

Syniti DR
Data Replicatorが強制停止することがある
本エラーは例えばOracle 11.2のクライアントを使用している場合「oracore11.dll」にて障害が発生した旨Windowsイベントログに記録されている可能性があります。
一部の条件下にて本事象が発生するケースがあり、エラー発生までの流れは以下の通りです。
1. DBMoto から Oracle へ Oracle クライアントで接続するためコネクションをオープンする
2. このオープンしたタイミングで Oracle クライアント側のoracore11.dll というファイル関連で何らかの障害が発生しエラーとなる可能性がある
3. 2に引きずられて DBMoto の Data Replicator が強制終了する
つまり、発生トリガーは1の「Oracle へのコネクションを確立した際」です。
これまで発生事例から Windows のダンプファイルの解析、マイクロソフト社のダンプ解析ツール ADPlus でさらに詳細を解析するなどし下記のことが判明しております。
・エラーは Oracle 側の DLL で発生している
・エラーは .NET Framework の外で発生している
・DBMoto はすべて .NET Framework 内で動作するので本エラーが DBMoto 起因である可能性は極めて低い
(DBMoto が原因の場合は .NET Framework 内でエラー発生する)
・再現するマシンが一部に限られている
回避策としてレプリケーション毎に Oracle への接続をオープンにしないようコネクションプールを有効にする方法がございます。設定手順は以下の通りです。
1. Data Replicator サービスを停止します
2. ターゲットの Oracle 接続を右クリック→「プロパティ」を開きます。
3. 接続 Oracle .NET Driver の右にあるボタンをクリックします。
4. Pooling が False になっているので True へ変更します。
これにより Oracle へのコネクションプーリングが有効となり、
本事象は発生しなくなります。
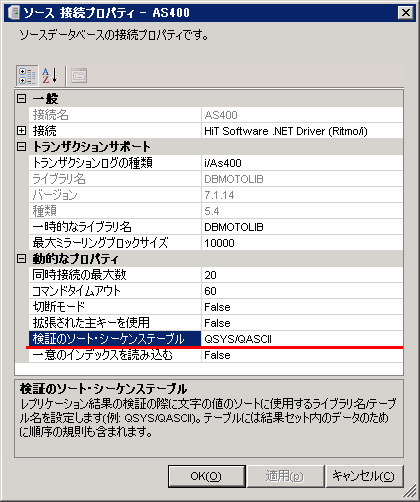
AS/400のレプリケーションで「レプリケーション検証機能」を使用すると文字変換が正しくないとのエラーが出ます。
DBMotoの機能に、レプリケーションのソースとターゲット双方のテーブル間で差異が生じていないかを確認するレプリケーション検証機能があります。
AS/400のテーブルで、VARGRAPHIC型もしくはGRAPHIC型があるテーブルで検証を行うと、「CCSID 65535とCCSID 13488の間の文字変換は正しくない」とのエラーメッセージが出力されることがあります。
このエラーメッセージは通常のレプリケーション中には発生せず、データは問題なくレプリケーションできていることが多いです。

これは、このレプリケーション検証機能使用時に限り、DBMotoの「検証のソート・シーケンステーブル」設定が有効であるため、GRAPHIC型が文字変換を行おうとして失敗しています。
対処法は、この設定個所の部分を空欄にすることです。(設定変更時はData Replicatorの停止が必要です。)
なお、通常のレプリケーションは、前述の通りこの設定を使用していないので、問題なく変換され動作します。
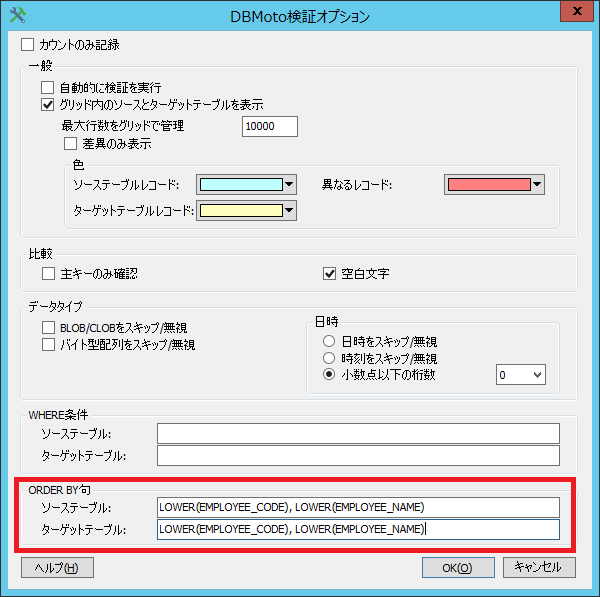
レプリケーション検証機能で正常なレコードがソースのみ、ターゲットのみのレコードとして表示されます。
レプリケーションの検証をすることで、ソースのみのレコード、ターゲットのみのレコード、ソースとターゲットで差異のあるレコードを確認できます。
しかし、本来、ソースにもターゲットにも存在し、差異のないレコードがソースのみ、ターゲットのみに存在するレコードとして表示されることがあります。
これは、DBMotoはソースとターゲットのレコードを比較する前に主キーをベースにレコードのソートを行いますが、このときのソースDBとターゲットDBのソートの仕様の違いによるものです。
例えば、Oracleの場合、大文字、小文字を区別してソートするため、D→aの順番でソートされ、MySQLの場合、大文字、小文字を区別せずソートするため、a→Dの順番でソートされます。
このソートの順番が異なるため、このような結果が生じます。
この事象を回避するため、検証機能のオプション「ORDER BY句」の「ソーステーブル」「ターゲットテーブル」に「LOWER(主キー)」を入力してください。こうすることで、大文字、小文字の区別なくソートが行えるため、問題なく検証することが可能です。
シンクロナイゼーション レプリケーション作成時にエラーが発生します。 「接続’DB接続名’用に定義されたユーザ’sa’はsysadminであり、シンクロナイゼーションでは有効ではありません。sysadmin以外のユーザでログインを定義してください。また、ディストリビュータを作成し、トランザクションログを読むためにsysadminのログインIDを供給しています。」
SQL Serverの接続設定に「sa」以外のユーザをご利用ください。
シンクロナイゼーションでは、更新がループしないようにするため、接続設定に使用したユーザでの更新はレプリケーション対象として検出しない仕様となっております。
そのため、シンクロナイゼーションを行う場合には、DBMoto専用ユーザを用意する必要がございます。
「sa」はDBMoto専用とすることができないため、このようなエラーが発生します。
CHARの代わりにVARCHARを使用してRedshiftにレプリケートすることで、より多くの文字をサポートし、予期しない文字の混在を防ぐことができます。
Version: Syniti Data Replication 9.6.0 以上
Amazon Redshiftのクラウドデータウェアハウスにレプリケートする際、データタイプがCHARのフィールドにエラーや予期せぬ文字が現れることがあります。 この現象の説明については、以下のURLを参照してください。
https://docs.amazonaws.cn/en_us/redshift/latest/dg/multi-byte-character-load-errors.html
エラーや予期せぬ文字を避けるために、RedshiftのターゲットのデータタイプをCHARではなくVARCHARに設定してください。
データベーススキーマの設計方法
データベーススキーマの設計は、データの書式が一貫していること、すべての項目が主キーを持つこと、重要なデータが除外されていないことを保証します。データベーススキーマは、視覚的なものと論理的なものがあり、データベースを管理するための公式のセットを含んでいます。開発者は、これらの公式とデータ定義を使用して、データベーススキーマを作成します。
最も一般的なデータベーススキーマの種類を以下に概説します。
階層的モデル: 階層型:ルートノードに子ノードが付随するツリー状の構造を持つデータベーススキーマを階層型という。このデータベーススキーマモデルは、家系図などのネストされたデータを格納することができる。
フラットモデル:フラットモデル: データを単次元または二次元の配列に整理したもので、行と列を持つスプレッドシートのようなモデル。このモデルは、複雑な関係を持たない単純なデータを表形式で整理するのに適している。
リレーショナルモデル:リレーショナルモデルは、データが表、行、列に整理されるフラットモデルに似ている。ただし、このモデルでは、異なるエンティティ間の関係を定義することができる。
スタースキーマ: スターデータベーススキーマは、データを「ディメンション」と「ファクト」に整理します。ディメンジョンには説明的なデータが含まれ、ファクトには数値が含まれる。
スノーフレークスキーマ: スノーフレーク(雪片)型データベーススキーマは、データベース内のデータを論理的に表現したものである。このタイプのスキーマの表現はスノーフレークに似ており、複数のディメンジョンが1つの集中ファクトテーブルにくっ付いている。
ネットワークモデル: ネットワークデータベーススキーマは、データを接続された複数のノードとして含みます。このモデルは、多対多の関係などの複雑な接続を可能にするため、特定のタスクを達成するために使用されます。
データベーススキーマ設計のベストプラクティス
データベーススキーマを最大限に活用するためのベストプラクティスを以下に紹介します。
セキュリティ: 効果的なデータベーススキーマの設計は、データセキュリティに重点を置く必要があります。また、ログイン情報、個人を特定できる情報(PII)、パスワードなどの機密データを保護するために、高度な暗号化を使用します。
名前の規則: スキーマ設計をより効果的にするために、データベースで適切な命名規則を定義することができます。テーブル、カラム、フィールド名には、複雑な名前、特殊文字、予約語を使用しないようにします。
正規化: 正規化とは、独立したエンティティやリレーションシップが、同じテーブルやカラムにまとめられないようにすることで、冗長性を排除するものです。これにより、データの整合性が向上し、開発者が情報を取得しやすくなります。また、正規化により、データベースのパフォーマンスを最適化することもできます。
ドキュメンテーション: データベーススキーマは、開発者とドキュメンテーションの作成にとって非常に重要です。データベーススキーマの設計は、説明書、コメント、スクリプトなどとともに文書化する必要があります。
データベースのスキーマには、大きく分けてどのような種類があるのでしょうか。
物理データベーススキーマ: 物理データベーススキーマは、データの物理的な配置と、ファイル、インデックス、キーと値のペアなどのストレージのブロックへの格納方法を表します。
論理データベーススキーマ:論理データベーススキーマはデータの論理的な表現を記述し、論理的な制約を伝達する。データはある種のデータレコードとして記述することができ、異なるデータ構造として格納される。ただし、データの実装などの内部的な詳細はこのレベルでは隠されている。
データベーススキーマは何に使うのですか?
データベーススキーマは、情報を体系的に整理するために設計された認知的な枠組みや概念です。スキーマがあれば、膨大な量の情報を素早く解釈することができる。未整理のデータベースは混乱しやすく、維持・管理も困難です。きれいで、効率的で、一貫性のあるデータベーススキーマの設計により、組織のデータを最大限に活用することができます。リレーショナルデータベースは、データの冗長性を排除し、データの不整合を防ぎ、データの検索と分析を容易にし、データの整合性を確保し、不正なアクセスからデータを保護するために、データベーススキーマ設計に大きく依存します。強力なテスト環境でデータをテーブルとカラムに整理することが極めて重要です。データの整合性を管理し、データベースとソースコードを更新する計画が必要です。
データベース・スキーマ設計とは?
データベーススキーマ設計は、データベースのアーキテクチャを開発するための設計図を提供することで、膨大な情報を体系的に格納することができる。また、データベースの構築に関わる戦略やベストプラクティスを指します。データベーススキーマ設計は、データを個別のエンティティに整理し、整理されたエンティティ間の関係を決定することによって、データの消費、解釈、取得をはるかに容易にします。
データベースのスキーマはどのように設計されているのですか?
データベース設計者は、プログラマーが効率的にデータベースを操作できるように、データベーススキーマを作成します。データベースを作成するプロセスは、データモデリングとして知られています。データベーススキーマを設計するためには、情報を収集し、それらをテーブル、行、列に並べる必要があります。情報を整理することで、理解しやすく、関連付けやすく、使いやすくする必要があります。
データベーススキーマの定義
データベーススキーマとは、リレーショナルデータベース全体の論理的、視覚的な構成のことである。データベースのオブジェクトは、テーブル、関数、リレーションとしてグループ化され表示されることが多い。スキーマは、データベース内のデータの構成と格納を記述し、さまざまなテーブル間の関係を定義します。データベーススキーマは、スキーマ図を通して描くことができるデータベースの記述的な詳細を含んでいます。
Syniti Data Replication (DR)とDBMotoはどう違いますか?
DBMotoはVer9.7から名称をSyniti Data Replication (略: Syniti DR)に変更しました。
名称のみの変更で機能に変更はありません。
今後名称をSyniti Data Replicationに変更してまいります。
Oracleからのミラーリングで「Record to update not found in target table」の後にターゲットへの補管INSERTでNOT NULL制約違反が発生する
まず更新対象レコードがターゲットに存在しない場合に「Record to update not found in target table」警告が発生し、その後DBMotoは補完INSERTを行います(行わないようにすることも可能です)
しかし Oracle のトランザクションログモードがLog Readerの場合、REDOログから取得できる情報は更新したカラムとPKのみとなります。
このため更新していないカラムはNULLとしてターゲットへのINSERTを行い、結果NOT NULL制約のカラムがあるとエラーになります。
対処方法は以下の2通りです。
1. Oracle のトランザクションログモードを「トリガー」にする(Oracle 10gかつDBMoto v9以降)
2. Oracle に対して以下のクエリを発行し、すべてのカラム情報をREDOログから取得できるようにする。
>ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
パーティション化したテーブルからミラーリングできますか?
可能です。
ただし、DBMotoではDML文のみレプリケーションするため、パーティションがDDL文で削除されたときはそれを反映できません。
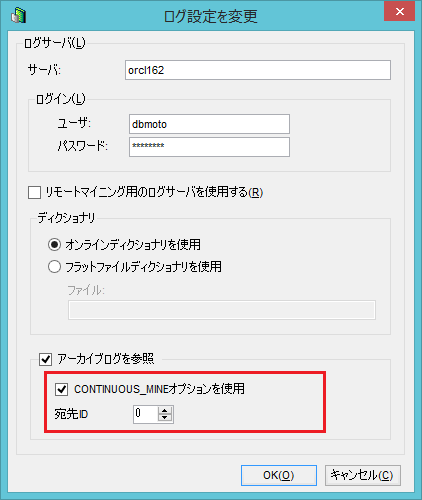
Oracleからのミラーリングタイミングが更新が起きていない時間帯でもバラバラです。
Oracleからのミラーリング時にはデフォルトでアーカイブログを参照し、またその際にCONTINIOUS_MINEオプションを有効にしています。
一部のOracle環境ではCONTINIOUS_MINEオプションをオンにしているとミラーリングタイミングがバラバラになることがあります。
CONTINIOUS_MINEオプションを外すとこの事象が解消することがあります。
オプションの切り替えにより、レプリケーションの性能劣化やOracleに対する負荷増加が発生することはほとんどありません。
DB2のHADR構成のスタンバイサーバからミラーリングは可能ですか?
トリガー形式およびログ参照形式のいずれも不可です。
DB2側の仕様でトリガーに必要な機能もログ参照に必要なAPIもスタンバイサーバでは利用できません。
SQL Serverでログ配布を受けているスレーブ側サーバからレプリケーションできますか?
SQL Serverの仕様上の制約によりできません。
MySQLへのミラーリングが反映されません
MySQLへミラーリングを行うためには、MySQLでautocommitが有効になっている必要があります。以下のクエリで確認が可能です。
mysql>SELECT @@autocommit;
もしもこの結果が0の場合、autocommitが無効になっているので、有効化してください。
もしアプリの都合で有効化が困難な場合は、以下の対応を行ってください。
1. Data Replicator を停止し、Management Center を閉じます。
2. 以下のファイルをダウンロードし、ExecuteList.xml を開きます。
https://www.climb.co.jp/soft/download/DBMoto/ExecuteList.zip
3. <connection name=”ここ”> に DBMoto で設定済みのMySQL 接続名を指定します。
4. ExecuteList.xml を DBMoto インストールディレクトリに配置します。
5. Data Replicator を開始し、正常にレプリケーションされることを確認します。
これによりMySQL への接続毎に「SET autocommit=1;」のコマンドを発行して一時的にautocommitを有効化してレプリケーションを行うようになります。
RDSのAurora/MySQLでバイナリログ(binlog)を使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてbinlog_formatを「ROW」に変更することでバイナリログを記録するようになり、ミラーリング可能となります。
【DBMotoでの設定】
「DBMySqlUtil.dll」をDBMotoインストールディレクトリに配置する必要があります。
お手元にない場合はお問合せください。
RDSのAurora/MySQLでトリガーを使用してミラーリングするためには?
【RDS Auroraの場合】
パラメータグループのDB Cluster Parameter Groupにてbinlog_formatが「OFF」になってる場合はそのままトリガーを使用可能です。
binlog_formatが有効化されている場合は、DB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
【RDS MySQLの場合】
パラメータグループのDB Parameter Groupにてlog_bin_trust_function_creatorsを「1」へ変更することでトリガーを使用することが可能となります。
Sybase ASEから差分レプリケーションは可能ですか?
トリガーを使用することで可能です。
ただし、Sybase ASEでは1つのテーブルにおいて1つのトリガーのみしか使用できない仕様のため、既存でテーブルにトリガーを設定している場合は、DBMotoから差分レプリケーションを実施することはできません。
メール設定において、SMTPポート番号465番で指定したが、エラーでメールが送信されない。
こちらはDBMotoで使用している.NET Frameworkの仕様による問題です。
仕様上SMTP over SSLのポート番号である465番を使用したメールの送信ができないようになっております。
別のポート番号をご利用ください。
スクリプトで、.Net Frameworkの○○という関数が動きません。
スクリプトに記述した、.Net Frameworkの関数が動作しないことがあります。
これは、その関数の動作に必要な.Net FrameworkのライブラリがDBMotoに読み込まれていないのが原因です。
DBMotoでは本体の動作に不要な.Net Frameworkのライブラリは読み込まないようになっております。
適宜リファレンスで必要な.Net Frameworkのライブラリを読み込んでください。
■例
SHA256CryptoServiceProvider関数を利用する場合、System.Core.dllというライブラリを呼び出す必要があります。
Microsoft公式のSHA256CryptoServiceProvider解説ページ
このDLLファイルは、C:\Windows\Microsoft.NET\Framework64\vX.X.XXXX(Xは任意のバージョン数値)にありますので、ここへのリファレンスを追加してください。(64bit版の場合)
DBMotoでOracleのマテリアライズドビューはレプリケーションできますか?
リフレッシュとミラーリングが可能です。
ミラーリング時の注意点として、DBMotoは差分データの取得にトランザクションログを用いていますが、マテリアライズビューにあるレコードに対するUPDATE操作をOracleが内部で行う際、UPDATEではなくDELETEとINSERTを組み合わせて行っているため、トランザクションログの数が1つではなく、2つになっています。
DBMotoのレコード処理件数表示はトランザクションログをベースにしている都合上、マテリアライズドビューのリフレッシュモードが「完全」の場合は、ビュー上の全レコード数×2、「部分」の場合は、UPDATE対象レコードの数×2の数が、レコード処理件数として表示されます。これはOracle側の仕様によるものです。
Amazon EC2上のDBMotoからAmazon Redshiftへの接続ができません。
EC2上のWindowsに用意したDBMotoからRedshiftに接続しようとするとフリーズすることがあります。
これは、EC2上のインスタンスのNIC設定に由来する問題です。レジストリ上からMTU値を設定します。
次の場所にあるレジストリ内にMTU値を示すレジストリエントリーを追加します。
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters\Interfaces\(アダプタのID)
追加するレジストリは、DWORD型で、値の名前は MTU 、データの値は 1500 に設定します。設定後コンピュータを再起動して、新しい値を適用します。
詳細は下記Amazon様ページをご覧いただきますよう、お願いいたします。
データベースへの接続が中断された – Amazon Redshift
マルチメンバーファイル(テーブル)からレプリケーションができません。
AS400上のマルチメンバーファイルとなっているテーブルからレプリケーションしようとすると、ステータスは成功なのに処理件数が0件のまま動かないことがあります。
これはマルチメンバーファイルの仕様上の制限でSELECTクエリが実行できないためです。
テーブルのエイリアスを作成していただければSELECTクエリで結果が取得できるため、レプリケーションできるようになります。
エイリアスを作成するクエリの一例は以下の通りです。
CREATE ALIAS MYLIB.FILE1MBR1 FOR MYLIB.MYFILE(MBR1)
CREATE ALIAS MYLIB.FILE1MBR2 FOR MYLIB.MYFILE(MBR2)
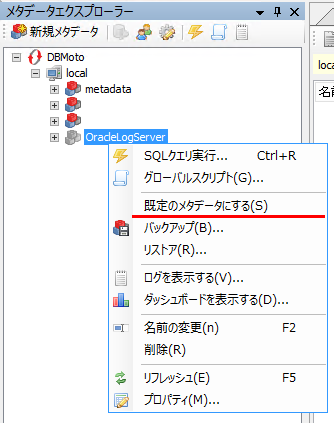
メタデータは複数作成できますか?同時に使用できますか?
DBMotoのメタデータは、複数作成することは可能です。
これにより運用環境とテスト環境それぞれのメタデータを用意できます。
しかし、複数のメタデータを同時に使用することはできません。それぞれのメタデータ内にあるレプリケーションは、それぞれのメタデータを有効化していない限り動作しません。
メタデータの切り替えは、メタデータ上で右クリックして表示されるメニューの、「既定のメタデータにする」で可能です。
MySQLレプリケーションのスレーブ側サーバからミラーリングをしたいのですが、必要な設定はなんですか?
スレーブ側MySQLのmy.iniの[mysqld]に次の一行を付け加えます。
log_slave_updates=TRUE
これは、スレーブサーバがマスターサーバから受け取った更新をスレーブサーバ自身のバイナリログに反映する設定となります。
デフォルトですと設定がされていない(FALSE)ため、DBMotoからスレーブ側のバイナリログを読み込みにいっても、マスター側の更新が記録されず、変更を検知できません。
ビューのレプリケーションに対応していますか?
参照するベースのテーブルが1つの場合かつSQLServerのビュー更新条件(特定の関数が使用されていないこと)を満たしている場合に限り、リフレッシュのみ可能です。
複数のベーステーブルを参照するビューの場合は、ビューの仕様でinsert, update, deleteが行えず、selectのみ可能となりますので、DBMotoでも同様にレプリケーションは行えなくなります。
DBMotoをどのマシンにインストールすればよいですか?
Windows OSのマシン(物理/仮想)にインストールします。
インストールしたマシンからソースDB・ターゲットDBのマシンに接続してレプリケーションの設定・実行を行います。
システム要件:https://www.climb.co.jp/soft/dbmoto/outline/system.html
DBMotoのインストール要件は?
Windows OSでMicrosoft .NET Frameworkがインストールされている必要があります。詳細は下記をご確認ください。
https://www.climb.co.jp/soft/dbmoto/outline/system.html
複数のテーブル内のレコードを1つのテーブルに結合可能ですか?
可能ですが注意が必要です。
ミラーリング時はPKが各テーブルで重複していなければ問題ありませんが、リフレッシュ時はそのまま実行してしまいますとリフレッシュ前に一度レコードを削除する処理(DBMotoの仕様)が行われます。これを回避するためにスクリプトでリフレッシュ時にレコードを削除しないようブロックする必要があります。
なお、各テーブル内のレコードが結合後に重複する可能性がある場合は、PK代わりのフィールドを新規で作成することでPK重複エラーを回避可能です。
DBMotoを仮想マシンにインストールすることは可能ですか?
VMwareのvSphere ESX/ESXiやMicrosoftのHyper-Vなど、仮想マシン上にもインストール可能です。
エージェント導入が必要ですか?
ソースDB・ターゲットDB・DBMotoマシンいずれに対してもエージェントを導入する必要はありません。
サポートしているDBの種類とバージョンは?
AS/400をはじめとする非常に多くのDBをサポートしております。また、DBのプラットフォーム(OS)には依存しません。
詳細な対応DB一覧は下記をご覧ください。
対応データベース一覧
どのようなレプリケーションモードがありますか?
下記の3つのモードをサポートしております。
・リフレッシュ(レコード全件レプリケーション)
・ミラーリング(片方向差分レプリケーション)
・シンクロナイゼーション(双方向差分レプリケーション)
ライセンス体系はどのようになっていますか?
ソースDBとターゲットDBの種類とマシンのスペックに依存します。
詳細はこちらをご参照ください。
使用する レプリケーションモードによって価格は異なるのでしょうか?
シンクロナイゼーション(双方向)を使用せず、ミラーリング(片方向)のみを使用する場合は、割引がございます。詳細はお問合せください。
開発環境やHA環境でも使用したいのですが、その場合は2倍の価格になりますか?
開発環境, バックアップ、HA環境、RACなどの構成で使用する場合は、価格が変わりますのでお問い合わせください。
お問合せはコチラ
代理店で購入可能ですか?
弊社から販売、代理店を通しての販売どちらも行っております。
サポートの回数に制限はありますか?
回数に制限はありません。
製品のバージョンアップの際には別途料金はかかりますか?
サポート期間内の場合、無償でバージョンアップをお客様自身で行うことができます。
また、弊社でもバージョンアップ作業(有償)を行っています。
日本語メニューに対応していますか?
操作画面は日本語化しております。
製品の操作マニュアルも日本語版を用意しております。
導入支援は行っていますか?
別料金となりますが、弊社にて設計、インストール、設定を行います。
保守費用について教えてください。
年間保守費用はライセンス価格の 20% となっており、初年度は必須です。
評価期間は何日間ですか?
評価用ライセンスキーが発行されてから15日間となります。
評価中のサポートは受けられますか?
無償でご利用いただけます。
質問の内容により、お時間を頂く場合がございます。予めご了承ください。
評価版に機能制限はありますか?
評価版に機能制限はありません。
評価版のお申込みはコチラ
評価するには何が必要になりますか?
下記の環境をご用意ください。
・DBMotoインストール用のWindowsPC(仮想マシンでも可)
・ソースDBとターゲットDB、及び評価の際に使用するテストデータ
※インストールするサーバについては、システム要件をご確認ください。
※インストールや設定方法についてのマニュアルやデモ動画を事前にご確認ください。
ミラーリング時の更新サイクルはどのくらいですか?
デフォルト値は60秒です。変更可能ですが、30秒~5分が推奨値となっております。
古いジャーナルは削除しても問題ないですか?
DBMotoから参照しているジャーナルより前のものについては削除して問題ありません。
AS/400にはどのドライバで接続するのでしょうか?
Ritmo/iというドライバを使用します。DBMotoに同梱されております。
ジャーナルレシーバはテーブル単位で作成する必要がありますか?それともまとめて1つでも問題ないですか?
1つにまとめても問題ありません。DBMotoではテーブル単位でレプリケーション定義を作成し、定義ごとにトランザクションIDを管理することが可能なためです。
DBMOTOLIBにジャーナルレシーバを作成してもよいですか?
可能ですが非推奨です。DBMOTOLIBにはDBMotoからAS/400のジャーナルを参 照するためのプロシージャが存在しますので、DBMOTOLIBにプロシージャ以外のデータが存在するとレプリケーションのパフォーマンスに影響が出る場合があります。
どのようにして差分レプリケーションが行われますか?
Redoログを参照します。事前にサプリメンタルロギングの設定が必要ですが、DBMotoから行うことが可能です。
Oracle10gのレプリケーション設定時にドライバエラーが出ます
DBMoto側のOracleクライアントドライバを最新の11gにしてください。Oracle側の既知不具合です。
Oracle RACに対応していますか?
対応しております。
データタイプBLOB/CLOBには対応していますか?
対応しておりますが、ミラーリングとシンクロナイゼーションについては、
Log Server経由のみ対応しています。
ビューはレプリケーションに対応していますか?
対応しておりません。
Oracleへ接続するドライバのダウンロード先を教えてください。
以下のサイトからOracleクライアント又はODACをダウンロード可能です。
http://www.oracle.com/technetwork/jp/database/windows/downloads/index.html
また、Oracleデータベースのバージョンに関わらず、ドライバのバージョンは11を使用してください。
どのようにして差分レプリケーションが行われますか?
DB2 Logを参照する方法と、トリガーログテーブルを作成する方法があります。DB2 Logを使用する場合、予めdb2udbreadlogという拡張ファイル(DBMotoに同梱済み)をDB2側に格納する必要があります。
DB2 UDBにはどのドライバで接続するのでしょうか?
Ritmo/DB2というドライバを使用します。DBMotoに同梱されております。
どのようにして差分レプリケーションが行われますか?
Distributorを参照する方法と、トリガーログテーブルを作成する方法があります。
SQL Server Express Editionに対応していますか?
対応しております。ただし差分レプリケーションの際にDistributorを使用することはできず、トリガーテーブルを作成する必要があります。
どのようにして差分レプリケーションが行われますか?
MySQLのバイナリログを参照する方法と、トリガーログテーブルを作成する方法があります。MySQLのバイナリログを使用する場合、拡張ファイルが必要となりますので別途お問い合わせください。
バイナリデータはレプリケーション可能ですか?
可能です。
AS/400からのミラーリングでトランザクションID取得のためにReadボタンを押下するとエラーになります
DBMotoからAS/400のジャーナルレシーバを参照するためのプロシージャを手動で作成した場合に、正しく作成されていない可能性があります。
カタログ・技術資料一覧から以下をご参照ください。
[DBMoto共通]AS400ジャーナル・プロシージャ作成手順書
電話サポートは24時間対応ですか?
弊社営業時間内(10:00~18:00)となります。
プロダクションサポートの場合、
弊社営業時間外はメーカーの英語サポートのみとなります。
OracleからのレプリケーションでORA-01291(ログ・ファイルがありません)が表示される。
OracleのRedoログが1周してDBMotoが参照しに行くIDが既になくなってしまった際に発生するエラーです。
復旧はリフレッシュするか、最新のトランザクションIDを取得する必要があります。
また、このエラーが頻発する場合はRedoログのサイズ設定を見直す必要があります。
Transaction Latency StatusにThreshold Warningが出る
この Warning は現在時刻と最後にレプリケーションした際の時刻がしきい値を超えたときに「レプリケーションが遅延しています」と警告を出すものです。
複数のソースサーバから1つのターゲットサーバに結合レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
https://www.climb.co.jp/soft/dbmoto/outline/example.html
1つのソースサーバから複数のターゲットサーバに分散レプリケーションすることは可能ですか?
可能です。詳細は下記ページをご参照ください。
AS/400のエラー「資源の限界を超えた」が発生しましたが原因はなんでしょうか?
下記ブログ記事をご参照ください。
リフレッシュ実行中にソースに更新があった場合はどうなりますか?
リフレッシュ完了後にミラーリングモードに移行し、更新分が差分レプリケーションされます。
シンクロナイゼーションで同一フィールドの同じ値を更新した時にコンフリクト扱いになりますか?
同じ値を更新した場合はコンフリクトとはみなされません。
サプリメンタルロギングを設定時の「Minimal Level」と「Database Level」は何が違うのでしょうか?また、実行されるSQLを教えてください。
●Minimal Level
レプリケーションするテーブルのみ(最低限)にサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA
・レプリケーション作成時
ALTER TABLE テーブル名 ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
●Database Level
データベース全体(すべてのテーブル)に対してサプリメンタルロギングの設定が行われます。
以下のSQLが実行されます。
・サプリメンタルロギング設定時
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS
レプリケーション定義を一括で作成する方法はありますか?
予めソース・ターゲットの接続設定を済ませたうえで「マルチレプリケーション作成」を選択することで可能です。
ジャーナルが切り替わった場合、DBMotoもちゃんと切り替えて追ってくれますか?
はい、AS/400側のジャーナルに合わせてDBMotoが参照するジャーナルも自動で切り替わります。
ターゲット→ソースへのリフレッシュは可能ですか?
リフレッシュはソース→ターゲット方向のみサポートしております。
サプリメンタルロギングの設定でOracle9iでは「Minimal Level」だけにチェックを入れても「Database Level」にも自動でチェックが入ってしまう
Oracle9iの仕様によるものです。
SQLServerへのレプリケーションで以下のエラーが発生しました。 System.Data.SqlClient.SqlException: IDENTITY_INSERT が OFF に設定されているときは、テーブル ‘XXXX’ の ID 列に明示的な値を挿入できません。
SQLServerのフィールドIdentityの仕様によるものです。Identity以外のPKフィールドを用意するかIdentity自体をOFFにする必要があります。
ミラーリング開始後すぐに終了してしまいます。再開してもすぐ終了します。
ミラーリング時にはPKの設定が必要です。DBに設定されているかご確認ください。もしされていない場合は、DBMotoから疑似PKを設定することも可能です。
レプリケーション定義を作成してもステータスがstoppedのままでレプリケーションが動いてくれません。
レプリケーション定義を作成した後に、Data Replicatorを起動する必要があります。
DBMotoインストーラ起動時にライセンスエラーが表示されます。
.NET Framework 2.0 SP2がインストールされていないのが原因です。
WindowsXPやWindowsServer2003・2003R2の場合、デフォルトではインストールされていないので、別途インストールが必要です。また、.NET Framework4.0単独では動作いたしません。
シンクロナイゼーション(双方向)における処理シーケンスを教えてください。
以下の流れとなります。
ソースのトランザクションログを検索⇒ターゲットのトランザクションログを検索⇒ソースからターゲットへの更新処理⇒ターゲットからソースへの更新処理
ミラーリングの真っ最中にスケジュールリフレッシュの時間になった場合はどのような挙動になりますか?
ミラーリングプロセス終了後にリフレッシュされます。強引に割り込むことはありません。
ミラーリング・シンクロナイゼーションの処理速度を上げる方法はありますか?
Data Replicator Option画面にある「Thread Execution Factor」の値を増やすことで処理速度の向上が期待できます。
UPDATE時のみレプリケーション対象外とすることは可能ですか?
スクリプトで対応可能です。
大量トランザクション時、レプリケーションステータスが「Mirroring」で成功数、合計数は0のままで何も動作していないように見える状態がかなり長い時間続いている。
ステータスがMirroringで動いていないように見えるときは、実際にはトランザクションログの参照を行っています。大量トランザクション処理時は時間がかかるケースがあります。
万が一の障害発生時の復旧方法は?
リフレッシュをする方法と、トランザクションIDを任意の位置に戻す方法の2通りあります。
Oracleでエラー「ORA-03113」が発生しました。
OracleとDBMoto間のネットワーク障害によるものです。
DBMotoの疑似PKを使ってレプリケーションしていますが、キーが重複していても重複キーエラーが発生しません。
疑似PKの重複キーチェックは行われません。重複キーエラーが出るのはDBのPK使用時に重複していた場合のみです。
リフレッシュ時にはまずターゲットのレコードを一度削除するようですが、削除しないようにできますか?
スクリプトで実現可能です。
DBMoto導入によってDBにかかる負荷はどの程度でしょうか?
DBMotoはDBに対するクライアントツールとしてのアクセスしか行わないため大きな負荷はかかりません。DBに対するエージェント導入も不要です。
ネットワーク障害が発生した場合、復旧処理は自動で行われますか?
自動で行われます。
必要とされる回線の帯域の目安はありますか?
回線が速ければレプリケーション速度も向上しますが、回線が遅くてもレプリケーションは十分可能です。ISDN回線を使用しているお客様もいらっしゃいます。
ログ出力先をWindowsイベントログにした場合historyファイルはどこにありますか?
Windowsイベントログでの運用の場合、historyファイルはご使用いただけません。
レコードの全消去時に他データべースへのレプリケーションをどのように行いますか?
AS/400でレコードの全消去を含む操作(CLRPFMやCPYF(REPLACEオプション))を行った場合、他データベースに対してこの変更をTRUNCATEとして他データベースに反映します。しかしレコードが対象ではなく、ファイルそのものを置き換えている場合など(RSTOBJ等)の場合、変更は他データベースへ反映されません。
シンクロナイゼーション時に双方の同じレコードを更新した場合にはどうなりますか?
下記のオプションから選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する(先勝ち)
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
なお、「TimeStampの遅いほうを優先(後勝ち)」としたい場合には、カスタムスクリプトの記述が必要となります。
ソースDBとターゲットDBで文字コードが異なっていても大丈夫?
問題ありません。DBMotoで文字コード変換を吸収します。
DBMoto内部ではUnicodeで処理され、双方のDBに対して文字コード変換を行います。
シンクロナイゼーションでレコードを更新してもレプリケーションされないことがあり、エラーも出力されません。
シンクロナイゼーションではDBMotoでの接続ユーザでレコードの更新をかけた場合にはレプリケーションされず、エラーも出力されません。これは無限ループを回避するための仕様です。シンクロナイゼーションを利用する場合、DBMotoで使用する接続ユーザは他のアプリケーションでは使用しないDBMoto専用のユーザを用意してください。
レプリケーション中にSQLServer側のコネクション数が最大値に達したというエラーが出ます。
SQL Server側とDBMoto側のMax Pool Sizeをご確認ください。DBMoto側のデフォルト値は100です。
スケジュール機能はありますか?
はい、あります。
リフレッシュを定期的に実行するリフレッシュスケジュール、ミラーリングを実行する日時を制限するミラーリングスケジュールの設定が可能です。
スケジュールは時・分・秒、年・月・日・曜日単位で細かく設定でき、複数設定も可能です。
DB障害が発生してレプリケーションが停止した際の復旧が心配です。データの不整合が発生してしまうのでは?
DBMotoは最後に更新したトランザクションIDを常に保持しておりますので、DB障害復旧後には、障害発生前の最後のトランザクションIDからレプリケーションを再開します。よって通常はデータの不整合が発生することはまずありません。
ミラーリングでソースに対してレコードの更新や削除を行った際に、ターゲット側にレコードが存在しなかった場合にはどのような挙動になりますか?
エラーメッセージ「ターゲットにレコードが存在しません」をログファイルに出力し、更新時にはターゲットに対して登録処理が行われます。オプション設定変更により登録処理を行わないようにもできます。
DBMotoで使用する通信の種類とポートを教えてください。
TCP/IPで通信し、DB で使用するデフォルトポートを使用します。例えばOracleの場合はデフォルトで1521を使用します。
データを加工したり変換してレプリケーションすることは可能ですか?
可能です。Expressionという機能を使用し、VB.NET の関数を使用できます。
自前の関数を定義して使用することは可能ですか?
可能です。スクリプトとしてオリジナルの関数を定義し、Expression という機能で呼び出すことが可能です。
レプリケーション対象外のフィールドがある場合に固定の値を必ず挿入する設定は可能ですか?
可能です。Expressionという機能を使用し、固定値を入れることも可能ですし、現在日時を挿入するなど、関数を使用することも可能です
マルチシンクロナイゼーションにおいて、ソースとターゲットの複数で同じタイミングで同一レコードの更新をかけた場合、どのサーバのレコードが優先されますか?
ソースとターゲットで同一レコードの更新があった場合の挙動は以下から選択可能です。
・ソースDBを優先する
・ターゲットDBを優先する
・TimeStampの早いほうを優先する
・カスタムスクリプト(上記3つ以外の挙動を設定したい場合など)
さらにターゲットの複数サーバで同一レコードの更新があった場合には、TimeStampの早いほうが優先されます。
ミラーリングモードでも初回でリフレッシュは可能ですか?
可能です。下記の弊社ブログをご参照ください。
DBMotoでの全件リフレッシュ・差分ミラーリングの再設定手順
nullを特定の値に変換してレプリケーションすることは可能でしょうか?
スクリプトを使用することで実現可能です。詳細は下記をご参照ください。
https://www.climb.co.jp/blog_dbmoto/archives/452
https://www.climb.co.jp/blog_dbmoto/archives/460

