貫性のある自動化された反復可能なものとなり、コスト超過につながる可能性のある手動エラーの発生を低減できます。
IaCテンプレートでは、リソースの制限を指定したり、インスタンスの種類を制限したり、スポットインスタンスのようなコスト効率の高い構成を自動的に有効にしたりすることで、コスト管理のベストプラクティスを組み込むことができます。さらに、IaCにより、組織はインフラストラクチャのバージョン管理が可能になり、変更の追跡や構成の最適化が容易になります。
6. FinOpsの実践の採用
FinOps(財務業務)は、財務上の説明責任と業務効率を組み合わせた、クラウドコストの管理における協調的なアプローチです。 財務、業務、エンジニアリングの各チーム間の部門横断的な協力を促し、ビジネス目標に沿いつつ、クラウド支出の最適化を図ります。 FinOpsの実践には、定期的なコスト分析、予測、最適化の取り組みが含まれます。
FinOpsの重要な要素のひとつはコストの透明性であり、これによりすべての利害関係者が詳細な支出データにアクセスできるようになります。 この共有された可視性は説明責任を促し、データに基づく意思決定を推進してコスト削減を実現します。さらに、FinOps を採用する組織は、自動化と分析を活用してコスト管理戦略を改善し、継続的な改善を優先しています。
7. バックアップ管理とストレージの最適化
バックアップ管理とストレージの最適化は、データ保護と災害復旧機能を損なうことなく AWS コストを最小限に抑えるために不可欠です。 組織はバックアップ戦略を評価し、冗長なバックアップを排除し、過剰な保持を回避し、コスト効率の高いストレージソリューションを活用すべきです。
Amazon S3 GlacierやGlacier Deep ArchiveなどのAWSサービスは、アクセス頻度の低いバックアップの長期保存に最適です。ライフサイクルポリシーを適用することで、企業はあらかじめ設定した期間が経過したデータを自動的に標準ストレージ層からより低コストのアーカイブストレージに移行することができます。例えば、Amazon S3で日次バックアップを30日間保持した後、Glacierに移行することで大幅なコスト削減を実現できます。
さらに、重複排除と圧縮技術によりバックアップのサイズを縮小し、ストレージコストを削減することができます。N2Wのようなツールは、バックアップポリシーの一元管理を簡素化し、コスト効率の高い手法の自動化と徹底を容易にします。バックアップ構成の定期的な監査により、組織の保持ポリシーへの準拠が保証され、不要なデータの蓄積を防止することができます。
N2W最適化クラウドバックアップによるAWSのコスト削減
AWSのコスト管理は、価格設定を理解するだけではなく、より賢明な意思決定を迅速に行うことが重要です。そこでN2WSがサポートします。
当社のクラウドネイティブなバックアップおよび災害復旧プラットフォームは、AWS環境を推測に頼らずに管理できるようにします。 古いスナップショットの自動アーカイブ、アイドルリソースのシャットダウン、利用率の低いボリュームの監視など、すべてを直感的な単一のダッシュボードから実行できます。 AWS、Azure、Wasabiのいずれにバックアップする場合でも、N2Wはデータの安全性、不変性、コスト最適化を保証します。
N2WSがコスト削減に役立つ主な方法:
- スマートなスナップショットアーカイブにより、ストレージ費用を最大92%削減。
- 自動化されたポリシーとクロスクラウドDRにより、毎週何時間も節約。
- エアギャップストレージと不変のスナップショットにより、バックアップのセキュリティを確保。
- 内蔵のコストエクスプローラーとアラートにより、支出を可視化。
クラウドのコスト削減は、保護の妥協を意味するものであってはなりません。
ExaGrid (4)
ExaGridのユニークなバリューポジション

段階型バックアップ・ストレージ:ExaGrid
ランディングゾーン
●最速バックアップ – インライン重複排除のボトルネックを回避
●最も高速なリストア – 重複排除されたデータのリハイドレーションが不要
リポジトリ層
●低コストの長期重複排除保持ストレージ
●業界をリードする 20:1 データ重複排除
– グローバル重複排除
●適応型重複排除
– バックアップウィンドウ中に重複排除と複製を実行
– 強力なオフサイトRTOとRPO
●ランサムウェアリカバリのための保持タイムロック
– ネットワークに面していない階層(階層化されたエアギャップ)
– 遅延削除
– 不変オブジェクト
スケールアウトアーキテクチャ
●1つのシステムで2.7PBのフルバックアップを毎時最大488TBでスケーリング
●バックアップデータが増大してもバックアップウィンドウは固定長
●スケールアップアーキテクチャのフォークリフトによるアップグレードを排除
●アプライアンスの組み合わせ – 年代やサイズを問わない
– 製品の陳腐化がない(メンテナンスとサポートのライフサイクル終了なし)
●7つの異なる容量のアプライアンスモデル
– データの成長に合わせて拡張可能
ディザスタリカバリサイトオプション
●DR用にオフサイトにレプリケート可能
●DRサイトの容量はプライマリの半分 – 非対称型
– 少ないアプライアンス
– 低コスト
●サイトAからB、BからAへのクロスレプリケーション
●ハブとスポークのトポロジーで最大16サイト
●マルチホップ – サイトAからBへ、サイトAからBへ、サイトAからCへ
●パブリッククラウドDRサイト – Amazon AWS & Azure
インストールが容易なアプライアンス・モデル
●リモート・インストールで数時間
冗長性
ホットスペアによるRAID6ディスク保護
– ホットスワップ対応
– 2台同時のドライブ故障にも対応
●冗長電源
– ホットスワップ対応
– どちらかの電源が故障してもシステムは稼動
統合されたシステム管理と包括的なセキュリティ
●システム内およびサイト間のすべてのアプライアンスに単一のユーザー・インターフェイスを提供
管理インターフェイスとバックアップターゲットのセキュリティのためのActive Directory
エンタープライズ管理アプリケーションとの統合のためのSNMPインターフェース
●ロールベースのアクセスコントロール
●ランサムウェアリカバリーのための保持タイムロック
– ネットワーク非接続層(階層型エアギャップ)
– 遅延削除
– 不変の重複排除オブジェクト
●二要素認証
●データ暗号化
●WAN経由でのレプリケーション時のデータ暗号化
●セキュリティチェックリストによりベストプラクティスの適用が容易
●データはチェックサムされ、データの完全性を保証する
●外部エンタープライズ管理アプリケーションへのシステムロギング
●内部自己記述データベース
バックアップ・アプリケーション・サポート
●25以上のバックアップアプリケーションとユーティリティ
– 異種バックアップアプリケーション環境をサポート
●Veeam
– SOBR – ジョブ管理の自動化
– Data Mover
– バックアップ・パフォーマンスの向上
– セキュリティの向上
– 合成フル・パフォーマンスの向上
– Veeam の重複排除を有効にし、ExaGrid でさらに重複排除が可能
●Oracle RMAN チャネルバックアップサポート
パフォーマンスを追求したExaGridアプライアンス

■ データ重複排除:
– ExaGridの革新的なデータ重複排除のアプローチは、受信したすべてのバックアップにゾーンレベルのデータ重複排除を使用することで、保存するデータ量を最小限に抑えることができます。
– ExaGridのゾーンレベル技術は、フルコピーを保存する代わりに、バックアップからバックアップへ粒度の細かいレベルで変更されたデータのみを保存します。ExaGridはゾーンスタンプと類似性検出を使用します。
– この独自のアプローチにより、必要なディスク容量を平均20:1、データの種類によっては10:1から最大50:1まで削減することができます。
– ExaGridは、Veeamのようなバックアップアプリケーションが重複排除をオンにしたまま、さらにExaGridがデータを重複排除し、ストレージ効率を向上させることができる唯一のベンダーです。
■ データバックアップのパフォーマンス:
– ExaGrid システムはバックアップと並行して、idl システムサイクルを使用して重複排除を実行します。
– 適応型重複排除(Adaptive Deduplication) と呼ばれるこのアプローチは、重複排除をバックアップパスから除外することで、バックアップの高速化とバックアップウィンドウの短縮を実現します。
– ExaGridはスケールアウトシステムの全ターゲット、全アプライアンスでグローバルにデータ重複排除をサポートします。
– ExaGridは適応型重複排除を採用し、インライン重複排除のパフォーマンス・ペナルティを回避します。
■ データリストアパフォーマンス:
– データリストアのパフォーマンス:最新のバックアップを重複排除された完全な状態で保持するため、高速なリストア、数秒から数分でのインスタントVMリカバリ、オフサイトテープコピーが可能です。
– リストアの90%以上、インスタントVMリカバリおよびテープコピーの100%は最新のバックアップから実行されます。このアプローチにより、重要なリストア中にデータを「水分補給」することで発生するオーバーヘッドを回避できます。
– ExaGridシステムからのリストア、リカバリ、コピーにかかる時間は、重複排除されたデータのみを保存するソリューションよりも桁違の高速が可能です。
ExaGridとDell EMC Data Domainとの比較
Dell EMC Data Domainを使用する利点
●重複排除により、長期保存に必要なディスク量が削減されるため、バックアップアプリケーションのディスクへの重複排除(つまり低コストのプライマリストレージディスク)と比較してコスト削減が可能
●重複排除により、オフサイトにレプリケートされるデータ量が削減され、WAN 帯域幅が節約される
Dell EMC Data Domainの短所
●インライン重複排除はバックアップを遅くする
●各リクエストごとにデータを再保存するため、リストアが大幅に遅くなる
●VMの起動には最大1時間、ファイルのリストアには最大20倍かかる
●パフォーマンスのスケーラビリティがないため(つまり、ディスクシェルフを追加するだけ)、データの増加に伴ってバックアップウィンドウが大きくなる
●フォークリフト・アップグレード(オーバーホール)を余儀なくされる – コントローラが限界に達した場合、システムを前進させ成長させるために多大なコストがかかる
●強制的な生産終了(EOL)ポリシーによる強制的な陳腐化、サポートの中止、またはサポート料金の大幅な増加
●ランサムウェアのリカバリに対応するために、デルから別途高価なソリューションを購入する必要がある。
●ランサムウェア・ソリューションはネットワーク上にあり(ネットワークに面している)、レプリケーション時にポートが開放されるため、ランサムウェア攻撃を受けやすい
●100TBを超えるとExaGridより高価 – Data Domainが適切なサイズであれば、2-3倍の価格に
● DELLは次回購入時に値上げすることが多い
Dell EMC Data Domainに対するExaGridの利点
●ExaGrid はディスクキャッシュの Landing Zone に直接書き込み(インライン重複排除なし)、Data Domain のインライン重複排除よりも 3 倍高速なディスク速度で書き込みを行う。
●ランディングゾーンのデータが重複排除されないため、リストアが20倍高速化。
●アプライアンスを追加することですべてのリソースをデータの増加に対応させるスケールアウトアーキテクチャにより、データが増加してもバックアップウィンドウの長さは一定に保たれる。
●ExaGridアーキテクチャ異なるサイズや世代のアプライアンスを混在が可能
●スケールアウトアーキテクチャにより、フォークリフト・アップグレードや製品の陳腐化がない
●リテンション・タイムロックによるシンプルなランサムウェアリカバリ、遅延削除とイミュータブルなデータオブジェクトによる非ネットワーク向けティア(ティアード・エアギャップ)を組込済
●ExaGridは100TB以上ならDataDomainよりさらに割安
NIS2 指令への準拠: ExaGridによる 3-2-1-1-0 バックアップ戦略の実装
NIS2(ネットワークおよび情報セキュリティ指令)は、EU(欧州連合)全域のサイバーセキュリティを強化するための法律です。EU加盟国は2024年10月17日までに国内法に反映し、施行する必要があります。
NIS2命令に準拠し、堅牢なデータ保護を確保するために、組織は3-2-1-1-0バックアップ戦略を採用する必要があります。この戦略には何が含まれ、エクサグリッドがコンプライアンスの達成にどのように役立つかを次に示します。
🔹 3-2-1-1-0 バックアップ戦略の理解
3:データのコピーを3つ保持します。これには、元のデータと少なくとも 2 つのバックアップが含まれます。
2:コピーを2種類のメディアに保存します。たとえば、ローカルストレージとクラウドストレージです。
1: バックアップ コピーを 1 つオフサイトに保管します。これにより、プライマリ ロケーションでの物理的な災害から保護されます。
1: 1 つのコピーが不変であり、変更または削除できないことを確認します。これにより、ランサムウェアやその他の悪意のある活動から保護されます。
0: 定期的なテストを通じてエラーがないことを確認します。これにより、バックアップが機能し、問題なく復元できるようになります。
🔹 ExaGridが 3-2-1-1-0 戦略をどのようにサポートするか
1.複数のバックアップコピー
ExaGridは、さまざまなバックアップ アプリケーションと統合することで、データの複数のコピーの維持を容易にし、コピーをアプライアンスのさまざまなゾーンに保存し、そのうちの 1 つはネットワークに接続されていません。
2. 多様な記憶媒体
ExaGrid システムは、さまざまな種類のストレージ メディアと連携して動作し、ディスクベースのストレージとクラウドベースのソリューションの両方をサポートしているため、さまざまなメディア間でデータの冗長性を確保できます。
3. オフサイトバックアップ機能
ExaGridのレプリケーション機能により、バックアップ データをオフサイトの場所に効率的かつ安全にレプリケーションできるため、1 つのコピーが常にリモートに格納されます。このオフサイト・コピーは、サイト固有の災害から保護します。
4.不変(イミュータブル)バックアップ
ExaGridのランサムウェア リカバリ用の保持タイムロックは、データの 1 つのコピーが不変であることを保証します。つまり、データを変更したり削除したりすることはできません。この機能は、ランサムウェアから防御し、データの整合性を確保するために重要です。
5. 定期的なテストによるエラーゼロ
ExaGrid システムは、定期的なバックアップの検証とテストをサポートしています。自動化された整合性チェックと定期的な復元テストにより、バックアップにエラーがなく、回復可能であり、「エラーゼロ」の要件に準拠していることが確認されます。
💡 NIS2 コンプライアンスにエクサグリッドを選ぶ理由
3-2-1-1-0バックアップ戦略の実装は、NIS2指令に準拠し、包括的なデータ保護を確保するために不可欠です。ExaGridの独自のアーキテクチャと高度な機能により、これらの要件を満たすのに役立つ理想的なソリューションとなっています。エクサグリッドを使用すると、バックアップ戦略が堅牢で、スケーラブルで、安全であることを確認できます。
👉 ExaGridが 3-2-1-1-0 の原則を効果的に実装するのにどのように役立つかについて話し合いたい場合は、クライムまでご連絡してください
クラウドバックアップの社会的通念 (10)
クラウドバックアップの社会的通念#10: ほとんどバックアップとアーカイブのツールは、バックアップとアーカイブのみのツールだ
誤り:ほとんどのソリューションでできることは限られていますが、バックアップやアーカイブ以上の機能を持つツールもあります。次のような高度な機能を提供するソリューションもあります:
●eDiscoveryとジャーナリングオプション
●高速検索機能
●保存およびアーカイブされたデータからのビジネス洞察と分析
クラウドバックアップについて迷いがありましたらクライムまでお問合せください。
クラウドバックアップの社会的通念#9: バックアップとアーカイブ・ソリューションは遅い
誤り:それは非効率な場合だけです。洗練されたバックアップ・アーカイブソリューションは、最近更新または追加されたファイルを優先的にバックアップし、プロセス全体を高速化します。これにより、プロセスが迅速化され、データが完全に安全にバックアップされます。
クラウドバックアップの社会的通念#7:クラウド・バックアップとアーカイブのソリューションはすべて同だ
誤り:むしろ、下記のこれらが真実です:
市場に出回っているソリューションの多くは、UXデザインが貧弱で、使い勝手が悪い。
これらのソリューションの多くは、エージェントとしてダウンロードしなければ動作しない。
バックアップとアーカイブは別物であり、ほとんどのベンダーは一緒に提供していない。
多くのソリューションはモジュールとして販売されており、非常にコストがかかる。
バックアップとアーカイブのソリューションのうち、保存やアーカイブされたデータに基づく洞察や分析を提供するものはごく少数である。
さらに、ほとんどのソリューションは、カレンダーやタスクなど、すべてをバックアップしているわけではない。
クラウドバックアップの社会的通念#6:バックアップとアーカイブは大げさであり、不可欠ではない
誤り:データ漏洩により、企業(北米) は平均461万ドルを失っている。包括的なバックアップ・アーカイビング・ソリューションにかかる月々数ドルと比較すれば、バックアップ・アーカイビングがいかに不可欠であるかがわかるだろう。多くの企業(まだ存続している企業もあれば、廃業した企業もある)が、このことを痛感している。
クラウドバックアップの社会的通念#5: 必要なのは規制対象企業のみ
誤り:規制対象外の企業は、データのバックアップとアーカイブに価値を見出しています。以下はその使用例です:
●監査では、少なくとも 6 年前にさかのぼる完全かつ正確なデータ記録の提出が求められることが多い (IRS、SEC など)。
●訴訟や規制当局の調査により、Microsoft 365/Google Workspaceのデータを改ざんや削除できないように法的保留が必要になる場合がある。
●アーカイブシステムにある高速ユニバーサル検索ツールを使用すると、ワンクリックでソリューション全体の検索クエリを高速化できます。
クラウドバックアップの社会的通念#4:バックアップ&アーカイブ・ソリューションは、データ・セキュリティを確保するために使用するには難しすぎる。
誤り:この考え方は、特定のバックアップシステム/ソリューションが、ソフトウェアを動作させる前提として、管理者がエージェントをダウンロードしてインストールする必要があることに起因しています。しかし、あるプロバイダーはより簡単でユーザーフレンドリーなシステムを持っています。これらのプロバイダーは、顧客が独自のバックアップ自動化システムを素早くセットアップすることを可能にし、ワンクリック復元オプションと相まって、バックアップとアーカイブを可能な限り手間のかからないものにします。
クラウドバックアップの社会的通念#8:データを取り戻すにはお金が必要
誤り:データを人質に取らないソリューションもあります。重要なアドバイス:適切なソリューションを選択する際には、他のソリューションやサービスに移行する際にデータを取り戻すための費用が発生するかどうかをプロバイダーに確認してください。
クラウドバックアップの社会的通念#2: クラウド・バックアップとアーカイブは高すぎる
誤り: 適切なソリューションであれば、1シートあたり月額数ドルで無停止のデータ保護が可能です。データ漏洩による企業の損害は平均461万ドル(前年比10%増)であり、データ・セキュリティを確保するために必要な費用を大幅に上回っています。
クラウドバックアップの社会的通念#3: クラウドバックアップは安全ではない
誤り:このような考えは、いくつかのソリューションの可視性の欠如によって助長されている。ローカルサーバーにデータを保存するのとは異なり、ローカルレベルで障害が発生しても、クラウドベースのデータで問題が発生することはありません。軍用レベルの暗号化と、大規模で安全なデータ保存のために特別に設計されたサーバーを提供するバックアップおよびアーカイブソリューションを見つけましょう。
クラウドバックアップの社会的通念#1: Google Workspace / Microsoft 365はすでにバックアップとアーカイブを行っています。
誤り:Microsoft 365は、削除したメールとファイルをごみ箱に最大90日間保存するだけです。Google Workspaceは、エンドユーザーのDriveファイルとメールを30日後にゴミ箱とスパムフォルダに削除します。どちらのソリューション/プロバイダも、ユーザーエラー、データ破損、ランサムウェアの脅威が発生した場合のデータの完全な復元を保証するものではありません。マイクロソフトでは、サードパーティによるデータのバックアップをとっておくことを推奨しています(マイクロソフト サービス契約セクション6b)。
N2WS (5)
N2WSバックアップサーバを保護するための重要なセキュリティのヒント
- 重要なバックアップインフラを隔離する: 厳重に制御されたイングレスとイグレスのルールを持つ専用VPCにN2WSを導入することを検討してください。これにより、バックアップ環境を本番トラフィックから隔離し、脅威や不正アクセスにさらされる機会を減らすことができます。
- スナップショット管理にライフサイクルポリシーを使用する: EBSスナップショットとS3オブジェクトに自動化されたライフサイクルポリシーを導入し、データをより低温のストレージ層に移行したり、古いスナップショットを削除したりします。これにより、コンプライアンスを維持しながらストレージコストを効果的に管理できます。
- 地域ごとにIAMロールをセグメント化: N2WS用に地域別のIAMロールを作成し、潜在的なセキュリティ侵害の影響範囲を最小限に抑えます。このセグメンテーションにより、特定の地域内での影響を抑制し、全体的なセキュリティを強化します。
- 最小権限の原則を委任ユーザに適用する: 委任ユーザを作成する際には、必要最小限の権限のみを付与する最小権限の原則を適用する。これにより、代理アカウントが漏洩した場合のリスクを軽減できます。
- ボリュームの暗号化を実施する: ボリュームを常に暗号化することがベストプラクティスであり、ディザスタリカバリ(DR)時の制限が少ないため、AWSが管理するKMSではなく、顧客が管理するKMSを使用することを推奨します。
ユーザ・クラウドバックアップのランサムウェア対策ヒント
- バックアップの暗号化を維持 データ保護を確実にし、ランサムウェアやサイバーセキュリティの問題によるリスクを軽減するために、暗号化されたリソースのクロスリージョンバックアップを作成します。
- バックアップネットワークをセグメント化する: バックアップシステムをメインネットワークから分離します。専用のVLANを使用し、バックアップが運用システムと同じネットワークセグメントからアクセスできないように。
- バックアップの完全性を定期的に検証する: バックアップの定期的なチェックと検証を行い、データが破損していないこと、必要なときに正常にリストアできることを確認します。
- ローリングバックアップ戦略を採用する: ローリングバックアップスケジュールを実施し、複数のバージョンのデータを異なる時間枠で保持する。これにより、ランサムウェア感染前の時点に復元することができます。
- エンドポイントプロテクションを使用してバックアップエージェントを保護する: バックアップ・エージェントを実行するすべてのデバイスとサーバーが、ランサムウェアのエントリ・ポイントにならないように、堅牢なエンドポイント保護機能を備えていることを確認します。
ディザスタリカバリー vs. BCPのヒント
- フェイルオーバープロセスの自動化 重要なITシステムのフェイルオーバー・メカニズムを自動化します。フェイルオーバーを自動化することで、リカバリ時間を短縮し、手動による介入を最小限に抑えながら、重要なサービスの運用を維持できます。N2WSのリカバリシナリオ機能を使用すると、フェイルオーバーをシームレスにオーケストレーションできるため、障害が発生した場合でもシステムを迅速にオンラインに戻すことができます。
- 資産インベントリの定期的な更新 すべてのIT資産とその構成の最新のインベントリを維持します。これにより、復旧計画が正確なものとなり、復旧作業中に重要なコンポーネントがすべて計上されるようになります。
- モジュール式の復旧計画を作成する: 障害の具体的な性質に基づいて、個別に起動できるモジュール式のセグメントで復旧計画を策定します。これにより、的を絞った効率的な復旧作業が可能になります。
- 高可用性システムに投資する: 重要なアプリケーションの継続的なアップタイムを保証する高可用性ソリューションを導入する。これにより、ダウンタイムを最小限に抑え、部分的なシステム障害が発生した場合でもサービスの継続性を維持します。
- DR訓練とテストの実施 自動化された災害復旧(DR)訓練を定期的に実施して、復旧計画をテストし、意図したとおりに機能することを確認します。N2WSを使用すると、このようなDR訓練をスケジュールして自動化できるため、復旧プロセスが効果的で、チームが実際のインシデントに備えていることを確認できます。
AWS環境の災害対策(DR)計画を立てる際に考慮すべきヒント
●DR運用にIAMポリシーを組み込む:DR運用や機密性の高いリカバリリソースへのアクセスを制限する、IAMの専門ポリシーを作成します。これによりセキュリティのレイヤーが追加され、権限のある担当者だけがフェイルオーバーを開始したり、重要なデータにアクセスしたりできるようになります。
●長期データ保持にはS3 Glacier Deep Archiveを利用:アクセス頻度の低いバックアップデータをS3 Glacier Deep Archiveに保存することで、ストレージコストを大幅に削減しながら、必要な時に数時間以内にデータを取得できる能力を維持できます。これは、DR計画の一環として重要なデータを長期間保持するのに最適です。
●重要なワークロードに対してマルチリージョンレプリケーションを実装する:Amazon S3 Cross-Region ReplicationやDynamoDB Global Tablesなどのサービスを使用して、最も重要なワークロードに対してマルチリージョンレプリケーションを設定します。これにより、AWSのリージョン全体が利用できなくなった場合でも、データとアプリケーションは利用可能な状態を維持できます。
●N2WSを活用したDRフェイルオーバーの自動化:N2WS Backup & Recoveryを使用して、新しいインスタンスの起動、DNSレコードの更新、ネットワーク設定の再構成などのフェイルオーバープロセスを自動化します。N2WSは、災害復旧の管理に合理化された信頼性の高いアプローチを提供し、手動介入を減らし、迅速な復旧を実現します。
●AWS Outposts を活用したハイブリッド DR ソリューションの検討:オンプレミスインフラストラクチャを大量に保有する組織では、AWS Outposts を使用して AWS サービスをデータセンターに拡張することを検討してください。このハイブリッドアプローチにより、オンプレミスのデータ主権とコンプライアンスを維持しながら、AWS の DR 機能を活用することができます。
N2Wの最適化クラウドバックアップでAWSのコスト削減
AWSのコスト管理は、価格設定を理解するだけではありません。より賢明な意思決定を迅速に行うことです。そこでN2Wがサポートします。
当社のクラウドネイティブなバックアップおよび災害復旧プラットフォームは、AWS環境を推測に頼らずに管理できるようにします。 古いスナップショットの自動アーカイブ、アイドルリソースのシャットダウン、利用率の低いボリュームの監視など、すべてを直感的なダッシュボードから実行できます。 AWS、Azure、Wasabiのいずれにバックアップする場合でも、N2Wはデータの安全性、不変性、コスト最適化を保証します。
N2Wがコスト削減に役立つ主な方法:
- スマートなスナップショットアーカイブにより、ストレージ費用を最大92%削減
- 自動化されたポリシーとクロスクラウドDRにより、毎週何時間も節約
- エアギャップストレージと不変のスナップショットにより、バックアップを安全に維持
- 内蔵のコストエクスプローラーとアラートにより、支出を可視化
クラウドのコスト削減は、保護の妥協を意味するものであってはなりません。
データベース (3)
データベース・バックアップへのヒント
●階層型ストレージのアプローチ:迅速な復元のために、最近のバックアップは高速ストレージ(SSDなど)に保存し、古いバックアップは安価で低速のストレージ(クラウドコールドストレージなど)に保存します。これにより、パフォーマンスとコストのバランスを取ることができます。
●きめ細かなバックアップウィンドウのスケジュール:高度な監視ツールを使用して、システム負荷とユーザーのトラフィックパターンを分析します。特に24時間365日稼働の業務では、パフォーマンスへの影響を最小限に抑えるため、最も業務が少ない時間帯にバックアップをスケジュールします。
●バックアップ・チェーニングの使用:増分バックアップを定期的にフル・バックアップにマージする「バックアップ・チェーニング」を導入します。これにより、リストアの複雑さが軽減され、増分バックアップ・プロセスの効率が向上します。
●クロス・データベースの整合性チェック:相互に作用する複数のデータベース(マイクロサービス・アーキテクチャなど)を扱う場合は、リストア時に依存関係にあるデータベース間の整合性を確保するために、システム全体のバックアップの整合性を定期的にチェックします。
●バックアップのメタデータ:特に複雑な環境では、データベースのスキーマと構成の詳細を常にバックアップします。バックアップに重要なメタデータが欠けていると、完全に機能する状態へのリストアに時間がかかったり、不完全な結果になることがあります。
Database Performance Analyzer (DPA): 2024.4
Database Performance Analyzer (DPA) 2024.4 ソフトウェアの提供のお知らせです。
- 柔軟なデータベースライセンス: セルフホスト型データベース製品に対するライセンスの付与方法を変更しました。 セルフホスト型ライセンスを1つ取得するだけで、ニーズに合わせてDPAを使用できます。 Azure SQL Databaseを監視している場合は、DBaaS環境専用の分割コストライセンスも導入しました。これにより、クラウドデータベースを簡単にコスト効率よく組み込むことができます。詳細については、担当のアカウントマネージャーまでお問い合わせください。
- MySQL/Percona MySQLワークロード分析は、SQL Server、Oracle、PostgreSQL(実行計画収集)用の強力なDPA機能、インデックスアドバイザ、テーブルチューニングアドバイザなど、人気の高い機能が含まれています。
- また、MySQL に関するセキュリティ対策も改善し、caching_sha2_password 認証をサポートするようになりました。チューニングアドバイザと併用することで、MySQL ユーザーの大幅な増加が見込まれます。
- セキュリティを念頭に置き、お客様からご要望のあった Windows のグループ管理サービスアカウント(gMSA)認証もサポートするようになりました。
- Oracle 関連では、Oracle のマルチテナント・アーキテクチャ上のターゲットとしてCDB をサポートするようになりました。これにより、より広範なアラート機能と可視性機能を備えた PDB を活用するインスタンスの全体像が完成しました。
Database Performance Analyzer (DPA):2024.3
Database Performance Analyzer (DPA)と の最新統合機能として、ServiceNow®とPagerDuty®を発表できることを嬉しく思います。この機能強化は、多くの要望に応えるもので、アラート通知を拡張し、IT運用をこれまで以上に効率的かつ迅速に行うことを可能にします。
DPAは、ServiceNow®とPagerDuty®に直接アラートを送信できるようになり、より効率的なワークフローが可能になりました。これにより、インシデントとイベントをより効果的に管理できるようになり、ITイベントの適切な通知、追跡、論理的なワークフローを確保できます。
動作方法
この統合により、SolarWinds Platform Connect 経由で SQL Sentry と DPA が貴社の ServiceNow® および PagerDuty® アカウントに接続されます。 設定が完了すると、DPA によって生成されたアラートは自動的にこれらのチャネルに送信され、IT チームはリアルタイム通知を受け取ることができ、問題が発生するとすぐに適切な優先順位付けと対処が行われるようになります。
統合のメリット
対応の迅速化:ServiceNow®とPagerDuty®にリアルタイムのアラートが送信されるため、チームはインシデントに迅速に対応でき、ダウンタイムを削減し、システムの信頼性を向上させることができます。
●インシデント管理の一元化:この統合により、すべてのITイベントを一元的に管理できるようになります。一元化によりワークフローが簡素化され、問題の追跡と解決が容易になります。
●業務の合理化:新しい統合により、適切なタイミングで適切な担当者にアラートが送信されることが保証されます。これにより、ITイベントやインシデントの優先順位付けと管理がより効果的に行われ、リソースが最適に利用されることが保証されます。
●すべてのサブスクリプション顧客が利用可能
この機能は、追加費用なしで、すべてのサブスクリプション顧客が利用可能です。これは、お客様のITインフラストラクチャを効率的に管理するための最高のツールと統合を提供するという、当社の継続的な取り組みの一環です。
Zerto (3)
貴社の災害復旧はスピードについていけますか? 第1部 – スピードの必要性
誰もが経験したことがあるでしょう。ビデオのクライマックスで恐ろしいスピンホイールが回り続けるのを眺めたり、フライトの遅延が画面に表示され、空港のゲートで足止めされたり、最悪の場合、緊急時にシステムがダウンし、最も必要な時に利用できなくなることがあります。このような瞬間は単なる不都合というだけでなく、最も洗練されたシステムであってもダウンタイムに対しては脆弱であることを思い知らされる瞬間でもあります。今日のハイリスクなデジタル経済において、ダウンタイムは世界中の企業にとっての弱点です。
ランサムウェア攻撃であれ、自然災害であれ、予期せぬシステム障害であれ、災害が発生すると、秒単位で時間が経過していきます。 1秒でも損失が増えれば、それだけ収益のリスクが高まり、信頼が損なわれ、顧客が他社に流れる可能性も高まります。 問題は、災害復旧(DR)計画が試されるかどうかではなく、ビジネスを存続させるのに十分な速さと信頼性があるかどうかです。
現代の復旧の現実:スピードと信頼性のどちらを優先するか?
競合他社の中には、DRにおいてはスピードだけでは危険であると主張する企業もあります。彼らは「あまりにも急いで、あまりにも速く復旧しようとすると、状況を悪化させる可能性がある」と主張しています。この考え方は誤った選択肢を示唆しており、復旧に関してはスピードと信頼性のどちらかを選択しなければならないと示唆しています。
Zertoでは、この考え方を根本的に否定しています。RPOとRTOはオプションではなく、生命線です。迅速な対応とリカバリの整合性への信頼のどちらかを選択する必要はありません。実際、真のレジリエンスには両方が必要です。その理由は次の通りです。
- ランサムウェアは待ってくれません。攻撃はエスカレートし、バックアップを標的とし、急速に広がっています。リカバリが遅い、または不完全であると、敵対者に混乱を引き起こす時間を与えることになります。
- ためらいは高くつく:システムが停止する時間が1分増えるごとに、金銭的および評判上のダメージも増大します。復旧が遅いと、ただ痛手を被るだけでなく、事業継続と廃業の分かれ目になることもあります。
- 信頼は準備から始まる:復旧とは、単にデータを復元することではなく、信頼を回復することです。DRソリューションは、結果をあれこれ考えずに迅速に復旧できる自信を与えてくれるものでなければなりません。
妥協のない復旧スピード
Zertoが他社と一線を画しているのは、信頼できる高速リカバリを実現する能力です。 当社は、スピードとデータ整合性のトレードオフを求めません。 Zertoの継続的データ保護(CDP)により、RPOはわずか数秒に短縮され、RTOは数分単位で達成できます。
競合他社は、定期的なスナップショットからのリカバリや、面倒な手動フェールオーバープロセスに頼っているかもしれませんが、これらのアプローチにはエラーが起こる余地が大きすぎます。 データにギャップが生じたり、数時間前の情報を復旧しなければならなかったり、プレッシャーのかかる状況下でシステムの検証に奔走したりすることになります。 Zertoは、以下の方法でこれらの脆弱性を低減します。
- リカバリギャップの排除:CDPはあらゆる変更をリアルタイムで取得し、データの最新性と安全性を確保します。
- フェイルオーバーの簡素化:自動化されたプロセスにより複雑性を軽減し、ビジネス復旧に集中できます。
- リカバリ期間の短縮:ランサムウェア、人為的エラー、ハードウェア障害など、どのような問題が発生しても、Zertoはシームレスなリカバリを実現し、危機が発生したことさえ忘れてしまうほどです。
スピードと信頼:事例
例えば、グローバルな消費財メーカーである当社のエンタープライズ顧客がランサムウェア攻撃を受けた際、数分以内に業務を復旧・復元することができました。データギャップも発生せず、躊躇することもなく、何よりも顧客の信頼を損なうこともありませんでした。競合他社の場合、手動による遅い復旧プロセスや不完全なバックアップにより、数時間、あるいは数日間もオフライン状態になる可能性がありました。
何が危機に瀕しているのでしょうか?
あらゆる組織がこの現実に直面しています。次に災害が起こるのは「起こるか起こらないか」の問題ではなく、「いつ起こるか」の問題なのです。そして、災害が起こった際には、貴社のDR戦略が競争力を維持できるかどうかを決定します。DRが追いつかない場合、貴社のシステムが回復に苦戦している間に競合他社が追い越してしまい、すでに最下位に甘んじていることになります。
そこで、自問してみてください。
- 貴社のリカバリソリューションは、最新の脅威のスピードに追いつくことができますか?
- どのような状況であっても、自信を持ってデータと業務を回復する準備ができていますか?
- スピードと信頼性を両立するパートナーがいますか?
結論:今こそ加速するとき
Zertoなら、単にリカバリするだけでなく、これまで以上に迅速かつスマートに、そして高い信頼性を実現できます。 遅い、時代遅れの手動プロセスに足止めされる必要はありません。 スピードが足かせになるのではなく、競争優位性となる今日のデジタル世界に適したリカバリを採用する時が来たのです。
貴社の災害復旧は間に合いますか? 第2部 – 回復における真の回復力を実現
最初の記事「災害復旧はスピードについていけるか? 第1部 – スピードの必要性」では、災害復旧(DR)におけるスピードの重要な役割について考察しました。 スピードが重要なのは間違いありませんが、それはソリューションの一部にすぎません。 本当の回復力とは、シームレスで包括的な復旧を確実にするために、スピードを超えたものです。
スピードは方程式の一部に過ぎない:真のレジリエンスを実現する復旧
災害が発生した際には、1秒1秒が重要となります。スピードは不可欠ですが、それだけでは十分ではありません。真のレジリエンス、つまりビジネス、評判、将来を守るためには、迅速な復旧だけでは不十分であり、どのような危機的状況においても、正確性、信頼性、俊敏性を備えた復旧能力が求められます。
多くの組織がここでつまずきます。 彼らは、RPOやRTOだけに注目し、スピードはパズルのほんの一部に過ぎないことに気づいていません。 回復のスピードだけでなく、「安全かつ柔軟に回復できるか」という点も重要です。 なぜなら、推測や見込みで回復作業を行うことは、回復とは言えないからです。
回復力の方程式
回復力とは、妥協することなくビジネスを継続できる形で回復する能力です。これを3つの要素からなる三角形として考えてみましょう。
- スピード: もちろん、これは非常に重要です。復旧に時間がかかれば、金銭的な損失、評判の低下、顧客の不満につながる可能性があります。
- 完全性: 復旧したデータが破損していたり、不完全であったり、信頼できないものでは、迅速な復旧も意味がありません。
- 柔軟性: デジタル環境は常に変化しており、復旧ソリューションは、新たな課題、環境、脅威に迅速に対応できなければなりません。
スピードだけではスタートラインに立つことができても、回復力があればレースを続けることができます。
リカバリギャップの危険性
多くのDRソリューションはスピードを約束しますが、データの整合性という重要なニーズには対応していません。たとえば、スナップショットベースのリカバリでは、災害発生前の特定の時点、数時間、あるいは数日前の状態にシステムを復元できるかもしれません。しかし、その欠落した数時間内に作成されたデータはどうなるのでしょうか?その過程で失われたトランザクション、顧客とのコミュニケーション、業務上の洞察はどうなるのでしょうか?
これは単なる技術的な問題ではなく、ビジネスリスクです。
- 顧客の信頼を損なう: 復旧ソリューションが十分でなかったために、顧客のデータが失われたと伝えることを想像してみてください。
- コンプライアンス違反による罰金リスクにさらされる: 規制当局は、データの紛失や誤処理を「復旧ギャップ」という言い訳として認めません。
- ビジネスがさらなる攻撃にさらされる: 復旧が不完全だと、敵対者にバックドアを開いたままにしてしまうことになります。
真のレジリエンスとは、すべてのデータ・バイトが記録され、すべてのシステムが稼働していることを確認しながら、自信を持って復旧できることを意味します。
Zertoによるレジリエンスの実現
Zertoでは、スピードは方程式の一部に過ぎないことを理解しています。そのため、当社のソリューションは以下を提供するように設計されています。
- 継続的なデータ保護:リアルタイム・レプリケーションにより、リカバリ・ギャップを削減し、データの整合性を確保します。
- 自動化されたオーケストレーション:複雑な処理を代行するツールにより、リカバリを簡素化します。
- クラウドの俊敏性:クラウドプロバイダーへの復旧、クラウドプロバイダーからの復旧、クラウドプロバイダー間の復旧を、同じレベルのスピードと信頼性で実現します。
- プロアクティブなテスト:自動化およびオーケストレーションされた無停止フェールオーバーテストにより、最も必要な時に、お客様の復旧計画が完璧に機能することを検証します。
スピード、整合性、柔軟性のいずれかを選択しなければならない競合他社とは異なり、Zertoはすべてを提供します。これにより、迅速かつ包括的な復旧が可能になります。
レジリエンスの実践
当社のお客様であるグローバルな繊維技術企業は、データと業務を脅かすランサムウェア攻撃に直面しました。Zertoを使用することで、データ損失はわずか10秒で、数分でシステムを復元することができました。Zertoを使用する前の攻撃では、12時間分のデータを失い、復旧に2週間を要しました。
不完全な復旧の真のコスト
では、なぜ組織は完全なレジリエンス(スピード、完全性、柔軟性)のソリューションを選ばないのでしょうか? 時代遅れの復旧方法に頼っている組織は、DRソリューションを最新化する初期費用に重点を置いていることが多いのです。 しかし、最新化しないことによるコストはどれほどでしょうか?
- 収益の損失:ダウンタイムが1分増えるごとに、収益が減少します。
- 評判の低下:危機的状況下で業務を継続できない企業に対して、顧客は辛抱強くありません。
- 規制による罰則:コンプライアンス違反は、特にヘルスケアや金融業界などでは、多額の罰金につながる可能性があります。
将来のためのレジリエンスの構築
最新型のDRは、単にスピードだけを追求するものではありません。 あらゆる危機に耐え、自信を持って回復し、次に何が起ころうとも適応できるビジネスを確保することが目的です。 Zertoを使用すれば、高速なリカバリが実現するだけでなく、包括的なリカバリが実現します。
そこで、自問してみてください。
- 貴社のリカバリソリューションは、回復力(スピード、整合性、柔軟性)を備えていますか?
- 今日の複雑なハイブリッド環境に適応できますか?
- 災害が発生した際に、生き残るだけでなく、成功を収める準備はできていますか?
Zertoなら、その答えはイエスです。
貴社の災害復旧は対応できますか? 第3部 – 柔軟性による回復力の向上
災害復旧において、回復力は究極の目標です。 私たちは、復旧においてスピードと整合性が果たす重要な役割について検討してきましたが、さらに重要な要素がもう一つあります。それは「柔軟性」です。
真の回復力とは、復旧のスピードや正確さだけに依存するものではありません。あらゆる状況、あらゆる環境、あらゆる課題に適応する能力に依存するものです。今日のハイブリッドかつマルチクラウドの世界では、柔軟性こそが俊敏性を引き出し、ビジネスの継続性を確保するための鍵となります。
見落とされがちなレジリエンスの要素
適応能力はレジリエンスの特長です。 企業がハイブリッドおよびマルチクラウド環境に移行するにつれ、硬直的なリカバリソリューションは足かせとなります。 現代のディザスタリカバリには、以下の機能が必要です。
- クラウドの自由: 機敏性を維持するには、複雑性を増すことなく、パブリック、プライベート、ハイブリッドクラウド間でリカバリできることが必要です。
- スケーラビリティ: ビジネスとともに成長し、進化する需要に対応するソリューション。
- 相互運用性:既存のツールやシステムとシームレスに統合し、危機発生時の混乱を最小限に抑えます。
Zerto は、これらの分野において比類ない柔軟性を提供し、お客様の復旧戦略が、必要な場所で、必要な時に、必要な方法で機能することを保証します。
柔軟性がレジリエンスの要である理由
現代のIT環境は、決して静的なものではありません。企業はオンプレミスのインフラストラクチャ、パブリッククラウド、プライベートクラウド、そしてますます増え続けるハイブリッド環境で業務を行っています。これに加えて、進化する脅威の状況、コンプライアンスの要求、そしてかつてないほど迅速なイノベーションのプレッシャーがあります。柔軟性のない災害復旧(DR)戦略では、これらの課題に対応することはできません。
柔軟性のないことによるリスク:
- ベンダーロックイン:単一のプラットフォームに縛られることで、危機的状況下での対応能力が制限されます。
- 移行中のダウンタイム:ワークロードの移動やインフラの近代化が、時間のかかる苦痛なプロセスになります。
- 機会損失:迅速な適応ができないと、適応できる競合他社に遅れをとることになります。
柔軟性の実例
柔軟性は流行語ではなく、測定可能な利点です。災害復旧戦略に柔軟性があれば、以下のような復旧が可能になります。
- どこでも
- オンプレミス、クラウド、ハイブリッドのどの環境であっても、柔軟性があれば、ビジネスにとって最も理にかなった場所でリカバリを行う自由が得られます。Zerto を使用すれば、インフラストラクチャの制約やベンダーの要件に縛られることはありません。
- いつでも
- 災害は都合の良い時を待ってはくれません。リカバリも同様です。柔軟性があれば、計画的な移行時でも、計画外の停止時でも、必要な時にリカバリを行う自信が得られます。
- 妥協なし
- 柔軟性により、データはそのまま維持され、シームレスなリカバリが実現し、業務が中断することなく継続されます。 障壁を取り除き、チームが迅速に行動できるようにすることです。
選択の自由
Zertoでは、ソリューションの核となる部分に柔軟性を組み込んでいます。 この適応性は、IT環境が進化する中で特に価値があります。BroadcomによるVMwareの買収など、業界の大きな変化により、企業は新しい選択肢を模索する必要に迫られています。
価格、パッケージング、サポートに関する不確実性と格闘しているVMwareのお客様に対して、Zertoはシンプルかつ強力な代替案を提供します。当社のソリューションは、業界をリードするRTO(目標復旧時間)とRPO(目標復旧時点)を維持しながら、お客様が選択したハイパーバイザーやクラウド環境へのシームレスな移行をサポートします。VMwareからの完全な移行であれ、マルチクラウド戦略のテストであれ、Zertoは移行に伴うダウンタイムのリスクを低減しながら、移行を可能にします。Zertoは、次のような機能を提供し、企業の復旧を支援します。
- プラットフォームに依存しない:AWS、Azure、プライベートデータセンターなど、クラウドプロバイダーやオンプレミスのインフラストラクチャへの復旧、またはそれら間の復旧、あるいはそれら内での復旧が可能です。
- シームレスなワークロードのモビリティ:災害復旧を緊急時だけでなく、計画的な移行、クラウドの導入、さらにはデータセンターの統合にも利用でき、ダウンタイムを最小限に抑えることができます。
- 中断のないテスト: 回復テストを必要なときにいつでも実行し、日常業務に影響を与えることなく、コンプライアンスと準備態勢を確保します。
- 継続的なデータ保護: 環境に関わらず、RPOとRTOを他に類を見ないレベルで確保します。
現実世界における柔軟性
例えば、多国籍繊維企業であるTenCate Protective Fabrics社では、クラウド戦略の変更の最中にあり、AWSからMicrosoft Azureへの移行が必要でした。Zertoを活用することで、同社はワークロードを移行し、地域製造拠点から水平型グローバルモデルにデータを移行しながら、6秒のRPOを実現することができました。
選択肢による回復力
柔軟性とは、今日の課題に対応するだけでなく、明日の未知の課題に備えることでもあります。Zerto を利用すれば、硬直したアーキテクチャやベンダーロックイン、時代遅れのソリューションに縛られることはありません。むしろ、リカバリ方法を選択する自由が得られ、ビジネスに適応する俊敏性と成功への自信が得られます。
自問してみてください。
- 現在の復旧戦略は変化のペースに追いついていますか?
- ダウンタイムやリスクなしに新しい環境やプラットフォームに切り替えることができますか?
- 復旧方法を選択する自由がありますか?それとも、特定の運用方法に縛られていますか?
Zertoなら、選択の自由が手に入ります。
AWS (5)
AWS Backupの制限について
AWS Backupは基本的なバックアップの自動化に重点を置いており、災害復旧、粒度の細かい復旧、復旧のオーケストレーションやドリルなどの組み込み機能が欠けているなど、いくつかの制限があります。しかし、よりシンプルなバックアップのニーズを持つ組織にとっては、便利なソリューションとなるでしょう。より高度な要件には、N2Wのようなサードパーティのツールが、より費用対効果や効率性の面で優れているでしょう。
- ワンクリックでのリストアなし:AWS Backupを使用したリストア操作の自動化は、API操作を使用してプログラム的に行う必要があり、これはDevOpsの実践がしっかりしている企業には適しているかもしれません。より簡単なリカバリオプションを求める人にとっては、N2Wはスクリプトを必要とせず、簡単かつほぼ瞬時にワンクリックでリカバリを行うことができます。
- 粒度の細かいリカバリなし: AWS Backupは、ファイル/フォルダレベルの粒度を伴わずにサーバー全体をリカバリします。(AWS Data Lifecycle Manager やその他の AWS サービスでは、より詳細なバックアップ戦略が利用できる可能性があります。)完全な柔軟性と詳細性が必要な場合は、N2W を使用してバックアップおよびリカバリのファイル/フォルダをドリルダウンしたり、複数の世代のバックアップを検索して特定のファイルを見つけることができます。バックアップの分類について事前に計画したりインデックスを作成しておく必要はありません。N2W が自動的にドリルダウンアクセスを提供します。
- 災害復旧なし:AWS Backupでは、ユーザーが手動でスナップショットを別のリージョンにコピーすることは可能ですが、自動復旧オプションはありません。 現在、多くの企業がAWS Organizationsの一部として複数のAWSアカウントを運用しているため、アカウント間のバックアップができないことは、企業にとって大きな制限となります。 アカウント間の災害復旧は、あらゆるDR計画の重要な要素であり、ランサムウェア、内部からの悪意ある攻撃、または人為的ミスなど、AWSアカウントが侵害されるのを防ぎます。
N2Wは、クロスリージョンおよびクロスアカウントの災害復旧を完全にサポートしています。例えば、ユーザーは30秒以内に他のリージョンまたはアカウントのEC2インスタンスを完全に復旧することができ、RTO(目標復旧時間)を短縮できます。
- ネットワークの復元なし: もう一つの重要な機能として、AWSインフラ全体の可用性を確保する上で不可欠なAmazon VPCのクローン作成とキャプチャができないという点が挙げられます。一方、N2W Backup & Recoveryでは、この機能が提供されており、停電や障害が発生した場合でも、わずか数分でインフラを迅速かつ完全に復旧させることができます。
- リカバリーシナリオなし:AWSバックアップには、リカバリーシナリオ機能(スクリプト作成なし)がありません。N2Wでは、完全なDRフェイルオーバーの綿密なオーケストレーションを作成し、リカバリーシナリオ内で復元したいリソースに変更を加え、リカバリーの優先順位を決め、DR訓練を自動化することができます。
- 真のアーカイブなし:AWSバックアップでは、EBSバックアップを低価格のS3ティアリングにアーカイブすることはできません(EFSのサポートは例外)。N2W Backup and Recoveryは、実際のS3バケットにデータをアーカイブする機能があり、あらゆるS3階層にティアリングすることができます。また、N2W ZeroEBSオプションでは、AWSスナップショットを一切使用せずにバックアップをアーカイブすることも可能です。つまり、N2Wを使用することで、ストレージコストを最大98%削減できるということです。
その他の制限事項としては、
- お客様のリソースが保護されているか、されていないかがわからない
- 検索機能が限定的(リソースを検索するにはボリュームIDを知っておく必要がある
- シングル・ペイン・オブ・グラス(一元管理)機能なし – 複数のアカウントを管理することはできず、すべてのアカウントはアカウントごとに管理される。ただし、同じマスター支払者アカウント下にある場合は例外(これは、独立したユーザーやクライアントを管理するMSPにとって特に重要である
- 監査に特に重要となる、何か問題が発生した場合のレポート、日次サマリー、アラート機能なし
- 正確なバックアップ時間の知識不足(バックアップは一定の時間枠内で行われる) – N2Wでは60秒ごとにバックアップが可能ですが、AWSバックアップでは最小間隔として1時間枠しか選択できません
- 自動コールドティア/長期保存(EBSスナップショットをAmazon S3またはAmazon Glacierにコピーする)のサポートなし
- 各アカウントで100のバックアップ保管庫と100のバックアップ計画に制限されるサービス制限。
- バックアップジョブを実行する際、リソースごとに同時に実行できるジョブは1つだけ。
- 災害復旧訓練のサポートが限定的
- バックアップ自体を保存しないとバックアップログを保存できない
- リソース制御のサポートがないため、ユーザーはインスタンスの開始/停止をスケジュールしてリソースの使用を最適化/最小化できない
- ファイルまたはフォルダレベルの復旧のサポートがない
- タグ管理に大きな制限がある。通常、ほとんどの使用事例では十分な数であるにもかかわらず、リソースに50以上のタグを設定することができない。
- 他のアカウント/地域におけるAmazon S3バケットの複製に対応していない
- バックアップコピー操作の前にアプリケーションを静止状態にすることが非常に重要である場合が多いが、アプリケーションの一貫性に対応していない
- 24時間365日の無料サポートなし。通常、顧客は営業時間まで待たなければならず、チケットへの対応には数日かかることもあります。ダウンタイムの数分間が企業に数百万ドルの損失をもたらし、顧客の信頼を失い、完全に廃業する可能性さえあることを考えると、これは大きなリスクです。
きめ細かく信頼性の高いバックアップ管理を確保する方法は他にもあり、どのツールが自社のニーズを満たすかを確認するために、他のオプションを調査し、テストすることが重要です。
AWS環境の災害対策(DR)計画を立てる際に考慮すべきヒント
●DR運用にIAMポリシーを組み込む:DR運用や機密性の高いリカバリリソースへのアクセスを制限する、IAMの専門ポリシーを作成します。これによりセキュリティのレイヤーが追加され、権限のある担当者だけがフェイルオーバーを開始したり、重要なデータにアクセスしたりできるようになります。
●長期データ保持にはS3 Glacier Deep Archiveを利用:アクセス頻度の低いバックアップデータをS3 Glacier Deep Archiveに保存することで、ストレージコストを大幅に削減しながら、必要な時に数時間以内にデータを取得できる能力を維持できます。これは、DR計画の一環として重要なデータを長期間保持するのに最適です。
●重要なワークロードに対してマルチリージョンレプリケーションを実装する:Amazon S3 Cross-Region ReplicationやDynamoDB Global Tablesなどのサービスを使用して、最も重要なワークロードに対してマルチリージョンレプリケーションを設定します。これにより、AWSのリージョン全体が利用できなくなった場合でも、データとアプリケーションは利用可能な状態を維持できます。
●N2WSを活用したDRフェイルオーバーの自動化:N2WS Backup & Recoveryを使用して、新しいインスタンスの起動、DNSレコードの更新、ネットワーク設定の再構成などのフェイルオーバープロセスを自動化します。N2WSは、災害復旧の管理に合理化された信頼性の高いアプローチを提供し、手動介入を減らし、迅速な復旧を実現します。
●AWS Outposts を活用したハイブリッド DR ソリューションの検討:オンプレミスインフラストラクチャを大量に保有する組織では、AWS Outposts を使用して AWS サービスをデータセンターに拡張することを検討してください。このハイブリッドアプローチにより、オンプレミスのデータ主権とコンプライアンスを維持しながら、AWS の DR 機能を活用することができます。
AWSの価格設定モデルの概要
AWSは、さまざまなビジネスニーズに対応するために、複数の価格モデルを提供しています。
オンデマンドインスタンス
オンデマンドインスタンスは、インスタンスの種類に応じて、コンピューティング能力を時間単位または秒単位で支払う従量制の価格モデルです。初期費用は発生せず、ユーザーは長期的な契約を結ぶことなく、いつでもインスタンスを開始または停止することができます。このモデルは、需要が予測できない作業負荷や短期プロジェクトに最適です。
利点:
- 柔軟性:必要に応じてインスタンスの起動と停止が可能。
- 初期費用なし:使用した分だけのお支払い。
- 使いやすさ:長期契約を必要としないシンプルな請求。
短所:
- コスト高:長期契約の他の料金モデルと比較すると割高。
- コスト管理:継続的に実行されるインスタンスでは、コストが予測しにくくなる可能性がある。
リザーブドインスタンスと割引プラン
リザーブドインスタンス(RI)とセービングプランは、1年または3年間の利用を確約する代わりに、オンデマンド価格よりも割引価格で利用できるものです。RIは前払いと利用確約に基づいて割引を提供し、セービングプランはインスタンスタイプを問わず、より柔軟に同様の割引を提供します。
利点:
- コスト削減:オンデマンドと比較して最大72%のコスト削減。
- 予測可能な請求:安定したワークロードに最適。
- 柔軟なセービングプラン:従来のRIよりも適応しやすい。
短所:
- 前払い契約:事前計画と長期的な契約が必要。
- 柔軟性の制限(RI):特定のインスタンスタイプとリージョンに制限される。
スポットインスタンス
スポットインスタンスでは、ユーザーは使用されていないAWSの容量を大幅に低い価格で入札することができ、オンデマンド料金よりも最大90%も安くなる場合もあります。ただし、これらのインスタンスは、容量が他の場所で必要になった場合、AWSによって中断される可能性があります。
長所:
- 大幅なコスト削減:非クリティカルなワークロードやバッチ処理に最適です。
- 高い可用性:地域全体にわたって予備の容量に幅広くアクセスできます。
短所:
- 中断のリスク:インスタンスはわずかな通知で終了される可能性があります。
- 限定的なユースケース:クリティカルなアプリケーションや時間的制約のあるアプリケーションには不向きです。
専用ホストおよび専用インスタンス
専用ホストおよび専用インスタンスは、単一のお客様専用の物理サーバーを提供します。これらのオプションは、コンプライアンス、ライセンス、規制要件が厳しい組織向けに設計されています。
利点:
- コンプライアンス:厳しいセキュリティおよびコンプライアンス要件に対応します。
- 専用リソース:他の顧客とのリソース共有はありません。
- ライセンスの持ち込み:特定のライセンスモデルに対応。
短所:
- 高コスト:専用ハードウェアを使用するため、他のモデルよりも高価。
- 限定的な拡張性:仮想化ソリューションと比較して柔軟性が低い。
AWSコストについてのエクスパートからのアドバイス
- インスタンスファミリーの更新機会を活用する:インスタンスファミリーの更新情報を定期的に確認しましょう。新しい世代のインスタンスファミリーは、同等のパフォーマンスまたはより低いコストで、より優れたパフォーマンスを提供していることがよくあります。ワークロードを最新のインスタンスファミリーに移行することで、大幅なコスト削減を実現できます。
- 複数のアカウントを統合する:組織で複数のAWSアカウントを使用している場合は、AWS Organizationsでそれらを統合することで、ボリュームディスカウントを共有し、請求を簡素化することができます。このアプローチは、コスト最適化のための集中管理も実現します。
- 地域ごとの価格差を活用:AWSの価格は地域によって異なります。レイテンシに敏感でないワークロードの場合は、コストの低い地域にリソースを展開します。例えば、US East (N. Virginia) や US West (Oregon) のような地域は、価格競争力があることが多いです。
- 未使用のボリュームに対するライフサイクルポリシーを実装:未使用のEBSボリュームは、多額の費用が発生する可能性があります。ライフサイクルポリシーを使用して、非アクティブなボリュームのスナップショットを自動的に作成し、削除することで、未使用のストレージが不要な費用を発生させないようにします。
- データの転送を監視し、キャッシングを使用:アプリケーションが頻繁に異なるリージョンやパブリックインターネット上のデータにアクセスすると、データ転送費用が高額になる可能性があります。Amazon CloudFrontやAWS Global Acceleratorなどのキャッシングレイヤーを実装して、転送トラフィック費用を削減します。
AWS コストの管理と削減のための7つのベストプラクティス
以下のベストプラクティスを導入することで、企業はAWSにおける最適な支出を確保することができます。
1. リソースの最適化と適正化
リソースの最適化と適正化には、AWSリソースの利用状況を分析し、不要な過剰プロビジョニングを排除しながら、ワークロード要件に確実に一致させることが含まれます。 このプロセスは、過剰なインスタンスやアイドル状態のインスタンスに対する無駄な支出を排除するのに役立ちます。 ライフサイクルポリシーを使用してストレージ階層間のデータ移行を自動化することで、継続的なコスト効率性を確保することができます。
Compute OptimizerやTrusted AdvisorなどのAWSサービスは、CPUやメモリの使用率などの指標を分析して実行可能な推奨事項を提供し、企業が最もコスト効率の高いインスタンスタイプやサイズを決定するのに役立ちます。ストレージの最適化については、企業はアクセス頻度の低いデータをAmazon S3 Infrequent AccessやGlacierなどのコスト効率の高いストレージソリューションに移行することができます。
2. コスト効率を高めるためのスケジュールと自動化
AWS Instance Schedulerのようなサービスを利用すると、管理者は夜間や週末、休日など、業務時間外にインスタンスを停止するルールを作成することができます。このアプローチは、24時間365日稼働させる必要のない開発、テスト、ステージング環境に特に有効です。
AWS Lambdaのような自動化ツールをCloudWatch Eventsと組み合わせることで、アイドル状態のインスタンスの終了や未使用のEBSボリュームの削除など、リソースのクリーンアップアクションをトリガーすることができます。需要が変動するワークロードの場合、オートスケーリング機能により、コストを削減しながらパフォーマンスを維持するために実行中のインスタンスの数を動的に調整することができます。
3. コスト割り当てタグの導入
コスト割り当てタグは、AWSの費用をビジネスユニット、チーム、プロジェクトに割り当て、追跡するために不可欠です。タグはリソースに付加されるメタデータラベルとして機能し、支出のきめ細かい分析を可能にします。例えば、「Environment: Production」や「Department: Finance」などのタグを使用することで、組織はコストのかかっている分野を特定し、是正措置を取ることができます。
AWSは、タグに基づいて支出をフィルタリングし分析するためのツールとして、Cost ExplorerやBudgetsなどを提供しています。組織全体で標準化されたタグ付けポリシーを徹底することで、クラウド利用の説明責任をより適切に果たすことができます。また、タグ付けはチャージバックやショーバックのプロセスを簡素化します。
4. 定期的なコストのモニタリングとガバナンス
AWSの費用を管理するには、定期的なコストの監視とガバナンスが不可欠です。AWS Cost Explorer、コストおよび使用状況レポート、AWS Budgetsは、費用の傾向を追跡し、異常を特定し、予算のしきい値を設定するためのツールを提供します。これらのツールは、費用がサービス、アカウント、および地域にどのように分散しているかを可視化します。
AWS Organizations を通じてサービスコントロールポリシー(SCP)を実装するなどのガバナンスの実践により、リソースが組織のポリシーに準拠してプロビジョニングされることを保証します。例えば、SCP を使用して、コストの高いインスタンスタイプの使用を制限したり、リソースのデプロイを特定のリージョンに限定することができます。ガバナンスポリシーと組み合わせた定期的なコストの見直しは、組織が非効率性を特定し、コスト削減策を実施するのに役立ちます。
5. コスト管理のためのコードとしてのインフラストラクチャの利用
AWS CloudFormation、AWS CDK、TerraformなどのInfrastructure as code(IaC)ツールを使用することで、企業はコードを使用してクラウドリソースを定義および管理することができます。 IaCにより、リソースのプロビジョニングが常に一貫性のある自動化された反復可能なものとなり、コスト超過につながる可能性のある手動エラーの発生を低減できます。
IaCテンプレートでは、リソースの制限を指定したり、インスタンスの種類を制限したり、スポットインスタンスのようなコスト効率の高い構成を自動的に有効にしたりすることで、コスト管理のベストプラクティスを組み込むことができます。さらに、IaCにより、組織はインフラストラクチャのバージョン管理が可能になり、変更の追跡や構成の最適化が容易になります。
6. FinOpsの実践の採用
FinOps(財務業務)は、財務上の説明責任と業務効率を組み合わせた、クラウドコストの管理における協調的なアプローチです。 財務、業務、エンジニアリングの各チーム間の部門横断的な協力を促し、ビジネス目標に沿いつつ、クラウド支出の最適化を図ります。 FinOpsの実践には、定期的なコスト分析、予測、最適化の取り組みが含まれます。
FinOpsの重要な要素のひとつはコストの透明性であり、これによりすべての利害関係者が詳細な支出データにアクセスできるようになります。 この共有された可視性は説明責任を促し、データに基づく意思決定を推進してコスト削減を実現します。さらに、FinOps を採用する組織は、自動化と分析を活用してコスト管理戦略を改善し、継続的な改善を優先しています。
7. バックアップ管理とストレージの最適化
バックアップ管理とストレージの最適化は、データ保護と災害復旧機能を損なうことなく AWS コストを最小限に抑えるために不可欠です。 組織はバックアップ戦略を評価し、冗長なバックアップを排除し、過剰な保持を回避し、コスト効率の高いストレージソリューションを活用すべきです。
Amazon S3 GlacierやGlacier Deep ArchiveなどのAWSサービスは、アクセス頻度の低いバックアップの長期保存に最適です。ライフサイクルポリシーを適用することで、企業はあらかじめ設定した期間が経過したデータを自動的に標準ストレージ層からより低コストのアーカイブストレージに移行することができます。例えば、Amazon S3で日次バックアップを30日間保持した後、Glacierに移行することで大幅なコスト削減を実現できます。
さらに、重複排除と圧縮技術によりバックアップのサイズを縮小し、ストレージコストを削減することができます。N2Wのようなツールは、バックアップポリシーの一元管理を簡素化し、コスト効率の高い手法の自動化と徹底を容易にします。バックアップ構成の定期的な監査により、組織の保持ポリシーへの準拠が保証され、不要なデータの蓄積を防止することができます。
N2W最適化クラウドバックアップによるAWSのコスト削減
AWSのコスト管理は、価格設定を理解するだけではなく、より賢明な意思決定を迅速に行うことが重要です。そこでN2WSがサポートします。
当社のクラウドネイティブなバックアップおよび災害復旧プラットフォームは、AWS環境を推測に頼らずに管理できるようにします。 古いスナップショットの自動アーカイブ、アイドルリソースのシャットダウン、利用率の低いボリュームの監視など、すべてを直感的な単一のダッシュボードから実行できます。 AWS、Azure、Wasabiのいずれにバックアップする場合でも、N2Wはデータの安全性、不変性、コスト最適化を保証します。
N2WSがコスト削減に役立つ主な方法:
- スマートなスナップショットアーカイブにより、ストレージ費用を最大92%削減。
- 自動化されたポリシーとクロスクラウドDRにより、毎週何時間も節約。
- エアギャップストレージと不変のスナップショットにより、バックアップのセキュリティを確保。
- 内蔵のコストエクスプローラーとアラートにより、支出を可視化。
クラウドのコスト削減は、保護の妥協を意味するものであってはなりません。

